
首个支持大模型快速推理的类脑智算集群正式发布,类脑智能探索未来智算新模式
国外巨头纷纷布局这一全球 AI 必争赛道,在此背景下,以灵汐科技为代表的中国AI企业,基于类脑智能技术,也给出了。相比于纯神经拟态的专用技术路线(一些类脑计算机),杭州灵汐的异构融合类脑芯片及系统能同时高效支持深度学习神经网络和脉冲神经网络,具有兼容PyTorch、TensorFlow等深度学习框架,可直接服务于多类开源大模型的快速推理。(简称LynAInfra 128)是由灵汐科技自研的一体化大
2025年12月11日,灵汐杭州电信类脑智算集群在杭州正式发布。该集群由杭州灵汐类脑科技有限公司牵头搭建运营,中国电信、中国电子科技南湖研究院以及脑启社区作为合作方参与,由杭州电信具体承担集成建设。该集群部署在中国电信杭州智算中心,整体规模超百亿神经元、算力规模超200POPS,这也是首个支持大模型快速推理的类脑智算集群。

电信类脑智算集群发布仪式
活动期间,中国电信杭州分公司副总王元昊发表致辞,他表示杭州电信智算中心是中国电信全国“2+3+7”智算体系关键节点,而类脑智算集群方案具有国产化、超高性价比、高性能、低延时的特性,能为AI 应用落地提供坚实的算力基石。

中国电信杭州分公司副总王元昊致辞
随后,中国电信杭州分公司副总王元昊、灵汐科技副总华宝洪与中国电子科技南湖研究院瞿崇晓副院长及脑启社区负责人窦伟博士一同正式发布类脑智算集群。
作为类脑智能技术的创新应用成果,灵汐杭州电信类脑智算集群依托类脑计算的核心特性——模仿人类神经元连接方式,具有“存算一体、众核并行、稀疏计算、事件驱动”的特性,可显著提升计算效率、大幅降低能耗,实现语言大模型推理的 “一快、一低、一降” :一是推理速度快,单用户的推理延迟控制在毫秒级别,速度性能相对于传统方案有明显优势(可流畅响应实时交互及长本文深度推理),告别卡顿;二是首token延迟也很低,可降至百毫秒乃至十毫秒级;三是功耗大幅下降,较业界同等推理算力水平可降低功耗二分之一至三分之二以上。相比于纯神经拟态的专用技术路线(一些类脑计算机),杭州灵汐的异构融合类脑芯片及系统能同时高效支持深度学习神经网络和脉冲神经网络,具有兼容PyTorch、TensorFlow等深度学习框架,可直接服务于多类开源大模型的快速推理。

灵汐智算平台大模型登录
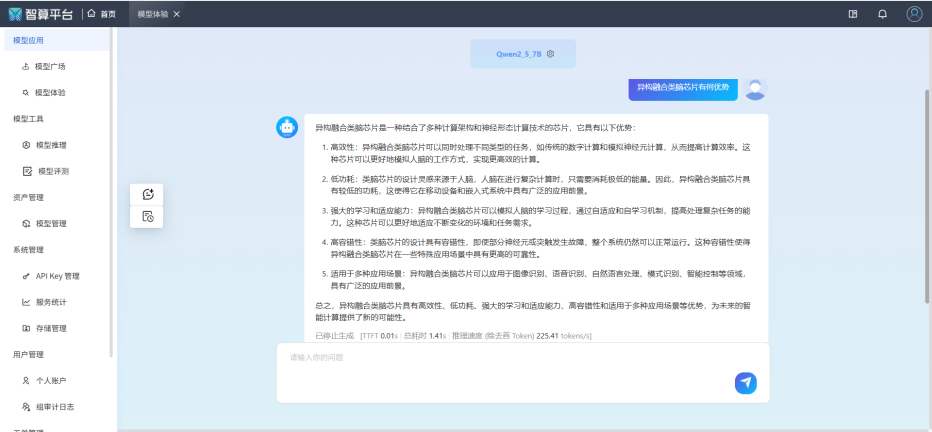
灵汐智算平台大模型快速推理
当前,大模型推理普遍存在吞吐速度慢(每秒十到几十词输出)和高延迟问题(常常超过1秒甚至数秒),对众多行业场景构成了制约。由此引发的 “时间敏感型推理” 技术革命正在全球范围内悄然进行。国外巨头纷纷布局这一全球 AI 必争赛道,在此背景下,以灵汐科技为代表的中国AI企业,基于类脑智能技术,也给出了“高实时、高吞吐、低延迟”的推理服务解决方案,将在金融应用、情感陪聊、快速导览、大规模数据标注以及无人机实时航拍处理、灾害预警与应急处置等领域场景逐步落地。

华宝洪介绍类脑智算集群及新一代高密类脑计算产品
发布仪式上,华宝洪还介绍了灵汐科技面向智算中心的新一代高密类脑计算产品。LynAInfra 128一体化方案(简称LynAInfra 128)是由灵汐科技自研的一体化大模型推理算力方案,为大模型提供模块化算力服务。通过多机柜的级联拓展,可支持各类规格的大模型,为客户提供一体化、高性能、低延时的大模型推理服务。
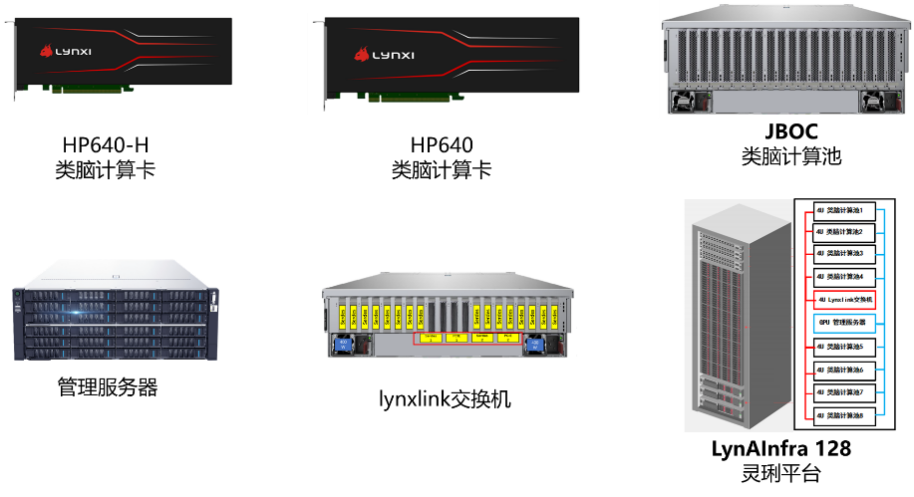
新一代高密类脑计算产品
LynAInfra 128集成128张高密算力板卡,整机柜提供近100P@fp16算力,机柜功耗在35KW以内,单位算力功耗为同规模方案最低,助力企业实现绿色低碳的智能化转型。LynAInfra 128方案通过创新性的类脑异构算力方案、高性能网络,实现单机柜即可替代传统多设备堆叠架构,显著减少硬件投入与运维复杂度,建设成本、运营费用双优化。让大模型推理的 TCO(总拥有成本)大幅降低,重塑行业性价比标杆。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)