
SF-LOC云端数据下载训练与代码解析
关于UCloud(优刻得)旗下的compshare算力共享平台UCloud(优刻得)是中国知名的中立云计算服务商,科创板上市,中国云计算第一股。Compshare GPU算力平台隶属于UCloud,专注于提供高性价4090算力资源,配备独立IP,支持按时、按天、按月灵活计费,支持github、huggingface访问加速。使用下方链接注册可获得20元算力金,免费体验10小时4090云算力。SF-
0. 简介
关于UCloud(优刻得)旗下的compshare算力共享平台
UCloud(优刻得)是中国知名的中立云计算服务商,科创板上市,中国云计算第一股。
Compshare GPU算力平台隶属于UCloud,专注于提供高性价4090算力资源,配备独立IP,支持按时、按天、按月灵活计费,支持github、huggingface访问加速。
使用下方链接注册可获得20元算力金,免费体验10小时4090云算力
https://www.compshare.cn/?ytag=GPU_lovelyyoshino_Lcsdn_csdn_display。
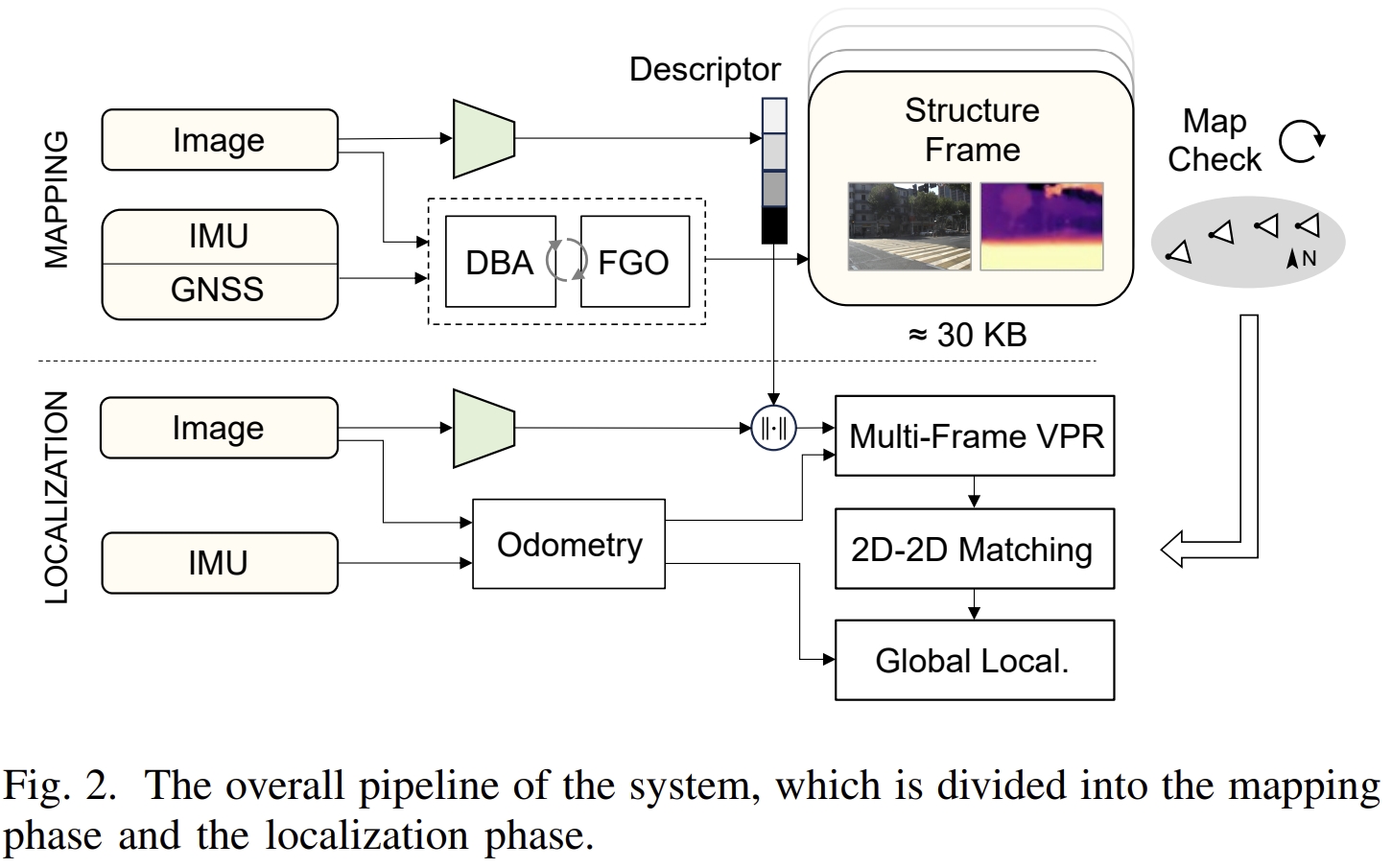
SF-Loc应该算是DBA-Fusion(RAL2024)的改进版。 在image+IMU的基础上额外加了map-aided localization.而所谓的map属于prior map,是由稀疏帧(每帧为稠密的深度)来组成的。而要实现map-aided localization,就需要分别解决mapping以及re-localization的两个问题。 针对mapping,需要考虑的则是建图的效率,地图单元的精度以及存储消耗。通过co-visbility等来保证map的稀疏性,通过紧凑的地图表征,使得每公里的map size降低为3 MB. 至于re-localization,首先其是与地图的表征方式紧耦合的,高的回调率(recall)以及高精度就意味着mapping记录的地图信息需要更仔细。
这里最近受到优刻得的使用邀请,正好解决了我在大模型和自动驾驶行业对GPU的使用需求。UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡1.88元,并附带200G的免费磁盘空间。暂时已经满足我的使用需求了,同时支持访问加速,独立IP等功能,能够更快的完成项目搭建。此外对于低性能的还有3080TI使用只需要0.88元,已经吊打市面上主流的云服务器了。
在这里我们已经装好了所有和CUDA相关的内容,VNC可视化作者也专门提供了可视化操作的docker,https://www.compshare.cn/images-detail?ImageID=compshareImage-18jslxkfacaf&ImageType=Community&ytag=GPU_lovelyyoshino_Lcsdn_csdn_display,我们只需要关注代码的使用即可
1. 数据集下载
在基于服务器的开发过程中,经常需要把数据传到服务器上,使用浏览器的方法就不太行了,下面根据Ubuntu/服务器上通过命令行下载数据给出了三种下载方式
1.1 Onedrive
首先用google浏览器(Chrome)打开OneDrive的分享链接,然后按F12打开开发者工具,切换到Network选项卡。然后点击下载的按钮,可以看到刷新Network选项卡,找到一个以download开头的请求,右键点击,选择Copy -> Copy as cURL(bash格式):
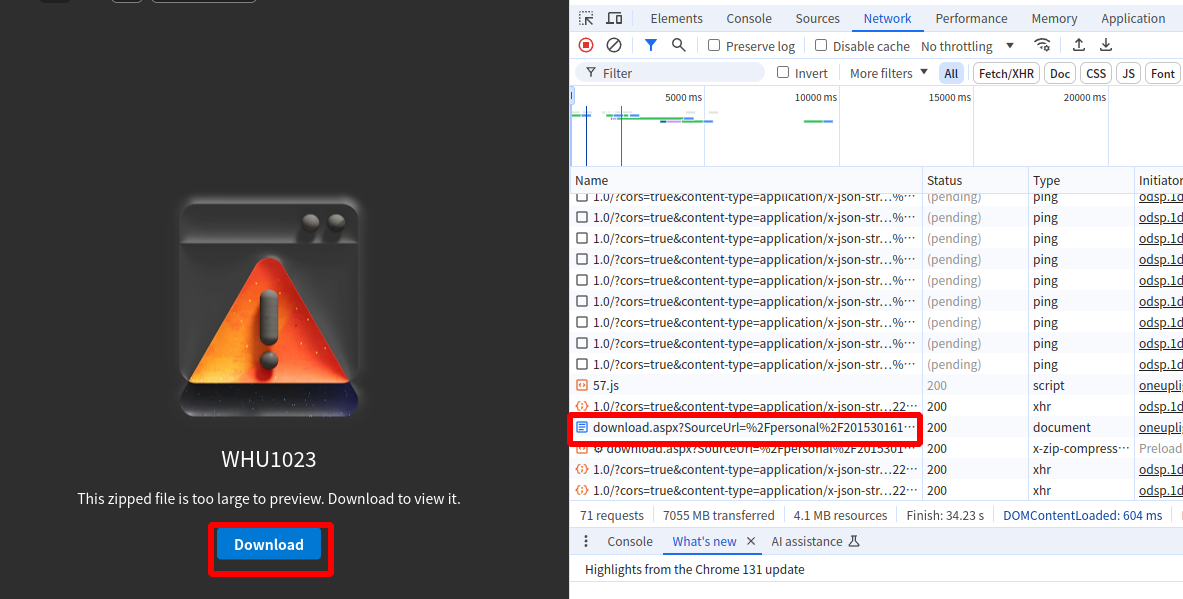
接下来复制到命令行。同时在末端输入–output WHU103.zip。就可以正常下载了。这里注意需要保持下载后缀需要一致
1.2 百度网盘
首先需要安装bypy包: pip install bypy
然后配置百度网盘的账号密码:bypy info。
将命令行提示的链接复制到浏览器,并复制浏览器中的授权码,粘贴到终端并回车(注意是粘贴到终端)
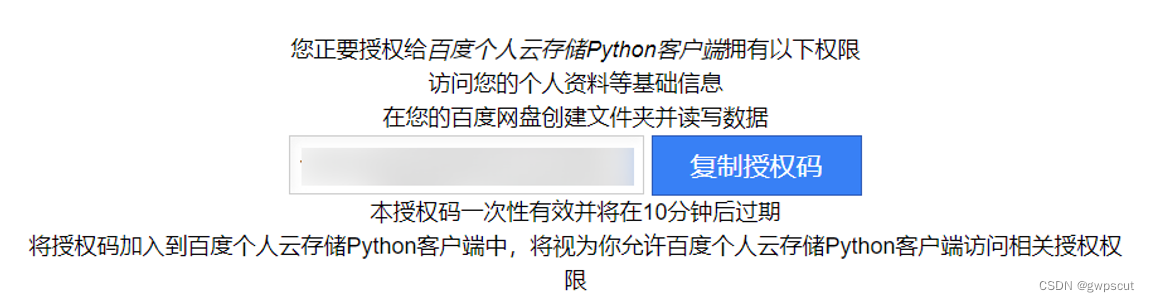

可以看到百度云盘中出现了我的网盘/我的应用数据/bypy文件夹,该文件夹将是服务器与百度云盘间沟通的桥梁。因此,需要将下载的数据放在bypy文件夹中。
常用的命令如下:
# 查看帮助
bypy --help
# 查看网盘文件
bypy list
# 下载文件或目录
bypy download [remotepath] [localpath]
# 上传文件或目录
bypy upload [localpath] [remotepath]
#开多线程加速下载
bypy --downloader aria2 download 远程目录 本地路径
1.3 Google Driver
首先需要下载Gdown pip install gdown 若出现下面报错,则执行pip install --upgrade --no-cache-dir gdown
Access denied with the following error:
Cannot retrieve the public link of the file. You may need to change
the permission to 'Anyone with the link', or have had many accesses.
