
醒醒!你离真正可运营的AI产品,还差一个完整的平台架构
企业级大模型平台建设面临算力管理、模型部署和运维等核心挑战。本文提出一站式解决方案,通过分层架构整合智算底座、模型层和应用层。底层兼容多架构算力资源池化,中层提供模型全生命周期管理,上层支持快速构建AI应用。平台强调安全合规与成本优化,建议企业采取试点到统一平台的渐进路径,平衡自建与采购策略。该架构旨在解决模型碎片化、算力利用率低等痛点,推动AI从技术演示转向稳定运营。
最近两年,只要聊到数字化转型,几乎绕不开一个词:大模型。
很多企业已经上了车:有人在做智能客服,有人在尝试知识问答,也有人在把大模型接进业务系统。但真正落地后,大家往往会发现几个共性问题:
- 模型不少,但不好管:版本散落在各个团队,谁在用哪个模型,说不清;
- 算力不便宜,却总感觉不够用:有的集群空着,有的任务排队排到天荒地老;
- 做出来一个 Demo 不难,要把它变成稳定可运营的产品,难。
深入聊几圈你会发现,很多问题不是“模型不够聪明”,而是底层平台没有搭好。如果把大模型能力比作一座大楼,模型只是中间几层,更关键的是下面的地基和上面的配套设施。
下面这张图,展示的就是一个比较完整的企业级大模型平台,从最底层的智算底座,到中间的模型层,再到最上面的应用和运营。本文就借这张图,带你从下往上走一遍,看清楚一套“一站式大模型平台”应该长什么样。
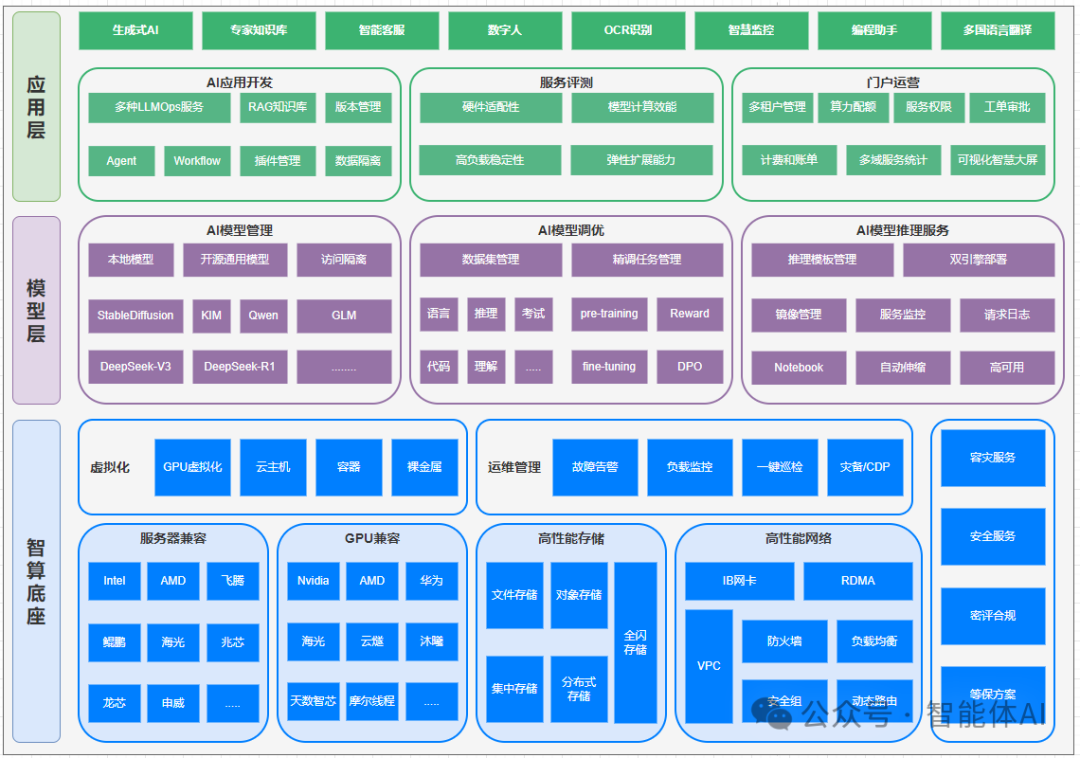
一、为什么企业需要“一站式”大模型平台?
