
大模型落地:从微调到企业级解决方案的全面实践指南
本文系统探讨了大语言模型(LLM)落地的四大关键环节:1)微调技术,包括LoRA等参数高效方法;2)提示词工程,通过Few-shot等策略提升效果;3)多模态应用,实现跨模态理解与生成;4)企业级解决方案,涵盖模型管理到安全合规。通过代码示例、流程图和对比表格,提供了从技术选型到部署落地的完整指南,并以智能客服系统为例展示了综合实践方案。文章还分析了未来发展趋势与挑战,为企业在算力成本、数据隐私等
引言
随着人工智能技术的飞速发展,大语言模型(LLM)已成为推动产业变革的核心力量。然而,将大模型从实验室成功落地到实际业务场景中,仍面临诸多挑战。本文将系统性地探讨大模型落地的四大关键环节:微调技术、提示词工程、多模态应用以及企业级解决方案,并通过代码示例、流程图、Prompt实例和可视化图表,为读者提供一套完整的大模型落地实践指南。
一、大模型微调:定制化模型能力的核心手段
1.1 微调概述
大模型微调(Fine-tuning)是指在预训练模型的基础上,使用特定领域的数据进行二次训练,使模型适应特定任务的过程。微调能够显著提升模型在特定领域的表现,同时保留预训练模型的通用能力。
1.2 微调方法对比
| 方法类型 | 特点 | 适用场景 | 计算资源需求 |
|---|---|---|---|
| 全参数微调 | 调整所有模型参数 | 领域差异大、数据充足 | 高 |
| 部分参数微调 | 仅调整部分参数层 | 计算资源有限 | 中 |
| LoRA微调 | 添加低秩适配矩阵 | 快速适应、参数高效 | 低 |
| Adapter微调 | 插入小型适配模块 | 多任务场景 | 中低 |
| Prompt微调 | 仅调整输入提示 | 数据极少场景 | 极低 |
1.3 LoRA微调代码示例
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
# 加载基础模型
model_name = "meta-llama/Llama-2-7b-hf"
model = AutoModelForCausalLM.from_pretrained(model_name)
# 配置LoRA参数
lora_config = LoraConfig(
r=16, # 低秩矩阵维度
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 目标模块
lora_dropout=0.05, # Dropout率
bias="none", # 偏置处理方式
task_type="CAUSAL_LM" # 任务类型
)
# 应用LoRA配置
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters() # 打印可训练参数比例
# 训练配置
training_args = TrainingArguments(
