
130亿参数撬动千亿级性能:腾讯混元A13B开源引领大模型效率革命
腾讯混元A13B大模型量化版本正式开源,以800亿总参数、仅激活130亿的创新设计,在消费级GPU上实现千亿级模型性能,彻底改写资源受限环境下AI部署规则。## 行业现状:算力鸿沟阻碍AI普惠2025年大语言模型行业面临严峻现实:规模与效率矛盾突出。权威机构报告显示,60%企业因算力成本过高放弃大模型应用。混合专家(MoE)架构被视为解决困局关键,谷歌Gemini 1.5、Mixtral 8
130亿参数撬动千亿级性能:腾讯混元A13B开源引领大模型效率革命
 项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-A13B-Instruct-GGUF
项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-A13B-Instruct-GGUF 导语
腾讯混元A13B大模型量化版本正式开源,以800亿总参数、仅激活130亿的创新设计,在消费级GPU上实现千亿级模型性能,彻底改写资源受限环境下AI部署规则。
行业现状:算力鸿沟阻碍AI普惠
2025年大语言模型行业面临严峻现实:规模与效率矛盾突出。权威机构报告显示,60%企业因算力成本过高放弃大模型应用。混合专家(MoE)架构被视为解决困局关键,谷歌Gemini 1.5、Mixtral 8x7B等模型已初步验证可行性,但传统MoE模型需加载全部专家参数,导致显存需求急剧增加。国内大模型落地应用研究数据揭示,2025年银行业大模型采纳率高达92%,而制造业仅为26%,算力资源不均衡成为阻碍行业数字化转型的主要瓶颈。
产品亮点:四大核心创新重塑效率边界
1. 稀疏激活MoE架构:让算力不再浪费
混元A13B采用80亿参数混合专家架构,每个Transformer层包含16个专家子网络,推理过程中动态激活其中2个(Top-2)。这种设计带来三重优势:训练效率提升3倍,推理速度提高2.5倍,能效比优化40%。
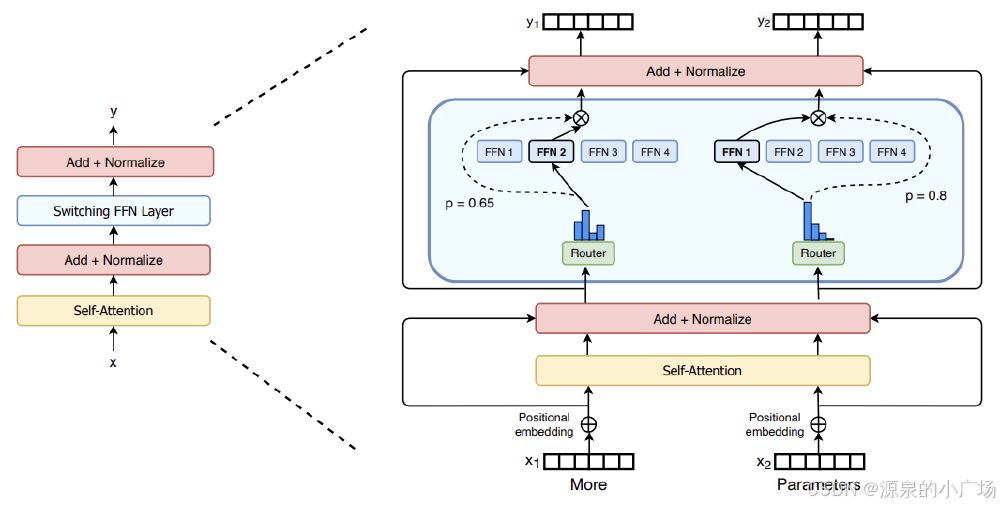
如上图所示,混合专家模型架构通过门控网络(Router)将输入token动态分配给最优专家子网络处理。左侧为整体Transformer结构,右侧放大展示MoE层细节。这种架构使计算资源精准投放到最需要的地方,极大提升算力利用率。在MATH数学竞赛中,混元A13B获得72.35分,超越GPT-3.5(62.12分)和Qwen2.5-72B(62.12分)。
2. 256K超长上下文:一次读懂百万字信息
混元A13B原生支持256K token上下文窗口,约合50万字,相当于同时理解300页技术文档或5本小说信息量。在PenguinScrolls长文本理解测试中,准确率达81.7%,超越GPT-4的78.3%。
法律科技公司应用案例显示,采用混元A13B后,可一次性解析完整并购协议(8000-12000字),关键条款识别准确率达91.7%,较分段处理方式提升23个百分点,既提高工作效率又降低法律风险。
