
IndexTTS2使用全记录,首次运行这些坑要避开
本文介绍了基于星图GPU平台自动化部署indextts2-IndexTTS2 最新 V23版本的全面升级情感控制更好 构建by科哥镜像的方法,助力用户高效搭建中文语音合成环境。该镜像支持情感调控与参考音频风格迁移,适用于AI配音、智能播报等场景,结合平台算力实现快速本地化部署与应用开发。
IndexTTS2使用全记录,首次运行这些坑要避开
在语音合成技术日益普及的今天,IndexTTS2 V23 凭借其出色的本地化部署能力与情感控制表现,成为中文TTS领域备受关注的开源项目。由社区开发者“科哥”维护的这一版本,在语音自然度、情绪表达和易用性上实现了显著提升。然而,尽管官方提供了便捷的启动脚本和WebUI界面,首次使用者仍可能遭遇模型下载失败、资源不足、端口冲突等典型问题。
本文将基于实际部署经验,系统梳理从环境准备到稳定运行的完整流程,重点揭示新手容易踩中的“隐藏陷阱”,并提供可落地的解决方案,帮助你高效完成首次部署。
1. 环境准备与镜像说明
1.1 镜像基本信息
- 镜像名称:
indextts2-IndexTTS2 最新 V23版本的全面升级情感控制更好 构建by科哥 - 核心特性:
- 支持细粒度情感调控(开心、温柔、愤怒等)
- 支持参考音频驱动的零样本风格迁移
- 基于Gradio的图形化WebUI操作界面
- 全程本地运行,无需联网调用API
该镜像已预装Python环境、PyTorch、CUDA依赖及项目代码,极大简化了配置流程。但即便如此,仍需注意硬件与网络条件是否满足要求。
1.2 推荐运行环境
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| CPU | 双核 | 四核及以上 |
| 内存 | 8GB | 16GB |
| 显卡 | 无(CPU模式) | NVIDIA GPU + 4GB显存 |
| 存储空间 | 10GB可用空间 | 20GB以上,建议SSD |
| 操作系统 | Linux(Ubuntu/CentOS) | Ubuntu 20.04+ |
提示:若使用CPU模式推理,单句生成时间可能长达10~30秒;启用GPU后可缩短至1~3秒。
2. 启动流程详解
2.1 启动WebUI服务
进入容器或主机环境后,执行以下命令启动服务:
cd /root/index-tts && bash start_app.sh
该脚本通常包含如下逻辑:
#!/bin/bash
export PYTHONPATH=$(pwd)
python webui.py --host 0.0.0.0 --port 7860 --gpu
参数说明:
--host 0.0.0.0:允许外部设备通过局域网IP访问(如手机、其他电脑)--port 7860:Gradio默认端口,可通过浏览器访问--gpu:启用CUDA加速,必须确保NVIDIA驱动和cuDNN已正确安装
启动成功后,终端会输出类似信息:
Running on local URL: http://0.0.0.0:7860
Running on public URL: http://<your-ip>:7860
此时打开浏览器访问 http://<服务器IP>:7860 即可进入WebUI界面。
2.2 首次运行的关键注意事项
(1)自动下载模型文件
首次运行时,程序会自动从Hugging Face或私有仓库拉取以下模型组件: - 文本编码器(BERT-based) - 声学模型(FastSpeech2变体) - 声码器(HiFi-GAN) - 情感嵌入模型(Style Encoder)
