
【前瞻创想】当平台工程遇上 Kurator:一块“云原生主板”的未来想象!
Kurator:云原生时代的“分布式主板”设计哲学 Kurator被定位为一款开源的分布式云原生平台,其核心设计理念是将自身视为“云原生主板”,而非重建控制平面。它通过三大统一设计——舰队抽象、集中控制入口(Cluster Operator+GitOps+多集群调度)和标准化治理能力(流量/策略/监控),整合Kubernetes、Karmada、KubeEdge等主流组件,形成可扩展的基座。面向未
一、写在前面:如果你现在是 2030 年的平台负责人
先想象一个画面:
2030 年,你作为一家大型互联网 / 产业公司的平台负责人,在月度经营会上被问到三个问题:
- “我们这季度多云成本为什么能降 20% 还没出事?”
- “为什么业务团队几乎感觉不到底层换云、扩 Region 的动作?”
- “AI 与边缘节点这块,怎么做到和主平台一个运维团队就搞定的?”
你摊开后台大盘,屏幕上不是一堆离散的集群列表,而是几个抽象的“舰队”:
fleet-saas-global托管所有线上 SaaS 工作负载;fleet-ai-compute专门跑训练与批任务;fleet-edge-iot管理全国成千上万的边缘节点;
这些舰队下面,挂着分布在多云、多 Region、本地机房的 K8s 集群,部分集群上跑着 Karmada 提供的多集群调度平面,边缘集群通过 KubeEdge 连接, AI 负载由 Volcano 统一调度。
你真正面对的是一块“云原生主板”,而不是散落一地的服务器 —— 这块“主板”,在今天(2025)的名字,就叫 Kurator。
这篇文章想做的,就是站在 平台工程(Platform Engineering)+ 架构演进 的联合视角,不再重复装软件、跑 demo,而是围绕一个核心问题展开:
如果把 Kurator 看成一块“分布式云原生主板”,我们应该如何理解它的插槽布局、总线设计,以及未来几年可以插上哪些“扩展卡”?
而且,Kurator也在热门开源项目之一:
二、Kurator 不是另一个“超级控制平面”,而是一块云原生主板
2.1 官方标签背后:一块以“统一”为设计目标的主板
从 Kurator 的官方描述看,它被定义为:
一个开源的分布式云原生平台,帮助用户构建自己的分布式云原生基础设施,促进企业数字化。
同时,Kurator 明确宣称“站在现有主流云原生技术栈的肩膀上”,包括 Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno 等。
把这些信息拼在一起,其实可以得到一个非常工程化的理解:
-
Kubernetes 是 CPU:负责容器编排与调度;
-
Karmada 是 多 Socket 插槽底座:负责多云、多集群统一编排;
-
KubeEdge 是 边缘扩展插槽:把总线延伸到工厂、门店、基站等边缘现场;
-
Volcano 是 算力加速器:面向 AI / HPC 等批任务,提供高级调度;
-
Istio、Prometheus、Kyverno 等是 网卡、监控卡、安全卡;
-
Kurator 本身,则是这块主板上的:
- 统一总线(统一编排 / 统一 API);
- 插槽布局(舰队、集群抽象);
- BIOS / 管理控制器(生命周期、策略、监控、发布)。
换个说法:
Kurator 并不是要重写一个“比 Kubernetes 更大的超级控制平面”,而是要做好“一块能插各种主流云原生组件的主板”。
这对平台工程团队非常关键——你不必相信某个“all in one 巨石系统”,你只需要相信:
- 这块主板遵守社区 API;
- 插槽足够标准化;
- 总线带宽足够;
- 管理芯片不会“独占一切,不让你换零件”。
2.2 架构上的三个关键设计点
站在“主板”视角看 Kurator,目前能观察到的关键设计点,大致有三类:
-
统一抽象维度:从集群到舰队
-
传统多集群平台喜欢在 UI 上列出一堆集群,让运维同学挨个点;
-
Kurator 引入“Fleet(舰队)”作为逻辑抽象,把一组集群在语义上绑定在一起:
- 可以按业务域(retail / finance / iot);
- 按环境(dev / staging / prod);
- 或者按地域(ap-south / eu-central)来划。
-
对平台工程来说,所有“发布策略、监控视图、策略基线”都可以以舰队为单位讨论。
-
-
统一控制入口:Cluster Operator + GitOps + 多集群调度
- 生命周期控制:通过自有 Cluster Operator 管理本地 / 云上集群生命周期;
- 编排控制:依托 Karmada 对工作负载做多集群调度;
- 配置控制:结合 FluxCD / GitOps,将“你想要的平台状态”写在 Git 仓库里。
- Kurator 把这三类控制端统一“走自己这块总线”,从而形成一个平台工程团队可以掌控的“单一控制面”。
-
统一治理能力:流量 / 策略 / 监控 / 发布的一致化
- 服务网格(Istio)在舰队视角下做多集群流量治理;
- 策略引擎(Kyverno 等)在舰队 / 集群 / 命名空间多层生效;
- Prometheus + Thanos 汇聚多集群指标,统一视图与告警路由;
- 增强的发布流水线在舰队维度实现金丝雀 / 蓝绿 / A/B。
这些东西如果你分别自己搭,当然也能干,但会演化成一个又一个“子平台”,然后你就需要一个“平台的管理平台” 😅。
Kurator 想做的,就是把这些常见“子平台能力”预埋在主板上,给你一块统一的基板。
如下是该Kurator的开源截图:
三、站在 3~5 年的时间轴上:Kurator 可以长成什么样?
