
GPU 优化 - 算力,内存带宽理论分析,roofline model, GPU演进
GPU 访存带宽计算:

里面x2, 是因为显存是DDR, double data rate memory, 在每个时钟周期的上升和下降沿都可以传输数据
拿我的个人笔记本电脑(GeForce GTX 1650 Ti)来说,
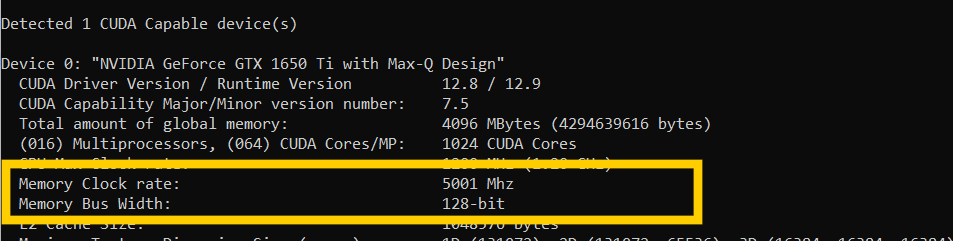

问题来了,这个带宽是单独读或者单独写的速率嘛?
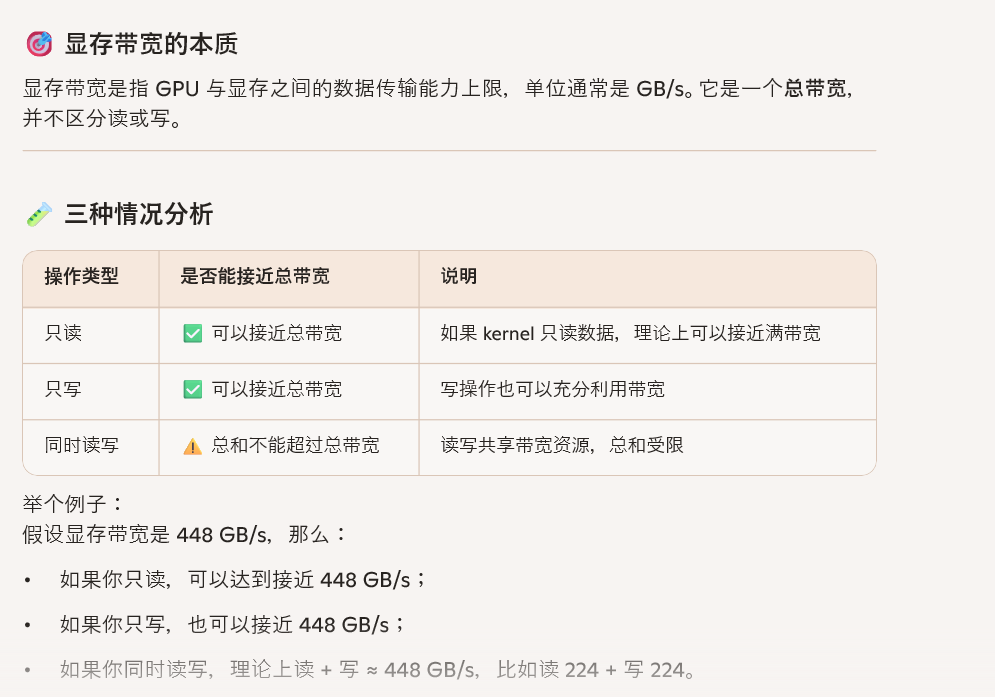
