
2025年未来网络发展大会:DeepSeek行业大模型算力网加速应用生态白皮书
当本地算力不足时,动态调度云端高性价比算力,提供 “极简接入、柔性访问、安全流转、可观可感” 的使用体验,支持 Serverless 容器按需启停,相比纯本地算力节省 50% 推理成本,同时盘活国产算力资源,助力供算方拓展分销渠道。2、算力网的解决方案:算力网通过 “算力阀”(类似水龙头,动态调配资源)和 “算力表”(类似水表,精准计量付费),实现 “最优匹配、按需启停”“精准计量、效用付费”,让
一、报告背景与编写主体
本白皮书由第九届未来网络发展大会组委会发布,主要编写单位为紫金山实验室、江苏省未来网络集团,另有苏交科集团、新华三、浪潮信息等多家企业与机构提供支持。报告聚焦行业大模型发展痛点,结合 DeepSeek 开源大模型的普及优势,提出基于算力网加速的边云一体化解决方案,旨在破解数据流通、算力使用难题,为国家 “东数西算” 与全国一体化算力网建设提供实践参考,推动 AI 在千行百业的落地应用。
二、现状与挑战
(一)DeepSeek 大模型发展现状
技术与市场突破:2024-2025 年,我国大模型完成 “技术 - 产品 - 市场” 转型,DeepSeek 以 “充分开源、深度思考、人文关怀” 特性成为现象级产品,将私有化部署成本降至 0,推动 B 端企业级应用普及,当前企业落地以 32B/70B 参数模型为主,智能体逐步融入企业办公与管理流程。
