
GPU算力租用之镜像选择攻略
点开我的实例➡更多➡创建自定义镜像创建镜像需要填充镜像名称、镜像描述、镜像时长然后创建(镜像创建时间约为3min左右)镜像时长默认1天,可手动调整2、镜像共享操作步骤。
在深度学习和高性能计算领域,GPU算力平台已经成了模型训练、大规模数据处理的核心工具,它的性能和可靠性好不好,直接影响着研发效率和成果落地。其实镜像功能并不是GPU平台的“附加福利”,而是判断这个平台够不够成熟、够不够好用的关键标准。说简单点,镜像功能就像给深度学习环境搭了个“稳定支架”,能实现环境标准化、可重复使用、跨设备稳定运行,还能追溯训练过程,这些都是GPU平台能发挥作用的基础。
使用问题及解决方案:
Q1:深度学习环境配置繁琐,版本不兼容问题频发,如何破解?
核心痛点:深度学习训练需精准匹配CUDA、cuDNN、深度学习框架及各类依赖库,版本错位易导致训练失败,重复配置环境耗时耗力,严重占用研发资源。
解决方案:借助镜像功能,对已调试完毕、可稳定运行的深度学习环境进行全量打包存储,后续使用时无需重复配置,可直接一键调用,从根源上解决环境配置繁琐问题,大幅降低版本不兼容风险,节省研发时间成本。
Q2:换机器、换显卡等设备切换场景下,原有环境易崩溃无法运行,如何保障环境稳定性?
核心痛点:设备更换、显卡迭代时,传统运行环境因硬件适配性不足,易出现崩溃、报错等问题,中断研发流程,影响推进效率。
解决方案:利用镜像功能的跨节点、跨显卡复用特性,实现环境标准化适配,无需二次调试即可快速适配新硬件,确保环境在设备切换过程中稳定运行,有效解决硬件变更带来的适配难题,提升设备切换效率。