You may still be able to access the file from the browser:
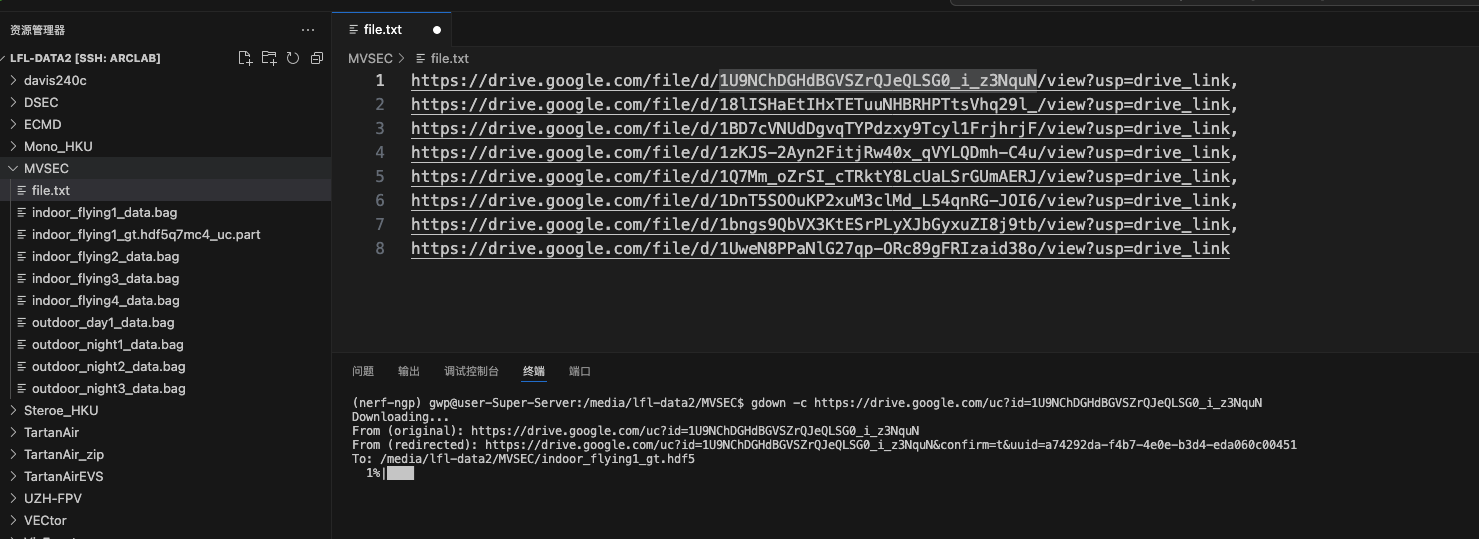
然后通过终端,进入对应的目录下,运行(-c好像是可以实现断点重新下载)。而所谓的标识符就是通过获取分享链接的id得到的,见如下图。
gdown https://drive.google.com/uc?id=标识符
或
gdown -c https://drive.google.com/uc?id=标识符
也可以通过下面代码实现批量式下载
import gdown
import re
# 读取文件ID列表
with open('file_ids.txt', 'r') as file:
for line in file:
url = line.strip()
# 跳过以 # 开头的行
if url.startswith('#'):
continue
# 使用正则表达式提取文件ID
file_id = re.search(r'https://drive\.google\.com/file/d/([^/]+)/', url)
if file_id:
print(f"从 URL 提取文件 ID: {file_id.group(1)}")
file_id = file_id.group(1)
download_url = f"https://drive.google.com/uc?id={file_id}"
# gdown.download(download_url, quiet=False,use_cookies=False)
try:
# 尝试下载文件
gdown.download(download_url, quiet=False)
except PermissionError as e:
print(f"下载文件时发生权限错误: {e}. 将继续下载下一个文件。")
except Exception as e:
print(f"下载文件时发生错误: {e}. 将继续下载下一个文件。")
else:
print(f"无法从 URL 提取文件 ID: {url}")
# gdown https://drive.google.com/uc?id=标识符
2. SF-LOC 部署流程
安装配置:
curl 'https://whueducn-my.sharepoint.com/personal/2015301610143_whu_edu_cn/_layouts/15/download.aspx?SourceUrl=%2Fpersonal%2F2015301610143%5Fwhu%5Fedu%5Fcn%2FDocuments%2FWHU1023%2Ezip' -H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' -H 'accept-language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7' -H 'cookie: FeatureOverrides_experiments=[]; msal.cache.encryption=%7B%22id%22%3A%220194fed5-fe19-7c36-a5f9-f9225727bae7%22%2C%22key%22%3A%22aXfj8Ji6abuIsIqujidMwD_1kbdzR3KjCbdQtIM3QTY%22%7D; MSFPC=GUID=a62228b763c449b08c0743ac7a0a4abc&HASH=a622&LV=202410&V=4&LU=1730084059499; FedAuth=77u/PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0idXRmLTgiPz48U1A+VjEzLDBoLmZ8bWVtYmVyc2hpcHx1cm4lM2FzcG8lM2Fhbm9uI2U0MDIwNTFmYjVjYjQ1YWMyMThlZThkMjhmYjk5ZTU3MGU5ZTRjNDU5MTBkNDU4ODRiNzM5NTdmYWZjNTY4ZmEsMCMuZnxtZW1iZXJzaGlwfHVybiUzYXNwbyUzYWFub24jZTQwMjA1MWZiNWNiNDVhYzIxOGVlOGQyOGZiOTllNTcwZTllNGM0NTkxMGQ0NTg4NGI3Mzk1N2ZhZmM1NjhmYSwxMzM4MzkxNjEyMjAwMDAwMDAsMCwxMzM4NDA2OTMzNDA3MDI4MzcsMC4wLjAuMCwyNTgsOTdkMTk4MzMtZTZiYi00NzIzLTljYjgtYzMzNWVmYTkwM2Y2LCwsMjEyZDJjNmItODVmMi00MTBkLWFmOTQtYTEwNzM5YzEzN2ZmLDJkNTA4MWExLWYwNmItNzAwMC1mMTNhLWRhODg3NjNkZDJmZCx0cEcxeXYxQk9FNm9INFQ1UzdiUjF3LDAsMCwwLCwsLDI2NTA0Njc3NDM5OTk5OTk5OTksMCwsLCwsLCwwLCwxOTI3MzgsdVhlaFFKUGxlVmpOQ2Jha1VoR0Q2SXlGUVFrLGpGak5JR21xL1p1aG5RaFg1MHVWWVF6SmtpckxxT2twZnVZcGVmN2ZnbVRJZExnSiszTy85bFoyRllZRkNkUE56c2RWL3NTd1MrRHhUaEtnS25telprN0xSMXhpeiswbjdPQStoZnowa2VVWmRvRWhRaHVlRW1ZSVdvQ0RQaktITEgwSlI1eGJIQ2hMVnA0S3NnamlDZ2Q1OC9JaG9UQTVCUWtvUVNGaTA1V3ZPRFFTRTZpR2VXS3dGbk1EWkpYdHZJR2hnSEsxVzlmMU1wSXg4Nm1ic2ZvaU53SHByTE0xN2dNY0tndmQ0TTZGeWtaNDVINzJHcnU4cWVYdTBsVXloMHdncndXT3ZKM0pZQ0tUQzI3Uzd0M3plVnNkdEk3Ny92bHBkclVyMjRNWk4yNStOZGdNZTNGN29sMldkNUcvRlIxL3JVNWFPb1pHYnJjSDhxRUVyUT09PC9TUD4=; ai_session=QGejoyJ34EgMXfdZn7QD9o|1739509335642|1739509540532' -H 'priority: u=0, i' -H 'referer: https://whueducn-my.sharepoint.com/personal/2015301610143_whu_edu_cn/_layouts/15/onedrive.aspx?id=%2Fpersonal%2F2015301610143%5Fwhu%5Fedu%5Fcn%2FDocuments%2FWHU1023%2Ezip&parent=%2Fpersonal%2F2015301610143%5Fwhu%5Fedu%5Fcn%2FDocuments&ga=1' -H 'sec-ch-ua: "Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"' -H 'sec-ch-ua-mobile: ?0' -H 'sec-ch-ua-platform: "Linux"' -H 'sec-fetch-dest: iframe' -H 'sec-fetch-mode: navigate' -H 'sec-fetch-site: same-origin' -H 'sec-fetch-user: ?1' -H 'service-worker-navigation-preload: {"supportsFeatures":[1855,61313]}' -H 'upgrade-insecure-requests: 1' -H 'user-agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36' --output WHU1023.zip
git clone --recurse-submodules https://github.com/GREAT-WHU/SF-Loc.git
cd SF-Loc
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu121
pip install torch-scatter -f https://data.pyg.org/whl/torch-2.1.0+cu121.html
pip install gdown tqdm numpy==1.25.0 numpy-quaternion==2022.4.3 opencv-python==4.7.0.72 scipy pyparsing matplotlib h5py
pip install ninja
pip install einops
pip install scikit-learn
pip install open3d
安装第三方库及GTSAM
cd thirdparty
git clone https://github.com/yuxuanzhou97/gtsam.git
cd gtsam
mkdir build
cd build
cmake .. -DGTSAM_BUILD_PYTHON=1 -DGTSAM_PYTHON_VERSION=3.10.11
make python-install
安装运行
cd SF_Loc
python setup.py install
mkdir model && cd model
gdown -c https://drive.google.com/uc?id=1PpqVt1H4maBa_GbPJp4NwxRsd9jk-elh
CUDA_VISIBLE_DEVICES=0 python launch_dba.py
我们来分别看一看输入的数据集格式和经过launch_dba后得到的数据
2.1 输入数据集
gt.txt
- 内容描述:该文件主要记录了一系列与定位相关的信息,包括时间、位置、速度和姿态等。目前来看这个是多源数据融合,以10HZ记录
- 数据字段:
- GPS时间:以周为单位的秒数,标识测量的具体时间点。
- 位置坐标(teb-x, teb-y, teb-z):在三维空间中的位置,以米为单位。
- 速度(veb-x, veb-y, veb-z):在三维空间中的速度,以米每秒为单位。
- 四元数(qnb-x, qnb-y, qnb-z, qnb-w):用于表示姿态的四元数,提供物体的旋转信息。
- 信号状态:指示数据的可靠性,例如“Float”表示浮点解。
- PDOP:位置精度下降因子,越小表示定位精度越高。
- Q:与定位质量相关的参数。
- 卫星数量:用于定位的卫星数量。
rtk.txt
- 内容描述:此文件记录了实时动态定位(RTK)系统的数据,提供高精度的位置和速度信息。这个是以1HZ频率发送
- 数据字段:
- GPS时间:同样以周为单位的秒数,标识数据采集的时刻。
- ECEF坐标(X、Y、Z):地心地固坐标系中的位置,以米为单位。
- 速度(Vx、Vy、Vz):在ECEF坐标系下的速度,以米每秒为单位。
- RMS误差(X-RMS, Y-RMS, Z-RMS, Vx-RMS, Vy-RMS, Vz-RMS):各坐标和速度的均方根误差,表示测量的不确定性。
- 卫星数量:参与定位计算的卫星个数。
- PDOP:位置精度下降因子,反映定位精度。
- 其他状态信息:包括信号的固定状态、质量、比率等。
stamp.txt
- 内容描述:该文件记录了图像采集的时间戳与对应的图像文件名之间的关系。
- 数据字段:
- 时间戳:表示图像采集时的具体时间,通常以秒为单位。
- 图像文件名:对应时间戳的图像文件名称,指向具体的图像数据。
imu.txt
- 内容描述:记录了惯性测量单元(IMU)的传感器数据,用于捕捉设备的运动状态。
- 数据字段:
- GPS时间:以周为单位的秒数,标识数据的采集时间。
- 角速度(gx, gy, gz):设备在三个轴向的旋转速度,以度每秒为单位。
- 加速度(ax, ay, az):设备在三个轴向的线性加速度,以米每二次方秒为单位。
2.2 输出数据
launch_dba相当于进行mapping的过程,会生成以下三个结果
poses_realtime.txt
- 内容描述:该文件记录了通过在线多传感器动态基于图的优化(DBA)方法估计的IMU位姿信息。
- 数据字段:
- 世界坐标系中的位姿:表示设备在地理空间中的位置和方向,通常包括位置坐标(x, y, z)和姿态(如四元数或欧拉角)。
- ECEF坐标系中的位姿:表示设备在地心地固坐标系中的位置,提供与全球定位系统(GPS)数据的一致性。
- 用途:这些位姿信息可用于实时监测设备的位置和方向,支持导航、地图构建等应用。
graph.pkl
- 内容描述:该文件以序列化的形式存储了GTSAM(Georgia Tech Smoothing And Mapping)框架中的因子图信息。
- 数据字段:
- 因子:表示不同传感器数据之间的关系,包括位姿因子、观测因子等,构成图的节点和边。
- 变量:节点代表要优化的变量,如位姿和特征点。
- 约束:边代表不同节点之间的约束关系,通常由传感器观测获得。
- 用途:通过使用GTSAM进行图优化,可以提高多传感器融合的精度和鲁棒性,常用于SLAM(同步定位与地图构建)等任务。
depth_video.pkl
- 内容描述:该文件存储了通过动态基于图的优化(DBA)方法估计的稠密深度信息。
- 数据字段:
- 稠密深度图:表示相机视野中每个像素点的深度值,通常以米为单位,提供场景的三维结构信息。
- 时间戳或帧信息:可能与深度图对应的图像帧或时间戳,便于与其他传感器数据对齐。
- 用途:稠密深度信息可用于三维重建、对象识别和环境感知等领域,增强计算机视觉任务的效果。
进行定位、获取GTSAM的因子图以及DBA生成的Depth map。然后运行下面代码进行全局图优化
python sf-loc/post_optimization.py --graph results/graph.pkl --result_file results/poses_post.txt
然后我们会有结果poses_post.txt ,这个里面是输出的优化结果
接下来再通过下面代码来稀疏化关键帧地图
python sf-loc/sparsify_map.py --imagedir ./WHU1023/image_undist/cam0 --imagestamp ../WHU1023/stamp.txt --depth_video results/depth_video.pkl --poses_post results/poses_post.txt --calib calib/1023.txt --map_indices results/map_indices.pkl
map_indices.pkl
- 内容描述:该文件包含了地图帧的索引和时间戳,指示了一组特定的动态基于图的优化(DBA)关键帧。
- 数据字段:
- 地图帧索引:表示选定关键帧在整个序列中的位置索引。这些索引用于快速访问和处理特定的帧数据。
- 时间戳:与每个关键帧对应的时间信息,通常以秒为单位,表示帧被采集的具体时刻。
- 用途:通过指定关键帧的索引和时间戳,研究人员或工程师可以有效地管理和调用重要的地图数据,支持后续的处理和分析,例如重建、可视化或进一步的优化。
map_stamps.txt
- 内容描述:该文件记录了每个地图帧的时间戳,与
map_indices.pkl中的关键帧索引相对应。 - 数据字段:
- 时间戳:每行通常包含一个时间戳,指示相应地图帧的采集时刻。
- 用途:这些时间戳提供了关键帧的时间参考,便于与其他传感器数据(如图像或IMU数据)进行同步和对齐,确保多传感器数据在时间上的一致性。
运行下面代码来生成lightweight structure frame map.同时通过VPR-methods-evaluation中所提供的脚本可以很方便的使用不同的VRP方法。