output_dir="./lora-finetuned",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
num_train_epochs=3,
logging_steps=10,
save_steps=50,
fp16=True, # 使用混合精度训练
)
# 创建训练器
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=tokenized_dataset, # 预处理后的数据集
data_collator=data_collator, # 数据整理器
)
# 开始微调
trainer.train()
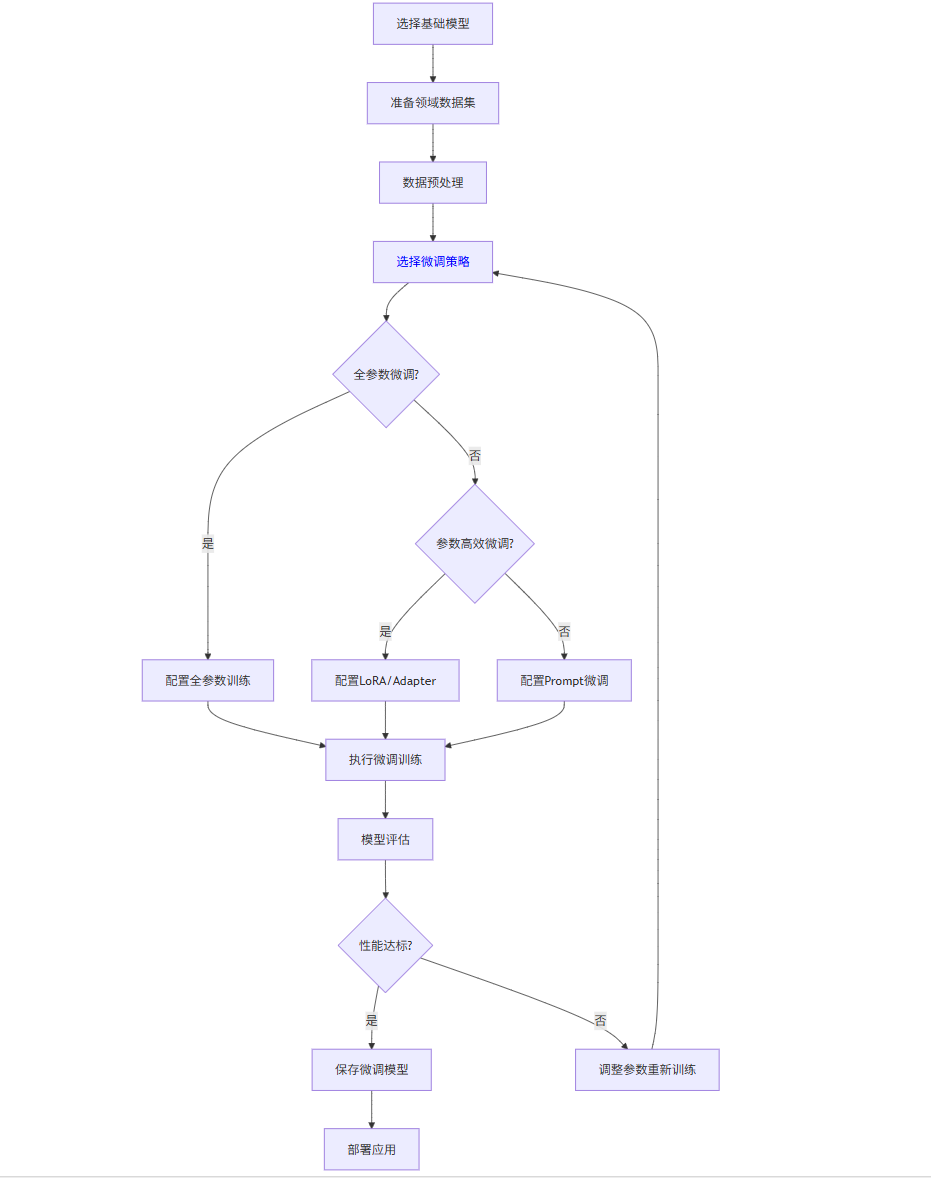
1.4 微调流程图
graph TD
A[选择基础模型] --> B[准备领域数据集]
B --> C[数据预处理]
C --> D[选择微调策略]
D --> E{全参数微调?}
E -->|是| F[配置全参数训练]
E -->|否| G{参数高效微调?}
G -->|是| H[配置LoRA/Adapter]
G -->|否| I[配置Prompt微调]
F --> J[执行微调训练]
H --> J
I --> J
J --> K[模型评估]
K --> L{性能达标?}
L -->|是| M[保存微调模型]
L -->|否| N[调整参数重新训练]
N --> D
M --> O[部署应用]
二、提示词工程:释放大模型潜能的艺术
2.1 提示词工程概述
提示词工程(Prompt Engineering)是通过精心设计输入提示,引导大模型生成更准确、更符合预期的输出结果的技术。良好的提示词设计可以显著提升模型性能,甚至替代部分微调工作。
2.2 高效提示词设计原则
- 明确性原则:清晰表达任务要求和期望输出格式
- 具体性原则:提供足够的上下文和背景信息
- 示例原则:通过少量示例(I few-shot)引导模型理解任务
- 角色设定:为模型分配特定角色,引导其专业视角
- 步骤分解:将复杂任务分解为简单步骤
2.3 Prompt示例集锦
2.3.1 零样本提示(Zero-shot)
请将以下文本分类为"积极"、"消极"或"中性":
"这家餐厅的服务态度非常好,食物也很美味。"
分类结果:
2.3.2 少样本提示(Few-shot)
任务:判断文本的情感倾向
示例1:
文本:"这部电影太精彩了,我看了三遍!"
情感:积极
示例2:
文本:"产品质量太差,用了两天就坏了。"
情感:消极
示例3:
文本:"今天的天气还不错。"
情感:中性
待分类文本:
"这次旅行体验一般,有好有坏。"
情感:
2.3.3 角色设定提示
你是一位有10年经验的金融分析师,请根据以下财务数据,分析该公司的财务状况并提出投资建议:
[财务数据表格]
2.3.4 链式思考提示(Chain-of-Thought)
问题:一个农场有鸡和兔共35只,它们共有94只脚。问鸡和兔各有多少只?
