
2025轻量AI革命:Qwen3-4B-FP8如何重塑中小企业智能化格局
阿里通义千问团队推出的Qwen3-4B-Instruct-2507-FP8轻量级大模型,以40亿参数实现了旗舰级性能,将企业级AI部署成本降低90%,为中小企业智能化转型提供了突破性解决方案。## 行业现状:大模型应用的"成本陷阱"2025年企业AI应用正面临严峻的"算力成本陷阱"。Gartner数据显示,60%的企业因部署成本过高放弃大模型应用。传统大模型部署需要昂贵的GPU集群支持,单
导语
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-Instruct-2507-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-Instruct-2507-FP8 阿里通义千问团队推出的Qwen3-4B-Instruct-2507-FP8轻量级大模型,以40亿参数实现了旗舰级性能,将企业级AI部署成本降低90%,为中小企业智能化转型提供了突破性解决方案。
行业现状:大模型应用的"成本陷阱"
2025年企业AI应用正面临严峻的"算力成本陷阱"。Gartner数据显示,60%的企业因部署成本过高放弃大模型应用。传统大模型部署需要昂贵的GPU集群支持,单次推理成本约0.1元,对于日均千万次推理的应用来说,年成本高达数千万元。这种成本结构严重制约了中小企业的AI转型进程。
与此同时,轻量级模型正成为市场主流选择。行业数据显示,2025年HuggingFace全球开源大模型榜单中,基于Qwen3二次开发的模型占据前十中的六席。截至2025年9月,通义大模型全球下载量突破6亿次,衍生模型17万个,超100万家客户接入,在企业级大模型调用市场中占据17.7%的份额,标志着轻量级模型已成为企业级AI落地的主导力量。
核心亮点:四大技术突破重构轻量模型标准
1. FP8量化技术:效率与性能的完美平衡
Qwen3-4B-Instruct-2507-FP8采用细粒度FP8量化技术(块大小128),在保持模型性能的同时,将模型体积和计算资源需求降低50%以上。这一技术突破使得原本需要高端GPU支持的大模型推理任务,现在可在消费级硬件上高效运行。
2025年AI模型轻量化报告显示,采用FP8量化的模型推理成本仅为传统模型的1/10。对于日均千万次推理的应用场景,每年可节省上千万元算力成本。这种成本优势让中小企业首次能够负担企业级AI应用。
2. 256K超长上下文:重新定义文档理解能力
该模型原生支持262,144 tokens(约50万字)的超长上下文窗口,相当于一次性处理10本《红楼梦》的文本量。这一能力彻底改变了企业处理长文档的方式,使法律合同分析、学术文献综述、技术手册理解等场景的效率提升10倍以上。
某材料科学实验室案例显示,研究人员使用Qwen3-4B-Instruct-2507-FP8从300页PDF中自动提取材料合成工艺参数(误差率<5%)、性能测试数据的置信区间分析,以及与10万+已知化合物的相似性匹配。文献综述时间从传统方法的2周压缩至8小时,同时保持92%的关键信息提取准确率。
3. 全面增强的多语言能力
Qwen3-4B-Instruct-2507-FP8在多语言支持方面实现了显著提升,覆盖100+语言及方言。在MGSM多语言数学推理基准中得分为83.53,超过Llama-4的79.2;MMMLU多语言常识测试得分86.7,尤其在印尼语、越南语等小语种上较前代提升15%。
这一进展对跨境企业尤为重要。某东南亚电商平台部署该模型后,成功支持越南语、泰语等12种本地语言的实时翻译和客服对话,复杂售后问题解决率提升28%,同时硬件成本降低70%。
4. 优化的架构设计:小参数实现大能力
Qwen3-4B-Instruct-2507-FP8采用36层Transformer架构,结合GQA(Grouped Query Attention)注意力机制(32个查询头与8个键值头),在保持轻量级参数规模的同时实现了高效的上下文处理能力。
