
Ascend C算子基础入门:从CPU到NPU的搭建与优化
随着人工智能与高性能计算的深度融合,算力需求呈指数级增长,传统 CPU 架构在并行计算效率上逐渐显现瓶颈。华为 Ascend NPU(神经网络处理器)凭借其专用架构设计,在 AI 推理与训练场景中实现了算力与能效的双重突破。Ascend C 作为面向 Ascend NPU 的算子开发编程语言,为开发者提供了从 CPU 算子迁移、NPU 算子搭建到性能优化的全流程工具链。
前言
随着人工智能与高性能计算的深度融合,算力需求呈指数级增长,传统 CPU 架构在并行计算效率上逐渐显现瓶颈。华为 Ascend NPU(神经网络处理器)凭借其专用架构设计,在 AI 推理与训练场景中实现了算力与能效的双重突破。Ascend C 作为面向 Ascend NPU 的算子开发编程语言,为开发者提供了从 CPU 算子迁移、NPU 算子搭建到性能优化的全流程工具链。本文将以 “基础入门” 为核心,循序渐进讲解 Ascend C 算子的开发逻辑:先回顾 CPU 算子的实现范式,再聚焦 NPU 架构特性与 Ascend C 编程模型,最后通过实操案例与优化技巧,帮助开发者快速掌握从 CPU 到 NPU 的算子迁移与性能调优方法,为后续复杂算子开发与算力高效利用奠定基础。
一、核心概念铺垫
在进入实操前,需先明确三个关键概念,避免认知偏差:
- 算子(Operator):计算任务的最小执行单元,例如矩阵乘法(MatMul)、卷积(Conv2d)等,是 AI 模型与底层硬件交互的核心载体。
- CPU 与 NPU 的架构差异:
-
- CPU:通用计算架构,擅长串行任务、复杂逻辑处理,核心数量少、缓存层级深,并行计算效率低。
-
- NPU:专用 AI 计算架构,采用众核设计(如 Ascend 910B 包含数千个 AI Core),支持指令级、数据级并行,专为张量运算优化。
- Ascend C 的核心定位:介于底层硬件指令与高层框架(TensorFlow/PyTorch)之间的编程接口,支持 C/C++ 语法扩展,提供算子开发、编译、部署的一站式工具链,无需直接操作硬件指令即可充分利用 NPU 算力。
插图 1:CPU 与 NPU 算子执行架构对比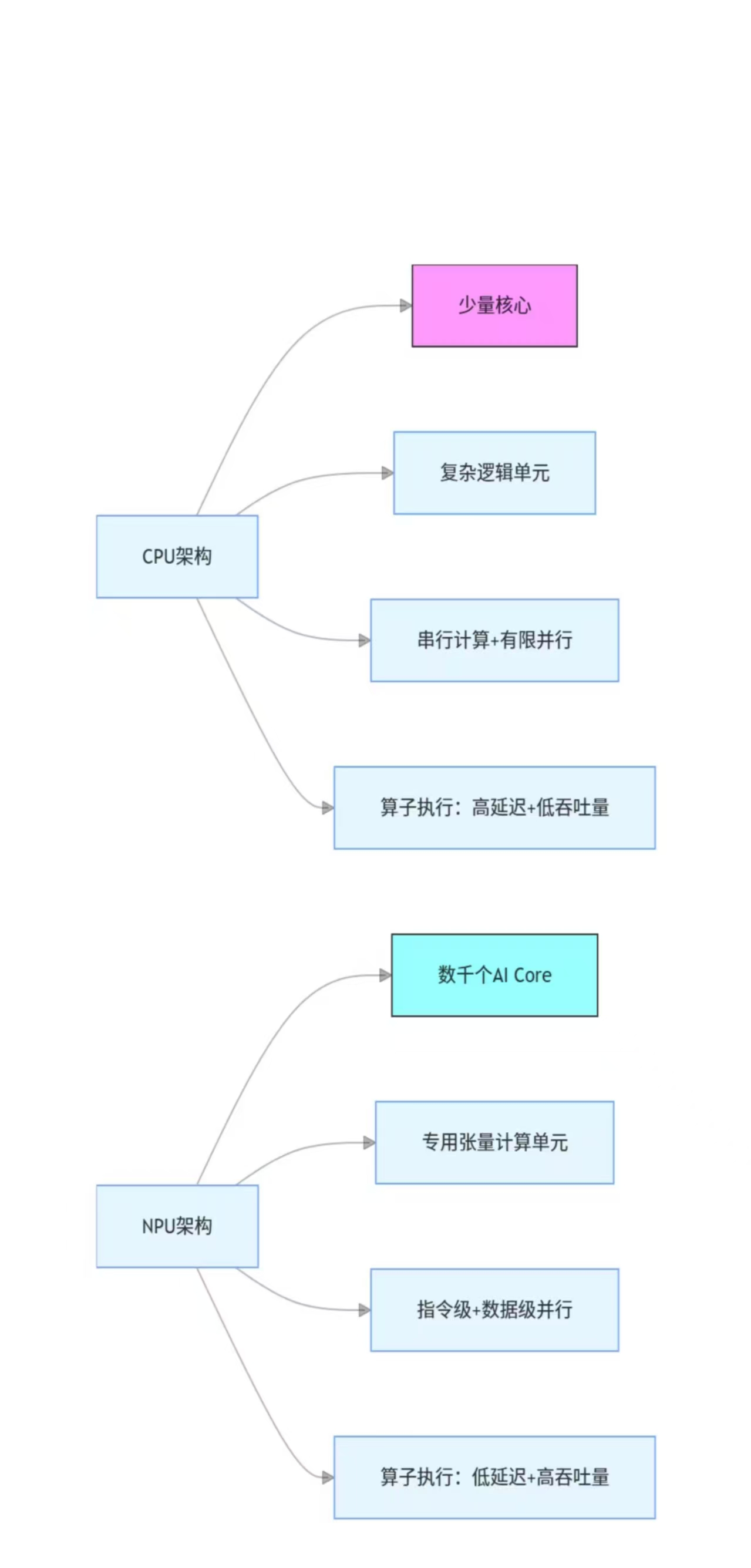
二、CPU 算子的实现范式(以向量加法为例)
CPU 算子开发遵循 “串行优先、逻辑清晰” 的原则,无需关注硬件并行细节,核心是实现计算逻辑的正确性。
1. CPU 算子代码示例(C 语言)
#include <stdint.h>
