
机器学习基础
一、机器学习概述1.1 人工智能概述1.人工智能起源?图灵测试、达特茅斯会议2.人工智能的3个阶段1980年代是正式形成期1990-2010年代是蓬勃发展期2012年之后是深度学习期3.人工智能、机器学习和深度学习之间的关系机器学习是人工智能实现的一个途径;深度学习是机器学习的一个方法发展而来的4.主要分支介绍(1)机器视觉人脸识别(2)机器视觉语音识别、语义识别(3)机器人5.人工智能必备三要素
一、机器学习概述
1.1 人工智能概述
1.人工智能起源?
图灵测试、达特茅斯会议
2.人工智能的3个阶段
1980年代是正式形成期
1990-2010年代是蓬勃发展期
2012年之后是深度学习期
3.人工智能、机器学习和深度学习之间的关系
机器学习是人工智能实现的一个途径;
深度学习是机器学习的一个方法发展而来的
4.主要分支介绍
(1)机器视觉
人脸识别
(2)机器视觉
语音识别、语义识别
(3)机器人
5.人工智能必备三要素
数据、算法、计算力
6.GPU、CPU适用范围
GPU - 计算密集型、可并行计算
CPU - IO密集型
二、机器学习的工作流程
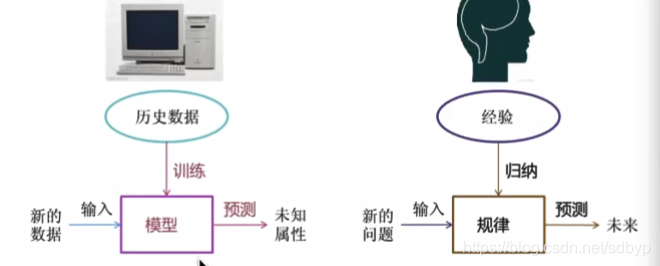
1.定义
从
数据中自动分析获得的模型,并利用模型对未知的数据进行预测.
2.机器学习的工作流程
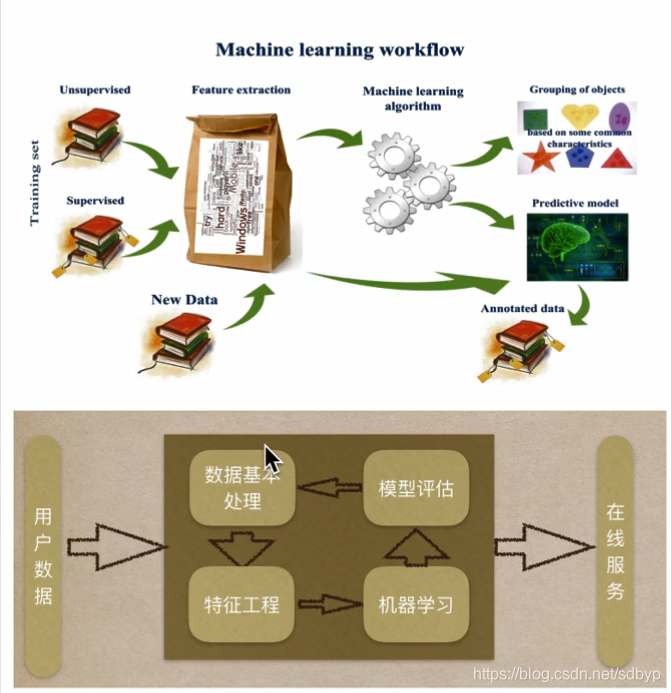
3.数据集的基本介绍
- 在数据集中一般
一行数据称为一个
样本;
一列数据称为一个特征;
有些数据有目标值(标签值),有些数据没有.
- 数据类型构成:
数据类型一:特征值+目标值(目标值是连续的和离散的);数据类型二:只有特征值,没有目标值.
