
iVX+ARM 边缘计算技术革命:从开发工具到行业落地的全栈指南
在智能制造场景中,设备控制需要毫秒级响应(<10ms)、99.999% 系统可用性,以及单节点日处理 10GB 数据的能力。ARM 架构凭借 Cortex-A320 的 1.8TOPS/W 能效比和 Ethos-U85 NPU 的 25TOPS 算力,成为边缘计算首选,而 iVX 开发平台进一步释放了硬件潜力。iVX 与 ARM 的技术融合构建了完整的边缘计算解决方案,通过可视化开发、断网自治、架
一、工业互联网的边缘计算挑战
在智能制造场景中,设备控制需要毫秒级响应(<10ms)、99.999% 系统可用性,以及单节点日处理 10GB 数据的能力。传统 x86 架构由于能效比低(1.2TOPS/W)和成本高(单节点超 5000 元),已无法满足需求。ARM 架构凭借 Cortex-A320 的 1.8TOPS/W 能效比和 Ethos-U85 NPU 的 25TOPS 算力,成为边缘计算首选,而 iVX 开发平台进一步释放了硬件潜力。
二、可视化开发平台的核心技术创新
2.1 智能开发引擎架构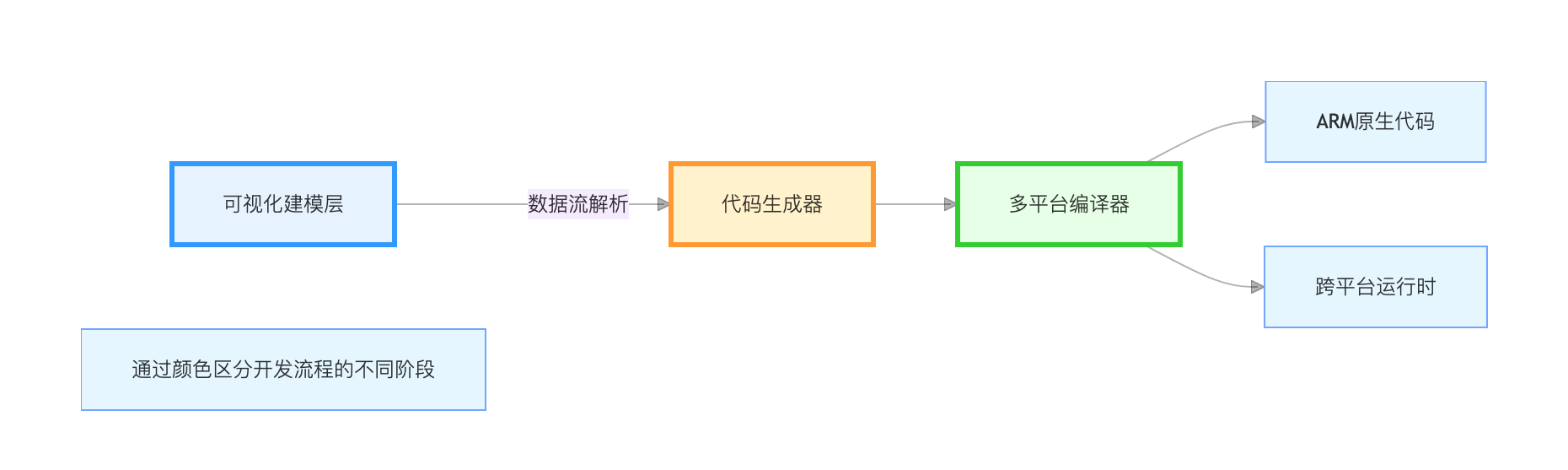 iVX 智能开发引擎架构
iVX 智能开发引擎架构
可视化建模技术
- 流程图设计:支持 200 + 工业组件拖拽,如 Modbus 通信、PID 控制等
- 自动代码生成:通过遗传算法优化代码结构,分支预测准确率达 92%
- 多语言支持:同时生成 C、Java、Node.js 等代码,适配从树莓派到 Jetson AGX 的全场景