让我们一步步思考:
1. 设鸡的数量为x,兔的数量为y
2. 根据题意可列出两个方程:
x + y = 35 (总数量)
2x + 4y = 94 (总脚数)
3. 解方程组:
从第一个方程得:x = 35 - y
代入第二个方程:2(35 - y) + 4y = 94
展开:70 - 2y + 4y = 94
合并:70 + 2y = 94
移项:2y = 24
解得:y = 12
代入x = 35 - y = 23
4. 答案:鸡有23只,兔有12只
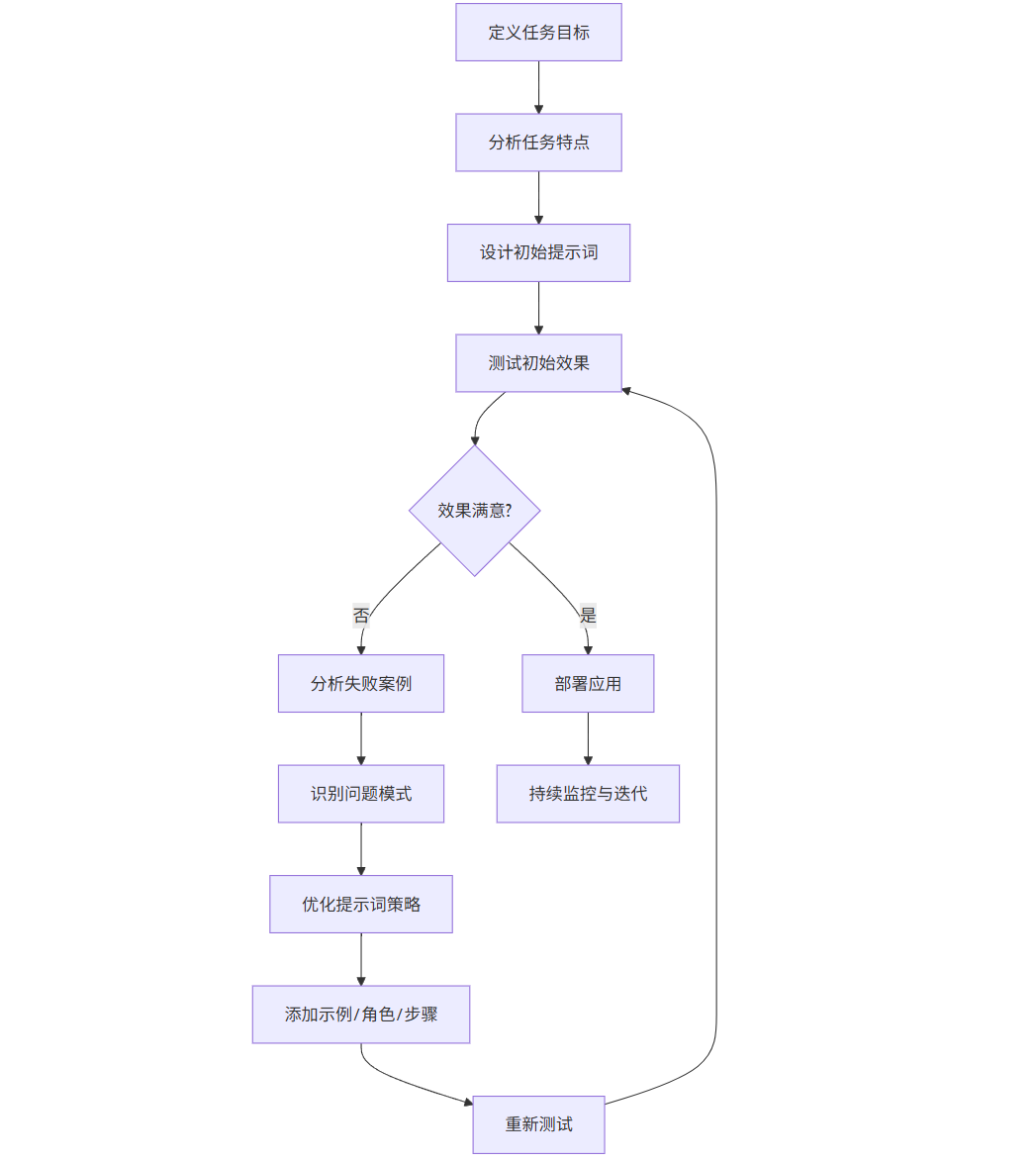
2.4 提示词优化流程图
graph TD
A[定义任务目标] --> B[分析任务特点]
B --> C[设计初始提示词]
C --> D[测试初始效果]
D --> E{效果满意?}
E -->|是| F[部署应用]
E -->|否| G[分析失败案例]
G --> H[识别问题模式]
H --> I[优化提示词策略]
I --> J[添加示例/角色/步骤]
J --> K[重新测试]
K --> D
F --> L[持续监控与迭代]
2.5 提示词效果对比表
| 提示策略 | 准确率 | 响应时间 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 基础提示 | 65% | 快 | 简单任务 | 实现简单 | 准确率低 |
| Few-shot | 82% | 中等 | 有标注数据 | 显著提升准确率 | 需要示例数据 |
| 角色设定 | 78% | 快 | 专业领域 | 增强专业性 | 可能过度限制 |
| 链式思考 | 89% | 慢 | 复杂推理 | 提升推理能力 | 响应延迟增加 |
| 混合策略 | 91% | 中等 | 复杂任务 | 综合优势 | 设计复杂 |
三、多模态应用:融合视觉与语言的新范式
3.1 多模态大模型概述
多模态大模型能够同时处理和理解文本、图像、音频等多种类型的数据,实现跨模态的信息融合与生成。这类模型在视觉问答、图像描述生成、文生图等任务中展现出强大能力。
3.2 多模态应用场景
- 视觉问答(VQA):根据图像内容回答相关问题
- 图像描述生成:为图片生成自然语言描述
- 文生图:根据文本描述生成对应图像
- 跨模态检索:以文本搜索图像或以图像搜索文本
- 多模态对话:结合图像和文本进行对话交互
3.3 CLIP模型应用代码示例
import torch
from PIL import Image
from transformers import AutoProcessor, CLIPModel
# 加载CLIP模型和处理器
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 加载图像
