
长上下文泛化问题:算力、显存与无限注意力
由于CSDN编辑器与我正在使用的编辑器(语雀) 格式转换有问题 公式可能显示错误 如需要细致观看可点击文中论文原文链接或者语雀作者:今天只为做一件事
在和AI对话时,有时候会发现它的记忆有点差;
比如你先发给它一个整体需求,随着任务的进行 它会逐渐记不清最开始的约定;这就是模型在使用时的长度超过模型训练长度所带来的“长文本泛化问题 (Long-Context Generalization)”
长上下文泛化问题
随着上下文增加,模型容易出现"Lost in the Middle"现象 即模型对文档中间信息的提取能力显著弱于头部和尾部
《 Lost in the Middle: How Language Models Use Long Contexts ****》—— 迷失在中间:语言模型如何利用长上下文
While recent language models have the ability to take long contexts as input, relatively little is known about how well they use longer context. We analyze the performance of language models on two tasks that require identifying relevant information in their input contexts: multi-document question answering and key-value retrieval. We find that performance can degrade significantly when changing the position of relevant information, indicating that current language models do not robustly make use of information in long input contexts. In particular, we observe that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts, even for explicitly long-context models. Our analysis provides a better understanding of how language models use their input context and provides new evaluation protocols for future long-context language models.
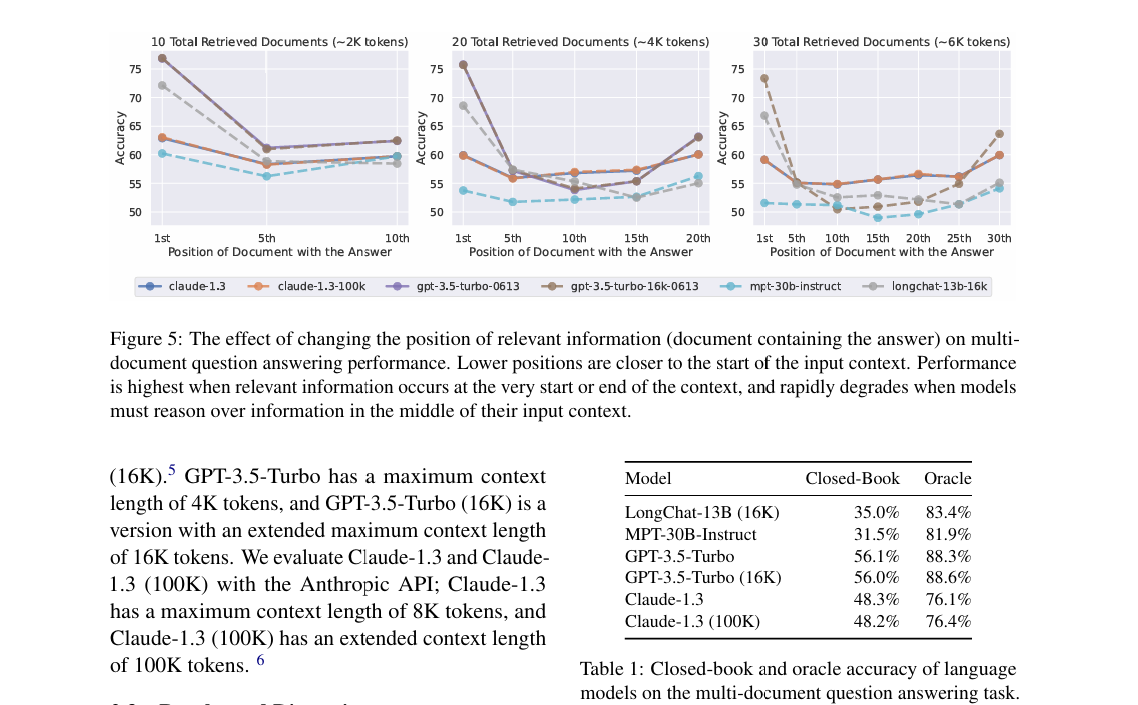
虽然最近的语言模型具备将长上下文作为输入的能力,但它们对较长上下文的使用效果知之甚少。我们分析了语言模型在两个需要识别输入上下文相关信息的任务上的表现:多文档问答和键值检索。我们发现,当相关信息的位置变化时,性能会显著下降,表明当前的语言模型在长输入上下文中并未充分利用信息。特别是,我们观察到,当相关信息出现在输入上下文的开始或结束时,性能通常最高;而当模型必须在长上下文中间访问相关信息时,性能也会显著下降,即使是显式长上下文模型也是如此。我们的分析更好地理解了语言模型如何使用输入上下文,并为未来的长上下文语言模型提供了新的评估方案。
究其原因在于模型在处理长文本时,遭遇了**“注意力陷阱(Attention Sink)”** 即过度关注输入序列内容开头的少数几个token,它就像黑洞一样吸走了本该分配给后续内容的计算资源,导致再往后的信息难以被模型注意到,哪怕后续信息对任务更重要,也难以避免出现**注意力退化(Attention Decay)**
标准Transformer的Self-Attention具有$ O(N^2)
$的复杂度。即使显存足够,KV Cache(键值缓存)的增长也会导致推理成本不可承受。
目前的解决方案
旨在解决长上下文泛化问题的注意力缺失和长文本注意力追加的权重取舍,通过从绝对位置编码向旋转位置编码 (RoPE) 的范式转变,并进一步结合 YaRN 的多尺度频率内插与 LongRoPE 的非均匀进化搜索策略,从数学层面修正了高频信息丢失问题,实现了模型在极少微调下对百万级 Token 的无损外推。
位置编码的改进
位置编码(Position Embedding)决定了模型"对距离的感知能力";
传统模型(如早期的BERT、GPT-2)使用绝对位置编码,这就像给每个Token编一个固定的门牌号,一旦推理时的长度超过了预训练时的最大门牌号,模型就会彻底迷路;为了解决这个问题,研究界演进出了 RoPE (旋转位置编码) 及其一系列变体
RoPE (Rotary Positional Embedding) —— 旋转位置编码
《 RoFormer: Enhanced Transformer with Rotary Position Embedding ****》—— RoFormer:采用旋转位置嵌入的增强型 Transformer
Position encoding recently has shown effective in the transformer architecture. It enables valuable supervision for dependency modeling between elements at different positions of the sequence. In this paper, we first investigate various methods to integrate positional information into the learning process of transformer-based language models. Then, we propose a novel method named Rotary Position Embedding(RoPE) to effectively leverage the positional information. Specifically, the proposed RoPE encodes the absolute position with a rotation matrix and meanwhile incorporates the explicit relative position dependency in self-attention formulation. Notably, RoPE enables valuable properties, including the flexibility of sequence length, decaying inter-token dependency with increasing relative distances, and the capability of equipping the linear self-attention with relative position encoding. Finally, we evaluate the enhanced transformer with rotary position embedding, also called RoFormer, on various long text classification benchmark datasets. Our experiments show that it consistently overcomes its alternatives. Furthermore, we provide a theoretical analysis to explain some experimental results. RoFormer is already integrated into Huggingface: \url{this https URL}.
