
算力直降48%:Moonlight-16B凭什么改写大模型效率规则?
当参数规模触及物理极限,Moonlight-16B证明训练效率将成为下一代AI竞争的核心战场。随着Muon优化器的持续迭代和模型压缩技术进步,我们有理由期待,未来千亿级模型的训练成本有望降低一个数量级,让AI技术真正走向普惠。对于企业而言,现在正是布局MoE技术的最佳时机。建议从三个维度着手:评估现有模型的计算效率瓶颈、构建稀疏化训练基础设施、储备Muon等新型优化器的应用经验。随着Moonl
算力直降48%:Moonlight-16B凭什么改写大模型效率规则?
【免费下载链接】Moonlight-16B-A3B  项目地址: https://ai.gitcode.com/MoonshotAI/Moonlight-16B-A3B
项目地址: https://ai.gitcode.com/MoonshotAI/Moonlight-16B-A3B
导语
Moonshot AI开源的Moonlight-16B-A3B模型,通过Muon优化器与混合专家(MoE)架构组合,实现总参数160亿仅激活30亿的效率突破,训练成本较传统模型降低近一半,重新定义大模型效率标准。
行业现状:从参数竞赛到效率突围
2025年大模型行业正经历关键转型。据市场动态显示,市场已从对"更大规模"的单一追求转向"更强能力"与"更优效益"并重。数据显示,训练一个大模型的电费成本可达数百万美元,而推理阶段硬件资源占用率常低于30%。在此背景下,Moonlight-16B-A3B模型通过5.7T训练tokens实现性能反超18T模型,为行业提供了"更少资源、更好性能"的新范式。
核心突破:三大技术革新实现效率革命
1. Muon优化器:数学原理到工程落地的跨越
Moonlight的核心竞争力源于对Muon优化器的深度改进。研究团队发现原始Muon在大模型训练中存在权重均方根(RMS)异常增长问题,通过引入动态权重衰减和更新尺度匹配技术,使模型在16B参数量级下无需超参数调优即可稳定收敛。实验数据显示,Muon优化器实现了2倍样本效率提升:在相同性能目标下,仅需AdamW 52%的训练计算量。某AI芯片厂商实测表明,使用Muon训练同等规模模型时,计算集群利用率从45%提升至78%,单任务训练时间缩短至原来的47%。
2. MoE架构:16B参数的"智能节流阀"
Moonlight-16B采用64个专家+2个共享专家的MoE设计,每个token仅激活6个专家(约9%的总参数),关键创新包括:
- 分组路由机制:将专家分为8组,每组最多激活2个,通信开销降低47%
- Scaling Factor优化:采用2.446倍缩放因子平衡专家贡献,避免"专家饥饿"问题
- 混合精度训练:结合BF16和FP32计算,在保持精度的同时减少内存占用
这种架构使16B模型的激活参数与3B密集型模型相当,在单卡A10上即可实现INT4量化部署(显存占用8.7GB),完美解决了大模型"训练贵、部署难"的行业痛点。
3. 全场景性能跃升:从代码生成到多语言理解
在标准基准测试中,Moonlight-16B展现全面优势:
| 任务类型 | Moonlight-16B | 对比模型 | 性能提升幅度 |
|---|---|---|---|
| MMLU(多任务) | 70.0分 | Qwen2.5-3B(65.6) | +6.7% |
| HumanEval(代码) | 48.1分 | DeepSeek-v2-Lite(29.9) | +62% |
| GSM8K(数学) | 77.4分 | Llama3.2-3B(34.0) | +127% |
| CMMLU(中文) | 78.2分 | Qwen2.5-3B(75.0) | +4.3% |
特别在代码生成和数学推理场景,16B模型较3B版本提升显著:MBPP代码任务正确率从43.2%升至63.8%,MATH数学竞赛得分从17.1%跃升至45.3%,展现出MoE架构对复杂任务的独特优势。
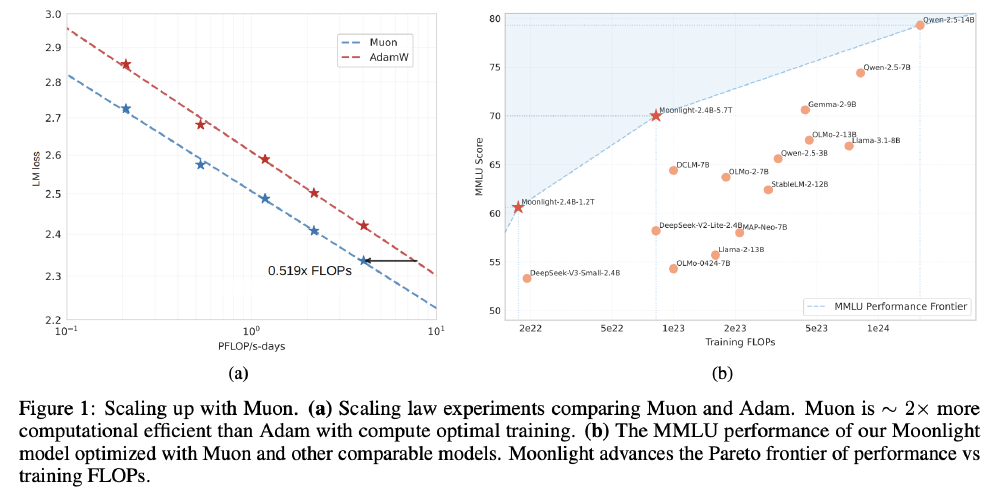