image = Image.open("example.jpg")
# 准备文本候选
texts = ["一只狗在草地上奔跑", "两只猫在沙发上睡觉", "一匹马在田野上吃草"]
# 处理输入
inputs = processor(
text=texts,
images=image,
return_tensors="pt",
padding=True
)
# 计算相似度
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 图像与文本的相似度分数
probs = logits_per_image.softmax(dim=1) # 转换为概率
# 输出结果
for i, text in enumerate(texts):
print(f"文本: '{text}' - 匹配概率: {probs[0][i].item():.4f}")
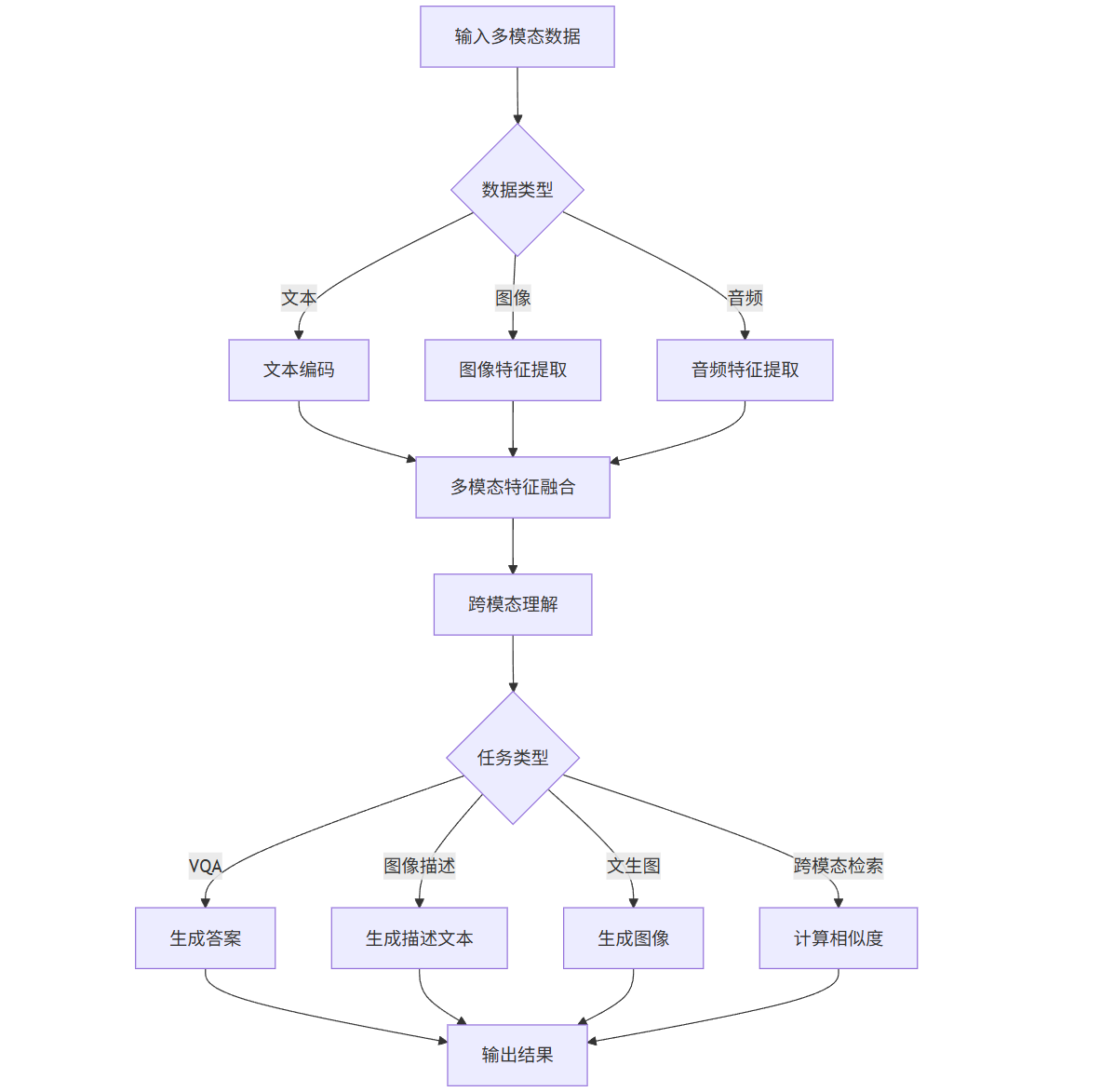
3.4 多模态应用处理流程图
graph TD
A[输入多模态数据] --> B{数据类型}
B -->|文本| C[文本编码]
B -->|图像| D[图像特征提取]
B -->|音频| E[音频特征提取]
C --> F[多模态特征融合]
D --> F
E --> F
F --> G[跨模态理解]
G --> H{任务类型}
H -->|VQA| I[生成答案]
H -->|图像描述| J[生成描述文本]
H -->|文生图| K[生成图像]
H -->|跨模态检索| L[计算相似度]
I --> M[输出结果]
J --> M
K --> M
L --> M
四、企业级解决方案:构建稳定可靠的大模型系统
4.1 企业级解决方案架构
企业级大模型解决方案需要综合考虑模型管理、服务部署、监控运维、安全合规等多个方面,构建一个完整的技术栈。
4.2 核心组件分析
- 模型管理平台:版本控制、性能评估、A/B测试
- 推理服务引擎:高性能推理、动态批处理、模型压缩
- 监控告警系统:性能指标监控、异常检测、自动扩缩容
- 安全合规框架:数据脱敏、内容审核、访问控制
- 持续集成/持续部署(CI/CD):自动化测试、灰度发布
4.3 FastAPI模型服务部署示例
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import pipeline
import torch
from typing import List, Optional
app = FastAPI(title="企业级大模型服务")