位置编码最近在变压器架构中表现出有效性。它为序列不同位置元素之间的依赖建模提供了宝贵的监督。本文首先探讨了将位置信息整合到基于Transformer的语言模型学习过程中的各种方法。随后,我们提出了一种名为旋转位置嵌入(RoPE)的新方法,以有效利用位置信息。具体来说,所提议的RoPE用旋转矩阵编码绝对位置,同时在自我注意力表述中包含了显式的相对位置依赖性。值得注意的是,RoPE实现了有价值的特性,包括序列长度的灵活性、随着相对距离增加而衰减的符号间依赖性,以及具备相对位置编码功能的能力。最后,我们在多个长文本分类基准数据集上评估了带有旋转位置嵌入的增强型变换器(也称为RoFormer)。我们的实验表明,它始终能够克服其他替代方案。此外,我们还提供了理论分析以解释一些实验结果。Roformer 已经集成到 Huggingface: \url{this https URL} 中。
RoPE 不再给 Token 贴标签,而是将 Token 的特征向量(Embedding)在一个高维空间中进行旋转,旋转的角度取决于该 Token 所在的位置;两个 Token 之间的相关性(Attention Score)不再取决于它们的绝对坐标,而取决于它们之间的相对夹角;
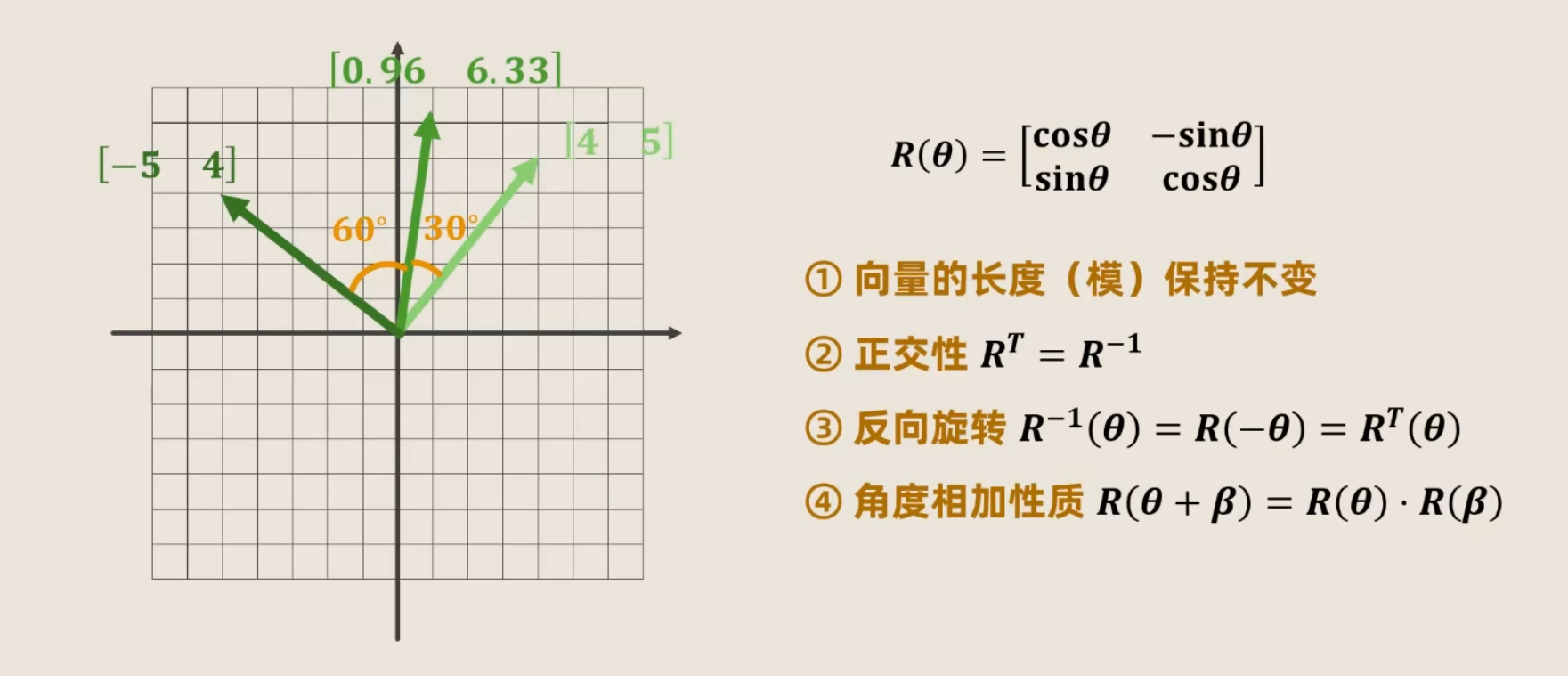
该范式实现了相对位置感知。由于旋转是连续的,模型理论上具备了处理比训练长度更长文本的潜力。它是目前 Llama、Qwen、Mistral 等几乎所有主流大模型的标配(2025)
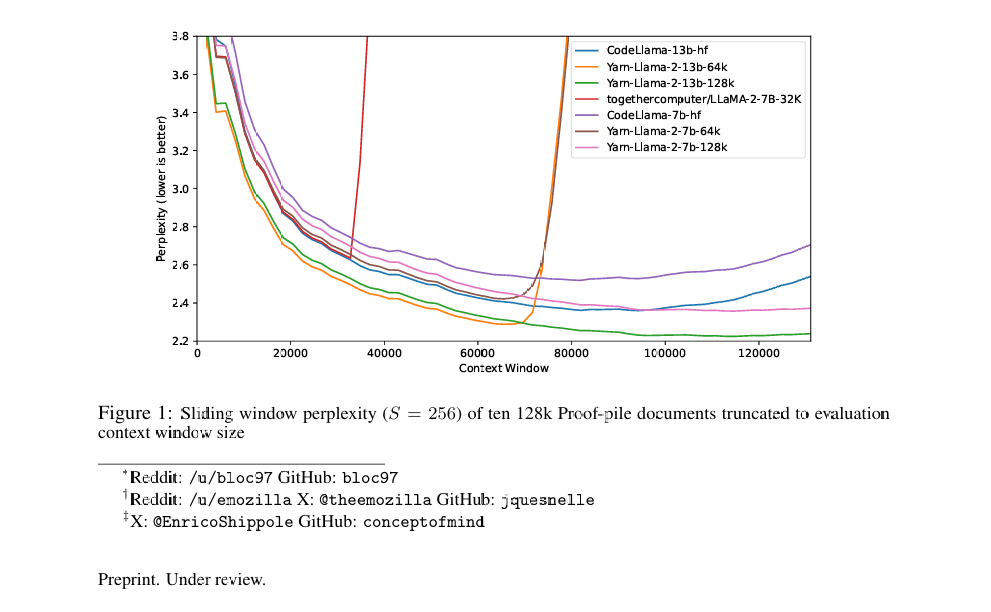
YaRN (Yet another RoPE extensioN) —— 多尺度频率内插
原始RoPE的问题是当你试图将一个在 4k 长度训练的模型直接扩展到 128k 时,如果只是简单地把位置序号挤进去(线性内插),模型会丢失高频信息。就像把一张高清照片强行压缩,细节会变模糊。
《 YaRN: Efficient Context Window Extension of Large Language Models 》—— YaRN:大型语言模型的高效上下文窗口扩展
Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize past the sequence length they were trained on. We present YaRN (Yet another RoPE extensioN method), a compute-efficient method to extend the context window of such models, requiring 10x less tokens and 2.5x less training steps than previous methods. Using YaRN, we show that LLaMA models can effectively utilize and extrapolate to context lengths much longer than their original pre-training would allow, while also surpassing previous the state-of-the-art at context window extension. In addition, we demonstrate that YaRN exhibits the capability to extrapolate beyond the limited context of a fine-tuning dataset. The models fine-tuned using YaRN has been made available and reproduced online up to 128k context length at this https URL
旋转位置嵌入(RoPE)已被证明能有效编码基于变换器的语言模型中的位置信息。然而,这些模型无法推广到它们训练时所用的序列长度之外。我们介绍YaRN(另一种RoPE扩展方法),这是一种计算效率高的方法,用于扩展此类模型的上下文窗口,所需token数是之前方法的10倍,训练步骤减少2.5倍。利用YaRN,我们展示了LLaMA模型能够有效利用并推演上下文长度,远超其原始预训练所允许的长度,同时超越了之前最先进的上下文窗口扩展技术。此外,我们展示了YaRN能够超越微调数据集有限上下文进行外推。使用YaRN微调的模型已在线发布,上下文长度可达128k,链接为 this https URL
YaRN 发现 RoPE 的不同维度(频率)对距离的敏感度不同:
- 高频部分: 负责捕捉邻近 Token 的精细逻辑(如语法)。YaRN 建议对这部分少做或不做改动,以保持局部精度。
- 低频部分: 负责捕捉长距离的宏观联系。YaRN 对这部分进行深度缩放。
YaRN解决了"内插"过程中的信息损失问题。 它将 RoPE 视为多尺度频率系统,通过对不同频率维度施加不同强度的平滑插值,让模型在不进行大规模重训练的情况下,依然能保持极高的长文本召回精度
LongRoPE (Microsoft, 2024) —— 非均匀插值与进化搜索
这是微软在 2024 年提出的方案,它将上下文一举推向了 200万 (2M) Token 的级别。
《 LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens 》—— LongRoPE:将LLM上下文窗口扩展到超过200万Tokens
Large context window is a desirable feature in large language models (LLMs). However, due to high fine-tuning costs, scarcity of long texts, and catastrophic values introduced by new token positions, current extended context windows are limited to around 128k tokens. This paper introduces LongRoPE that, for the first time, extends the context window of pre-trained LLMs to an impressive 2048k tokens, with up to only 1k fine-tuning steps at within 256k training lengths, while maintaining performance at the original short context window. This is achieved by three key innovations: (i) we identify and exploit two forms of non-uniformities in positional interpolation through an efficient search, providing a better initialization for fine-tuning and enabling an 8x extension in non-fine-tuning scenarios; (ii) we introduce a progressive extension strategy that first fine-tunes a 256k length LLM and then conducts a second positional interpolation on the fine-tuned extended LLM to achieve a 2048k context window; (iii) we readjust LongRoPE on 8k length to recover the short context window performance. Extensive experiments on LLaMA2 and Mistral across various tasks demonstrate the effectiveness of our method. Models extended via LongRoPE retain the original architecture with minor modifications to the positional embedding, and can reuse most pre-existing optimizations.
