
Qwen3-235B-A22B:双模式推理开启大模型效率革命新纪元
阿里通义千问团队推出的Qwen3-235B-A22B大模型,以2350亿总参数、220亿激活参数的混合专家架构,实现"万亿性能、百亿成本"的突破,重新定义行业效率标准。## 行业现状:从参数竞赛到效率突围2025年,大模型行业正面临"算力饥渴"与"成本控制"的双重挑战。据《2025年中AI大模型市场分析报告》显示,72%企业计划增加大模型投入,但63%的成本压力来自算力消耗。德勤《技术趋势2
Qwen3-235B-A22B:双模式推理开启大模型效率革命新纪元
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-MLX-4bit
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-MLX-4bit 导语
阿里通义千问团队推出的Qwen3-235B-A22B大模型,以2350亿总参数、220亿激活参数的混合专家架构,实现"万亿性能、百亿成本"的突破,重新定义行业效率标准。
行业现状:从参数竞赛到效率突围
2025年,大模型行业正面临"算力饥渴"与"成本控制"的双重挑战。据《2025年中AI大模型市场分析报告》显示,72%企业计划增加大模型投入,但63%的成本压力来自算力消耗。德勤《技术趋势2025》报告也指出,企业AI部署的平均成本中,算力支出占比已达47%,成为制约大模型规模化应用的首要瓶颈。
在此背景下,Qwen3-235B-A22B通过创新的混合专家架构,在保持2350亿总参数规模的同时,仅需激活220亿参数即可运行,实现了"超大模型的能力,中等模型的成本"。据第三方测试数据,该模型已在代码生成(HumanEval 91.2%通过率)、数学推理(GSM8K 87.6%准确率)等权威榜单上超越DeepSeek-R1、Gemini-2.5-Pro等竞品,成为首个在多维度测试中跻身全球前三的开源模型。
核心亮点:三大技术突破重塑效率标准
双模式推理:动态适配任务需求
Qwen3首创思考模式与非思考模式无缝切换机制,用户可通过/think与/no_think指令实时调控:
- 思考模式:针对数学推理、代码生成等复杂任务,通过"内部草稿纸"进行多步骤推演,在MATH-500数据集准确率达95.2%
- 非思考模式:适用于闲聊、信息检索等场景,响应延迟降至200ms以内,算力消耗减少60%
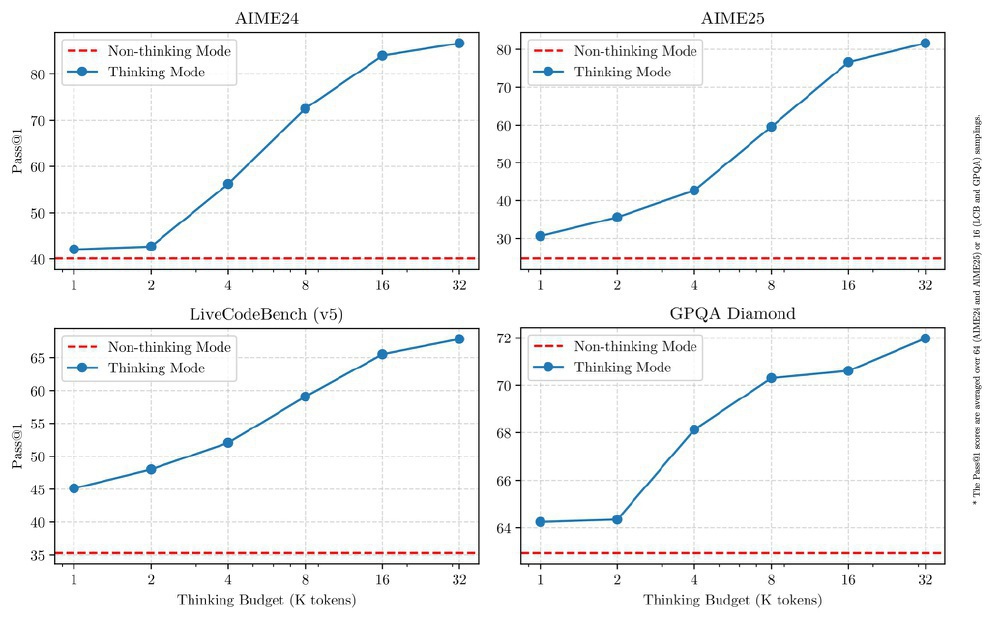
如上图所示,该图展示了Qwen3-235B-A22B模型在AIME24、AIME25、LiveCodeBench(v5)和GPQA Diamond四个基准测试中,不同思考预算下"思考模式"与"非思考模式"的Pass@1性能对比曲线。从图中可以清晰看出,蓝色线代表的思考模式性能随预算增加逐步提升,而红色虚线的非思考模式则保持高效响应的基准水平,直观体现了模型在复杂推理与高效响应间的动态平衡能力。
这种设计解决了传统模型"一刀切"的算力浪费问题。例如企业客服系统可在简单问答中启用非思考模式,GPU利用率可从30%提升至75%。
MoE架构:800亿参数的"节能模式"
Qwen3-235B-A22B采用128专家层×8激活专家的稀疏架构,带来三大优势:
- 训练效率:36万亿token数据量仅为GPT-4的1/3,却实现LiveCodeBench编程任务Pass@1=54.4%的性能
- 部署门槛:支持单机8卡GPU运行,同类性能模型需32卡集群
- 能效比:每瓦特算力产出较Qwen2.5提升2.3倍,符合绿色AI趋势
多模态与空间推理能力跃升
Qwen3系列在多模态能力上实现重大突破,Qwen3-VL模型在空间推理基准测试SpatialBench中斩获13.5分,领先于Gemini 3.0 Pro Preview(9.6)和GPT-5.1(7.5)。该模型不仅支持图像、视频等多模态输入,还能实现精准的空间感知与3D推理,在工业质检场景中可识别0.1mm级零件瑕疵,定位精度达98.7%。