python sf-loc/generate_sf_map.py --imagedir ../WHU1023/image_undist/cam0 --imagestamp ../WHU1023/stamp.txt --depth_video results/depth_video.pkl --poses_post results/poses_post.txt --calib calib/1023.txt --map_indices results/map_indices.pkl --map_file sf_map.pkl
sf_map.pkl
-
内容描述:该文件包含了结构帧地图(Structure Frame Map),是进行重新定位(re-localization)所需的所有信息。
-
数据字段:
- 帧数据:存储了关键帧的位姿信息,包括位置和姿态,通常以矩阵或四元数的形式表示。
- 特征点:包含与每个帧相关的三维特征点的坐标信息。这些特征点有助于在环境中识别和匹配。
- 连接关系:描述不同帧之间的空间关系,可能包括关键帧之间的相对变换信息,帮助建立整个地图的连通性。
- 其他元数据:可能包括有关帧的时间戳、采样频率、传感器类型等附加信息。
-
用途:
- 重新定位:结构帧地图为设备在未知环境中重新定位提供了基础数据。当设备失去定位时,可以通过匹配当前观测到的特征与结构帧地图中的特征来恢复位姿。
- 环境理解:通过结构帧地图,系统能够更好地理解环境的几何结构,从而提高导航和决策能力。
- 地图构建:在实时操作中,结构帧地图可以作为动态更新的地图,支持持续的环境感知和地图构建。

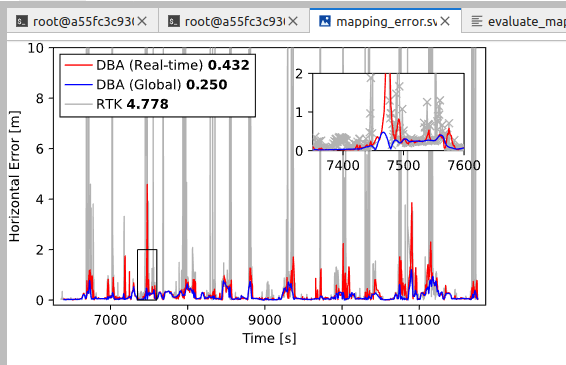
最后就可以使用下面的脚本来生成期望的评估指标
python scripts/evaluate_map_poses.py
3. 代码阅读解析
3.1 dbaf.py
这段代码定义了一个DBAFusion类,用于实现基于视觉的定位和映射(SLAM)功能。该类首先加载模型权重,然后利用输入的视频流进行跟踪和本地束调整,并能将其计算出的结果序列可视化并保存至指定路径。
import torch
import lietorch
import numpy as np
from droid_net import DroidNet
from depth_video import DepthVideo
from motion_filter import MotionFilter
from dbaf_frontend import DBAFusionFrontend
from collections import OrderedDict
from torch.multiprocessing import Process
from lietorch import SE3
import geom.projective_ops as pops
import droid_backends
import pickle
class DBAFusion:
def __init__(self, args):
super(DBAFusion, self).__init__()
self.load_weights(args.weights) # 加载DroidNet模型权重
self.args = args
# 存储图像、深度、位姿和内参(在进程之间共享)
self.video = DepthVideo(args.image_size, args.buffer, save_pkl=args.save_pkl, stereo=args.stereo, upsample=args.upsample)
# 过滤传入的帧,以确保有足够的运动
self.filterx = MotionFilter(self.net, self.video, thresh=args.filter_thresh)
# 前端处理过程
self.frontend = DBAFusionFrontend(self.net, self.video, self.args)
self.frontend.filterx = self.filterx # 将过滤器关联到前端
self.pklpath = args.pklpath # 保存路径
self.upsample = args.upsample # 上采样标志
def load_weights(self, weights):
"""加载训练好的模型权重"""
print(weights)
self.net = DroidNet() # 创建DroidNet实例
state_dict = OrderedDict([
(k.replace("module.", ""), v) for (k, v) in torch.load(weights).items()])
# 只保留部分参数,可能是出于GPU memory限制或模型结构变化的原因
state_dict["update.weight.2.weight"] = state_dict["update.weight.2.weight"][:2]
state_dict["update.weight.2.bias"] = state_dict["update.weight.2.bias"][:2]
state_dict["update.delta.2.weight"] = state_dict["update.delta.2.weight"][:2]
state_dict["update.delta.2.bias"] = state_dict["update.delta.2.bias"][:2]
self.net.load_state_dict(state_dict) # 加载权重到模型中
self.net.to("cuda:0").eval() # 转移模型到GPU并设置为评估模式
def track(self, tstamp, image, depth=None, intrinsics=None):
"""主线程 - 更新地图"""
with torch.no_grad(): # 禁用梯度计算
# 检查是否有足够的移动
self.filterx.track(tstamp, image, depth, intrinsics)
# 本地束调整(优化地图)
self.frontend()
def terminate(self, stream=None):
"""终止可视化进程,返回位姿[t, q]"""
del self.frontend # 删除前端引用以释放资源
def save_vis_easy(self):
mcameras = {} # 存储相机位姿
mpoints = {} # 存储三维点云
mstamps = {} # 存储时间戳
mdisps = {} # 存储位移信息
with torch.no_grad():
dirty_index = torch.arange(0, self.video.count_save, device='cuda') # 获取待保存数据的索引
# 对必要的数据进行选择,从视频记录中选取对应的信息
stamps = torch.index_select(self.video.tstamp_save, 0, dirty_index)
poses = torch.index_select(self.video.poses_save, 0, dirty_index)
disps = torch.index_select(self.video.disps_save, 0, dirty_index)
images = torch.index_select(self.video.images_save, 0, dirty_index)
Ps = SE3(poses).inv().matrix().cpu().numpy() # 计算位姿逆矩阵
points = droid_backends.iproj(SE3(poses).inv().data, disps, self.video.intrinsics[0]).cpu() # 反投影获得三维点
thresh = 0.4 * torch.ones_like(disps.mean(dim=[1, 2])) / 4.0 * (1.0 / torch.median(disps.mean(dim=[1, 2]))) # 设置阈值
count = droid_backends.depth_filter(
self.video.poses_save, self.video.disps_save, self.video.intrinsics[0], dirty_index, thresh) # 深度过滤
count = count.cpu()
disps = disps.cpu()
if self.upsample:
disps_up = torch.index_select(self.video.disps_up_save, 0, dirty_index) # 如果需要,则获取上采样结果
disps_up = disps_up.cpu()
masks = ((count >= 1) & (disps > .5 * disps.mean(dim=[1, 2], keepdim=True))) # 根据计数和深度生成掩码
for i in range(len(dirty_index)):
pose = Ps[i] # 当前帧的位姿
ix = dirty_index[i].item() # 当前帧的索引
mcameras[ix] = pose # 将位姿存入字典
mask = masks[i].reshape(-1) # 重塑掩码形状
pts = points[i].reshape(-1, 3)[mask].cpu().numpy() # 筛选3D点
clr = images[i].reshape(-1, 3)[mask].cpu().numpy() # 筛选颜色
stamp = stamps[i].cpu() # 获取当前帧的时间戳
# 根据是否上采样来构建不同格式的数据
if self.upsample:
mpoints[ix] = {'pts': pts, 'clr': clr, 'disp': disps[i].cpu().numpy(), 'disps_up': disps_up[i].cpu().numpy(), 'rgb': images[i].cpu().numpy()}
else:
mpoints[ix] = {'pts': pts, 'clr': clr, 'disp': disps[i].cpu().numpy(), 'rgb': images[i].cpu().numpy()}
mstamps[ix] = stamp # 存储时间戳
mdisps[ix] = disps[i].numpy() # 存储位移信息
# 构造最终的字典,将所有数据一起保存
ddict = {'points': mpoints, 'cameras': mcameras, 'stamps': mstamps, 'disps': mdisps, 'Tic': self.video.Ti1c, 'xyz_ref': self.video.ten0}
f_save = open(self.pklpath, 'wb') # 打开文件以写入
pickle.dump(ddict, f_save) # 使用pickle库将数据保存到文件
所有和droid_backends相关的其实是CUDA封装
setup(
name='droid_backends',
ext_modules=[
CUDAExtension('droid_backends',
include_dirs=[osp.join(ROOT, 'thirdparty/eigen')],
sources=[
'src/droid.cpp',
'src/droid_kernels.cu',
'src/correlation_kernels.cu',
'src/altcorr_kernel.cu',
],
extra_compile_args={
'cxx': ['-O3'],
'nvcc': ['-O3',
'-gencode=arch=compute_60,code=sm_60',
'-gencode=arch=compute_61,code=sm_61',
'-gencode=arch=compute_70,code=sm_70',
'-gencode=arch=compute_75,code=sm_75',
'-gencode=arch=compute_80,code=sm_80',
'-gencode=arch=compute_86,code=sm_86',
]
}),
],
cmdclass={ 'build_ext' : BuildExtension }
)
3.2 motion_filter.py
下面的操作就是来根据运动来筛选判断对应在深度预估的情况下,在累计一段距离后可以作为关键帧来进行保存
import cv2
import torch
import lietorch
from collections import OrderedDict
from droid_net import DroidNet
import geom.projective_ops as pops
from modules.corr import CorrBlock
import numpy as np
class MotionFilter:
"""
该类用于过滤输入帧并提取特征
"""
def __init__(self, net, video, thresh=2.5, device="cuda:0"):
"""
初始化MotionFilter类的实例
参数:
- net: 包含网络模块的对象
- video: 视频数据对象,用于存储处理过的帧
- thresh: 用于判断运动阈值的浮点数,默认为2.5
- device: 指定使用的设备(如"cuda:0")
"""
# 分离网络模块
self.cnet = net.cnet # 上下文网络
self.fnet = net.fnet # 特征网络
self.update = net.update # 更新函数
self.video = video # 视频对象
self.thresh = thresh # 阈值
self.device = device # 设备
self.count = 0 # 帧计数器
# 图像归一化的均值和标准差
self.MEAN = torch.as_tensor([0.485, 0.456, 0.406], device=self.device)[:, None, None]
self.STDV = torch.as_tensor([0.229, 0.224, 0.225], device=self.device)[:, None, None]
@torch.cuda.amp.autocast(enabled=True)
def __context_encoder(self, image):
"""
提取上下文特征
参数:
- image: 输入图像张量
返回:
- net: 上下文特征
- inp: 中间特征
"""
net, inp = self.cnet(image).split([128, 128], dim=2) # 将输出分为两部分
return net.tanh().squeeze(0), inp.relu().squeeze(0)
@torch.cuda.amp.autocast(enabled=True)
def context_encoder(self, image):
"""
提取上下文特征
参数:
- image: 输入图像张量
返回:
- net: 上下文特征
- inp: 中间特征
"""
net, inp = self.cnet(image).split([128, 128], dim=2) # 将输出分为两部分
return net.tanh().squeeze(0), inp.relu().squeeze(0)
@torch.cuda.amp.autocast(enabled=True)
def __feature_encoder(self, image):
"""
提取用于相关体积的特征
参数:
- image: 输入图像张量
返回:
- 特征张量
"""
return self.fnet(image).squeeze(0) # 从特征网络中获取特征并去掉多余维度
@torch.cuda.amp.autocast(enabled=True)
def feature_encoder(self, image):
"""
提取用于相关体积的特征
参数:
- image: 输入图像张量
返回:
- 特征张量
"""
return self.fnet(image).squeeze(0) # 从特征网络中获取特征并去掉多余维度
@torch.cuda.amp.autocast(enabled=True)
@torch.no_grad()
def track(self, tstamp, image, depth=None, intrinsics=None):
"""
主更新操作 - 在视频中的每一帧上运行
参数:
- tstamp: 当前时间戳
- image: 当前帧图像
- depth: 深度信息(可选)
- intrinsics: 内部参数(可选)
"""
Id = lietorch.SE3.Identity(1,).data.squeeze() # 创建单位变换矩阵
ht = image.shape[-2] // 8 # 高度缩放因子
wd = image.shape[-1] // 8 # 宽度缩放因子
# 归一化图像
inputs = image[None, :, [2, 1, 0]].to(self.device) / 255.0 # 转换为张量并归一化
inputs = inputs.sub_(self.MEAN).div_(self.STDV) # 减去均值并除以标准差
# 提取特征
gmap = self.__feature_encoder(inputs) # 当前帧的特征, fnet
### 始终将第一帧添加到深度视频 ###
if self.video.counter.value == 0:
net, inp = self.__context_encoder(inputs[:, [0]]) # 获取上下文特征
self.net, self.inp, self.fmap = net, inp, gmap # 保存当前状态
self.video.append(tstamp, image[0], Id, 1.0, depth, intrinsics / 8.0, gmap, net[0, 0], inp[0, 0]) # 添加到视频
### 仅在有足够运动时添加新帧 ###
else:
# 索引相关体积
coords0 = pops.coords_grid(ht, wd, device=self.device)[None, None] # 创建坐标网格
corr = CorrBlock(self.fmap[None, [0]], gmap[None, [0]])(coords0) # 计算关键帧与当前帧之间的相关性
# 使用一次更新迭代近似流动幅度
_, delta, weight = self.update(self.net[None], self.inp[None], corr) # 更新状态并计算变化量
print(tstamp, 'motion: %f' % delta.norm(dim=-1).mean().item()) # 打印运动幅度
# 检查运动幅度 / 将新帧添加到视频
if delta.norm(dim=-1).mean().item() > self.thresh: # 如果运动幅度超过阈值
self.count = 0 # 重置计数器
net, inp = self.__context_encoder(inputs[:, [0]]) # 获取新的上下文特征
self.net, self.inp, self.fmap = net, inp, gmap # 更新状态
self.video.append(tstamp, image[0], None, None, depth, intrinsics / 8.0, gmap, net[0], inp[0]) # 添加到视频
else:
self.count += 1 # 增加计数器
3.3 depth_video.py
import numpy as np
import torch
import lietorch
import droid_backends
from torch.multiprocessing import Process, Queue, Lock, Value
from droid_net import cvx_upsample
import geom.projective_ops as pops
from multi_sensor import MultiSensorState
import gtsam
from gtsam.symbol_shorthand import B, V, X
from scipy.spatial.transform import Rotation
import copy
import logging
import geoFunc.trans as trans
from lietorch import SE3
import cv2
import matplotlib.cm as cm
import matplotlib
import pickle
def BA2GTSAM(H: np.ndarray, v: np.ndarray, Tbc: gtsam.Pose3):
"""
将给定的Hessian矩阵和向量转换为GTSAM格式。
参数:
H (np.ndarray): Hessian矩阵,形状为(n, n)。
v (np.ndarray): 向量,形状为(n,)。
Tbc (gtsam.Pose3): 变换矩阵,用于坐标系转换。
返回:
tuple: 转换后的Hessian矩阵和向量。
"""
A = -Tbc.inverse().AdjointMap() # 获取逆变换的伴随矩阵并取负
A = np.concatenate([A[3:6,:],A[0:3,:]],axis=0) # 重排矩阵以适应后续计算
ss = H.shape[0]//6 # 每个状态变量对应6维
J = np.zeros_like(H) # 初始化Jacobian矩阵
for i in range(ss):
J[(i*6):(i*6+6),(i*6):(i*6+6)] = A # 填充Jacobian矩阵
JT = J.T # 计算Jacobian的转置
return np.matmul(np.matmul(JT,H),J),np.matmul(JT,v) # 返回转换后的Hessian和向量
def CustomHessianFactor(values: gtsam.Values, H: np.ndarray, v: np.ndarray):
"""
创建自定义Hessian因子用于GTSAM优化。
参数:
values (gtsam.Values): 包含当前估计值的字典。
H (np.ndarray): Hessian矩阵。
v (np.ndarray): 向量。
返回:
gtsam.LinearContainerFactor: GTSAM中的线性容器因子。
"""
info_expand = np.zeros([H.shape[0]+1,H.shape[1]+1]) # 扩展信息矩阵
info_expand[0:-1,0:-1] = H # 填充Hessian部分
info_expand[0:-1,-1] = v # 填充向量部分
info_expand[-1,-1] = 0.0 # 最后一项无意义
h_f = gtsam.HessianFactor(values.keys(),[6]*len(values.keys()),info_expand) # 创建Hessian因子
l_c = gtsam.LinearContainerFactor(h_f,values) # 创建线性容器因子
return l_c # 返回线性容器因子
class DepthVideo:
def __init__(self, image_size=[480, 640], buffer=1024, save_pkl=False, stereo=False, upsample=False, device="cuda:0"):
"""
深度视频类初始化,设置图像大小、缓冲区等属性。
参数:
image_size (list): 图像尺寸,默认为[480, 640]。
buffer (int): 缓冲区大小,默认为1024。
save_pkl (bool): 是否保存为pkl文件,默认为False。
stereo (bool): 是否使用立体视觉,默认为False。
upsample (bool): 是否进行上采样,默认为False。
device (str): 使用的设备,默认为"cuda:0"。
"""
# 当前关键帧计数
self.counter = Value('i', 0)
self.ready = Value('i', 0)
self.ht = ht = image_size[0]
self.wd = wd = image_size[1]
### 状态属性 ###
self.tstamp = torch.zeros(buffer, device="cuda", dtype=torch.float64).share_memory_() # 时间戳
self.images = torch.zeros(buffer, 3, ht, wd, device="cuda", dtype=torch.uint8) # 图像数据
self.dirty = torch.zeros(buffer, device="cuda", dtype=torch.bool).share_memory_() # 脏标志
self.red = torch.zeros(buffer, device="cuda", dtype=torch.bool).share_memory_() # 红色标志
self.poses = torch.zeros(buffer, 7, device="cuda", dtype=torch.float).share_memory_() # 位姿
self.disps = torch.ones(buffer, ht//8, wd//8, device="cuda", dtype=torch.float).share_memory_() # 深度图
self.disps_sens = torch.zeros(buffer, ht//8, wd//8, device="cuda", dtype=torch.float).share_memory_() # 感知深度图
self.disps_up = torch.zeros(buffer, ht, wd, device="cuda", dtype=torch.float).share_memory_() # 上采样深度图
self.intrinsics = torch.zeros(buffer, 4, device="cuda", dtype=torch.float).share_memory_() # 内参
self.stereo = stereo
c = 1 if not self.stereo else 2 # 根据是否立体选择通道数
### 特征属性 ###
self.fmaps = torch.zeros(buffer, c, 128, ht//8, wd//8, dtype=torch.half, device="cuda").share_memory_() # 特征图
self.nets = torch.zeros(buffer, 128, ht//8, wd//8, dtype=torch.half, device="cuda").share_memory_() # 网络输出
self.inps = torch.zeros(buffer, 128, ht//8, wd//8, dtype=torch.half, device="cuda").share_memory_() # 输入数据
# 初始化位姿为单位变换
self.poses[:] = torch.as_tensor([0, 0, 0, 0, 0, 0, 1], dtype=torch.float, device="cuda")
### DBAFusion
# 用于.pickle保存
self.disps_save = torch.ones(25000, ht//8, wd//8, device="cuda", dtype=torch.float) # 保存深度图
self.poses_save = torch.ones(25000, 7, device="cuda", dtype=torch.float) # 保存位姿
self.tstamp_save = torch.zeros(25000, device="cuda", dtype=torch.float64) # 保存时间戳
self.images_save = torch.zeros(25000, ht//8, wd//8, 3, device="cuda", dtype=torch.float) # 保存图像
if upsample:
self.disps_up_save = torch.zeros(25000, ht, wd, device="cuda", dtype=torch.float).share_memory_() # 保存上采样结果
self.count_save = 0 # 保存计数器
self.save_pkl = save_pkl # 是否保存为pkl
self.upsample_flag = upsample # 上采样标志
self.state = MultiSensorState() # 多传感器状态
self.last_t0 = 0 # 上一个时间点t0
self.last_t1 = 0 # 上一个时间点t1
self.cur_graph = None # 当前图
self.cur_result = None # 当前结果
self.marg_factor = None # 边缘化因子
self.prior_factor = [] # 先验因子列表
self.prior_factor_map = {} # 先验因子映射
self.cur_ii = None # 当前索引ii
self.cur_jj = None # 当前索引jj
self.cur_target = None # 当前目标
self.cur_weight = None # 当前权重
self.cur_eta = None # 当前eta
self.imu_enabled = False # IMU使能标志
self.ignore_imu = False # 忽略IMU标志
self.xyz_ref = [] # XYZ参考
# 外部参数,需要在主.py中设置
self.Ti1c = None # 形状 = (4,4)
self.Tbc = None # gtsam.Pose3
self.tbg = None # 形状 = (3)
self.reinit = False # 重新初始化标志
self.vi_init_t1 = -1 # VI初始化时间t1
self.vi_init_time = 0.0 # VI初始化时间
self.gnss_init_t1 = -1 # GNSS初始化时间t1
self.gnss_init_time = 0.0 # GNSS初始化时间
self.ten0 = None # 初始位置
self.init_pose_sigma = np.array([0.1, 0.1, 0.0001, 0.0001, 0.0001, 0.0001]) # 初始化位姿标准差
self.init_bias_sigma = np.array([1.0, 1.0, 1.0, 0.1, 0.1, 0.1]) # 初始化偏置标准差
self.logger = logging.getLogger('dba_fusion') # 日志记录器
self.logger.setLevel(logging.DEBUG) # 设置日志级别
fh = logging.FileHandler('dba_fusion.log') # 文件处理器
formatter = logging.Formatter('%(msecs)d - %(name)s - %(levelname)s - %(message)s') # 日志格式
fh.setFormatter(formatter) # 应用格式
# 添加处理器到记录器
self.logger.addHandler(fh)
self.logger.info('Start logging!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!') # 开始日志记录
