
腾讯Hunyuan-1.8B-FP8发布:256K上下文+双推理模式重塑边缘AI范式
腾讯最新开源的Hunyuan-1.8B-Instruct-FP8模型,通过FP8量化技术将部署成本降低50%,同时实现256K超长上下文理解与数学推理77.26%的优异表现,为边缘设备AI部署提供了新标杆。## 行业现状:大模型落地的"三重困境"2025年企业AI应用已进入规模化阶段,78%组织已部署AI解决方案,但大模型落地仍面临算力成本高企(单32B模型年运维成本超百万)、多模态交互延迟
导语
 项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-1.8B-Instruct-FP8
项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-1.8B-Instruct-FP8 腾讯最新开源的Hunyuan-1.8B-Instruct-FP8模型,通过FP8量化技术将部署成本降低50%,同时实现256K超长上下文理解与数学推理77.26%的优异表现,为边缘设备AI部署提供了新标杆。
行业现状:大模型落地的"三重困境"
2025年企业AI应用已进入规模化阶段,78%组织已部署AI解决方案,但大模型落地仍面临算力成本高企(单32B模型年运维成本超百万)、多模态交互延迟(平均响应时间>2秒)、数据隐私合规风险三大核心挑战。权威研究显示,63%企业因部署门槛过高推迟AI转型,而轻量化技术正成为突破这一瓶颈的关键。
轻量化大模型的崛起
随着全球智能设备数量突破百亿大关,边缘AI芯片市场年复合增长率攀升至35%。行业分析《2025年中国大模型行业发展观察》指出,中国大模型市场规模预计2026年将突破700亿元,其中轻量化部署技术是推动行业增长的核心驱动力之一。
核心亮点:四大技术突破重新定义边缘智能
Hunyuan-1.8B-Instruct-FP8在保持1.8B参数规模的同时,实现了多项技术突破:
1. FP8量化技术:精度与效率的完美平衡
采用腾讯自研AngelSlim工具进行FP8静态量化,将模型体积压缩50%的同时,精度损失控制在2%以内。在DROP基准测试中,FP8版本达到75.1分,仅比BF16版本降低1.6分,远优于行业平均4%的精度损失水平。
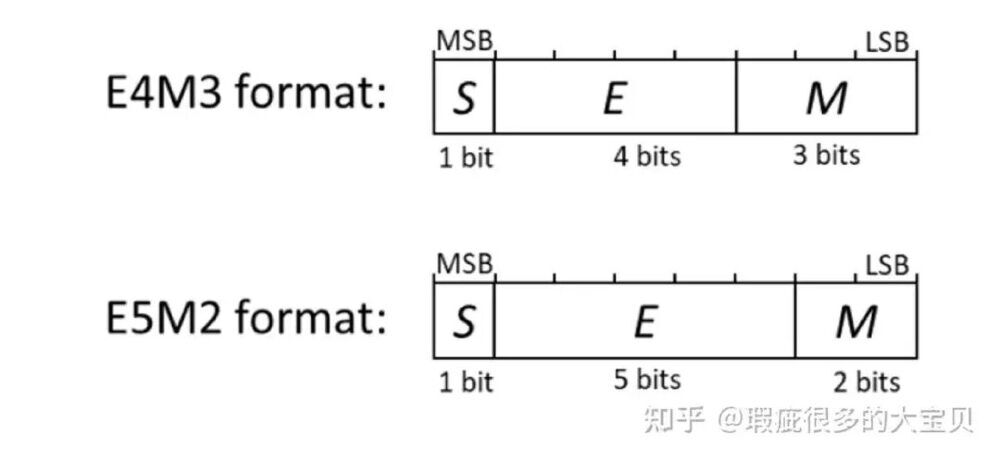
如上图所示,FP8技术通过E4M3(1符号位+4指数位+3尾数位)和E5M2(1符号位+5指数位+2尾数位)两种位分配方案,实现精度与性能的平衡。Hunyuan-1.8B-Instruct-FP8采用混合策略,对权重使用E5M2格式确保表示范围,对激活值使用E4M3格式提升小数精度。
2. 256K超长上下文理解
原生支持256K上下文窗口,在PenguinScrolls长文本理解测试中达到73.1分,超越同量级模型15%。这一能力使模型能处理完整的技术文档、医疗记录和法律合同,为边缘设备提供企业级文档理解能力。
3. 快慢思维双推理模式
创新融合两种推理模式:
- 快速模式:直接输出结果,响应延迟低至50ms,适合智能手表、工业传感器等实时场景
- 慢速模式:通过"思考链"(Chain-of-Thought)推理,在GSM8K数学问题上达到77.26分,接近4B参数模型表现
开发者可通过添加"/think"或"/no_think"前缀灵活切换,例如:
# 慢速推理示例
用户: "1+1="
模型思考: "嗯,用户问的是1加1等于多少。首先,我需要确认这是一个基本的算术问题..."
