
突破渲染极限:微多边形时代的软硬协同光栅化架构
《软硬协同渲染机制突破微多边形渲染瓶颈》摘要:本文揭示了传统GPU硬件光栅化在处理微多边形(投影面积<1像素)时存在的Quad Overdraw性能陷阱(75%算力浪费),并提出革命性的软硬协同渲染解决方案。该方案通过计算着色器实现软件光栅化,结合Visibility Buffer架构,实现像素级精准写入;同时采用动态路由机制,根据三角形屏幕面积智能分配渲染路径(大三角形走硬件光栅化,微多边
在实时渲染领域,我们正见证着一场从几何细节到影视级资产(如 Unreal Engine 5 的 Nanite 网格)的革命。随之而来的,是屏幕空间中投影面积接近甚至小于 1 像素的微多边形(Micro-polygons)。然而,这些微小的三角形却给传统的 GPU 硬件光栅化管线带来了致命的性能陷阱。
为了彻底突破这一技术天花板,业界引入了一种革命性的架构:软硬协同渲染机制(Soft-Hard Collaborative Rendering)。它不是简单地用软件替代硬件,而是将两者完美融合,建立一个“软件定义、硬件加速”的智能混合管线。
硬件光栅化的致命软肋:Quad Overdraw 与性能塌陷
GPU 的硬件光栅化器(Hardware Rasterizer)是过去三十年实时图形学的基石,它对处理覆盖多个像素的三角形拥有惊人的效率。但它的设计之初有一个核心假设,即三角形具有可观的屏幕覆盖率。当面对微多边形时,这一假设被彻底打破,暴露出其固定管线的内在缺陷。
微多边形的定义
从图形学角度看,当三角形在屏幕空间的投影面积 A<1 像素时,我们称之为微多边形。
2×2 Quad 像素四边形导致的过度绘制 (Quad Overdraw)
这是硬件光栅化器处理微多边形时的核心瓶颈。
为了计算纹理 Mipmap 采样所需的屏幕空间导数(Derivatives,即 ∂x∂u and ∂y∂v),GPU 硬件光栅化器总是以 **2×2 的像素块(Quad)**为最小调度单元。这意味着,即使一个微小三角形只覆盖了 Quad 中的 1 个像素,GPU 依然会唤醒 4 个像素线程进行着色。
公式 (1):量化 Quad 过度绘制开销 (Quad Overdraw Factor)
我们可以定义 Quad 过度绘制因子 Q 为:
Q=Effective Screen Pixels Shaded∑(Rasterized Quads×4)
当处理密集的微多边形网格时,大部分 Quads 中只有 1 个有效像素,导致 Q≈4,这意味着 ALU 利用率直线下降,高达 75% 的着色算力被浪费在丢弃的像素上。
如下面的对比图所示:
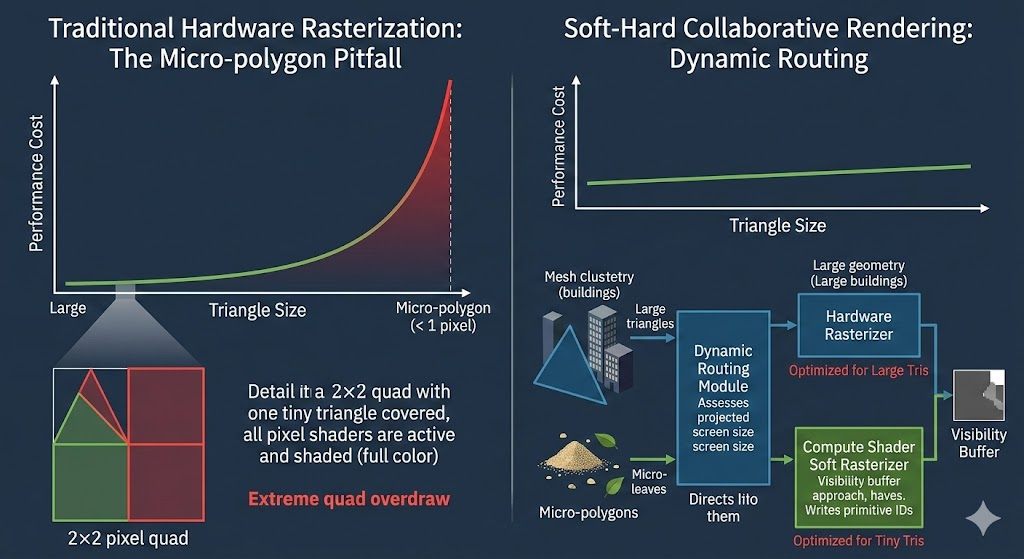
左图:传统硬件光栅化的微多边形陷阱。 随着三角形变小,性能开销急剧指数级上升(红色曲线)。插图清晰地展示了一个 2×2 Quad,中间只有一个极小的三角形,但四个像素都被激活并着色(Full color),从而导致极高的 Quad Overdraw。
此外,极小的三角形还会导致光栅化器的三角形装配和剔除阶段(Setup & Culling Rate)成为整个 GPU 前端的严重带宽瓶颈。
破局之刃:基于计算着色器的软件光栅化
面对硬件固定逻辑的缺陷,基于计算着色器(Compute Shader)的纯软件光栅化成为了破局的关键。软光栅不再依赖专用光栅化硬件,而是利用 GPU 的通用计算能力解决问题。
软光栅的核心优势:
-
消灭 Quad Overdraw: 软光栅可以绕过 Quad 的死板规则。它通过原子操作(如
InterlockedMin)将深度值和图元 ID(Primitive ID)直接写入缓冲。 -