大型上下文窗口是大型语言模型(LLM)中一个理想的特性。然而,由于高微调成本、长文本稀缺以及新代币位置带来的灾难性值,当前扩展上下文窗口限制在约12.8万个代币。本文介绍了LongRoPE,首次将预训练LLM的上下文窗口扩展至令人印象深刻的204.8万个令牌,且在256k训练长度内仅需1k微调步骤,同时保持原始短上下文窗口的性能。这通过三项关键创新实现:(i)通过高效搜索识别并利用位置插值中的两种非均匀性,提供更好的微调初始化,并在非微调场景下实现8倍扩展;(ii)我们引入一种渐进扩展策略,先对长度为256k的LLM进行微调,然后对经过微调的扩展LLM进行第二次位置插值,以实现2048k上下文窗口;(iii)我们重新调整8k长度的LongRoPE,以恢复短上下文窗口的性能。在LLaMA2和Mistral上进行的广泛实验证明了我们方法的有效性。通过LongRoPE扩展的模型保留了原始架构,仅对位置嵌入做了些微修改,并且可以复用大多数已有的优化。
之前的 YaRN 虽然分了高低频,但缩放比例仍然是基于人工经验。LongRoPE 利用进化算法(Evolutionary Search),为 RoPE 的每一个维度寻找最优的缩放系数。它首先在非微调状态下寻找最佳外推参数,然后在极短的序列上进行微调(恢复性能),最后再外推到极长序列;它不是一次性变长,而是通过捕捉位置编码中的“非均匀性”,让模型在不同长度下都能自适应。
通过自动化搜索和非均匀缩放,将这一物理特性的潜力发挥到了极致,支撑起了 2024-2025 年工业界对百万级序列的需求 证明了位置编码中隐藏着巨大的冗余,通过非均匀的参数微调,旧架构也能跑通超长上下文
线性复杂度架构
为了彻底解决复杂度问题,2024-2025年见证了非Transformer架构的崛起。
SSM 与 Mamba:线性时代
在深度学习的发展史上,如果说 RNN(循环神经网络)是第一代序列模型,Transformer 是统治了过去八年(2017-2025)的第二代,那么以 Mamba 为代表的 SSM(状态空间模型) 则被广泛认为是第三代序列模型的核心竞争者。
Transformer 架构的核心是 Self-Attention(自注意力机制)。它的问题在于:为了理解当前的词,它必须回头看前面所有的词,并且计算每两个词之间的相关性。计算量和显存占用随长度 N 的增加呈平方级$ (O(N^2)) $增长;当文本达到 100k 以上时,显存会迅速耗尽,推理速度变得极慢。
《 Mamba: Linear-Time Sequence Modeling with Selective State Spaces 》—— Mamba:带有选择性状态空间的线性时间序列架构
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers’ computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5* higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
如今支撑着深度学习中大多数令人兴奋应用的基础模型,几乎全部基于Transformer架构及其核心注意力模块。许多亚二次时间架构,如线性注意力、门控卷积和循环模型,以及结构化状态空间模型(SSM),已被开发出来解决变换器在长序列上的计算效率低,但它们在语言等重要模态上的表现不如关注。我们发现此类模型的一个关键弱点是无法进行基于内容的推理,并进行了若干改进。首先,仅仅让SSM参数成为输入的函数,通过离散模态解决了其弱点,使模型能够根据当前符号选择性地沿序列长度维度传播或遗漏信息。其次,尽管这一变化阻碍了高效卷积的使用,我们设计了一个具有硬件感知的递归模式并行算法。我们将这些选择性SSM集成到一个简化的端到端神经网络架构中,无需注意力,甚至不依赖MLP模块(Mamba)。曼巴喜欢快速推理(5*吞吐量高于Transformer)以及序列长度的线性缩放,其性能在处理百万长度的真实数据上有所提升。作为通用序列模型骨干,Mamba在语言、音频和基因组学等多种模态上实现了最先进的性能。在语言建模方面,我们的Mamba-3B模型在预训练和下游评估中均优于同等规模的Transformers,且规模为其两倍。
Mamba 的突破:选择性扫描机制 (Selective Scan)
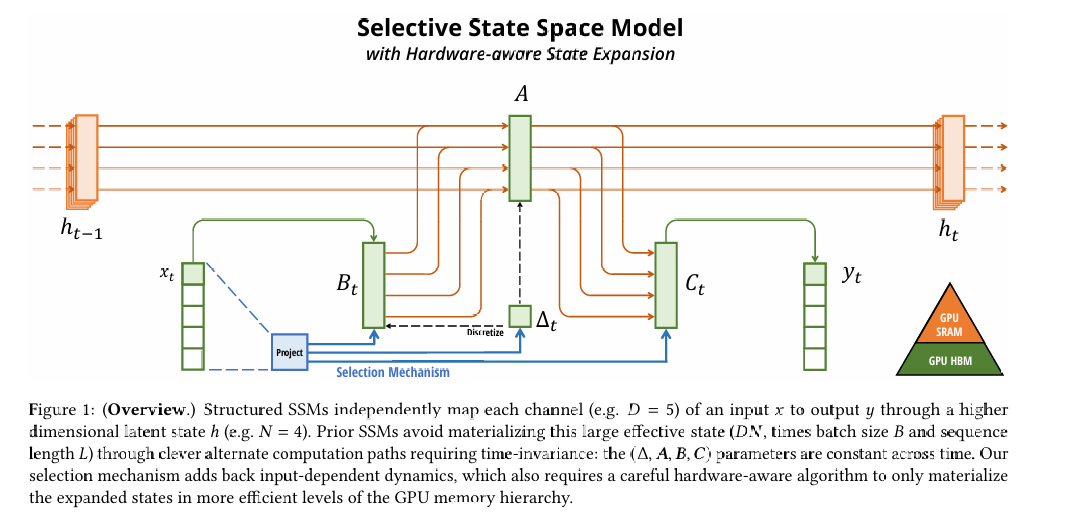
该架构抛弃了注意力机制,回归并重构了 SSM(状态空间模型)。你可以将其类比为一个高度智能的压缩机;
隐藏状态(Hidden State)Mamba 不存储之前所有的 Token(即不需要庞大的 KV Cache),而是维护一个固定大小的"记忆状态"
选择性(Selectivity)记忆 传统的 SSM 或 RNN 会无差别地记住所有信息,导致后面记不住前面。Mamba 的 Selective Scan(S6)算法 让模型能根据当前的输入,自动决定:“这个信息很重要,存入记忆” 或 “这是废话,直接丢弃”
Mamba架构的复杂度是$ O(N) $处理 100 万个词的计算压力,只是处理 1 万个词的 100 倍,而不是 10,000 倍。
Jamba:平衡精度与效率
为什么需要 Jamba?虽然 Mamba 很快,但它有一个局限性:由于它将所有信息压缩在固定大小的状态中,当需要进行极度精确的检索(例如在 200 万字里找一个具体的电话号码)时,它偶尔会表现得不如 Transformer。
Jamba的核心机制其实是Hybrid(混合)架构,由AI21 Labs 在 2024 年提出,它并不是全用Mamba,也不是全用Transformer,它将Transformer 层 和 Mamba 层 交替堆叠(例如:每 4 层里有 1 层是 Transformer,3 层是 Mamba)。
《 Jamba: A Hybrid Transformer-Mamba Language Model 》—— ****Jamba:一种混合变换器-Mamba语言模型
We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
我们介绍Jamba,一种基于新型混合Transformer-Mamba专家混合(MoE)架构的新型基础大型语言模型。具体来说,Jamba 交错了变形金刚和 Mamba 层块,享受了两种模型家族的优势。部分层中加入了MoE,以增加模型容量,同时保持活跃参数的使用可控性。这种灵活的架构允许针对资源和目标进行特定配置。在我们实现的具体配置中,最终得到一个强大的型号,能装进一块80GB的GPU中。Jamba大规模构建,提供高吞吐量和较小内存占用,相较于原版Transformers,同时在标准语言模型基准测试和长上下文评估中表现最先进。令人惊讶的是,该模型在最多25.6万个令牌上下文长度下表现强劲。我们研究各种架构决策,比如如何组合Transformer和Mamba层,如何混合专家,并展示了其中一些在大规模建模中至关重要。我们还介绍了这些架构的若干有趣特性,这些特性是Jamba的培训和评估揭示的,并计划释放多次消融检查点,以鼓励对这一新颖架构的进一步探索。我们将Jamba实现的权重以宽松许可形式公开。
并不是简单地将两个模型拼接,而是采用了"三明治"式的堆叠结构。在 Jamba 的架构中,大多数层是 Mamba 层(基于 SSM,状态空间模型),每隔固定的间隔(例如 8 层或 4 层)插入一个 Attention 层(Transformer 核心)。
- Mamba 层:负责处理长程背景。它像一个高效的“过滤器”,以$ O(N) $线性复杂度处理输入,将信息不断压缩进一个固定大小的状态变量(Hidden State)中。
- Attention 层:负责"高精度快照"。由于 Mamba 在压缩信息时可能丢失极其微小的细节,Attention 层通过计算全局注意力,重新扫描所有 Token 之间的关系,起到校准和增强的作用。
这种设计实现了计算开销与建模精度之间的最优平衡。它打破了 Transformer 全局注意力的资源浪费,也克服了纯 Mamba 记忆模糊的缺陷;
专家混合机制(MoE, Mixture of Experts)集成:
Jamba 在这些混搭层之上,还引入了 MoE(Mixture of Experts) 架构。这意味着在每一层中,模型拥有多个专家组件(MLP),但对于每个输入的 Token,只有其中 1-2 个专家会被激活。
- 对长文本的意义:
处理长文本时,算力需求是巨大的。MoE 允许 Jamba 拥有巨大的参数量(例如 52B),但在推理时,实际参与计算的活跃参数量(Active Parameters)极小(仅约 12B)。 - 解决的问题: 极大地提升了模型在处理超长序列时的吞吐量(Throughput)。在同等算力下,Jamba 产生 Token 的速度远快于传统的密集型模型(Dense Models)。
锚点效应:解决 Mamba 的"健忘"问题
长上下文泛化的一个核心难题是"状态饱和"。在纯 Mamba 架构中,随着文本增加,那个固定大小的记忆瓶颈(State Bottleneck)会变得拥挤,导致模型忘记早期的细节。
Jamba的解决方案是将Attention 层设在 Jamba 中扮演“全局锚点”的角色。由于 Attention 层拥有自己的 KV Cache,它可以直接回溯到 10 万个 Token 之前的精确位置,这种架构在"大海捞针"测试中表现极佳。即使线索隐藏在 25.6 万个 Token 的中间,Attention 层也能精准地将其提取出来,而中间的 Mamba 层则负责维持语法的连贯性和长程逻辑。
显存奇迹:KV Cache 的 8 倍压缩
这是 Jamba 最具工业价值的突破。在 Transformer 中,显存的大头是 KV Cache(它随着长度线性增长),由于大部分层是 Mamba 层(Mamba 不需要 KV Cache),只有极少数的 Attention 层需要维护 KV Cache。
根据 AI21 Labs 的数据,Jamba 相比同等规模的 Transformer,其 KV Cache 的内存占用减少了 约 8 倍。这意味着在单张 80GB 的 H100 显卡上,Jamba 可以容纳原本需要 8 张显卡才能支撑的上下文长度。这种存储效率的指数级提升,是实现“超长上下文泛化”从理论走向大规模商用的关键。
动态稀疏与门控机制
虽然 Jamba 试图通过改变架构来解决效率问题,然而混合架构带来了更多超参、更多部署复杂度(层间接口、KV 管理、MoE 路由开销) 在 2025 年,工业界发现通过对 Transformer 本身进行"手术"可能是更优解。Transformer 的所有 Attention Head 并非生而平等,这引出了阿里云研究团队(本节提及的是由麻省理工、清华、阿里通义实验室等在2024-2025年间共同推进))荣获 NeurIPS 2025 最佳论文奖的关键技术论文。:
**《 DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads ****》—— **DuoAttention:高效的长上下文大型语言模型推理,支持检索和流式读头
Deploying long-context large language models (LLMs) is essential but poses significant computational and memory challenges.Caching all Key and Value (KV) states across all attention heads consumes substantial memory.Existing KV cache pruning methods either damage the long-context capabilities of LLMs or offer only limited efficiency improvements.In this paper, we identify that only a fraction of attention heads, a.k.a, Retrieval Heads, are critical for processing long contexts and require full attention across all tokens.In contrast, all other heads, which primarily focus on recent tokens and attention sinks—referred to as Streaming Heads—do not require full attention.Based on this insight, we introduce DuoAttention, a framework that only applies a full KV cache to retrieval heads while using a light-weight, constant-length KV cache for streaming heads, which reduces both LLM’s decoding and pre-filling memory and latency without compromising its long-context abilities.DuoAttention uses a lightweight, optimization-based algorithm with synthetic data to identify retrieval heads accurately.Our method significantly reduces long-context inference memory by up to 2.55× for MHA and 1.67× for GQA models while speeding up decoding by up to 2.18× and 1.50× and accelerating pre-filling by up to 1.73× and 1.63× for MHA and GQA models, respectively, with minimal accuracy loss compared to full attention.Notably, combined with quantization, DuoAttention enables Llama-3-8B decoding with 3.33 million context length measured on a single A100 GPU. Code is provided in https://github.com/mit-han-lab/duo-attention.
