
GPU 算力翻倍,AI 反而变慢了?FlashAttention-4 给出了惊人的答案
《FlashAttention-4:重新定义GPU上的Attention计算》 随着GPU算力持续提升,Attention计算却未获得等比例加速。最新研究发现,现代GPU的矩阵运算已足够快,但Softmax中的指数运算和内存访问成为新瓶颈。FlashAttention-4通过算法-硬件协同设计实现突破:1)用多项式逼近替代昂贵的exp运算;2)重构异步流水线;3)优化Softmax重缩放策略;4)
如果你最近在关注大模型训练,可能会发现一个很反常的现象。GPU 一代比一代强。算力翻倍、Tensor Core 更快、AI 芯片越来越猛。但很多研究人员却发现:
模型训练速度并没有等比例提升。
问题出在哪里?答案其实藏在一个很多人忽略的地方:
Attention。

而最近发布的一篇论文FlashAttention-4给出了一个非常有意思的答案。甚至可以说,它重新定义了 Attention 在 GPU 上应该如何实现。
一、AI 世界最重要的一层:Attention
几乎所有现代 AI 模型——
-
GPT
-
Claude
-
Gemini
-
多模态模型
底层都建立在 Transformer 架构上。而 Transformer 最核心的一步,就是 Attention。简单理解:
Attention 的作用就是:
让模型决定“哪些信息更重要”。
例如一句话:
The animal didn't cross the street because it was too tired模型需要判断:“it” 指的是谁?是 animal,还是 street?Attention 就是用来解决这种“上下文关联”的。

但问题是:
Attention 的计算复杂度是:O(N²)也就是说:上下文越长,计算量爆炸。这也是为什么很多模型:
-
4K
-
8K
-
32K
-
100K token
一旦上下文变长,算力需求就会疯狂增长。
二、FlashAttention:改变游戏规则的优化
为了加速 Attention,研究界过去几年做了很多努力。其中最成功的方案之一,就是:FlashAttention。它的核心思想很简单:减少 GPU 内存访问。因为在 GPU 上:
数据移动往往比计算更慢。
FlashAttention 通过 Tile 分块计算:让 Attention 在 SRAM 中完成计算,避免频繁访问显存。结果非常惊人:
-
显存减少
-
速度更快
-
长序列训练更稳定
于是:FlashAttention 成为了很多 AI 框架的默认实现。但问题是——
GPU 变了。

三、新 GPU 出现了一个“奇怪现象”
新一代 GPU ——NVIDIA Blackwell。带来了巨大的算力提升。相比上一代,NVIDIA Hopper,Tensor Core 的性能:
提升超过 2 倍。
但很多研究人员跑 benchmark 时发现:Attention 并没有变快那么多。于是他们做了一件事情,分析 GPU 的瓶颈。结果非常意外。真正拖慢速度的不是矩阵乘法,而是:
Softmax。
更具体来说,是两个操作:
-
指数运算 exp()
-
shared memory 访问
换句话说:GPU 的矩阵计算已经快到一种程度——
其它步骤反而成了拖后腿的。
论文把这种现象称为:Asymmetric Hardware Scaling
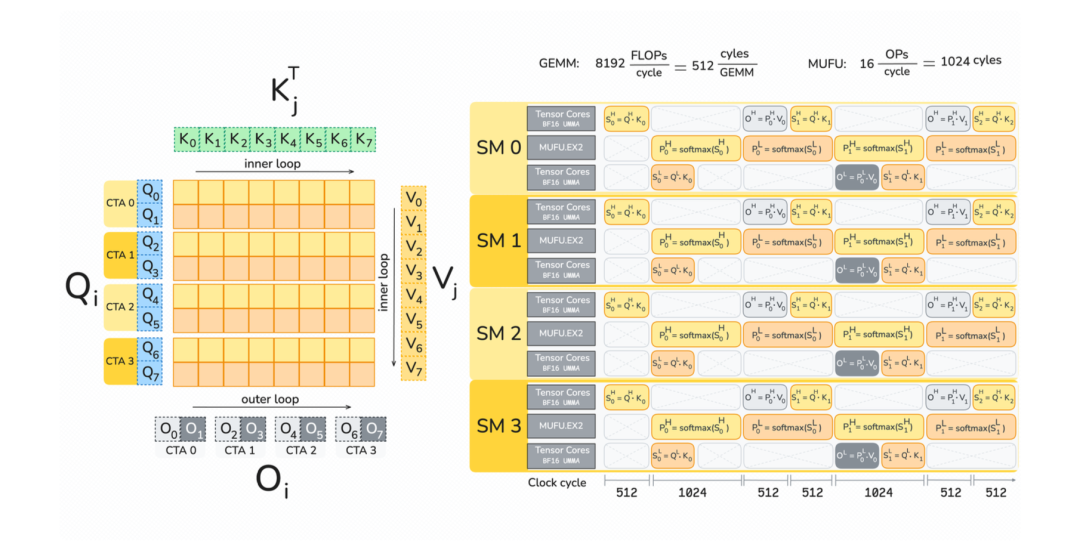
四、FlashAttention-4 的核心思路
面对这个问题,研究人员做了一件非常大胆的事情:重新设计 Attention 的 GPU 内核。不是简单优化。而是 算法 + 硬件协同设计。
FlashAttention-4 的优化主要集中在四个方向。