Q3:团队协作中存在环境差异,易出现“本地能跑、平台报错”问题,如何实现协作一致性?
核心痛点:团队成员的环境配置标准不统一,导致代码在本地运行正常、在平台运行异常,引发协作阻碍,拖慢任务推进进度。
解决方案:通过镜像功能实现运行环境全维度标准化,确保所有团队成员、所有运行设备采用完全一致的环境配置,从根本上规避环境差异引发的兼容性问题,保障团队协作高效协同。
Q4:训练过程中遇服务器重启、误删文件等意外,易导致训练成果丢失,如何避免资源浪费?
核心痛点:服务器故障、操作失误等突发情况,易造成代码、数据集、模型权重等训练成果丢失,导致前期投入的研发资源无效损耗,中断训练流程。
解决方案:依托镜像功能完整留存训练全流程状态,涵盖代码文件、数据集、模型权重及各类参数配置,即便遭遇意外,也可从断点处快速恢复训练,保障研发过程的连续性,避免训练成果浪费。
实测了智星云镜像共享功能,告别环境内耗,效率直接翻倍。今天就从实操角度,给大家拆解这个能让科研/研发效率翻倍的工具,新手也能直接抄作业。
镜像实测核心操作:3分钟上手,全程无代码
1、创建自定义镜像:实例的镜像部署完成后,则可创建自定义镜像。
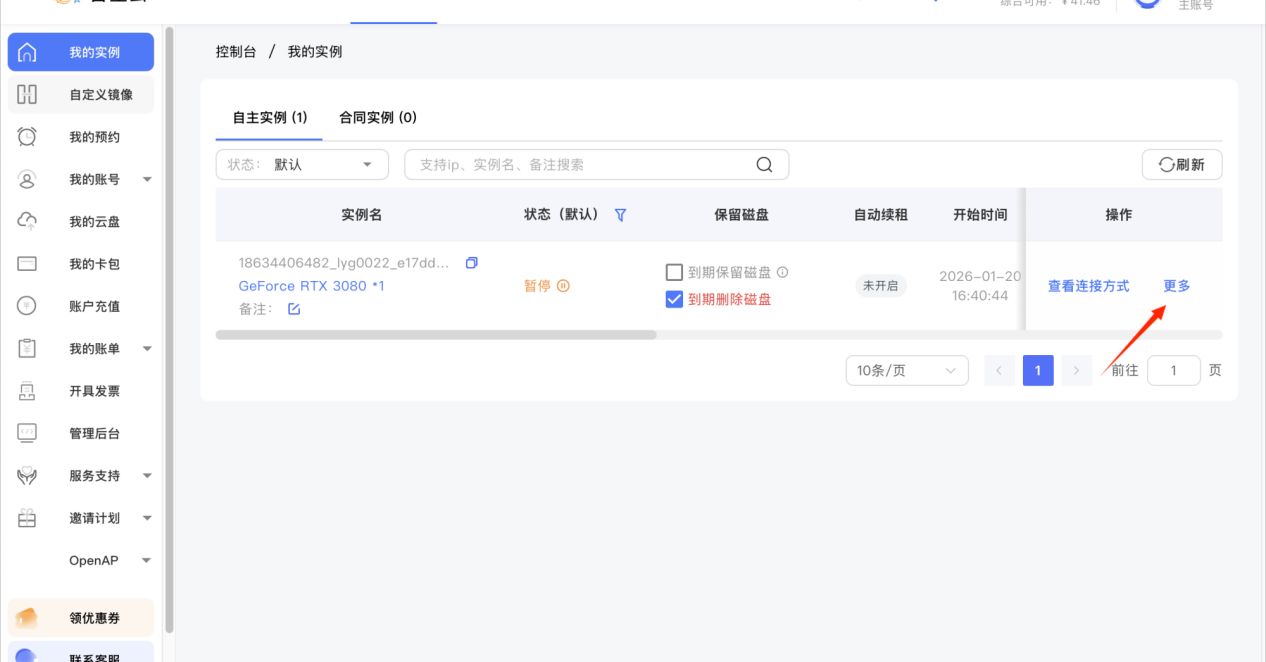
点开我的实例➡更多
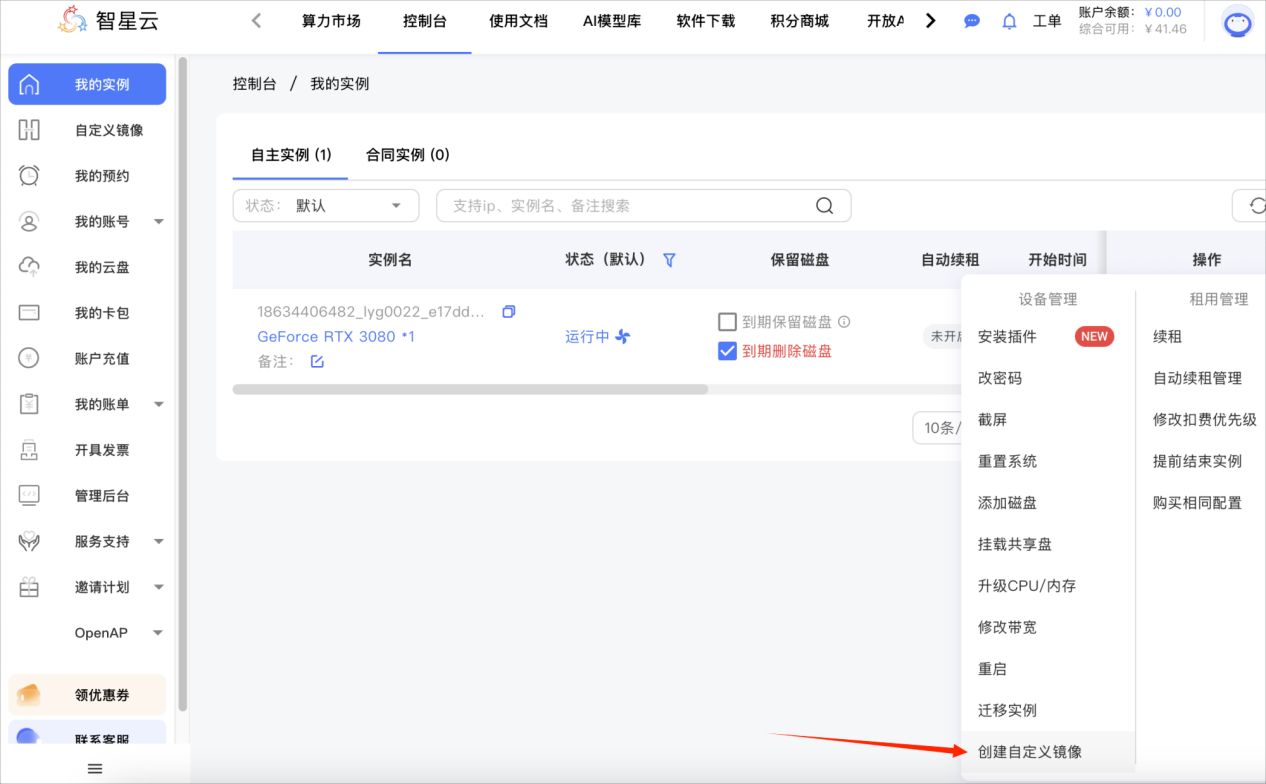
➡创建自定义镜像
创建镜像需要填充镜像名称、镜像描述、镜像时长然后创建(镜像创建时间约为3min左右)
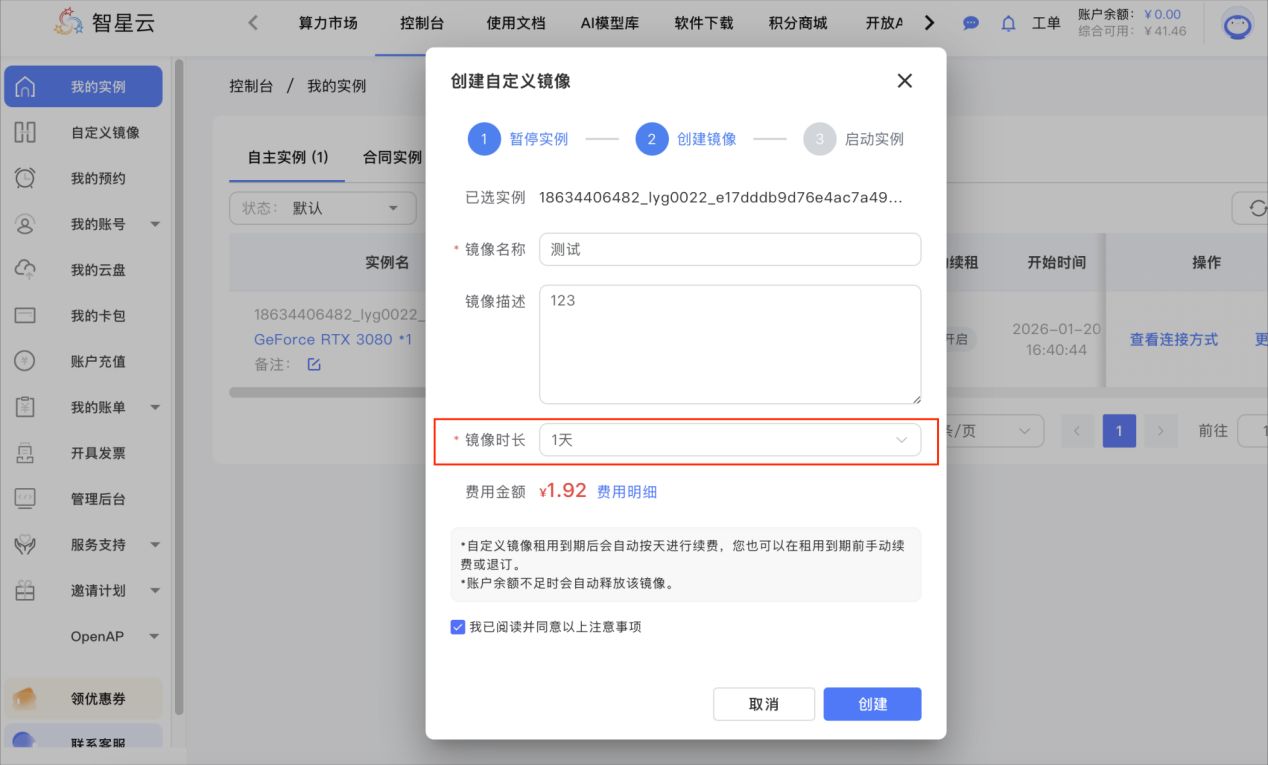
镜像时长默认1天,可手动调整
2、镜像共享操作步骤 在操作模块点击共享(仅制作成功的镜像支持共享,未完成或失败镜像无法发起共享)
