
算力告急?用ATLAS框架!LLM自适应测试,为你节省90%的GPU资源,效果不打折!
大语言模型(LLM)的评估正陷入一场“军备竞赛”——为了全面衡量模型能力,主流基准测试往往包含数千甚至数万道题目。例如HellaSwag有5608题,GSM8K有1307题,完整评估一次需耗费数天时间, computational成本高昂。更严重的是,静态评估将所有题目“一视同仁”,忽略了题目质量差异:3%-6%的题目存在“负区分度”(即越强的模型反而正确率越低,可能源于标注错误),却仍被计入平均
一、当LLM评估陷入“题海战术”:数千道测试题拖慢研发,静态评分掩盖模型真实能力
大语言模型(LLM)的评估正陷入一场“军备竞赛”——为了全面衡量模型能力,主流基准测试往往包含数千甚至数万道题目。例如HellaSwag有5608题,GSM8K有1307题,完整评估一次需耗费数天时间, computational成本高昂。更严重的是,静态评估将所有题目“一视同仁”,忽略了题目质量差异:3%-6%的题目存在“负区分度”(即越强的模型反而正确率越低,可能源于标注错误),却仍被计入平均分,导致评分失真。此外,固定题目集容易被模型“ memorize”(数据污染),高分未必反映真实能力;而平均分又会掩盖能力相近模型的细微差异,例如两个准确率相同的模型,可能因解决的题目难度不同而实际能力相差悬殊。
面对这些痛点,美国圣母大学(University of Notre Dame)团队提出ATLAS(Adaptive Testing for LLM Ability Scoring)框架,将心理测量学中的“计算机自适应测试”(CAT)引入LLM评估:通过动态选择最具信息量的题目,在保证评估精度的前提下,将测试题目数量减少90%,同时降低数据污染风险。
二、论文技术速览
▌核心贡献:提出ATLAS自适应测试框架,基于IRT模型动态选择高信息量题目,实现LLM能力精准估计
▌性能指标:HellaSwag仅需42题达0.154 MAE(与全量评估相当)| 平均减少90%题目 | 项目曝光率<10% | 测试重叠率16-27%
▌代码状态:已开源
▌技术谱系:静态基准测试→IRT参数校准→动态项目选择(ATLAS)
三、从“一刀切”到“因材施教”:LLM评估的技术演进与ATLAS的突破契机
