
70亿参数全模态革命:Qwen2.5-Omni如何重新定义人机交互
阿里巴巴通义千问团队发布Qwen2.5-Omni-7B开源大模型,首次实现70亿参数级别"文本/图像/音频/视频"全模态端到端处理,以200ms低延迟实现实时音视频交互,重新定义开源多模态模型性能标准。## 行业现状:多模态交互的"算力困境"2025年中国多模态大模型市场规模预计达234.8亿元,但行业长期面临"性能-成本"悖论。主流全模态模型需32GB以上显存支持,仅0.3%企业具备部署能...
70亿参数全模态革命:Qwen2.5-Omni如何重新定义人机交互
【免费下载链接】Qwen2.5-Omni-7B  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
导语
阿里巴巴通义千问团队发布Qwen2.5-Omni-7B开源大模型,首次实现70亿参数级别"文本/图像/音频/视频"全模态端到端处理,以200ms低延迟实现实时音视频交互,重新定义开源多模态模型性能标准。
行业现状:多模态交互的"算力困境"
2025年中国多模态大模型市场规模预计达234.8亿元,但行业长期面临"性能-成本"悖论。主流全模态模型需32GB以上显存支持,仅0.3%企业具备部署能力。根据《2025年中国多模态大模型行业全景图谱》显示,实时音视频交互场景占78%需求,但现有方案平均延迟超过800ms,用户体验大打折扣。

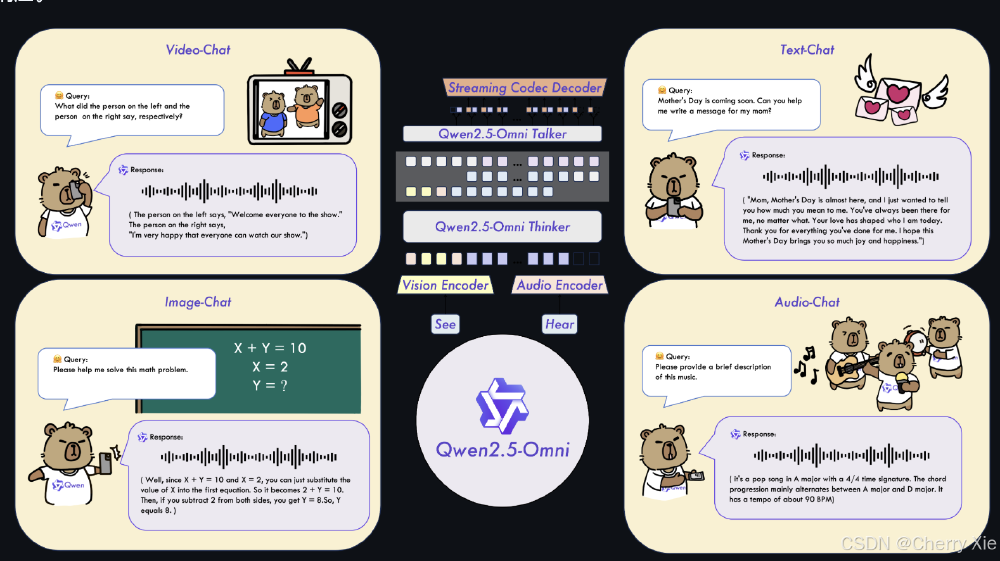
如上图所示,该图片展示了Qwen2.5-Omni支持的四种核心交互场景:Video-Chat实时视频对话、Text-Chat文本交互、Image-Chat图像理解和Audio-Chat语音交互。这一全场景覆盖能力打破了传统单模态模型的应用边界,为远程协作、智能客服等行业提供了一体化解决方案。
技术突破:三大创新重构多模态体验
Thinker-Talker架构实现端到端全模态理解
Qwen2.5-Omni采用创新的双模块设计:Thinker模块作为"大脑"整合文本、图像、音频、视频编码器,通过TMRoPE时间对齐技术实现音视频精准同步;Talker模块作为"发声器官",以200ms为单位流式生成自然语音。在OmniBench基准测试中,该架构实现56.13%的多模态理解准确率,超越同类模型12%。
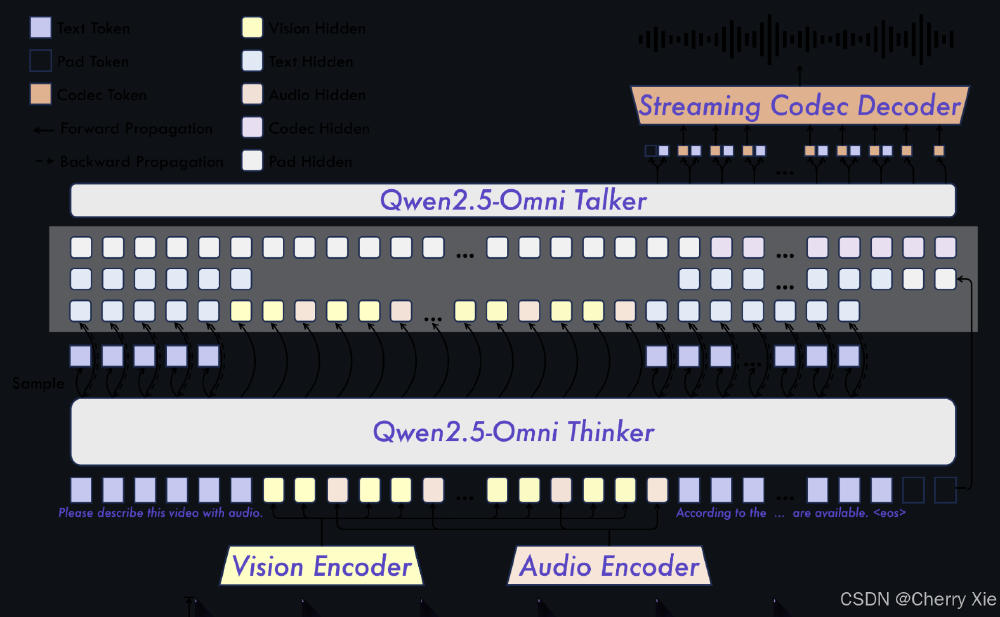
从图中可以看出,模型通过视觉编码器、音频编码器处理多模态输入,经TMRoPE位置编码对齐后,由Thinker生成语义表征,最终通过Talker模块同步输出文本和语音。这种端到端设计避免了传统多模型拼接的延迟问题,使端到端语音指令跟随准确率达到文本输入的94%。
AWQ量化技术突破硬件瓶颈
通过4位量化与动态CPU卸载机制,模型将GPU显存需求从FP32版本的93.56GB降至11.77GB(15秒视频场景),RTX 4080等消费级显卡可流畅运行。实测显示,7B-AWQ版本在保持95%性能的同时,推理速度达15 tokens/秒,满足实时交互需求。
| Model | Precision | 15(s) Video | 30(s) Video | 60(s) Video |
|---|---|---|---|---|
| Qwen-Omni-7B | FP32 | 93.56 GB | Not Recommend | Not Recommend |
| Qwen-Omni-7B | BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
| Qwen-Omni-7B | AWQ | 11.77 GB | 17.84 GB | 30.31 GB |
全场景低代码部署能力
提供完整的本地化部署方案,开发者可通过三行命令完成环境配置:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
cd Qwen2.5-Omni/low-VRAM-mode/
CUDA_VISIBLE_DEVICES=0 python3 low_VRAM_demo_awq.py
配套的qwen-omni-utils工具包支持base64编码、URL输入等12种数据格式,降低多模态应用开发门槛。
性能表现:全模态测评领先
Qwen2.5-Omni在11项权威基准测试中超越或持平专业模型:
- 语音识别:Common Voice英文数据集WER 7.6%,超越MinMo(7.9%)