# 加载模型
model_name = "meta-llama/Llama-2-7b-chat-hf"
generator = pipeline(
"text-generation",
model=model_name,
device=0 if torch.cuda.is_available() else -1,
torch_dtype=torch.float16
)
class GenerationRequest(BaseModel):
prompt: str
max_length: int = 200
temperature: float = 0.7
top_p: float = 0.9
num_return_sequences: int = 1
class GenerationResponse(BaseModel):
generated_text: List[str]
processing_time: float
@app.post("/generate", response_model=GenerationResponse)
async def generate_text(request: GenerationRequest):
try:
# 生成文本
outputs = generator(
request.prompt,
max_length=request.max_length,
temperature=request.temperature,
top_p=request.top_p,
num_return_sequences=request.num_return_sequences,
pad_token_id=generator.tokenizer.eos_token_id
)
# 提取生成文本
generated_texts = [
output["generated_text"][len(request.prompt):].strip()
for output in outputs
]
return GenerationResponse(
generated_text=generated_texts,
processing_time=0.5 # 实际应用中应计算真实处理时间
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health_check():
return {"status": "healthy"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
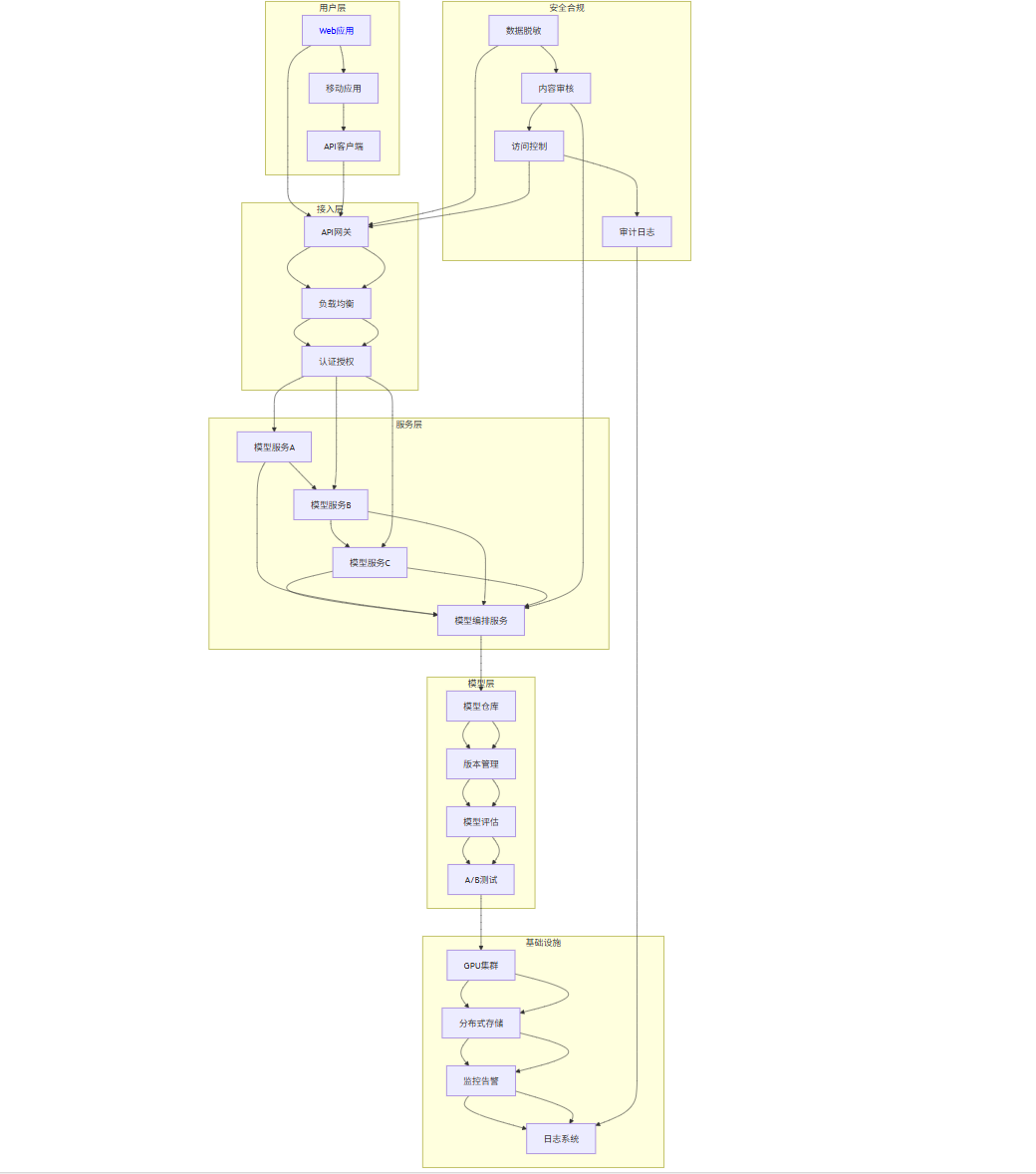
4.4 企业级解决方案架构图
graph TB
subgraph "用户层"
A[Web应用] --> B[移动应用]
