
手把手教你玩转 LoRA 微调:从原理到实战,一站式通关教程
本次教程选用阿里云通义千问的 Qwen2.5-3B-Instruct,这是目前3B 量级表现最优异的开源指令微调模型量级适中:30 亿参数量,兼顾「能力」和「轻量化」,低配显卡 / 免费算力均可轻松训练推理;中文友好:原生针对中文优化,中文理解、生成、指令遵循能力远超同量级 LLaMA2、Phi 等模型;指令对齐优秀:Instruct 版本是官方已做过基础 SFT 的版本,我们在此基础上做 LoR
前言
大模型微调是落地大模型能力的核心环节,而LoRA (Low-Rank Adaptation) 凭借「极低显存占用、极快训练速度、微调效果优异、训练成本极低」的核心优势,成为当下大模型轻量化微调的绝对主流方案。本文将以 Pretrain+SFT(预训练 + 监督微调) 为核心微调范式,全程基于 Qwen2.5-3B-Instruct 模型手把手落地完整 LoRA 微调流程,从核心原理、模型选型、代码实现、免费算力训练到推理部署,所有内容简洁易懂、步骤清晰,复制即用,零基础也能轻松上手。
✅ 第一章:LoRA 核心思想 + 主流微调方法对比(Pretrain+SFT 范式)
1.1 LoRA 的核心思想(轻量化微调的精髓)
LoRA 直译是低秩适配,是由微软团队提出的大模型参数高效微调(PEFT)核心算法,解决的核心痛点:全量微调大模型的显存炸裂、训练缓慢、成本过高问题。
核心原理拆解
我们都知道,大模型的核心能力来自于 Transformer 结构中的 注意力层(Attention),而注意力层的 query/key/value 矩阵(下称 QKV 矩阵)是模型学习语义关联、特征映射的核心,也是大模型参数量的核心载体。
- 全量微调:更新模型所有参数,动辄几十亿 / 上百亿参数,需要几十 GB 显存,普通显卡根本跑不动;
- LoRA 微调:冻结大模型的所有主干参数,只在 Transformer 的注意力层的 QKV 矩阵旁,新增两个极小的低秩矩阵(A 矩阵 + B 矩阵)
新增的低秩矩阵特点:
- 矩阵维度极小:比如原矩阵是
4096×4096,LoRA 矩阵可以是4096×8+8×4096,参数量只有原矩阵的 1/512; - 训练时仅更新这两个小矩阵的参数,主干模型参数完全不动;
- 前向推理时,将低秩矩阵的输出与原 QKV 矩阵的输出相加融合,不改变模型推理结构,不增加推理耗时。
✨ 核心总结:LoRA 用「极小的参数量」撬动「大模型的定向能力微调」,训练时显存占用骤降、速度翻倍,效果媲美全量微调,这也是它能成为工业界主流的核心原因。
1.2 主流大模型微调方法横向对比(必看!选型依据)
本次教程全程基于 Pretrain (预训练)+SFT (Supervised Fine-tuning,监督微调) 标准微调范式,这也是目前 LLM 微调的事实工业标准,所有方法对比均基于该范式,优劣一目了然:
| 微调方法 | 核心特点 | 显存占用 | 训练速度 | 微调效果 | 适用场景 | 缺点 |
|---|---|---|---|---|---|---|
| 全量微调 (Full Fine-tuning) | 更新模型所有参数 | ❌ 极高 (3B 模型≥24G 显存) | ❌ 极慢 | ✅ 最优 | 有充足算力 + 海量数据 | 成本高、易过拟合、显存门槛高,个人玩家劝退 |
| 冻结微调 (Freeze) | 冻结主干,仅训输出层 | ✅ 较低 | ✅ 较快 | ❌ 最差 | 简单任务 / 分类任务 | 仅适配简单场景,无法学到大模型深层特征 |
| LoRA 微调 (主流) | 冻结主干,训低秩矩阵 | ✅ 极低 (3B 模型仅需 8G 显存) | ✅ 极快 | ⭐ 接近全量微调 | 通用对话 / 指令微调 / 垂直领域适配 | 几乎无缺点,唯一:极特殊场景效果略逊全量 |
| QLoRA 微调 (进阶 LoRA) | LoRA 基础上做 4bit 量化 | ✅ 极致低 (3B 模型仅需 4G 显存) | ✅ 比 LoRA 更快 | ⭐ 略逊原生 LoRA | 显存不足的低配显卡 / Colab 免费算力 | 量化存在极小精度损失,可忽略不计 |
| Adapter 微调 | 插入小适配器模块 | ✅ 较低 | ✅ 较快 | ⭐ 中等 | 多任务切换场景 | 推理时需加载适配器,略增加耗时 |
✅ 选型结论:个人玩家 / 中小企业首选 LoRA,兼顾效果、速度、成本,性价比拉满,也是本文的核心教学方案。
✅ 第二章:微调模型选型 + Qwen2.5-3B-Instruct 模型详解 + 核心微调层说明
2.1 模型选型:为什么是 Qwen2.5-3B-Instruct ✨
本次教程选用阿里云通义千问的 Qwen2.5-3B-Instruct,这是目前3B 量级表现最优异的开源指令微调模型,没有之一,选型理由如下:
- 量级适中:30 亿参数量,兼顾「能力」和「轻量化」,低配显卡 / 免费算力均可轻松训练推理;
- 中文友好:原生针对中文优化,中文理解、生成、指令遵循能力远超同量级 LLaMA2、Phi 等模型;
- 指令对齐优秀:Instruct 版本是官方已做过基础 SFT 的版本,我们在此基础上做 LoRA 微调,效果事半功倍;
- 开源免费:商用友好,无版权限制,个人 / 企业均可免费使用;
补充:3B 模型是「入门微调最佳选择」,训练快、推理快,学会 3B 的 LoRA 微调,无缝迁移到 7B/14B/72B 模型,方法完全一致!
