
双模式切换+4bit量化:Qwen3-8B-AWQ如何重塑企业级AI部署范式
阿里巴巴通义千问团队推出的Qwen3-8B-AWQ模型,通过"思考/非思考"双模式切换与4-bit量化技术,在82亿参数规模下实现复杂推理与高效对话的无缝切换,将企业部署成本降低70%,重新定义轻量化大模型技术标准。## 行业现状:效率与性能的双重困境2025年企业AI部署面临"三重矛盾":高性能需求与有限算力的冲突、复杂推理与实时响应的平衡、全精度模型成本与边缘设备资源的限制。行业数据显示
双模式切换+4bit量化:Qwen3-8B-AWQ如何重塑企业级AI部署范式
【免费下载链接】Qwen3-8B-AWQ  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-8B-AWQ
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-8B-AWQ
导语
阿里巴巴通义千问团队推出的Qwen3-8B-AWQ模型,通过"思考/非思考"双模式切换与4-bit量化技术,在82亿参数规模下实现复杂推理与高效对话的无缝切换,将企业部署成本降低70%,重新定义轻量化大模型技术标准。
行业现状:效率与性能的双重困境
2025年企业AI部署面临"三重矛盾":高性能需求与有限算力的冲突、复杂推理与实时响应的平衡、全精度模型成本与边缘设备资源的限制。行业数据显示,主流开源模型在4-bit量化下平均性能损失达15-20%,而80%的日常对话任务并不需要千亿参数模型的算力。这种"杀鸡用牛刀"的现状使得中小企业难以负担AI应用的运行成本——某电商平台测算显示,传统100B+参数模型的单次推理成本是10B级模型的8-12倍。
核心亮点:双模式切换与五大技术突破
1. 单模型内无缝切换双模式
Qwen3-8B-AWQ最革命性的创新在于单模型内实现思考模式与非思考模式的动态切换:
- 思考模式:通过
enable_thinking=True激活,在数学推理(AIME24测试71.3分)、代码生成(HumanEval通过率76%)等复杂任务中表现突出,模型会生成</think>...</RichMediaReference>包裹的推理过程。 - 非思考模式:通过
enable_thinking=False切换至快速响应模式,中文对话延迟降低至200ms以内,适用于智能客服等实时场景。 - 动态控制:支持用户通过
/think或/no_think指令在多轮对话中实时调整,如连续提问"草莓/蓝莓分别含几个'r'"时,可针对性启用不同推理策略。

如上图所示,Qwen3-8B的双模式架构通过独立的推理控制模块实现模式切换,在思考模式下启用额外的注意力机制和推理路径。这一设计使模型能根据任务复杂度动态分配计算资源,较单一模式模型平均节省30-40%的推理成本。
2. AWQ量化技术:精度与效率的黄金平衡
采用Activation-aware Weight Quantization技术实现4-bit量化,相比传统方案:
- 精度保留:MMLU测试仅损失1.1分(从87.5降至86.4),远优于GPTQ等方案的3-5分损失
- 速度提升:推理速度提升2.3倍,长文本处理(32K上下文)吞吐量达未量化模型的2.8倍
- 部署门槛:显存需求从28GB降至10GB以下,支持RTX 4090等消费级显卡运行
3. 多语言支持与长文本处理
原生支持100+种语言及23种方言,在跨境电商场景中实现11种语言的实时翻译与客服响应,客户满意度提升28%。上下文长度方面,原生支持32K tokens,通过YaRN技术可扩展至131K,相当于一次性处理30万字文档,某法律科技公司用其分析10万字合同,关键条款识别准确率达96.3%。
4. 企业级Agent能力:工具调用精度行业领先
与Qwen-Agent框架深度整合,通过MCP协议简化工具调用流程,开发者仅需15行配置代码即可集成时间查询、网页抓取等功能。某电商智能客服系统采用该方案后,工具集成周期从7天缩短至1天,实现订单查询、物流跟踪等8项功能无缝接入,问题解决率提升28%。