B --> C[API客户端]
end
subgraph "接入层"
D[API网关] --> E[负载均衡]
E --> F[认证授权]
end
subgraph "服务层"
G[模型服务A] --> H[模型服务B]
H --> I[模型服务C]
I --> J[模型编排服务]
end
subgraph "模型层"
K[模型仓库] --> L[版本管理]
L --> M[模型评估]
M --> N[A/B测试]
end
subgraph "基础设施"
O[GPU集群] --> P[分布式存储]
P --> Q[监控告警]
Q --> R[日志系统]
end
subgraph "安全合规"
S[数据脱敏] --> T[内容审核]
T --> U[访问控制]
U --> V[审计日志]
end
A --> D
C --> D
D --> E
E --> F
F --> G
F --> H
F --> I
G --> J
H --> J
I --> J
J --> K
K --> L
L --> M
M --> N
N --> O
O --> P
P --> Q
Q --> R
S --> D
T --> J
U --> D
V --> R
五、综合实践案例:智能客服系统构建
5.1 系统需求分析
构建一个基于大模型的智能客服系统,需要处理文本查询、知识库检索、多轮对话等功能,并保证高可用性和安全性。
5.2 技术方案设计
- 模型选择:Llama-2-7B-Chat作为基础模型
- 微调策略:使用LoRA进行领域适配
- 提示词设计:角色设定+知识库检索+多轮对话管理
- 多模态扩展:支持图像查询和视频分析
- 部署架构:Kubernetes集群+自动扩缩容
5.3 核心代码实现
class IntelligentCustomerService:
def __init__(self, model_path, knowledge_base):
# 加载微调后的模型
self.model = self._load_model(model_path)
self.knowledge_base = knowledge_base
self.conversation_history = {}
def _load_model(self, model_path):
"""加载微调后的模型"""
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
return model, tokenizer
def _retrieve_knowledge(self, query):
"""从知识库检索相关信息"""
# 实现知识库检索逻辑
return "相关知识点:..."