总大小约为 3~5GB,耗时取决于网络质量。常见问题包括: - 下载中断导致文件不完整 - 国内访问Hugging Face速度慢甚至超时 - 磁盘空间不足引发写入失败
✅ 解决方案:
- 使用国内镜像源(如有提供)
- 提前确认至少10GB空闲存储空间
- 在高速网络环境下进行首次初始化
- 若中途失败,删除
cache_hub/目录重新开始
(2)端口被占用
若7860端口已被占用(例如Jupyter Notebook或其他Gradio应用),会导致启动失败。
# 查看端口占用情况
lsof -i :7860
# 终止占用进程
kill -9 <PID>
也可修改启动脚本中的端口号:
python webui.py --port 7861 --gpu
随后通过 http://<ip>:7861 访问。
(3)GPU不可用或CUDA错误
常见报错信息:
CUDA out of memory
No module named 'torch'
AssertionError: Torch not compiled with CUDA enabled
✅ 检查清单:
- 是否安装了NVIDIA驱动?运行
nvidia-smi验证 - PyTorch版本是否匹配CUDA?运行
python -c "import torch; print(torch.cuda.is_available())"应返回True - 容器是否挂载了GPU?使用
--gpus all启动Docker容器
示例Docker启动命令:
docker run --gpus all -p 7860:7860 -it your-indextts2-image
3. WebUI功能使用指南
3.1 主界面结构解析
WebUI采用三栏布局,功能清晰:
- 左侧输入区:支持长文本输入,自动分段处理
- 中部控制区:
- 情感选择下拉菜单(如“开心”、“悲伤”、“严肃”)
- 语速、音高、语调强度调节滑块
- 右侧参考音频上传区:
- 可上传WAV/MP3格式音频作为风格参考
- 系统提取风格向量实现语气迁移
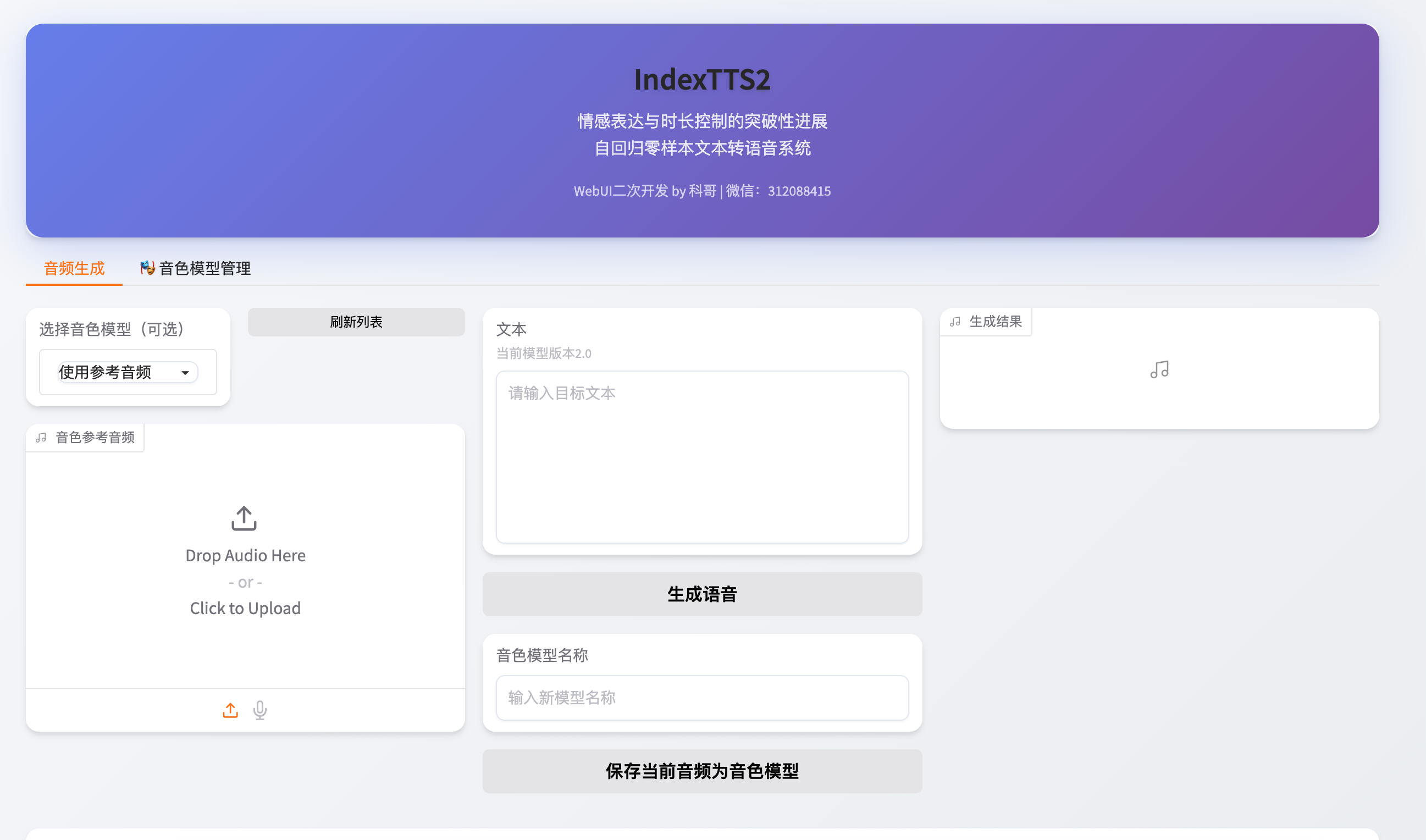
图1:WebUI主界面
3.2 情感控制实践技巧
方法一:预设情感标签
直接选择“温柔”、“激动”等标签,适用于标准化场景,如客服播报、儿童故事。
方法二:参考音频驱动(推荐)
上传一段目标语气的录音(建议5~10秒清晰人声),系统将自动学习其语调特征。例如: - 上传一段欢快的朗读 → 输出语音带有跳跃感 - 上传低沉缓慢的叙述 → 输出语音更具沉稳气质
注意:避免背景噪音过大或混响严重的音频,否则会影响风格提取效果。
3.3 输出结果管理
生成完成后,页面底部播放器可实时试听,并提供 .wav 文件下载链接。所有音频默认保存在 outputs/ 目录下,按时间戳命名。
4. 常见问题与避坑指南
4.1 模型缓存目录不可删除
系统首次运行后会在根目录生成 cache_hub/ 文件夹,用于存放Hugging Face模型缓存。切勿手动删除此目录,否则下次启动将重新下载全部模型,浪费时间和带宽。
缓存路径示例:
/root/index-tts/cache_hub/models--index-tts--fastpitch/
/root/index-tts/cache_hub/models--index-tts--hifigan/
存储优化建议:
若主磁盘空间紧张,可通过软链接方式迁移到大容量硬盘:
# 创建目标目录
mkdir /mnt/large_disk/cache_hub
# 移动原目录并建立符号链接
mv cache_hub/* /mnt/large_disk/cache_hub/
rm -rf cache_hub
ln -s /mnt/large_disk/cache_hub ./cache_hub
程序仍能正常识别路径,实现无缝切换。
4.2 内存不足导致崩溃
在低内存(<8GB)环境中运行GPU模式,可能出现OOM(Out of Memory)错误。
临时缓解措施:
- 关闭不必要的后台进程
- 减少并发请求数量(避免多标签页同时生成)
长期建议:
- 升级至16GB内存
- 或改用CPU模式运行(牺牲速度换取稳定性)
修改启动命令:
python webui.py --host 0.0.0.0 --port 7860 --cpu
4.3 权限与路径问题
部分用户反映无法写入输出目录或读取上传音频。
原因排查:
- 当前用户对
/root/index-tts是否有读写权限? - SELinux或AppArmor是否限制了文件访问?
修复命令:
chown -R $USER:$USER /root/index-tts
chmod -R 755 /root/index-tts
4.4 服务后台常驻运行
直接前台运行 start_app.sh 会导致关闭终端后服务中断。生产环境应使用守护进程管理。
推荐方案:systemd服务
创建服务文件 /etc/systemd/system/indextts.service:
[Unit]
Description=IndexTTS2 WebUI Service
After=network.target
[Service]
Type=simple
User=root
WorkingDirectory=/root/index-tts
ExecStart=/usr/bin/python webui.py --host 0.0.0.0 --port 7860 --gpu
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
启用并启动服务:
systemctl daemon-reexec
systemctl enable indextts.service
systemctl start indextts.service
此后可通过 systemctl status indextts 查看运行状态,异常时自动重启。
5. 总结
部署 IndexTTS2 V23 虽然整体流程简洁,但首次使用者极易在以下几个环节受阻:
- 首次模型下载耗时长且依赖稳定网络
- GPU环境未正确配置导致无法加速
- 端口冲突或权限问题阻碍服务启动
- 误删
cache_hub导致重复下载
通过本文梳理的启动流程与避坑策略,你可以更有信心地完成部署。关键要点总结如下:
- 确保8GB+内存与4GB+显存,优先使用GPU模式
- 首次运行务必在高速网络环境下进行
- 不要删除
cache_hub目录,必要时可用软链接迁移 - 生产环境使用
systemd实现服务常驻 - 合理使用参考音频提升情感表现力
一旦成功运行,你将获得一个完全自主可控、支持高拟真情感语音合成的强大工具,无论是用于内容创作、智能硬件开发还是无障碍辅助系统,都具备极高的实用价值。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。
更多推荐


 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)