
Ling-mini-2.0开源:160亿参数MoE模型如何重新定义大模型效率边界
蚂蚁集团百灵团队正式开源MoE架构大语言模型Ling-mini-2.0,以160亿总参数、14亿激活参数的设计,实现了7-8B稠密模型的性能水平,同时将推理速度提升2倍以上,标志着大模型行业从参数竞赛转向效率优化的关键拐点。## 行业现状:参数竞赛遭遇算力天花板2025年,大语言模型行业正面临严峻的效率瓶颈。据《开源模型参数状态报告》显示,主流开源模型平均参数规模达671B,但实际部署中仅3
Ling-mini-2.0开源:160亿参数MoE模型如何重新定义大模型效率边界
【免费下载链接】Ling-mini-2.0  项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ling-mini-2.0
项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ling-mini-2.0
导语
蚂蚁集团百灵团队正式开源MoE架构大语言模型Ling-mini-2.0,以160亿总参数、14亿激活参数的设计,实现了7-8B稠密模型的性能水平,同时将推理速度提升2倍以上,标志着大模型行业从参数竞赛转向效率优化的关键拐点。
行业现状:参数竞赛遭遇算力天花板
2025年,大语言模型行业正面临严峻的效率瓶颈。据《开源模型参数状态报告》显示,主流开源模型平均参数规模达671B,但实际部署中仅37B参数被有效激活,"参数冗余"现象导致算力资源严重浪费。与此同时,企业级应用对模型响应速度和部署成本的要求日益严苛,72%的组织计划在2025年增加AI投入,但近40%企业年度投入已超过25万美元,效率优化成为行业突围的关键。
在此背景下,混合专家(MoE)架构凭借"稀疏激活"特性成为破局方向。通过仅激活部分参数处理输入,MoE模型在保持大参数量优势的同时显著降低计算开销。Ling-mini-2.0的推出,正是这一技术路线的最新实践——以1/32的激活比例(每token仅激活1.4B参数),实现了与7-8B稠密模型相当的性能。
核心亮点:四大技术突破重构效率标准
1. 极致稀疏的MoE架构设计
Ling-mini-2.0采用创新的1/32激活比例MoE架构,总参数16B但单token激活参数仅1.4B(非嵌入层789M)。这一设计基于团队提出的"Ling Scaling Laws",通过优化专家粒度、共享专家比例、注意力分配及路由策略,使小激活模型实现7倍等效稠密性能。

如上图所示,在MMLU-Pro、Humanity's Last Exam等推理基准测试中,Ling-mini-2.0显著超越Qwen3-4B/8B等稠密模型,甚至在部分任务上达到GPT-OSS-20B水平。这一对比充分体现了MoE架构在性能与效率平衡上的优势,为资源受限场景提供了高效解决方案。
2. FP8混合精度训练的工业级突破
作为业界首个支持FP8混合精度训练的MoE开源方案,Ling-2.0通过细粒度量化(tile/block wise scaling)解决了传统FP8训练的精度损失问题。实验显示,在20T+训练token规模下,FP8与BF16的loss差异稳定在0.001以内,且无上涨趋势。
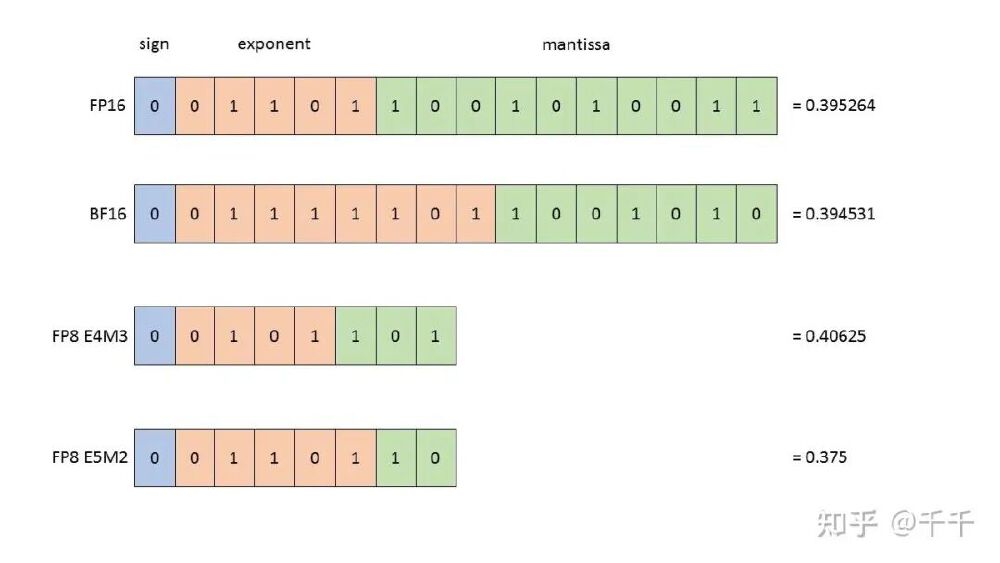
该图展示了FP16、BF16与两种FP8格式(E4M3/E5M2)的位结构差异。Ling团队通过FP8优化器、按需转置权重和填充路由图等技术创新,在8×80G GPU配置下实现109532 token/s的训练吞吐量,较LLaMA 3.1 8B提升34.86%,单机显存占用减少14-16GB。
