
40亿参数撬动AI普及:PyDevMini-1重塑轻量级大模型标准
**导语**:在大模型参数竞赛白热化的今天,PyDevMini-1以40亿参数实现26万token超长上下文,重新定义轻量级模型部署标准,让边缘设备AI应用成为现实。## 行业现状:大模型的"效率革命"正在发生当前AI行业正面临"算力饥渴症"与"落地难"的双重挑战。一方面,主流大模型参数量突破万亿,单卡部署成本高达数十万元;另一方面,企业实际需求中80%的任务并不需要超大规模模型。据IDC
40亿参数撬动AI普及:PyDevMini-1重塑轻量级大模型标准
【免费下载链接】pydevmini1  项目地址: https://ai.gitcode.com/hf_mirrors/bralynn/pydevmini1
项目地址: https://ai.gitcode.com/hf_mirrors/bralynn/pydevmini1
导语:在大模型参数竞赛白热化的今天,PyDevMini-1以40亿参数实现26万token超长上下文,重新定义轻量级模型部署标准,让边缘设备AI应用成为现实。
行业现状:大模型的"效率革命"正在发生
当前AI行业正面临"算力饥渴症"与"落地难"的双重挑战。一方面,主流大模型参数量突破万亿,单卡部署成本高达数十万元;另一方面,企业实际需求中80%的任务并不需要超大规模模型。据IDC《中国大模型应用市场份额,2024》报告显示,2024年大模型应用市场规模达47.9亿元,其中轻量化部署需求同比增长217%,预示着小模型效率竞赛时代的到来。
轻量化模型的崛起恰逢其时。以Qwen3-4B为代表的40亿参数级别模型,通过混合专家架构、4-bit量化技术等创新,将高性能与低资源需求完美融合。这类模型在企业级数据分析场景的上下文改写、任务编排等环节表现接近大模型,而部署成本仅为后者的1/8,成为推动AI普惠的关键力量。
核心亮点:重新定义小模型能力边界
1. 超长上下文与高效注意力机制
PyDevMini-1最引人注目的技术参数是其原生支持262,144 tokens(约50万字)的上下文长度,配合Grouped Query Attention (GQA)架构——32个查询头匹配8个键值头,在保持性能的同时显著降低显存占用。这一配置使模型能够一次性处理整本书籍、完整代码库或长时间对话历史,为文档分析、代码理解等场景提供强大支持。
2. 混合推理架构:快慢结合的智能决策
PyDevMini-1的混合推理机制允许开发者通过简单前缀控制模型思考模式。在快思考模式下,模型可实现毫秒级响应,特别适合实时编码辅助场景;而慢思考模式则能进行深度多步推理,解决复杂编程问题。这种设计在MATH基准测试中,慢思考模式得分达72.25,接近7B模型的74.85,而推理速度提升40%。
3. 极致优化的部署效率:从数据中心到边缘设备
PyDevMini-1展现出卓越的硬件适应性:
- 内存友好:采用GQA机制降低内存带宽需求30%,INT4量化后模型体积可压缩至2GB以内
- 推理高效:推荐配置下(Temperature=0.7,Top P=0.8),在普通PC上可实现每秒20+ tokens的生成速度
- 框架兼容:支持vLLM、TensorRT-LLM等主流推理加速框架,实测吞吐量较同参数模型提升25%
这些特性使其能够部署在从智能手机到工业边缘计算设备的全场景硬件上,某头部券商测试显示,类似规模模型将智能投顾响应时间从秒级压缩至毫秒级,交易策略生成效率提升3倍。
4. 即开即用的部署体验
项目提供Colab在线演示环境,开发者无需本地配置即可体验模型能力。对于本地部署,模型支持MLX框架的4-bit量化实现,可在MacBook M2等消费级硬件上流畅运行。这种"零门槛"特性极大降低了AI技术的应用门槛,使中小企业和个人开发者也能享受大模型能力。