很多企业现在的状态是这样的:
算力从云厂商买一点、服务器自己再上几台;模型从各大开源社区拉一些;业务线各自找团队搞几个 Demo。刚开始看着都挺热闹,但时间一长,就会暴露出问题:
- 项目“烟囱化”:每个项目一套环境、一套模型、一套数据,重复建设严重;
- 运维成本高:出问题不知道找谁,找到了也很难排查;
- 安全和合规无法保证:数据在哪、谁在用,缺乏统一视角。
所以,越来越多企业意识到:与其各搞各的,不如搭一套统一的平台,把算力、模型、工具和应用开发能力都整合进来,既能支撑现在的项目,也能承载未来的增长。
接下来,我们就顺着这张架构图,从最底层的“智算底座”开始往上看。

二、最底层的“地基”:智算底座如何托起大模型时代
1. 多架构算力兼容:让“芯片多样性”成为优势
在算力这件事上,没有“放之四海而皆准”的唯一选择。
有的场景更依赖传统 CPU,有的却高度依赖 GPU、NPU 等专用加速芯片,还有国产化、本地部署等因素要考虑。
在服务器层面,这个平台兼容了 Intel、AMD 这样的国际主流 CPU,也支持飞腾、鲲鹏、海光、兆芯、龙芯、申威等国产架构。
在 GPU 侧,既能用 NVIDIA,也能用 AMD、华为,还能对接海光、云鉴、沐曦、天数智芯、摩尔线程等一众国产算力芯片。
对企业来说,这种多样性意味着:
- 可以结合成本、性能和国产化要求自由搭配;
- 不会被某一家芯片厂商绑死,长期规划更灵活;
- 后续引入新硬件时,平台可以平滑适配。
2. 虚拟化与资源池化:算力像水电一样按需取
有了硬件,还需要把它“变成资源”。
这一层提供了 GPU 虚拟化、云主机、容器、裸金属四种形态:
- GPU 虚拟化:把一块 GPU 划成多个虚拟卡,用于小模型推理或开发测试;
- 云主机:适合通用运算和轻量业务;
- 容器:适合频繁发布迭代的模型服务,天然契合微服务架构;
- 裸金属:给大规模训练和高性能场景提供接近“原生硬件”的体验。
真正落地时,一般是训练跑在大规格裸金属或 GPU 服务器上,推理则用容器+虚拟化的方式弹性扩缩。
通过资源池化,算力不再被某个项目“独占”,可以按需分配、按量计费。
3. 高性能存储与网络:大模型的“血管”和“神经”
大模型训练对数据吞吐的要求极高,如果存储与网络跟不上,再多 GPU 也是干等。
在存储方面,这个平台把常见形态都考虑进去了:
- 文件存储:适合代码、模型文件等;
- 对象存储:适合海量训练数据、日志、图片等非结构化数据;
- 全闪存储:提供高 IOPS 和低时延,服务关键训练任务;
- 集中存储 + 分布式存储:兼顾性能与规模。
网络则通过 IB 网卡、RDMA、VPC 等技术,构建出一张高速、低时延、可隔离的网络:
- IB+RDMA 让多机多卡训练的通信开销降到最低;
- VPC 和安全组、防火墙、动态路由,保证不同业务和租户之间的隔离与安全;
- 负载均衡负责把流量合理分发到不同服务节点,避免“冷热不均”。
4. 运维与安全:稳定运行才是真本事
任何平台真正落地,最终都要回到一个字:稳。
这张图里可以看到几个关键能力:
- 故障告警、负载监控:实时掌握各节点状态和资源利用情况;
- 一键巡检:常规体检,提前发现风险;
- 文查/CDP:文档与数据保护,避免误删、误操作带来不可逆损失;
- 安全服务、密评合规、等保方案:帮助政企客户满足监管要求;
- 客户服务:从环境部署到日常运维,有完整服务体系兜底。
如果说算力、存储、网络是骨骼和肌肉,那这些运维与安全能力就是免疫系统,让这套平台可以长久运行而不积重难返。
三、模型层:让大模型真正“可管、可训、可用”
夯实了智算底座,接下来就来到整个架构的“心脏”:模型层。
1. 模型管理:给模型建一个“资产仓库”
很多团队现在管理模型的方式,其实非常原始:目录里堆一堆 xxx-v1、xxx-v2 文件,靠人记哪个是最新的,哪个是线上在用的。
遇到合规审计,往往是一头雾水。
在这套平台里,模型管理被当成一种“资产管理”来做:
- 支持本地模型和开源通用模型统一管理;
- 已集成 Stable Diffusion、KIM、Qwen、GLM、DeepSeek-V3、DeepSeek-R1 等主流模型;
- 对每一个模型可以配置访问权限、使用范围,实现访问隔离;
- 结合数据集管理,可以记录某个模型是基于哪几批数据训练出来的,为后续追溯和优化提供基础。
简单说,就是把模型当作企业的重要资产,而不是“散落在某个工程师电脑里的文件”。
2. 模型调优:把通用大模型打造成企业专属智能体
通用大模型再强,它对你的业务不了解,真正能产生价值的,是经过企业数据和场景调优之后的“专属模型”。
这部分的能力主要包括:
- 精调任务管理:统一管理预训练(pre-training)、微调(fine-tuning)、DPO 等任务;
- 支持多种任务类型:包括语言、推理、代码生成等;
- 引入 Reward、DPO 等新一代对齐技术,让模型更“懂企业规矩”,比如必须遵守的业务流程、合规要求等;
- 训练数据和任务可以统一在平台上配置和跟踪,形成一条可追溯的调优流水线。
对业务方来说,你不需要关心底层用了多少卡、跑了多久,只要关心:
给什么数据、设什么目标、训练结果表现怎么样。
3. 模型推理服务:稳定可扩展的在线 AI 工厂
模型训练完并不是终点,把它变成一个稳定、可扩展的在线服务才是关键。
平台在推理服务这块做了几件事:
- 推理集群管理:支持按模型、业务划分集群,集中管理资源;
- 双引擎部署:可以适配不同的推理引擎,根据场景选择最合适的一种;
- 镜像管理:统一维护推理镜像,保证环境一致;
- 服务监控、请求日志:随时掌握服务指标,必要时能追踪到具体请求;
- 自动伸缩:高峰期自动扩容,低峰期收缩,节省成本;
- 高可用:通过多副本部署与故障转移,确保服务不中断;
- 为算法工程师提供 Notebook 环境,方便线上调试和实验。
很多企业从“Demo 阶段”迈向“生产阶段”时,最容易在这一层栽跟头。
有了这样一套推理服务体系,模型上线和运维的门槛就会低很多。
四、应用层:把 AI 能力装进一个个可落地的场景
当底层算力和模型能力都准备好后,真正决定价值的,是能否快速构建面向业务的应用。
1. 典型应用矩阵:从生成式 AI 到行业助手
在应用层,这个平台预置了不少常见场景:
- 生成式 AI:如文案生成、图像生成等;
- 专家知识库:对接企业内部文档和知识,提供专业问答服务;
- 智能客服:替代或辅助人工客服处理大量标准化问题;
- 数字人:结合语音、视频,实现更具互动感的对话体验;
- OCR 识别:对票据、合同等进行自动识别录入;
- 智慧整控:做一些综合监控与智能分析;
- 编程助手:辅助开发者写代码、查问题;
- 多国语言翻译:帮助企业处理跨语言沟通需求。
这些应用并不是孤立的,而是依托统一的大模型能力构建出来的不同“前端”。
2. AI 应用开发平台:让更多人能搭建自己的 AI 应用
光有预置应用还不够,企业还需要根据自身行业特点做定制开发。
为此,平台在应用开发这一块下了不少功夫:
- 多种 LLMOps 服务:围绕大模型的全生命周期管理(发布、监控、回滚等);
- RAG 知识库:支持把企业内部文档、数据库等接入模型,实现“带企业记忆”的问答;
- Agent、Workflow:从简单的对话助手升级到能调用工具、执行流程的“智能代理”,比如自动拉取报表、填单、发邮件;
- 版本管理、插件管理、数据隔离:保证每一次迭代都有据可查,不同项目之间互不干扰;
- 数据服务:把企业现有的业务系统和外部数据源串联起来。
在这样的平台上,开发一个面向某个业务线的问答助手,可能只需要:
配置知识库 → 配一个 Agent → 做一些简单流程编排 → 接到前端或微信企业号中,就可以上线试用。
3. 服务评测与门户运营:从“技术平台”走向“运营平台”
很多公司搭完平台之后,会有一个新的问题:
“我们到底用了多少算力?哪几个部门用得最多?效果究竟如何?”