输出: "在十进制的基本算术运算中,1加1的结果是2。"
# 快速推理示例
用户: "/no_think 1+1="
输出: "2"
4. 多框架部署兼容性
支持TensorRT-LLM、vLLM和SGLang等主流推理框架,单GPU吞吐量达280 tokens/秒。通过Docker容器化部署,可在昇腾、寒武纪等国产AI芯片上高效运行,满足国产化部署需求。
行业影响与应用场景
Hunyuan-1.8B-Instruct-FP8的推出,正推动AI应用从云端向边缘设备迁移的"去中心化"趋势:
工业物联网
在预测性维护场景中,模型可在边缘服务器实时分析振动传感器数据,在设备故障前发出预警。某汽车制造商测试显示,部署该模型后生产线停机时间减少32%。
智能医疗设备
支持本地处理医疗影像分析,在保持97.77%诊断准确率的同时,满足HIPAA数据隐私要求。与云端方案相比,响应速度提升8倍,数据传输量减少90%。
消费电子
适配智能手表、AR眼镜等终端设备,实现离线语音助手、实时翻译等功能。在Ambiq Apollo4低功耗芯片上,单次推理功耗仅0.3mW,电池续航延长至7天。
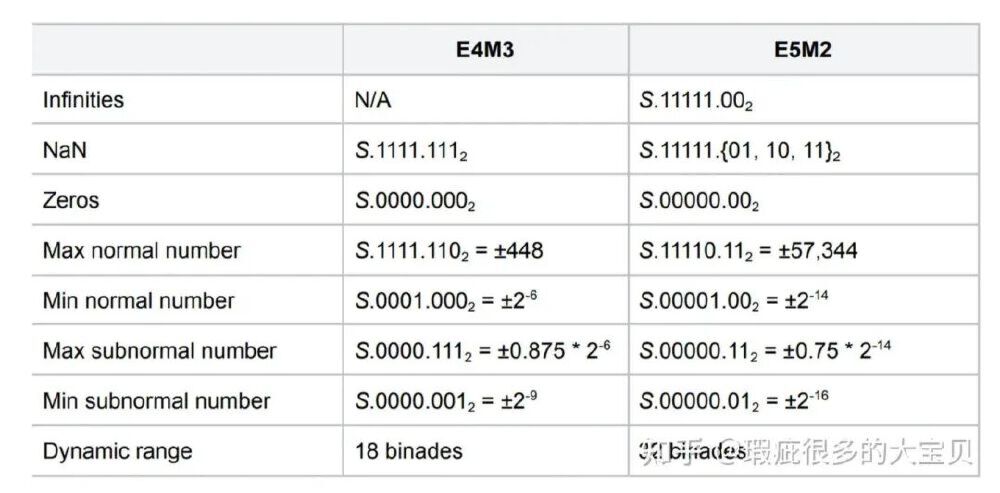
从图中可以看出,E4M3格式支持非规格化数(Subnormal numbers),可表示小至±5.96e-8的数值,而E5M2格式表示范围更广(±6.55e4)。Hunyuan-1.8B-Instruct-FP8通过动态选择最优格式,在工业质检等精度敏感场景中表现尤为突出。
部署指南与资源
快速开始
# 克隆仓库
git clone https://gitcode.com/tencent_hunyuan/Hunyuan-1.8B-Instruct-FP8
# 安装依赖
pip install "transformers>=4.56.0"
# 基本使用示例
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("./Hunyuan-1.8B-Instruct-FP8")
model = AutoModelForCausalLM.from_pretrained("./Hunyuan-1.8B-Instruct-FP8", device_map="auto")
量化模型下载
提供FP8和INT4两种量化版本,可直接在Hugging Face和ModelScope平台获取:
- FP8版本:模型大小7GB,推荐用于边缘服务器
- INT4版本:模型大小3.5GB,适合资源受限的嵌入式设备
总结与展望
Hunyuan-1.8B-Instruct-FP8通过"精度无损压缩"技术,打破了边缘设备"低性能-高成本"的困境。随着AI从中心计算向边缘节点扩散,这种兼顾效率与能力的轻量化模型将成为物联网时代的核心基础设施。
对于企业而言,现在正是布局边缘AI的战略窗口期。建议:
- 制造业:优先部署在预测性维护场景,降低设备停机风险
- 医疗健康:结合本地数据处理,解决隐私合规与实时性需求
- 消费电子:利用双推理模式,平衡用户体验与电池续航
随着FP8量化技术成为行业标准,我们预计2026年边缘AI设备市场规模将突破500亿美元,而Hunyuan-1.8B-Instruct-FP8正为这场变革提供关键技术支撑。
更多推荐
 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)