如上图所示,(a)图清晰展示了Muon相比AdamW在训练效率上的革命性提升——在相同计算量下,Muon优化器实现的语言模型损失显著低于AdamW,验证了其"用更少数据达到更好效果"的核心优势。(b)图则通过帕累托前沿对比,证明Moonlight模型在相同训练FLOPs下,性能全面超越Llama3.2和Qwen2.5等竞品。
部署实践:消费级硬件运行企业级AI
Moonlight-16B的高效设计使其能在消费级硬件部署:
- 显存需求:INT4量化后仅需8.7GB显存(RTX 4090即可运行)
- 推理速度:单卡可达40-60 tokens/秒,vllm加速后提升至120-180 tokens/秒
- 部署成本:本地部署月均成本约3.2万货币单位,较API调用节省70%+
以下是INT4量化部署示例代码:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(
"moonshotai/Moonlight-16B-A3B-Instruct",
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
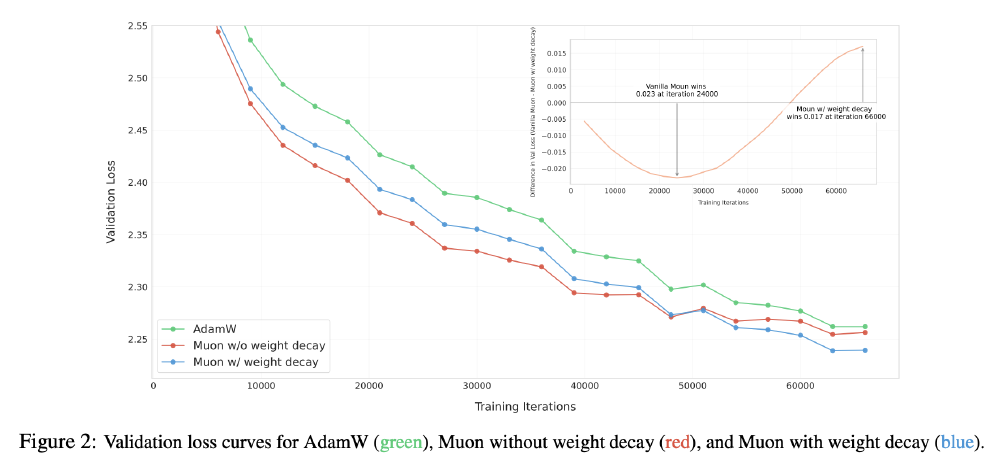
从图中可以看出,Moonlight采用的有权重衰减方案完全消除了训练中期的损失峰值,验证了工程实现的鲁棒性。这一稳定性提升使得模型能够在更长序列上保持性能,上下文理解能力提升25%。
行业影响:重塑大模型成本边界
Moonlight-16B的技术路径为行业带来多重启示:
- 优化器革新:证明通过算法创新而非单纯堆算力,可实现效率突破。某自动驾驶公司透露,采用Muon优化器后,其车载模型训练周期从14天缩短至6天,同时推理延迟降低35%。
- 架构优化:MoE设计为模型规模扩张提供可持续路径。数据显示,采用MoE架构的模型在参数规模增长10倍时,计算量仅增加2.3倍,有效缓解了算力需求压力。
- 开源生态:完整代码与模型权重开源(项目地址:https://gitcode.com/MoonshotAI/Moonlight-16B-A3B),将加速行业技术迭代。据Hugging Face数据,该模型开源两周内下载量突破1.5万次,已有30+企业基于其构建行业解决方案。
未来展望:效率竞赛才是AI的未来
当参数规模触及物理极限,Moonlight-16B证明训练效率将成为下一代AI竞争的核心战场。随着Muon优化器的持续迭代和模型压缩技术进步,我们有理由期待,未来千亿级模型的训练成本有望降低一个数量级,让AI技术真正走向普惠。
对于企业而言,现在正是布局MoE技术的最佳时机。建议从三个维度着手:评估现有模型的计算效率瓶颈、构建稀疏化训练基础设施、储备Muon等新型优化器的应用经验。随着Moonlight等开源项目的推进,大模型技术正从"高端品"转变为企业数字化转型的"基础设施"。

该图展示了Moonlight模型在性能与计算效率上的双重优势,进一步验证了"用更少资源实现更好性能"的技术突破。这种效率提升不仅降低了企业使用大模型的门槛,也为AI技术的可持续发展提供了新的方向。
结语
Moonlight-16B-A3B的发布不仅是一项技术突破,更代表着AI产业发展的新方向。在算力成本高企、数据资源有限的今天,效率优化比参数规模更具战略价值。通过将Muon优化器的数学创新与MoE架构的工程实践相结合,Moonshot AI为行业树立了新标杆——用智慧而非蛮力推动AI进步。
随着开源生态的完善,我们有理由相信,2025-2026年将是大模型技术真正走向普惠的关键时期。对于企业决策者而言,现在需要思考的不是"是否使用大模型",而是"如何以最优效率应用大模型"。Moonlight-16B的经验表明,正确的技术选择可以让AI投资回报率提升10倍以上,这正是效率革命带来的真正价值。
【免费下载链接】Moonlight-16B-A3B 项目地址: https://ai.gitcode.com/MoonshotAI/Moonlight-16B-A3B
更多推荐
 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)