
OpenCSG Chinese FineWeb:清华最新论文背后的中文数据基石
向下对接 L0(Raw Data):从 PB 级的原始网络爬取数据(如 Common Crawl)中,通过启发式清洗、去重、格式标准化等基础处理,筛选出具备基本可读性的文本。向上支撑 L2/L3/L4:为后续的模型驱动精选(L2)、合成精炼(L3)、知识组织化(L4)提供规模足够大、噪声可控的原材料库。Chinese FineWeb 正是 OpenCSG 为这一层级量身打造的中文数据集。当模型架构
当清华团队提出分层数据管理框架,推动 AI 从“堆数据”走向“精细化治理”,OpenCSG 开源的 Chinese FineWeb 数据集成为这套体系中不可或缺的 L1 层基础——这不是巧合,而是开源社区与学术前沿的一次深度协同。
OpenCSG Chinese FineWeb 被清华论文选中
2026 年 2 月,清华大学自然语言处理实验室(刘知远、韩旭、孙茂松团队)联合 ModelBest Inc. 在 arXiv 发表了一篇重磅论文:《Data Science and Technology Towards AGI Part I: Tiered Data Management》(arXiv:2602.09003)。
这篇论文提出了一个系统化的 L0–L4 分层数据管理框架,旨在解决当前大模型训练中“过度依赖数据规模扩张”的困境。而在论文构建的中文 Web 数据体系中,OpenCSG 开源的 Chinese FineWeb 系列数据集(尤其是 Chinese FineWeb-edu-v2)被明确选定为 L1 层(Filtered Data)的基础中文语料来源。
这意味着什么?在通往 AGI 的数据管理体系中,Chinese FineWeb 不是可有可无的配角,而是整个中文数据链路的起点和基石。没有这一层的高质量过滤数据,后续的模型驱动精选(L2)、合成精炼(L3)乃至知识组织化(L4)都将成为无源之水。
论文核心观点:AI 进入“数据与模型协同演化”新阶段
清华团队在论文中系统回顾了 AI 发展的四个阶段:
符号学习时代:依赖专家编写的规则和知识库,通过显式规则实现智能。
监督学习时代:以标注数据为驱动,从手工特征工程过渡到端到端的深度学习,模型性能直接依赖数据规模、质量和表征能力。
自监督学习时代:预训练范式的兴起,通过海量无标注语料的自监督学习,模型能够压缩和内化世界知识,产生强大的泛化能力和涌现能力。
反馈学习时代:通过强化学习和人类反馈(RLHF),模型在持续交互中主动探索行为空间,提升决策能力和适应性。
而论文认为,当前 AI 正在进入第五个阶段:数据与模型协同演化(Data-Model Co-Evolution)。在这个新阶段,模型不再只是数据的被动消费者,而是主动参与数据的组织、筛选、评分和生成;高质量数据反过来又放大模型的能力,形成正向反馈循环。
这一判断的背后,是对当前“堆数据”范式瓶颈的深刻洞察:
数据稀缺性矛盾:高质量公开数据资源日益枯竭,未来模型发展不能再单纯依赖扩大数据规模。
多阶段需求矛盾:LLM 训练涵盖预训练、中期训练、对齐微调等多个阶段,每个阶段对数据质量、数量和分布的要求截然不同,粗放的混合训练策略严重制约了高价值数据样本的充分利用。
成本收益矛盾:数据管理必须在获取成本与模型性能收益之间取得平衡——早期阶段应采用启发式过滤等轻量低成本手段,深度管理阶段才引入 LLM 标注等高成本精细化方法。

为什么是 Chinese FineWeb?OpenCSG 的技术选择
在论文提出的五层数据框架中,L1 层(Filtered Data)承担着承上启下的关键角色:
向下对接 L0(Raw Data):从 PB 级的原始网络爬取数据(如 Common Crawl)中,通过启发式清洗、去重、格式标准化等基础处理,筛选出具备基本可读性的文本。
向上支撑 L2/L3/L4:为后续的模型驱动精选(L2)、合成精炼(L3)、知识组织化(L4)提供规模足够大、噪声可控的原材料库。
Chinese FineWeb 正是 OpenCSG 为这一层级量身打造的中文数据集。 它继承了 HuggingFace FineWeb 的工程理念,专门针对中文网络文本的特殊性进行了系统性处理:
OpenCSG 的数据处理流程
语言过滤:精准识别中文内容,剔除混杂语言和乱码。中文网络环境复杂,常见中英混杂、繁简混用、编码错误等问题,OpenCSG 采用多层语言识别策略,确保数据集的语言纯净度。
去重处理:基于 MinHash-LSH 等算法进行大规模去重。网络爬取数据存在大量重复内容,包括完全重复、近似重复、模板化重复等多种形态。Chinese FineWeb 通过模糊去重技术,在保留内容多样性的同时,大幅降低冗余。
低质内容剔除:过滤广告、色情、暴力等明显低质内容。OpenCSG 构建了针对中文互联网环境的内容质量评估体系,包括广告识别、垃圾信息过滤、有害内容检测等多个维度。
编码标准化:处理繁简转换、编码统一等中文特有问题。中文数据常见 GB2312、GBK、UTF-8 等多种编码,还存在繁简体混用的情况。Chinese FineWeb 统一采用 UTF-8 编码,并根据应用场景提供繁简体版本。
格式规范化:统一文本格式,修复断行、空格、标点等排版问题。网络爬取的原始文本常存在格式混乱、HTML 标签残留、特殊字符干扰等问题,OpenCSG 通过规范化处理,确保文本的可读性和一致性。
相比原始的 Common Crawl 中文数据,Chinese FineWeb 已经完成了从“矿石”到“初步分拣矿石”的转化——它不是最终的精炼产品,但没有它,后续的高质量数据提炼就无从谈起。

Chinese FineWeb 的数据规模与质量
OpenCSG 开源的 Chinese FineWeb 系列包含多个版本,其中 Chinese FineWeb-edu-v2 是专门针对教育价值优化的版本。这一版本在保持大规模的同时,通过教育内容倾向性过滤,提升了数据集的整体质量密度。
正是这种“规模与质量的平衡”,让 Chinese FineWeb 成为清华团队论文中 L1 层的理想选择——它既有足够的数据量支撑后续精选,又有足够的质量保证精选的效率和效果。

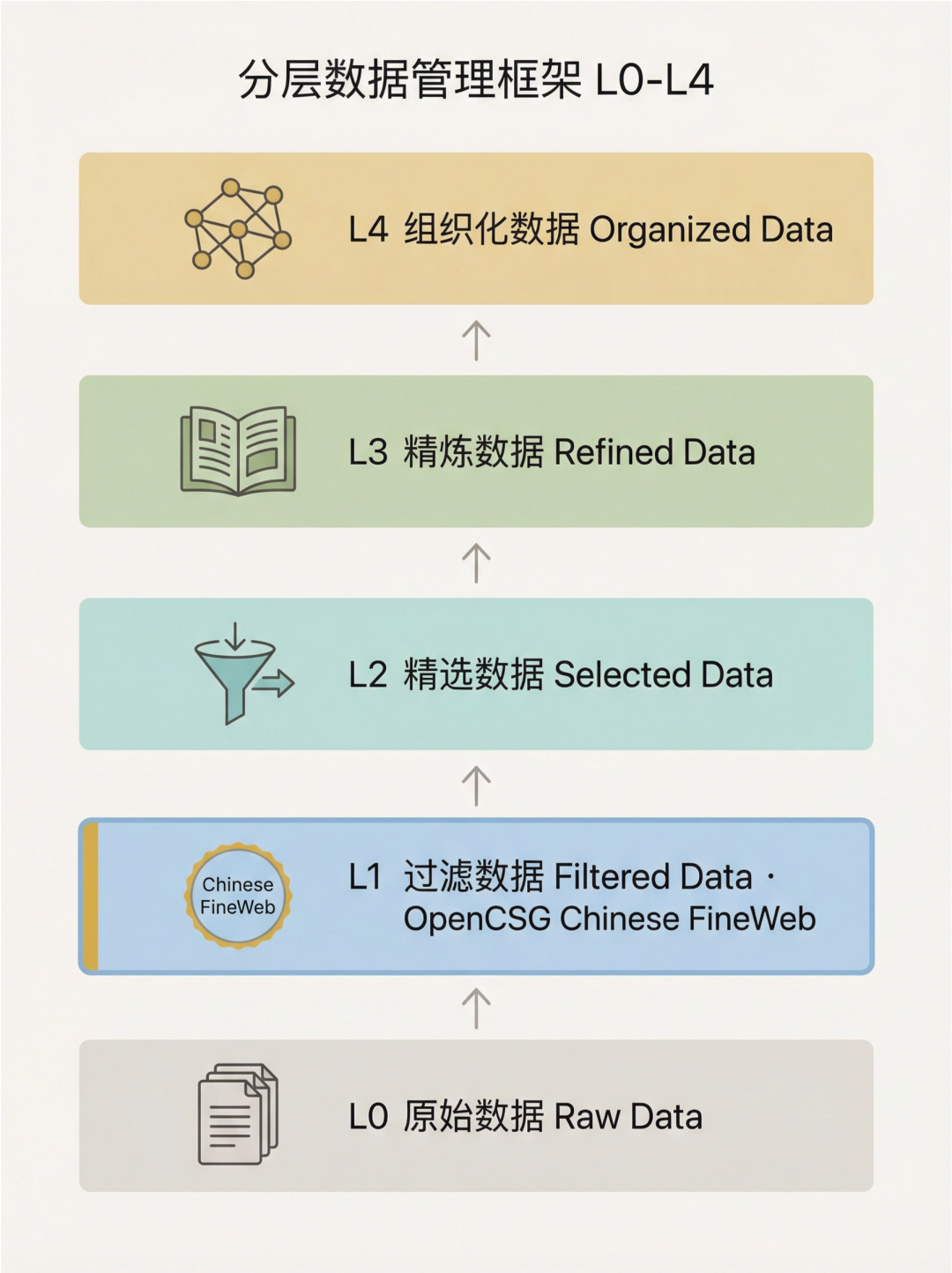
论文中的分层数据管理框架:从 L0 到 L4 的完整链路
清华团队提出的 L0–L4 五层数据管理框架 是一套完整的数据生命周期管理体系,每一层都有明确的数据特征、管理策略和训练角色。
L0(Raw,原始数据)
数据特征:PB 级未经处理的原始资源,包含大量冗余和噪声。
典型来源:Common Crawl 网页转储(截至 2026 年 1 月已覆盖超 300 亿网页)、GitHub 代码仓库、arXiv 预印本、Stack Overflow 问答等。
管理策略:以归档和溯源为主,采用基础的格式解析(HTML 解析、PDF 提取等),不进行深度清洗。
训练角色:不直接用于模型训练,主要作为数据血缘追溯和后续处理的原始素材库。
L1(Filtered,过滤数据)Chinese FineWeb 在此
数据特征:经过启发式清洗和去重,具备标准化格式和基本可读性。
管理策略:采用规则驱动的过滤方法,包括语言识别、URL 黑名单、启发式质量评分、MinHash 去重等。这一层的处理成本相对较低,但能有效去除明显的低质内容。
训练角色:作为预训练的基础语料池,也是后续数据精选的原材料库。