部署长上下文大型语言模型(LLM)至关重要,但带来了显著的计算和内存挑战。缓存所有注意力头的所有键和值(KV)状态会消耗大量内存。现有的KV缓存剪枝方法要么损害LLM的长上下文能力,要么仅带来有限的效率提升。本文指出,只有一小部分注意力头,即检索头,对于处理长上下文至关重要,并且需要所有标记的全注意力。相比之下,其他主要关注近期代币和注意力消耗的标题——称为流媒体头——则不需要全神贯注。基于这一见解,我们介绍了DuoAttention框架,该框架仅对检索头使用完整的KV缓存,而流式头则使用轻量级、恒长的KV缓存,从而减少LLM的解码和预填充内存及延迟,同时不影响其长上下文能力。DuoAttention采用一种轻量级的优化算法,结合合成数据,准确识别检索头。我们的方法显著减少了长上下文推理记忆最多2.55×对于MHA和1.67×对于GQA模型,同时将解码速度提升至2.18倍×以及1.50×预填充加速可达1.73×以及1.63×分别针对MHA和GQA模型,准确率损失最小,而全注意力则是如此。值得注意的是,结合量化技术,DuoAttention使Llama-3-8B解码能够在单个A100 GPU上实现333万上下文长度的解码。代码以 https://github.com/mit-han-lab/duo-attention 提供。
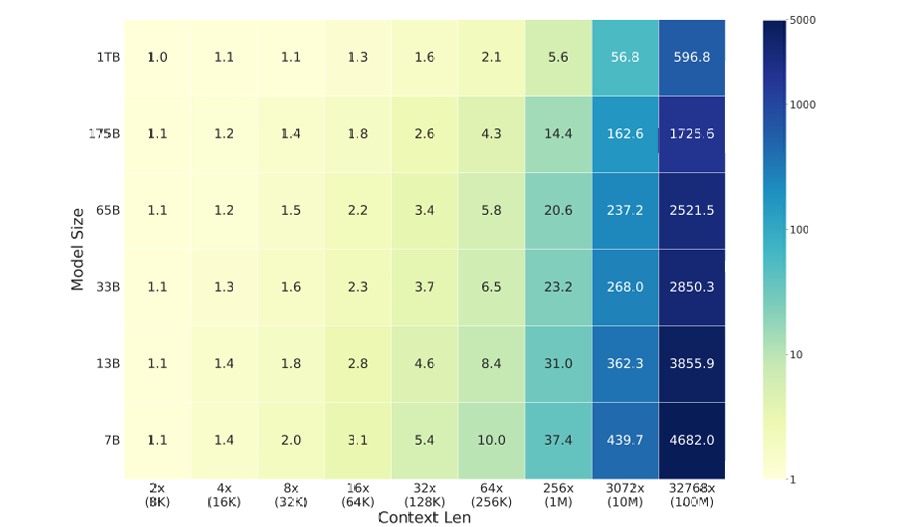
( 每个数据集的训练FLOPs成本比,参考4k上下文大小,并考虑不同的模型维度。在x轴上,你会看到上下文长度,例如,32x(128k) 表示上下文长度为128k,是同一模型4k上下文长度的32倍 )
阿里云 Qwen 团队(通义千问)的研究指出,在处理长上下文时,模型中只有极少数的"检索头 (Retrieval Heads)"需要保留完整的 KV Cache 来捕捉长距离依赖,而其余大部分"流式头 (Streaming Heads)"只需要关注最近的上下文。
我们不得不重新提到在标准的 Transformer 中,我们假设所有的 Attention Head(注意力头)都需要“观六路,听八方”,因此我们强制保留了所有层、所有头的 KV Cache。
但在对大量长文本模型(如 Qwen-2.5-72B-Instruct)进行注意力图(Attention Map)分析后,研究人员发现了一个惊人的现象:
- 流式头 (Streaming Heads):大部分 Head(约 70%~90%)其实非常"短视"。它们只关注最近的几十到几百个 Token(比如关注语法结构、短语搭配)。对于 10 万个 Token 之前的历史,它们的注意力权重几乎为 0。对于这些头,保存全部历史 KV Cache 是纯粹的浪费。
- 检索头 (Retrieval Heads):只有极少数 Head(约 10%~30%)承担了"长期记忆"的职责。它们在"大海捞针"任务中会被激活,去寻找那些很久以前出现的关键信息(如人名、特定数字)。
门控机制 (Gating Mechanism)
“门控”并非指在推理时对每个 Token 动态开关(那样计算开销太大),而是在微调或校准阶段(Calibration Stage)引入的一个可学习的掩码(Learnable Mask)。
它需要错两件事:
1.引入门控参数
对于第 $ i < f o n t s t y l e = " c o l o r : r g b ( 26 , 28 , 30 ) ; " > 层、第 < / f o n t > <font style="color:rgb(26, 28, 30);"> 层、第 </font> <fontstyle="color:rgb(26,28,30);">层、第</font> j < f o n t s t y l e = " c o l o r : r g b ( 26 , 28 , 30 ) ; " > 个注意力头,我们引入一个可学习的门控标量 < / f o n t > <font style="color:rgb(26, 28, 30);"> 个注意力头,我们引入一个可学习的门控标量 </font> <fontstyle="color:rgb(26,28,30);">个注意力头,我们引入一个可学习的门控标量</font> g_{i,j} \in [0, 1] $。
模型的注意力计算被修改为:
$ \text{Attention output} = (1 - g_{i,j}) \times \text{Streaming_Attn} + g_{i,j} \times \text{Full_KV_Attn} $
- 如果 $ g_{i,j} $ 趋向于 0,该头被识别为流式头。
- 如果 $ g_{i,j} $ 趋向于 1,该头被识别为检索头。
2.稀疏化正则训练 (Sparsity-Regularized Training)
模型会通过在一个长文本数据集上进行轻量级训练(或校准),目标函数不仅包含预测下一个 Token 的准确率(Loss),还加入了一个正则项(Regularization Term),强迫模型尽可能多地将 $ g_{i,j} $ 推向 0(即尽可能多地抛弃历史)。
$ L_{total} = L_{model} + \lambda \times \sum (\text{KV_Cache_Budget}) $
结果: 经过这个过程,模型"被迫"承认:“好吧,其实我只需要第 2、15、32 号头来记住全文,其他的头我只看最近的 256 个词就够了。”
该技术的显存与精度的双赢
通过这种机制,模型在推理时可以丢弃 80%-90% 的 KV Cache,显存占用接近线性模型(Mamba),但因为保留了关键的“检索头”,其在“大海捞针”等任务上的精度远超纯 SSM 模型。一旦训练完成,这个门控 $ g $ 就变成了固定的二值(0 或 1)。在 2026 年的生产环境(如 vLLM 或 SGLang 框架)中,这意味着:
1.显存占用的极致压缩 (KV Cache Eviction)
在推理阶段,工程实现上会执行严格的 KV Cache 驱逐策略:
- 对于流式头 (Streaming Heads):我们只维护一个很小的滚动窗口 (Rolling Buffer),比如最近 512 个 Token。一旦新的 Token 进来,最老的 Token 对应的 KV 值就被物理删除。
- 对于检索头 (Retrieval Heads):我们保留完整的 KV Cache。
算笔账:
假设一个模型有 32 个层,每层 32 个头(共 1024 个头),上下文长度 1M (100万) Tokens。
- 传统 Transformer:需存 1024 个头的 1M 历史。显存占用 = 100%。
- 门控机制优化后:假设只有 10% 是检索头。
- 10% 的头存 1M 历史。
- 90% 的头只存 512 个历史。
- 显存占用 $ \approx $ 10% + 忽略不计。
- 结论:在几乎不损失能力的前提下,上下文容量直接提升了 10 倍。
2.精度远超纯 SSM/Mamba
这正是该机制击败纯线性模型(如 Mamba)的关键。
- Mamba 的弱点:Mamba 为了实现线性复杂度,强行把历史信息压缩进一个固定大小的隐状态(Hidden State)。这种“有损压缩”注定会丢失细节。当你问它“第 342 行那个具体的电话号码是多少”时,状态里可能只剩下一个模糊的影子,导致回答错误。
- 门控 Transformer 的优势:虽然我们丢弃了 90% 的 KV Cache,但那保留下来的 10% 是原汁原味的、未经压缩的 Attention。
- 当需要“大海捞针”时,那 10% 的检索头依然可以进行全局扫描,精确匹配到之前的 Token。
- 只要有一个头记住了,模型就能回答正确。
想象一个负责整理几百万本书(长文本)的图书馆团队(模型):
- 传统模型:要求团队里 100 个人(所有的 Head)每个人都必须要把每一本书的内容背下来。这不仅慢,而且脑子(显存)不够用。
- 纯 Mamba 模型:把书的内容写成一页摘要。虽然省事,但如果问“第 500 本书第 3 页左下角的注脚是什么”,看摘要的人是答不上来的。
- 门控机制 (DuoAttention):
- 发现团队里 90 个人 其实是负责搬运和分类的(流式头),他们只需要知道刚才那本书放在哪(最近上下文),不需要背书。
- 指定剩下的 10 个人 为“档案专家”(检索头),他们被允许使用电脑记录所有细节。
- 当用户提问细节时,那 90 个人解决语言流畅度问题,那 10 个专家负责调取精准记忆。
这就是为什么在 2026 年 “Transformer + 门控稀疏化”成为了比纯 Mamba 更受工业界欢迎的落地技术方案——它在效率上逼近了 Mamba,但在关键的"记忆精准度"上从未妥协。
分布式计算与注意力优化
关于解决长上下文泛化问题,如果说 Mamba/Jamba 是在"设计更好的发动机",那么 Ring Attention 和 FlashAttention-3 就是在"修筑更宽的高速公路"和"提升引擎的转速"。
Ring Attention:分布式计算的突破
传统的分布式处理长文本的方法(如张量并行 Tensor Parallelism)在处理数百万序列时,由于 GPU 之间需要频繁同步大量数据,会导致通信开销巨大,系统效率极低。
《 Ring Attention with Blockwise Transformers for Near-Infinite Context 》—— ****用区块式变换器进行环注意力,实现近无限上下文
Transformers have emerged as the architecture of choice for many state-of-the-art AI models, showcasing exceptional performance across a wide range of AI applications. However, the memory demands imposed by Transformers limit their ability to handle long sequences, thereby posing challenges in utilizing videos, actions, and other long-form sequences and modalities in complex environments. We present a novel approach, Ring Attention with Blockwise Transformers (Ring Attention), which leverages blockwise computation of self-attention and feedforward to distribute long sequences across multiple devices while fully overlapping the communication of key-value blocks with the computation of blockwise attention. Our approach enables training and inference of sequences that are up to device count times longer than those achievable by prior memory-efficient Transformers, without resorting to approximations or incurring additional communication and computation overheads. Extensive experiments on language modeling and reinforcement learning tasks demonstrate the effectiveness of our approach in allowing millions of tokens context size and improving performance.
