
英伟达跌成这样,是不是AI算力就没用了?
在于它并没有PRM,不对中间的生成步骤做任何干预(MCTS也没用)就是让模型自己的生成COT,然后因为模型被教育要一直思考,就不停的生成,生成多了,突然就到了一个“Aha”时刻,问题就被解答了,其实简单讲就式这个意思,不断的循环RL,对你要做的police,这个policy在这里就指带最初的V3,因为它是个在线的RL,不断的优化策略逼近 output reward最高的标准(它连reward模型都
还是先说结论,有用,然后我们在来科学的理性的分析,有没有用
首先为啥会大跌?
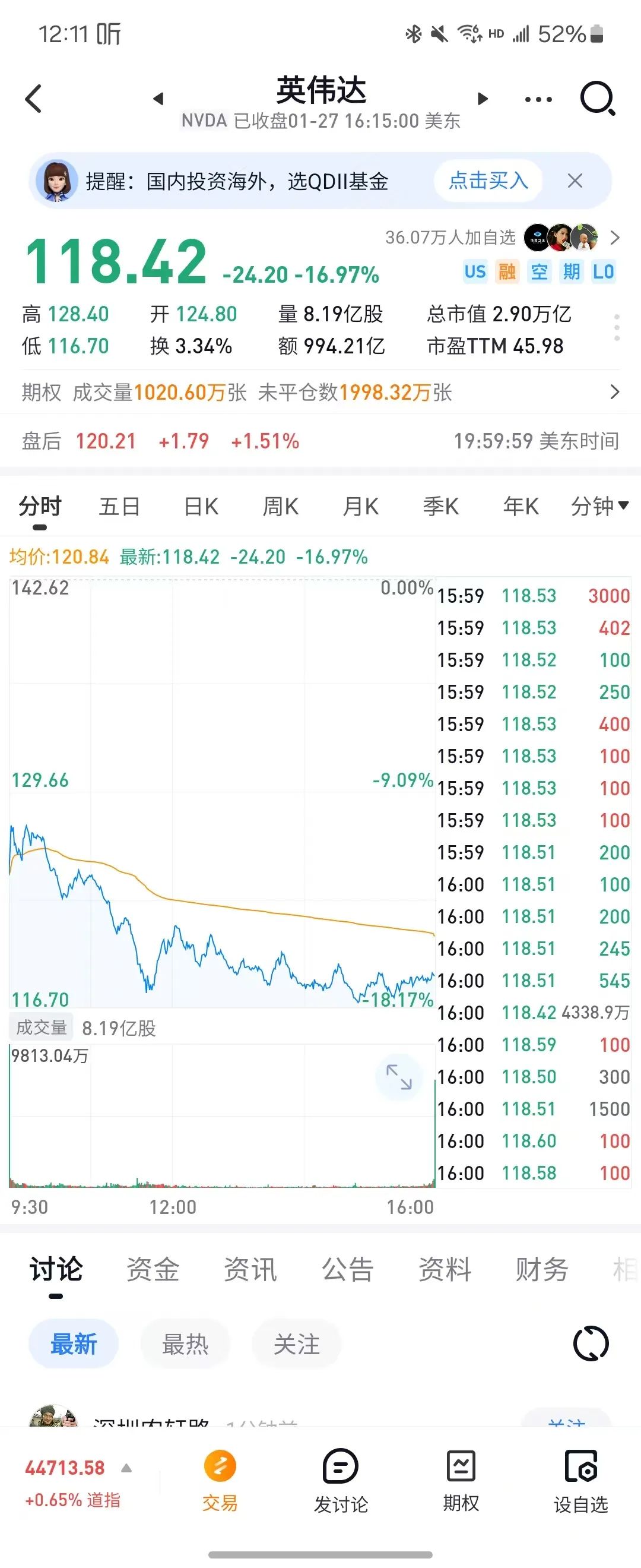
因为Deepseek R1吗?其实不是,是因为DeepseekV3
https://mp.weixin.qq.com/s/FUamd2LtioSdhOKy9Wt5CQ?token=313245269&lang=zh_CN
我在它刚发布V3的时候就写了这篇技术文,也发了微博,详细分析了和解释了一下它的价值,因为正常来讲,这个规模的模型,我们如果要做pretrain,那就是万卡左右的级别
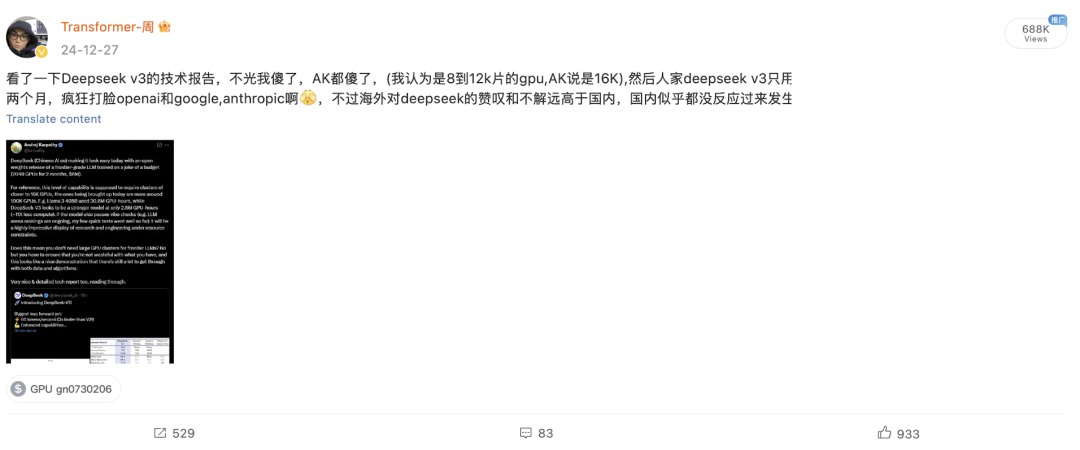
然后它给做到2000多块卡,就拿下了,效果还不错,所以它狠有价值,那是不是大家伙儿按着它的论文就能复现2000多块卡进行同等级别的pretrain呢?
答案是不太成。
至少现在我理解的大多数同学不太具备MOE工程调优的能力,你们训的模型别说256个专家,就算是8个专家,我随便拆掉两个,拆不拆都没区别

,更别说那些极致优化,你们罩着论文能get到几分都说不好。