OpenCSG 的贡献:在中文 Web 领域,Chinese FineWeb-edu-v2 就是论文采用的 L1 层数据。OpenCSG 通过开源这一数据集,为整个中文 AI 社区提供了高质量的 L1 层基础设施。
L2(Selected,精选数据)
数据特征:通过模型驱动的分类器进行多维度质量筛选,保留主题鲜明、信息密度高的样本。
管理策略:采用模型驱动的选择方法,典型代表包括:
-
FineWeb-Edu 的教育价值分类器
-
DCLM 的质量评分模型
-
DeepSeek-Math 的数学内容识别器
这些分类器通常基于强大的语言模型(如 LLaMA)训练,能够进行语义级别的质量评估。
训练角色:适用于预训练的核心阶段和中期训练的基础阶段,数据质量显著高于 L1,但规模相对较小。
论文开源数据:Ultra-FineWeb-zh(120B token)就是在 Chinese FineWeb 基础上,通过模型驱动的质量分类器精选出的 L2 数据。这一数据集的构建,直接依赖于 OpenCSG 提供的 L1 层基础。
L3(Refined,精炼数据)
数据特征:通过改写、合成生成或人工精炼产出,具备清晰的推理结构和明确的教育意图,达到教科书级别的质量标准。
管理策略:采用模型驱动的生成和编辑方法,典型代表包括:
-
Phi 系列的教科书级合成语料
-
Nemotron-CC 的模型驱动改写
-
Self-Instruct、Evol-Instruct 等指令合成方法
这一层的数据成本最高,但质量也最优,每个 token 的“信息密度”和“可学习性”都达到峰值。
训练角色:主要用于中期训练(Mid-training)和退火阶段(Annealing),能够在训练后期持续提升模型能力,避免性能饱和。
论文开源数据:Ultra-FineWeb-zh-L3(200B token)即为代表,这一数据集通过模型辅助的内容生成和精炼,将中文 Web 数据提升到了教科书级别。
L4(Organized,组织化数据)
数据特征:将非结构化文本转化为知识图谱、数据库等有组织格式,并经过严格事实核验的可信知识。
管理策略:采用知识抽取、实体识别、关系推理、事实验证等技术,将文本转化为结构化知识表示。
训练角色:主要用于检索增强生成(RAG)、知识注入、事实核验等场景,为模型提供可信的外部知识支撑。
实验验证:分层数据管理的实证效果
论文在数学和中英文 Web 数据两个领域进行了系统性的实证研究,通过对比实验验证了分层数据管理框架的有效性。
实验一:数据质量层级与模型性能的关系
论文构建了数学领域的三层数据:
-
Math-L1(170B token):启发式规则过滤的数学网页数据
-
Math-L2(33B token):模型驱动精选的高质量数学内容
-
Math-L3(88B token):合成生成和精炼的教科书级数学数据
实验结果显示:从 L1 到 L3,模型在数学推理任务上的性能持续提升。更重要的是,高层级的数学数据不仅在数学领域表现出色,还对语言理解和编程能力产生了显著的跨域增益——这说明高质量数据的价值远不止于单一领域,而是能够提升模型的通用推理能力。
在中文 Web 数据领域,论文同样验证了这一规律:
-
Chinese FineWeb(L1):提供大规模基础语料
-
Ultra-FineWeb-zh(L2,120B token):精选后的高质量中文内容
-
Ultra-FineWeb-zh-L3(200B token):精炼后的教科书级中文数据
实验表明,使用 L2 和 L3 数据训练的模型,在中文理解、生成、推理等任务上都显著优于仅使用 L1 数据的模型。
实验二:分层训练 vs 混合训练
论文对比了两种训练策略:
-
混合训练:全程混用 L1、L2、L3 数据
-