Transformers 已成为许多先进AI模型的首选架构,在广泛的AI应用中展现出卓越的性能。然而,Transformers 对内存的需求限制了其处理长序列的能力,因此在复杂环境中利用视频、动作及其他长篇序列和模态时面临挑战。我们提出了一种新颖的方法——带分块式变换器进行环状注意力(Ring Attention),它利用分块式自注意力和前馈计算,将长序列分布到多个设备,同时在关键值块的通信与分块式注意力的计算完全重叠。我们的方法能够训练和推断比以往高效内存转换器更长的序列,而无需依赖近似或增加通信和计算开销。在语言建模和强化学习任务上的大量实验证明了我们方法在允许数百万个令牌实现上下文大小和提升性能方面的有效性。
Ring Attention 将长序列切分成多个"块"(Blocks),分配到不同的 GPU 节点上。这些 GPU 排成一个环形;
计算与通信的重叠(Overlap): 这是其最天才的地方。当 GPU 0 正在计算它手头那一块文本的注意力时,它同时在后台将这一块数据传给 GPU 1,并从 GPU n 接收数据。
它消除了内存壁垒,由于注意力计算是分块完成的,没有任何一个 GPU 需要存储完整的序列信息。内存压力被均匀分摊到整个集群。
FlashAttention-3 :硬件极限的异步计算
如果说 Ring Attention 解决了多卡之间的通信瓶颈,那么 FlashAttention-3 则是为了解决单卡内部算力与显存速度不匹配的"最后一公里"难题。在 H100 等 Hopper 架构 GPU 普及后,传统的 FlashAttention-2 依然受限于内存带宽(Memory Bound),GPU 的计算单元经常因为等待数据搬运而空转。
《 FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision 》—— FlashAttention-3:具有异步性和低精度的快速准确注意力
Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. FlashAttention elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU. We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0\times with FP16 reaching up to 740 TFLOPs/s (75% utilization), and with FP8 reaching close to 1.2 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6\times lower numerical error than a baseline FP8 attention.
注意力作为无处不在的Transformer架构的核心层,是大型语言模型和长上下文应用的瓶颈。FlashAttention提出了一种通过最小化内存读写来加速GPU注意力的方法。然而,它尚未充分利用近期硬件中出现的新功能,FlashAttention-2在H100 GPU上的利用率仅为35%。我们开发了三种主要技术来加速Hopper GPU的关注速度:利用张量核心和TMA的异步,(1)通过曲速专用实现整体计算和数据移动的重叠;(2)交错的块级matmul和softmax作;(3)利用硬件支持支持FP8低精度的块量化和非相干处理。我们证明了我们的方法FlashAttention-3在H100 GPU上实现了1.5-2.0的加速FP16可达740 TFLOPs/s(利用率75%),FP8接近1.2 PFLOPs/s。我们验证FP8 FlashAttention-3实现了2.6数值误差低于基础FP8的注意力。
FlashAttention-3将 Hopper GPU 上的注意力计算速度相比 FlashAttention-2 提升了 1.5-2.0 倍。主要的改进来自三项技术:
- 通过 Warp 特化(Warp-Specialization)
实现的生产者-消费者异步性,即不同的线程束分别专注于数据搬运和计算; - 重叠块状 GEMM 和 Softmax 操作;
- 使用 FP8 进行低精度训练。
这使得大语言模型能够达到 H100 理论最大 FLOPS 的 75%,显著降低了长上下文模型的训练时间和成本。
FlashAttention-3 的核心在于"彻底的异步流水线"。 在 FlashAttention-2 中,GPU 的计算单元(Tensor Cores)和数据搬运单元(DMA)往往是串行工作的——搬运时不算,算时不搬。
FlashAttention-3 利用了 Hopper 架构独有的 TMA(Tensor Memory Accelerator)和 WGMMA 指令,构建了一个生产者-消费者模型: Warp 特化(Warp Specialization):它将 GPU 的线程束分成两队,一队只负责疯狂地从显存搬运数据(生产者),另一队只负责疯狂地计算(消费者)。
计算掩盖延迟(Overlap): 通过这种分工,数据搬运的时间被计算时间完美掩盖。这就像流水线上的机械臂,以前是"抓起零件-加工-放下",现在是"一边加工当前零件,一边已经抓好了下一个零件"。
这一优化使得长文本训练的算力利用率(MFU)从 40% 飙升至 75% 以上,使得百万级上下文的训练不再是单纯的显存噩梦,而在时间成本上也变得可接受。
随机YaRN
即便长上下文泛化问题的难度颇高,但各大研究团队并没有停止对问题最佳解决方案的探索。很高兴,在本文最新编辑日期的今天(2026年6月23日) 学术界迎来了新的预训练解决方案:
《 Randomized YaRN Improves Length Generalization for Long-Context Reasoning 》—— 随机YaRN提升了长上下文推理的长度推广性
Large language models (LLMs) are typically pretrained on short sequences and then extended to work on longer sequences with additional training. However, such LLMs still struggle to further generalize to very long sequences. We propose Randomized YaRN, a training method that improves length generalization by combining YaRN-based positional extrapolation with randomized positional encoding and a length curriculum. During training on short context data, tokens are assigned YaRN positional encodings sampled from a larger position range, exposing the model to out-of-distribution positional representations even on short-context inputs. We evaluate Randomized YaRN on two challenging long-context reasoning benchmarks, BABILong and Multi-Round Coreference Resolution (MRCR). When training on data with <8K context, Randomized YaRN consistently improves reasoning performance on context lengths from 16K to 128K and outperforms standard fine-tuning, with the largest gains appearing at far out-of-distribution lengths. Our results suggest that progressively exposing models to OOD positional distributions provides an effective recipe for generalizable long-context reasoning.