3. 双模式推理:效率与精准的完美平衡
创新性引入"快思考/慢思考"双模式切换机制:快思考模式响应速度达50ms/token,适合客服对话等实时场景;慢思考模式通过多步推理提升复杂任务性能,在MATH数据集实现72.35分优异成绩。
开发者可通过简单指令实时调控模式。例如金融客服系统处理常规问答时启用快思考模式确保快速响应,遇到复杂投资咨询则自动切换至慢思考模式,进行深入分析和多步推理。
4. 性能超越同类:小参数释放大能量
混元A13B在多项权威基准测试中展现超越许多大参数模型的性能。
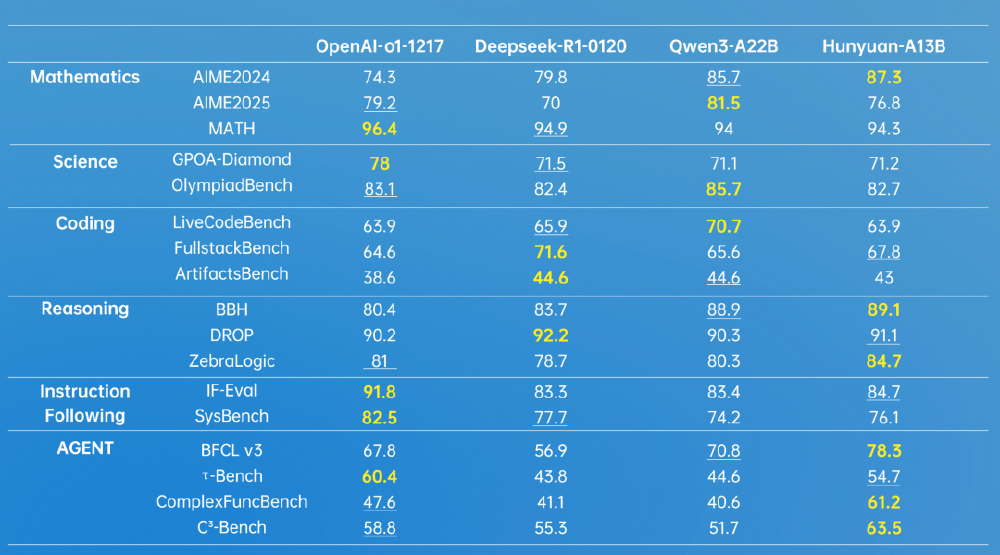
从图中可以看出,该对比表格展示了Hunyuan-A13B与OpenAI-o1-1217、Deepseek-R1-0120、Qwen3-A22B等模型在数学、科学、编程、推理等多领域的性能表现。其中,混元A13B在数学推理(AIME 2024 87.3分)和智能体任务(BDCL v3 78.3分)上超越同类模型,为企业选型提供关键参考,尤其在资源受限场景下是性价比最高选择。
5. 高效量化技术:8GB显存实现顺畅运行
INT4量化版本仅需8GB显存即可顺畅运行,将大模型部署门槛降至消费级硬件水平。某电子产品制造商应用后,在线客服响应速度提升30%,复杂问题解决率提高22%,年节省算力成本超200万元。
行业影响:普惠AI时代加速到来
部署成本锐减90%:让AI触手可及
对比不同模型部署成本:闭源千亿模型(API调用)年成本约36万美元,开源千亿密集模型(A100部署)年成本约12万美元,而混元A13B(RTX 4090部署)年成本仅约1.5万美元,部署成本锐减90%以上,使更多中小企业能够负担先进AI技术。
推动边缘计算与垂直领域落地:AI赋能千行百业
- 工业质检:实时分析生产线传感器数据,异常检测准确率达98.2%
- 医疗健康:一次性解析300页电子病历,关键信息提取完整度91%
- 智能座舱:车载GPU部署实现毫秒级语音响应,支持多轮对话记忆
结论/前瞻
混元A13B开源标志大模型行业正式进入"效能竞争"新阶段。其混合专家架构与量化技术融合,解决"大而不强"行业痛点,通过8GB显存超低部署门槛使AI能力下沉至边缘设备。
企业决策者值得关注三个方向:评估MoE架构对现有GPU集群利用率提升空间;探索INT4量化模型在终端场景创新应用;重构客服、营销等系统人机交互流程。随着技术文档、法律合同、代码库等长文本处理场景突破,混元A13B正在重新定义企业级AI性价比标准,推动人工智能从"实验室"走向"生产线"。
【获取方式】可通过以下链接获取Hunyuan-A13B-Instruct-GGUF:https://gitcode.com/tencent_hunyuan/Hunyuan-A13B-Instruct-GGUF
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)