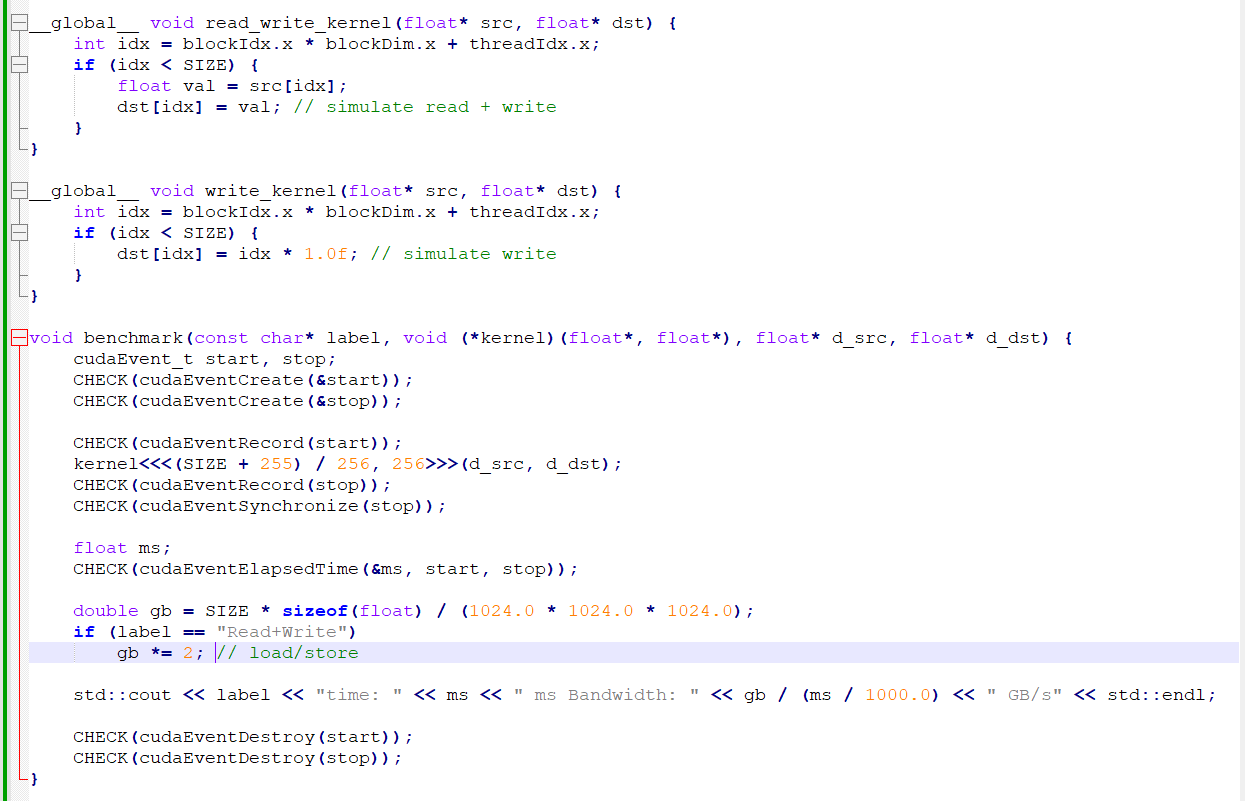
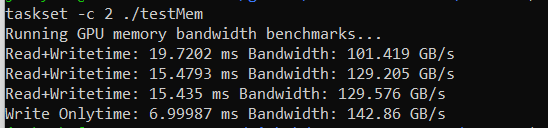
我如何写一个cuda程序让访存达到最大带宽?很简单,
算力分析:
指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是 FLOPS or FLOP/s。


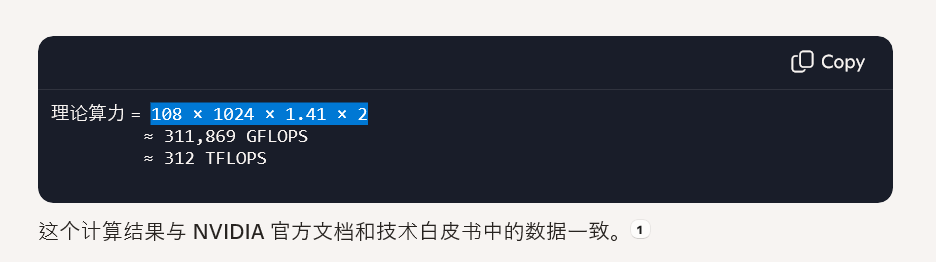
再拿我的个人电脑(GeForce GTX 1650 Ti)来说,