像素级精准写入: 对于小于 1 像素的三角形,一个计算线程就能完成其归属判断和写入,没有任何冗余的像素着色。
-
细粒度剔除: 软光栅可以在 Compute Shader 中完成更细致的三角形/像素级遮挡剔除(Occlusion Culling)和背面剔除(Backface Culling)。
软光栅的核心架构:Visibility Buffer (V-Buffer)
软件光栅化通常与 Visibility Buffer 架构结合使用。其核心思想是:先计算可见性,再进行着色。 软光栅输出一个 V-Buffer,它存储每个像素对应的 对。随后,只需遍历 V-Buffer,根据图元 ID 去提取材质数据并进行一次着色。这彻底将几何复杂度与着色复杂度解耦。
纯软件光栅化也不是银弹。当处理占据屏幕大片区域的大型三角形时,Compute Shader 的原子操作冲突(Atomic Contentions)会急剧增加,此时其效率远不如硬件光栅化器。
黄金分割:软硬协同渲染机制
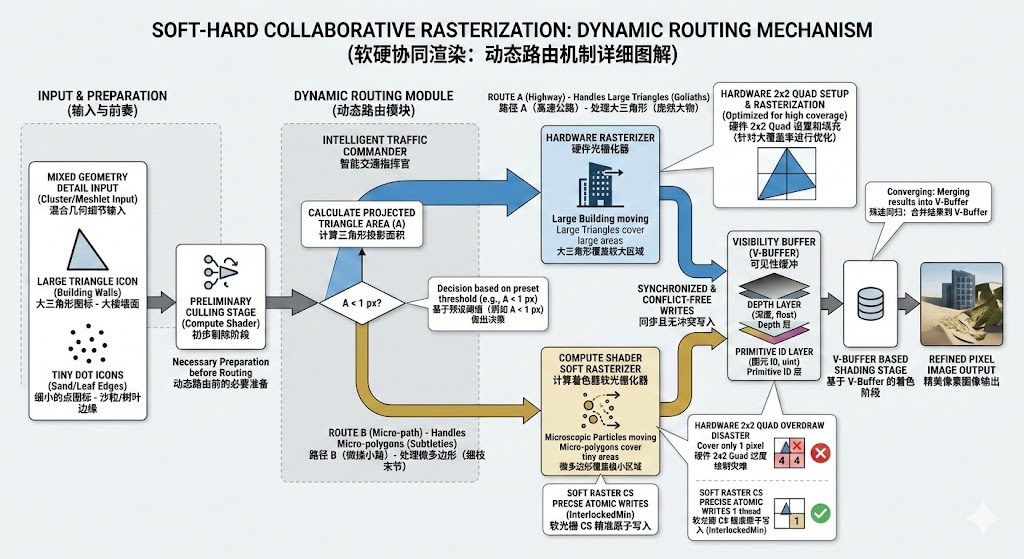
既然硬件和软件光栅化各有所长,软硬协同机制(如 UE5 Nanite 背后的核心思想)便应运而生。这种机制本质上是一个智能的动态路由系统,它在运行时动态评估几何体的特性,将其分配到最适合的路径。
右图:软硬协同渲染机制。 性能曲线(蓝色)非常平滑且接近线性。协同管线(Mixed Scene)通过“动态路由模块”评估投影面积,将大三角形(大楼)引向专用“硬件光栅化器”,将微多边形(沙子、叶片)引向基于 Visibility Buffer 的“计算着色器软光栅化器”,两者最终同步输出到一个统一的 V-Buffer。
动态分流管线的核心步骤
协同管线的关键在于在几何阶段进行细粒度的分类与分流:
-
集群划分 (Cluster Setup): 离线或在运行时将网格划分为包含少量三角形(例如 128 个)的集群(Clusters/Meshlets)。
-
屏幕空间面积评估 (Screen Area Evaluation): 在 Compute Shader 中计算每个三角形投影到屏幕上的近似面积。
公式 (2):三角形屏幕空间面积计算
给定一个三角形的三个顶点投影坐标 ,其屏幕空间面积 A 为:
在实际应用中,为了追求极致效率,通常使用其包围盒(Bounding Box)的面积来近似。
-
动态路由 (Dynamic Dispatch):
-
硬件队列 (Hardware Queue): 如果 A≥Athreshold(例如,平均面积 ≥4 像素),将 Cluster 数据输出到 DispatchIndirectBuffer,走硬件渲染队列。
-
软件队列 (Software Queue): 如果 A<Athreshold(微多边形),直接在当前 Compute Shader 中启动软光栅路径。
-
计算着色器协同路径实现 (伪代码核心)
以下是一个简化版的 Compute Shader 关键核心,展示了分流逻辑和软件路径的原子操作写入 V-Buffer。
// Compute Shader for Soft-Hard Rasterization
// Group size for efficient parallel processing of vertices or clusters
[numthreads(128, 1, 1)]
void CSSoftHardRasterization(uint3 dtID : SV_DispatchThreadID)
{
// 1. Get Cluster and perform standard culling (Frustum, Backface, Occlusion)
// ... Culling Logic ...