self.pkl_counter = 0 # pkl计数器
self.rollup_sum = 0 # 汇总和
def get_lock(self):
""" 获取计数器锁 """
return self.counter.get_lock()
def __item_setter(self, index, item):
"""
设置指定索引的项目,包括时间戳、图像、位姿等。
参数:
index (int or torch.Tensor): 索引,可以是整数或张量。
item (tuple): 包含要设置的数据元组。
"""
if isinstance(index, int) and index >= self.counter.value:
self.counter.value = index + 1 # 更新计数器
elif isinstance(index, torch.Tensor) and index.max().item() > self.counter.value:
self.counter.value = index.max().item() + 1 # 更新计数器
self.tstamp[index] = item[0] # 设置时间戳
self.images[index] = item[1] # 设置图像
if item[2] is not None:
self.poses[index] = item[2] # 设置位姿
if item[3] is not None:
self.disps[index] = item[3] # 设置深度图
if item[4] is not None:
depth = item[4][3::8,3::8] # 下采样深度图
self.disps_sens[index] = torch.where(depth>0, 1.0/depth, depth) # 设置感知深度图
if item[5] is not None:
self.intrinsics[index] = item[5] # 设置内参
if len(item) > 6:
self.fmaps[index] = item[6] # 设置特征图
if len(item) > 7:
self.nets[index] = item[7] # 设置网络输出
if len(item) > 8:
self.inps[index] = item[8] # 设置输入数据
def __setitem__(self, index, item):
"""
支持通过索引设置DepthVideo对象的项目。
参数:
index (int or torch.Tensor): 索引,可以是整数或张量。
item (tuple): 包含要设置的数据元组。
"""
with self.get_lock():
self.__item_setter(index, item) # 调用内部方法设置项目
def __getitem__(self, index):
"""
按照索引获取DepthVideo对象的项目。
参数:
index (int): 索引。
返回:
tuple: 包含位姿、深度图、内参、特征图、网络输出和输入数据的元组。
"""
with self.get_lock():
# 支持负索引
if isinstance(index, int) and index < 0:
index = self.counter.value + index # 转换为正索引
item = (
self.poses[index],
self.disps[index],
self.intrinsics[index],
self.fmaps[index],
self.nets[index],
self.inps[index])
return item # 返回项目元组
def append(self, *item):
"""
在当前计数器位置追加新项目。
参数:
item (tuple): 要追加的数据元组。
"""
with self.get_lock():
self.__item_setter(self.counter.value, item) # 调用内部方法设置项目
### 几何操作 ###
@staticmethod
def format_indicies(ii, jj):
"""
格式化索引,将其转换为长整型,并移动到CUDA设备。
参数:
ii (torch.Tensor or other): 第一个索引。
jj (torch.Tensor or other): 第二个索引。
返回:
tuple: 格式化后的索引ii和jj。
"""
if not isinstance(ii, torch.Tensor):
ii = torch.as_tensor(ii) # 转换为张量
if not isinstance(jj, torch.Tensor):
jj = torch.as_tensor(jj) # 转换为张量
ii = ii.to(device="cuda", dtype=torch.long).reshape(-1) # 移动到CUDA并调整形状
jj = jj.to(device="cuda", dtype=torch.long).reshape(-1) # 移动到CUDA并调整形状
return ii, jj # 返回格式化后的索引
def upsample(self, ix, mask):
"""
对深度图进行上采样。
参数:
ix (torch.Tensor): 要上采样的索引。
mask (torch.Tensor): 掩码,用于上采样。
"""
disps_up = cvx_upsample(self.disps[ix].unsqueeze(-1), mask) # 使用cvx_upsample进行上采样
self.disps_up[ix] = disps_up.squeeze() # 存储上采样结果
def normalize(self):
"""
归一化深度图和位姿。
"""
with self.get_lock():
s = self.disps[:self.counter.value].mean() # 计算深度图均值
self.disps[:self.counter.value] /= s # 归一化深度图
self.poses[:self.counter.value,:3] *= s # 归一化位姿
self.dirty[:self.counter.value] = True # 标记为脏
def reproject(self, ii, jj):
"""
从索引ii投影到索引jj。
参数:
ii (torch.Tensor): 源索引。
jj (torch.Tensor): 目标索引。
返回:
tuple: 投影坐标和有效掩码。
"""
ii, jj = DepthVideo.format_indicies(ii, jj) # 格式化索引
Gs = lietorch.SE3(self.poses[None]) # 创建SE3对象
coords, valid_mask = \
pops.projective_transform(Gs, self.disps[None], self.intrinsics[None], ii, jj) # 进行投影变换
return coords, valid_mask # 返回投影坐标和有效掩码
def reproject_comp(self, ii, jj, xyz_comp):
"""
从索引ii投影到索引jj,并考虑补偿xyz_comp。
参数:
ii (torch.Tensor): 源索引。
jj (torch.Tensor): 目标索引。
xyz_comp (torch.Tensor): 补偿坐标。
返回:
tuple: 投影坐标和有效掩码。
"""
ii, jj = DepthVideo.format_indicies(ii,jj) # 格式化索引
Gs = lietorch.SE3(self.poses[None]) # 创建SE3对象
coords, valid_mask = \
pops.projective_transform_comp(Gs, self.disps[None], self.intrinsics[None], ii, jj, xyz_comp) # 进行带补偿的投影变换
return coords, valid_mask # 返回投影坐标和有效掩码
def distance(self, ii=None, jj=None, beta=0.3, bidirectional=True):
"""
计算帧之间的距离度量。
参数:
ii (torch.Tensor or None): 第一帧索引。
jj (torch.Tensor or None): 第二帧索引。
beta (float): 距离计算的超参数,默认为0.3。
bidirectional (bool): 是否双向计算,默认为True。
返回:
torch.Tensor: 帧间距矩阵或单个距离值。
"""
return_matrix = False
if ii is None:
return_matrix = True
N = self.counter.value # 当前计数
ii, jj = torch.meshgrid(torch.arange(N), torch.arange(N)) # 创建网格
ii, jj = DepthVideo.format_indicies(ii, jj) # 格式化索引
if bidirectional:
poses = self.poses[:self.counter.value].clone() # 克隆当前位姿
d1 = droid_backends.frame_distance(
poses, self.disps, self.intrinsics[0], ii, jj, beta) # 计算第一方向的距离
d2 = droid_backends.frame_distance(
poses, self.disps, self.intrinsics[0], jj, ii, beta) # 计算第二方向的距离
d = .5 * (d1 + d2) # 计算平均距离
else:
d = droid_backends.frame_distance(
self.poses, self.disps, self.intrinsics[0], ii, jj, beta) # 单向计算距离
if return_matrix:
return d.reshape(N, N) # 返回距离矩阵
return d # 返回单个距离值
def rm_new_gnss(self, t1):
"""
移除新的GNSS测量并更新图。
参数:
t1 (int): 当前时间步。
"""
if (self.gnss_init_t1 > 0 and self.state.gnss_valid[t1]) or self.state.odo_valid[t1]:
graph_temp = gtsam.NonlinearFactorGraph() # 创建临时非线性因子图
linear_point = self.marg_factor.linearizationPoint() # 获取边缘化因子的线性化点
graph_temp.push_back(self.marg_factor) # 将边缘化因子添加到图中
dd_dump = {}
dd_dump['factors'] = [] # 因子存储
dd_dump['rollup'] = self.rollup_sum # 汇总和
if self.state.gnss_valid[t1]: # 如果GNSS有效
T1 = self.state.wTbs[t1] # 当前位姿
T0 = self.state.wTbs[t1-1] # 前一位姿
p = np.matmul(trans.Cen(self.ten0).T, self.state.gnss_position[t1] - self.ten0) # 计算GNSS位置
n0pbg = self.state.wTbs[t1].rotation().rotate(self.tbg) # 旋转背景
p = p - n0pbg # 修正位置
p = p - T1.translation() + T0.translation() # 更新位置
if not linear_point.exists(X(t1-1)):
linear_point.insert(X(t1-1), self.cur_result.atPose3(X(t1-1))) # 插入线性化点
gnss_factor = gtsam.GPSFactor(X(t1-1), p,\
gtsam.noiseModel.Robust.Create(\
gtsam.noiseModel.mEstimator.Cauchy(0.08),\
gtsam.noiseModel.Diagonal.Sigmas(np.array([1.0,1.0,5.0])))) # 创建GNSS因子
graph_temp.push_back(gnss_factor) # 添加GNSS因子到图中
dd_dump['factors'].append({'type':'gnss','symbol':X(t1-1), 'pos': p}) # 存储GNSS因子信息
if self.state.odo_valid[t1]: # 如果里程计有效
v1 = np.matmul(self.state.wTbs[t1].rotation().matrix().T, self.state.vs[t1]) # 当前速度
v0 = np.matmul(self.state.wTbs[t1-1].rotation().matrix().T, self.state.vs[t1-1]) # 前一速度
v = self.state.odo_vel[t1] - v1 + v0 # 计算修正后的速度
if not linear_point.exists(X(t1-1)):
linear_point.insert(X(t1-1), self.cur_result.atPose3(X(t1-1))) # 插入线性化点
if not linear_point.exists(V(t1-1)):
linear_point.insert(V(t1-1), self.cur_result.atVector(V(t1-1))) # 插入线性化点
odo_factor = gtsam.VelFactor(X(t1-1),V(t1-1),v,gtsam.noiseModel.Diagonal.Sigmas(np.array([2.0,2.0,2.0]))) # 创建里程计因子
graph_temp.push_back(odo_factor) # 添加里程计因子到图中
dd_dump['factors'].append({'type':'odo', 'X':X(t1-1), 'V':V(t1-1), 'vel': v}) # 存储里程计因子信息
if len(dd_dump['factors']) > 0: # 如果有因子被添加
pickle.dump(dd_dump,self.pkl_fp) # 保存因子信息
h_factor = graph_temp.linearizeToHessianFactor(linear_point) # 线性化因子图
self.marg_factor = gtsam.LinearContainerFactor(h_factor,linear_point) # 更新边缘化因子
def set_prior(self, t0, t1, loose=False):
"""
设置先验因子。
参数:
t0 (int): 起始时间步。
t1 (int): 结束时间步。
loose (bool): 是否松散约束,默认为False。
"""
if loose:
for i in range(t0,t0+2):
self.prior_factor_map[i] = []
self.prior_factor_map[i].append(gtsam.PriorFactorPose3(X(i),\
self.state.wTbs[i], \
gtsam.noiseModel.Diagonal.Sigmas(np.array([1.0, 1.0, 1.0,1.0,1.0,1.0])))) # 为GNSS创建先验因子
