
【Nature 2025】**LCTfound** :肺部 CT 视觉基础模型
本文发表在Nature Communications 2025,设计一个名为 LCTfound 的肺部 CT 视觉基础模型,它通过大规模的自监督学习,旨在成为肺部影像诊断与处理的通用智能平台。作者主要来自清华大学、复旦大学、广州医科大学第一附属医院等单位,背靠国家支持,资源和团队都比较豪华,训练集直接来自五个医院收集,验证集才使用开源数据集,算力直接上天河二号超算平台,文章撰写和配图都很漂亮,这不
本文发表在Nature Communications 2025,设计一个名为 LCTfound 的肺部 CT 视觉基础模型,它通过大规模的自监督学习,旨在成为肺部影像诊断与处理的通用智能平台。
作者主要来自清华大学、复旦大学、广州医科大学第一附属医院等单位,背靠国家支持,资源和团队都比较豪华,训练集直接来自五个医院收集,验证集才使用开源数据集,算力直接上天河二号超算平台,文章撰写和配图都很漂亮,这不是常规科研机构能做到的,因此本文先概述下文章大意,然后主要从代码角度去分析模型原理,本研究展示了DDPM 如何同时兼顾高级语义(诊断)和低级像素(增强)任务,这个挺值得学习的。

一、论文概述
现用AI生成论文概览
1.核心科学问题
本研究旨在解决肺部CT人工智能系统开发中的两大瓶颈:高质量标注数据的稀缺(尤其是针对罕见病)以及现有模型生成能力有限导致的临床实用性受限。
2.核心研究假设
作者假设:通过在超大规模、多中心的肺部CT数据集上,利用去噪扩散概率模型(DDPM影像特征与临床基本信息(如窗宽、窗位等)联合编码,可以构建一个在少量标注甚至无标注情况下,能胜任从“扫描级”诊断到“像素级”图像处理多种任务的基础模型。
3.研究设计
监督预训练:在 LungCT-28M 数据集上通过扩散策略学习稳健的特征表示。
实验验证:在涵盖诊断、分割、影像增强等 8 项下游任务中验证模型性能。
基准对比:将模型与 MAE、MedSAM 等顶尖医疗及通用基础模型进行多中心数据对比。
4.数据/样本来源
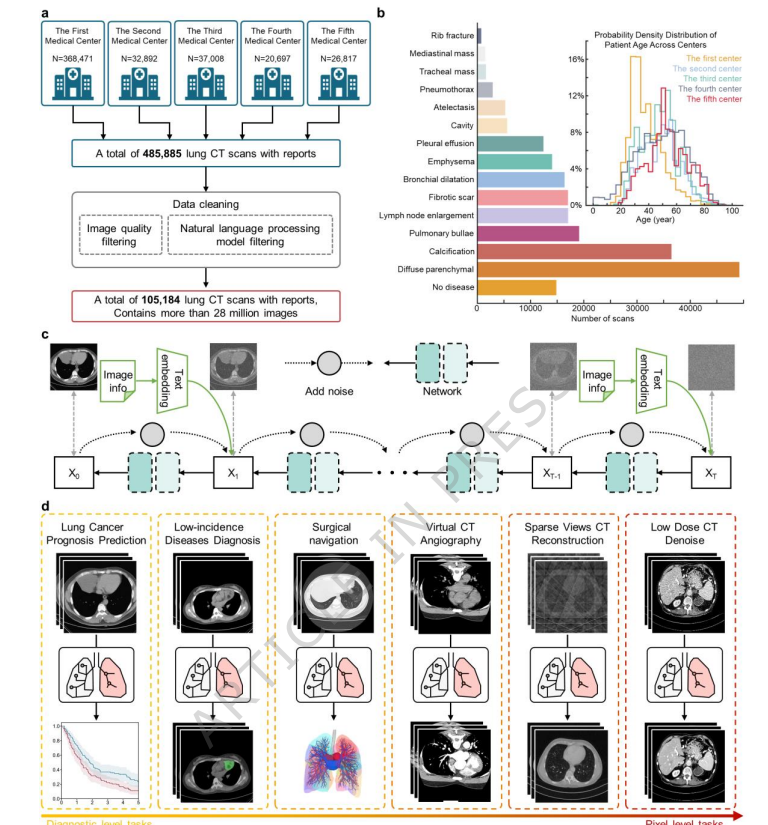
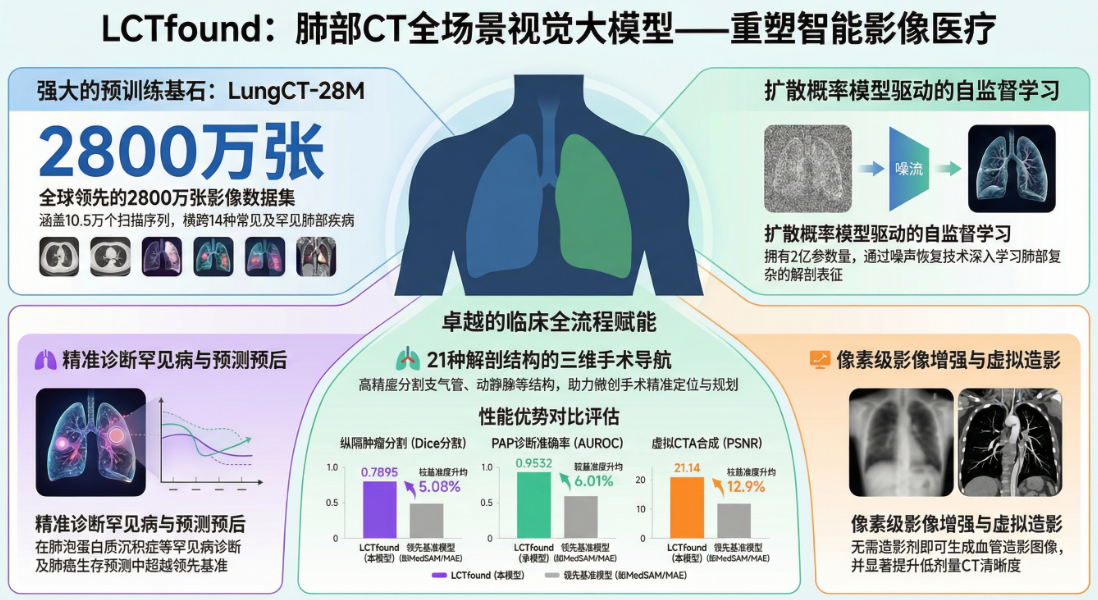
LungCT-28M 数据集:包含来自 5 个中心的 105184 次 CT 扫描,超过 2800 万张图像,涵盖 14 种常见疾病。
验证集:包括 LUNG1(420次扫描)、LUNA16、Mayo 2016 等公共数据集,以及来自多家医院的私有测试集(如 PAP 罕见病数据集)。
5.方法与技术
关键技术:去噪扩散概率模型(DDPM)自监督预训练。
算法模型:带有 Transformer 模块的 U-net 架构(约 200M 参数)。
关键机制:临床信息(经 Bert 编码)与影像特征通过 Cross-Attention 机制耦合。
实验平台:天河二号超算平台。
评价指标:诊断采用 AUROC;分割采用 Dice 系数;像素任务采用 PSNR、SSIM、VIF、RMSE、CLIPIQA、LPIPS。
统计验证:使用 Wilcoxon 符号秩和检验及 1,000 次自助抽样法计算 95% 置信区间。
6.核心发现
模型通用性:LCTfound 在无需大量标注的情况下,性能持续优于 MAE 和 MedSAM 等模型。
少样本优势:在罕见病(如 PAP 和纵隔肿瘤)的诊断和分割中展现出极强的迁移能力。
生成式潜力:其生成的虚拟 CTA 影像和稀疏视图重建质量极高,可减少辐射和造影剂伤害。
7.实验结果
定量结果:纵隔肿瘤分割 Dice 达到 0.7895(领先 MedSAM 5.08%);PAP 诊断 AUROC 达 0.9532;16 视图 CT 重建 PSNR 为 33.38。
定性结论:LCTfound 生成的热力图(Saliency map)能够精准聚焦病灶区域,与临床特征高度吻合。
辅助结果包括:
COVID-19 诊断:在 COVIDx CT 数据集上达到 99% 以上的 AUC。
零样本能力:在肺结节超分辨率任务中展现出优秀的零样本生成性能。
8.亮点讨论
亮点:开创性地将扩散模型应用于 CT 领域基础模型(DDPM-driven);跨越了从诊断到图像增强的巨大任务鸿沟。
局限性:目前主要基于 2D 图像预训练,对 z 轴连续性极强的小病灶(如肺结节)的 3D 空间建模仍有提升空间
二、通过代码理解模型
1.核心架构与预训练 (Pre-training)
pretrain_code/train_2D_ddpm.py这是 LCTfound 的“大脑”部分。从代码看不是简单的去噪自动编码器,而是结合了文本条件的条件扩散模型(Conditional DDPM)。
(1)模型骨架 (UNet2DConditionModel):代码使用了 diffusers 库中的 UNet2DConditionModel。
- 关键配置:在
down_block_types和up_block_types中,明确使用了"CrossAttnDownBlock2D"和"CrossAttnUpBlock2D"。 - 作用:这直接对应了论文中提到的 Cross-Attention 机制,允许模型在生成/理解图像时,关注外部的条件信息(如临床报告、扫描参数)。
(2)多模态条件注入 (BERT Embedding):
模型使用 BertModel(路径指向 ./chinesebert)处理中文临床文本,提取 [CLS] 向量作为句子的全局特征,并将其作为 encoder_hidden_states 传入 U-Net。这使得 LCTfound 能够理解“磨玻璃结节”、“肺气肿”等文本描述对应的图像特征。
# train_2D_ddpm.py 中
tokenizer = BertTokenizer.from_pretrained(bert_path)
bert_model = BertModel.from_pretrained(bert_path)