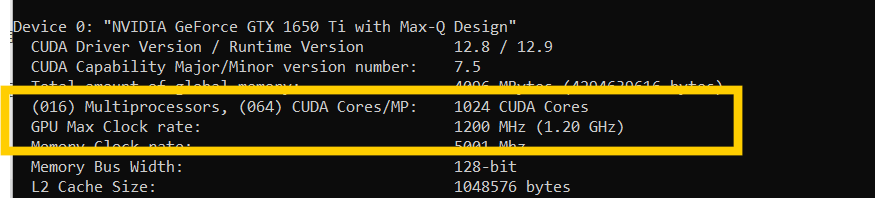
算力 = 1024 x 1200 Mhz x 2 = 2.4576 TFLOPs
另外提一点,gpu 处理器里面没有SIMD指令,所以单个cycle只能处理一个加法和乘法。
tensor core 算力:以A00为例


roofline model:
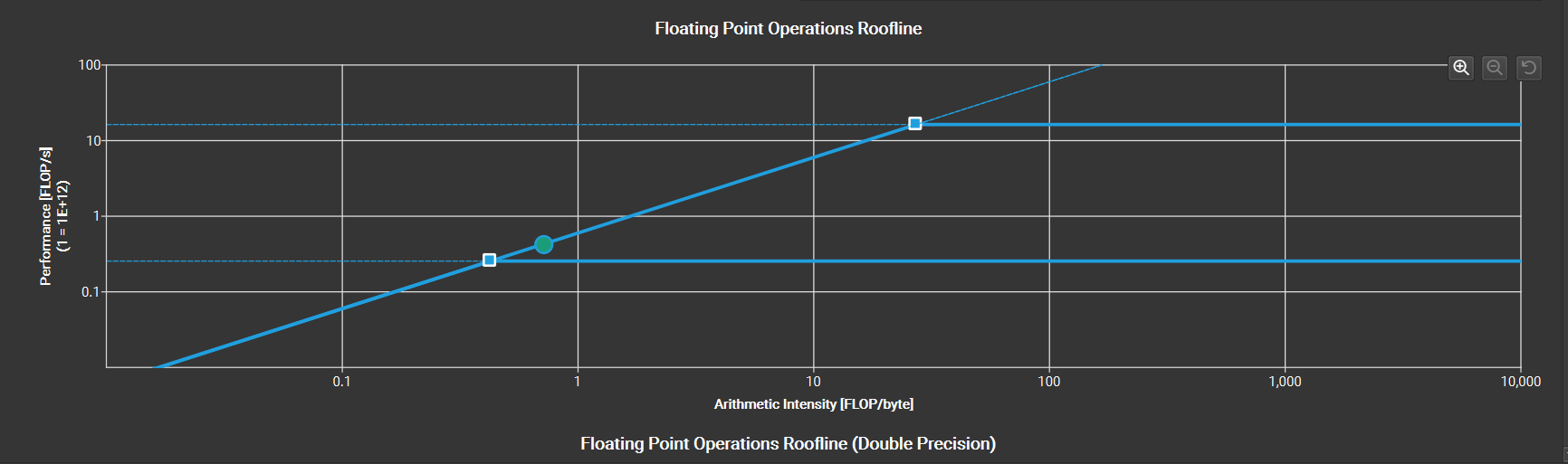
查看博客(Roofline Model与深度学习模型的性能分析 - 知乎)