if not self.ignore_imu:
self.prior_factor_map[i].append(gtsam.PriorFactorConstantBias(B(i),\
self.state.bs[i], \
gtsam.noiseModel.Diagonal.Sigmas(self.init_bias_sigma))) # 为IMU创建先验因子
self.last_t0 = t0 # 更新last_t0
self.last_t1 = t1 # 更新last_t1
return
for i in range(t0,t0+2):
self.prior_factor_map[i] = []
self.prior_factor_map[i].append(gtsam.PriorFactorPose3(X(i),\
self.state.wTbs[i], \
gtsam.noiseModel.Diagonal.Sigmas(self.init_pose_sigma))) # 创建先验因子
if not self.ignore_imu:
self.prior_factor_map[i].append(gtsam.PriorFactorConstantBias(B(i),\
self.state.bs[i], \
gtsam.noiseModel.Diagonal.Sigmas(self.init_bias_sigma))) # 创建IMU先验因子
self.last_t0 = t0 # 更新last_t0
self.last_t1 = t1 # 更新last_t1
def ba_final(self, itrs, lm, ep, motion_only):
"""
进行最终的稀疏优化过程。这个函数主要在给定的时间窗口内对状态执行边际化操作并估算相机位姿,速度和IMU偏差。
参数:
itrs: 优化迭代次数
lm: 莱文伯格-马夸特算法中的阻尼因子
ep: 收敛误差阈值
motion_only: 是否仅处理运动数据(True)或包含所有传感器数据(False)
"""
t0 = self.last_t0 + 1 # 初始化t0为上一个步骤的t0加1
with self.get_lock(): # 获取线程锁
while t0 < self.last_t1 - 2: # 如果当前时间小于最后一次记录的时间减2
marg_paras = [] # 边际化参数列表
graph = gtsam.NonlinearFactorGraph() # 创建非线性因子图
# 筛选出需要边际化的时刻索引
marg_idx = torch.logical_and(torch.greater_equal(self.cur_ii, self.last_t0), \
torch.less(self.cur_ii, t0))
marg_idx2 = torch.logical_and(torch.less(self.cur_ii, self.last_t1 - 2), \
torch.less(self.cur_jj, self.last_t1 - 2))
marg_idx = torch.logical_and(marg_idx, marg_idx2)
marg_ii = self.cur_ii[marg_idx] # 合并到marg_idx的II索引
marg_jj = self.cur_jj[marg_idx] # 合并到marg_idx的JJ索引
marg_t0 = self.last_t0
marg_t1 = t0 + 1 # marginalization结束的时间
dd_dump = {}
dd_dump['factors'] = []
dd_dump['states'] = None
dd_dump['rollup'] = self.rollup_sum
if len(marg_ii) > 0: # 当前情况有可用的数据
marg_result = gtsam.Values() # 创建gtsam的Value对象
for i in range(self.last_t0, marg_t1): # 遍历从last_t0到marg_t1之间的所有时间点
if i < t0: # 当i小于当前t0时
marg_paras.append(X(i)) # 添加X(i)作为边际化参数
# 保存结果
if self.save_pkl:
self.tstamp_save[self.count_save] = self.tstamp[i].clone()
# ...省略保存其他信息...
self.count_save += 1
# Save marginalized poses
TTT = np.matmul(SE3(self.poses[i].clone()[None])[0].cpu().inv().matrix(), np.linalg.inv(self.Ti1c))
ppp = TTT[0:3, 3]
qqq = Rotation.from_matrix(TTT[:3, :3]).as_quat()
cur_t = self.tstamp[i].clone()
line = '%.6f %.6f %.6f %.6f %.6f %.6f %.6f %.6f' % (cur_t, ppp[0], ppp[1], ppp[2], \
qqq[0], qqq[1], qqq[2], qqq[3])
self.save_fp.writelines(line + '\n')
self.save_fp.flush()
marg_result.insert(X(i), self.cur_result.atPose3(X(i))) # 插入当前状态
# 将边际化需要的目标、权重和η提取出来
marg_target = self.cur_target[marg_idx]
marg_weight = self.cur_weight[marg_idx]
marg_eta = self.cur_eta[0:marg_t1 - marg_t0]
bacore = droid_backends.BACore() # 初始化后端BA核心
bacore.init(self.poses, self.disps, self.intrinsics[0], torch.zeros_like(self.disps_sens),
marg_target, marg_weight, marg_eta, marg_ii, marg_jj, marg_t0, marg_t1, itrs, lm, ep, motion_only)
H = torch.zeros([(marg_t1 - marg_t0) * 6, (marg_t1 - marg_t0) * 6], dtype=torch.float64, device='cpu')
v = torch.zeros([(marg_t1 - marg_t0) * 6], dtype=torch.float64, device='cpu')
bacore.hessian(H, v) # 从后端计算Hessain和v
for i in range(6):
H[i, i] += 0.00025 # 为主对角线增加平滑项
# 转换为GTSAM格式
Hgg = gtsam.BA2GTSAM(H, v, self.Tbc)
Hg = Hgg[0:(marg_t1 - marg_t0) * 6, 0:(marg_t1 - marg_t0) * 6]
vg = Hgg[0:(marg_t1 - marg_t0) * 6, (marg_t1 - marg_t0) * 6]
vis_factor = CustomHessianFactor(marg_result, Hg, vg) # 创建视觉因子
graph.push_back(vis_factor) # 将之添加入factor图
dd_dump['factors'].append({'type': 'vis', 'factor': vis_factor})
else:
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!') # 输出警告没有可用于边际化的数据
# 对每个有效时间点i进行IMU和GNSS查询,将相应因素加入图中
for i in range(self.last_t0, marg_t1):
if i < t0:
if X(i) not in marg_paras:
marg_paras.append(X(i)) # 添加状态
if not self.ignore_imu: # 如果IMU被启用
marg_paras.append(V(i))
marg_paras.append(B(i))
ff = gtsam.gtsam.CombinedImuFactor(\
X(i), V(i), X(i + 1), V(i + 1), B(i), B(i + 1),\
self.state.preintegrations[i]) # 创建组合IMU因子
graph.push_back(ff) # 将IMU因子添加至图中
dd_dump['factors'].append({'type': 'imu', 'meas': self.state.preintegrations_meas[i],'factor': gtsam.LinearContainerFactor(gtsam.HessianFactor(ff.linearize(self.cur_result)),self.cur_result)})
# GNSS验证
if self.gnss_init_t1 > 0:
if self.state.gnss_valid[i]:
p = np.matmul(trans.Cen(self.ten0).T, self.state.gnss_position[i] - self.ten0)
n0pbg = self.state.wTbs[i].rotation().rotate(self.tbg)
p = p - n0pbg
gnss_factor = gtsam.GPSFactor(X(i), p,\
gtsam.noiseModel.Robust.Create(\
gtsam.noiseModel.mEstimator.Cauchy(0.08),\
gtsam.noiseModel.Diagonal.Sigmas(np.array([1.0, 1.0, 5.0]))))
graph.push_back(gnss_factor) # 添加GNSS因子
# ODO Factor
if self.state.odo_valid[i]:
vb = self.state.odo_vel[i]
odo_factor = gtsam.VelFactor(X(i), V(i), vb, gtsam.noiseModel.Diagonal.Sigmas(np.array([2.0, 2.0, 2.0])))
graph.push_back(odo_factor) # 加入ODO因子
keys = self.prior_factor_map.keys() # 获取先验因子的键
for i in sorted(keys):
if i < t0:
for iii in range(len(self.prior_factor_map[i])):
graph.push_back(self.prior_factor_map[i][iii]) # 逐个添加先验因子
dd_dump['factors'].append({'type': 'prior', 'factor': self.prior_factor_map[i][iii]})
del self.prior_factor_map[i] # 删除已处理的因子
if not self.marg_factor == None:
graph.push_back(self.marg_factor) # 如果存在边际因子则添加进图
self.marg_factor = gtsam.marginalizeOut(graph, self.cur_result, marg_paras) # 执行边际化
dd_dump['states'] = self.cur_result # 储存当前状态
# 实例化时间戳字典
dd_dump['tstamps'] = {}
for i in graph.keyVector():
if i >= X(0) and i < X(100000):
dd_dump['tstamps'][i-X(0)] = self.tstamp[i-X(0)].item() # 存储时间戳
pickle.dump(dd_dump, self.pkl_fp) # 将全部信息转存
# 更新当前的 II 和 JJ 用以下一轮的边际化
retain_mask = torch.logical_and(self.cur_ii >= t0, self.cur_jj >= t0)
self.cur_ii = self.cur_ii[retain_mask]
self.cur_jj = self.cur_jj[retain_mask]
self.cur_target = self.cur_target[retain_mask]
self.cur_weight = self.cur_weight[retain_mask]
self.cur_eta = self.cur_eta[t0 - self.last_t0:] # 刷新本次更新的 eta
self.last_t0 = t0 # 更新last_t0
t0 += 1 # 增加时间计数
def ba(self, target, weight, eta, ii, jj, t0=1, t1=None, itrs=2, lm=1e-4, ep=0.1, motion_only=False):
"""
稠密束调整 (Dense Bundle Adjustment, DBA)
该函数用于优化相机位姿和深度图,通过最小化重投影误差来提高视觉SLAM系统的精度。
参数:
target: 目标点云数据,表示要优化的特征点位置。
weight: 权重,用于加权不同观测值的重要性。
eta: 学习率或收敛阈值,控制优化过程中的步长。
ii: 当前帧中每个特征点的索引。
jj: 与当前帧对应的参考帧中每个特征点的索引。
t0: 优化开始时间戳(默认值为1)。
t1: 优化结束时间戳(默认为None,将自动计算)。
itrs: 优化迭代次数(默认值为2)。
lm: Levenberg-Marquardt算法的阻尼因子(默认值为1e-4)。
ep: 收敛容忍度(默认值为0.1)。
motion_only: 是否仅考虑运动模型(默认值为False)。
"""
with self.get_lock():
# [t0, t1] 为束调整优化的时间窗口
if t1 is None:
t1 = max(ii.max().item(), jj.max().item()) + 1
# 1) 仅视觉BA
# 2) 多传感器BA
if not self.imu_enabled:
droid_backends.ba(self.poses, self.disps, self.intrinsics[0], self.disps_sens,
target, weight, eta, ii, jj, t0, t1, itrs, lm, ep, motion_only)
for i in range(self.last_t0, min(ii.min().item(), jj.min().item())):
if self.save_pkl:
# 保存边缘化结果
self.tstamp_save[self.count_save] = self.tstamp[i].clone()
self.disps_save[self.count_save] = self.disps[i].clone()
self.poses_save[self.count_save] = self.poses[i].clone()
if self.upsample_flag:
self.disps_up_save[self.count_save] = self.disps_up[i].clone()
self.images_save[self.count_save] = self.images[i,[2,1,0],::8,::8].permute(1,2,0) / 255.0 # 可能是 "3::8, 3::8"?