# ...
inputs = tokenizer(text, return_tensors='pt', ...)
cls_embedding = outputs.last_hidden_state[:, 0, :] # 提取 [CLS] 向量
prompt_embeding.append(cls_embedding)
这是主要训练代码,因此进行完整的注释以供学习:
前半部分导库之类是通用的
import os
import pdb
import math
from PIL import Image
from tqdm.auto import tqdm
import torch
import torch.nn.functional as F
from dataclasses import dataclass
from accelerate import Accelerator
from diffusers import UNet2DModel, UNet2DConditionModel
from diffusers import DDPMScheduler
from my_pipeline_ddpm import DDPMPipeline
from diffusers.optimization import get_cosine_schedule_with_warmup
from utils.util import get_dl
import safetensors
from transformers import BertTokenizer, BertModel
# 定义训练配置类,用于管理所有超参数
@dataclass
class TrainingConfig:
# 输入图像的分辨率大小 (256x256)
image_size = 256
# 训练时的批次大小 (Batch Size)
train_batch_size = 24
# 验证/评估时的批次大小
eval_batch_size = 16
# 训练的总轮数 (Epochs)
num_epochs = 6
# 梯度累积步数,用于在显存不足时模拟更大的 Batch Size
gradient_accumulation_steps = 1
# 学习率
learning_rate = 1e-4
# 学习率预热步数 (Warmup)
lr_warmup_steps = 10000
# 每多少步进行一次评估和保存
eval_freq_step = 10000
# 混合精度设置,"bf16" (Brain Floating Point) 比 fp16 更稳定
mixed_precision = "bf16" # `no` for float32, `fp16` for automatic mixed precision
# 模型和日志的输出目录
output_dir = "save_dir" # the model name locally and on the HF Hub
# 数据加载的工作线程数
num_workers = 4
# 是否覆盖输出目录
overwrite_output_dir = True # overwrite the old model when re-running the notebook
# 随机种子,保证实验可复现
seed = 421
# BERT 模型的本地路径,用于提取文本特征
bert_path = "./chinesebert"
# 辅助函数:将多张图片拼接成网格状,方便可视化
def make_grid(images, rows, cols):
w, h = images[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
for i, image in enumerate(images):
grid.paste(image, box=(i % cols * w, i // cols * h))
return grid
# 评估函数:在训练过程中生成样本以检查模型效果
def evaluate(config, epoch, pipeline, prompt_embeding):
# 从随机噪声开始采样图像 (反向扩散过程)
# 这里的 pipeline 是自定义的 DDPMPipeline,支持 condition 输入
images = pipeline(
batch_size=config.eval_batch_size,
generator=torch.manual_seed(config.seed), # 使用固定种子以观察同一噪声源的生成变化
condition=prompt_embeding, # 传入文本条件 Embedding
).images
# 计算网格的行列数
num_grid = int(math.sqrt(config.eval_batch_size))
# 将生成的图片拼成网格
image_grid = make_grid(images, rows=num_grid, cols=num_grid)
# 创建保存目录
test_dir = os.path.join(config.output_dir, "samples")
os.makedirs(test_dir, exist_ok=True)
# 保存生成的图像,文件名包含 epoch 信息
image_grid.save(f"{test_dir}/{epoch:04d}.png")
# 辅助函数:获取 HuggingFace 仓库的全名 (如果需要上传到 Hub)
def get_full_repo_name(model_id: str, organization: str = None, token: str = None):
if token is None:
token = HfFolder.get_token()
if organization is None:
username = whoami(token)["name"]
return f"{username}/{model_id}"
else:
return f"{organization}/{model_id}"
接下来是核心训练循环
# 核心训练循环函数
def train_loop(config, accelerator, model, noise_scheduler, optimizer, train_dataloader, lr_scheduler):
# 获取 BERT 模型路径
bert_path = config.bert_path
# 加载 BERT 分词器
tokenizer = BertTokenizer.from_pretrained(bert_path)
# 加载 BERT 模型结构
bert_model = BertModel.from_pretrained(bert_path)
# 初始化 Accelerator 的追踪器 (如 TensorBoard)
if accelerator.is_main_process:
if config.output_dir is not None:
os.makedirs(config.output_dir, exist_ok=True)
accelerator.init_trackers("train_example")
# 使用 Accelerator 准备所有训练对象 (模型、优化器、数据加载器等)
# 这会自动处理设备放置 (Device Placement) 和分布式训练设置
model, optimizer, train_dataloader, lr_scheduler, bert_model = accelerator.prepare(
model, optimizer, train_dataloader, lr_scheduler, bert_model
)
global_step = 0 # 全局步数计数器
print("start training.")