传统LLM评估依赖“静态基准测试”,即所有模型回答固定题目集后计算平均分。这种方式源于早期NLP任务,但随着模型能力提升,其三大缺陷日益凸显:
- 效率低下:数千道题目中,大量“简单题”(模型正确率>95%)和“无效题”(负区分度)浪费算力;
- 评分失真:平均分无法区分“擅长难题”和“擅长简单题”的模型,例如两个准确率80%的模型,能力可能相差1.2个标准差;
- 数据污染:固定题目易泄露到预训练数据,模型通过“死记硬背”得高分,而非真实推理能力。
为解决这些问题,研究者曾尝试用IRT(项目反应理论) 校准题目参数(难度、区分度、猜测率),但早期应用局限于“静态子集选择”(如MetaBench仅筛选固定题目子集),未能实现动态适配。直到ATLAS框架提出,才真正将“自适应测试”落地:通过实时估计模型能力,动态挑选对当前模型最具信息量的题目,直至达到预设精度阈值后停止测试。这一思路类似“个性化考试”——对新手出简单题,对专家出难题,用最少的题目精准定位能力水平。
四、ATLAS框架拆解:用IRT模型“校准题目”,动态选择“最聪明的考题”
ATLAS的核心是**“先校准题目,再动态测试”**,分为四个关键步骤:
1. 题目质量过滤:剔除“无效题”
从原始基准数据中筛选高区分度题目:
- 移除“低方差题”(如所有模型正确率>95%或<5%的题目);
- 计算“点二列相关系数”(r_pb),保留r_pb>0.1的题目(确保题目能区分模型能力)。
例如在WinoGrande中,3.2%的题目因r_pb<0.1被剔除,避免无效题目干扰评估。
2. IRT参数校准:给题目“贴标签”
采用三参数逻辑斯蒂(3PL)IRT模型,为每个题目估计三个参数:
- 难度(b_i):模型能力达到该值时,正确率为50%(排除猜测);
- 区分度(a_i):题目区分不同能力模型的能力(a_i越高,区分度越强);
- 猜测率(c_i):随机猜测时的正确率(如四选一题目c_i≈0.25)。
公式如下: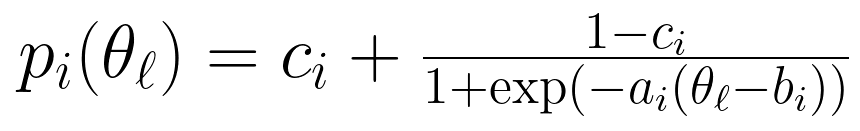
(其中 为模型能力估计值)
为模型能力估计值)
为实现大规模校准,团队提出“分区校准+共同模型链接”策略:将题目分为多个子集独立校准,再通过所有模型的能力估计值统一参数尺度,计算复杂度从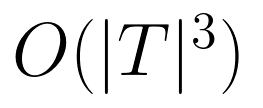 降至