def _generate_prompt(self, user_id, query):
"""生成完整提示词"""
# 获取历史对话
history = self.conversation_history.get(user_id, [])
# 检索知识库
knowledge = self._retrieve_knowledge(query)
# 构建提示词
prompt = f"""你是一位专业的客服代表,请根据以下信息回答用户问题:
知识库信息:
{knowledge}
历史对话:
{chr(10).join(history)}
用户当前问题:
{query}
请提供专业、准确的回答:"""
return prompt
def process_query(self, user_id, query, image=None):
"""处理用户查询"""
# 生成提示词
prompt = self._generate_prompt(user_id, query)
# 多模态处理
if image:
# 图像分析逻辑
image_analysis = self._analyze_image(image)
prompt += f"\n\n用户上传的图像分析:{image_analysis}"
# 生成回答
response = self._generate_response(prompt)
# 更新对话历史
self._update_history(user_id, query, response)
return response
def _generate_response(self, prompt):
"""生成模型回答"""
inputs = self.tokenizer(prompt, return_tensors="pt")
outputs = self.model.generate(**inputs, max_new_tokens=500)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return response.split("请提供专业、准确的回答:")[-1].strip()
def _update_history(self, user_id, query, response):
"""更新对话历史"""
if user_id not in self.conversation_history:
self.conversation_history[user_id] = []
self.conversation_history[user_id].append(f"用户: {query}")
self.conversation_history[user_id].append(f"客服: {response}")
# 保持历史记录在合理长度
if len(self.conversation_history[user_id]) > 10:
self.conversation_history[user_id] = self.conversation_history[user_id][-10:]
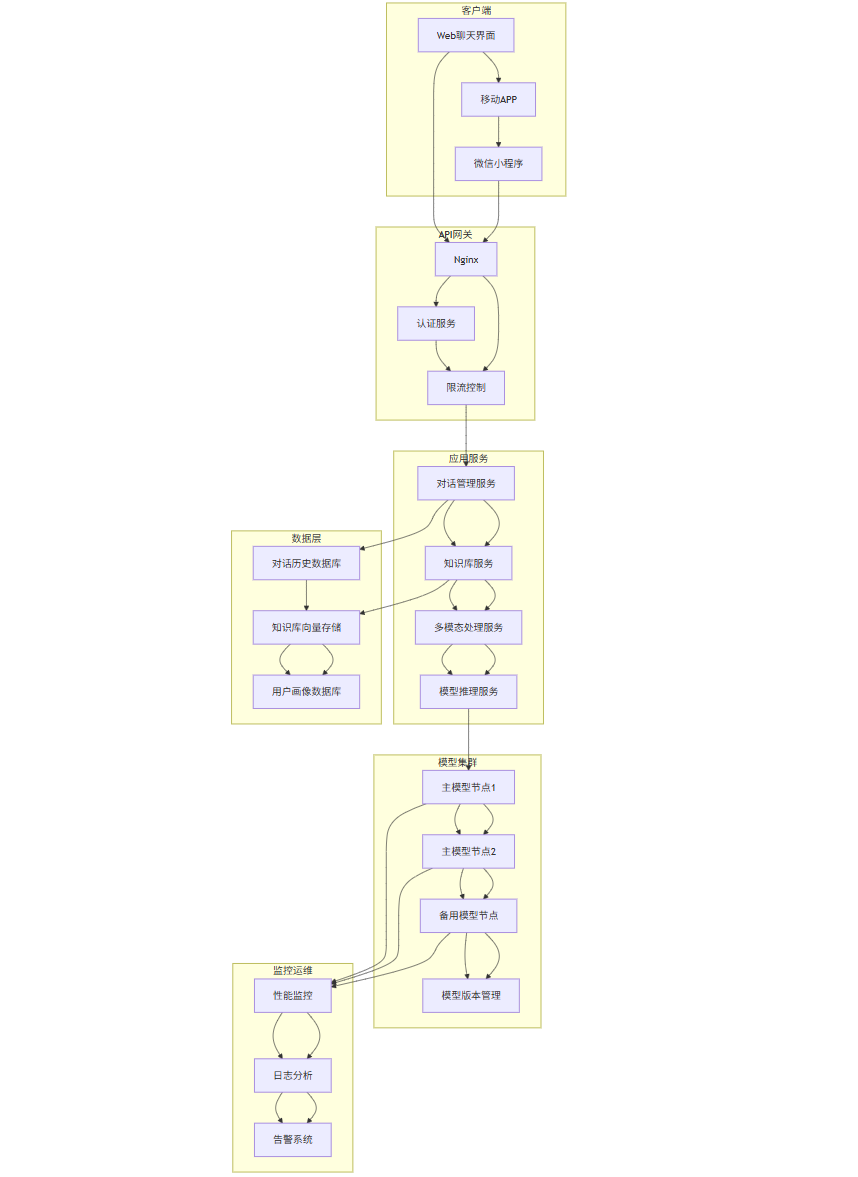