如果我们把“Kurator 作为主板”的设定当真,把时间轴拉长到 3~5 年,有几个方向非常值得认真想象一下。
3.1 从“编排统一”升级为“决策统一”
今天的 Kurator 更偏向于“把操作统一起来”:
- 多集群调度交给 Karmada;
- 边缘节点交给 KubeEdge;
- 批任务调度交给 Volcano;
Kurator 负责:
- 把这三类控制平面挂到自己的“主板总线”上;
- 提供统一的抽象、视图和操作入口。
但 3~5 年之后,更迫切的问题不再是“我能不能把它们操作起来”,而是:
“在一堆可用的云、集群、GPU、边缘节点中,我该如何选择?”
也就是说,Kurator 需要从 “统一编排层” 升级为 “统一决策层”。
可预见的几个子方向:
-
SLO + 成本 + 风险 三维度综合调度
-
当多云、多 Region 成为常态,同一份业务可能有多种“投放点”可选:
- 便宜但延迟稍高的 Region;
- 贵但离用户非常近的 Edge;
- 资源紧张但已经有数据本地缓存的集群;
-
Kurator 完全可以在自己的 CRD 中定义一种“调度意图”:
max-latency=100mscost-priority=highgeo-compliance=EU-only
-
然后把这种“调度意图”翻译成对 Karmada / Volcano / KubeEdge 的具体配置。
-
-
多云 FinOps(成本运营)内建化
-
平台工程团队每天都在被问:“这月成本为什么又超了?”
-
如果 Kurator 能把多云账单、节点利用率、工作负载类型等拉在一起,形成成本视角的舰队大盘,并能“反推”出几点优化建议,比如:
- 哪些 cluster 适合迁到 Spot;
- 哪些 Job 可以挪到夜间低价时段;
-
那它就从“运维工具”变成了“经营工具”。
-
-
业务拓扑驱动的调度决策
- 今天的调度多基于资源和 Region;
- 五年后,更多公司会用“业务拓扑(业务域 / 租户 / 数据域)”做平台组织单位;
- Kurator 有舰队抽象,天生适合在这个方向上继续推,把“你的业务地图”映射到“集群 / 云 / 节点地图”上。
3.2 云边闭环与“模型流”的一体化
KubeEdge 的毕业,意味着“云原生边缘计算”从试水期进入“工业化使用期”:
- 制造业、零售、物流、能源等行业都在边缘跑 AI 推理;
- 边缘节点上有大量实时数据产生;
- 云端负责更重的模型训练与策略推演。
如果我们把“数据”和“模型”也当成一种“流”,那 Kurator 未来有几个非常自然的创想空间:
-
模型版本视角的舰队治理
-
不仅要知道“这个舰队跑了哪些应用”,还要知道:
- 当前在线模型版本是 v1.13 还是 v1.15?
- 哪些工厂/门店仍然没有更新到最新的推理镜像?