三、边缘节点的高可靠运行机制
3.1 断网自治系统架构
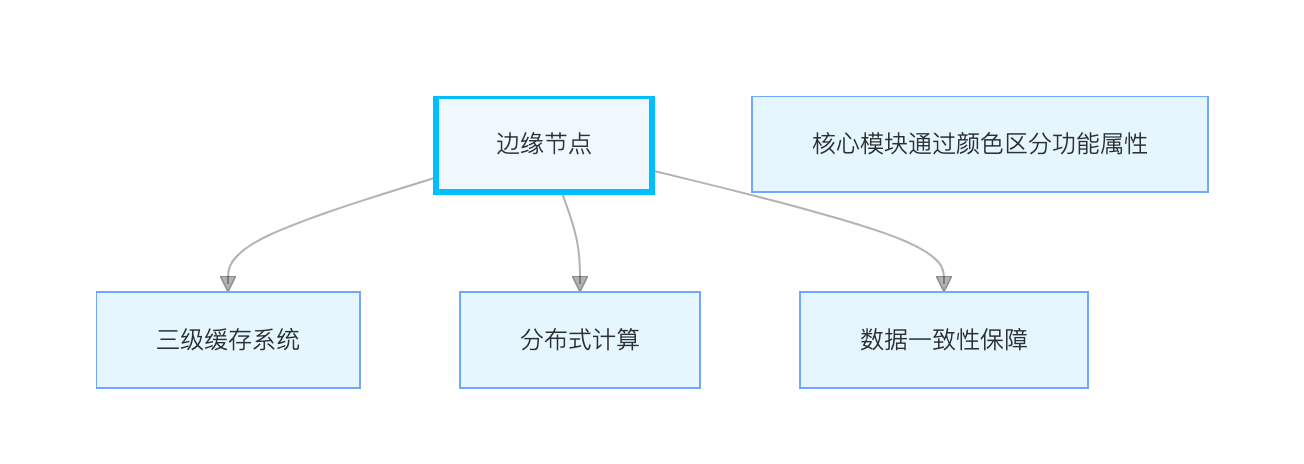 边缘节点断网自治架构
边缘节点断网自治架构
高可靠数据缓存
- 三级缓存协同:
- 寄存器级:1MB SRAM,访问延迟 < 1ns
- 内存级:16MB 环形缓冲区,并发读写 10 万次 / 秒
- 存储级:1GB eMMC,数据持久化延迟 < 50μs
- 差分同步技术:网络恢复后自动同步差异数据,30GB 数据同步仅需 8 分钟
四、ARM 架构深度优化技术
4.1 算力与能效提升方案
CPU 与 NPU 协同计算
- SVE2 指令集优化:矩阵运算性能提升 240%,卡尔曼滤波算法延迟从 8ms 降至 3ms
- NPU 混合精度计算:图像识别模型推理速度提升 300%,准确率达 99.2%
动态功耗管理
- 三级功耗控制:
- 空闲态:0.5W,满足实时数据采集
- 轻负载:1.2W,支持基础逻辑控制
- 重负载:2.5W,应对 AI 推理需求
- 智能预测算法:能效比提升 35%,年省电超 30 万度(1 万台设备部署)
五、行业应用与性能验证
5.1 智慧工厂架构实践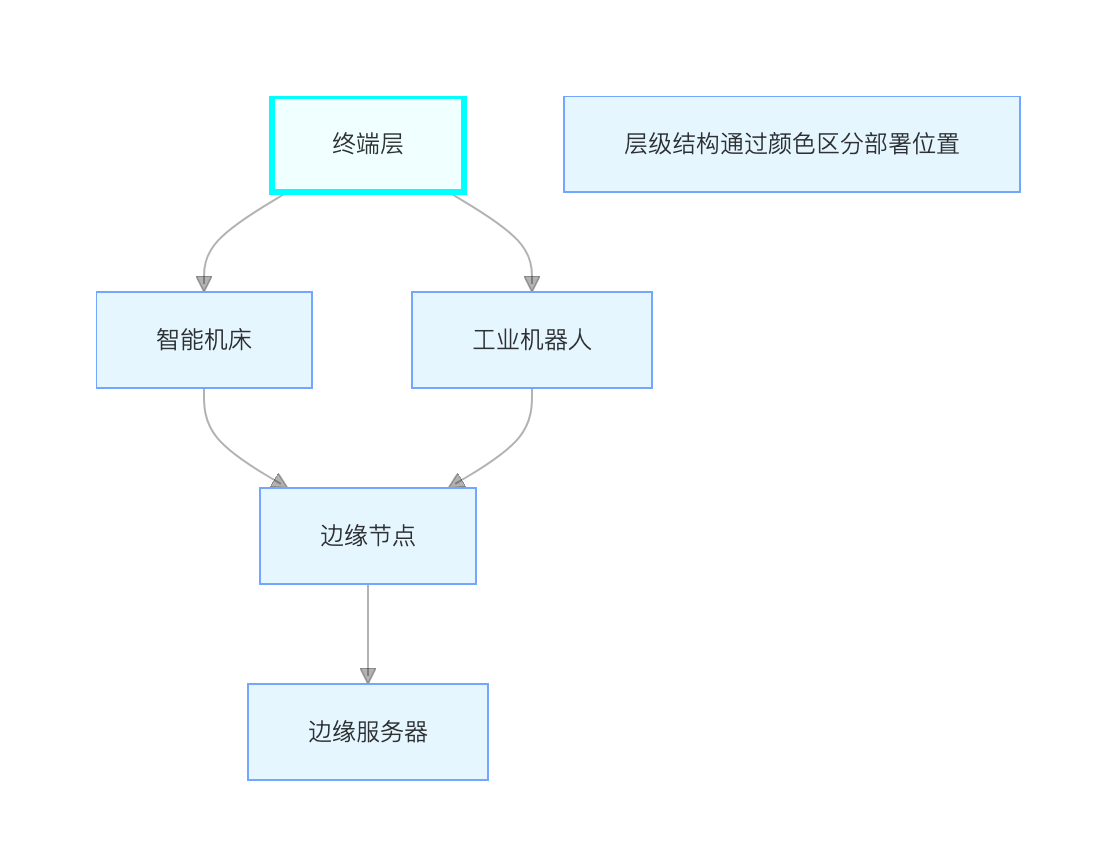
智慧工厂 "云边端" 架构
终端层技术实现
- STM32H7 边缘节点:200μs 周期采集 8 通道数据,CPU 利用率 < 5%