5.4 系统部署架构图
graph TB
subgraph "客户端"
A[Web聊天界面] --> B[移动APP]
B --> C[微信小程序]
end
subgraph "API网关"
D[Nginx] --> E[认证服务]
E --> F[限流控制]
end
subgraph "应用服务"
G[对话管理服务] --> H[知识库服务]
H --> I[多模态处理服务]
I --> J[模型推理服务]
end
subgraph "模型集群"
K[主模型节点1] --> L[主模型节点2]
L --> M[备用模型节点]
M --> N[模型版本管理]
end
subgraph "数据层"
O[对话历史数据库] --> P[知识库向量存储]
P --> Q[用户画像数据库]
end
subgraph "监控运维"
R[性能监控] --> S[日志分析]
S --> T[告警系统]
end
A --> D
C --> D
D --> F
F --> G
G --> H
H --> I
I --> J
J --> K
K --> L
L --> M
M --> N
G --> O
H --> P
P --> Q
K --> R
L --> R
M --> R
R --> S
S --> T
5.5 系统效果评估
| 评估指标 | 传统规则系统 | 微调后大模型 | 多模态增强版 |
|---|---|---|---|
| 问题解决率 | 65% | 82% | 89% |
| 平均响应时间 | 1.2s | 2.5s | 3.1s |
| 用户满意度 | 3.2/5 | 4.1/5 | 4.5/5 |
| 知识库覆盖率 | 70% | 85% | 92% |
| 多轮对话能力 | 弱 | 中等 | 强 |
六、未来展望与挑战
6.1 技术发展趋势
- 模型小型化:通过蒸馏、量化等技术实现模型轻量化
- 多模态融合深化:更自然的多模态交互体验
- 自主智能体:具备规划、执行能力的AI系统
- 边缘计算部署:模型在边缘设备的高效运行
6.2 面临的挑战
- 算力成本:大模型训练和推理的高昂成本
- 数据隐私:用户数据保护与模型训练的平衡
- 幻觉问题:模型生成虚假信息的风险控制
- 伦理合规:AI系统的公平性、透明性和可解释性
6.3 发展建议
- 构建混合架构:结合大模型和小模型的优势
- 持续评估优化:建立完善的模型评估体系
- 加强人机协作:设计有效的人机协同机制
- 重视安全治理:建立全生命周期的安全治理框架
结语
大模型的落地应用是一个系统工程,需要从微调技术、提示词工程、多模态应用到企业级解决方案进行全方位考虑。通过本文提供的实践指南和技术方案,企业可以更有效地将大模型能力转化为实际业务价值。随着技术的不断演进,大模型将在更多领域展现其变革潜力,推动人工智能进入新的发展阶段。
在实施过程中,建议企业根据自身业务需求和资源条件,选择合适的技术路径,循序渐进地推进大模型落地应用,同时密切关注技术发展趋势,持续优化和升级解决方案,以保持竞争优势。
更多推荐
 38
38 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)