现存短板:DeepSeek-V3/R1 暂不支持多模态能力(“只会听不会看”),难以满足部分生产场景需求,需待 DeepSeek-R2 补全该短板。
(二)行业大模型演进与挑战
演进路径:从 “通用大模型” 到 “行业大模型” 需经历 “企业大模型→行业大模型” 阶段。企业大模型以 “推理(大模型 + 知识库)” 和 “微调(大模型 * 数据集)” 为核心,通过 “推理积累数据→微调更新模型” 循环形成专属大模型;行业大模型尚处研究阶段,潜在路径包括 “跨企业数据训练”“多企业大模型分流整合”“群体协作增智”,当前以企业大模型的 “推理向微调过渡” 为主。
核心挑战:尽管 DeepSeek 解决了模型成本问题,但数据流通不畅(企业敏感数据传输不安全、效率低)、算力使用不便(公共算力未充分利用、企业本地资源有限)仍制约行业大模型规模化应用。
(三)算力网加速的需求背景
1、现有部署模式局限:
云部署:基于互联网提供轻量化服务,但存在 “数据传不出(敏感数据不敢传)、网络运不动(传输慢)、算力信不过(担心数据窃取)” 问题。
一体机部署:本地局域网部署可解决安全问题,但面临 “建设成本高(采购 + 运维开销大)、服务性能僵(规模与性能固定)、模型更新慢(版本迭代困难)” 挑战。
2、算力网的解决方案:算力网通过 “算力阀”(类似水龙头,动态调配资源)和 “算力表”(类似水表,精准计量付费),实现 “最优匹配、按需启停”“精准计量、效用付费”,让企业像用水用电一样用算,弥补云部署与一体机的不足,实现边云协同。