# 开始 Epoch 循环
for epoch in range(config.num_epochs):
# 设置进度条
progress_bar = tqdm(total=len(train_dataloader), disable=not accelerator.is_local_main_process, dynamic_ncols=True)
progress_bar.set_description(f"Epoch {epoch}")
# 遍历数据加载器中的每一个 Batch
for step, batch in enumerate(train_dataloader):
# --- 1. 文本条件处理 (Text Conditioning) ---
prompt_embeding = []
# batch[1] 包含文本描述列表
for text in batch[1]:
# 使用 BERT 分词器处理文本,转为 Tensor,并移动到对应设备
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
inputs = {k:inputs[k].to(batch[0].device) for k in inputs}
# 提取 BERT 特征,不计算梯度 (冻结 BERT)
with torch.no_grad():
outputs = bert_model(**inputs)
# 获取 BERT 最后一层的隐藏状态
# 取 [CLS] token (索引0) 的向量作为整个句子的嵌入表示 (Sentence Embedding)
cls_embedding = outputs.last_hidden_state[:, 0, :].squeeze()
# 调整形状为 (1, 1, hidden_dim) 以适配 U-Net 的输入要求
prompt_embeding.append(cls_embedding.view(1, 1, -1))
# 将 Batch 中所有文本的 Embedding 拼接起来 -> (Batch_Size, 1, hidden_dim)
prompt_embeding = torch.cat(prompt_embeding, dim=0)
# pdb.set_trace() # 调试断点
# --- 2. 图像数据准备 ---
# 获取干净的图像数据,取前3个通道 (RGB) -> (Batch_Size, 3, H, W)
clean_images = batch[0][:,:3,:,:]
# --- 3. 前向扩散过程 (Forward Diffusion) ---
# 采样与图像形状一致的高斯噪声
noise = torch.randn(clean_images.shape).to(clean_images.device)
bs = clean_images.shape[0]
# 为每张图片随机采样一个时间步 t (0 到 T-1)
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bs,), device=clean_images.device
).long()
# 根据时间步 t,将噪声添加到干净图像上
# 公式: x_t = sqrt(alpha_bar_t) * x_0 + sqrt(1 - alpha_bar_t) * noise
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
# --- 4. 模型预测与反向传播 ---
# 使用 gradient accumulation (梯度累积) 上下文
with accelerator.accumulate(model):
# 预测噪声残差 (Noise Residual)
# 输入: 加噪图像, 时间步, 文本条件 Embedding
# return_dict=False 确保返回 tuple,[0] 取出预测结果
noise_pred = model(noisy_images, timesteps, encoder_hidden_states=prompt_embeding, return_dict=False, )[0]
# 计算损失:预测噪声与真实噪声之间的 MSE Loss
loss = F.mse_loss(noise_pred, noise)
# 反向传播计算梯度
accelerator.backward(loss)
# 梯度裁剪,防止梯度爆炸 (阈值 1.0)
accelerator.clip_grad_norm_(model.parameters(), 1.0)
# 更新模型参数
optimizer.step()
# 更新学习率
lr_scheduler.step()
# 清空梯度
optimizer.zero_grad()
# --- 5. 日志记录 ---
progress_bar.update(1)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
global_step += 1
# --- 6. 评估与保存 ---
# 仅在主进程中执行,且满足评估频率要求时
if accelerator.is_main_process and global_step % config.eval_freq_step == 0:
# 创建推理 Pipeline,使用当前模型的解包版本 (去掉 DDP 包装)
pipeline = DDPMPipeline(unet=accelerator.unwrap_model(model), scheduler=noise_scheduler)
# 生成并保存评估图像
# 计算当前的 step 索引用于命名
evaluate(config, epoch*len(train_dataloader)+step, pipeline, prompt_embeding)
# 保存模型权重到输出目录
pipeline.save_pretrained(config.output_dir)
接下来是程序入口:
# 程序入口
if __name__ == "__main__":
# 实例化配置对象
config = TrainingConfig()
#### 数据集和数据加载器设置 ####
# get_dl 是自定义的数据加载函数,返回 DataLoader 和 Dataset
train_dataloader, train_dataset = get_dl(config=config)
#### 模型设置 ####
# 初始化条件 U-Net 模型 (UNet2DConditionModel)
model = UNet2DConditionModel(
sample_size=config.image_size, # 目标图像分辨率
in_channels=3, # 输入通道数 (RGB 为 3)
out_channels=3, # 输出通道数
layers_per_block=2, # 每个 U-Net 块中的 ResNet 层数
block_out_channels=(64, 128, 256, 512, 1024), # 每个 U-Net 块的输出通道数置
# 下采样块类型配置
down_block_types=(
"DownBlock2D", # 普通下采样
"CrossAttnDownBlock2D", # 带交叉注意力的下采样 (用于注入文本条件)
"CrossAttnDownBlock2D",
"CrossAttnDownBlock2D",
"DownBlock2D",
),
# 上采样块类型配置 (与下采样对称)
up_block_types=(
"UpBlock2D",
"CrossAttnUpBlock2D",
"CrossAttnUpBlock2D",
"CrossAttnUpBlock2D",
"UpBlock2D",
),
norm_num_groups=32, # Group Normalization 的组数
# addition_embed_type="text",
# addition_embed_type_num_heads=64,
encoder_hid_dim_type="text_proj", # 编码器隐藏层维度类型,使用投影
encoder_hid_dim=768, # 编码器隐藏层维度 (对应 BERT-base 的输出维度 768)
)
# --- 加载预训练权重 (可选) ---
# 指定预训练权重的路径
model_path = "/GPUFS/gyfyy_jxhe_1/User/gaozebin/project/ddpm/2d_ddpm_lung_with_ca/ddpm-lung-256-big-1/unet"
# 使用 safetensors 加载权重文件
pretrained_w = safetensors.torch.load_file(model_path + "/diffusion_pytorch_model.safetensors")
# 将权重加载到模型中,strict=False 允许部分键值不匹配
model.load_state_dict(pretrained_w, strict=False)
# --- 测试模型输入输出形状 (调试用) ---
sample_image, _ = train_dataset[10] # 取出一个样本
sample_image = sample_image.unsqueeze(0) # 增加 Batch 维度 -> (1, 3, H, W)
print("Input shape:", sample_image.shape)
# out = model(sample_image, timestep=0).sample
# print("Output shape:", out.shape)
# print("Out value:", out.min(), out.max())
# --- 噪声调度器 (Scheduler) 设置 ---
# 初始化 DDPM 调度器,设置扩散步数为 1000
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
# 生成随机噪声
noise = torch.randn(sample_image.shape)
# 设定一个测试时间步
timesteps = torch.LongTensor([50])
# 测试加噪过程
noisy_image = noise_scheduler.add_noise(sample_image, noise, timesteps)
# 保存加噪后的测试图片
Image.fromarray(((noisy_image.permute(0, 2, 3, 1) + 1.0) * 127.5).type(torch.uint8).numpy()[0]).save("noise_img.png")
# (注释掉的代码) 测试模型预测和损失计算
# noise_pred = model(noisy_image, timesteps).sample
# loss = F.mse_loss(noise_pred, noise)
# print(loss)
# --- 优化器与学习率调度器 ---
# 使用 AdamW 优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate)
# 使用带预热的余弦退火学习率调度器
lr_scheduler = get_cosine_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=config.lr_warmup_steps,
num_training_steps=(len(train_dataloader) * config.num_epochs),
)
# --- 初始化 Accelerator ---
# 配置混合精度、梯度累积和日志记录
accelerator = Accelerator(
mixed_precision=config.mixed_precision,
gradient_accumulation_steps=config.gradient_accumulation_steps,
log_with="tensorboard",
project_dir=os.path.join(config.output_dir, "logs"),
)
# --- 启动训练循环 ---
train_loop(config, accelerator, model, noise_scheduler, optimizer, train_dataloader, lr_scheduler)