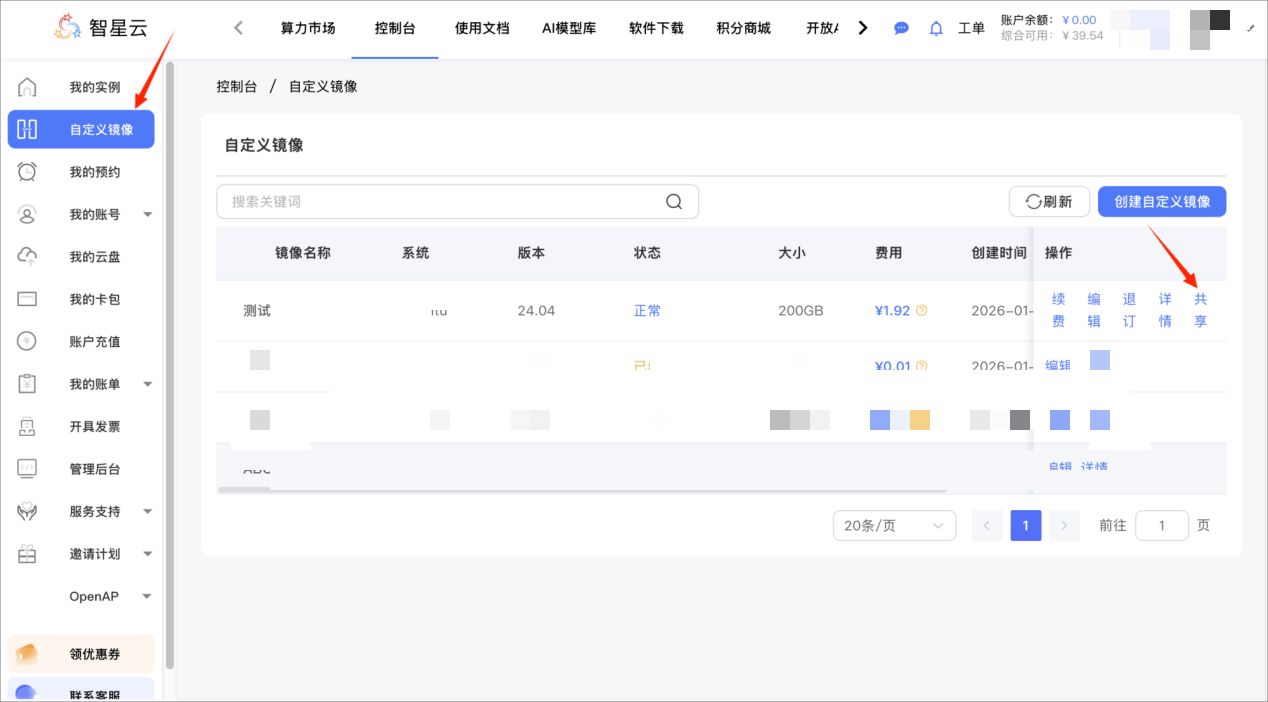
自定义镜像模块查找做好的镜像
填写被邀请人的手机号进行共享
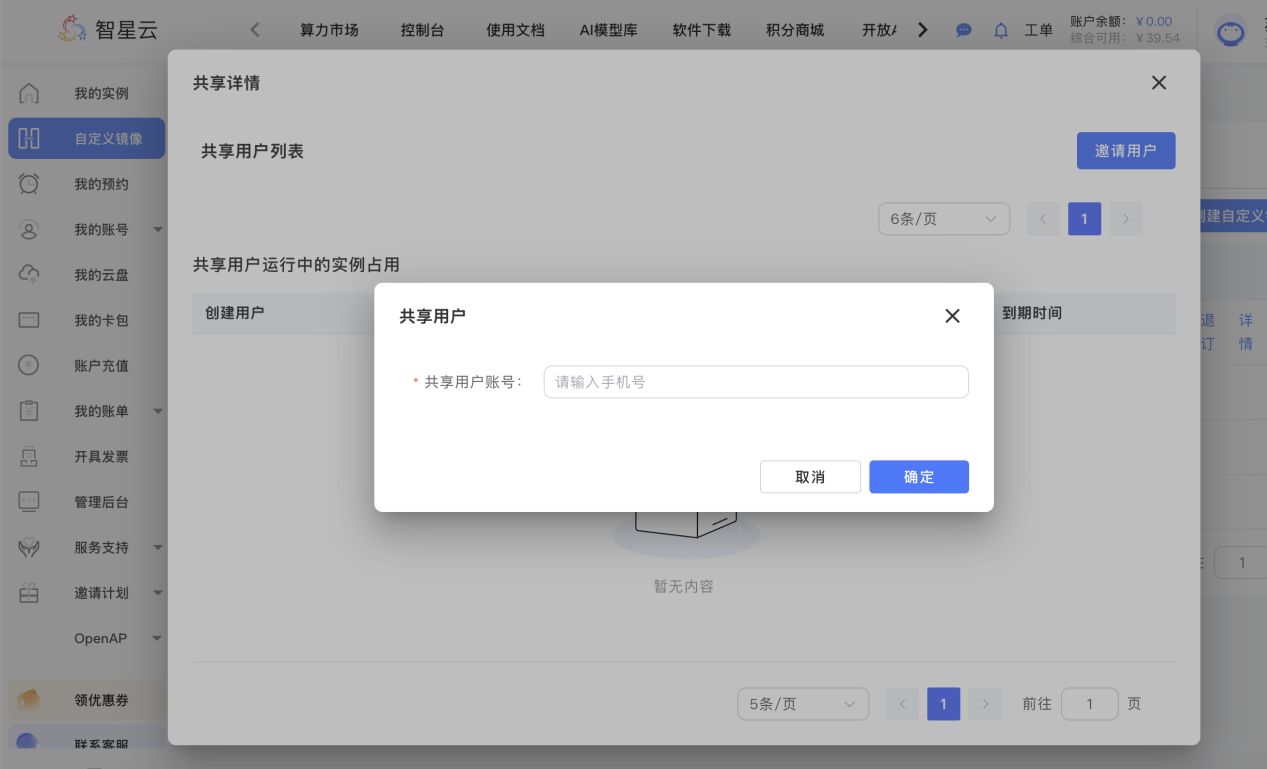
邀请用户
邀请后在共享详情处会出现分享的记录,可随时关闭共享
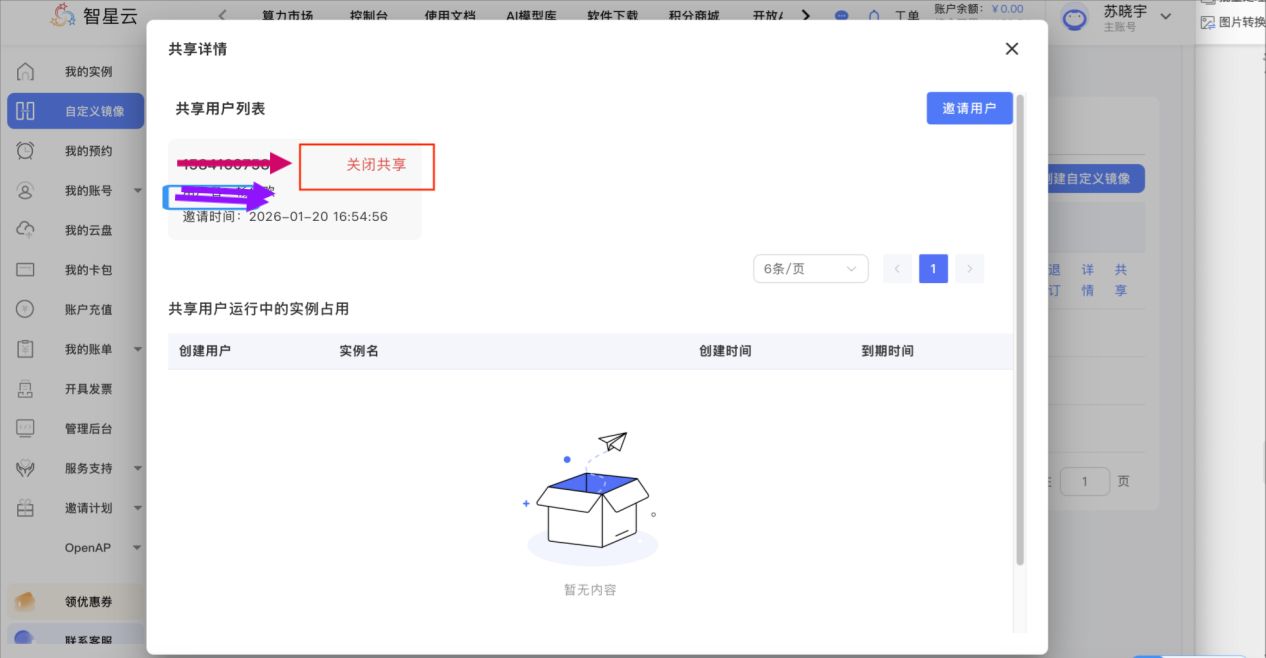
关闭共享后被共享人无法直接使用该镜像,可重新制作自定义镜像使用
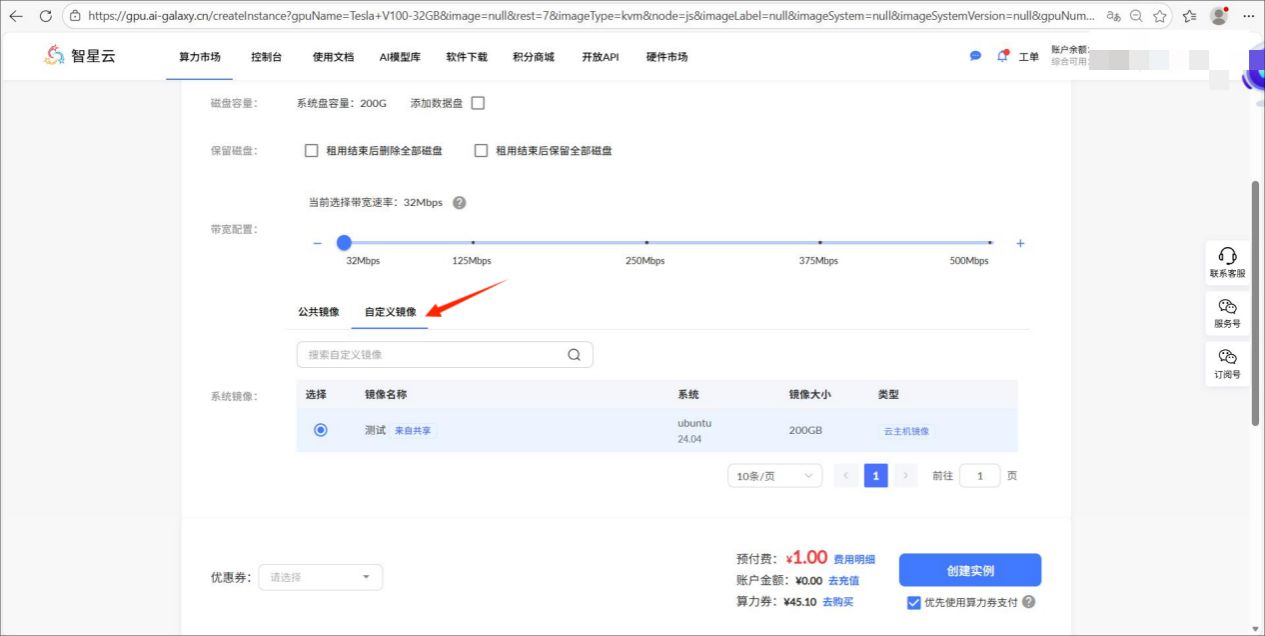
3、被共享人一键使用:创建实例的界面处选择自定义镜像则可看到分享成功的镜像,点击使用即可。
镜像体验小tips:
-
接收方看不到镜像:大概率是手机号输错了,或者分享方的镜像还没制作完成/已过期,核对一下手机号和镜像状态,刷新页面或重新登录就行;
-
启动实例失败:记得优先选分享方制作镜像时的显卡型号,不然可能硬件不兼容,另外清理下账号里的无用镜像和过期实例,释放存储空间就好;
-
镜像制作慢:正常情况3分钟左右就能好,制作期间别操作实例,耐心等一等就OK,记得提前充值,避免余额不足导致镜像被释放。
总的来说,镜像功能完善不完善,直接影响着GPU平台的环境标准化、资源复用效率、跨设备稳定性,还有训练过程的可追溯性,这些都是判断平台好不好用的核心要点。所以说,镜像功能自然就成了检测GPU算力平台成熟度、规范性和实用性的核心标准,看它的表现,就能知道这个平台能不能满足深度学习研发和高性能计算的需求。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)