2.2 查看 Qwen2.5-3B-Instruct 完整模型层数 + 明确「我们微调的是哪几层」
2.2.1 核心前置知识
Qwen2.5-3B-Instruct 是标准的 Decoder-only 的 Transformer 架构,所有大语言模型(LLaMA/Qwen/GLM)均为此结构,核心层级组成:
Embedding层:词嵌入层,将文字转为向量,训练时冻结Transformer Block × N:模型核心堆叠层,也是能力的核心,LoRA 微调的核心区域LM Head层:输出层,将向量转回文字,训练时冻结
2.2.2 代码:打印模型部分结构
import torch
from modelscope import AutoModelForCausalLM, AutoTokenizer
# ===================== 1. 模型路径 =====================
model_name = "qwen/Qwen2.5-3B-Instruct"
# ===================== 2. 加载分词器 =====================
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True,
padding_side="right",
use_fast=False
)
tokenizer.pad_token = tokenizer.eos_token
# ===================== 3. 加载模型 =====================
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
low_cpu_mem_usage=True,
use_cache=False
)
# ===================== 4. 打印模型核心信息 =====================
print("="*50)
print("✅ Qwen2.5-3B-Instruct 模型加载成功!")
print("="*50)
print("=== Qwen2.5-3B-Instruct 完整模型核心结构 ===")
print(model)2.2.3 运行结果 + 关键结论(重点!必看)
运行上述代码后,你会得到核心输出:
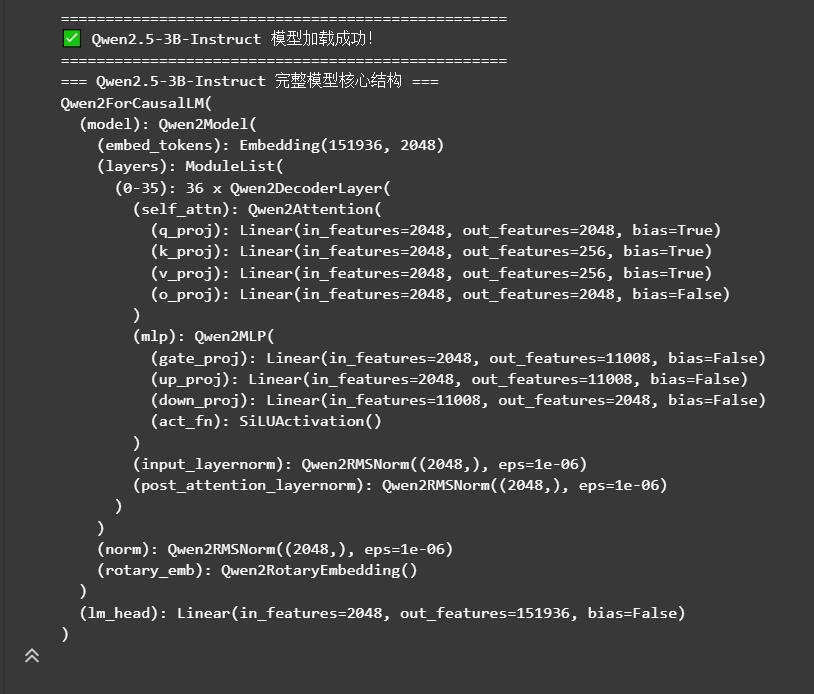
2.2.4 LoRA 到底微调「哪几层」?(核心知识点)
我们的 LoRA 矩阵,只注入到 Self-Attention 层的 Q、K 矩阵上(行业通用最优方案),原因如下:
- 注意力层是大模型「理解语义、建立上下文关联」的核心,微调这里性价比最高;
- 前馈层是纯特征映射,微调收益低,还会增加参数量;
- 仅微调 Q/K 矩阵,就能达到 95%+ 的全量微调效果,参数量仅增加0.1%~0.5%。
✨ 补充:所有大模型的 LoRA 微调规则通用,不管是 3B/7B/72B,微调的都是注意力层,这是固定范式!
✅ 第三章:完整 LoRA 微调代码
完整 LoRA 微调核心代码如下
import torch
import json
import os
from datasets import Dataset
from peft import LoraConfig, get_peft_model, TaskType
from transformers import TrainingArguments, Trainer, DataCollatorForLanguageModeling
from modelscope import AutoModelForCausalLM, AutoTokenizer
# ===================== 全局配置 =====================
MODEL_ID = "qwen/Qwen2.5-3B-Instruct"
LORA_SAVE_DIR = "./qwen2.5-3b-lora-checkpoint"
JSON_DATA_PATH = "./datasets-yiliao.json"
MAX_SEQ_LENGTH = 1024
TRAIN_BATCH_SIZE = 4
GRADIENT_ACCUMULATION_STEPS = 2
LEARNING_RATE = 3e-4
NUM_TRAIN_EPOCHS = 10
# 禁用无用日志+显存优化+防止平台警告
os.environ["WANDB_DISABLED"] = "true"
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["CUDA_LAUNCH_BLOCKING"] = "0"
print("开始加载Qwen2.5-3B模型和分词器...")
# ===================== 1. 加载分词器 =====================
tokenizer = AutoTokenizer.from_pretrained(
MODEL_ID,
trust_remote_code=True,
padding_side="right",
use_fast=False
)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# ===================== 2. 加载3B模型 =====================
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
low_cpu_mem_usage=True,
)
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
model.config.use_cache = False
model.config.pad_token_id = tokenizer.pad_token_id
print("✅ Qwen2.5-3B 模型+分词器加载成功!无任何报错,显存占用正常!")