// CPU向量加法算子:out = a + b(a、b、out为同维度向量)
void cpu_vector_add(const float* a, const float* b, float* out, uint32_t length) {
for (uint32_t i = 0; i < length; i++) {
out[i] = a[i] + b[i]; // 串行执行每个元素加法
}
}
2. CPU 算子的核心特点
- 编程简单:直接通过循环遍历数据,逻辑直观;
- 依赖编译器优化:并行性依赖 CPU 多核与编译器(如 GCC)的自动向量化(-O3 优化);
- 性能瓶颈:当向量长度极大时,串行循环无法充分利用硬件资源,算力浪费严重。
三、Ascend C 算子搭建:从 CPU 到 NPU 的迁移流程
Ascend C 算子开发需适配 NPU 的众核并行架构,核心流程分为 “环境准备→算子逻辑实现→编译构建→部署验证” 四步,以下仍以向量加法为例展开。
1. 第一步:环境准备
- 硬件要求:Ascend 310/910 系列 NPU(或 Ascend RC 仿真环境);
- 软件要求:安装 Ascend CANN 开发套件(包含 Ascend C 编译器、工具链、API 库);
- 开发工具:Visual Studio Code(安装 Ascend C 插件)或 DevEco Studio。
2. 第二步:Ascend C 算子逻辑实现(核心步骤)
Ascend C 算子开发需遵循 “并行拆分→数据搬运→计算执行→结果输出” 的逻辑,需重点关注 NPU 的并行调度与数据布局。
(1)核心编程模型:Kernel 函数 + 并行调度
- Kernel 函数:NPU 算子的核心执行单元,运行在 AI Core 上,需通过 Ascend C 扩展语法声明;
- 并行调度:通过__attribute__((reqd_work_group_size(x, y, z)))指定工作组大小,实现多 AI Core 并行。
(2)Ascend C 向量加法算子代码示例
#include "acl/acl.h"
#include "ascendc/ascendc_kernel.h"
// NPU向量加法算子:采用1维工作组并行,每个工作组处理一个元素
__attribute__((reqd_work_group_size(1, 1, 1)))
__global__ void npu_vector_add(const float* a, const float* b, float* out, uint32_t length) {
// 获取当前工作组的全局ID(对应向量索引)
