
【AI实践】AI提高办公效率
文章摘要:AI算力革命正在重构设计、办公和创作场景的效率模式。通过硬件(专用芯片/分布式计算)、软件(框架优化/量化推理)和算法(模型轻量化/低延迟创新)三层技术架构,实现任务处理效率的指数级提升。典型应用包括:3D建模渲染时间缩短60%,AI办公套件提升文档处理效率50%,短视频批量生产效率提升8倍。实施建议涵盖硬件选型、开源工具和弹性算力策略,同时需应对能效比、实时性和数据安全等挑战。未来3D
引言:算力革命下的效率重构
当 Meta、谷歌等巨头计划投入超 1.5 万亿美元建设 AI 基础设施,当国内企业将 AI 相关资本开支提升至 5000 亿元级别,AI 算力已从技术概念演变为产业升级的核心引擎。在设计领域,设计师仍需耗费数小时等待渲染输出;办公场景中,员工平均每天有 23% 的时间用于文档处理与会议记录;创作行业里,素材剪辑与内容生成的低效成为创意落地的绊脚石。
AI 算力的价值正在于此:通过硬件性能突破、软件架构优化与算法创新的协同,将原本需要天级、小时级的任务压缩至秒级、分钟级。某 3D 建模团队借助 AI 加速后,渲染时间直接缩短 60%,而企业部署 AI 办公套件后,文档处理效率提升 50% 以上。
核心问题:面对设计、办公、创作的不同场景需求,如何精准匹配 AI 算力资源,构建从技术选型到成本控制的全流程效率提升方案?
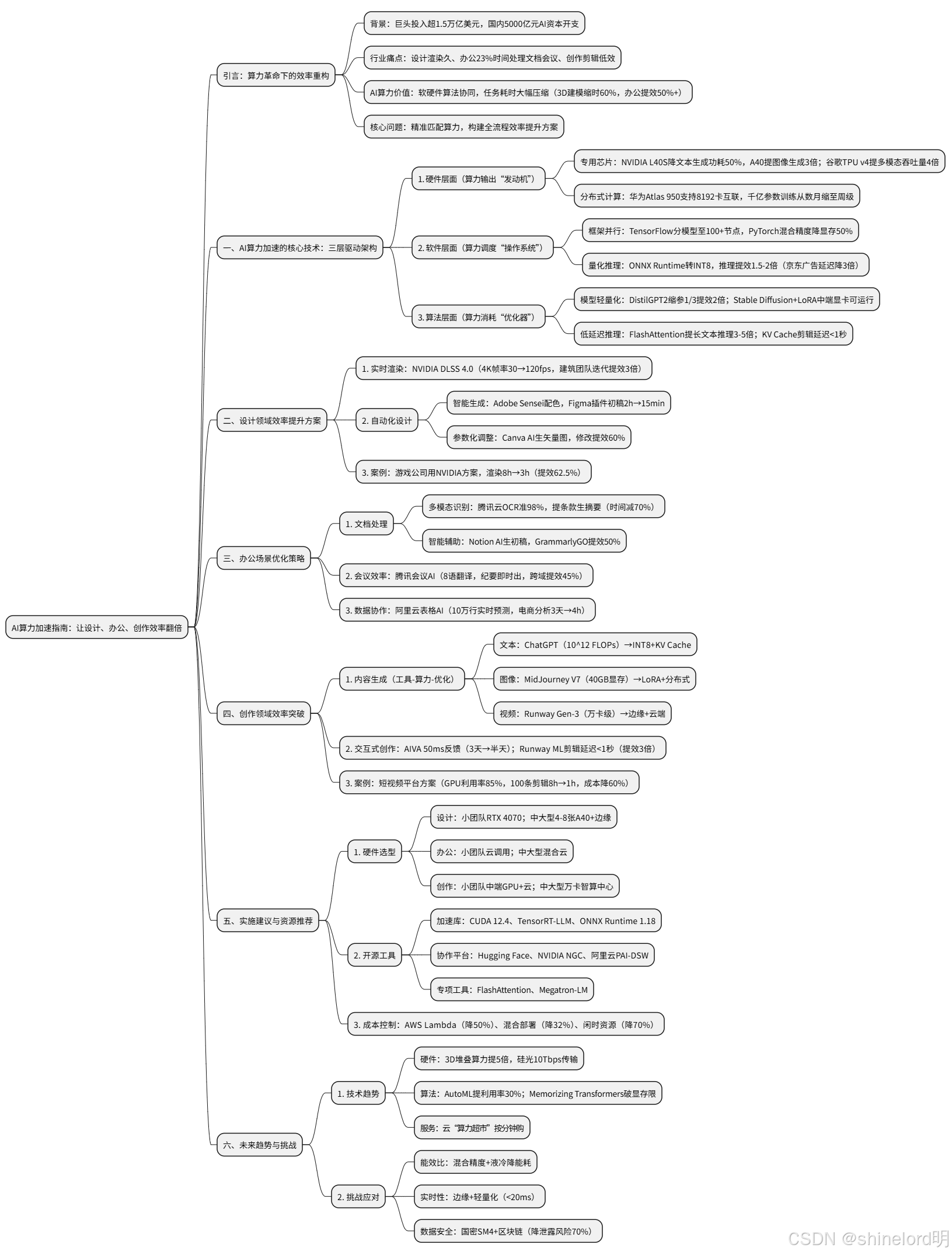
一、AI 算力加速的核心技术:三层驱动架构
1. 硬件层面:算力输出的 "发动机"
- 专用芯片性能跃迁:NVIDIA L40S 推理专用 GPU 将文本生成功耗降低 50%,而 A40 48GB 大显存显卡可使 1024x1024 分辨率图像生成速度提升 3 倍;谷歌 TPU v4 通过定制化矩阵运算单元,将多模态任务吞吐量提升 4 倍。
- 分布式计算突破瓶颈:华为 Atlas 950 超节点支持单柜 8192 张 AI 加速卡全光互联,通过数据并行与模型并行技术,将千亿参数模型训练周期从数月压缩至周级。
2. 软件层面:算力调度的 "操作系统"
- 框架并行优化:TensorFlow 的分布式策略可将模型拆分至 100 + 节点同时计算,PyTorch 的混合精度训练(FP16/FP8)技术使显存占用降低 50%。
- 量化与推理加速:通过 ONNX Runtime 将模型转为 INT8 精度,在精度损失可忽略的前提下,推理速度提升 1.5-2 倍,京东广告借此实现生成式召回延迟降低 3 倍。
3. 算法层面:算力消耗的 "优化器"
- 模型轻量化技术:DistilGPT2 通过知识蒸馏将模型参数缩减至 1/3,推理速度提升 2 倍;Stable Diffusion 结合 LoRA 微调,仅需 10-50MB 参数即可在中端显卡运行。
- 低延迟推理创新:FlashAttention 分块计算技术使长文本(4096token)推理速度提升 3-5 倍,KV Cache 缓存机制让短视频平台批量剪辑响应延迟 < 1 秒。