降至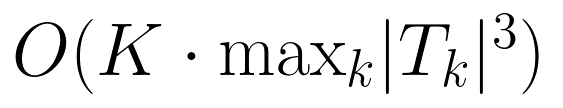 ,确保在5个基准(共约1万题)上高效完成校准。
,确保在5个基准(共约1万题)上高效完成校准。
3. 动态题目选择:每道题都“信息量最大化”
测试时,ATLAS为每个模型实时调整题目选择:
- 初始阶段:选择难度接近当前能力估计(初始为0)的题目;
- 迭代阶段:计算所有未使用题目的Fisher信息量(衡量题目对能力估计的贡献),从信息量前5的题目中随机选择1道(避免过度依赖特定题目类型);
- 终止条件:当能力估计的标准误差(SE)<0.1/0.2/0.3(可配置)或题目数达上限(500题)时停止。
Fisher信息量公式为: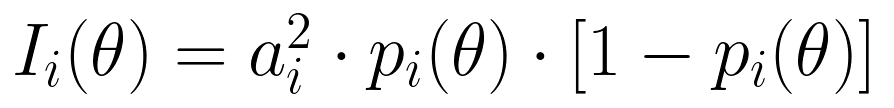
(a_i越高、题目正确率接近50%时,信息量越大)
4. 能力估计:用IRT分数替代“平均分”
通过模型的答题记录,采用期望后验估计(EAP) 计算能力值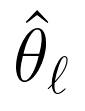 ,公式为:
,公式为: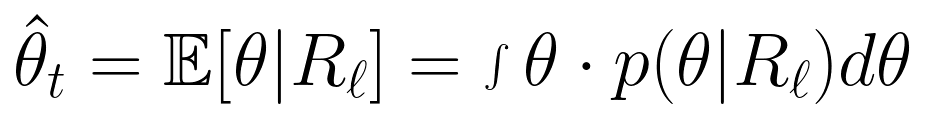
该分数综合考虑题目难度和区分度,能有效区分平均分相同但能力不同的模型。
五、实验验证:90%题目减少+更高精度,23%模型排名发生巨变
团队在5个主流基准(WinoGrande、TruthfulQA、HellaSwag、GSM8K、ARC)上验证了ATLAS的性能,核心结果如下:
1. 效率与精度:用1/10的题目达到全量评估效果
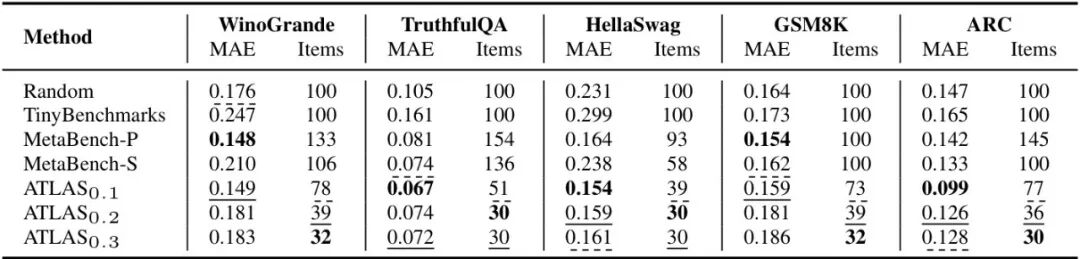 表格1:不同方法的MAE和平均题目数对比,数值越低越好
表格1:不同方法的MAE和平均题目数对比,数值越低越好
ATLAS在各基准上实现“降维打击”:
- HellaSwag:仅用39题(全量5608题的0.7%)即达到0.154 MAE,与MetaBench(93题)精度相当,题目数减少58%;
- TruthfulQA:51题实现0.067 MAE,比MetaBench-P(154题)题目数减少67%,精度提升17%;
- ARC:77题实现0.099 MAE,比MetaBench-P(145题)题目数减少47%,精度提升30%。
2. 抗污染能力:题目曝光率<10%,测试重叠率<27%