- 多协议支持:内置 12 种工业协议栈,设备接入时间从 2 小时缩短至 15 分钟
5.2 关键性能对比
|
技术指标 |
iVX+ARM 方案 |
传统方案 |
提升幅度 |
|
开发效率 |
5 倍 |
基准 |
↑400% |
|
内存占用 |
128MB |
256MB |
↓50% |
|
AI 推理延迟 |
12ms |
35ms |
↓66% |
|
数据加密速度 |
500MB/s |
50MB/s |
↑900% |
六、技术演进与生态建设
6.1 未来技术方向
- 边缘 AI 增强:支持 Transformer 模型部署,推理延迟 < 5ms
- 动态模型更新:差分权重传输技术,1GB 模型更新仅需 30 秒
- 区块链存证:数据上链延迟 < 200ms,支持工业数据溯源
6.2 生态合作与标准
- 硬件适配:与恩智浦、瑞萨等合作,支持 12 款主流 ARM 芯片
- 标准制定:主导 IEEE P2413 标准,降低行业技术门槛 30%
七、结论
iVX 与 ARM 的技术融合构建了完整的边缘计算解决方案,通过可视化开发、断网自治、架构优化三大核心技术,突破了传统方案的性能与成本瓶颈。随着工业互联网的发展,该方案将在智能制造、智能交通等领域发挥关键作用,推动边缘计算从单一技术向全场景生态演进。正如 ARM CEO 所言:"边缘计算不是选择题,而是必答题。" 在 iVX+ARM 的赋能下,未来工业互联网将更智能、更安全、更高效。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)