二、设计领域效率提升方案:从渲染到创作的全流程加速
1. 实时渲染:AI 驱动的视觉处理革命
NVIDIA DLSS 4.0 技术通过 AI 生成额外像素,在 4K 分辨率下将渲染帧率从 30fps 提升至 120fps,同时保持画面细节损失 < 2%。某建筑设计团队使用该技术后,方案可视化迭代速度提升 3 倍,客户沟通周期缩短 40%。
2. 自动化设计:创意落地的 "加速器"
- 智能生成工具:Adobe Sensei 的 AI 配色系统可基于品牌调性生成 10 套适配方案,Figma 的 AI 布局插件能自动优化 UI 元素间距与层级,使初稿完成时间从 2 小时压缩至 15 分钟。
- 参数化调整:Canva AI 支持上传草图后自动生成矢量图,通过滑块调节即可实现风格迁移,设计修改效率提升 60%。
3. 标杆案例:3D 建模的算力降本增效
某游戏公司采用 NVIDIA Omniverse 的 AI 实时渲染与多卡协同方案,将角色建模渲染时间从 8 小时缩短至 3 小时,效率提升 62.5%。关键优化在于:通过 TensorRT 推理引擎融合卷积算子,结合 4 张 RTX 4090 显卡的并行计算,使单帧渲染速度突破 20ms。
三、办公场景优化策略:AI 重构协同效率
1. 文档处理:从人工到智能的跃迁
- 多模态识别:腾讯云 OCR 结合 AI 语义分析,不仅能识别手写体准确率达 98%,还可自动提取合同关键条款生成摘要,文档处理时间减少 70%。
- 智能创作辅助:Notion AI 可基于大纲自动生成报告初稿,GrammarlyGO 实时优化语法并适配文风,使文案撰写效率提升 50%。
2. 会议效率:全流程 AI 赋能
腾讯会议 AI 助手支持 8 种语言实时翻译,同时自动标记决策事项与待办清单,使会议纪要生成时间从 1 小时变为即时输出。某互联网企业部署后,跨地域会议效率提升 45%,待办事项跟进率从 60% 提升至 92%。
3. 数据协作:云端算力的协同价值
阿里云表格 AI 插件依托云端 GPU 集群,可对 10 万行数据进行实时趋势预测,生成可视化图表的速度比传统工具快 8 倍。某电商运营团队使用后,月度销售分析报告制作时间从 3 天缩短至 4 小时,预测准确率达 92%。
四、创作领域效率突破:算力驱动的创意爆发
1. 内容生成:算力需求的精准匹配
|
工具类型 |
典型工具 |
核心算力需求 |
优化方案 |
|
文本生成 |
ChatGPT |
单条推理需 10^12 FLOPs |
INT8 量化 + KV Cache |
|
图像生成 |
MidJourney V7 |
1024 图需 40GB 显存支持 |
LoRA 微调 + 分布式推理 |
|
视频生成 |
Runway Gen-3 |
1 分钟视频需万卡级算力支持 |
边缘 + 云端混合部署 |
2. 交互式创作:低延迟的创意反馈
