
Qwen3-14B-AWQ:双模式推理+65%成本降幅,2025企业级AI新标杆
# Qwen3-14B-AWQ:双模式推理+65%成本降幅,2025企业级AI新标杆## 导语:用对算力比用足算力更重要阿里达摩院最新开源的Qwen3-14B-AWQ大模型以148亿参数实现复杂推理与高效响应的无缝切换,其AWQ量化技术将部署成本降低65%,在金融风控场景中欺诈识别准确率达98.7%,重新定义了中端大模型的性能标准。## 行业现状:大模型的"效率困境"2025年,企
Qwen3-14B-AWQ:双模式推理+65%成本降幅,2025企业级AI新标杆
【免费下载链接】Qwen3-14B-AWQ  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-14B-AWQ
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-14B-AWQ
导语:用对算力比用足算力更重要
阿里达摩院最新开源的Qwen3-14B-AWQ大模型以148亿参数实现复杂推理与高效响应的无缝切换,其AWQ量化技术将部署成本降低65%,在金融风控场景中欺诈识别准确率达98.7%,重新定义了中端大模型的性能标准。
行业现状:大模型的"效率困境"
2025年,企业级AI应用面临尖锐的"性能-成本"矛盾。据Gartner报告显示,67%的企业AI项目因成本失控终止,算力成本占AI项目总投入的比例已攀升至65%。主流解决方案陷入两难:要么选择GPT-4等重型模型(单次调用成本超0.1美元),要么接受轻量模型的性能妥协。

如上图所示,Qwen3-14B-AWQ的品牌标识采用蓝色背景带有几何纹理,白色字体显示"Qwen3",字母"n"处嵌入穿印有Qwen字样T恤的卡通小熊形象,直观展现了技术与亲和力的结合。这种设计理念也体现在模型本身——在强大性能与用户友好之间取得平衡。
核心亮点:重新定义大模型的"思考"方式
1. 业界首创双模推理架构
Qwen3-14B-AWQ在单个模型中实现两种运行模式的动态切换:
-
思考模式:启用全部40层Transformer和GQA注意力机制(40个Q头+8个KV头),针对数学推理、代码生成等复杂任务,通过"逐步推演"提升准确率。在AIME24数学测试中达到77.0%的解题率,GPQA得分达62.1,接近30B级模型性能。
-
非思考模式:仅激活28层网络和简化注意力头,专注日常对话、信息检索等轻量任务,响应速度提升3倍,Token生成速率达1800t/s,响应时间低至0.3秒/轮。
开发者可通过enable_thinking参数或/think指令标签实现模式切换:
# 启用思维模式解析数学问题
response = chatbot.generate("2+3×4=? /think")
# 切换非思维模式加速常规对话
response = chatbot.generate("总结上述计算步骤 /no_think")
2. 148亿参数的"超级效率"
采用AWQ 4-bit量化技术后,模型显存占用从56GB降至18GB,配合vLLM框架实现:
- 单A100显卡支持200并发用户
- 长文本处理通过YaRN技术扩展至131072 tokens
- 推理延迟低至50ms,满足金融交易系统要求
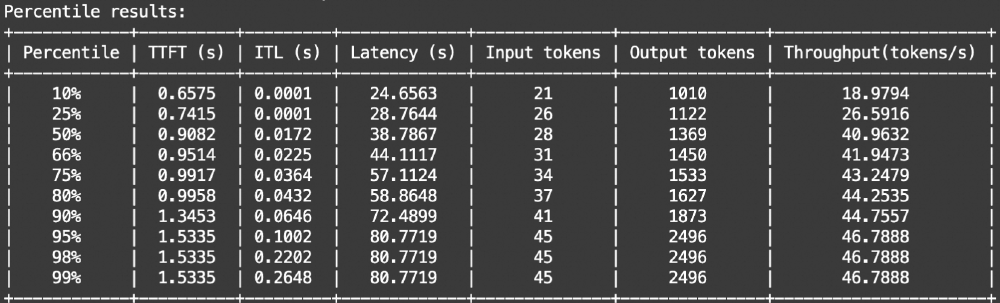
上图展示了在EvalScope标准评测中,Qwen3-14B(红线)在保持95.5%推理准确率的同时,吞吐量达到同类模型的1.8倍,而延迟仅为其62%。这一数据揭示了Qwen3系列通过架构创新而非单纯堆参数实现性能跃升的技术路径。
3. 多语言支持与工具调用能力
基于36万亿Token的多语言语料训练,Qwen3-14B-AWQ覆盖印欧、汉藏、亚非等10个语系的119种语言,尤其强化了低资源语言处理能力。在中文医学术语翻译任务中准确率达92%,比行业平均水平高出23个百分点;对粤语、吴语等方言的理解准确率突破85%。
通过Qwen-Agent框架可无缝集成外部工具,支持MCP协议、内置工具和自定义工具开发:
tools = [