1 用数学近似替代指数运算
Softmax 中最贵的一步是:
exp(x)在 GPU 中,这个操作由特殊单元执行,但吞吐量很低,研究人员想到一个办法:不用 exp,而是用多项式逼近。
核心思想:把指数拆成:
2^x = 2^{整数} × 2^{小数}然后:
-
整数部分 → 位运算
-
小数部分 → 多项式近似
例如:
2^x ≈ a + bx + cx² + dx³这些计算可以在 FMA 单元完成。
结果:指数运算速度大幅提升。而在 BF16 精度下:误差几乎可以忽略。

2 重新设计 GPU 计算流水线
FlashAttention-4 还重新设计了 GPU 的执行流水线。传统流程是:
矩阵乘法 → softmax → 输出而 FlashAttention-4 采用 异步 pipeline:当一部分数据在做矩阵乘法,另一部分同时:

-
做 softmax
-
做数据加载
这种方式类似:CPU 的超流水线执行,GPU 利用率大幅提升。
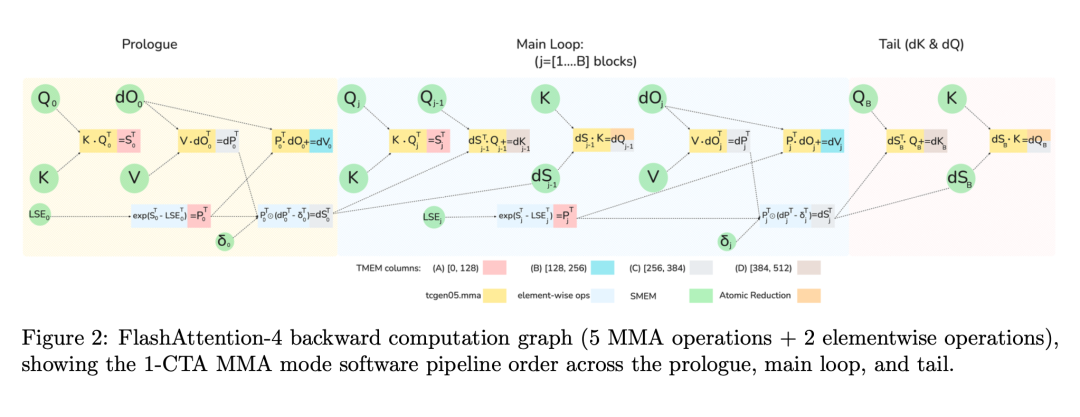
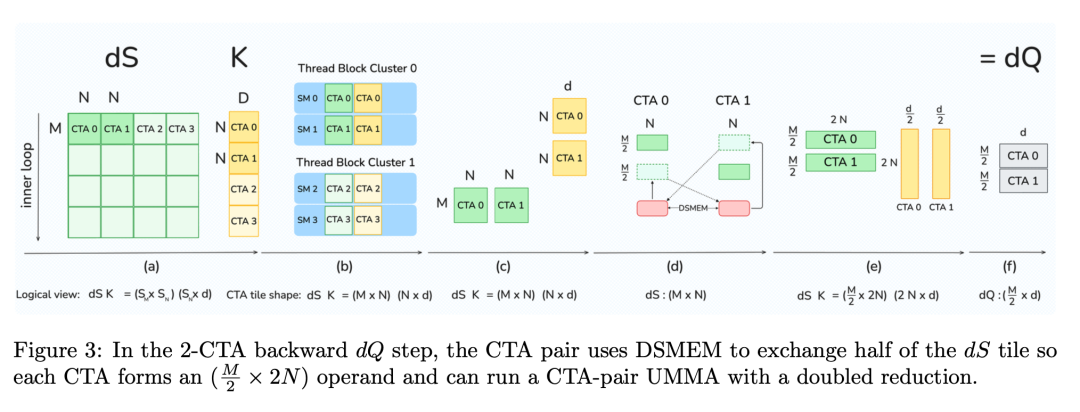
3 减少 Softmax 重缩放
FlashAttention 使用一种叫 online softmax 的算法。
它会频繁执行一个操作:
rescaleFlashAttention-4 的观察是:其实只有在 最大值变化时 才需要 rescale。于是他们加了一层判断:如果变化不大:直接跳过 rescale。结果:Softmax 的计算量再次减少。
4 利用 GPU 新的 Tensor Memory
Blackwell GPU 引入了一个新的内存层:Tensor Memory,每个 SM 大约:256KB
FlashAttention-4 利用这个内存:存储中间 Attention 结果。
好处是:
-
减少 shared memory 访问
-
降低寄存器压力
-
支持更大的 tile
这进一步提升了性能。
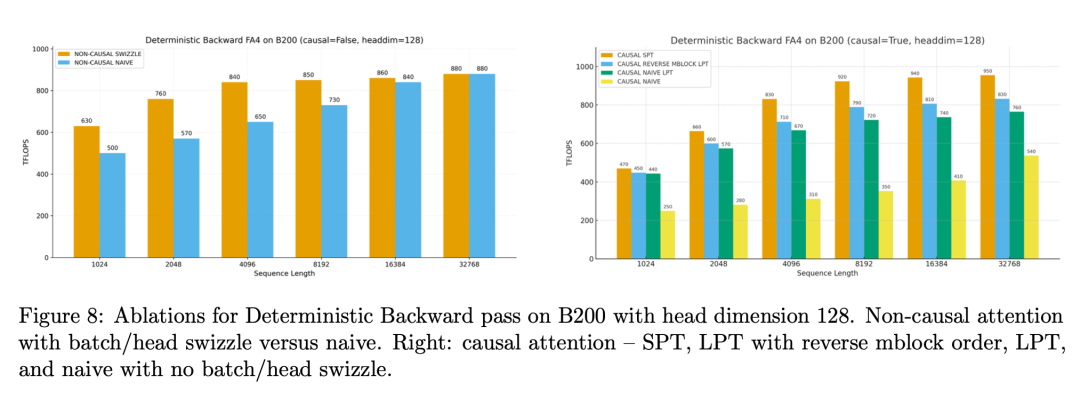
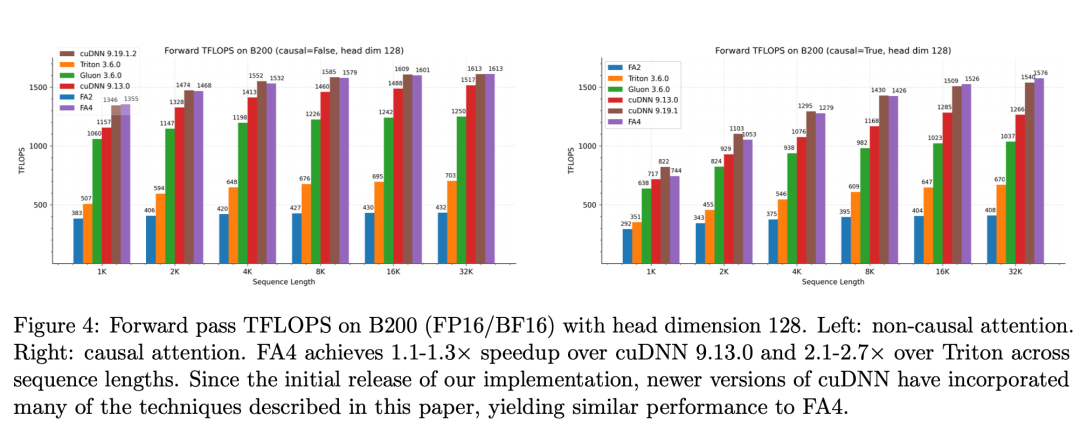
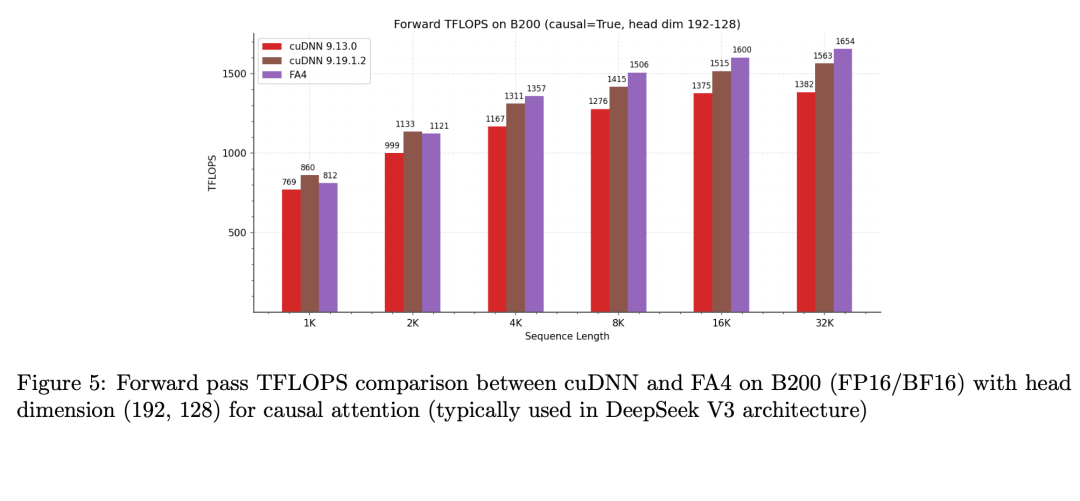
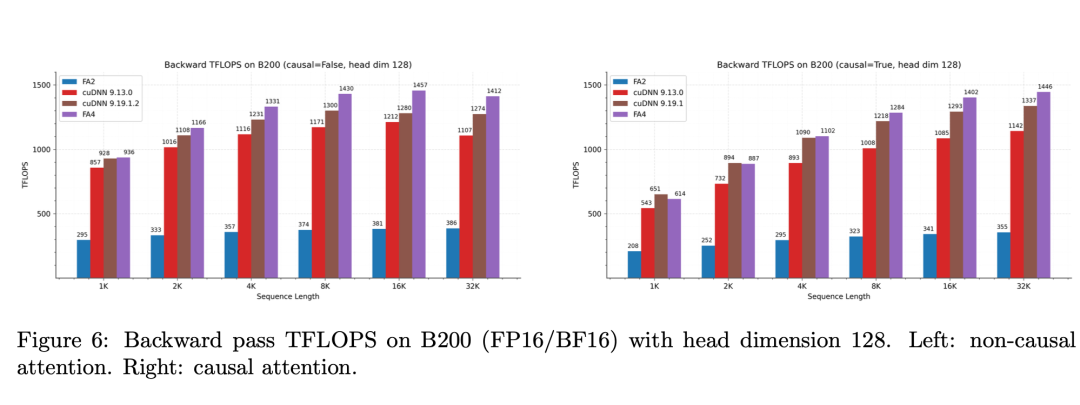
五、性能提升有多大?
论文在NVIDIA B200 GPU 上进行了测试。结果非常惊人。相比其他实现:
FlashAttention-4:比 cuDNN Attention 快 1.1 – 1.3 倍
比 Triton 实现 快 2 – 2.7 倍
峰值算力:1613 TFLOPS,大约达到 GPU 理论算力的:71%对于 GPU kernel 来说:这是一个非常高的利用率。
六、一个很多人没注意的改变
FlashAttention-4 还有一个有意思的变化。它不再使用复杂的 C++ 模板。而是基于CuTe-DSL
一个 Python DSL。优势非常明显:
-
Python 写 GPU kernel
-
自动生成 PTX
-
JIT 编译
最关键的是:编译时间从 55 秒降到 2.5 秒。研究人员可以更快测试新想法。
七、这篇论文真正重要的地方
FlashAttention-4 的意义,其实不仅仅是一个优化。它揭示了一个趋势:未来 AI 系统的性能瓶颈,可能不再是:矩阵计算。而是:
-
内存访问
-
非线性函数
-
调度
也就是说:AI 进入了一个新的阶段:算力不是唯一瓶颈。如何设计 更贴近硬件的算法,会变得越来越重要。
如果说最早的 FlashAttention 解决的是:“Attention 太占显存”
那么 FlashAttention-4 解决的是:“GPU 太快了,其它部分反而跟不上。”
当 AI 硬件继续狂飙时,这类 算法 + 硬件协同设计 的优化,很可能会越来越重要。也许未来的大模型性能突破,并不来自新的模型结构。而来自这些 隐藏在底层的系统工程创新。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程


更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)