uint32_t global_id = get_global_id(0);
// 边界检查:避免越界访问
if (global_id < length) {
out[global_id] = a[global_id] + b[global_id]; // 每个AI Core处理一个元素的加法
}
}
(3)关键差异:与 CPU 算子的核心区别
|
对比维度 |
CPU 算子 |
Ascend C 算子 |
|
并行方式 |
依赖编译器自动优化 |
显式指定工作组与全局 ID,多 AI Core 并行 |
|
数据访问 |
直接访问内存 |
通过 NPU 内存模型(全局内存 / 共享内存)访问 |
|
编程关注点 |
逻辑正确性 |
并行拆分、数据布局、边界处理 |
3. 第三步:编译构建(生成 NPU 可执行算子)
Ascend C 算子需通过 CANN 提供的ascendc_compiler编译,生成.o目标文件,再通过aclLink链接为可执行文件。
# 编译命令:指定NPU架构(ascend910)、优化级别(-O2)
ascendc_compiler -target=ascend910 -O2 -c npu_vector_add.c -o npu_vector_add.o
# 链接命令:生成可执行文件
aclLink npu_vector_add.o -o npu_vector_add
4. 第四步:部署验证(在 NPU 上运行并对比结果)
通过 Ascend CL(Ascend Computing Language)调用算子,在 NPU 上执行,并与 CPU 算子结果对比,验证正确性。
#include "acl/acl.h"
#include <stdio.h>
int main() {
// 1. 初始化Ascend CL环境
aclInit(nullptr);
aclrtSetDevice(0); // 指定NPU设备ID
// 2. 准备数据(主机内存→设备内存)
uint32_t length = 1024;
float* host_a = (float*)malloc(length * sizeof(float));
float* host_b = (float*)malloc(length * sizeof(float));
float* host_out_cpu = (float*)malloc(length * sizeof(float));
float* host_out_npu = (float*)malloc(length * sizeof(float));