三、算力网加速解决方案
(一)方案定位
基于国家 “东数西算” 安全总线的广域确定性网络,连接用户本地与八大枢纽节点算力资源,解决网络安全、可靠性与速率瓶颈。当本地算力不足时,动态调度云端高性价比算力,提供 “极简接入、柔性访问、安全流转、可观可感” 的使用体验,支持 Serverless 容器按需启停,相比纯本地算力节省 50% 推理成本,同时盘活国产算力资源,助力供算方拓展分销渠道。
(二)总体架构
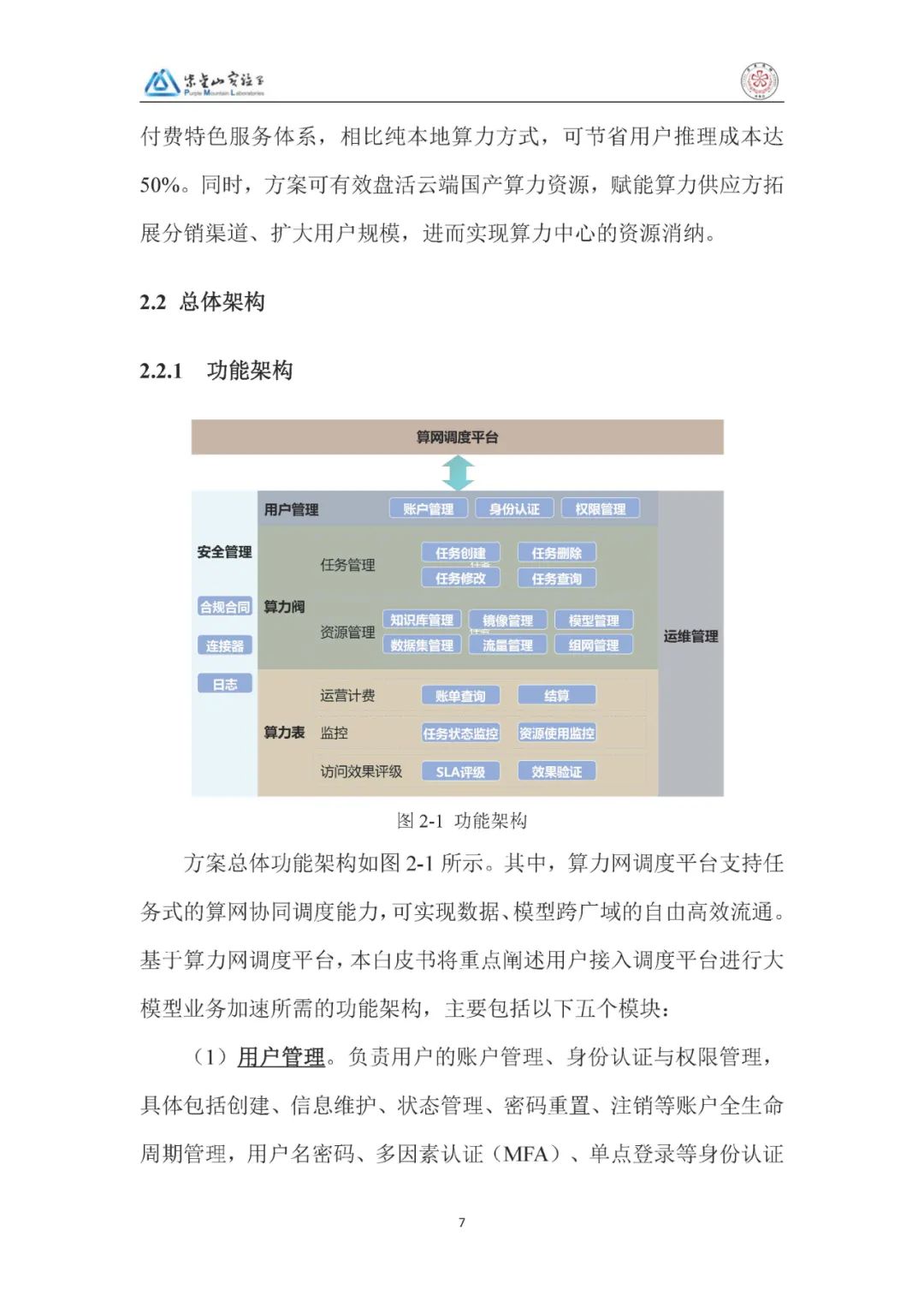
1、功能架构:以算力网调度平台为核心,包含五大模块:
用户管理:负责账户全生命周期管理、多因素认证(MFA)、RBAC 细粒度权限控制。
算力阀:管理云端任务(增删改查)、对接知识库、纳管推调镜像、适配算力资源、管理模型与数据集。
算力表:提供账单查询、在线结算、任务监控、访问效果评级(微调效果、推理时延等)。
运维管理:涵盖基础设施采控、平台版本配置、智能监控告警、全栈自动化运维与可视化大屏。
安全管理:基于可信数据空间,通过分布式架构、区块链智能合约、隐私增强技术,实现数据分级分类与可信流通。
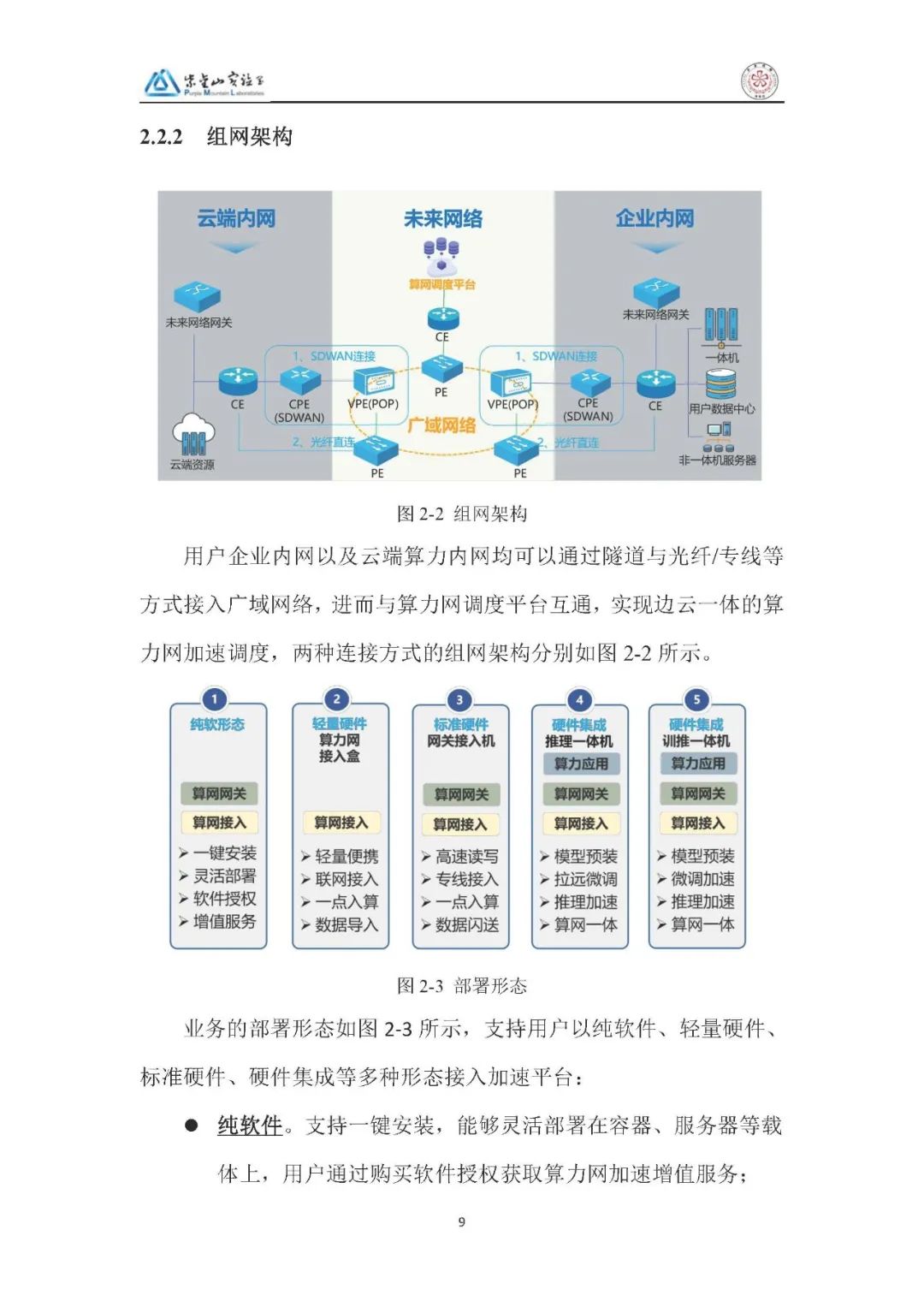
组网架构:用户企业内网与云端算力内网通过隧道 + 光纤 / 专线接入广域网络,与算力网调度平台互通,支持纯软件(容器部署)、轻量硬件(算力接入盒)、标准硬件(网关接入机)、硬件集成(推理 / 训推一体机)四种接入形态。