if (IsCulled()) return;
// 2. Access Triangle indices and vertices for the cluster
// ... Fetch Data ...
// 3. Project vertices to screen space
float2 p0 = ProjectToScreen(v0);
float2 p1 = ProjectToScreen(v1);
float2 p2 = ProjectToScreen(v2);
// 4. Evaluate screen-space area (or simplified Bounding Box area)
float area = CalculateTriangleScreenArea(p0, p1, p2);
// Dynamic Routing Threshold (e.g., area > 4 pixels for HW)
const float HW_AREA_THRESHOLD = 4.0f;
if (area >= HW_AREA_THRESHOLD)
{
// --- HARDWARE ROUTE ---
// Atomically increment visible cluster count and write to Indirect Buffer
// The subsequent Indirect Draw call will handle large triangles
WriteToHardwareIndirectBuffer(clusterID);
}
else
{
// --- SOFTWARE ROUTE ---
// Process each pixel covered by the micro-triangle within this thread
// or a small subgroup of threads.
// Get bounding box in pixels
int2 minP = floor(min(p0, min(p1, p2)));
int2 maxP = ceil(max(p0, max(p1, p2)));
// Rasterization loop (pixel-level granular culling, no quad restrictions)
for (int y = minP.y; y <= maxP.y; ++y)
{
for (int x = minP.x; x <= maxP.x; ++x)
{
float2 pixelPos = float2(x + 0.5f, y + 0.5f);
float3 bary = CalculateBarycentric(pixelPos, p0, p1, p2);
// Precise pixel-level barycentric culling
if (bary.x >= 0.0f && bary.y >= 0.0f && bary.z >= 0.0f)
{
// Compute depth for this pixel
float depth = InterpolateDepth(bary, v0_depth, v1_depth, v2_depth);
// Unified Visibility Buffer (V-Buffer): Pack (Depth, PrimitiveID)
uint depthUint = asuint(depth);
// Use Atomic InterlockedMin for race-free depth testing and writing ID
// This packs Depth and PrimitiveID into a 64-bit value to update atomically
InterlockedMin(VisibilityBuffer_Depth_PrimID[uint2(x, y)], Pack(depthUint, primitiveID));
}
}
}
}
}
总结与展望
软硬协同光栅化机制是图形学向极限挑战的里程碑。它打破了“固定管线至上”或“全软件化”的思维定势,彻底解决了微多边形带来的 Quad Overdraw 灾难,让影视级的亿万多边形资产真正在实时引擎中达到了 60 帧以上的流畅体验。
这种机制的优势总结如下:
| 评估维度 | 硬件光栅化 (固定管线) | 协同渲染机制 (Soft-Hard) | 解决的痛点 |
| 微多边形 (A<1) | 性能塌陷 (Q factor ≈4) | 极佳 (路由至软光栅) | 消除 Quad Overdraw 浪费 |
| 大三角形 (A>4) | 极佳 (专用硬件高效填充) | 极佳 (路由至硬光栅) | 维持专用硬件效率 |
| 带宽瓶颈 | Setup Rate 严重受限 | 按需分配,大幅降低吞吐开销 | 优化 GPU 前端吞吐量 |
| 剔除粒度 | 实例级/粗糙集群级 | 像素级/三角形级 | 极大提高有效三角形比例 |
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)