CrossAttnDownBlock2D/CrossAttnUpBlock2D:在卷积层之间插入了 Transformer (Cross-Attention) 层的块。这部分完全复用了diffusers库成熟的架构实现。
再看数据集怎么构建的,在不同任务中都有数据集构建,大同小异,我们选择其中一个classification/data_utils.py,这个类主要用于加载 2D 肺部 CT 切片数据,并结合临床文本信息(如性别、年龄等)进行多模态分类任务的数据准备。
import json
import natsort
import numpy as np
from glob import glob
from PIL import Image
import torch
import torch.nn as nn
from monai import transforms
from torch.utils.data import Dataset
class MDataset_2D(Dataset):
def __init__(
self,
image_size,
section="train", # 数据集划分:'train', 'val', 或 'test'
processor=None, # 可选的外部处理器(如 Transformer 的 image_processor)
use_processor=False
):
super().__init__()
# 原始数据存放路径
fp = "/path/to/data/"
# 加载数据集划分文件 (JSON格式),包含 train/val/test 的病人ID列表
with open("/path/to/split.json", "r") as f:
self.split = json.load(f)
# 加载标签文件 (Numpy格式),是一个字典 {pid: label}
self.labels = np.load("/path/to/label.npy", allow_pickle=True).item()
# 获取当前 section 对应的病人 ID 列表
pids = self.split[section]
# 定义临床信息的 Embedding 字典:将文本特征映射为固定数值向量
# 例如:性别(female/male)、部位(left/right)、年龄(old/young)、特征(obesity等)
self.clinic_embed = {
'female':np.array([0]), 'male':np.array([1]), 'left':np.array([0]), 'right':np.array([1]),
'old':np.array([0]), 'young':np.array([1]), 'standard':np.array([0]), 'trachea':np.array([0.5]),'obesity':np.array([1]),
}
self.paths = []
# --- 构建图像路径列表 ---
iids = []
for iid in pids:
# 使用 glob 查找该病人 ID 下的所有 png 格式 CT 切片
cts = glob(f"{fp}/{iid}*.png")
if cts != []:
iids.append(iid)
# 使用自然排序 (natsort) 确保文件名按切片顺序排列 (如 slice_1, slice_2, ... slice_10)
cts = natsort.natsorted(cts)
# --- 关键策略:切片选择 ---
# 训练集:选取中间切片的前后各 6 张(共 ~12 张),增加数据丰富度
if section == "train":
self.paths += cts[len(cts) // 2 - 6 : len(cts) // 2 + 6]
# 验证/测试集:仅选取正中间的 1 张切片,作为该病人的代表进行预测
else:
self.paths += cts[len(cts) // 2 : len(cts) // 2 +1]
print(section, iids) # 打印当前加载的病人 ID 列表
# --- 定义数据增强与预处理流程 (使用 MONAI) ---
self.transform = transforms.Compose([
# 统一调整图像分辨率
transforms.Resize([image_size,image_size]) ,
# 仅在训练时:随机旋转图像(增加模型鲁棒性)
transforms.RandRotate(range_x=0.5, range_y=0.5, prob=0.5) if section == "train" else nn.Identity(),
# 转换为 PyTorch Tensor
transforms.ToTensor(),
# 仅在训练时:随机粗粒度 Dropout (在图像上挖洞遮挡),防止过拟合
transforms.RandCoarseDropout(4, (16,16)) if section == "train" else nn.Identity(),
])
self.use_processor = use_processor
if use_processor:
self.processor = processor
self.image_size = image_size
def __len__(self):
# 返回数据集的总样本数
return len(self.paths)
def __getitem__(self, index):
# 获取第 index 张图片的路径
fp = self.paths[index]
fn = fp.split("/")[-1]
# 从文件名解析病人 ID (假设格式为 PID_xxx.png)
pid = fn.split("_")[0]
# 获取该样本的分类标签
label = self.labels[pid]
# --- 读取图像 ---
# 打开图片并转为灰度 ('L'),归一化到 [0, 1]
arr_f = np.array(Image.open(fp).convert("L")) / 255.
# 读取对应的 "_zg" 后缀图像 (可能是去噪图或某种增强视图)
# 注意:代码虽然读取了它,但在后续构建 arr 时并未使用 arr_zg
arr_zg = np.array(Image.open(fp.replace(".png", "_zg.png")).convert("L")) / 255.
# --- 处理临床文本特征 ---
embed_vec = []
# 遍历该病人的临床关键词列表 (self.clinic)
# !注意!:self.clinic 在 __init__ 中未见定义,这可能是一个 Bug 或应当在外部加载
# 实际运行时可能需要补充:self.clinic = np.load("clinic_info.npy").item()
for word in self.clinic[pid]:
# 查表获取向量
vec = torch.tensor(self.clinic_embed[word]).float()
embed_vec.append(vec)
# 将所有关键词向量拼接成一个长向量
embed_vec = torch.cat(embed_vec, dim=-1)
embed_vec = embed_vec.squeeze(0)
# --- 构建 3 通道输入 ---
# 虽然 CT 是单通道,但为了适配常规预训练模型,这里将其复制 3 份模拟 RGB
arr = np.zeros((3, self.image_size, self.image_size))
arr[0] = arr_f
arr[1] = arr_f
arr[2] = arr_f
# --- 返回数据 ---
# 如果使用特定的 Processor (如 CLIP/BERT 的处理器)
if self.use_processor:
res = self.processor.image_processor(
images=self.transform(arr), do_rescale=False
)
return res, label, pid, fn, embed_vec
# 默认返回:增强后的图像 Tensor、标签、ID、文件名、临床特征向量
return self.transform(arr), label, pid, fn, embed_vec
2.下游任务 A:图像增强 (Image Enhancement)
image_enhancement/patch_cold_diffusion.py这部分实现了论文提到的 Cold Diffusion 技术,用于低剂量 CT 去噪或伪影去除。在传统扩散 (DDPM)中认为图像的“退化”是加高斯噪声。而本文Cold Diffusion采用另外的思路,认为图像的“退化”可以是任意过程(比如低剂量 CT 扫描导致的伪影、模糊)。
核心模块 (UNet):这里的 U-Net 经过了修改,它接收 x_adjust(调节参数)和 adjust(开关),这允许模型不仅仅是去噪,而是根据输入的条件(如低剂量图像本身)来进行确定性的修复。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import copy
from einops import rearrange
from .UNet2D import UNet2DConditionModel # 引用了基础的 UNet 结构
import safetensors
# 位置编码 (Sinusoidal Positional Embeddings)
# 用于将时间步 t (time step) 编码为向量,告诉模型现在的去噪程度
class SinusoidalPosEmb(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, x):
device = x.device
half_dim = self.dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
emb = x[:, None] * emb[None, :]
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return emb
# ... (中间省略了基础的 conv, up, outconv 模块,它们是构建 UNet 的积木) ...
# 调节网络 (Adjust Net)
# 这是一个轻量级的卷积网络,用于从输入的条件图像 (如低剂量图) 中提取特征
# 这些特征将作为“偏移量” (gamma, beta) 注入到主 U-Net 中
class adjust_net(nn.Module):
def __init__(self, out_channels=64, middle_channels=32):
super(adjust_net, self).__init__()
# 简单的 4 层卷积网络,不断下采样并提取特征
self.model = nn.Sequential(
nn.Conv2d(2, middle_channels, 3, padding=1),
nn.ReLU(inplace=True),
nn.AvgPool2d(2),
# ... (中间层)
nn.Conv2d(middle_channels*4, out_channels*2, 1, padding=0)
)
def forward(self, x):
out = self.model(x)
# 全局平均池化:将特征图变为 1x1 的向量
out = F.adaptive_avg_pool2d(out, (1,1))
# 将输出拆分为两部分:gamma (缩放) 和 beta (平移)
# 这是一种类似 AdaIN (Adaptive Instance Normalization) 的机制
out1 = out[:, :out.shape[1]//2]
out2 = out[:, out.shape[1]//2:]
return out1, out2
# 自定义的 UNet 结构
# 论文中提到参考了 CBDNet,并加入了 Time Step Embedding
class UNet(nn.Module):
def __init__(self, in_channels=2, out_channels=1):
super(UNet, self).__init__()
# 时间步编码层 MLP
dim = 32
self.time_mlp = nn.Sequential(
SinusoidalPosEmb(dim),
nn.Linear(dim, dim * 4),
nn.GELU(),
nn.Linear(dim * 4, dim)
)