-
Kurator 可以在自身抽象层增加“模型版本拓扑图”,并把它和 KubeEdge + CI/CD 流水线连起来。
-
-
云上训练 + 边缘推理 的策略闭环
-
训练集群由 Volcano 调度;推理集群由 KubeEdge 管理;
-
Kurator 在中间可以承担“模型流发动机”的角色:
- 根据边缘回传的效果指标触发再训练;
- 训练完成后自动在少数边缘节点舰队做灰度;
- 灰度效果达标后再放大范围。
-
-
边缘资源的“业务就近”调度
-
很多 IoT / 视频分析场景,边缘节点之间本身也存在拓扑关系(同园区、同机架等);
-
如果 Kurator 能在舰队里表达这些“物理/逻辑拓扑”,再配合 Karmada / KubeEdge 的调度,就能做到类似:
- “优先把任务调度到离摄像头最近的那批节点上”;
- “同一租户的任务尽量落在同一园区边缘资源上”。
-
这意味着 Kurator 不只是“云资源中枢”,而是真正意义上的“云边一体平台中枢”。

3.3 AI 原生调度时代:Kurator + Volcano 的下一层协同
Volcano 之所以被大量 AI 场景采用,是因为它对队列、公平调度、抢占、回填和异构设备支持做了大量增强,是“云原生批处理调度”的事实标准之一。
从 Kurator 的角度看,未来可以在三个层面更大胆一点:
-
算力视角的一等公民
-
现在平台视图常见分层:云 → 集群 → 命名空间 → 服务;
-
对 AI 平台来说,应该有一条并行视图:算力池 → 队列 → 任务 → 模型;
-
Kurator 完全可以在舰队层给出“算力池”抽象:
- 这是 A100 舰队;
- 那是昆鹏 / Ascend 舰队;
- 还有一块是消费级 GPU 混部舰队。
-
-
训练 / 推理的协同策略
-
三五年后大部分公司都会有类似的诉求:
- “白天主打推理,晚上主打训练”;
- “关键节假日,大部分算力优先用于推荐 / 风控策略,不跑大规模训练”;
-
这类策略如果散落在各个调度器身上,非常难以统一管理;
-
如果 Kurator 作为主板,把这些“算力运营策略”写进自己的 CRD,然后分别翻译给 Volcano 和 Karmada,就会变得非常自然。
-
-
FinOps × 算力运营 的可视化闭环
-
GPU 成本跷跷板一压,很多显卡预算都要外溢成“平台工程 KPI”;
-
如果 Kurator 能告诉你:
- “某个模型过去 30 天的算力成本曲线”;
- “哪个团队的平均排队时间 / 利用率指标最不健康”;
-
那你就从“被问责的人”转变成“给别人发问责邮件的人”😂。
-
四、Kurator 带来的一个隐性变化:平台工程的工作重心会整体上移
很多人看 Kurator,第一反应是:
“这不就是帮我们把多集群管理这块做薄一点嘛。”
但从平台工程视角看,更深层的变化在于 —— 工作重心会从“搞集群”整体上移到“搞产品形态”。
4.1 集群生命周期管理:从“脚本工程”变成“产品运营”
有了 Kurator 的 Cluster Operator 之后:
- 新增集群 → 写 CR / MR;
- 扩缩容 → 调整节点池规格 & 数量,交给控制器;
- 升级 → 批量操作策略化;
- 清理 → 幂等删除。
平台工程师从“每天写脚本、对着控制台点来点去”变成:
- 设计集群规格与模板库;
- 设计集群准入规则与成本配额;
- 决定哪些业务可以申请什么等级的集群;
- 跟踪“集群 SKU” 的健康度与利用率。