大型语言模型(LLM)通常先在短序列上进行预训练,然后通过额外训练扩展到更长的序列。然而,这类大型语言模型仍难以进一步推广到非常长的序列。我们提出了随机YaRN训练方法,通过结合基于YaRN的位置外推、随机位置编码和长度课程,提升长度推广。在短上下文数据训练时,标记被赋予从更大位置范围抽样的YaRN位置编码,使模型即使在短上下文输入下也暴露于分布外的位置表示。我们基于两个具有挑战性的长上下文推理基准——BABILong和多轮共指解析(MRCR)来评估随机YaRN。在以<8K上下文数据训练时,随机YaRN在上下文长度从16K到128K持续提升推理性能,且优于标准微调,最大提升出现在远离分布长度时。我们的结果表明,逐步将模型暴露于OOD位置分布,为可推广的长上下文推理提供了有效配方。
提出在短上下文训练时就随机分配来自更大位置范围的 YaRN 编码,让模型提前适应OOD位置分布。在 BABILong 和 MRCR 基准上,仅用 <8K 数据训练即可在 16K-128K 上稳定提升推理性能。
OOD指的是**Out-of-Distribution(分布外)**的位置分布。在机器学习、自然语言处理领域中,模型通常是在特定的数据集上进行训练的,这些数据集具有一定的特征分布。当模型遇到与训练时所见数据特征明显不同的情形时,我们称这种情况为遇到了OOD样本或情况。对于基于Transformer架构的语言模型而言,它们对输入序列中的每个位置都有一种隐含的理解或预期,这种理解是基于训练过程中见到的数据模式形成的。
LLM 预训练通常在短序列(4K-8K)上进行,然后需要扩展到更长上下文(128K+)现有方法面临一个矛盾即在短数据上训练推理时泛化到长上下文中,模型从未见过超出训练长度的位置编码,导致注意力计算崩溃,现有方法(如上文提到的YaRN、位置插值)在简单检索任务上表现不错,但在推理任务(需要跨长距离信息做逻辑推断)上泛化能力很弱。
该论文提出了Randomized YaRN(随机YaRN) = YaRN 编码 + 随机位置采样 + 长度课程学习:YaRN 是一种 RoPE 位置编码外推方法,通过缩放因子 s 将位置编码的范围从 L_pre 扩展到 s × L_pre。它对低频 RoPE 维度做 NTK-by-parts 插值,并对注意力温度做长度相关缩放。
NTK-by-parts 是一种处理神经网络中的位置编码,它基于神经切线核(Neural Tangent Kernel, NTK)理论。是一种精细化调整位置编码的技术,旨在通过区分对待不同频率范围内的位置信息来优化模型处理长序列的能力。这种方法结合了神经切线核的概念,使得即使是在面对超出原始设计长度限制的情况下,也能有效地利用位置编码信息。
随机位置采样
这是该论文最关键的发现。具体做法:
训练数据:短序列,长度 L(如 4K)目标泛化:长序列,长度 L’(如 128K)
每个训练 step:
- 从 [1, L_t] 范围内无放回随机采样 L 个位置索引 I = {i₁, i₂, …, i_L},其中 i₁ < i₂ < … < i_L(排序后)
- 第 j 个 token 不再使用原始位置 j 的编码,而是使用采样位置 i_j 的 YaRN 编码:PẼ(j) = YaRN(i_j; s)
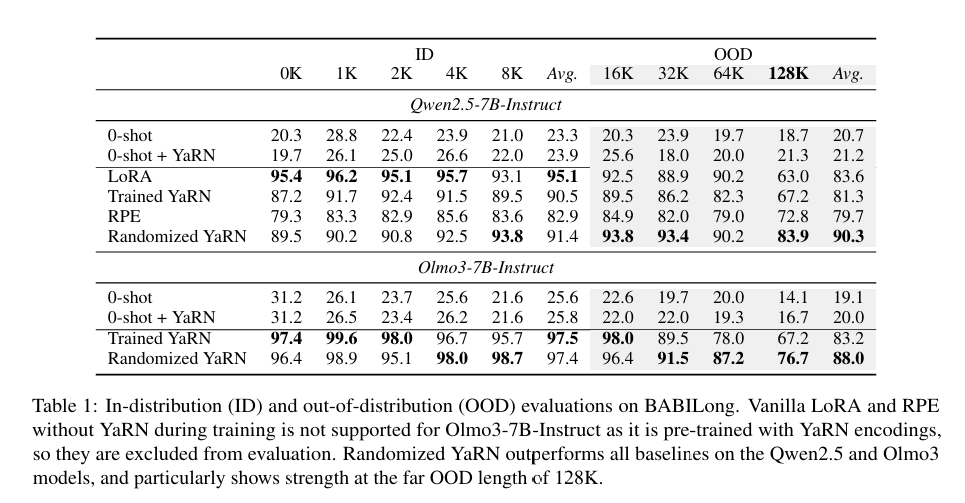
就像让一个只在城市道路开过车的司机,先在模拟器里体验高速公路的感觉虽然路(实际序列)很短,但编码(位置信号)已经在模拟长距离场景。不是一开始就用最大采样范围 L_T,而是逐步增大:
- Epoch 1: L₁ = 8K (中等 OOD 位置)
- Epoch 2: L₂ = 16K (更大 OOD 位置)
…
- Epoch T: L_T = 目标长度

因为直接用大范围 OOD 位置训练会导致训练不稳定,渐进式增大让模型先学会中等外推,再逐步适应**极端外推。**论文实验显示:去掉课程后 OOD 性能下降最高达 18.3%
训练完成后,推理时不需要随机采样。直接使用标准 YaRN:第 j 个 token 的编码 = YaRN(j; s’)其中 s’ 是推理时的缩放因子。论文发现一个惊喜现象:> s’ > s 是可行的 训练时用较小的缩放因子(如 s=2),推理时用更大的(如 s’=4),性能反而更好。
Randomized YaRN 的创新在于:不是发明新的位置编码,而是在训练策略上操作。通过随机化+课程,在短上下文中训练时伪造长距离位置信号,通过课程学习渐进式增大伪造范围,让模型在不接触真正长数据的情况下学会长上下文推理泛化。这是一个以小博大的策略,用极低的训练成本(<5K 样本、<8K 上下文、约 250 GPU 小时)实现 128K 上下文的推理能力,比传统长文本训练方案便宜几个数量级。
需要注意的是,该论文仅验证了了 7B 模型,更大模型例如70B/405B上的效果未知,仅使用了英文数据,对语言的泛化也未验证,对生成任务(如长文本续写)的效果未验证。虽然只需 <5K 样本,但随机位置采样增加了训练复杂度。论文未讨论 Randomized YaRN vs RAG 的权衡
Claude Code的实现思路(2026泄露)
有趣的是2026 年3月31日,Anthropic 的 Claude Code CLI 源码通过 npm 包中未清理的 <font style="color:rgb(31, 35, 40);background-color:rgba(129, 139, 152, 0.12);">.map</font> 文件泄露,由 @Fried_rice 首先公开。Source Map 文件包含了从编译后代码到原始 TypeScript 源码的完整映射,让我们得以窥探在编码方向有着深度研究的Claude Code是如何处理长上下文泛化问题的。
本小节我们不对CC(Claude Code)的整体架构深入,只对它的上下文压缩策略进行深度刨析 仅供学习。
Claude对上下文压缩的设计思路是分层压缩,按需触发
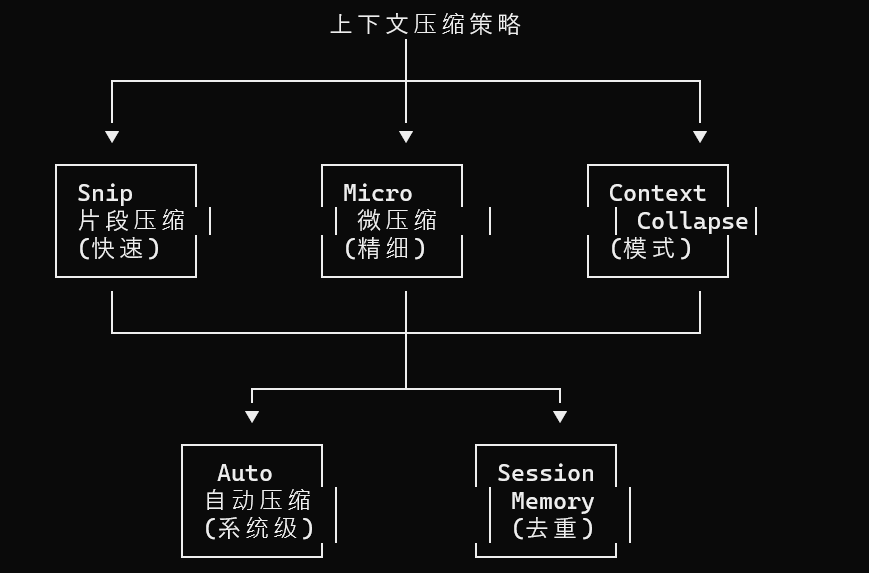
- Snip Compaction(片段压缩)
- 机制:将历史消息中较长的工具输出替换为摘要,例如
**<font style="color:rgb(17, 24, 39);">"此结果已被省略"</font>** - 特点:速度最快,代价是丢失详细信息
- 定位:快速释放空间的第一选择
- Micro Compaction(微压缩)
- 机制:对单条消息内部的冗余内容进行压缩,例如重复的文件路径或代码块
- 特点:精细优化,保留语义完整性
- 定位:在不丢弃整条消息的前提下清理冗余
- Context Collapse(上下文折叠)
- 机制:将多轮相似的工具调用合并为一个摘要,例如
**<font style="color:rgb(17, 24, 39);">"连续读取了5个文件"</font>** - 特点:识别重复模式并消除冗余
- 定位:专门处理工具调用序列中的模式冗余
- Auto Compaction(自动压缩)
- 机制:当 token 使用接近阈值(90%)时触发的完整压缩流程
- 特点:有熔断器(Circuit Breaker)保护——追踪
**<font style="color:rgb(17, 24, 39);">consecutiveFailures</font>**,连续失败超过阈值后停止尝试,防止无限重试 - 定位:系统级的全面压缩兜底
- Session Memory Compaction(会话记忆压缩)
- 机制:将消息内容与已存在于 CLAUDE.md 和记忆系统中的信息进行去重
- 特点:如果信息已经持久化,就无需在上下文中保留
- 定位:与持久化记忆系统联动的智能去重
每种策略针对不同的场景:Snip 快速释放空间,代价是丢失详细信息;Micro 精细优化,保留语义;Context Collapse 减少重复模式的冗余;Auto 系统级别的完整压缩;Session Memory 与持久化记忆的去重。
这五种策略在 Pre-API 阶段按顺序级联调用,形成一个从轻量到重量的压缩管道。
除了预防性的五种压缩策略外,当 API 调用因上下文过大而失败时,查询引擎还有七级错误恢复级联,其中多个级别直接涉及压缩:
Level 2: Collapse Drain(折叠清空)
- 触发条件:上下文过大导致请求失败
- 机制:执行紧急上下文折叠,丢弃最旧的消息
Level 3: Reactive Compact(响应式压缩)
- 触发条件:Collapse Drain 不够时
- 机制:使用 LLM 对历史消息进行有选择的摘要
- 通过
**<font style="color:rgb(17, 24, 39);">hasAttemptedReactiveCompact</font>**标志确保每个查询循环只尝试一次,防止反复压缩
if (!state.hasAttemptedReactiveCompact) {
state.hasAttemptedReactiveCompact = true;
await reactiveCompact(state.messages);
continue; // 重试API调用
}
if (!state.hasAttemptedReactiveCompact) {
state.hasAttemptedReactiveCompact = true;
await reactiveCompact(state.messages);
continue; // 重试API调用
}
Level 4-5: Max Output Tokens 恢复
- Level 4:将输出限制从默认值提升到 64K(一次尝试)
- Level 5:如果仍不够,允许最多3次续接请求,通过注入
**<font style="color:rgb(17, 24, 39);">"Please continue."</font>**用户消息来续接
Claude Code对级联的设计原则是:
- 每种恢复只尝试一次:通过各自的守卫标志(
**<font style="color:rgb(17, 24, 39);">hasAttemptedReactiveCompact</font>**、**<font style="color:rgb(17, 24, 39);">maxOutputTokensRecoveryCount</font>**)防止重入 - 从轻量到重量:先尝试低成本恢复(流式回退),再尝试高成本恢复(LLM 压缩)
- 无交叉影响:每级恢复独立运行,不依赖其他级别的状态
- 90% 阈值:token 使用达到预算的 90% 时停止续接,留出余量
- 递减收益检测:3次以上续接且每次产出少于 500 token 时停止——“表明模型正在’磨蹭’——反复输出无意义的内容来填充 token”
- 子代理不参与预算:子代理完成单一任务后返回,主线程负责全局预算,避免预算争抢
记忆系统与长上下文泛化
记忆系统的入口文件MEMORY.md 有着严格的大小限制:
- 200 行 / 25KB(约 6K-8K tokens)
- 两级截断:先按行截断(200行),再按字节截断(25KB),且在最后一个换行处截断保持行完整性
MEMORY.md 在每个 API 调用中都作为系统提示的一部分发送给模型。过大的 MEMORY.md 会消耗大量 token 预算、降低模型对其他上下文信息的注意力、增加每次 API 调用的成本。
记忆召回机制
记忆系统使用 Sonnet 侧查询而非嵌入搜索来召回相关记忆:
用户消息 → 扫描记忆文件(前30行frontmatter)→ 格式化清单 → Sonnet侧查询
→ 过滤已展示 → 加载内容 → 注入上下文
- 只读前30行 frontmatter 进行快速扫描,避免读取完整文件
- 记忆清单压缩为一行:每个文件
**<font style="color:rgb(17, 24, 39);">路径 | 类型 | 名称: 描述</font>** - 过滤已展示的记忆:通过
**<font style="color:rgb(17, 24, 39);">alreadySurfaced</font>**Set 避免重复注入 - 年龄追踪:用颜色标记(🟢🟡🟠🔴)帮助选择时效性记忆
系统明确排除了可从其他来源推导的信息,这本身就是一种长上下文优化: 
扣留机制(Withholding Mechanism)
它对长上下文管理非常重要。
function yield_or_withhold(event: QueryEvent) {
if (isRecoverableError(event) && !allRecoveryAttempted()) {
withheldEvents.push(event);
} else {
yield event;
}
}
当 API 返回错误(如 **<font style="color:rgb(17, 24, 39);">max_tokens</font>** 被截断),系统会尝试自动恢复。在恢复期间,错误事件被扣留不传给 UI,避免用户看到一个即将被修复的错误。只有当所有恢复尝试都失败后,扣留的错误事件才被释放。这保证了压缩/恢复过程对用户是透明的。
延迟预取(Deferred Prefetches)
启动时的上下文优化,在首次 REPL 渲染完成后才启动一系列预取操作:
async function runDeferredPrefetches() {
initUser();
getUserContext();
prefetchSystemContext();
getRelevantTips();
prefetchAWSCredentials();
prefetchGCPCredentials();
countFilesRoundedRg();
// ...