# ... (定义编码器 Encoder / 解码器 Decoder 的各层) ...
# 为每一层定义了 adjust_net,用于接收条件特征
self.adjust1 = adjust_net(128)
self.adjust2 = adjust_net(256)
self.adjust3 = adjust_net(256)
self.adjust4 = adjust_net(128)
# ...
def forward(self, x, t, x_adjust, adjust):
# 1. 基础特征提取
inx = self.inc(x)
# 2. 时间步编码
time_emb = self.time_mlp(t)
# --- 下采样块 1 ---
down1 = self.down1(inx)
condition1 = self.mlp1(time_emb) # 时间条件
b, c = condition1.shape
condition1 = rearrange(condition1, 'b c -> b c 1 1')
# --- 关键逻辑:条件注入 ---
if adjust:
# 如果开启调节 (Cold Diffusion 逻辑)
# 使用 adjust_net 从 x_adjust (低剂量图) 中计算 gamma 和 beta
gamma1, beta1 = self.adjust1(x_adjust)
# 将特征进行 仿射变换 (Affine Transformation):F = F + gamma * time + beta
down1 = down1 + gamma1 * condition1 + beta1
else:
# 标准扩散:仅注入时间条件
down1 = down1 + condition1
conv1 = self.conv1(down1)
# ... (后续层重复此逻辑) ...
out = self.outc(conv4)
return out
# 封装的主网络类
class Network(nn.Module):
def __init__(self, in_channels=3, out_channels=1, context=True):
super(Network, self).__init__()
# 这里直接实例化了 diffusers 的 UNet2DConditionModel
# 这意味着它可能在 pre-train 阶段用 UNet2DConditionModel,
# 而在 fine-tune 阶段或者某些特定配置下混合使用了上面定义的自定义 UNet 逻辑
self.unet = UNet2DConditionModel(
sample_size=256,
# ... (配置参数与预训练一致) ...
encoder_hid_dim=768,
)
# 加载预训练权重
model_path = "/path/to/pretrained/model/"
pretrained_w = safetensors.torch.load_file(model_path + "/diffusion_pytorch_model.safetensors")
self.unet.load_state_dict(pretrained_w, strict=False)
print(f"load from {model_path}")
# 修改输出层:适应特定的增强任务 (如输出单通道残差)
self.unet.conv_out = nn.Conv2d(64, 1, kernel_size=3, padding=1)
torch.nn.init.kaiming_normal_(self.unet.conv_out.weight)
self.context = context
def forward(self, x, t, y, x_end, adjust=True, prompt_emb=None):
# 如果需要上下文 (context),提取中间切片
if self.context:
x_middle = x[:, 1].unsqueeze(1)
else:
x_middle = x
# 拼接条件图像 y 和 x_end
x_adjust = torch.cat((y, x_end), dim=1)
# 前向传播:计算残差
# 注意:这里的输出 out 被加上了 x_middle (残差学习)
# 这意味着模型只需要学习“如何修改原图得到好图”,而不是从头生成一张图
out = self.unet(x, t, x_adjust, adjust=adjust, prompt_emb=prompt_emb)[0] + x_middle
return out
这里再补充说明一下,上面的注入包含两个步骤:提取(Extraction) 和 融合(Fusion),称为 基于特征的线性调制(Feature-wise Linear Modulation, 类似于 FiLM 或 AdaGN)。
第一步:提取“调节参数” (Extraction)。首先,模型需要从“条件图像”(例如低剂量的 CT 图,代码中的 x_adjust)中提炼出控制信号。这就是 adjust_net 的工作。两个向量 γ\gammaγ (gamma) 和 β\betaβ (beta)。这两个向量代表了这张图的全局风格或退化特征(例如“整体噪声水平很高”或“对比度很低”)。
class adjust_net(nn.Module):
# ...
def forward(self, x):
out = self.model(x) # 1. 卷积提取特征
out = F.adaptive_avg_pool2d(out, (1,1)) # 2. 压缩空间信息:变成 1x1 的点
# 假设 out 的通道数是 2C
out1 = out[:, :out.shape[1]//2] # 3. 前一半通道作为 gamma (缩放系数)
out2 = out[:, out.shape[1]//2:] # 4. 后一半通道作为 beta (平移/偏移系数)
return out1, out2
第二步:注入主网络 (Injection / Fusion)。接下来,这些提取出的 γ\gammaγ 和 β\betaβ 被送到主 U-Net 的每一层中,去“修改”中间的特征图。看 UNet 的 forward 函数中的这一行核心代码:
# down1: 主网络的特征图 (Feature Map)
# condition1: 当前的时间步编码 (Time Embedding),告诉模型现在去噪进行到哪一步了
if adjust:
gamma1, beta1 = self.adjust1(x_adjust) # 获取调节参数
# === 核心注入公式 ===
down1 = down1 + gamma1 * condition1 + beta1
可以将其想象为一个 “智能旋钮” 系统:
[ 低剂量 CT 图像 ]
|
v
[ Adjust Net (调节器) ]
|
+-----> 生成 gamma (旋钮:控制时间影响力)
|
+-----> 生成 beta (滑杆:直接修正特征基准值)
| 注入
v
[ 主 U-Net 特征层 ] <--- [ 时间步 Time Step ]
将这个公式拆解为三个部分:Znew=Zoriginal+(γ⋅Etime)+βZ_{new} = Z_{original} + (\gamma \cdot E_{time}) + \betaZnew=Zoriginal+(γ⋅Etime)+β,其中**ZoriginalZ_{original}Zoriginal (down1)是主网络当前层原本提取到的图像特征。β\betaβ (beta1) —— 直接偏移 (Bias/Shift)直接加在特征图上,这是一个“平移”操作。比如低剂量 CT 整体像素值偏低或有底噪,β\betaβ 可以直接给特征图加上一个数值,把整体特征分布“拉”回来。这就好比给图片整体调亮或调暗。γ⋅Etime\gamma \cdot E_{time}γ⋅Etime (gamma1 * condition1) —— 时间调制 (Time Modulation),这是一个“缩放”操作,但它缩放的是时间信息**。不同的图像质量(由 x_adjust 决定)需要不同的去噪强度:如果输入图像质量很差,模型可能生成一个很大的 γ\gammaγ,放大时间信号,告诉主网络:“现在不仅是第 50 步,而且因为图像太烂,你要按第 80 步的力度去处理!”,如果图像质量尚可,γ\gammaγ 可能很小,减少时间信息的干扰。γ\gammaγ 决定了模型多大程度上应该听取“时间步”的指令,β\betaβ 直接加在特征图上,用于修正底色或基础特征。
这里可能有人会问一个问题,为什么前一半通道作为 gamma (缩放系数),后一半通道作为 beta (平移/偏移系数)?这是一个非常经典且高效的深度学习设计模式,源于 特征线性调制(Feature-wise Linear Modulation, FiLM) 或 自适应实例归一化(AdaIN) 的思想。将通道一分为二并不是什么深奥的魔法,而是一种为了计算效率和参数解耦的工程实现惯例,简单解释一下。在图像增强或生成任务中,我们希望通过外部条件(如低剂量图像 x_adjust)来“调节”主网络的特征。最简单且强大的调节方式是线性变换:y=Scale×x+Shifty = \text{Scale} \times x + \text{Shift}y=Scale×x+Shift,在代码的上下文中,这个公式体现为:NewFeature=OldFeature+(γ×TimeEmb)+β\text{NewFeature} = \text{OldFeature} + (\gamma \times \text{TimeEmb}) + \betaNewFeature=OldFeature+(γ×TimeEmb)+β,为了完成这个操作,对于每一个特征通道,网络必须同时预测出两个完全独立的值:γ\gammaγ (Gamma):作为乘法因子(缩放系数)和**β\betaβ (Beta)**:作为加法因子(平移/偏置系数)。为了得到这两个参数,我们有两种设计选择:
方案 A(笨重):设计两个独立的网络,Net1 输出 γ\gammaγ,Net2 输出 β\betaβ。这样计算量翻倍,显存占用大,且两个网络无法共享底层的图像特征提取过程。
方案 B(高效 - LCTfound 采用的):设计一个网络,让它一次性输出所有需要的信息。请看 image_enhancement/patch_cold_diffusion.py 中 adjust_net 的定义:
# ... 最后一层卷积
# 注意这里的输出通道数是 out_channels * 2
nn.Conv2d(middle_channels*4, out_channels*2, 1, padding=0)
正是因为最后一层输出了双倍的通道(out_channels * 2),所以在 forward 函数中必须将其劈成两半,才能分别赋值给 gamma 和 beta。
这是深度学习中实现条件生成(Conditional Generation)的标准“黑话”。
3.下游任务 B:分割与特征探针 (Segmentation)
segmentation/pixel_classifier.py`, `segmentation/unet.py代码展示了如何利用基础模型进行 Few-shot(少样本)分割,如论文中的纵隔肿瘤分割。这个文件的核心思想非常巧妙:它不再重新训练整个庞大的 U-Net 来做分割,而是将 LCTfound 视为一个冻结的特征库。对于 CT 图像上的每一个像素点,LCTfound 都能提取出一个深层的特征向量(Feature Vector)。这个 pixel_classifier 就是一个简单的多层感知机,它的任务是:**只看这个特征向量,告诉我这个像素是“肿瘤”还是“背景”?**这种方法(通常称为 Linear Probing 或 Pixel Classification)大大降低了对标注数据的需求,非常适合医学图像中的少样本场景。
# 辅助函数:计算多分类准确率
def multi_acc(y_pred, y_test):
# 对预测结果取 Log Softmax,得到概率分布
y_pred_softmax = torch.log_softmax(y_pred, dim=1)
# 取概率最大的类别作为预测标签
_, y_pred_tags = torch.max(y_pred_softmax, dim=1)