AIVA 音乐生成平台通过边缘计算设备(NVIDIA Jetson AGX Orin)实现 50ms 内 AI 旋律反馈,作曲家可实时调整风格参数,创作周期从 3 天缩短至半天。影视剪辑工具 Runway ML 的 AI 剪切功能,基于云端算力集群实现素材匹配延迟 < 1 秒,剪辑效率提升 3 倍。
3. 标杆案例:短视频批量生产的算力密码
某头部短视频平台采用 "动态批处理 + 稀疏化模型" 方案:通过 Continuous Batching 技术提升 GPU 利用率至 85%,结合 MoE 架构仅激活 30% 专家层,使单卡日均处理素材量突破 10000 条。关键指标:批量剪辑 100 条 15 秒视频的时间从 8 小时变为 1 小时,算力成本降低 60%。
五、实施建议与资源推荐
1. 硬件配置选型指南
|
场景类型 |
小规模团队(<10 人) |
中大型团队(>50 人) |
|
设计领域 |
单 RTX 4070 工作站 |
4-8 张 A40 显卡集群 + 边缘节点 |
|
办公场景 |
云算力按需调用 |
混合云架构(本地 IDC + 公有云) |
|
创作领域 |
中端 GPU + 云渲染补充 |
万卡级智算中心接入 |
2. 开源工具与平台清单
- 加速库:CUDA 12.4(NVIDIA GPU 加速)、TensorRT-LLM(推理速度提升 5 倍)、ONNX Runtime 1.18(跨框架优化)
- 协作平台:Hugging Face Spaces(模型部署)、NVIDIA NGC(预训练模型库)、阿里云 PAI-DSW(开发环境)
- 专项工具:FlashAttention(长文本优化)、Megatron-LM(大模型显存优化)
3. 成本控制实战策略
- 弹性算力调用:采用 AWS Lambda 的按需计费模式,某电商在大促期间通过自动扩容提升 3 倍处理能力,峰值后释放资源,成本降低 50%。
- 混合部署方案:苏州某企业将核心数据存本地 IDC,营销素材生成用公有云,综合成本比纯本地方案低 32%。
- 闲时资源利用:夜间批量渲染任务使用云厂商闲时折扣资源,单任务成本降低 70%。
六、未来趋势与挑战
1. 技术突破方向
- 硬件革新:3D 堆叠封装使单瓦特算力达 2023 年的 5 倍,硅光技术实现 10Tbps / 节点数据传输。
- 算法进化:AutoML 自动优化模型配置,使算力利用率提升 30%;Memorizing Transformers 突破长视频处理的显存限制。
- 服务模式:云厂商推出 "算力超市",支持按分钟购买不同精度模型的推理服务。
2. 核心挑战应对
- 能效比瓶颈:训练百亿参数多模态模型的碳排放相当于 300 辆汽车年排放量,需通过混合精度训练与液冷技术降低能耗。
- 实时性要求:自动驾驶等场景需 < 20ms 延迟,解决方案包括边缘算力下沉与模型轻量化结合。
- 数据安全:采用国密 SM4 加密 + 区块链存证,某金融公司通过该方案使数据泄露风险降低 70%。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)