- 数据划分:
训练数据(训练集):构建模型 - 70% ~ 80%;测试数据(测试集):评估模型 - 20% ~ 30%;
4.数据基本处理
5.特征工程
(1)定义
把数据转换为机器更容易识别的数据;
(2)为什么需要特征工程
数据和特征决定了机器学习的上限,而模型和算法知识逼近这个上限而已.
(3)包含内容
特征提取
特征预处理
特征降维
6.机器学习
(1)类型
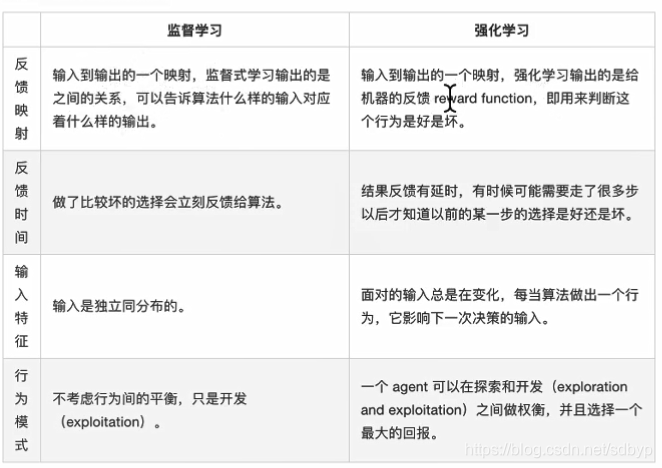
监督学习– 有特征值、有目标值-回归问题 – 目标值连续
-分类问题 – 目标值离散
-目的:预测结果
-案例:猫狗分类、房价预测
-分类算法:k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
-回归算法:线性回归、岭回归
无监督学习– 仅有特征值-目的:发现潜在的结构
-案例:“人以类聚物以群分”
聚类方法:k-means,降维
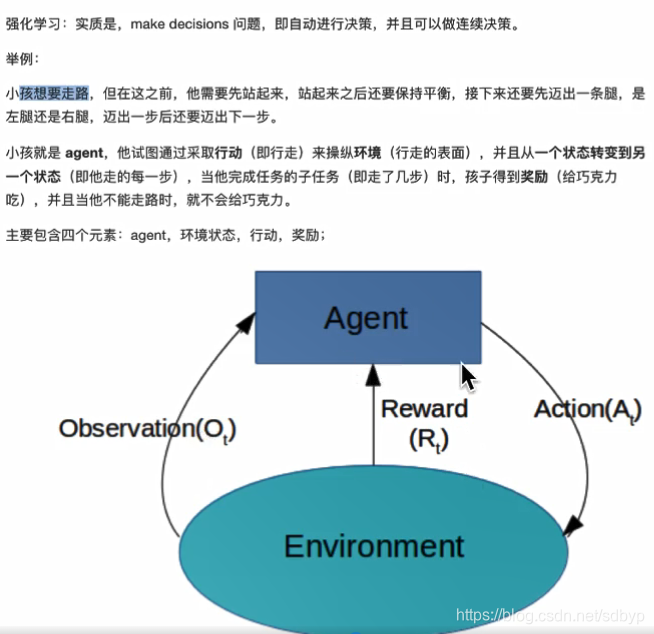
半监督学习– 部分数据有目标值,部分没有强化学习– 动态过程,上一步的输出是下一步的输入

7.模型评估
(1)分类模型评估
准确率:预测正确数占样本总数的比例.精确率:正确预测为正占全部预测为正的比例.召回率:正确预测为正占全部正样本的比例.F1-score:主要用于评估模型的稳健性.AUC指标:用于评估样本不均衡的情况.
(2)回归模型评估





(3)拟合
欠拟合:使用的特征太少(识别天鹅,把鸭子也识别为天鹅)
过拟合:使用的特征太多,
8.网络数据集
UCI(University of California Irvine):http://archive.ics.uci.edu/ml/index.php
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)