# 统计预测正确的数量
correct_pred = (y_pred_tags == y_test).float()
acc = correct_pred.sum() / len(correct_pred)
# 返回百分比准确率
acc = acc * 100
return acc
# 核心类:像素分类器 (MLP)
# 参考了 datasetGAN 的实现,这是一个利用生成模型特征做分割的经典工作
class pixel_classifier(nn.Module):
def __init__(self, numpy_class, dim):
super(pixel_classifier, self).__init__()
# 隐藏层维度设定为 256
hidden_c = 256
# 策略分歧:如果类别数少于 30 (大多数医学分割任务)
if numpy_class < 30:
self.layers = nn.Sequential(
# 第一层:将输入特征维度 (dim) 映射到 256
# 注意:dim 是 LCTfound 提取出的特征向量长度 (例如拼接了多个层级的特征)
nn.Linear(dim, hidden_c),
# Dropout 防止过拟合,这在少样本训练中非常重要
nn.Dropout(0.25),
nn.ReLU(), # 激活函数
nn.BatchNorm1d(num_features=hidden_c), # 批归一化,加速收敛
# 第二层:256 -> 32
nn.Linear(hidden_c, 32),
nn.Dropout(0.25),
nn.ReLU(),
nn.BatchNorm1d(num_features=32),
# 输出层:32 -> 类别数 (例如 2: 背景/肿瘤)
nn.Linear(32, numpy_class)
)
else:
# 如果类别很多 (复杂分割),使用更深或更宽的网络 (这里逻辑似乎写反了或者仅是另一种配置)
# 这段代码实际上去掉了 Dropout,可能是为了应对大类别时需要更强的拟合能力
self.layers = nn.Sequential(
nn.Linear(dim, 256),
nn.ReLU(),
nn.BatchNorm1d(num_features=256),
nn.Linear(256, 128),
nn.ReLU(),
nn.BatchNorm1d(num_features=128),
nn.Linear(128, numpy_class)
)
# 权重初始化函数:支持多种初始化方式 (Normal, Xavier, Kaiming)
# 良好的初始化对于 MLP 的快速收敛至关重要
def init_weights(self, init_type='normal', gain=0.02):
'''
initialize network's weights
init_type: normal | xavier | kaiming | orthogonal
'''
def init_func(m):
classname = m.__class__.__name__
# 对卷积层和全连接层进行初始化
if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
if init_type == 'normal':
nn.init.normal_(m.weight.data, 0.0, gain)
elif init_type == 'xavier':
nn.init.xavier_normal_(m.weight.data, gain=gain)
elif init_type == 'kaiming':
nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
nn.init.orthogonal_(m.weight.data, gain=gain)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias.data, 0.0)
# 对 BatchNorm 层进行初始化
elif classname.find('BatchNorm2d') != -1:
nn.init.normal_(m.weight.data, 1.0, gain)
nn.init.constant_(m.bias.data, 0.0)
self.apply(init_func)
def forward(self, x):
# 前向传播:直接通过 MLP
return self.layers(x)
# 加载模型集成 (Ensemble) 的辅助函数
# 论文中提到为了稳定性,可能会训练多个小的 MLP 并取平均
def load_ensemble(args, device='cpu'):
models = []
# 遍历保存的模型文件 (model_0.pth, model_1.pth ...)
for i in range(args['model_num']):
model_path = os.path.join(args['exp_dir'], f'model_{i}.pth')
state_dict = torch.load(model_path)['model_state_dict']
# 实例化模型并使用 DataParallel (多卡支持)
model = nn.DataParallel(pixel_classifier(args["number_class"], args['dim'][-1]))
model.load_state_dict(state_dict)
model = model.module.to(device)
# 设置为评估模式
models.append(model.eval())
return models
4.下游任务 C:分类 (Classification)
classification/main.py
这一部分的代码展示了如何将一个生成式的基础模型(LCTfound)转化为一个判别式的分类器,用于诊断任务,与常见的“微调整个网络”不同,该代码采用了 “多时间步特征提取 + 轻量级分类头” 的策略。其原理是扩散模型在处理图像时,不同时间步(Timestep)关注的信息不同:
ttt 较小 (接近原图):模型关注高频细节(纹理、边缘)。
ttt 较大 (接近噪声):模型关注低频结构(形状、轮廓、全局语义)。
代码通过向图像添加不同程度的噪声(例如 t=1,20,50t=1, 20, 50t=1,20,50),然后让 LCTfound 去“看”这些加噪图,从而提取出多层次的特征用于分类。
系统输入一张 2D 肺部 CT 切片。系统生成 3 个版本的图像:xt=1x_{t=1}xt=1 (清晰), xt=20x_{t=20}xt=20 (微噪), xt=50x_{t=50}xt=50 (模糊)。LCTfound 的 Encoder 分别处理这 3 张图,提取出 3 组特征图,因为设置了 return_deep_fea=True,U-Net 只跑完下采样过程就返回,效率较高。3 组特征被拼接在一起,形成一个包含丰富语义(来自高噪图)和细节纹理(来自低噪图)的“超级特征”。CNN 层 + 全连接层根据这个“超级特征”判断疾病类别(如:肺炎 vs 正常)。
这种方法充分利用了预训练扩散模型对图像结构的深刻理解,通常比直接从头训练一个 ResNet 效果更好,尤其是在小样本医学数据上。
这部分代码由两个关键文件组成:
main.py:训练主脚本,负责数据加载、训练循环、指标计算(AUC/PAUC)和模型保存。UNet2D.py:定义了经过修改的 U-Net 结构以及分类适配器(Wrapper),实现了“多时间步特征提取”的核心逻辑。
先看主程序:classification/main.py
# 从 UNet2D 文件中导入分类模型封装类
# 注意:源码中 import 的是 CLSDDPM_2D,但对应的 UNet2D.py 定义的类名为 CLIPDDPM_2D,两者逻辑一致
from UNet2D import CLSDDPM_2D
from dataclasses import dataclass
from accelerate import Accelerator # HuggingFace 加速库,用于混合精度和分布式训练
cudnn.benchmark = True
import argparse
from monai.metrics.rocauc import compute_roc_auc # 使用 MONAI 库计算 AUC
import torch.multiprocessing
# 设置多进程共享策略,防止数据加载时显存溢出
torch.multiprocessing.set_sharing_strategy('file_system')
# --- 参数解析函数 ---
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--seed", type=int, default=1234567, help="随机种子")
parser.add_argument("--backbone", type=str, default="ddpm", help="骨干网络名称")
parser.add_argument("--experiment", type=str, default="some", help="实验名称,用于保存文件")
args = parser.parse_args()
return args
args = parse_args()
# --- 随机种子设置函数 (保证实验可复现) ---
def set_seed(args):
seed = args.seed
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# 确保卷积算法确定性
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(args)
# --- 训练配置类 ---
@dataclass
class TrainingConfig:
image_size = 256 # 输入图像分辨率
batch_size = 2 # 批次大小 (由于 3D CT 数据量大,通常设置较小)
num_epochs = 10 # 训练轮数
gradient_accumulation_steps = 1 # 梯度累积步数
learning_rate = 1e-3
mixed_precision = "fp16" # 混合精度设置 ('no' 或 'fp16')
output_dir = "save_dir" # 模型保存路径
overwrite_output_dir = True
seed = 0
num_workers = 4 # 数据加载线程数
config = TrainingConfig()
# --- 数据集加载部分 ---
batch_size = config.batch_size
image_size = config.image_size
# 实例化自定义数据集 (MDataset_2D 负责加载 CT 切片和临床信息)
tr_dataset = MDataset_2D(image_size, section='train')
val_dataset = MDataset_2D(image_size, section='val')
test_dataset = MDataset_2D(image_size, section='test')
image_datasets = {"train": tr_dataset, "val": val_dataset, "test": test_dataset}
# 构建 DataLoader
dataloaders = {x: torch.utils.data.DataLoader(
image_datasets[x],
batch_size=batch_size,
shuffle=x=="train", # 仅训练集打乱
num_workers=config.num_workers,
pin_memory=False
) for x in ['train', 'val', "test"]}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val', 'test']}