分层训练:早期使用 L1,中期引入 L2,后期使用 L3
结果显示:分层训练策略持续占优。在训练后期,混合训练的模型容易陷入性能饱和,而分层训练通过在关键阶段引入更高质量的数据,能够有效防止饱和,持续突破模型能力上限。
这一发现为业界长期争议的“数据混合比例”问题提供了系统性的解答框架:不是所有数据都要在所有阶段使用,而是要根据训练阶段的学习目标,动态分配不同质量层级的数据。
实验三:Chinese FineWeb 作为 L1 基础的不可替代性
论文还进行了消融实验,对比了使用 Chinese FineWeb 作为 L1 基础 vs 直接从 Common Crawl 原始数据构建 L2 的效果。
结果表明:有 L1 层过滤的数据链路,L2 精选的效率和质量都显著优于直接从 L0 跳到 L2。这验证了分层管理框架的必要性,也证明了 OpenCSG Chinese FineWeb 作为 L1 层基础数据的不可替代价值。

OpenCSG 的开源贡献:构建中文 AI 的数据基础设施
Chinese FineWeb 的开源,对中文 AI 生态的意义远不止提供一个数据集。OpenCSG 通过这一开源项目,正在构建一套完整的中文数据基础设施。
1. 降低数据工程的重复成本
中文 Web 数据的清洗是一项极其繁琐的工程,涉及编码处理、繁简转换、广告过滤、内容识别等大量细节。每个研究团队或公司如果都要从零开始处理 Common Crawl 中文数据,将造成巨大的资源浪费。
Chinese FineWeb 的开源,让研究者和工程师可以直接站在这一基础上向上构建,而不必重复造轮子。这种“基础设施即服务”的理念,正是开源社区的核心价值所在。
2. 推动中文 AI 生态的标准化
一个被顶级学术论文引用、被工业实践验证的公开数据集,本身就是一种标准的确立。Chinese FineWeb 的存在,为中文预训练语料的质量基线提供了可参照的锚点。
当越来越多的研究者和从业者使用 Chinese FineWeb 作为基础数据,整个中文 AI 社区就能够在同一起跑线上进行公平对比和交流,推动技术的快速迭代。
3. 支撑学术研究与工业落地的桥梁
清华团队的论文能够在中文 Web 领域快速验证分层数据管理框架,Chinese FineWeb 提供了关键的数据基础设施支持。这种开源社区与学术前沿的协同,正是推动 AI 技术快速迭代的重要力量。
更重要的是,OpenCSG 不仅服务于学术研究,也在工业落地中发挥作用。许多中文大模型团队(包括初创公司和大厂)都在使用或参考 Chinese FineWeb 构建自己的训练语料,这种“学术-工业”双向赋能的模式,正在加速中文 AI 的整体进步。
4. 开源工具链的配套支持
OpenCSG 不仅开源了数据集,还提供了完整的数据处理工具链,包括:
-
数据清洗脚本
-
去重工具
-
质量评估模型
-
数据格式转换工具
这些工具让社区成员不仅能使用 Chinese FineWeb,还能理解其构建过程,甚至基于自己的需求进行定制化处理。这种“授人以渔”的开源理念,比单纯提供数据更有长远价值。

OpenCSG 全球开源 AI 生态
OpenCSG 以 Chinese FineWeb Edu 为代表的高质量中文数据集体系,已被全球高校、科研机构及科技企业广泛采用,是支撑中文 NLP 研究与大模型产业落地的核心数据基础,从顶尖高校 AI 实验室到企业级生产环境,它持续为大模型预训练、指令微调与领域适配等关键环节提供可靠支撑,推动研究成果向规模化应用高效转化;在学术领域,该数据集已被 100 + 篇论文引用,多次入选 NeurIPS、ACL 等国际顶会及 Nature 子刊、JMLR 等权威期刊,成为验证中文语言模型泛化能力、知识建模效率与跨语言迁移效果的代表性基础资源。