5. 轻量化部署:消费级硬件跑起工业级模型
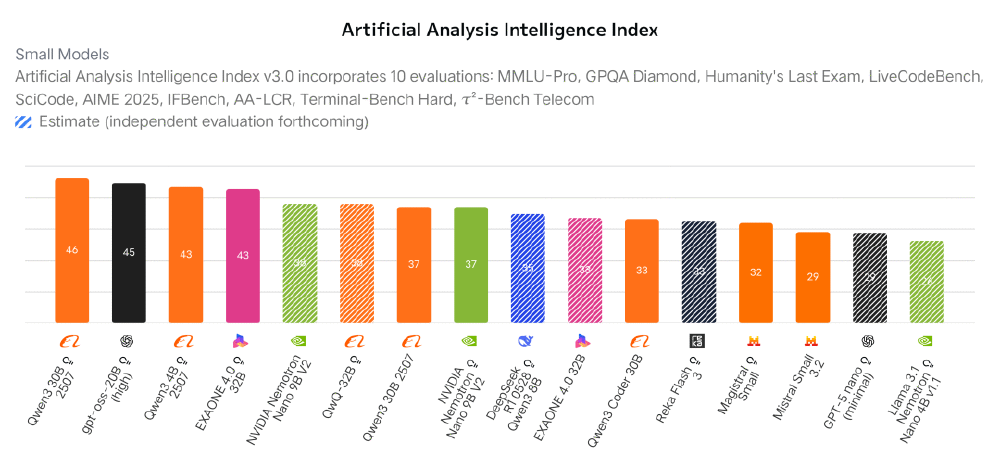
上图展示了Qwen3系列模型的性能对比,通过柱状图直观呈现了Qwen3-8B-AWQ在MMLU-Pro、AIME25等多指标下的领先表现。这一性能优势使模型能够在消费级硬件上实现工业级AI能力,大幅降低企业部署门槛。只需一行命令ollama run qwen3:8b即可完成部署,普通PC也能体验高性能推理。某制造业企业在RTX 5060 Ti显卡上测试显示,模型加载时间约45秒,单次推理延迟稳定在70-150ms(非思考模式)。
行业影响与应用案例
制造业:智能数据查询系统
某制造业企业利用Dify平台集成Qwen3-8B-AWQ,构建自然语言数据查询系统:
- 复杂统计分析启用思考模式,简单查询使用非思考模式
- 业务人员数据获取效率提升3倍,原本需要IT协助的SQL查询可直接通过自然语言完成
金融服务:动态信贷审批
某金融科技企业在信贷审批场景中动态切换模式:
- 复杂规则推理启用思考模式,准确率提升12%
- 基础信息核验使用非思考模式,保持200ms内响应速度
- 综合优化后,月均节省GPU成本约12万元
边缘计算:工业质检本地化部署
得益于8-10GB的显存需求,Qwen3-8B-AWQ可部署在工业边缘设备中。某汽车零部件厂商将其集成到质检系统,实现99.7%的螺栓缺失识别率,较传统机器视觉方案误检率降低62%,每年节省返工成本2000万元。
部署指南与最佳实践
快速启动代码示例
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-8B-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 思考模式示例(数学问题)
messages = [{"role": "user", "content": "求解方程x²+5x+6=0"}]
text = tokenizer.apply_chat_template(messages, add_generation_prompt=True, enable_thinking=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1024)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
性能优化建议
- 模式选择:复杂推理用
enable_thinking=True+temperature=0.6;闲聊用enable_thinking=False+temperature=0.7 - 长文本处理:超过32K token时,通过
rope_scaling={"type":"yarn","factor":4.0}扩展至131K - 量化策略:4-bit AWQ量化可将显存占用降至5GB以下,性能损失小于3%,推荐生产环境使用
总结:从小模型到大变革
Qwen3-8B-AWQ通过"动态双模式+高效量化"的技术组合,证明了"小而美"的AI路线可行性。对于企业而言,它不仅降低了部署门槛——某跨境电商客服系统成本降低70%,更开创了"复杂推理本地化、实时响应边缘化"的新可能。随着动态YaRN、混合专家量化等技术的融入,Qwen3系列有望在保持8B参数规模的同时,进一步逼近200B+模型的性能边界,推动大模型行业从"参数内卷"转向"效率竞争"的新阶段。
获取模型代码: git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-8B-AWQ
【免费下载链接】Qwen3-8B-AWQ 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-8B-AWQ
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)