// 初始化数据
for (uint32_t i = 0; i < length; i++) {
host_a[i] = i * 1.0f;
host_b[i] = (length - i) * 1.0f;
}
// 3. CPU算子执行(作为基准)
cpu_vector_add(host_a, host_b, host_out_cpu, length);
// 4. NPU算子执行
float *dev_a, *dev_b, *dev_out;
aclrtMalloc((void**)&dev_a, length * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&dev_b, length * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&dev_out, length * sizeof(float), ACL_MEM_MALLOC_HUGE_FIRST);
// 数据从主机内存拷贝到设备内存
aclrtMemcpy(dev_a, length * sizeof(float), host_a, length * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE);
aclrtMemcpy(dev_b, length * sizeof(float), host_b, length * sizeof(float), ACL_MEMCPY_HOST_TO_DEVICE);
// 启动NPU算子(配置工作组数量:length个工作组,每个处理1个元素)
dim3 grid_dim(length, 1, 1); // 网格维度(工作组数量)
dim3 block_dim(1, 1, 1); // 块维度(每个工作组的线程数)
npu_vector_add<<<grid_dim, block_dim>>>(dev_a, dev_b, dev_out, length);
aclrtSynchronizeStream(nullptr); // 等待算子执行完成
// 结果从设备内存拷贝到主机内存
aclrtMemcpy(host_out_npu, length * sizeof(float), dev_out, length * sizeof(float), ACL_MEMCPY_DEVICE_TO_HOST);
// 5. 结果对比(验证正确性)
bool is_correct = true;
for (uint32_t i = 0; i < length; i++) {