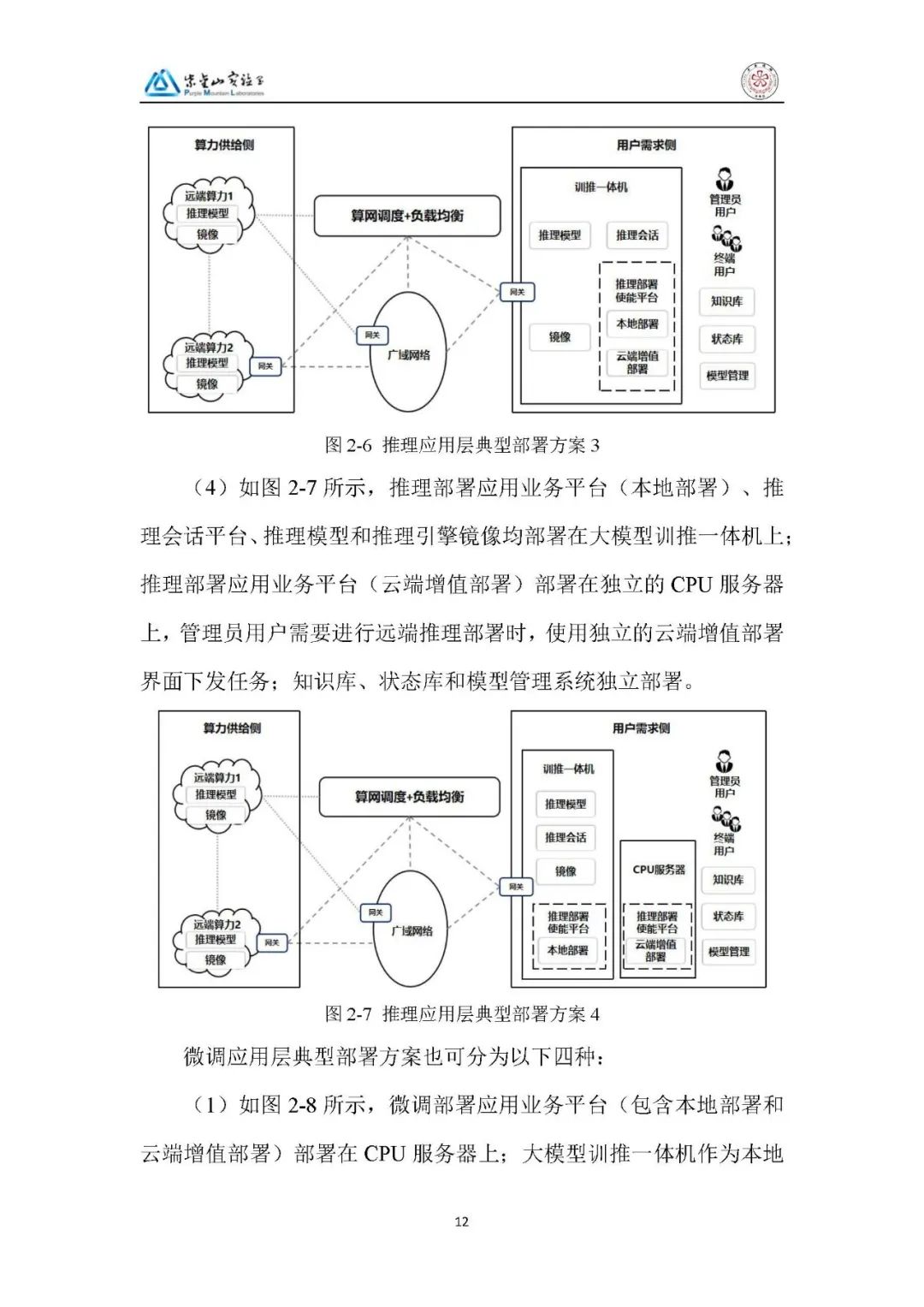
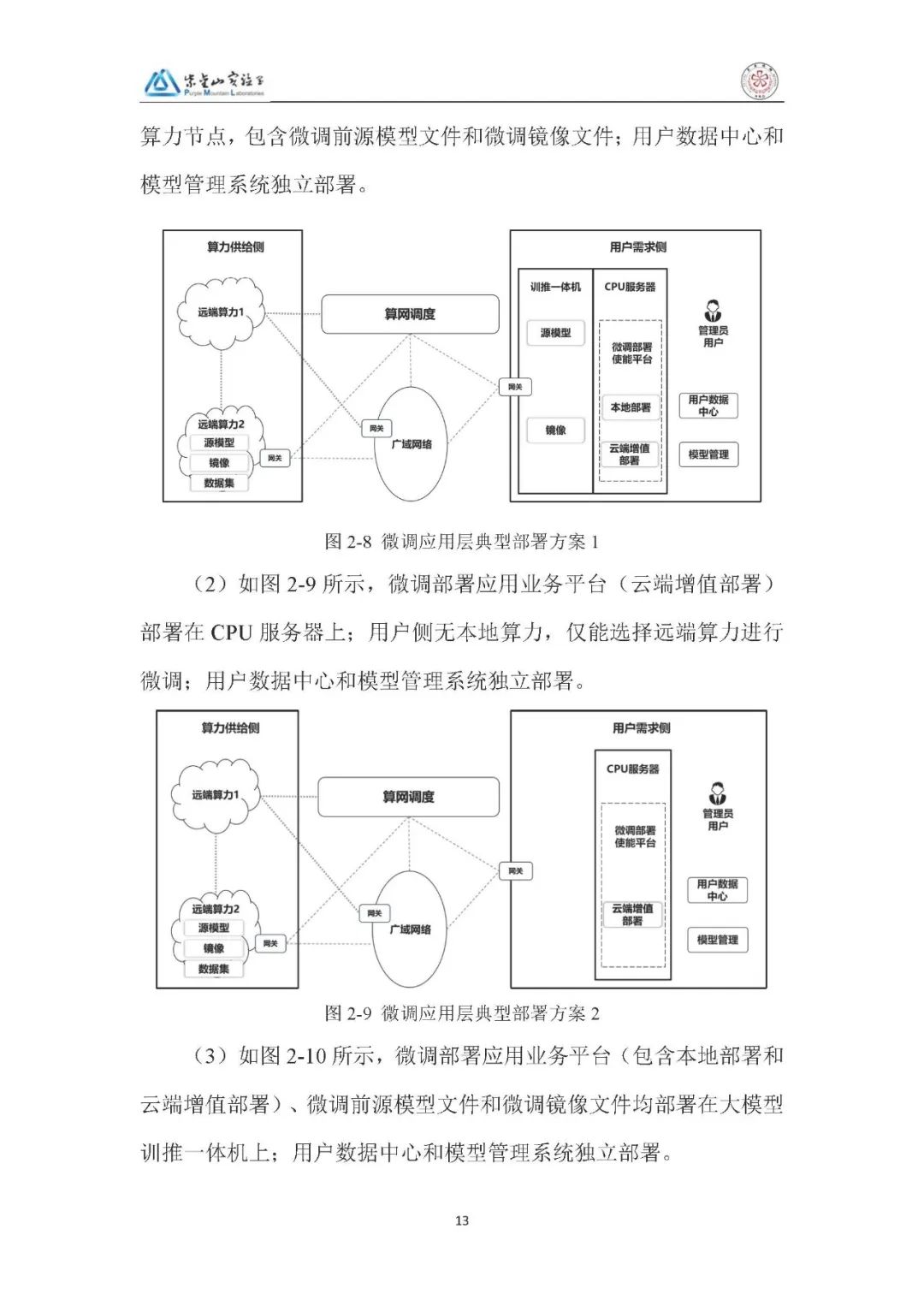
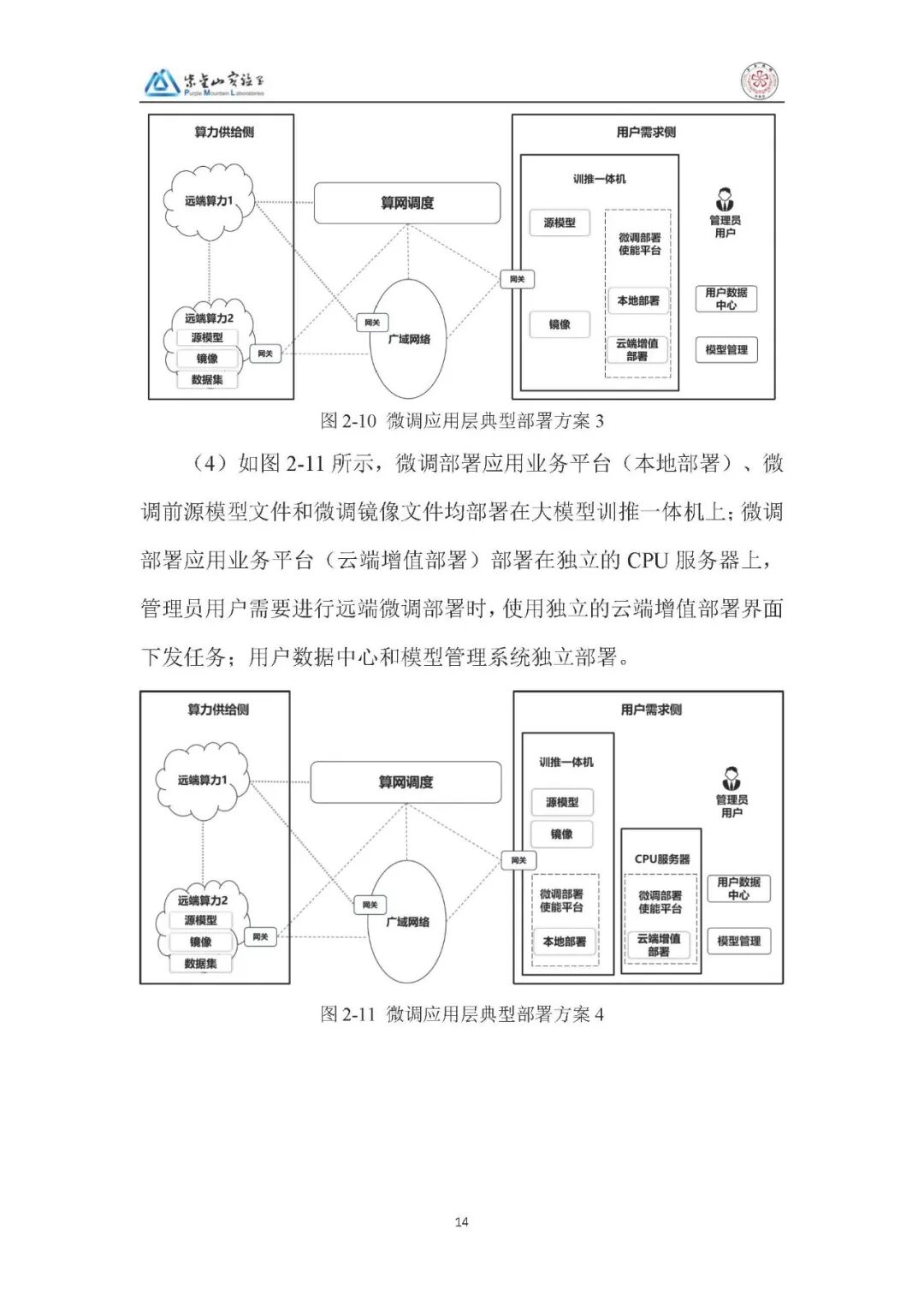
2、部署方案:
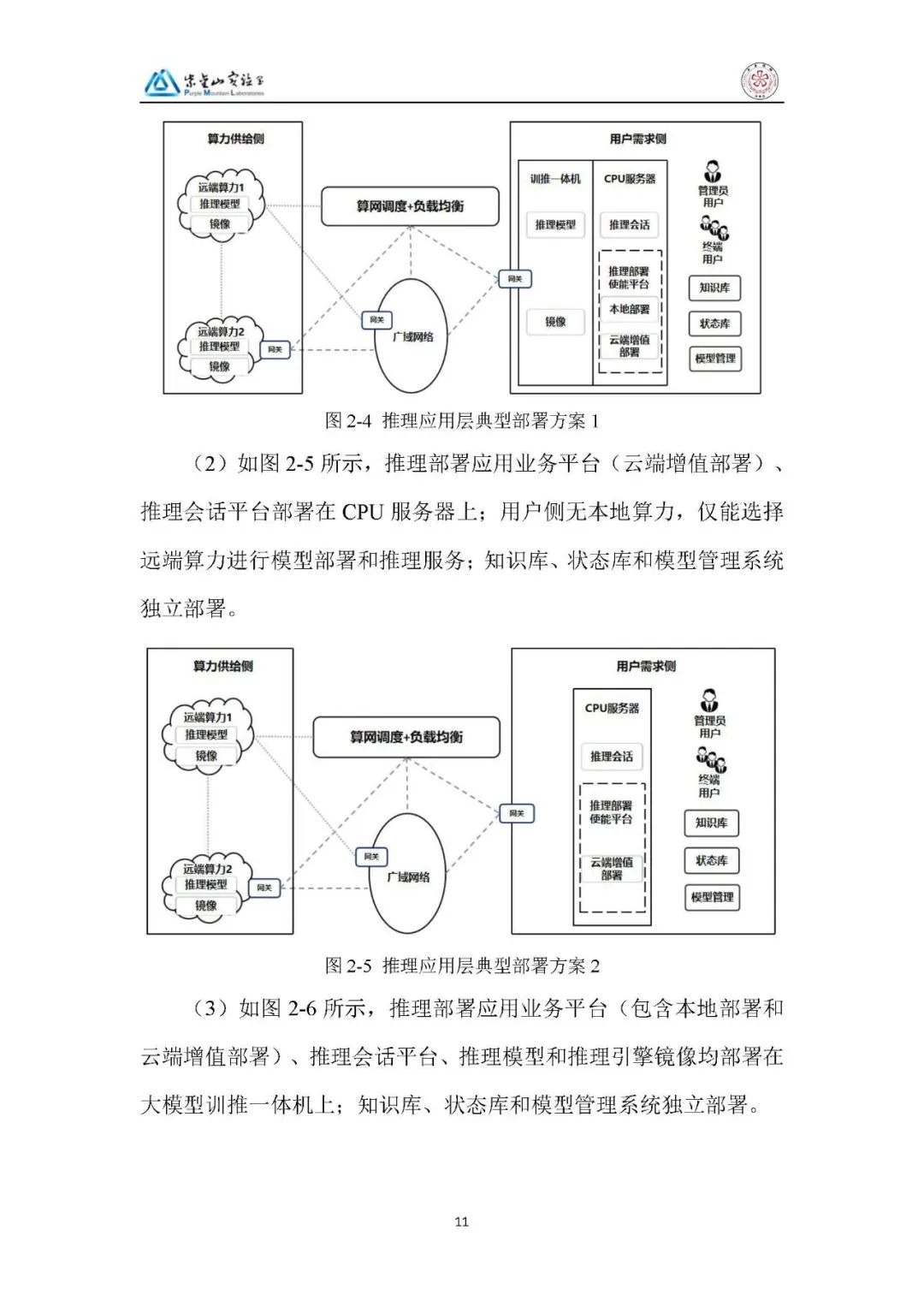
推理应用层:分四种方案,核心差异在于本地算力有无及业务部署载体(CPU 服务器 / 训推一体机),支持本地与云端增值部署结合,知识库、模型管理系统独立部署。
微调应用层:同样分四种方案,适配本地算力不足时的远端微调需求,用户数据中心与模型管理系统独立部署,确保数据安全。
(三)业务流程
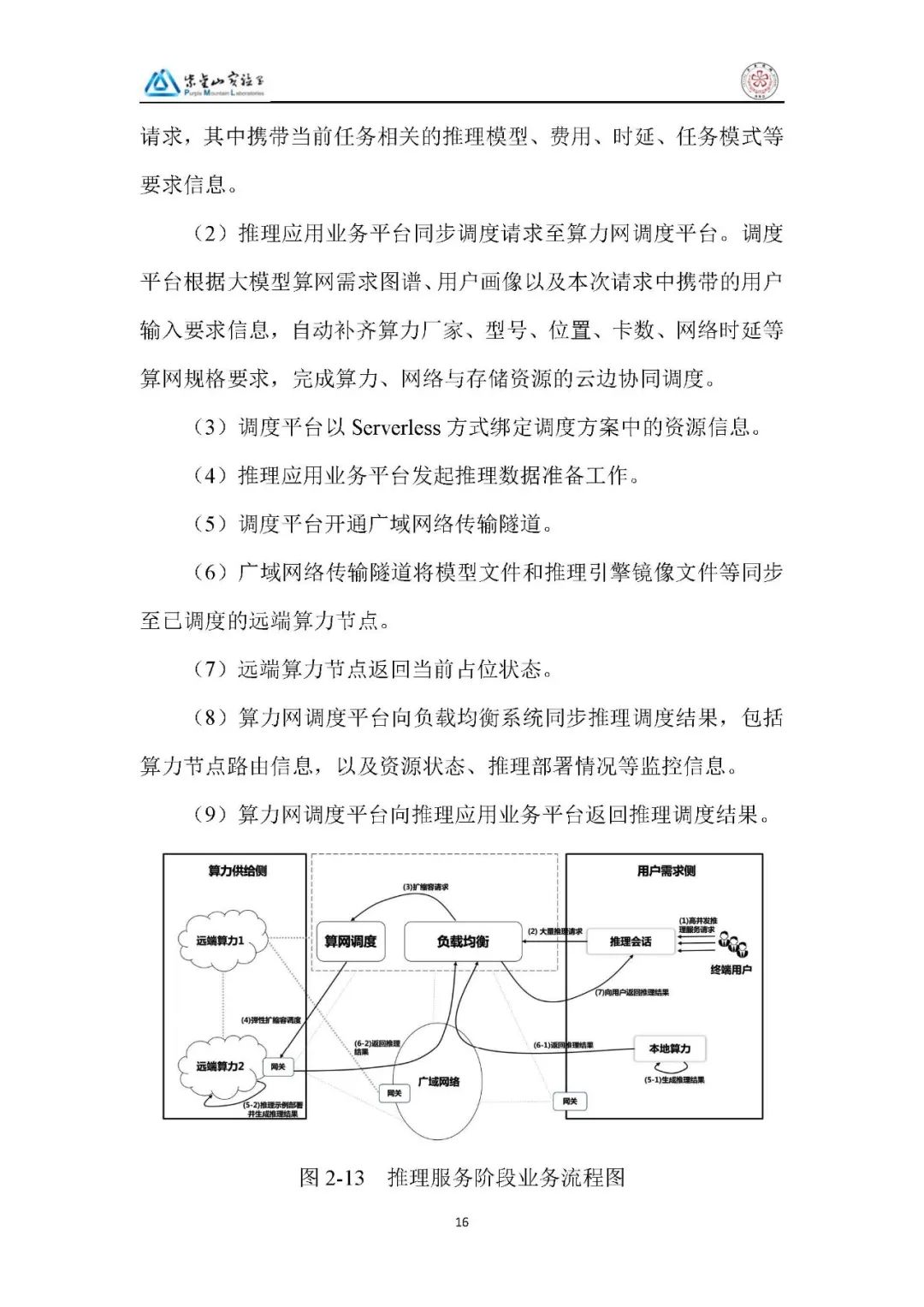
1、推理加速(“算随网动” 模式):
调度阶段:管理员发起请求,调度平台基于 “模型 - 场景 - 算力 - 资源” 图谱匹配边缘 / 远端算力,以 Serverless 占位绑定资源,开通传输隧道同步模型与镜像,同步结果至负载均衡模块。
服务阶段:终端用户发起高并发请求,负载均衡系统根据最小路径等策略分流至本地 / 远端算力,远端算力在流量分发后启动实例完成扩容,保障服务连续性。
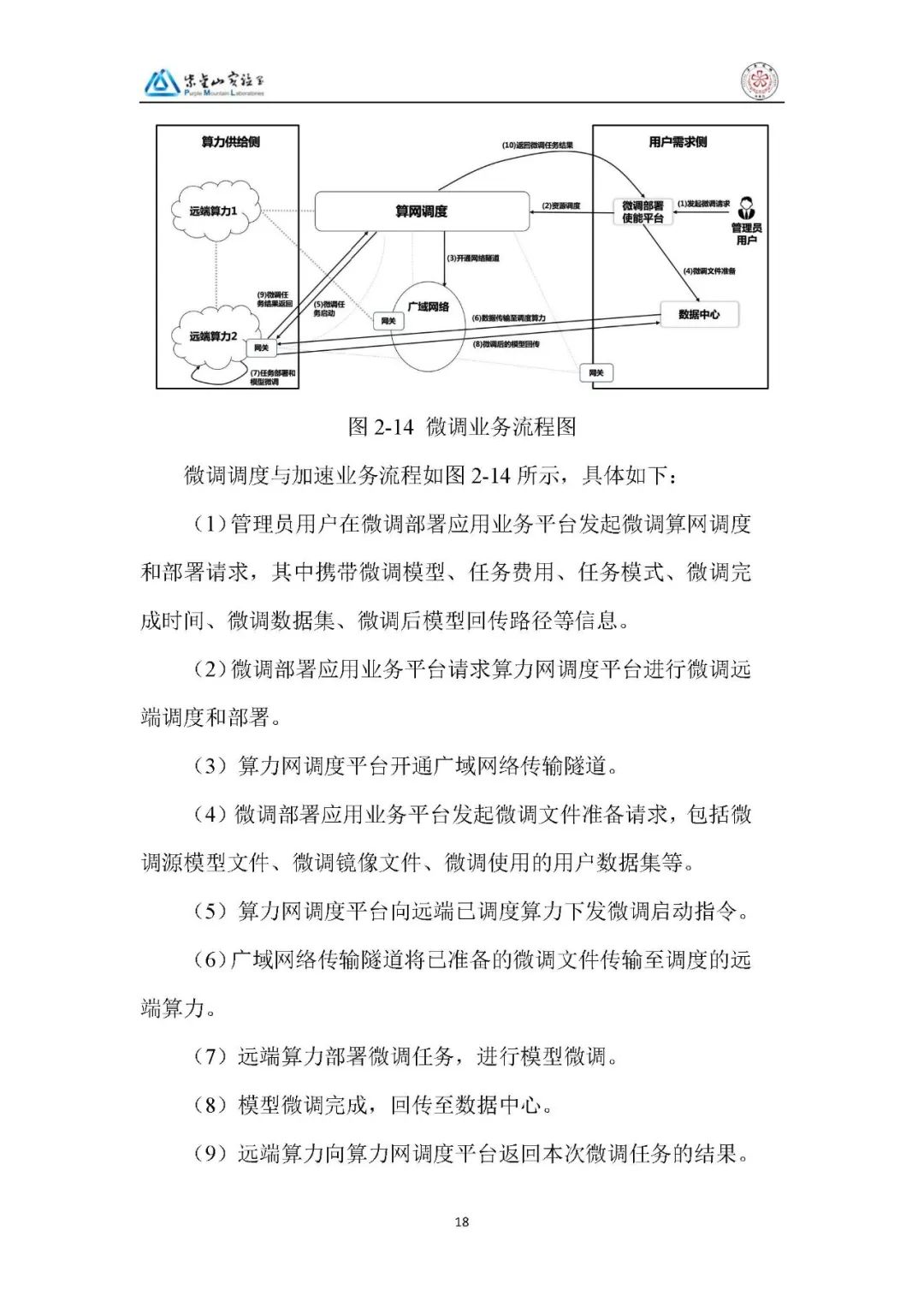