3. 300+token/s的推理速度与128K超长上下文
得益于高度稀疏的架构设计,Ling-mini-2.0在H20硬件上实现300+token/s的生成速度,较8B稠密模型快2倍;在128K上下文场景下(通过YaRN外推技术),相对加速比可达7倍。这一特性使其特别适合长文档处理、代码生成等实时性要求高的任务。

上图显示了不同模型在2000token问答场景下的推理速度对比。Ling-mini-2.0的300+token/s性能,配合其开源的vLLM/SGLang部署方案,为企业级应用提供了低延迟选项,尤其适用于客服对话、实时分析等交互场景。
4. 全链条开源策略与生态支持
团队采取"更开放的开源策略",不仅发布最终模型,还开源5个预训练 checkpoint(5T/10T/15T/20T token版本及base模型),并提供完整的FP8训练代码、部署工具和性能优化指南。在8/16/32×80G GPU配置下,训练吞吐量较Qwen3 8B提升90-120%,大幅降低二次开发门槛。
行业影响:从技术验证到商业落地的关键跨越
Ling-mini-2.0的开源标志着MoE技术从学术研究走向工业应用的成熟。其核心价值体现在三个维度:
技术普惠:通过FP8训练方案和稀疏架构设计,将大模型训练门槛从32×80G GPU降至8卡配置,使中小企业和研究机构具备定制化训练能力。实测显示,在8×80G GPU上,Ling-mini-2.0训练吞吐量达109532 token/s,较LLaMA 3.1 8B提升34.86%。
场景革新:300+token/s的推理速度和128K上下文,使其在移动端本地化部署成为可能。据腾讯科技报道,该模型已实现在苹果设备上的本地运行,响应速度较同类方案提升2倍,为隐私敏感场景(如医疗诊断、金融分析)提供合规解决方案。
生态共建:开源策略吸引了多领域开发者参与。目前已有社区贡献者基于Ling架构开发了法律文档分析、代码审计等垂直领域模型,印证了其作为研究平台的价值。团队同步提供的vLLM/SGLang部署补丁,进一步降低了企业级应用的落地成本。
结论与前瞻
Ling-mini-2.0通过16B总参数/1.4B激活参数的精妙设计、FP8训练技术突破和全链条开源策略,为大模型行业树立了"智能稀疏"的新标杆。其7倍等效稠密性能、300+token/s推理速度和90-120%吞吐量提升,不仅回应了算力成本压力,更重新定义了效率优化的技术路径。
未来,随着MoE架构在多模态融合、持续学习等方向的探索,以及硬件厂商对稀疏计算的针对性优化,我们或将看到更多"小激活大能力"的模型出现。对于企业而言,现在正是评估稀疏模型在客服、代码生成、文档处理等场景落地的最佳时机——通过Ling-mini-2.0这类高效模型,在性能、成本与隐私间找到新平衡点。
行动建议:技术团队可优先评估其在长文档处理(128K上下文)和实时交互(300+token/s)场景的应用潜力;研究机构可重点关注其MoE路由策略和FP8训练代码,探索进一步优化空间。关注项目GitHub获取最新进展,参与社区讨论获取部署最佳实践。
【免费下载链接】Ling-mini-2.0 项目地址: https://ai.gitcode.com/hf_mirrors/inclusionAI/Ling-mini-2.0
更多推荐
 15
15 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)