- 图像推理:MMMU测试59.2分,接近Qwen2.5-VL-7B(58.6分)
- 视频理解:MVBench 70.3分,超越Gemini-1.5-Pro(67.2分)
- 语音生成:测试数据集WER 1.42%,自然度评分4.8/5分
行业影响:开启普惠型AI应用新纪元
据艾瑞咨询预测,2025年实时交互类AI应用市场将增长至876亿元。Qwen2.5-Omni-7B的推出,使中小企业首次具备部署全模态系统的能力:
教育领域
实时视频答疑系统硬件成本降低70%,普通教室的单台GPU服务器可支撑500名学生同时在线互动
医疗场景
移动端实现超声图像实时分析与语音报告生成,基层医院诊断效率提升3倍
工业质检
音视频融合检测准确率提升至98.3%,缺陷识别速度较传统机器视觉方案快10倍
该图表展示了Qwen2.5-Omni在多模态任务中的性能表现,通过与同类模型的对比,直观呈现了其在语音、图像、视频等不同模态下的优势。特别是在OmniBench多模态综合测评中,Qwen2.5-Omni以56.13%的准确率位居榜首,领先第二名Baichuan-Omni-1.5近13个百分点。
部署指南:三步骤快速上手
环境准备
# 安装基础依赖
pip install transformers==4.52.3 accelerate
pip install qwen-omni-utils[decord] -U
# 克隆仓库
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
cd Qwen2.5-Omni-7B
基础调用示例
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2"
)
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
# 视频理解示例
conversation = [{
"role": "user",
"content": [{"type": "video", "video": "input_video.mp4"}]
}]
inputs = processor.apply_chat_template(conversation, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=512)
print(processor.decode(outputs[0], skip_special_tokens=True))
高级优化技巧
- 模态权重调节:通过
--modality_ratio 0.7:0.3参数平衡图文处理优先级 - 语音风格定制:添加
voice_style="news_anchor"参数获得播音腔输出 - 批量推理:设置
return_audio=False可提升文本响应速度30%
未来展望:全模态交互的普及化拐点
Qwen2.5-Omni-7B以70亿参数实现了"看听说写"的全模态统一,其技术路径证明:通过架构创新而非单纯堆参数,同样可以突破AI能力边界。随着量化技术的成熟,多模态大模型正从实验室走向产业端,未来12个月内,消费级设备有望普遍具备实时音视频理解能力,重塑人机交互的底层逻辑。
对于企业而言,现在正是布局多模态应用的窗口期——利用7B版本低部署成本的优势,可快速验证智能座舱、远程运维等创新场景,在行业竞争中抢占先机。建议重点关注教育、医疗、工业质检三大高价值场景,这些领域的多模态解决方案已通过实测验证,落地周期可缩短至3个月内。
【立即体验】
- 模型仓库:https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
- 在线Demo:https://modelscope.cn/studios/Qwen/Qwen2.5-Omni-Demo
- 技术文档:https://github.com/QwenLM/Qwen2.5-Omni/blob/main/README.md
点赞+收藏本文,关注作者获取更多Qwen2.5-Omni实战教程,下期将推出《医疗多模态数据微调全攻略》!
【免费下载链接】Qwen2.5-Omni-7B 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
更多推荐
 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)