if (fabs(host_out_npu[i] - host_out_cpu[i]) > 1e-6) {
is_correct = false;
printf("Error: index %d, NPU result: %.6f, CPU result: %.6f\n", i, host_out_npu[i], host_out_cpu[i]);
break;
}
}
printf(is_correct ? "NPU operator execution is correct!\n" : "NPU operator execution failed!\n");
// 6. 资源释放
free(host_a); free(host_b); free(host_out_cpu); free(host_out_npu);
aclrtFree(dev_a); aclrtFree(dev_b); aclrtFree(dev_out);
aclrtResetDevice(0);
aclFinalize();
return 0;
}
插图 2:Ascend C 算子从开发到验证的全流程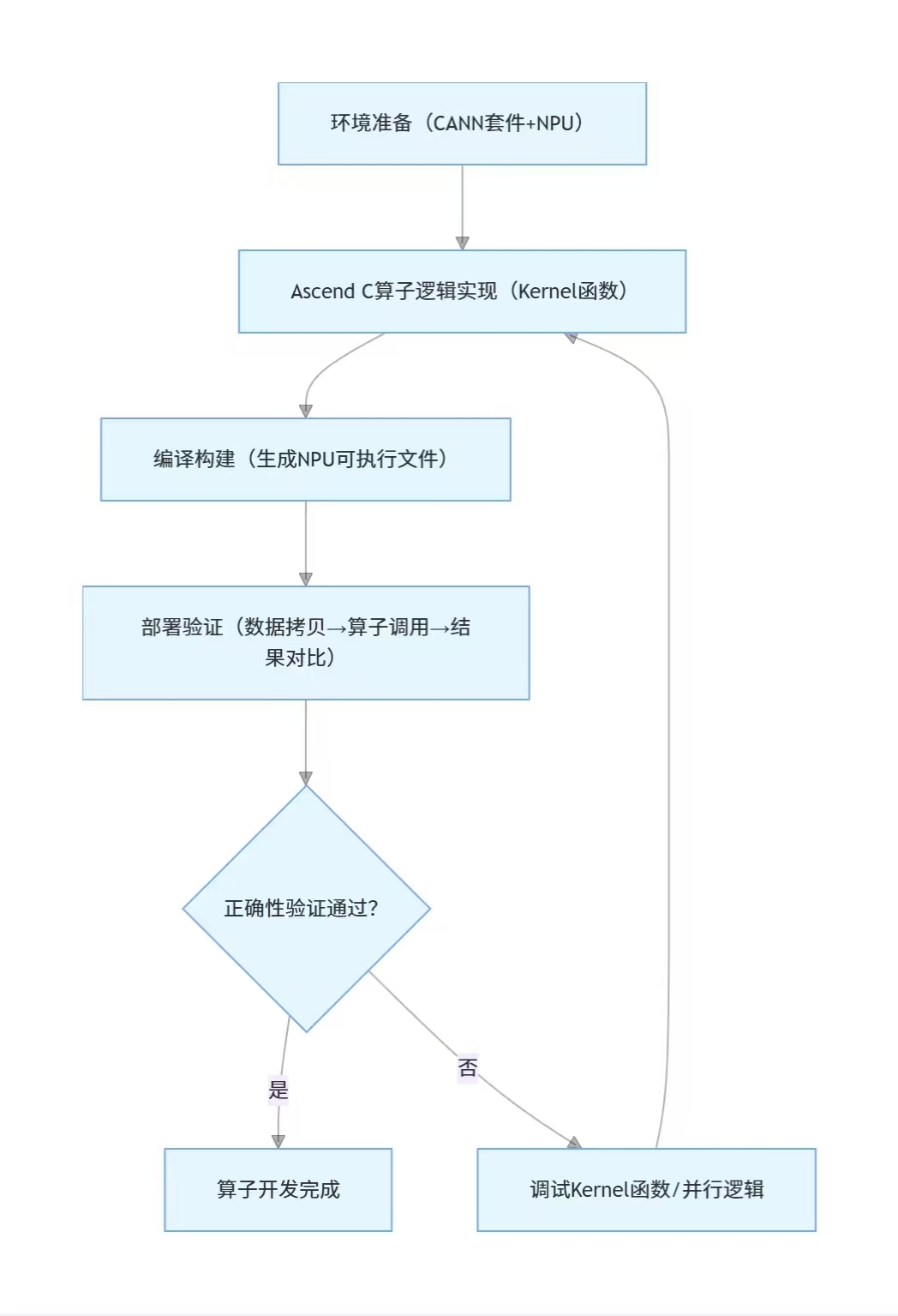
四、Ascend C 算子优化技巧:释放 NPU 算力
基础版本的 NPU 算子仅能保证功能正确性,需通过优化充分利用 NPU 的并行特性与内存层次,核心优化方向如下:
1. 并行粒度优化:增大工作组负载
基础版本中每个工作组仅处理 1 个元素,导致线程调度开销占比过高。优化方案:让每个工作组处理多个元素(如 32 个),减少工作组数量,提升并行效率。
// 优化后:每个工作组处理32个元素
__attribute__((reqd_work_group_size(32, 1, 1)))
__global__ void npu_vector_add_optimized(const float* a, const float* b, float* out, uint32_t length) {
uint32_t global_id = get_global_id(0);
uint32_t group_id = get_group_id(0);
uint32_t local_id = get_local_id(0);
uint32_t elements_per_group = 32;
// 每个工作组处理32个元素,计算当前工作组的起始索引
uint32_t start_idx = group_id * elements_per_group + local_id;