self.count_save += 1
self.last_t0 = min(ii.min().item(), jj.min().item())
self.last_t1 = t1
else:
t0 = min(ii.min().item(), jj.min().item())
""" 边缘化处理 """
if self.last_t1 != t1 or self.last_t0 != t0:
if self.last_t0 > t0:
t0 = self.last_t0
elif self.last_t0 == t0:
t0 = self.last_t0
else:
marg_paras = []
graph = gtsam.NonlinearFactorGraph()
marg_idx = torch.logical_and(torch.greater_equal(self.cur_ii,self.last_t0),\
torch.less(self.cur_ii,t0))
marg_idx2 = torch.logical_and(torch.less(self.cur_ii,self.last_t1-2),\
torch.less(self.cur_jj,self.last_t1-2))
marg_idx = torch.logical_and(marg_idx,marg_idx2)
marg_ii = self.cur_ii[marg_idx]
marg_jj = self.cur_jj[marg_idx]
marg_t0 = self.last_t0
marg_t1 = t0 + 1
dd_dump = {}
dd_dump['factors'] = []
dd_dump['states'] = None
dd_dump['rollup'] = self.rollup_sum
if len(marg_ii) > 0:
marg_t0 = self.last_t0
marg_t1 = torch.max(marg_jj).item() + 1
marg_result = gtsam.Values()
for i in range(self.last_t0, marg_t1):
if i < t0:
marg_paras.append(X(i))
if self.save_pkl:
# 保存边缘化结果
self.tstamp_save[self.count_save] = self.tstamp[i].clone()
self.disps_save[self.count_save] = self.disps[i].clone()
self.poses_save[self.count_save] = self.poses[i].clone()
if self.upsample_flag:
self.disps_up_save[self.count_save] = self.disps_up[i].clone()
self.images_save[self.count_save] = self.images[i,[2,1,0],::8,::8].permute(1,2,0) / 255.0 # 可能是 "3::8, 3::8"?
self.count_save += 1
marg_result.insert(X(i), self.cur_result.atPose3(X(i)))
marg_target = self.cur_target[marg_idx]
marg_weight = self.cur_weight[marg_idx]
marg_eta = self.cur_eta[0:marg_t1 - marg_t0]
bacore = droid_backends.BACore()
bacore.init(self.poses, self.disps, self.intrinsics[0], torch.zeros_like(self.disps_sens),
marg_target, marg_weight, marg_eta, marg_ii, marg_jj, marg_t0, marg_t1, itrs, lm, ep, motion_only)
H = torch.zeros([(marg_t1 - marg_t0) * 6, (marg_t1 - marg_t0) * 6], dtype=torch.float64, device='cpu')
v = torch.zeros([(marg_t1 - marg_t0) * 6], dtype=torch.float64, device='cpu')
bacore.hessian(H, v)
for i in range(6):
H[i,i] += 0.00025
Hgg = gtsam.BA2GTSAM(H, v, self.Tbc)
Hg = Hgg[0:(marg_t1 - marg_t0) * 6, 0:(marg_t1 - marg_t0) * 6]
vg = Hgg[0:(marg_t1 - marg_t0) * 6, (marg_t1 - marg_t0) * 6]
vis_factor = CustomHessianFactor(marg_result, Hg, vg)
graph.push_back(vis_factor)
dd_dump['factors'].append({'type':'vis','factor':vis_factor})
else:
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
for i in range(self.last_t0, marg_t1):
if i < t0:
if X(i) not in marg_paras:
marg_paras.append(X(i))
if not self.ignore_imu:
marg_paras.append(V(i))
marg_paras.append(B(i))
ff = gtsam.gtsam.CombinedImuFactor(
X(i), V(i), X(i+1), V(i+1), B(i), B(i+1),
self.state.preintegrations[i])
graph.push_back(ff)
dd_dump['factors'].append({'type':'imu', 'meas':self.state.preintegrations_meas[i],'factor':gtsam.LinearContainerFactor(gtsam.HessianFactor(ff.linearize(self.cur_result)), self.cur_result)})
if self.gnss_init_t1 > 0:
if self.state.gnss_valid[i]:
p = np.matmul(trans.Cen(self.ten0).T, self.state.gnss_position[i] - self.ten0)
n0pbg = self.state.wTbs[i].rotation().rotate(self.tbg)
p = p - n0pbg
gnss_factor = gtsam.GPSFactor(X(i), p,
gtsam.noiseModel.Robust.Create(
gtsam.noiseModel.mEstimator.Cauchy(0.08),
gtsam.noiseModel.Diagonal.Sigmas(np.array([1.0, 1.0, 5.0]))))
graph.push_back(gnss_factor)
dd_dump['factors'].append({'type':'gnss', 'symbol':X(i), 'pos': p})
dd_dump['ten0'] = self.ten0
if self.state.odo_valid[i]:
vb = self.state.odo_vel[i]
odo_factor = gtsam.VelFactor(X(i), V(i), vb, gtsam.noiseModel.Diagonal.Sigmas(np.array([2.0, 2.0, 2.0])))
dd_dump['factors'].append({'type':'odo', 'X':X(i), 'V':V(i), 'vel': vb})
graph.push_back(odo_factor)
keys = self.prior_factor_map.keys()
for i in sorted(keys):
if i < t0:
for iii in range(len(self.prior_factor_map[i])):
graph.push_back(self.prior_factor_map[i][iii])
dd_dump['factors'].append({'type':'prior', 'factor':self.prior_factor_map[i][iii]})
del self.prior_factor_map[i]
if not self.marg_factor == None:
graph.push_back(self.marg_factor)
self.marg_factor = gtsam.marginalizeOut(graph, self.cur_result, marg_paras)
dd_dump['states'] = self.cur_result
dd_dump['tstamps'] = {}
for i in graph.keyVector():
if i >= X(0) and i < X(100000):
dd_dump['tstamps'][i-X(0)] = self.tstamp[i-X(0)].item()
pickle.dump(dd_dump, self.pkl_fp)
if self.reinit == True:
all_keys = self.marg_factor.keys()
for i in range(len(all_keys)):
if all_keys[i] == B(t0):
all_keys[i] = B(0)
graph = gtsam.NonlinearFactorGraph()
graph.push_back(self.marg_factor.rekey(all_keys))
b_l = gtsam.BetweenFactorConstantBias(B(0), B(t0), gtsam.imuBias.ConstantBias(np.array([.0,.0,.0]), np.array([.0,.0,.0])), gtsam.noiseModel.Diagonal.Sigmas(self.init_bias_sigma))
graph.push_back(b_l)
result_tmp = self.marg_factor.linearizationPoint()
result_tmp.insert(B(0), result_tmp.atConstantBias(B(t0)))
self.marg_factor = gtsam.marginalizeOut(graph, result_tmp, [B(0)])
self.reinit = False
# print(self.marg_factor.keys())
self.last_t0 = t0
self.last_t1 = t1
""" 优化过程 """
H = torch.zeros([(t1-t0)*6, (t1-t0)*6], dtype=torch.float64, device='cpu')
v = torch.zeros([(t1-t0)*6], dtype=torch.float64, device='cpu')
dx = torch.zeros([(t1-t0)*6], dtype=torch.float64, device='cpu')
bacore = droid_backends.BACore()
active_index = torch.logical_and(ii >= t0, jj >= t0)
self.cur_ii = ii[active_index]
self.cur_jj = jj[active_index]
self.cur_target = target[active_index]
self.cur_weight = weight[active_index]
self.cur_eta = eta[(t0 - ii.min().item()):]
bacore.init(self.poses, self.disps, self.intrinsics[0], self.disps_sens,
self.cur_target, self.cur_weight, self.cur_eta, self.cur_ii, self.cur_jj, t0, t1, itrs, lm, ep, motion_only)
self.cur_graph = gtsam.NonlinearFactorGraph()
params = gtsam.LevenbergMarquardtParams()#;params.setMaxIterations(1)
# IMU因子
if not self.ignore_imu:
for i in range(t0, t1):
if i > t0:
if np.linalg.norm(self.state.bs[i-1].vector() - self.state.preintegrations[i-1].biasHat().vector()) > 0.01:
self.state.preintegrations[i-1] = gtsam.PreintegratedCombinedMeasurements(self.state.params, self.state.bs[i-1])
for iii in range(len(self.state.preintegrations_meas[i-1])):
dd = self.state.preintegrations_meas[i-1][iii]
if dd[2] > 0:
self.state.preintegrations[i-1].integrateMeasurement(dd[0], dd[1], dd[2])
imu_factor = gtsam.gtsam.CombinedImuFactor(
X(i-1), V(i-1), X(i), V(i), B(i-1), B(i),
self.state.preintegrations[i-1])
self.cur_graph.add(imu_factor)
# 先验因子
keys = self.prior_factor_map.keys()
for i in sorted(keys):
if i >= t0 and i < t1:
for iii in range(len(self.prior_factor_map[i])):
self.cur_graph.push_back(self.prior_factor_map[i][iii])
# 边缘化因子
if self.marg_factor is not None:
self.cur_graph.push_back(self.marg_factor)
# GNSS因子
if self.gnss_init_t1 > 0:
for i in range(t0, t1):
if self.state.gnss_valid[i]:
# print('GNSS valid!!!!!!!!!!!!!!!!!!!!')
p = np.matmul(trans.Cen(self.ten0).T, self.state.gnss_position[i] - self.ten0)
n0pbg = self.state.wTbs[i].rotation().rotate(self.tbg)
p = p - n0pbg
gnss_factor = gtsam.GPSFactor(X(i), p,
gtsam.noiseModel.Robust.Create(
gtsam.noiseModel.mEstimator.Cauchy(0.08),
gtsam.noiseModel.Diagonal.Sigmas(np.array([1.0, 1.0, 5.0]))))
self.cur_graph.push_back(gnss_factor)
# 里程计因子
for i in range(t0, t1):
if self.state.odo_valid[i]:
vb = self.state.odo_vel[i]
odo_factor = gtsam.VelFactor(X(i), V(i), vb, gtsam.noiseModel.Diagonal.Sigmas(np.array([2.0, 2.0, 2.0])))
self.cur_graph.push_back(odo_factor)
""" 多传感器DBA迭代 """
for iter in range(2):
if iter > 0:
self.cur_graph.resize(self.cur_graph.size()-1)
bacore.hessian(H, v) # 相机帧
Hgg = gtsam.BA2GTSAM(H, v, self.Tbc)
Hg = Hgg[0:(t1-t0)*6, 0:(t1-t0)*6]
vg = Hgg[0:(t1-t0)*6, (t1-t0)*6]
initial = gtsam.Values()
for i in range(t0, t1):
initial.insert(X(i), self.state.wTbs[i]) # 索引需要处理
initial_vis = copy.deepcopy(initial)
vis_factor = CustomHessianFactor(initial_vis, Hg, vg)
self.cur_graph.push_back(vis_factor)
if not self.ignore_imu:
for i in range(t0, t1):
initial.insert(B(i), self.state.bs[i])
initial.insert(V(i), self.state.vs[i])
optimizer = gtsam.LevenbergMarquardtOptimizer(self.cur_graph, initial, params)
self.cur_result = optimizer.optimize()
# 回缩和深度更新
for i in range(t0, t1):
p0 = initial.atPose3(X(i))
p1 = self.cur_result.atPose3(X(i))
xi = gtsam.Pose3.Logmap(p0.inverse()*p1)
dx[(i-t0)*6:(i-t0)*6+6] = torch.tensor(xi)
if not self.ignore_imu:
self.state.bs[i] = self.cur_result.atConstantBias(B(i))
self.state.vs[i] = self.cur_result.atVector(V(i))
self.state.wTbs[i] = self.cur_result.atPose3(X(i))
dx = torch.tensor(gtsam.GTSAM2BA(dx, self.Tbc))
dx_dz = bacore.retract(dx)
del bacore
self.disps.clamp_(min=0.001)
3.4 droid_net.py
最后一块就是DroidNet处理的代码了,其主要是用来处理深度信息的,在load_weights中加载参数并处理,下面我们就来看看droid_net.py这个代码
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import OrderedDict
from modules.extractor import BasicEncoder
from modules.corr import CorrBlock
from modules.gru import ConvGRU
from modules.clipping import GradientClip
from lietorch import SE3
from geom.ba import BA
import geom.projective_ops as pops
from geom.graph_utils import graph_to_edge_list, keyframe_indicies
from torch_scatter import scatter_mean
import time
def cvx_upsample(data, mask):
""" 上采样像素级变换场 """
batch, ht, wd, dim = data.shape # 获取输入数据的批次、h、高度、宽度和维度信息
data = data.permute(0, 3, 1, 2) # 调整数据形状,从 (batch, h, w, dim) 到 (batch, dim, h, w)
mask = mask.view(batch, 1, 9, 8, 8, ht, wd)
mask = torch.softmax(mask, dim=2) # 应用softmax到mask的第2维
up_data = F.unfold(data, [3,3], padding=1) # 使用unfold提取局部区域特征
up_data = up_data.view(batch, dim, 9, 1, 1, ht, wd)
up_data = torch.sum(mask * up_data, dim=2) # 对每个patch使用mask加权求和
up_data = up_data.permute(0, 4, 2, 5, 3, 1)
up_data = up_data.reshape(batch, 8*ht, 8*wd, dim) # 将上采样数据调整为目标大小
return up_data
def upsample_disp(disp, mask):
""" 上采样位移图 """
batch, num, ht, wd = disp.shape
disp = disp.view(batch*num, ht, wd, 1) # 重塑disp以便与mask一起处理
mask = mask.view(batch*num, -1, ht, wd) # 同样重塑mask
return cvx_upsample(disp, mask).view(batch, num, 8*ht, 8*wd) # 返回上采样后的位移图
class GraphAgg(nn.Module):
def __init__(self):
super(GraphAgg, self).__init__()
self.conv1 = nn.Conv2d(128, 128, 3, padding=1) # 第一层卷积
self.conv2 = nn.Conv2d(128, 128, 3, padding=1) # 第二层卷积
self.relu = nn.ReLU(inplace=True) # ReLU激活函数
self.eta = nn.Sequential(
nn.Conv2d(128, 1, 3, padding=1), # 提取最终输出eta,该值用于后续计算
GradientClip(),
nn.Softplus()) # 使用Softplus作为最后的非线性激活
self.upmask = nn.Sequential(
nn.Conv2d(128, 8*8*9, 1, padding=0)) # 用于生成Mask的卷积网络
def forward(self, net, ii):
""" 前向传递,执行图聚合操作 """
batch, num, ch, ht, wd = net.shape
net = net.view(batch*num, ch, ht, wd) # 重塑输入
_, ix = torch.unique(ii, return_inverse=True) # 查找unique索引
net = self.relu(self.conv1(net)) # 第一个卷积层并应用ReLU激活
net = net.view(batch, num, 128, ht, wd)
net = scatter_mean(net, ix, dim=1) # 在指定维度上对net进行均值聚合
net = net.view(-1, 128, ht, wd) # 重塑为合适的形状
net = self.relu(self.conv2(net)) # 第二个卷积层并应用ReLU激活
eta = self.eta(net).view(batch, -1, ht, wd) # 计算eta
upmask = self.upmask(net).view(batch, -1, 8*8*9, ht, wd) # 生成upmask
return .01 * eta, upmask # 返回缩放后的eta和upmask
class UpdateModule(nn.Module):
def __init__(self):
super(UpdateModule, self).__init__()
cor_planes = 4 * (2*3 + 1)**2 # 定义相关平面数
self.corr_encoder = nn.Sequential(
nn.Conv2d(cor_planes, 128, 1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, 3, padding=1),
nn.ReLU(inplace=True))
self.flow_encoder = nn.Sequential(
nn.Conv2d(4, 128, 7, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(128, 64, 3, padding=1),
nn.ReLU(inplace=True))
self.weight = nn.Sequential(
nn.Conv2d(128, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 2, 3, padding=1),
GradientClip(),
nn.Sigmoid()) # 权重估计模块
self.delta = nn.Sequential(
nn.Conv2d(128, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 2, 3, padding=1),
GradientClip()) # 位移更新模块
self.gru = ConvGRU(128, 128+128+64) # 基于卷积的GRU
self.agg = GraphAgg() # 图聚合模型
def forward(self, net, inp, corr, flow=None, ii=None, jj=None, upsample=False):
""" RaftSLAM更新算子 """
batch, num, ch, ht, wd = net.shape
if flow is None: # 如果没有flow,则初始化为零张量
flow = torch.zeros(batch, num, 4, ht, wd, device=net.device)
output_dim = (batch, num, -1, ht, wd)
net = net.view(batch*num, -1, ht, wd) # 重塑net
inp = inp.view(batch*num, -1, ht, wd) # 重塑inp
corr = corr.view(batch*num, -1, ht, wd) # 重塑corr
flow = flow.view(batch*num, -1, ht, wd) # 重塑flow
corr = self.corr_encoder(corr) # 编码相关图
flow = self.flow_encoder(flow) # 编码流场
net = self.gru(net, inp, corr, flow) # 更新net
### 更新变量 ###
delta = self.delta(net).view(*output_dim) # 计算delta
weight = self.weight(net).view(*output_dim) # 计算weight
delta = delta.permute(0,1,3,4,2)[...,:2].contiguous() # 重排delta
weight = weight.permute(0,1,3,4,2)[...,:2].contiguous() # 重排weight
net = net.view(*output_dim) # 重塑net为输出形状
if ii is not None:
### 注意!!!! ###
# 我们发现这对于VIO性能毫无意义,因此禁用它来节省计算。
# 请随意重新启用。
if upsample:
eta, upmask = self.agg(net, ii.to(net.device)) # 执行图聚合
return net, delta, weight, eta, upmask # 返回所有计算结果
else:
return net, delta, weight, None, None # 返回计算结果,不包含聚合内容
else:
return net, delta, weight # 返回计算结果
class DroidNet(nn.Module):
def __init__(self):
super(DroidNet, self).__init__()
self.fnet = BasicEncoder(output_dim=128, norm_fn='instance') # 特征提取网络
self.cnet = BasicEncoder(output_dim=256, norm_fn='none')
self.update = UpdateModule() # 更新模块实例化
def extract_features(self, images):
""" 运行特征提取网络 """
# 归一化图片
images = images[:, :, [2,1,0]] / 255.0 # 将BGR转为RGB并归一化
mean = torch.as_tensor([0.485, 0.456, 0.406], device=images.device)
std = torch.as_tensor([0.229, 0.224, 0.225], device=images.device)
images = images.sub_(mean[:, None, None]).div_(std[:, None, None]) # 标准化
fmaps = self.fnet(images) # 从fnet获取特征
net = self.cnet(images) # 从cnet获取特征
net, inp = net.split([128,128], dim=2) # 分开net和inp
net = torch.tanh(net) # tanh压缩net
inp = torch.relu(inp) # relu激活(inp)
return fmaps, net, inp # 返回提取的特征图和两个渠道的变换速率
def forward(self, Gs, images, disps, intrinsics, graph=None, num_steps=12, fixedp=2):
""" 估算帧对之间的SE3或Sim3变换 """
u = keyframe_indicies(graph) # 获取关键帧索引
ii, jj, kk = graph_to_edge_list(graph) # 获取图边关系
ii = ii.to(device=images.device, dtype=torch.long) # 转置至设备
jj = jj.to(device=images.device, dtype=torch.long)
fmaps, net, inp = self.extract_features(images) # 提取图像特征
net, inp = net[:,ii], inp[:,ii] # 根据关键帧选择对应特征
corr_fn = CorrBlock(fmaps[:,ii], fmaps[:,jj], num_levels=4, radius=3) # 计算相似度
ht, wd = images.shape[-2:] # 获取图像高度和宽度
coords0 = pops.coords_grid(ht//8, wd//8, device=images.device) # 初始化坐标网格
# 项目变换得到目标点位置
coords1, _ = pops.projective_transform(Gs, disps, intrinsics, ii, jj)
target = coords1.clone()
Gs_list, disp_list, residual_list = [], [], [] # 初始化列表记录
for step in range(num_steps): # 开始迭代更新步骤
Gs = Gs.detach() # 避免梯度传播
disps = disps.detach()
coords1 = coords1.detach()
target = target.detach()
# 提取运动特征
corr = corr_fn(coords1) # 得到当前的correlation
resd = target - coords1 # 计算残差
flow = coords1 - coords0 # 计算流场
motion = torch.cat([flow, resd], dim=-1) # 合并深度、颜色等信息形成motion tensor
motion = motion.permute(0,1,4,2,3).clamp(-64.0, 64.0) # 限定范围并调整维度
# 更新过程,通过UpdateModule完成
net, delta, weight, eta, upmask = \
self.update(net, inp, corr, motion, ii, jj)
target = coords1 + delta # 更新target的坐标
for i in range(2): # 循环优化全局解
Gs, disps = BA(target, weight, eta, Gs, disps, intrinsics, ii, jj, fixedp=2) # 最小二乘优化
coords1, valid_mask = pops.projective_transform(Gs, disps, intrinsics, ii, jj) # 投影变换获得新坐标
residual = (target - coords1) # 计算最新的残差
Gs_list.append(Gs) # 更新Gs参数
disp_list.append(upsample_disp(disps, upmask)) # 更新displacement
residual_list.append(valid_mask * residual) # 更新有效掩膜下的残差
return Gs_list, disp_list, residual_list # 返回各步骤的更新结果
4. 参考链接
更多推荐

 17
17 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)