这本质上是在把 IaaS / K8s 侧的“资源产品化”,Kurator 则是支撑这件事的主板。
4.2 发布与变更管理:从“流水线拼拼凑凑”变成“平滑渐进的体验设计”
Kurator 在统一应用分发与渐进式发布上的努力,实际上是在整理一个“变更产品”:
-
对开发者来说,只需要选择:
- “我这一次是金丝雀,还是蓝绿,还是直接滚动”;
- “多集群灰度是先 CN、再 EU 还是先 Edge 再 Cloud”;
-
对平台工程师来说,需要设计:
- 各类变更策略对不同舰队的默认行为;
- 变更失败后的自动回滚条件与节流规则;
- 伴随变更的监控指标绑定(SLO 守门员)。
这个时候,平台团队的工作已经从“写一个 pipeline yaml”变成“设计一个可理解、可预测的变更体验”。
Kurator 提供的是“变更的执行总线”,你提供的是“变更的产品化抽象”。
4.3 策略与合规:从“写 Admission Webhook”到“经营一套策略即代码体系”
以前你要做安全与合规,大概率三件事:
- 写 Admission Webhook;
- 配一堆 OPA / Kyverno 策略;
- 写文档告诉别人“不要乱搞”。
有了 Kurator 的统一策略管理(结合 Kyverno 之类),你可以站得更高:
- 定义“平台强制策略层”、“舰队策略层”、“应用自定义策略层”;
- 提供策略模板集(比如“金融场景”、“政务场景”);
- 把“策略变更”纳入发布流水线,实现策略的测试与回滚。
从那一刻起,你不再只是“写规则的人”,而是“运营一套安全策略产品的人”。✨
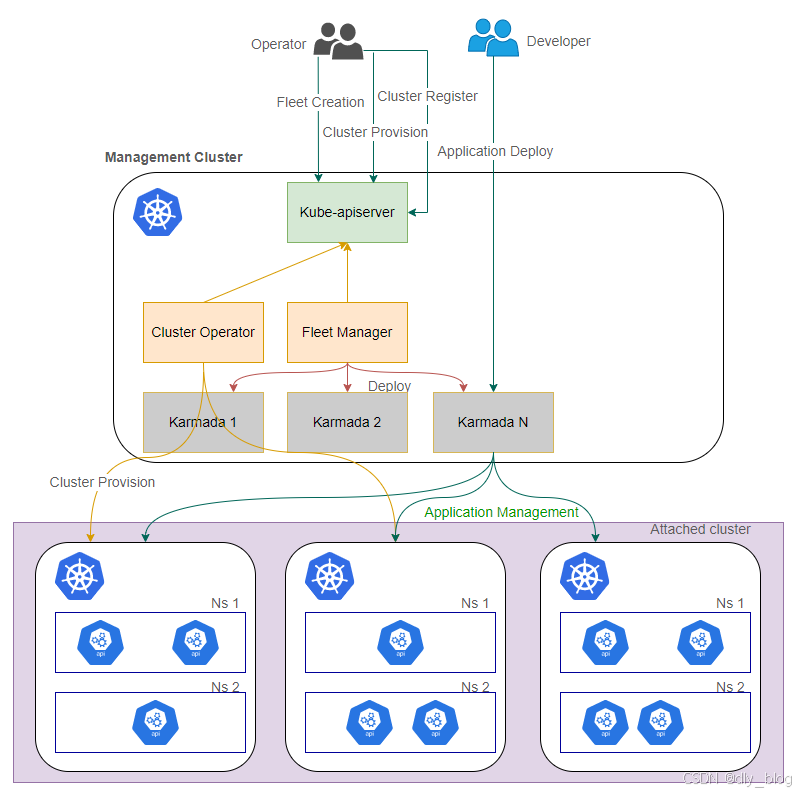
最后,我们纵观下Kurator产品的架构图:
五、从社区视角看 Kurator:为什么它有潜力跑得更远
从开源社区角度,Kurator 的选择其实走了一条相对“成熟但难”的路:
- 没有自己造新的调度器,而是选择 Karmada + Volcano;
- 没有自己做边缘框架,而是选择 KubeEdge(一个已经毕业的 CNCF 项目);
- 没有另讲一套服务网格,而是选了 Istio 等主流方案;
- 明确标注“站在这些项目的肩膀上”。
这意味着什么?
-
技术路线风险更低
- 长期与主流社区共振,比“自创一套生态”更难,但也更安全;
- 你不用担心上游项目被抛弃,只需要盯着它们的 Roadmap。
-
经验沉淀更容易回流上游
- Kurator 作为一栈整合者,会积累大量真实场景(金融、多云 SaaS、边缘 AI 等)的落地经验;
- 这些经验如果通过 Issue / PR / 文档反馈到 Karmada / KubeEdge / Volcano 社区,会形成良性循环。
-
对企业用户更友好
- 企业不用担心“被锁死在某个平台的私有能力里”;
- 即使未来 Kurator 被替换,上游 K8s / Karmada / Volcano / KubeEdge 仍然可以复用。
六、结尾:别把 Kurator 当“又一个平台”,它更像“你未来 5 年的平台主板”
最后,用一句话把全文收回到最开头那个画面:
当你习惯用“舰队”和“主板”而不是“单集群”和“脚本”,去思考平台架构时,Kurator 就从一个“开源项目”真正升级成了你团队的“基础设施产品”。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)