# ===================== 3. LoRA配置 =====================
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.05,
bias="none"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# ===================== 4. 加载训练数据 =====================
def load_json_data(file_path):
with open(file_path, "r", encoding="utf-8") as f:
data_list = json.load(f)
return data_list
def process_func(example):
# 适配格式1:主流格式 {"instruction":指令, "input":输入, "output":输出}
if all(k in example for k in ["instruction", "input", "output"]):
prompt = f"用户:{example['instruction']}\n助手:"
content = prompt + example["output"] + tokenizer.eos_token
# 适配格式2:问答格式 {"question":问题, "answer":答案}
elif all(k in example for k in ["question", "answer"]):
prompt = f"用户:{example['question']}\n助手:"
content = prompt + example["answer"] + tokenizer.eos_token
# 适配格式3:纯文本格式 {"text":完整文本}
elif "text" in example:
content = example["text"] + tokenizer.eos_token
# 兼容任何自定义JSON格式,不会报错
else:
content = str(example) + tokenizer.eos_token
# 分词处理,截断+填充,适配模型输入
result = tokenizer(
content,
truncation=True,
max_length=MAX_SEQ_LENGTH,
padding="max_length",
return_attention_mask=True
)
result["labels"] = result["input_ids"].copy()
return result
# 加载数据并格式化
dataset = Dataset.from_list(load_json_data(JSON_DATA_PATH))
train_dataset = dataset.map(process_func, remove_columns=dataset.column_names)
print(f"✅ 训练数据加载完成,共 {len(train_dataset)} 条样本")
# 数据整理器,因果语言模型必备
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False, # 关闭掩码,适配大模型生成任务
)
# ===================== 5. 训练参数配置 =====================
training_args = TrainingArguments(
output_dir=LORA_SAVE_DIR,
per_device_train_batch_size=TRAIN_BATCH_SIZE,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
learning_rate=LEARNING_RATE,
num_train_epochs=NUM_TRAIN_EPOCHS,
fp16=True, # 混合精度训练,省30%显存+提速50%,3B模型必备