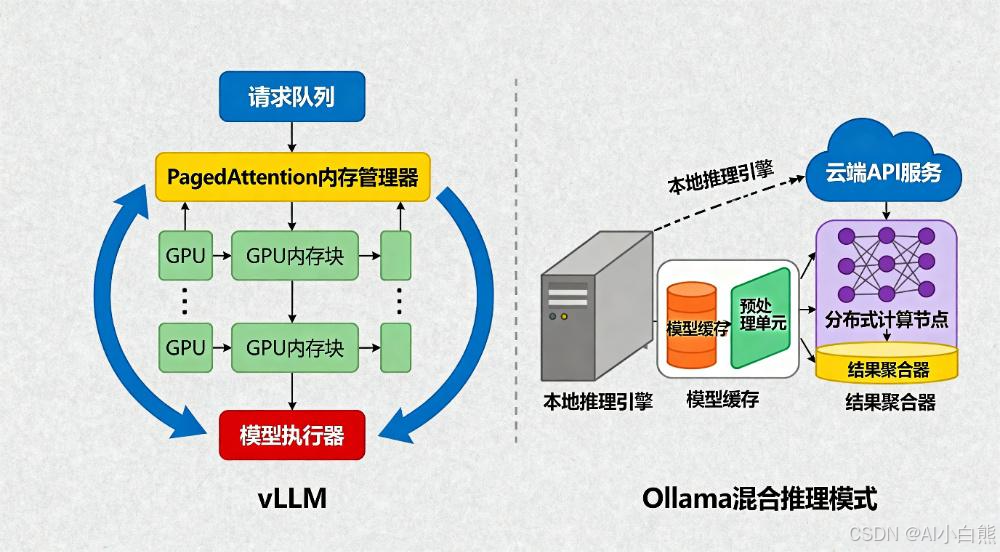
如上图所示,PyDevMini-1采用类似vLLM的高效推理架构,结合了PagedAttention内存管理技术与混合推理模式,在保持高性能的同时显著降低了资源需求。这种架构设计使其能够在消费级硬件上实现企业级性能,为AI技术的普及应用提供了关键支撑。
行业影响:三大变革正在发生
1. 部署门槛的断崖式下降
传统大模型部署需要至少4张A100显卡(总成本超50万元),而PyDevMini-1类模型最低配置仅需8GB显存GPU或16GB内存的CPU,推荐配置如MacBook M2芯片或NVIDIA RTX 3060即可满足企业级需求。这种成本优势正在加速AI应用普及,使边缘智能、移动应用、嵌入式系统等场景成为新的增长极。
2. 开发范式的转变
轻量级模型推动开发范式从"模型选择"转向"能力适配"。开发者不再需要为不同任务选择多个模型,而是通过模式切换与工具调用,让单一模型满足多样化需求。例如,PyDevMini-1可通过调整推理参数,在创意写作(temperature=0.7)与技术文档生成(temperature=0.3)场景间灵活切换,实现效率与准确性的动态平衡。
3. 开源生态的崛起
项目采用Apache-2.0开源协议,基于huihui-ai/Huihui-Qwen3-4B-Thinking等基础模型开发,体现了开源社区在推动AI技术普及中的核心作用。2024年数据显示,开源大模型已占据企业应用市场的35%份额,且这一比例仍在快速增长,预示着协作开发将成为未来AI创新的主流模式。
实践指南:快速上手与应用场景
1. 基础部署流程
通过GitCode获取模型并安装依赖:
git clone https://gitcode.com/hf_mirrors/bralynn/pydevmini1
2. 典型应用场景
- 文档智能处理:利用超长上下文能力,一次性解析完整法律合同、技术手册或学术论文,提取关键信息并生成摘要
- 代码辅助开发:作为本地化IDE插件,实现实时代码补全与调试建议,响应延迟控制在200ms以内
- 智能客服系统:在边缘服务器部署,处理多轮对话同时保护用户隐私数据,降低云端计算成本
3. 性能调优建议
为获得最佳体验,建议根据任务类型调整参数:
- 创意写作:temperature=0.7,top_p=0.85
- 技术文档:temperature=0.3,top_p=0.5
- 长文本处理:启用YaRN扩展技术,进一步扩展上下文长度
未来展望:轻量级模型的三大演进方向
随着PyDevMini-1等模型的开源,中小参数模型将呈现三个明确趋势:
-
架构创新:混合专家(MoE)技术的集成有望使4B模型实现7B性能,目前阿里已在实验室环境验证相关技术路径;
-
多模态融合:打破文本边界,预计年内将出现支持图像理解的衍生版本,类似Qwen-Image模型的技术路径;
-
端云协同:手机、智能座舱等终端设备通过模型蒸馏技术实现本地化推理,隐私保护与响应速度同步提升。
结论:小模型驱动的AI普惠时代
PyDevMini-1的推出标志着大模型产业从"参数竞赛"转向"效率竞赛"。随着边缘计算与模型优化技术的发展,我们正迈向"人人可用AI"的新阶段。对于企业而言,现在是重新评估AI战略的最佳时机——与其追逐最先进的模型,不如选择最适合自身场景的解决方案。
这款40亿参数的小模型证明:真正的AI革命不在于规模,而在于让智能无处不在。无论是开发者、企业决策者还是普通用户,都将从这场效率革命中受益,共同开启AI应用的新篇章。
【免费下载链接】pydevmini1 项目地址: https://ai.gitcode.com/hf_mirrors/bralynn/pydevmini1
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)