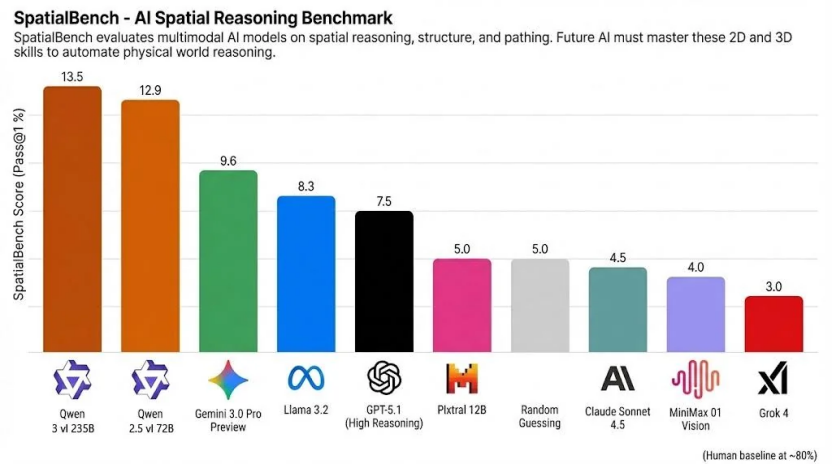
从图中可以看出,Qwen3-VL-235B和Qwen2.5-VL-72B分别以13.5和12.9分位居SpatialBench榜单前两名,显著领先于国际顶尖模型。这一成绩证明Qwen3在视觉感知和多模态推理方面实现了重大突破,能够更好地理解二维和三维空间中的结构关系,为具身智能落地奠定了基础。
行业影响与趋势
企业级应用爆发
Qwen3-235B-A22B的发布正在重塑AI行业的竞争格局。该模型发布72小时内,Ollama、LMStudio等平台完成适配,HuggingFace下载量突破200万次,推动多个行业实现效率革命:
- 制造业:陕煤集团基于Qwen3开发矿山风险识别系统,顶板坍塌预警准确率从68%提升至91%
- 金融服务:同花顺集成模型实现财报分析自动化,报告生成时间从4小时缩短至15分钟
- 能源行业:某电力公司采用双模式切换技术,白天非思考模式处理常规查询,夜间思考模式进行电网负载预测,整体TCO降低62%
技术架构创新引领行业方向
Qwen3的混合专家架构和双模式推理机制正在改变大模型的研发方向。行业开始从单纯的参数规模竞赛转向计算效率与智能水平的平衡,更多团队开始探索"小激活参数、大总参数"的高效模型设计。据行业分析,2025年下半年混合专家模型的市场占比预计将从15%提升至40%。

该架构图清晰展示了Qwen3-VL的核心工作流程,Vision Encoder将视觉输入(图片、视频)转化为tokens后,与文本tokens协同进入Qwen3 LM Dense/MoE Decoder处理。这种设计直观呈现了DeepStack等关键技术的实现路径,体现了Qwen3在多模态融合上的技术突破,为开发者构建跨模态应用提供了清晰的技术路线图。
部署与实践指南
Qwen3-235B-A22B-MLX-4bit模型已在GitCode开源,开发者可通过以下命令获取并部署:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-MLX-4bit
cd Qwen3-235B-A22B-MLX-4bit
pip install -r requirements.txt
模型支持动态切换双模式,示例代码如下:
# 思考模式示例
response = generate(
model, tokenizer,
prompt="求解方程:x² + 5x + 6 = 0 /think",
enable_thinking=True,
max_tokens=1024
)
# 非思考模式示例
response = generate(
model, tokenizer,
prompt="介绍一下太阳系八大行星 /no_think",
enable_thinking=False,
max_tokens=512
)
总结与展望
Qwen3-235B-A22B通过创新的混合专家架构和双模式推理机制,实现了"万亿性能、百亿成本"的突破,重新定义了大模型的效率标准。其动态适配任务复杂度的能力,使得AI系统第一次能够像人类一样"按需思考",在复杂推理与高效响应间找到最佳平衡点。
随着混合专家架构的普及,AI行业正告别"参数军备竞赛",进入"智能效率比"驱动的新发展阶段。Qwen3不仅是一次技术突破,更标志着企业级AI应用从"高端解决方案"向"基础设施"的历史性转变。对于企业而言,现在正是布局这一技术变革的最佳时机,通过场景分层部署和渐进式落地,充分释放大模型技术的商业价值。
未来,随着工具集成能力的不断增强和多模态交互的深入发展,Qwen3有望成为连接数字世界与物理世界的智能枢纽,开启人机协作的新纪元。
更多推荐
 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)