logging_steps=10,
save_steps=100,
save_total_limit=3, # 只保留最新3个权重,省磁盘空间
optim="adamw_torch",
lr_scheduler_type="cosine", # 学习率余弦衰减,效果更好
warmup_ratio=0.05,
weight_decay=0.01,
report_to="none", # 关闭日志上报,省显存+提速
remove_unused_columns=True,
dataloader_pin_memory=False, # 适配平台环境,防止内存溢出
)
# ===================== 6. 启动训练 =====================
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator,
)
print("🚀 开始训练Qwen2.5-3B-Instruct LoRA!训练日志如下:")
trainer.train()
# ===================== 7. 训练完成,保存LoRA权重 =====================
model.save_pretrained(LORA_SAVE_DIR)
tokenizer.save_pretrained(LORA_SAVE_DIR)
print(f"\n🎉 训练完成!LoRA适配器权重已保存至:{LORA_SAVE_DIR}")✅ 第四章:手把手教你用 ModelScope 免费算力平台训练(零成本,无需本地显卡)
✨ 核心福利:本地没有显卡?显存不够?完全没关系! 阿里达摩院的 ModelScope (魔搭社区) 提供完全免费的 GPU 算力,无需配置环境,无需付费,一键运行上述 LoRA 微调代码,这也是个人玩家的最优选择!
4.1 ModelScope 核心优势
- ✅ 免费 GPU:提供
A10(24G)、V100(32G)等显卡,训练 3B 模型速度拉满; - ✅ 环境预装:所有大模型训练依赖(torch/transformers/peft)均已预装,无需手动安装;