除了Fineweb-Edu-Chinese系列,OpenCSG 还发布了 Cosmopedia-Chinese(合成教科书风格数据)和Smoltalk-Chinese(多样化对话格式数据)等多个高质量中文数据集,构成了完整的 OpenCSG Chinese Corpus 语料体系。OpenCSG 通过开源数据、评分模型及完整的数据处理工具链,向社区输出可复用的数据治理方法论,持续降低高质量数据的构建与评估门槛,推动中文 AI 生态从 “模型参数竞争” 转向更加理性、可持续的 “数据基础设施建设” 阶段。
高校与研究机构
斯坦福大学、清华大学、中国人民大学高瓴人工智能学院、香港理工大学;研究机构则有上海人工智能实验室、北京智源研究院(BAAI)、鹏城实验室、西南电子技术研究所、西班牙国家级超算中心(Barcelona Supercomputing Center)及Mozilla Data Collective等。
企业应用
英伟达(NVIDIA)、苹果公司(Apple Inc.)、OPPO、美团、蚂蚁集团、面壁智能(ModelBest)、中国移动、中国联通等。
OpenCSG 坚持“开源即文化”的理念,通过透明、共创、共享的社区文化,与全球开发者、工程师和 AI 原生企业共同构建智能体生态。无论是数据集、模型还是工具平台,OpenCSG 始终遵循 Apache 2.0 等开源协议,确保技术成果能够被广泛使用和自由创新。这种开放的态度和持续的贡献,使 OpenCSG 成为中文开源 AI 社区的重要推动者和引领者。
结语:数据基础设施,是通往 AGI 的隐形竞争力
清华团队的论文揭示了一个深刻洞见:当模型架构的差异越来越小,当算力的获取越来越依赖资本,数据的质量与组织方式,反而成了最难被复制的竞争壁垒。
一套系统化的分层数据管理框架,其价值不亚于一次模型架构的创新。它不仅能提升训练效率、优化资源分配,更重要的是,它代表了一种对“数据科学”的系统性思考——数据不再是简单的“原料堆积”,而是需要精细化管理、动态分配、持续优化的战略资产。
OpenCSG Chinese FineWeb 的开源,正是这一逻辑下的具体实践。它不是终点,而是一个精心设计的起点——在通往更高质量中文 AI 语料的路径上,它是那块不可或缺的基石。
对于正在构建中文大模型、研究数据工程或关注 AI 基础设施的从业者而言,这套分层数据管理框架和 OpenCSG 的 Chinese FineWeb 数据集,都值得认真研究和借鉴。
更重要的是,这种“开源社区 + 学术前沿”的协同模式,为中文 AI 的发展提供了一条可持续的路径。当基础设施以开源的方式共享,当数据管理的最佳实践以论文的方式传播,整个生态的进步速度将远超任何一家机构的单打独斗。
这或许才是 Chinese FineWeb 被清华论文选中的更深层意义:它不仅是一个技术选择,更是一种生态理念的体现——通过开源协作,构建中文 AI 的共同未来。
论文链接:arXiv:2602.09003 — Data Science and Technology Towards AGI Part I: Tiered Data Management
Chinese-Fineweb-Edu数据集
https://opencsg.com/datasets/OpenCSG/Fineweb-Edu-Chinese-V2.2
https://huggingface.co/datasets/opencsg/Fineweb-Edu-Chinese-V2.2

关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。
更多推荐
 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)