class_names = ["2", "greater than 2"] # 示例类别名
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
print(dataset_sizes)
# --- 核心训练循环函数 ---
def train_model(config, model, dataloaders, criterion, optimizer, scheduler, num_epochs=15, mode="Train"):
since = time.time()
phase_candidate = ['train', 'val'] # 默认包含训练和验证阶段
# 初始化 Accelerator,处理设备分配和混合精度
accelerator = Accelerator(
mixed_precision=config.mixed_precision,
gradient_accumulation_steps=config.gradient_accumulation_steps,
log_with="tensorboard",
project_dir=os.path.join(config.output_dir, "logs"),
)
# 准备对象
training_dataloader, val_dataloader, test_loader = dataloaders["train"], dataloaders["val"], dataloaders["test"]
model, optimizer, training_dataloader, val_dataloader, test_loader, scheduler = accelerator.prepare(
model, optimizer, training_dataloader, val_dataloader, test_loader, scheduler
)
# 如果是测试模式,加载已保存的权重
if mode == "Test":
saved = torch.load(f"checkpoints/saved.pkl")
# 去除 DDP 训练带来的 'module.' 前缀
saved = {k.replace("module.", ""):saved[k] for k in saved}
model.load_state_dict(saved)
num_epochs = 1
phase_candidate = ['val'] # 或者 'test'
dataloaders = {"train":training_dataloader, "val":val_dataloader, "test": test_loader}
best_auc = 0.0 # 记录最佳 AUC
for epoch in range(num_epochs):
set_seed(args) # 每个 epoch 重置种子,但在 DataLoader shuffle 开启时可能影响不大
if accelerator.is_main_process: print(f'Epoch {epoch}/{num_epochs - 1}')
if accelerator.is_main_process: print('-' * 10)
for phase in phase_candidate:
if phase == 'train':
model.train() # 训练模式
else:
model.eval() # 评估模式
running_loss = 0.0
running_corrects = 0
# 存储本轮预测结果,用于计算 AUC
epoch_p = {} # 预测概率 (Prediction)
epoch_t = {} # 真实标签 (Target)
iid = {} # 病人 ID
iifn = {} # 文件名
step = 1
c = 0 # 全局计数器
print(phase)
st = time.time()
# 遍历数据
# inputs: 图像, labels: 标签, id_list: 病人ID, fn_list: 文件名
for inputs, labels, id_list, fn_list, _ in dataloaders[phase]:
labels = labels.float()
optimizer.zero_grad()
# 前向传播
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs) # 调用分类模型
loss = criterion(outputs.flatten(), labels) # 计算 Loss
# 反向传播 (仅训练阶段)
if phase == 'train':
accelerator.backward(loss)
optimizer.step()
# 处理输出
logits = torch.sigmoid(outputs).detach().cpu() # 转换为概率
labels = (labels > 0.5).float() # 二值化标签
# 收集每个样本的预测结果
for i in range(inputs.shape[0]):
epoch_p[c] = logits[i][None]
epoch_t[c] = labels[i].detach().cpu()[None]
iid[c] = id_list[i]
iifn[c] = fn_list[i]
c += 1
# 打印中间日志
if step % 400 == 0 and accelerator.is_main_process:
print(f"Step {step} loss: {running_loss / (inputs.size(0) * step)}")
print(time.time() - st)
st = time.time()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum((logits.data > 0.5) == labels.detach().cpu().data)
step += 1
# --- 计算 Patient-level AUC (PAUC) ---
# 这是医学影像的关键步骤:将属于同一个病人的多张切片预测结果聚合
patient_p = {}
patient_t = {}
for i,k in enumerate(epoch_p):
if iid[k] not in patient_p:
patient_p[iid[k]] = []
patient_t[iid[k]] = []
patient_p[iid[k]].append(epoch_p[k]) # 收集该病人的所有预测概率
patient_t[iid[k]].append(epoch_t[k]) # 收集该病人的真实标签
# 聚合策略:取平均值 (Mean Aggregation)
# 即用所有切片的平均分代表该病人的最终得分
patient_p = [torch.mean(torch.cat(v)) for k,v in patient_p.items()]
patient_t = [torch.mean(torch.cat(v)) for k,v in patient_t.items()]
# 计算病人级别的 AUC
patient_auc = compute_roc_auc(torch.tensor(patient_p), torch.tensor(patient_t))
# 收集多卡数据 (如果是分布式训练)
epoch_p = accelerator.gather(torch.cat(list(epoch_p.values())))
epoch_t = accelerator.gather(torch.cat(list(epoch_t.values())))
if phase == 'train':
scheduler.step() # 更新学习率
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / (dataset_sizes[phase])
# 主进程打印本轮最终结果
if accelerator.is_main_process:
aucs = []
# 计算切片级别 (Slice-level) AUC
auc = compute_roc_auc(epoch_p, epoch_t)
aucs.append(auc)
auc = np.mean([i for i in aucs if i != 0])
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f} Auc: {auc:.4f} PAUC: {patient_auc:.4f}')
# 保存最佳模型 (基于切片 AUC)
if phase == 'val':
if auc > best_auc:
best_auc = auc
# 保存详细预测结果用于后续分析
with open(f"res/{args.backbone}_{args.experiment}_interval_best.pkl", "wb") as f:
pickle.dump({"pred": epoch_p, "gt": epoch_t, "id":iid, "fn":iifn},f)
if mode == "Train":
# 保存模型权重
torch.save(model.state_dict(), f"checkpoints/{args.backbone}_best_{args.experiment}_{np.round(auc,3)}.pkl")
if mode == "Train":
# 保存最新的检查点
torch.save(model.state_dict(), f"checkpoints/{args.backbone}_{args.experiment}_last.pkl")
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
return model
# --- 主执行逻辑 ---
backbone_name = args.backbone
mode = "Train"
num_cls = 1 # 二分类问题,输出一个概率值
# 初始化分类模型 (CLIPDDPM_2D / CLSDDPM_2D)
model_ft = CLSDDPM_2D(
"/path/to/pretrained/ddpm/model", # 预训练 LCTfound 模型路径
num_cls=num_cls,
seq_len=3, # 特征序列长度 (对应3个时间步)
steps=[1,20,50], # 关键参数:选择的时间步
# t=1: 接近原图,关注纹理细节
# t=20: 中等噪声
# t=50: 高噪声,关注轮廓结构
)
# 冻结部分参数或开启微调
# 这里设置为全部参数可训练 (Full Finetuning)
for paras in model_ft.model.parameters():
paras.requires_grad = True
# 定义损失函数:二分类交叉熵 (带 Logits 输入)
criterion = nn.BCEWithLogitsLoss()
# 定义优化器:AdamW
optimizer_ft = optim.AdamW(model_ft.parameters(), lr=0.001, weight_decay=1e-3)
# 学习率调度器:每 10 epoch 衰减为 0.1 倍
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.1)
# 开始训练
model_ft = train_model(config, model_ft, dataloaders, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=4, num_cls=num_cls, mode=mode)
模型定义文件:classification/UNet2D.py
这个文件很长,包含大量引用的 diffusers 代码。我只注释了两个关键部分:UNet2DConditionModel 中关于特征提取的修改。CLIPDDPM_2D 类(对应 main.py 中的分类器),这是将生成模型转为分类器的核心。
