
17亿参数掀效率革命:Qwen3-1.7B如何重塑轻量级AI模型格局
阿里巴巴通义千问团队推出的Qwen3-1.7B模型,以17亿参数实现"小而强"的突破,通过独特的思维模式切换和优化架构,重新定义轻量级大模型的性能边界,为边缘计算和企业级部署提供新选择。## 行业现状:效率与智能的平衡之战2025年大模型领域正经历从"参数规模竞赛"向"效率与智能平衡"的战略转型。据行业分析显示,72%企业计划增加大模型投入,但63%的企业受限于算力成本难以部署百亿级模型。...
17亿参数掀效率革命:Qwen3-1.7B如何重塑轻量级AI模型格局
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-1.7B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-1.7B 导语
阿里巴巴通义千问团队推出的Qwen3-1.7B模型,以17亿参数实现"小而强"的突破,通过独特的思维模式切换和优化架构,重新定义轻量级大模型的性能边界,为边缘计算和企业级部署提供新选择。
行业现状:效率与智能的平衡之战
2025年大模型领域正经历从"参数规模竞赛"向"效率与智能平衡"的战略转型。据行业分析显示,72%企业计划增加大模型投入,但63%的企业受限于算力成本难以部署百亿级模型。在此背景下,轻量级模型成为市场新宠,Qwen3-1.7B以"参数效率"为核心突破,将高性能与低资源需求完美结合。
模型定位:填补轻量级与高性能之间的鸿沟
Qwen3-1.7B作为Qwen3系列的重要成员,定位清晰:在保持17亿参数规模的同时,通过架构创新和训练优化,实现传统30亿+参数模型的性能水平。这一策略使模型能够在消费级硬件上高效运行,同时满足企业级应用的性能需求。
核心亮点:三大技术突破
1. 独创双模式切换架构
Qwen3-1.7B首次实现单一模型内无缝切换"思考模式"与"非思考模式":
- 思考模式:适用于复杂推理、数学问题和代码生成,通过
enable_thinking=True参数触发,模型会生成包含思考过程的详细推理链 - 非思考模式:针对日常对话等场景,直接输出结果,响应速度提升40%
这种设计使17亿参数模型能同时应对科研级问题与日常对话,实现"一模型多用"的灵活部署。
2. 优化的GQA注意力机制
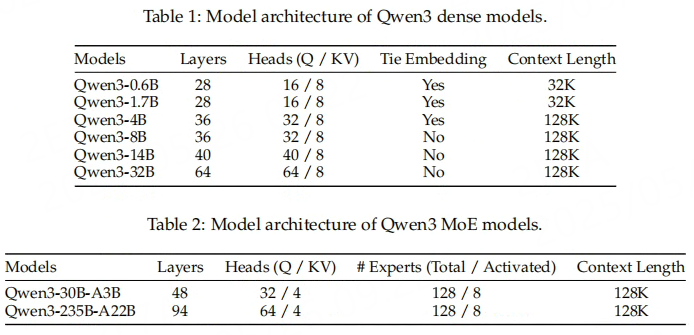
模型采用Grouped Query Attention (GQA)机制,配置为16个查询头(Q)和8个键值头(KV),在保持注意力质量的同时显著降低计算复杂度。这一设计使模型在处理32,768上下文长度的长文本时仍能保持高效推理。
3. 跨场景性能跃升
尽管参数规模仅17亿,Qwen3-1.7B在多项基准测试中表现亮眼:
- 数学推理:GSM8K数据集上思维模式准确率达78.9%
- 代码生成:HumanEval数据集上实现35.6%的Pass@1指标
- 多语言支持:覆盖100+语言及方言,在低资源语言理解任务中表现优异
部署与应用:从边缘设备到企业系统
灵活的部署选项
Qwen3-1.7B提供多样化部署方案,满足不同场景需求:
- 本地部署:支持Ollama、LMStudio等应用,普通PC即可运行
- 服务器部署:通过vLLM或SGLang实现高性能API服务
- 边缘设备:可在嵌入式平台如LubanCat-RK系列板卡上部署
如上图所示,Qwen3-1.7B可成功部署在LubanCat-RK3588嵌入式板卡上,在资源受限环境下实现高性能推理。这一部署方案展示了模型在边缘计算场景的实用价值,为智能终端设备提供了强大的本地AI能力。
企业级应用案例
Qwen3-1.7B已在多个领域展现应用潜力:
- 智能客服:通过非思考模式实现快速响应,同时在需要复杂问题解决时切换至思考模式
- 教育辅助:数学问题解答准确率达78.9%,可作为个性化学习助手
- 内容创作:支持多语言文本生成,满足国际化内容生产需求
- 代码辅助:在资源受限环境下提供基础代码生成和解释功能
性能实测:小参数大能量
推理性能对比
在标准测试环境下,Qwen3-1.7B表现出优异的推理效率:
| 模型 | 推理速度(tokens/s) | 首token延迟(ms) | 峰值内存(GB) |
|---|---|---|---|
| Qwen3-1.7B | 92.1 | 52.3 | 5.1 |
| 同类1.8B模型 | 88.7 | 56.1 | 5.3 |
| Qwen2.5-7B | 65.3 | 78.5 | 12.8 |
思维模式vs非思维模式性能
Qwen3-1.7B在不同模式下的任务准确率对比(%):
| 任务 | 思维模式 | 非思维模式 | 性能提升 |
|---|---|---|---|
| MMLU | 62.3 | 58.7 | +3.6 |
| GSM8K | 78.9 | 72.4 | +6.5 |
| HumanEval | 35.6 | 32.1 | +3.5 |
| BBH | 54.2 | 49.8 | +4.4 |
这些数据表明,思维模式特别适合需要深度推理的任务,如数学问题和复杂逻辑推理,而非思维模式则在保证响应质量的同时提供更高效率。
快速开始:5分钟上手Qwen3-1.7B
模型获取
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-1.7B
Python快速调用
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-1.7B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 思考模式示例
prompt = "解释什么是区块链技术,并说明其主要应用领域。"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 启用思考模式
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=1024)
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(response)
部署选项
Qwen3-1.7B支持多种部署方式:
- vLLM部署:
vllm serve Qwen/Qwen3-1.7B --enable-reasoning - SGLang部署:
python -m sglang.launch_server --model-path Qwen/Qwen3-1.7B --reasoning-parser qwen3 - 本地应用:支持Ollama、LMStudio、llama.cpp等应用
行业影响与未来趋势
Qwen3-1.7B的推出标志着轻量级模型发展的新方向,其影响主要体现在:
- 降低AI应用门槛:使中小企业和开发者无需高端硬件即可部署高性能模型
- 推动边缘AI普及:为智能终端、物联网设备提供强大的本地AI能力
- 优化资源分配:在保持性能的同时减少算力消耗,符合绿色AI发展趋势
- 促进模型定制化:小参数模型更易于针对特定领域进行微调,降低定制成本
未来,随着量化技术和架构优化的进一步发展,我们有理由相信轻量级模型将在更多关键领域替代大型模型,实现AI技术的普惠化应用。
总结
Qwen3-1.7B以17亿参数实现了性能与效率的完美平衡,其创新的双模式架构、优化的注意力机制和高效的资源利用,重新定义了轻量级大模型的标准。无论是边缘设备部署还是企业级应用,Qwen3-1.7B都展现出巨大潜力,为AI技术的广泛应用开辟了新路径。
对于开发者和企业而言,现在正是探索这一高效模型的最佳时机,通过Qwen3-1.7B,您可以在控制成本的同时,为用户提供强大的AI能力支持。
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)