2、微调加速(“网随算动” 模式):管理员发起微调请求,调度平台开通隧道、传输微调文件(源模型、镜像、数据集),远端算力执行微调任务,完成后回传模型,全程无需用户关注算力位置与架构。
(四)关键能力
1、极简接入:
极简资源配置:构建 “模型 - 场景 - 算力 - 资源” 四维图谱,自动映射业务需求(如 70B 推理需≥200 TFLOPS 算力、≥80GB 显存)与算力资源,免除手动配置。
无感交互:支持任务模板保存与自动触发(本地资源不足时自动调度),提供 “省心模式(自动择优)”“放心模式(用户确认)”,兼顾效率与可控性。
2、柔性访问:
全域负载均衡:基于多维度算力标识,结合强化学习模型,优先保障本地业务,不足时按地理位置、QPS 加权等策略分流至云端,辅以故障自愈机制。
弹性伸缩:业务并发超水位时扩容(推理仅占位、流量分发后启动实例;微调直接启动实例),低于水位时释放云端资源,实现无级变速。
模型适配:构建 “模型 - 算力卡 - 业务类型 - 服务协议 - 镜像文件” 五维映射矩阵,统一纳管镜像,解决跨域异构算力适配问题。
安全流转:构建可信数据空间,通过分布式存储、数字智能合约(规范数据使用权限)、数据沙箱 / 隐私计算(管控数据操作)、区块链存证(日志不可篡改),实现数据全流程安全合规流通。
3、可观可感:
状态可观:动态拓扑仪表盘实时展示算力与网络状态,统计任务并发量、资源利用率,跟踪推理时延、微调梯度同步等关键指标。
