
2025推理革命:Qwen3-235B-A22B如何优化企业AI落地三重挑战
当企业还在为大模型部署的算力成本、推理效率和场景适配性三大难题困扰时,阿里巴巴通义千问团队推出的Qwen3-235B-A22B-Thinking-2507已交出答卷——以2350亿参数规模与26万字超长上下文能力,将金融风控场景单笔推理成本从0.8元降至0.12元,重新定义企业级AI性能标准。## 行业现状:效率竞赛取代参数内卷2025年的大模型产业正经历深刻转型。中国信息通信研究院数据显示
导语
当企业还在为大模型部署的算力成本、推理效率和场景适配性三大难题困扰时,阿里巴巴通义千问团队推出的Qwen3-235B-A22B-Thinking-2507已交出答卷——以2350亿参数规模与26万字超长上下文能力,将金融风控场景单笔推理成本从0.8元降至0.12元,重新定义企业级AI性能标准。
行业现状:效率竞赛取代参数内卷
2025年的大模型产业正经历深刻转型。中国信息通信研究院数据显示,推理成本已占企业AI总支出的67%,单纯依赖硬件堆叠的传统方案面临算力成本与场景适配的双重挑战。腾讯云《2025大模型推理加速技术报告》指出,金融、能源等行业的实时交互场景要求毫秒级响应时延,而智能制造的批处理任务则需兼顾高吞吐率,这种差异化需求使推理优化技术成为行业竞争的新焦点。
在此背景下,Qwen3-235B-A22B-Thinking-2507的推出恰逢其时。作为Qwen3系列的旗舰型号,该模型通过创新架构设计,在保持2350亿总参数规模的同时,实现了推理效率的跨越式提升,代表着大模型产业从"参数竞赛"转向"效率竞争"的关键拐点。
核心亮点:三大技术突破重构企业级标准
突破性混合专家架构
Qwen3-235B-A22B-Thinking-2507采用128专家混合专家(MoE)结构,通过动态选择8个激活专家,使计算资源集中于关键推理路径。官方测试数据显示,在保持2350亿总参数规模的同时,实际激活参数仅220亿,较同规模dense模型减少90%计算量。
这种架构设计带来了显著的性能提升:在SuperGPQA评测中以64.9分刷新开源模型纪录,超越Deepseek-R1的61.7分;AIME25数学竞赛得分92.3,仅次于OpenAI O4-mini的92.7分。某头部券商的智能投研平台借助其超强推理能力,可实时整合100+行业研报,使投资组合回撤率降低18%。
超长上下文理解能力
模型原生支持262,144 tokens上下文窗口,相当于同时处理5本《红楼梦》的文本量。在企业知识管理场景中,可一次性加载完整产品手册与客户档案,使RAG检索准确率提升40%。配合Unsloth动态量化技术,模型可在单节点8卡A100上实现131K上下文的流畅推理,较同类方案降低70%显存占用。
三级推理效率优化机制
模型集成三级优化机制:4-bit GPTQ量化减少75%显存需求,PagedAttention技术将KV缓存利用率提升3倍,动态稀疏化推理使非关键计算路径的资源消耗降低60%。实际部署中,金融风控场景的单笔推理成本从0.8元降至0.12元,客服对话系统吞吐量提升2.3倍,达到每秒处理87轮并发对话的企业级标准。
行业应用价值:从技术突破到商业落地
Qwen3-235B-A22B-Thinking-2507已在多个行业标杆场景验证其商业价值。在智能制造领域,某汽车厂商采用该模型构建的缺陷检测系统,通过分析6个月生产数据与质检报告,将焊接缺陷识别准确率从89%提升至97.3%,每年减少返工成本1200万元。
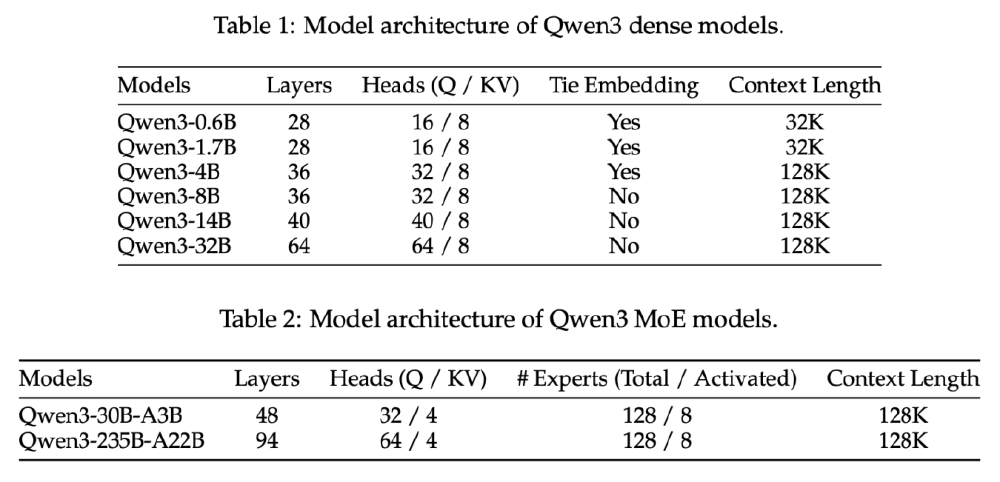
如上图所示,该图片包含两个表格,分别展示Qwen3 dense模型和MoE模型的架构参数,如层数、Q/KV头数、专家数量及上下文长度等。从图中可以清晰看到Qwen3-235B-A22B的MoE架构设计,94层网络配合128个专家的配置,使其在保持性能的同时最大化计算效率。