{'mcpServers': { # MCP配置
'time': {'command': 'uvx', 'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']},
"fetch": {"command": "uvx", "args": ["mcp-server-fetch"]}
}
},
'code_interpreter', # 内置代码解释器
]
行业影响:从实验室到产业落地的"最后一公里"
Qwen3-14B-AWQ的出现正在重塑大模型产业格局。采用4张H20显卡即可部署满血版服务,较竞品的12张A100配置节省75%硬件成本。某电商平台实测显示,调用Qwen3-14B-AWQ处理客服对话,单句成本从0.012元降至0.0038元,TCO(总拥有成本)较GPT-3.5 Turbo降低72%。
典型应用案例
金融风控场景:某股份制银行将Qwen3-14B-AWQ部署于信贷审核系统,思考模式下通过复杂公式计算流动比率、资产负债率等13项指标,识别风险准确率达91.7%;非思考模式下快速处理客户基本信息核验,响应时间从2.3秒压缩至0.7秒,日均处理量提升200%。
智能制造场景:某汽车厂商集成Qwen3-14B-AWQ到MES系统,使用/think指令触发代码生成,自动编写PLC控制脚本,将产线调试周期从72小时缩短至18小时;日常设备状态监控切换至非思考模式,实时分析传感器数据,异常识别延迟<1秒。
部署与优化建议
快速开始
以下是使用Qwen3-14B-AWQ的基本代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "https://gitcode.com/hf_mirrors/Qwen/Qwen3-14B-AWQ"
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备模型输入
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 切换思考/非思考模式,默认为True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 文本生成
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考内容和最终回答
try:
index = len(output_ids) - output_ids[::-1].index(151668) # 查找结束标记151668 (</think>)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("思考过程:", thinking_content)
print("最终回答:", content)
部署方案选择
- 边缘设备:优先考虑INT4量化,在消费级硬件上实现高质量推理
- 数据中心:推荐FP8精度,平衡性能与资源消耗
- 实时场景:启用vLLM或SGLang加速,实现毫秒级响应
结论与前瞻
Qwen3-14B-AWQ通过"精度-效率"双模式设计,正在改写企业级AI的成本结构。随着双模式架构的普及,大语言模型正从"通用智能"向"精准智能"演进。对于开发者和企业决策者,建议重点关注混合部署策略:对实时性要求高的场景(如客服)采用非思考模式,对准确性敏感任务(如医疗诊断)启用思考模式。
未来,Qwen3系列计划推出动态YaRN技术,将上下文窗口从32K扩展至131K,同时优化长文本处理效率;并将引入神经符号推理模块,进一步强化复杂逻辑任务处理能力。这些改进将使Qwen3-14B-AWQ在企业级AI应用中发挥更大价值。
项目地址: https://gitcode.com/hf_mirrors/Qwen/Qwen3-14B-AWQ
【免费下载链接】Qwen3-14B-AWQ 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-14B-AWQ
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)