效果可感:可视化看板展示 TTFT、TPOT、QPS 等指标,通过 A/B 测试对比微调效果,自动生成审计报告,预测性规避 SLA 违约。
四、算力网资源量化测评
(一)测评概述与环境测评
目标:为算力网调度提供依据,让用户无需关注算力归属与架构,测评覆盖英伟达(H20、L40、V100)与 5 款国产智算芯片,针对 DeepSeek-R1 的 32B/70B 模型,测试吞吐量、时延、QPS 等指标。
测评环境:基于 vLLM 框架,输入 / 输出长度均为 1024,最大上下文 5000,精度根据芯片类型适配(如 H20 用 bfloat16,V100 用 float16)。
(二)吞吐测评结果
性能排序:总体性能从高到低为 H20>D 卡(国产)>E 卡(国产)>C 卡(国产)>V100>L40>A 卡(国产)>B 卡(国产),L40 因无 NVLink、缺乏专用 Tensor Core,性能不及 V100。
关键规律:随并发数增加,输出 Token 吞吐从快速增长趋于平稳,每一并发平均吞吐从快速下降趋于平稳,并发拐点随卡数增加而上升、随模型增大而下降(如 E 卡 8 卡 32B 模型拐点>256 并发,8 卡 70B 模型拐点为 128 并发)。
SLA 适配:当要求每一并发吞吐≥15 token/s 时,H20 8 卡支持 32B 模型 250 并发、70B 模型 140 并发,国产 D 卡 8 卡支持 32B 模型 135 并发,为调度扩容提供数据支撑。