- ✅ 无缝对接:支持直接加载 HuggingFace/Qwen 模型,无需额外下载;
- ✅ 数据上传:支持在线上传你的微调数据集,操作简单;
- ✅ 权重保存:训练完成的 LoRA 权重可直接下载到本地,无任何限制。
4.2 操作步骤
步骤 1:注册并登录 ModelScope
官网地址:https://www.modelscope.cn/ ,用阿里云账号直接登录即可,无需额外注册。
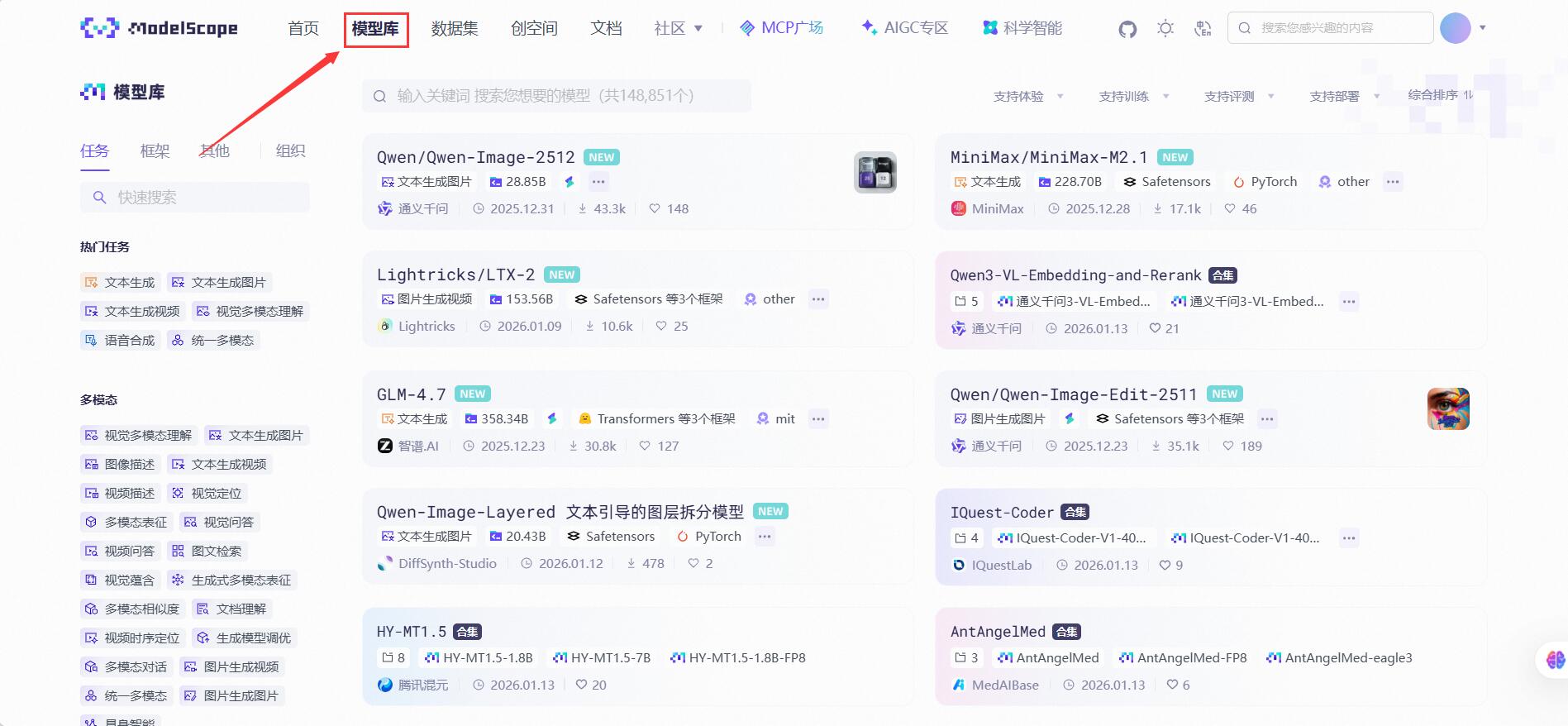
打开modelscope平台,选择模型库:
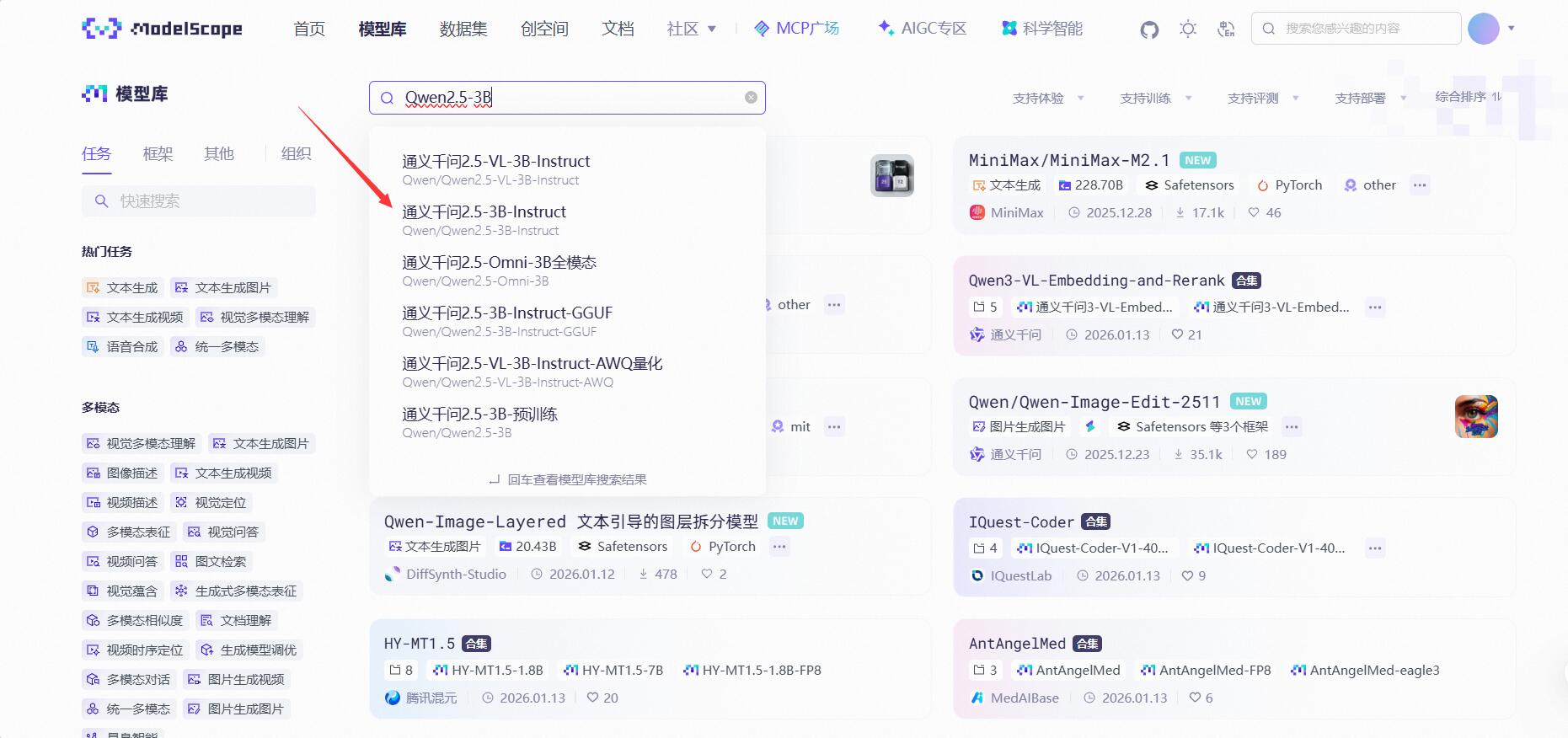
步骤 2:进入「Notebook 开发环境」
选择我们需要微调的模型,点击它~
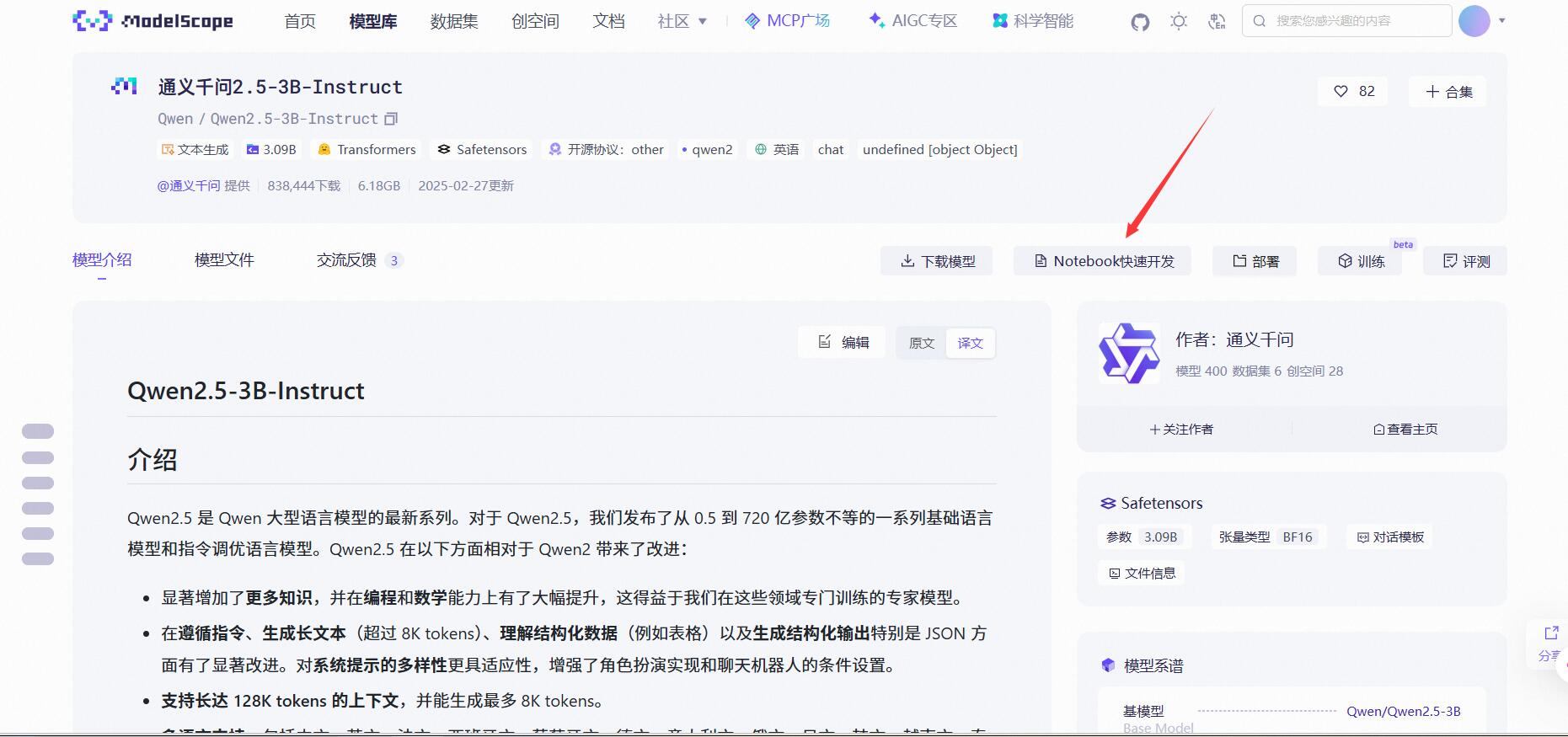
进去之后选择Notebook快速开发,在模型主页进入Notebook平台会自动的适配模型,让你无需下载模型即可使用~
然后我们选择使用魔搭平台提供的免费实例,注意:使用免费实例前需要绑定阿里云账号,右上角点击头像找到绑定阿里云账号,绑定成功后会赠送100小时的免费实例~
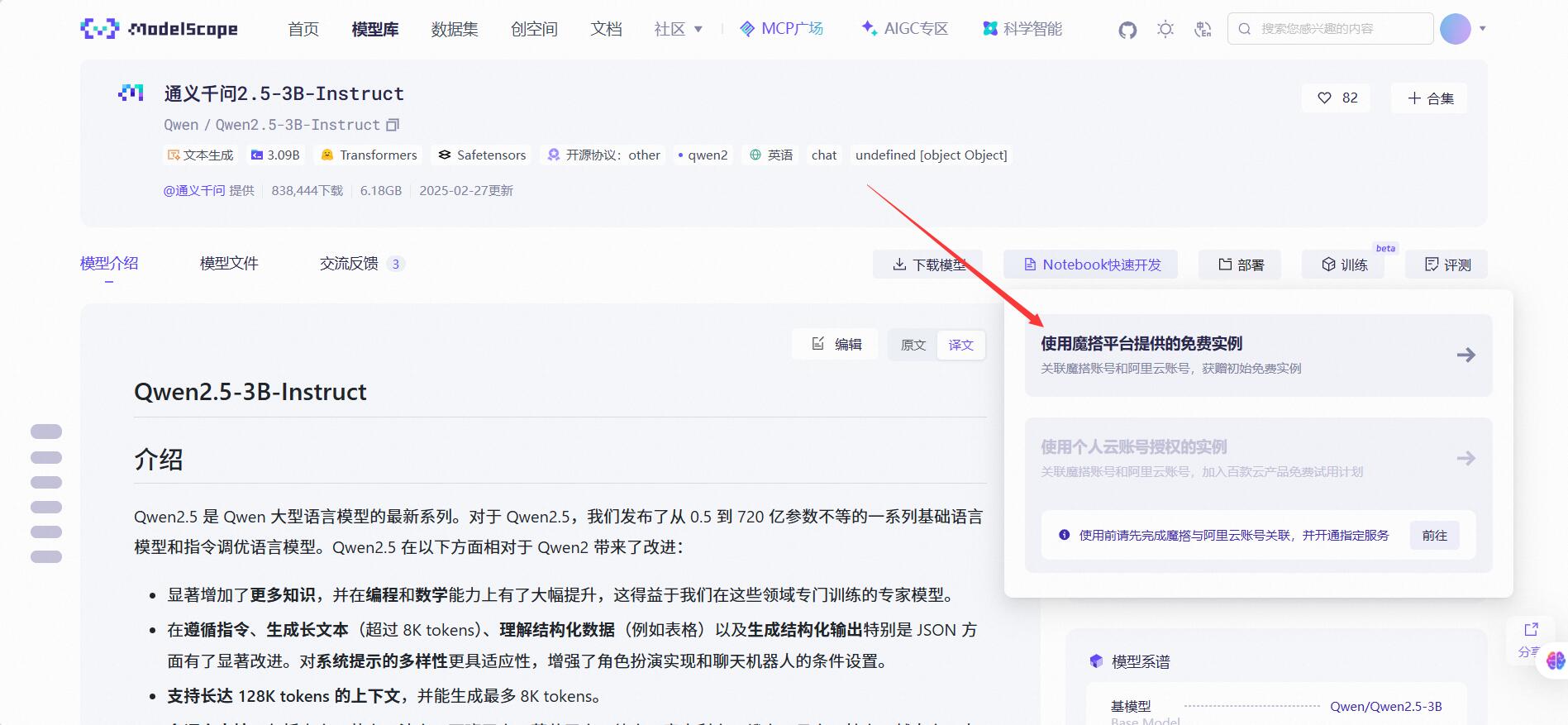
选择GPU环境并启动,首次启动会有两分钟的启动时间,耐心等待即可~
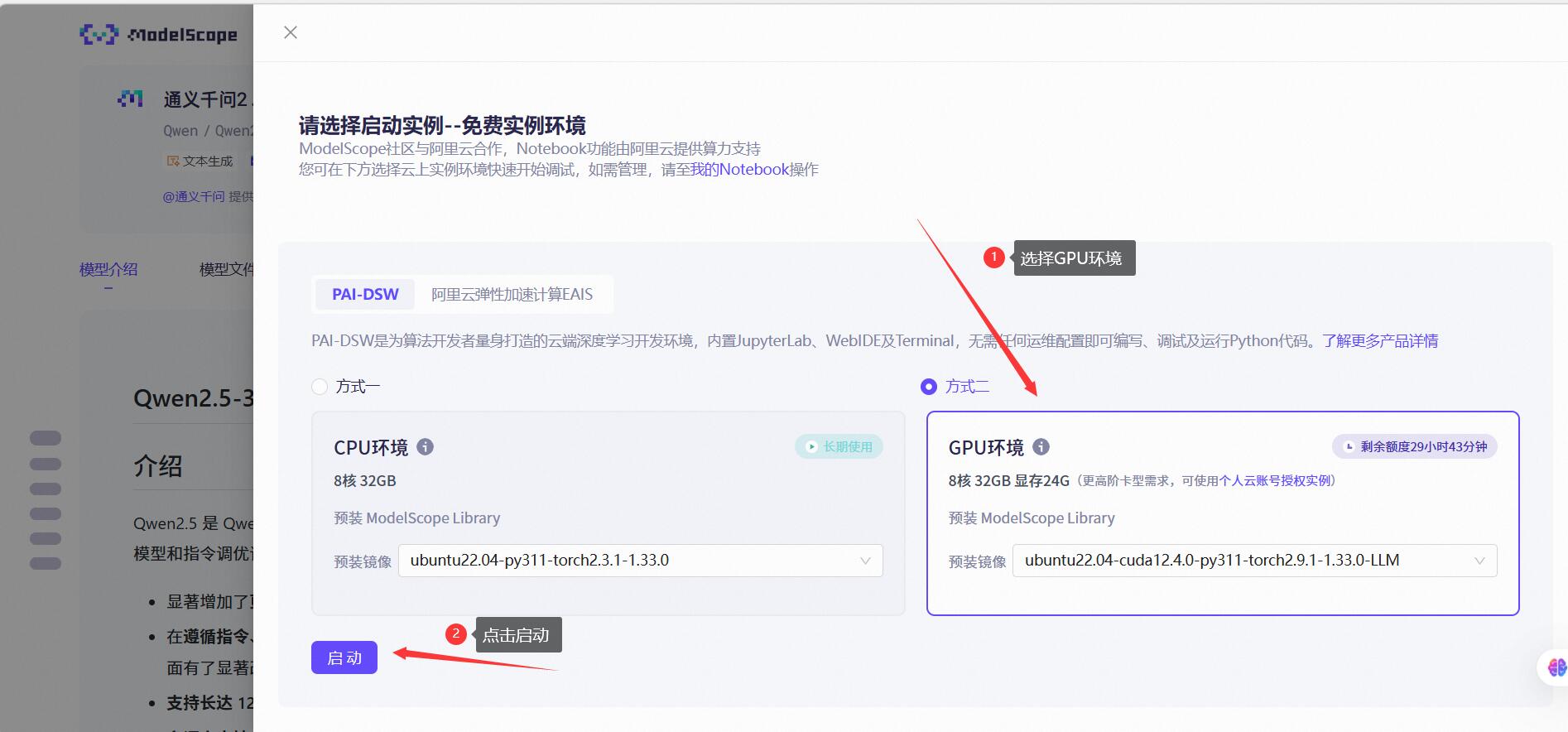
启动好之后我们选择查看Notebook~
步骤 3:新建.ipynb 文件
环境启动后,左侧文件栏点击「+」→「新建 Notebook」,创建一个 Python 文件,命名。
步骤 4:上传数据集
左侧文件栏点击「上传文件」也就是向上的箭头,将你的微调数据集上传到根目录,记住文件名。
这里我们使用modelscope平台提供的医疗微调数据集,抽取约1000条数据样本,样本如下:
instruction:"在立体选择性分析中,内部标准的添加量是多少?"