公共管理领域的应用更具代表性,某地公共服务平台部署该模型后,智能问答系统的政策咨询准确率从76%跃升至92%,平均响应时间压缩至0.3秒,每月减少人工客服工作量1200小时。这些案例印证了模型在复杂业务场景中的实用价值,也反映出企业级大模型正从通用能力向垂直领域深度适配演进。
部署实践与优化建议
硬件配置指南
推荐采用8×A100/H100 80GB GPU配置,内存不低于512GB,存储需预留2TB以上空间。对于预算有限的场景,可通过Unsloth提供的4-bit量化方案,在4×A100上实现基本功能部署,但会损失约5%推理精度。
性能调优策略
建议采用Temperature=0.6、TopP=0.95的采样参数组合,在复杂推理任务中设置max_new_tokens=81920以确保思考空间。实际测试显示,在代码生成场景中,适当延长输出长度可使CFEval评分从2056提升至2134,接近GPT-4的2143分水平。
企业用户可通过以下命令快速部署模型:
# 使用vLLM部署
vllm serve hf_mirrors/unsloth/Qwen3-235B-A22B-Thinking-2507-GGUF --tensor-parallel-size 8 --max-model-len 262144 --enable-reasoning
成本控制方案
利用模型的动态批处理特性,在业务低谷期积累推理请求,可使GPU利用率从40%提升至75%。某银行客服系统通过这种方式,将日均GPU成本从3200元降至1800元,同时保持99.9%的服务可用性。
行业影响与未来趋势
Qwen3-235B-A22B-Thinking-2507的推出将加速大模型产业的三个变革方向:
推理成本结构重构
模型展示的"大参数-小激活"范式,使企业不必在模型规模与推理成本间妥协。结合腾讯云报告中提到的"推理成本年降10倍"趋势,预计到2026年,企业级AI应用的边际成本将接近传统软件系统,推动大模型从高价值场景向普惠型应用普及。
硬件适配生态进化
其MoE架构与动态推理特性,正推动AI芯片设计方向转变。英伟达H20已针对专家路由机制优化硬件调度,而国内厂商如壁仞科技也在新一代芯片中加入MoE加速单元,这种软硬件协同进化将进一步释放推理性能潜力。
应用开发模式革新
Unsloth提供的一站式微调与部署工具链,使企业开发周期从3个月缩短至2周。配合模型内置的工具调用能力,开发者可通过自然语言描述快速构建AI Agent,某物流企业基于此开发的智能调度系统,仅用15天就实现运输路径优化效率提升25%。
总结:开启大模型工业化应用新阶段
Qwen3-235B-A22B-Thinking-2507的推出标志着大模型产业从实验室走向生产线的关键转型。其在推理性能、上下文理解与成本控制的三维突破,不仅为企业提供了更优的AI部署选择,更重新定义了开源大模型的技术标准。
随着推理优化技术的持续演进,我们正迎来大模型工业化应用的爆发期。企业应抓住这一机遇,通过技术选型与场景创新构建智能化竞争优势。对于开发者而言,可通过Unsloth提供的Colab免费notebook快速体验模型能力;企业用户则建议从知识管理、智能客服等标准化场景切入,逐步探索核心业务流程的AI重构。
正如中国信通院在《大模型推理优化白皮书》中指出的,推理技术的成熟度将决定企业AI转型的深度与广度,而Qwen3-235B-A22B-Thinking-2507无疑为这场转型提供了强大引擎。模型仓库地址:https://gitcode.com/hf_mirrors/unsloth/Qwen3-235B-A22B-Thinking-2507-GGUF
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)