(三)时延测评结果
小并发场景:各芯片 TTFT(首 Token 延迟)与 TPOT(每 Token 时间)趋势一致;大并发场景部分芯片性能瓶颈显现,TTFT 与 TPOT 趋势分化。
Prefix 缓存影响:开启缓存后,非首次推理 TTFT 大幅下降(预热效果),但对 TPOT 影响小;高并发下缓存命中率降低,首次与非首次推理性能差异缩小。
SLA 适配示例:32B 模型 32 并发场景下,要求 TTFT<2s、TPOT<100ms 时,H20-8 卡、C 卡(2/4/8 卡)、D 卡 - 8 卡为符合要求的资源。
五、典型场景与应用案例
(一)入企 —— 交通规划报告
苏交科集团基于 DeepSeek-671B 模型本地推理生成公路规划报告,低并发(≤阈值)耗时 42s,并发 60 时耗时 72s,并发 100 时超 300s;接入算力网后,通过云边协同分流,并发 60 耗时缩短至 45s,并发 100 耗时 75s,显著提升推理效率。
(二)入企 —— 医疗问答推理
苏州某医疗研究所基于 DeepSeek-32B 构建医疗推理引擎,本地 L20 算力高并发时时延激增;接入算力网调用云端寒武纪 MLU370 算力,端到端延迟降低 40%,并发吞吐量提升 3 倍,部署成本节省 50% 以上。
(三)入园 —— 医疗诊断微调