}
这些预取结果(如系统上下文、用户偏好)后续会作为上下文注入,但延迟获取确保了:
- 不阻塞首次绘制
- 利用用户输入前的 1-3 秒空闲时间
- 如果用户的第一个请求在预取完成前到来,系统会等待相关预取完成
Claude Code 通过工程优化(压缩、恢复、缓存)让有限的上下文窗口发挥最大价值。在通用型商业模型下 这是比学术创新(无限注意力)更务实的解决方案。
上下文泛化被忽视的维度
我们希望"模型不仅要能存(DuoAttention),还得能无限延伸(Infinite Context)" 以及 “模型不仅要能找(大海捞针),还得能懂(复杂推理)”。
无限记忆与压缩 (Infinite Memory & Compressive Transformer)
在本文中提到的无论是 LongRoPE 还是 DuoAttention,本质上还是在优化一个“固定窗口”(Fixed Window)。也就是说我们依然面临一个物理极值:显存终究是有限的,即使窗口大到 1000万 Token,它终究有个头。
在 2026 年,AGI 的目标是“终身学习 (Lifelong Learning)”或“无限流式对话”。我们需要一种机制,让旧的 KV Cache 不是被简单的丢弃(如 DuoAttention 的流式头做法),而是被压缩成长期记忆摘要。
Google DeepMind 在 2024 年提出的 Infini-attention 提供了一种打破物理显存限制的方案:它不再试图存储所有历史,而是试图压缩历史。
《 Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention 》—— 不留上下文:高效的无限上下文变换器,具备无限注意力
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
这项工作引入了一种高效的方法,将基于Transformer的大型语言模型(LLMs)扩展到无限长输入,且具有有限的内存和计算能力。我们提出方法的一个关键组成部分是一种被称为无限注意力的新注意力技术。Infini-attention将压缩记忆融入原版注意力机制,并在单个变换器模块中内置了掩蔽的局部注意力和长期线性注意力机制。我们展示了方法在长上下文语言建模基准测试、100万序列长度的通行密钥上下文块检索以及50万本书摘要任务中(使用1B和8B语言模型)的有效性。我们的方法引入了最小的有界内存参数,并支持了大型语言模型的快速流推断。
Infini-attention 并不是一个新的模型架构,而是对标准 Transformer 注意力层(Attention Layer)的一种改造。它将注意力计算拆分为两部分:局部掩码注意力 (Masked Local Attention) 和 压缩记忆 (Compressive Memory)。
(引述内容来自论文翻译解析)文本被切分成一段段的片段 (Segment):
- **局部注意力 (Local Attention) **
- 对于当前正在处理的片段(比如最新的 2k tokens),模型使用标准的点积注意力(Dot-product Attention)。
- 作用:保持对当前语境的极致敏感度,捕捉复杂的语法和逻辑细节。这保证了模型并没有退化成模糊的 RNN。
- **压缩记忆 (Compressive Memory) **
- 当一个片段处理完,即将滑出窗口时,旧的 KV Cache 不会被丢弃。
- 线性压缩:Infini-attention 利用联想记忆矩阵 (Associative Memory Matrix) 的概念。它将旧的 Key ($ K < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ; " > ) 和 V a l u e ( < / f o n t > <font style="color:rgb(0, 0, 0);">) 和 Value (</font> <fontstyle="color:rgb(0,0,0);">)和Value(</font> V < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ; " > ) 通过外积 ( < / f o n t > <font style="color:rgb(0, 0, 0);">) 通过外积 (</font> <fontstyle="color:rgb(0,0,0);">)通过外积(</font> K^T V < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ; " > ) 的方式累加到一个固定的记忆矩阵 < / f o n t > <font style="color:rgb(0, 0, 0);">) 的方式累加到一个固定的记忆矩阵 </font> <fontstyle="color:rgb(0,0,0);">)的方式累加到一个固定的记忆矩阵</font> M_s $ 中。
- 固定显存:无论过去了多少个 Segment,这个记忆矩阵 $ M_s < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ; " > 的大小是固定的(只与 H i d d e n S i z e 相关,与序列长度 < / f o n t > <font style="color:rgb(0, 0, 0);"> 的大小是固定的(只与 Hidden Size 相关,与序列长度 </font> <fontstyle="color:rgb(0,0,0);">的大小是固定的(只与HiddenSize相关,与序列长度</font> N $ 无关)。这意味着,显存占用不再随长度线性增长,而是常数级 (Constant)。
- 信息的检索与融合
- 当模型需要查询(Query)信息时,它会同时做两件事:
- 看当前的局部窗口(标准 Attention)。
- 去查询那个固定的记忆矩阵 $ M_s $(通过线性注意力 Linear Attention 机制提取信息)。
- 最后,通过一个可学习的门控标量 $ \beta $,将“局部直觉”和“长期记忆”融合在一起。
数学 (Simplified)
传统的 Attention 是存下所有的 $ K < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ; " > 和 < / f o n t > <font style="color:rgb(0, 0, 0);"> 和 </font> <fontstyle="color:rgb(0,0,0);">和</font> V < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ; " > 列表,查询时计算 < / f o n t > <font style="color:rgb(0, 0, 0);"> 列表,查询时计算 </font> <fontstyle="color:rgb(0,0,0);">列表,查询时计算</font> Q \times K^T < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ; " > ,复杂度 < / f o n t > <font style="color:rgb(0, 0, 0);">,复杂度 </font> <fontstyle="color:rgb(0,0,0);">,复杂度</font> O(N^2) < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ; " > 或 < / f o n t > <font style="color:rgb(0, 0, 0);"> 或 </font> <fontstyle="color:rgb(0,0,0);">或</font> O(N) $ 显存。
Infini-attention 的记忆更新更像是一个流式压缩过程:$ M_{new} = M_{old} + \sigma(K)^T V $
查询时:
$ A_{memory} = \frac{\sigma(Q) M_{new}}{\sigma(Q) z_{new}} $
这本质上是将 Linear Attention(线性注意力) 作为长时记忆的存储容器,而保留 Softmax Attention 处理高精度的短期任务。
为什么它是“DuoAttention”后的必然一步?
- 对比 Mamba:Mamba 也压缩状态,但它是通过状态空间方程压缩,虽然快,但在“回溯具体细节”时容易模糊。Infini-attention 保留了 Transformer 的 Query-Key 检索机制,虽然是压缩态,但检索精度通常优于纯 RNN 类模型。
- 对比 DuoAttention:
- DuoAttention (2025 SOTA):通过区分“流式头”和“检索头”,丢弃 90% 不重要的缓存。局限:剩下的 10% 检索头依然会随着时间无限膨胀,最终爆显存。
- Infini-attention (终极方案):它不丢弃,而是将旧信息“折叠”进参数里。优势:理论上它可以处理无限长的上下文,只受限于压缩带来的信息有损程度(Compression Loss)。
形象比喻:办公桌与档案馆
- 标准 Transformer:把几万份文件全部铺在桌子上(显存),桌子满了就死机。
- DuoAttention:把不重要的草稿纸扔掉,只在桌子上保留重要的合同。但如果合同积攒了 10 年,桌子依然会满。
- Infini-attention:
- 桌子上只放最近 1 小时的文件(Local Attention)。
- 旧的文件(无论重要与否),都被扫描成缩微胶卷(Compressive Memory),存入一个无限容量的柜子。
- 当你需要查旧资料时,用特殊的阅读器去扫描胶卷。虽然比直接看纸质文件稍微模糊一点点,但你可以存下一整座图书馆。
从检索到推理评测的进化 (Beyond Retrieval Benchmark)
2024-2025 年间,大模型领域出现了一种通货膨胀现象——模型厂商竞相宣称自己支持 128k、200k 甚至 1M 的上下文。
文章开头引用的**《Lost in the Middle》和中间提到的大海捞针 (Needle In A Haystack)测试,在 2025-2026 年已经属于"及格线测试"。现在的模型(特别是经过 DuoAttention 优化的),找一个具体的"针"已经太容易了。真正的长文本泛化问题,现在的瓶颈在于“多跳推理 (Multi-hop Reasoning)”。即:针 A 在第 100 页,针 B 在第 5000 页,模型需要找到 A 和 B,然后结合两者得出结论 C**。很多模型能找到 A 和 B,但无法在长距离下建立两者的逻辑联系。
《 RULER: What’s the Real Context Size of Your Long-Context Language Models? 》—— RULER:你们的长上下文语言模型的真实上下文大小是多少?