这时就需要评测和运营能力来兜底。
在这张图里,平台提供了:
- 服务评测:从硬件适配性、模型计算效率,到高负载稳定性都有量化指标;
- 门户运营:支持多租户管理、算力配额、服务权限、工单审批;
- 计费和账单、多域服务统计、可视化大屏:可以清楚看到哪个项目、哪个部门消耗了多少资源,效果如何,为后续预算和优化提供依据。
当你能用运营视角去看整个平台时,AI 不再只是成本中心,而会逐渐变成可以度量投入产出比的“新型生产力工具”。
五、从架构到实践:企业落地大模型平台的几点建议
有了这样的架构蓝图,真正落地时还会遇到很多细节问题。结合近期和一些企业交流的经验,简单给几点建议,供你参考。
1. 建设路径:从小范围试点到统一平台
比较稳妥的路径通常是:
- 选一两个业务场景(例如客服或内部知识问答)做试点;
- 同时规划好底层平台架构,把算力、存储、模型管理等基础能力先搭“骨架”;
- 随着试点项目跑通,再逐步吸纳更多业务线接入,统一到同一套平台上。
避免一开始就大而全堆功能,而是让实际项目倒逼平台演进。
2. 自建还是采购:没有标准答案
- 如果企业有较强技术团队、对数据安全要求极高(例如金融、政府等),可以考虑以自建为主,结合厂商的平台方案做定制;
- 如果团队人手有限、业务需要快速试错,可以重点考虑采购成熟平台,在其之上做二次开发。
关键是明确边界:哪些是必须自己掌控的,哪些可以交给合作伙伴。
3. 安全合规与成本优化要同步考虑
-
在安全方面,不要等项目快上线了再想起“等保”“密评”这些事。
网段规划、访问控制、日志留存等最好在一开始就设计好;
-
在成本方面,可以从一开始就建立资源计量和成本看板,让业务方对算力成本有感知,有利于后续优化和预算管理。
4. 人才与组织同样重要
再好的平台,如果没有合适的团队来用,效果也会大打折扣。
建议尽早考虑:
- 谁负责平台建设与运维?
- 谁负责结合业务挖掘应用场景?
- 数据治理由谁牵头?
有的企业选择成立“AI 中台”或“数据智能部”,把这些职责整合起来,这是一个值得参考的方向。
六、总结
从这张架构图可以看到,一套完整的大模型平台,并不只是“有几个模型”这么简单,而是从下到上分成三大块:
- 智算底座:解决算力、存储、网络、安全这些“基础设施”问题;
- 模型层:让模型可以统一管理、持续调优、稳定推理;
- 应用层:通过开发平台和运营门户,让大模型能力真正进入一个个业务场景。
对于正在规划或已经在路上的企业来说,也许不一定要照着这张图一模一样去实现,但它提供了一个比较完整的思考框架:
每往上走一层,都要问自己——下面这一层是否已经打牢?
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)