南京笑领科技(口腔医疗 SaaS 平台)本地算力不支持微调,接入算力网调度天数智芯天垓 150 算力,用 15GB 训练集微调 DeepSeek-70B 模型 140 次迭代后,推理结果与目标答案相似度从 8% 提升至 75%;15GB 数据传输仅需 10s(确定性网络),算力效能超 99.998%。
(四)入校 —— 基因检测编辑
贵州师范大学研究茶树多酚氧化酶(PPO)基因,本地算力不足难以处理 10Tb 多组学数据;接入算力网后,用 DeepSeek-32B 模型完成基因测序与编辑,精准识别古茶树种质资源,选育优良杂交种,提升茶叶加工品质。
(五)政务 —— 政务推理问答
江宁数据局政务系统高并发时本地算力不足,借助算力网连接远端算力中心,以本地大模型为核心,高并发时动态调用云端资源,保障民生服务响应及时,降低整体算力成本。
六、总结与展望
当前算力网加速解决方案已通过多个场景验证,有效破解行业大模型的数据与算力难题。未来需结合 “东数西算” 与全国一体化算力网建设,进一步完善算力调度算法、优化多模态模型适配,推动更多企业拥有专属大模型、行业形成特色大模型,走出我国特色 AI 发展路径。
点击文后阅读原文,可获得下载资料的方法。






















欢迎加入智能交通技术群!扫码进入。

点击文后阅读原文,可获得下载资料的方法。

联系方式:微信号18515441838
更多推荐
 1
1 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)