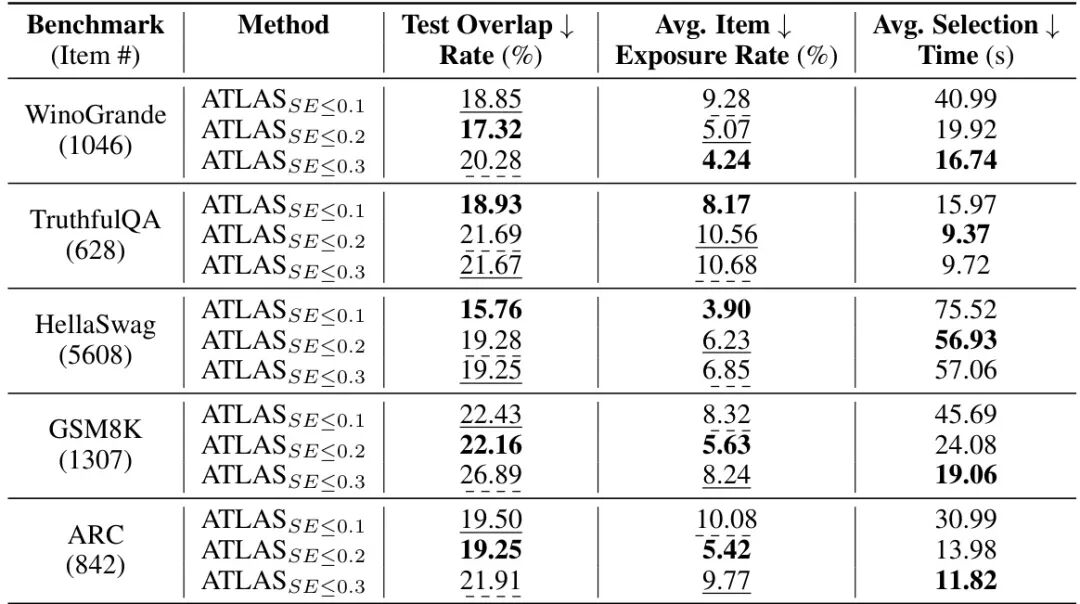 表2:ATLAS的测试重叠率、题目曝光率和选择时间
表2:ATLAS的测试重叠率、题目曝光率和选择时间
- 低曝光率:单题平均仅在<10%的模型评估中出现(如HellaSwag曝光率3.9%),远低于静态基准的100%曝光,大幅降低数据污染风险;
- 低重叠率:任意两个模型的测试题目重叠率仅16%-27%(如HellaSwag为15.8%),避免“一套题考所有模型”的漏洞。
3. 模型区分度:23%-31%模型排名变动,揭开“平均分陷阱”
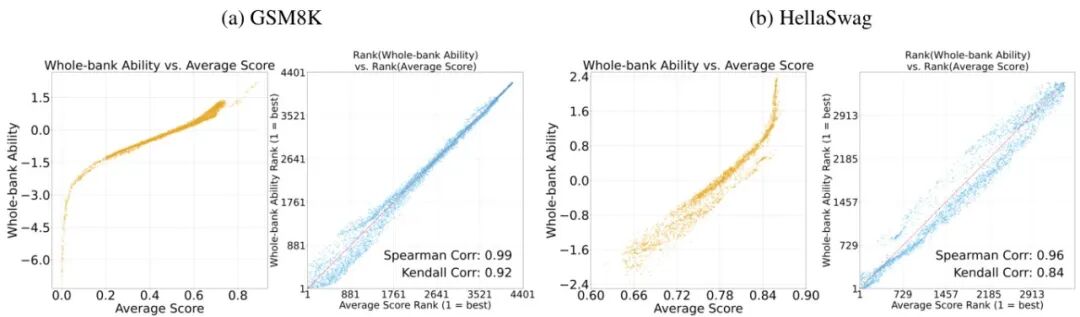 图2:IRT能力估计vs原始准确率的排名对比,右侧显示23%模型排名变动>10位
图2:IRT能力估计vs原始准确率的排名对比,右侧显示23%模型排名变动>10位
ATLAS的IRT能力分数能区分“平均分相同但能力不同”的模型:
- 案例:两个在WinoGrande上准确率均为83.3%的模型,因解决题目难度不同,IRT能力分数分别为1.2和0.6(图3);
- 排名重构:在GSM8K上,23%的模型IRT排名较准确率排名变动>10位;在HellaSwag上,这一比例达31%,揭示静态评分的局限性。
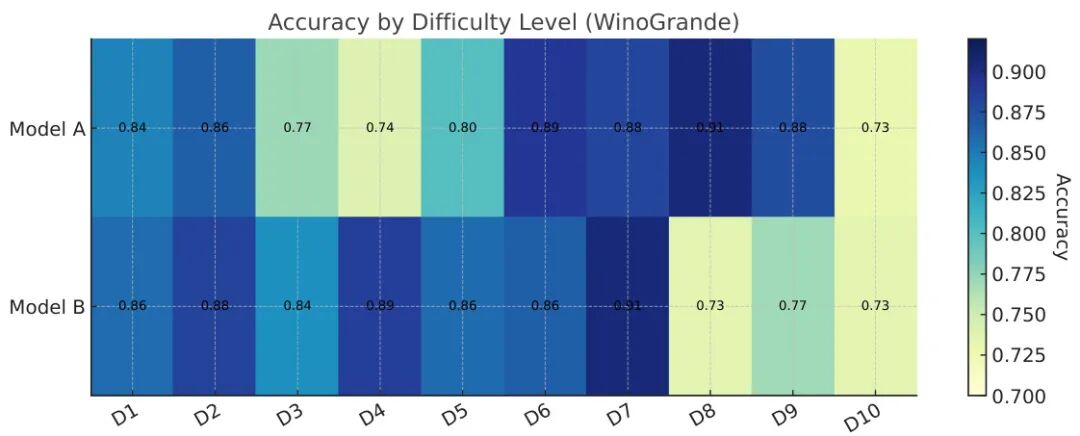 图3:相同准确率模型的题目响应热力图,模型A擅长难题(右侧深色),模型B擅长简单题(左侧深色),IRT分数差异显著
图3:相同准确率模型的题目响应热力图,模型A擅长难题(右侧深色),模型B擅长简单题(左侧深色),IRT分数差异显著
总结
ATLAS框架通过引入心理测量学的“自适应测试”思想,彻底改变了LLM评估的范式:从“题海战术”转向“精准狙击”,用90%的题目减少实现与全量评估相当的精度;从“平均分模糊”转向“IRT能力精准量化”,揭示模型真实能力差异;从“固定题目集易污染”转向“动态题目低曝光”,提升评估安全性。开源的代码和校准题目库(覆盖5大主流基准)为LLM研发提供了高效、可靠的评估工具,推动评估从“经验主义”走向“测量科学”。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!
更多推荐
 16
16 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)