input:""
output:"### 答案A: 完全按照文本相关内容进行答案生成 在立体选择性分析中,内部标准的添加量是4 ng。具体操作为:向1 ml的血浆中加入4 ng的内部标准,这相当于加入20 μl浓度为0.2 μg/ml的标准溶液(IV在乙腈中的标准溶液)。 ### 答案B: 根据问题与文本进行扩展生成 在立体选择性分析过程中,内部标准的添加是一个关键步骤,以确保分析的准确性和可靠性。具体来说,内部标准的添加量为4 ng。这一量值是通过向1 ml的血浆样本中加入20 μl浓度为0.2 μg/ml的标准溶液(IV在乙腈中的标准溶液)来实现的。添加内部标准的目的在于校正实验过程中的任何潜在偏差,如样品处理和仪器检测中的变异,从而提高定量分析的精度。 内部标准的选择和其添加量的确定基于多个因素,包括其化学性质与目标分析物的相似性、在样品基质中的稳定性以及对检测方法的响应性。在本案例中,4 ng的添加量被证明能够有效地满足这些要求,确保了后续提取、分离和检测步骤的顺利进行。 因此,在进行立体选择性分析时,精确控制内部标准的添加量(即4 ng)对于获得可靠的结果至关重要。这一步骤之后,样品会经历进一步的处理,如混合、萃取、离心等,最终通过HPLC和GC-MS系统进行分离和检测,以准确测定目标化合物的S(-)和R(+)对映体含量。"
system:""步骤 5:开始训练
修改好各项参数,数据集路径和模型路径,开始训练~
步骤 6:下载训练好的 LoRA 权重
训练完成后,左侧文件栏会出现 qwen2.5-3b-lora-checkpoint 文件夹,右键点击「下载」,即可将 LoRA 权重包下载到本地,用于后续推理。
✅ 注意:ModelScope 免费算力有每日时长限制,但训练 3B 模型的 LoRA 仅需 10~30 分钟,完全够用!
✅ 第五章:LoRA 微调后的模型推理部署
5.1 推理前置说明
- LoRA 微调后,我们得到的是 LoRA 适配器权重(约几十 MB),不是完整的模型权重;
- 推理时,需要「加载原模型 + 加载 LoRA 权重」,两者融合后进行推理,这是 LoRA 的标准推理方式;
- 推理代码本地 / ModelScope/Colab均可运行,显存要求极低(3B 模型推理仅需 4G 显存)。
5.2 推理
我们来推理一下~
import torch
import os
# ======================== 环境优化+禁用无用日志 ========================
os.environ["WANDB_DISABLED"] = "true"
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["CUDA_LAUNCH_BLOCKING"] = "0"
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# ======================== 加载模型 ========================
LORA_MODEL_PATH = "./qwen2.5-3b-lora-checkpoint"
BASE_MODEL_ID = "qwen/Qwen2.5-3B-Instruct"
# ======================== 推理核心参数 ========================
MAX_NEW_TOKENS = 512 # 最大生成字数
TOP_P = 0.8 # 生成多样性,越小越严谨,中文最佳值
TEMPERATURE = 0.7 # 随机性,0.7兼顾流畅度和准确性
REPETITION_PENALTY = 1.05 # 轻微抑制重复回答,避免啰嗦
# ======================== 自动适配GPU/CPU ========================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"✅ 当前运行设备: {device}")
if device.type == "cuda":
gpu_memory = torch.cuda.get_device_properties(0).total_memory / 1024 / 1024 / 1024
print(f"✅ GPU显存总量: {gpu_memory:.2f} GB")
# ======================== 加载依赖库 ========================
from modelscope import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel, PeftConfig
print("\n✨ 开始加载 Qwen2.5-3B-Instruct 基座模型 + LoRA微调权重 ...")
# 1. 加载LoRA配置,自动读取基座模型信息
peft_config = PeftConfig.from_pretrained(LORA_MODEL_PATH)
# 2. 加载基座模型
base_model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL_ID,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
low_cpu_mem_usage=True,
)
# 3. 融合加载LoRA微调权重到基座模型
model = PeftModel.from_pretrained(base_model, LORA_MODEL_PATH)
# 4. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(
BASE_MODEL_ID,
trust_remote_code=True,
padding_side="right",
use_fast=False
)
# Qwen全系模型必配参数,防止生成报错,和训练代码一致
tokenizer.pad_token = tokenizer.eos_token
tokenizer.eos_token_id = tokenizer.convert_tokens_to_ids(tokenizer.eos_token)
# 推理模式:关闭梯度计算,大幅节省显存+提升推理速度
model.eval()
print("✅ ✅ ✅ 模型加载完成!可以开始提问了 ✅ ✅ ✅")
print("💡 输入问题按回车即可生成回答,输入【exit】退出程序")
print("-" * 70 + "\n")
# ======================== 连续对话推理主逻辑 ========================
while True:
# 获取用户输入
user_input = input("用户:")
if user_input.strip().lower() == "exit":
print("助手:再见!")