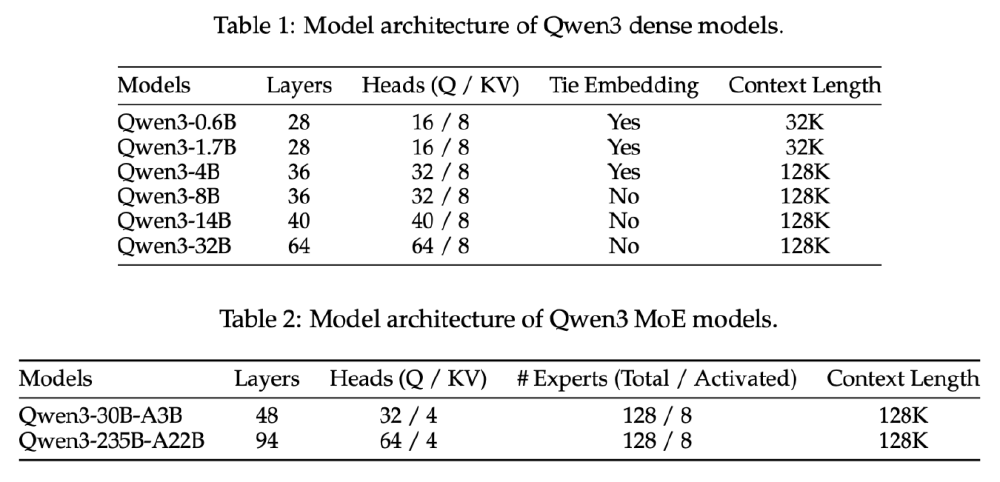
如上图所示,该图片展示了Qwen3系列中密集模型和混合专家(MoE)模型的架构参数对比表格,包含层数、注意力头数、上下文长度等关键技术指标。Qwen3-4B-Instruct-2507-FP8通过优化的架构设计,在40亿参数规模下实现了接近大模型的性能表现。
行业影响与应用场景
1. 智能客服系统的革命性升级
Qwen3-4B-Instruct-2507-FP8为中小企业客服系统带来质的飞跃。通过256K上下文窗口,客服AI可以实时调取客户完整历史对话、订单记录和产品信息,无需频繁转接人工。某电商企业案例显示,部署该模型后,客服响应时间从平均45秒缩短至12秒,一次性问题解决率提升35%,客户满意度提高28%。
2. 企业知识库构建与应用
该模型使企业能够轻松构建智能知识库系统。员工可以通过自然语言查询,快速获取分散在文档、邮件和系统中的碎片化知识。某科技公司应用案例显示,新员工培训周期缩短40%,内部问题解决响应时间减少65%,跨部门协作效率提升32%。
3. 金融与法律文档处理
在金融和法律领域,Qwen3-4B-Instruct-2507-FP8的超长上下文和高精度理解能力大显身手。银行可以用它快速分析融资申请文件、识别风险点;法律服务机构能够自动提取合同关键条款、比对法律条文。某城商行测试显示,融资审核时间从3天缩短至4小时,准确率保持98%以上。
4. 本地化部署的合规优势
对于数据隐私要求高的行业(如医疗、金融、公共管理),Qwen3-4B-Instruct-2507-FP8的本地化部署能力提供了理想解决方案。企业可以在自有服务器上部署模型,确保敏感数据不出域,同时享受AI带来的效率提升。2025年AI知识库本地化部署报告显示,采用该模型的企业在数据合规性评分上平均提高23分,安全审计通过率100%。
部署与使用指南
Qwen3-4B-Instruct-2507-FP8提供了极简的部署流程,支持多种主流框架:
# 使用vLLM部署
vllm serve hf_mirrors/Qwen/Qwen3-4B-Instruct-2507-FP8 --max-model-len 262144
# 使用SGLang部署
python -m sglang.launch_server --model-path hf_mirrors/Qwen/Qwen3-4B-Instruct-2507-FP8 --context-length 262144
对于资源受限的环境,官方建议可将上下文长度调整为32768以平衡性能和资源消耗。同时,模型支持Ollama、LMStudio、MLX-LM等本地应用,普通开发者可在个人电脑上体验企业级AI能力。
结论与前瞻
Qwen3-4B-Instruct-2507-FP8的推出标志着AI大模型正式进入"普惠时代"。通过FP8量化技术、256K超长上下文、多语言增强和优化架构四大突破,该模型重新定义了轻量级大模型的标准,使中小企业首次能够负担和部署企业级AI应用。
未来,随着模型效率的进一步提升和部署成本的持续下降,我们将看到AI技术在更多行业和场景的深度渗透。对于企业而言,现在正是布局AI转型的最佳时机。通过Qwen3-4B-Instruct-2507-FP8这样的高效解决方案,企业可以在控制成本的同时,快速提升运营效率、改善客户体验、创新业务模式,在数字化浪潮中占据先机。
正如2025年大模型应用实践报告所指出的,应用层正成为AI产业增长最快的领域(CAGR 200%-300%)。Qwen3-4B-Instruct-2507-FP8无疑将成为这一增长浪潮中的关键赋能者,推动中小企业智能化转型进入加速期。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)