# ... (省略了 diffusers 库的 imports) ...
import torch
import torch.nn as nn
import safetensors
# ... (省略 helper classes) ...
class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
# ... (省略文档字符串) ...
@register_to_config
def __init__(
self,
# ... (常规 UNet 参数)
# --- 关键自定义参数 ---
return_deep_fea=False, # 新增参数:控制是否仅返回深层特征
):
super().__init__()
self.return_deep_fea = return_deep_fea # 保存标志位
# ... (常规初始化代码,定义 down_blocks, mid_block, up_blocks) ...
def forward(
self,
sample: torch.FloatTensor,
timestep: Union[torch.Tensor, float, int],
encoder_hidden_states: torch.Tensor,
# ... (其他参数)
) -> Union[UNet2DConditionOutput, Tuple]:
# ... (常规的前处理:时间嵌入、文本条件嵌入、初始卷积) ...
# --- Down 阶段 (编码器) ---
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
# ... (执行下采样块计算) ...
down_block_res_samples += res_samples
# --- 关键修改:特征提取截断 ---
# 如果开启 return_deep_fea,则在此处停止!
# 不再执行 Mid Block 和 Up Blocks (解码器)
# 这对于分类任务极大提高了效率,因为我们只需要编码器的压缩语义特征
if self.return_deep_fea:
return sample
# ... (后续的 Mid Block 和 Up Blocks 代码,仅在生成模式下执行) ...
# =========================================================================
# 分类适配器核心类 (对应 main.py 中的 CLSDDPM_2D)
# =========================================================================
class CLIPDDPM_2D(nn.Module):
'''
Wrapper to extract features from pretrained DDPMs.
(预训练 DDPM 特征提取封装器)
:param steps: list of diffusion steps t. (要采样的时间步列表,如 [1, 20, 50])
:param blocks: list of the UNet decoder blocks.
'''
def __init__(self, model_path, num_cls=2, steps=[0], seq_len=1, clip_train=True):
super().__init__()
self.steps = steps # 保存时间步配置
# 加载预训练的 LCTfound U-Net
self._load_pretrained_model(model_path)
self.clip_train = clip_train # 标记是否用于 CLIP 风格训练或普通分类
# --- 定义分类头 ---
if not self.clip_train:
# 如果是普通分类,定义最终的全连接层
self.fc = nn.Linear(768, num_cls)
torch.nn.init.xavier_uniform_(self.fc.weight)
# 特征压缩层:
# 输入维度: 512 * seq_len (因为 U-Net 深层特征通常是 512 或 1024 通道,且拼接了 seq_len 次)
# 输出维度: 768 (映射到标准的 Embedding 维度)
self.conv = nn.Conv2d(512*seq_len, 768, 3)
torch.nn.init.xavier_uniform_(self.conv.weight)
self.act = nn.ReLU() # 激活函数
# 全局平均池化:将 (Batch, 768, H, W) -> (Batch, 768, 1, 1)
self.avg = nn.AdaptiveAvgPool2d((1,1))
self.seq_len = seq_len # 序列长度 (例如 3)
def _load_pretrained_model(self, model_path):
from diffusers import DDPMScheduler
# 初始化噪声调度器
self.noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
# 初始化 U-Net (注意这里 return_deep_fea 默认为 False,但在 forward 中可能未直接使用该标志,
# 而是依赖 CLIPDDPM_2D 自身的逻辑截取输出,或者源码中其实有配套修改)
# 实际上在 main.py 的逻辑里,这个 U-Net 充当特征提取器
self.model = UNet2DConditionModel(
sample_size=256,
# ... (U-Net 配置参数,必须与预训练时一致) ...
down_block_types=(
"DownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D"
),
# ...
encoder_hid_dim=768,
)
# 加载 safetensors 权重
pretrained_w = safetensors.torch.load_file(model_path + "/diffusion_pytorch_model.safetensors")
self.model.load_state_dict(pretrained_w)
print(f"\033[91mPretrained model is successfully loaded from {model_path}\033[0m")
self.model.eval() # 默认设为评估模式
# 前向传播
# x: 输入图像 (Clean Image)
# encoder_hidden_states: 文本/条件 Embedding
def forward(self, x, encoder_hidden_states):
noise = torch.randn(x.shape).to(x.device) # 生成随机噪声
activations = []
input_with_noise = []
t = self.steps[0] # 取出初始时间步 (虽然后面循环里覆盖了 t)
# --- 核心循环:多时间步特征提取 ---
for i in range(self.seq_len):
# 获取当前循环对应的时间步 (这里代码逻辑似乎只用了 steps[0],可能需要根据 i 来索引 self.steps[i])
# 正常逻辑应该是: t_step = self.steps[i]
t = torch.tensor([t]).to(x.device).long()
# 1. 加噪 (Forward Diffusion)
# 将干净图像 x 加噪到 t 时刻 -> noisy_x
noisy_x = self.noise_scheduler.add_noise(x, noise, t)
# 2. 特征提取
# 将加噪图送入 U-Net,提取特征
# 注意:这里的 self.model 调用依赖于 return_deep_fea=True 的行为 (如果配置了)
# 或者该版本的 forward 会返回所有中间层
direct_out = self.model(noisy_x, t, encoder_hidden_states=encoder_hidden_states)
# 收集特征
activations.append(direct_out)
del(noise)
del(noisy_x)
# --- 特征融合 ---
# 将不同时间步提取的特征在通道维度 (dim=1) 拼接
# Shape: (Batch, 512*seq_len, H', W')
first = torch.cat(activations, dim=1)
# --- 分类头计算 ---
first = self.conv(first) # 卷积压缩 -> (Batch, 768, H', W')
first = self.act(first) # ReLU
outputs = self.avg(first.contiguous()) # 池化 -> (Batch, 768, 1, 1)
outputs = torch.flatten(outputs, 1) # 展平 -> (Batch, 768)
if self.clip_train:
return outputs # 如果是 CLIP 预训练,返回特征向量
# Dropout 防止过拟合
outputs = torch.nn.functional.dropout(outputs, p=0.5)
# 最终全连接层 -> (Batch, num_cls)
outputs = self.fc(outputs.contiguous())
return outputs
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)