The needle-in-a-haystack (NIAH) test, which examines the ability to retrieve a piece of information (the “needle”) from long distractor texts (the “haystack”), has been widely adopted to evaluate long-context language models (LMs). However, this simple retrieval-based test is indicative of only a superficial form of long-context understanding. To provide a more comprehensive evaluation of long-context LMs, we create a new synthetic benchmark RULER with flexible configurations for customized sequence length and task complexity. RULER expands upon the vanilla NIAH test to encompass variations with diverse types and quantities of needles. Moreover, RULER introduces new task categories multi-hop tracing and aggregation to test behaviors beyond searching from context. We evaluate 17 long-context LMs with 13 representative tasks in RULER. Despite achieving nearly perfect accuracy in the vanilla NIAH test, almost all models exhibit large performance drops as the context length increases. While these models all claim context sizes of 32K tokens or greater, only half of them can maintain satisfactory performance at the length of 32K. Our analysis of Yi-34B, which supports context length of 200K, reveals large room for improvement as we increase input length and task complexity. We open source RULER to spur comprehensive evaluation of long-context LMs.
大海捞针(NIAH)测试,用于考察从长的干扰文本(“干草堆”)中提取信息(“针”)的能力,已被广泛用于评估长上下文语言模型(LM)。然而,这种简单的检索检验仅反映了一种表面的长上下文理解。为了更全面地评估长上下文LM,我们创建了一个新的合成基准RULER,提供灵活配置以实现可定制的序列长度和任务复杂度。RULER在原版NIAH测试基础上扩展,涵盖了不同类型和数量的针头变化。此外,RULER引入了多跳追踪和聚合等新任务类别,以测试超越上下文搜索的行为。我们评估了17个长上下文学习模式,其中包含13个代表性任务。尽管在原版NIAH测试中几乎达到完美准确率,但几乎所有模型在上下文长度增加时性能都会大幅下降。虽然这些模型都声称上下文大小为32K或更大,但只有一半能在32K时保持令人满意的性能。我们对支持20万上下文长度的Yi-34B的分析显示,随着输入长度和任务复杂度的增加,仍有很大改进空间。我们开源 RULER 以促进对长上下文 LM 的全面评估。
核心概念:有效上下文长度 (Effective Context Length)
RULER 提出了一个残酷的概念:宣称长度 (Claimed Context) vs 有效长度 (Effective Context)。
NVIDIA 的研究发现,许多宣称支持 128k 上下文的模型,一旦任务稍微复杂一点,其有效长度(即性能不显著下降的长度)可能只有 4k 到 32k。超过这个阈值,模型虽然不会报错,但开始胡言乱语。
RULER 的四大核心测试
为了测试模型是否真的具备长程注意力,RULER 设计了比“找针”难得多的任务,这些任务强迫模型必须关注整个序列,且不能有丝毫遗忘:
- 1. Variable Tracking (变量追踪) —— 状态维护
- 任务描述:模拟代码执行。在长文本中定义一系列变量赋值操作。例如:
<font style="color:rgb(0, 0, 0);">X = 5</font>… (隔 1000 字) …<font style="color:rgb(0, 0, 0);">Y = X + 2</font>… (隔 5000 字) …<font style="color:rgb(0, 0, 0);">X = Y * 3</font>…
最后问:<font style="color:rgb(0, 0, 0);">X</font>等于多少? - 难度所在:这不能靠简单的语义相似度检索。模型必须像计算机内存一样,按时间顺序维护变量的状态更新。只要漏看中间的一步赋值,最终结果全错。这是对模型**“思维链 (Chain of Thought)”稳定性**的极致考验。
- 任务描述:模拟代码执行。在长文本中定义一系列变量赋值操作。例如:
- 2. Aggregation (信息聚合) —— 全局扫描
- 任务描述:输入大量文本,要求模型统计其中出现频率最高的词,或者对分散在全文的数值求和。
- 难度所在:DuoAttention 等稀疏机制容易在这里翻车。因为“检索头”可能只关注了人名或特定实体,而忽略了普通的词。聚合任务要求模型不能跳读,必须平等地扫描每一个 Token 并维持一个内部计数器。
- 3. Multi-hop Tracing (多跳追踪) —— 逻辑桥接
- 任务描述:针 A 在第 10 页说“张三是李四的老师”,针 B 在第 100 页说“李四不仅没当警察,反而成了罪犯”。
- 问题:“张三的学生后来从事了什么职业?”
- 难度所在:模型必须先检索到 A,解析出实体关系,将其作为新的 Query 去检索 B。很多模型能找到 A 也能找到 B,但无法在相隔 10 万字的情况下建立两者的逻辑连接。
- 4. Famous Works (熟悉度干扰测试)
- 任务描述:使用知名的小说文本,但人为篡改其中的关键信息。
- 难度所在:测试模型是真正从当前的 Long Context 中提取信息,还是在依靠预训练时的记忆(幻觉)来回答问题。
为什么 RULER 在 2026 年至关重要?
在 2026 年,我们构建的不再是简单的 Chatbot,而是 Long-Context Agents (长上下文智能体)。
- 场景 1:代码助手。一个 Agent 读取了整个项目的 10 万行代码。如果它通过不了 Variable Tracking 测试,它就无法理解一个全局变量在不同文件中是如何被修改的,从而给出的重构建议会导致严重的 Bug。
- 场景 2:法律/金融分析。如果它通过不了 Aggregation 测试,它就无法准确统计一份 500 页财报中“风险”一词出现的频率分布,从而误导投资决策。
由此可见,在 DuoAttention 和 Infini-attention 解决了“物理容量”之后,RULER 才是检验 AGI 智商的真正试金石。它标志着长文本技术从像“搜索引擎一样检索 (Retrieval)” 进化到了"像人类一样阅读与推理 (Reasoning)"的新阶段。
参考文献与致谢
部分权威文献来自 Cornell University(美国纽约州私立研究型-康奈尔大学) arxiv.org收录 、****字节跳动(Douyin Group) SAMI 团队以及HuggingFace**** 社区开源及公开评测数据上的证据和论文;
@Solana-井上川美[日本]. 对部分内容、平台及文字进行修正 翻译和发布;
@Solana-上野铃兰[日本]. 对部分内容、平台及文字进行修正 翻译和发布;
@AI精密国际-Arose[菲律宾]. 对表述文章的格式与论文引述进行审核修正;
再次表示感谢。
本文的研究与技术综述离不开全球多个权威科研机构、科技巨头及开源社区的支持。特别致谢以下组织在长上下文领域做出的开创性贡献:
- Google DeepMind:在无限注意力机制(Infini-attention)与记忆压缩领域的探索;
- NVIDIA Research:在硬件加速算法(FlashAttention-3)及长文本评测基准(RULER)上的行业定义级工作;
- Microsoft Research:在位置编码进化搜索(LongRoPE)方面的突破;
- Alibaba Cloud (阿里云) 通义实验室:在稀疏门控注意力(DuoAttention/Qwen)及开源生态上的卓越贡献;
- AI21 Labs:在混合架构(Jamba)设计上的工程创新;
- Meta AI & Mistral AI:其 Llama 与 Mistral 系列模型为长文本扩展提供了最广泛的基座;
- MIT Han Lab & Tsinghua University:在高效推理算法层面的学术支持。
需要注意的是,在本文**《长上下文泛化问题:算力、显存与无限注意力》中仍有多项垂直领域的工程细节未能充分提及(例如 “KV Cache 的 2-bit/4-bit 混合精度量化”、“基于 Ring Attention 的百万级序列分布式训练通信优化**”、“长文本合成数据(Synthetic Data)的构造策略” 等领域的研究)。
参考文献(本文中提及并引用的关键论文):
[1.] 《 Attention Is All You Need 》(注意力就是你所需要的一切 —— Transformer 架构奠基作)
[2.] 《 RoFormer: Enhanced Transformer with Rotary Position Embedding 》(RoFormer:采用旋转位置嵌入的增强型 Transformer)
[3.] 《 Lost in the Middle: How Language Models Use Long Contexts 》(迷失在中间:语言模型如何利用长上下文)
[4.] 《 YaRN: Efficient Context Window Extension of Large Language Models 》(YaRN:大型语言模型的高效上下文窗口扩展)
[5.] 《 LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens 》(LongRoPE:将LLM上下文窗口扩展到超过200万Tokens)
[6.] 《 Mamba: Linear-Time Sequence Modeling with Selective State Spaces 》(Mamba:带有选择性状态空间的线性时间序列架构)
[7.] 《 Jamba: A Hybrid Transformer-Mamba Language Model 》(Jamba:一种混合变换器-Mamba语言模型)
[8.] 《 DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads 》(DuoAttention:高效的长上下文大型语言模型推理,支持检索和流式读头)
[9.] 《 Ring Attention with Blockwise Transformers for Near-Infinite Context 》(用区块式变换器进行环注意力,实现近无限上下文)
[10.] 《 FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision 》(FlashAttention-3:具有异步性和低精度的快速准确注意力)
[11.] 《 Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention 》(不留上下文:高效的无限上下文变换器,具备无限注意力)
[12.] 《 RULER: What’s the Real Context Size of Your Long-Context Language Models? 》(RULER:你们的长上下文语言模型的真实上下文大小是多少?)
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)