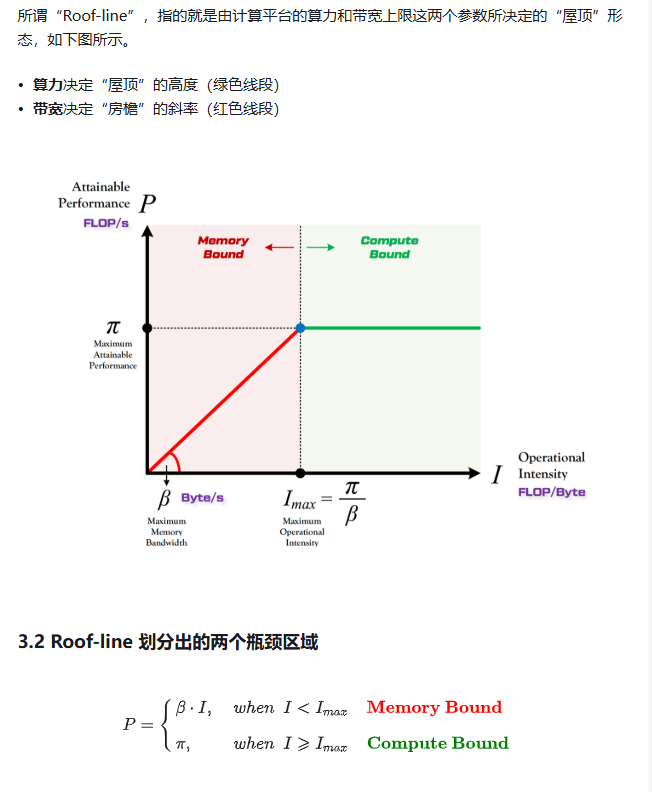
很好理解,当计算不足以掩藏内存读取的话,性能达不到最好。这个时候,尽可能的提高I(计算强度,也就是计算访存比)会带来性能提升,比如说减少内存的读取(方块矩阵乘法不就是这样嘛)。
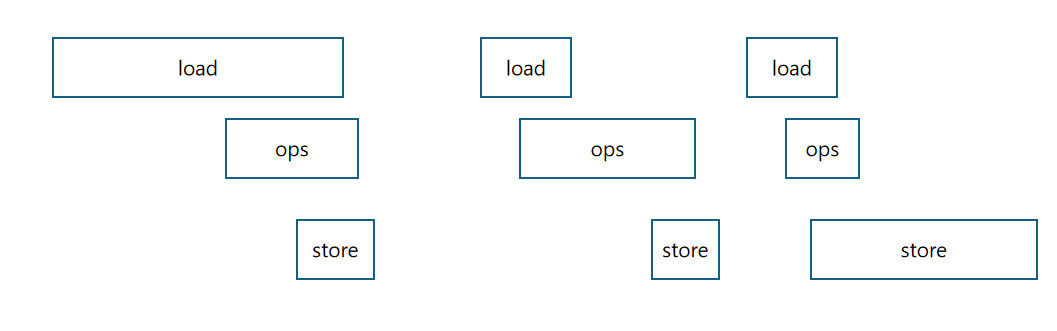
其实我想换一种说法,对于一个程序,由三个步骤,读取数据,计算,写回结果,它的性能极限取决于每个步骤的最大值。就是说,我们程序花费最小时间是三个步骤的最大时间,不可能更小了。不管每个步骤怎么分块隐藏其他步骤的时间,但是实际时间消耗肯定超过每个步骤的最大时间。