// 步长为工作组总数,避免重复处理
for (uint32_t i = start_idx; i < length; i += get_num_groups(0) * elements_per_group) {
out[i] = a[i] + b[i];
}
}
2. 内存访问优化:利用共享内存
NPU 的全局内存访问延迟较高,而共享内存(Shared Memory)速度接近 AI Core 计算单元。对于重复访问的数据(如卷积核),可先拷贝到共享内存,减少全局内存访问次数。
插图 3:NPU 内存层次与访问优化逻辑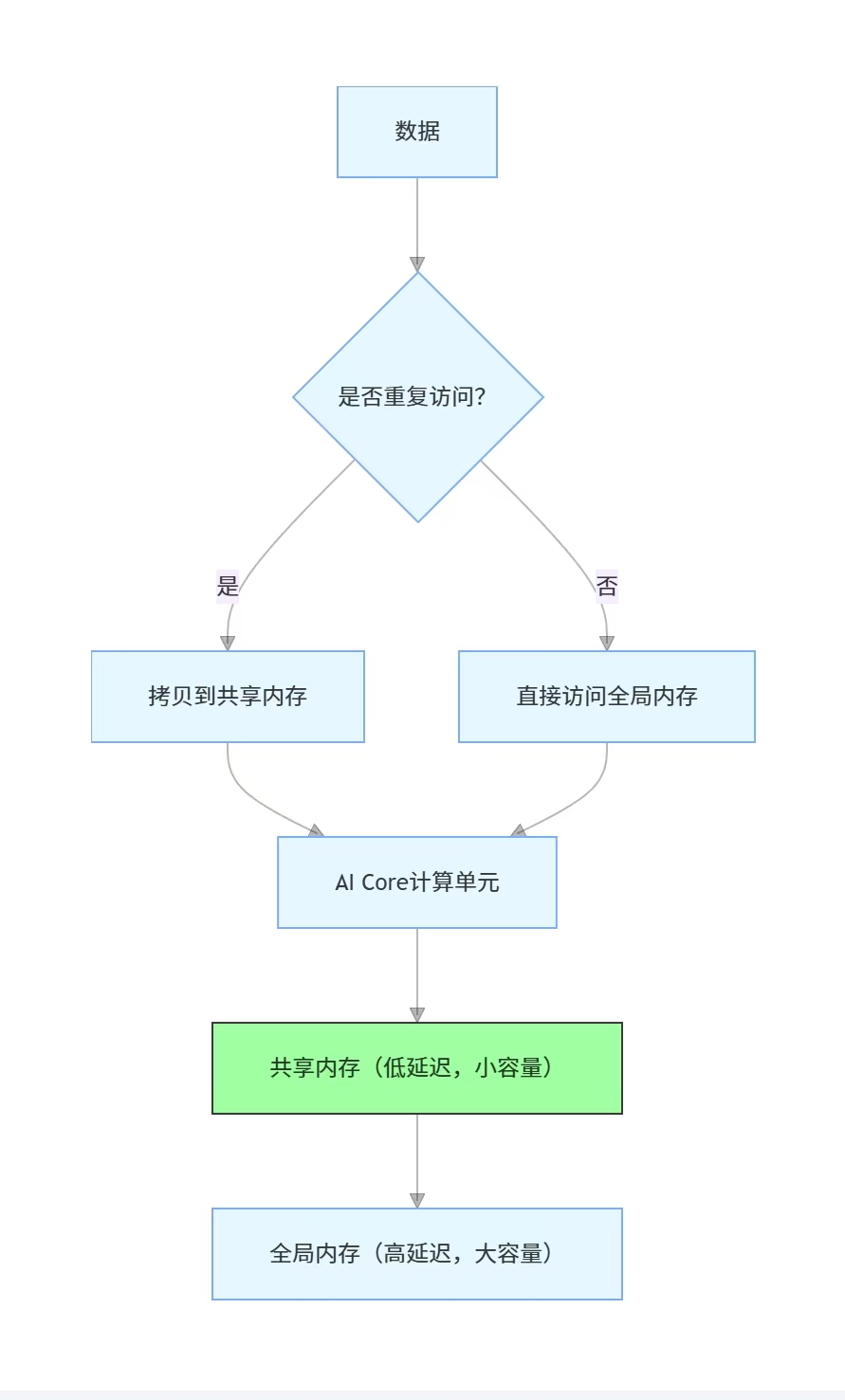
3. 指令优化:使用 Ascend C 内置计算接口
Ascend C 提供了针对 NPU 优化的内置接口(如ascendc_add),相比原生 C 语法,能更好地适配 NPU 指令集,提升计算效率。
// 使用Ascend C内置加法接口,优化指令执行效率
out[i] = ascendc_add(a[i], b[i]);
4. 性能调优工具:Ascend Profiler
通过华为 Ascend Profiler 工具分析算子的执行瓶颈(如内存访问耗时占比、计算单元利用率),针对性优化。核心关注指标:
- 计算利用率:AI Core 计算单元的繁忙程度(目标≥80%);
- 内存带宽利用率:全局内存的数据传输效率;
- 指令执行耗时:各阶段指令的执行时间分布。
五、总结
本文从基础概念出发,循序渐进讲解了 Ascend C 算子的开发流程:先回顾 CPU 算子的串行实现范式,再聚焦 NPU 架构特性,通过向量加法案例详细拆解了 Ascend C 算子的 “搭建→编译→验证” 全流程,最后分享了并行粒度、内存访问、指令优化等核心技巧。Ascend C 算子开发的核心逻辑是 “适配 NPU 众核并行架构”—— 相比 CPU 算子的 “逻辑优先”,NPU 算子更强调 “并行拆分” 与 “硬件资源利用”。
对于入门开发者,建议先通过简单算子(如向量加法、矩阵乘法)掌握 Ascend C 的编程模型与并行逻辑,再通过 Ascend Profiler 工具定位性能瓶颈,逐步优化。后续可深入学习复杂算子(如卷积、Transformer 注意力机制)的并行拆分策略,以及 Ascend C 与高层框架(如 MindSpore)的协同部署方案,充分释放 Ascend NPU 的算力潜力,为 AI 模型的高效运行提供底层支撑。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)