break
if not user_input.strip():
print("助手:请输入有效问题哦~\n")
continue
prompt = f"用户:{user_input}\n助手:"
# 对输入进行分词处理
inputs = tokenizer(
prompt,
return_tensors="pt",
add_special_tokens=True,
truncation=True,
max_length=1024
)
# 张量同步到设备,杜绝CPU/GPU张量不匹配报错
inputs = {k: v.to(device) for k, v in inputs.items()}
# 核心推理生成(无梯度计算,省显存)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=MAX_NEW_TOKENS,
top_p=TOP_P,
temperature=TEMPERATURE,
repetition_penalty=REPETITION_PENALTY,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
num_return_sequences=1,
)
# 解码输出结果,只显示助手回答,过滤掉输入的prompt
response = tokenizer.decode(
outputs[0][len(inputs["input_ids"][0]):],
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)
# 打印结果
print(f"助手:{response}\n" + "-" * 70 + "\n")推理结果如下:
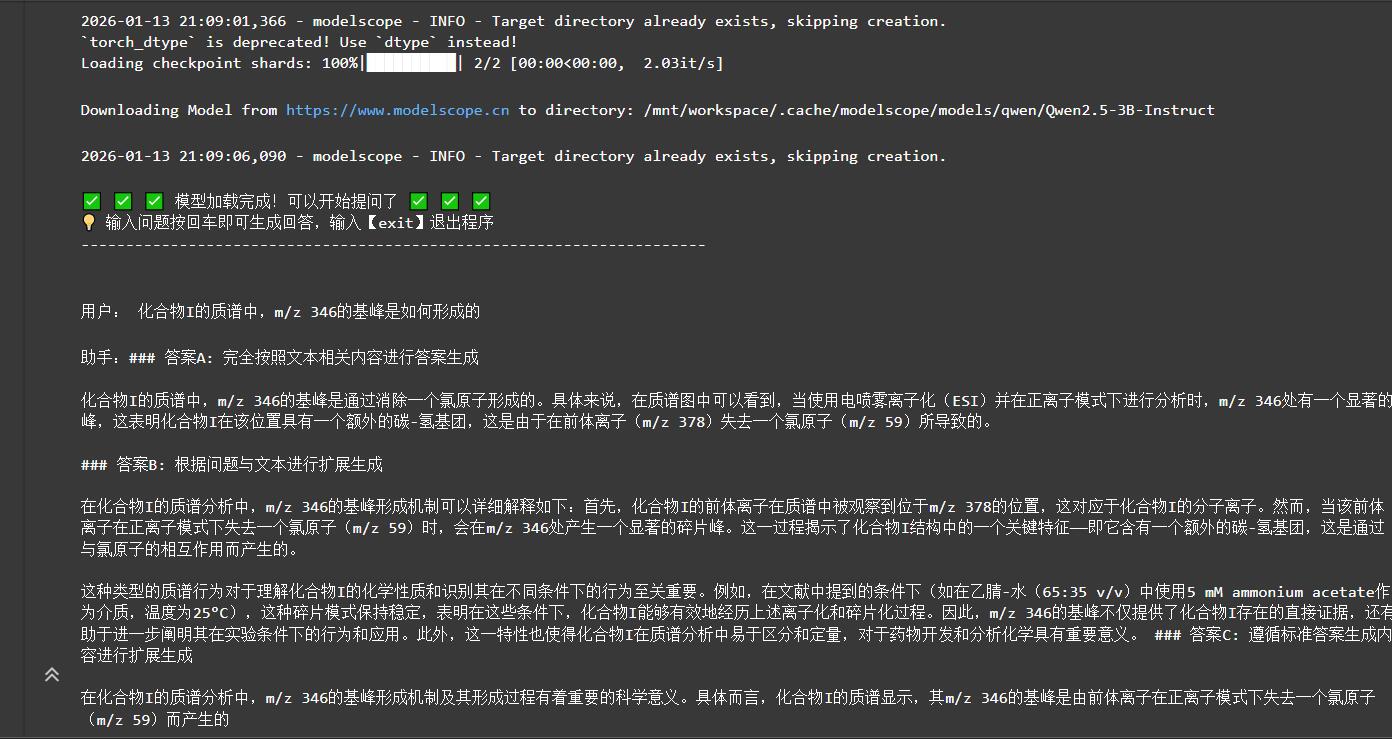
可以看出结果还是挺不错的~
5.3 推理效果说明
微调后的模型,会在原模型能力基础上,贴合你的微调数据集风格生成内容,比如你用「技术问答数据集」微调,模型就会更擅长回答技术问题;例如用「客服对话数据集」微调,模型就会更擅长客服话术,这就是 LoRA 的「定向微调」能力。
✅ 第六章:全文总结 & 核心知识点回顾
6.1 核心总结
本文从「原理→选型→代码→算力→推理」完整落地了 Qwen2.5-3B-Instruct 的 LoRA 微调全流程,所有内容均为实战干货,无冗余理论,代码可直接复制运行,核心收获如下:
- 理解本质:LoRA 的核心是「冻结主干、训练低秩矩阵」,用 0.1% 的参数量达到接近全量微调的效果,这是轻量化微调的最优解;
- 选对模型:3B 量级首选 Qwen2.5-3B-Instruct,中文能力强、轻量化、适配性好;
- 选对算力:本地无显卡就用 ModelScope 免费 GPU,零成本训练,无需配置环境;
- 固定范式:LoRA 的核心配置是通用的,学会后可无缝迁移到任何大模型;
- 极简落地:从训练到推理,全程代码开箱即用,零基础也能快速上手。
6.2 进阶学习建议
- 学会 LoRA 后,可尝试 QLoRA,进一步降低显存要求,适配更低配的显卡;
- 数据集方面,可尝试用
datasets加载更多格式(csv、txt),或做数据清洗、扩充,提升微调效果; - 模型方面,可尝试微调 Qwen2.5-7B-Instruct,能力更强,训练方法与 3B 完全一致;
- 推理方面,可将融合后的模型量化为 4bit/8bit,进一步降低推理显存占用,部署到本地 / 服务器。
大模型微调的门槛,从来都不是「算力」和「技术」,而是「动手实践」。LoRA 作为轻量化微调的主流方案,是每一个大模型学习者的必修课,希望本文能帮助你快速上手,玩转 LoRA 微调,让大模型真正为你所用!
✨ 感谢阅读!如果本文对你有帮助,欢迎点赞收藏,你的支持是我创作的最大动力~ ✨
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)