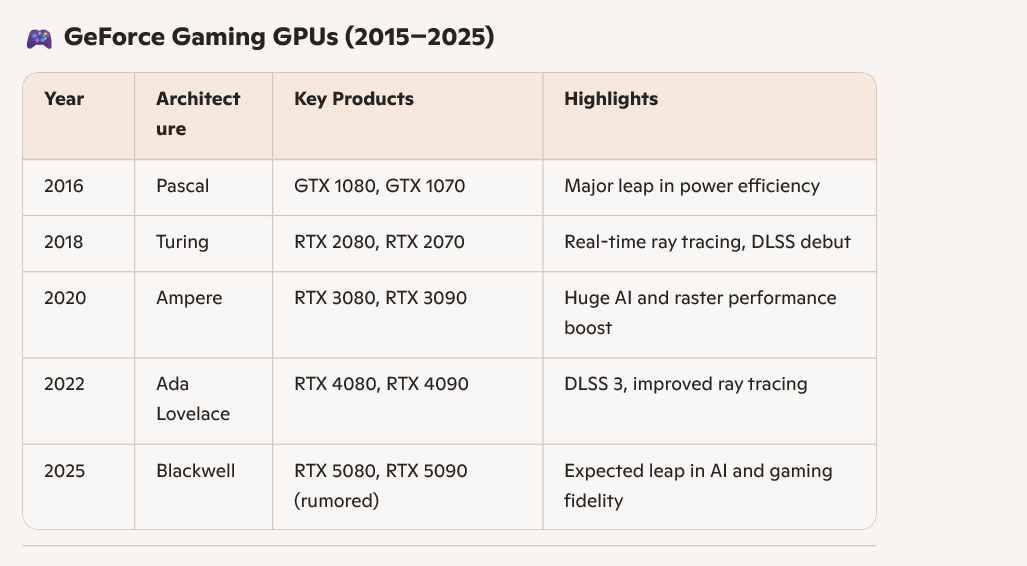
英伟达GPU演进:
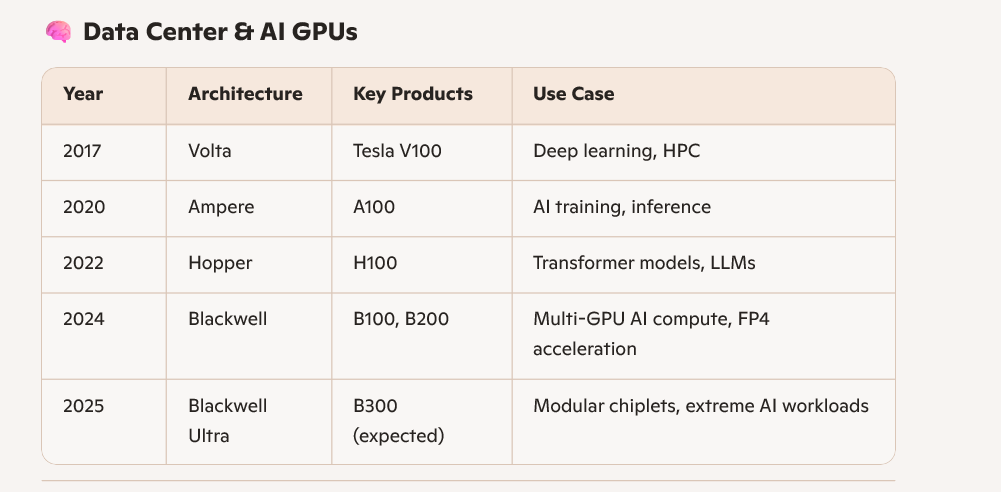
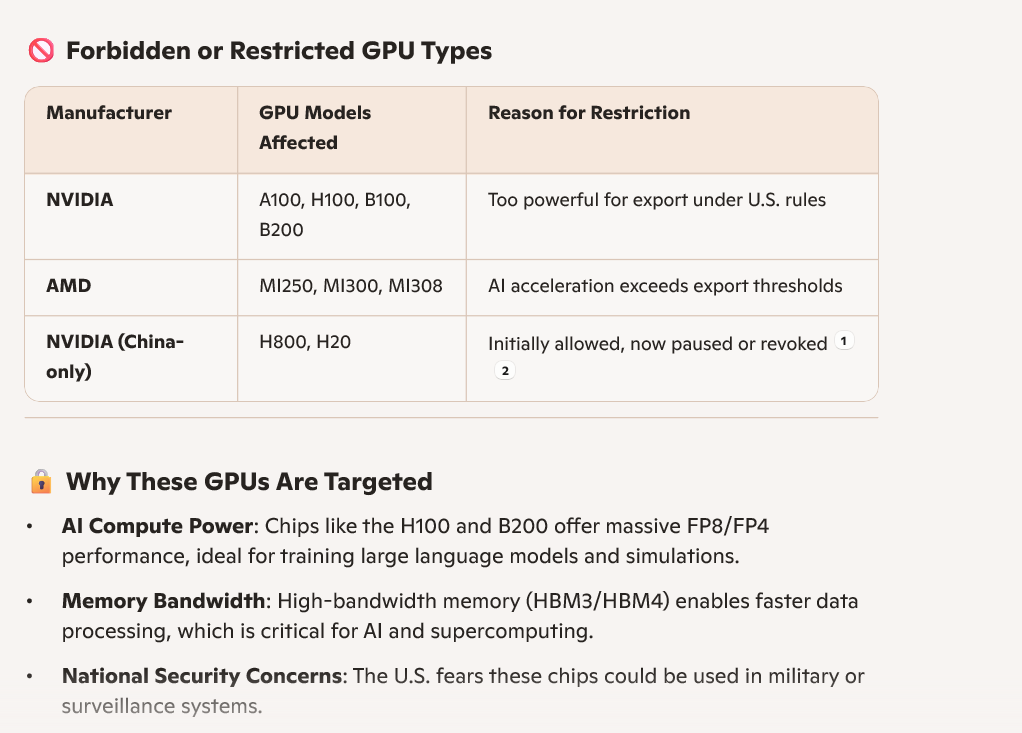
中国被禁的GPU芯片系列
我们对比一下B100 vs H100
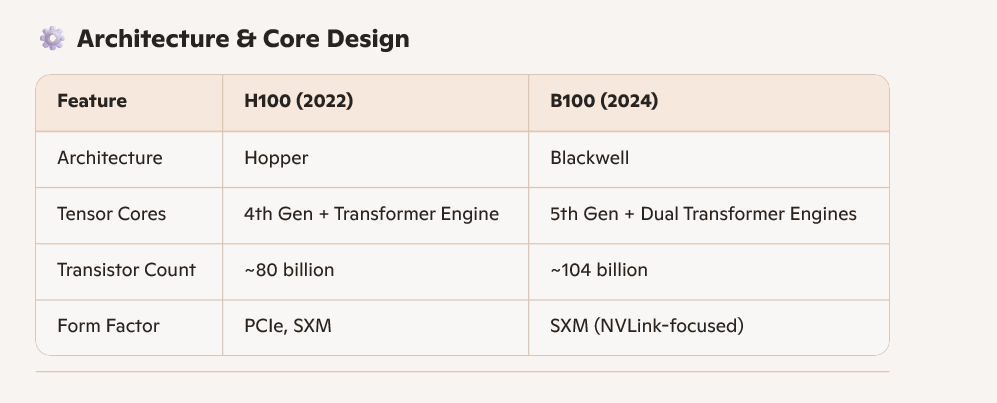
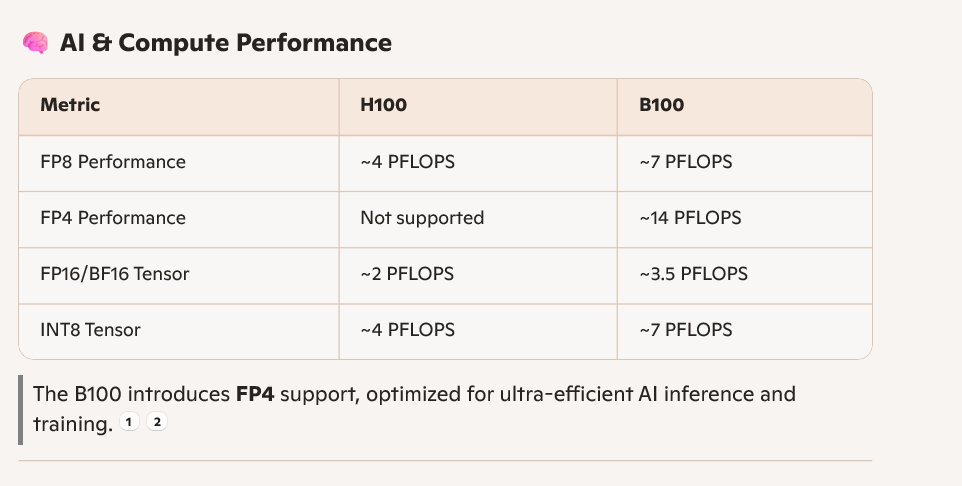

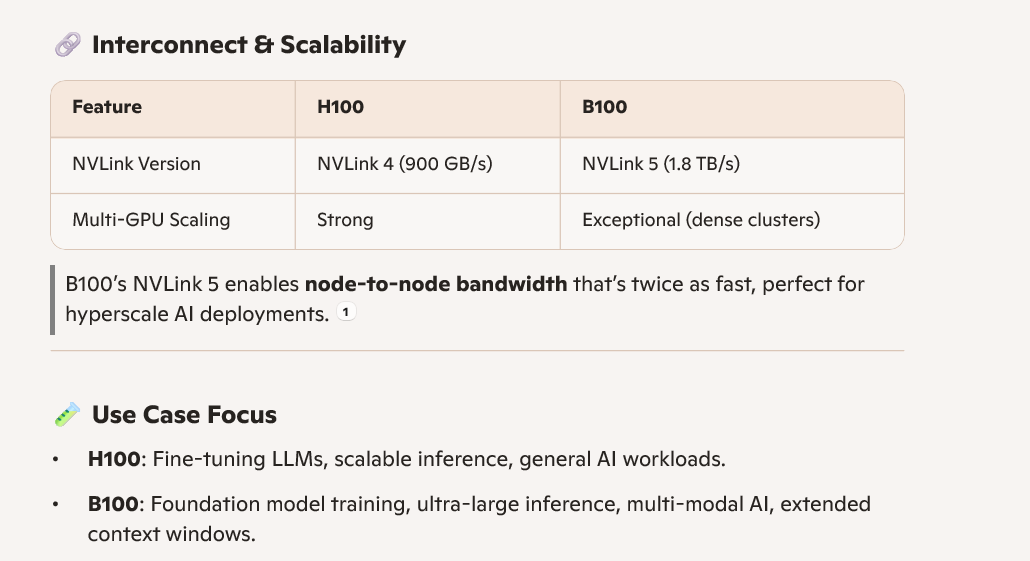
为什么B100的算力比H100增加了那么多?
1. 把两块芯片通过chiplet技术融合在一个GPU里面,相当于增加了SM的数量

2. 优化了tensor core实现,相当于tensor core 一个clock cycle 多做一些浮点运算

总结下来,GPU要强,一般通过各种工艺去提升算力,显存带宽,网络互联能力(NVlink)。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)