其实最省的主要是FP8,但是前提是你得支持才行,你手里得有H的卡,而且你能整明白Mix-precision和FP8的配合,这个如果大规模好弄的话,Meta就不会只在量化小模型的时候才用Fp8,而训的时候用BF16了,DeepseekV3也好,R1也好,给你开源的都是权重,训练代码和学习率等重要的超参数,可是不会给你的。
但是
如果你们能做到一半,那么恭喜你,你为公司在pretrain上省了5000块卡,年底评选给个excellent不过分,从这个角度上来讲,V3的极致优化开辟了一个低成本的pretrain之路,在我之前的文章中也写过了,这里就不赘述了
从这个角度解读,对现行世界上所有的算力公司除了Groq,都是利空
然后我们接着看R1
R1是干嘛的,是对V3的后训练,也就是post train
一个模型的训练周期不是只有pretrain就结束了,pretrain训练出来的我们都叫base model,比如V3(V3肯定是经过SFT的,要不也用不了,我们就是拿它举例)它的特点是学习知识,请注意,知识和推理是两个概念。
如果非要比,你可以简单理解为它把书本上的字和句子,关联性都记住了,但是它可能说不明白话,这个时候需要sft,就是指令微调,即让它说人话
但是只是说人话就够了吗?
可能还是不够,我刚才说了知识不等于推理,如何让它的说出来的人话,像人类,甚至像人类一样思考得结论?
这就是RL reinforcement learning 即强化学习领域的问题
关于端到端模型训练请看我的文章(我写的书里也有讲)
https://mp.weixin.qq.com/s/BS0Rgmjv3osNFobfbi-XIw?token=313245269&lang=zh_CN
传统的RL最早就是RLHF,现在大多是RLAIF
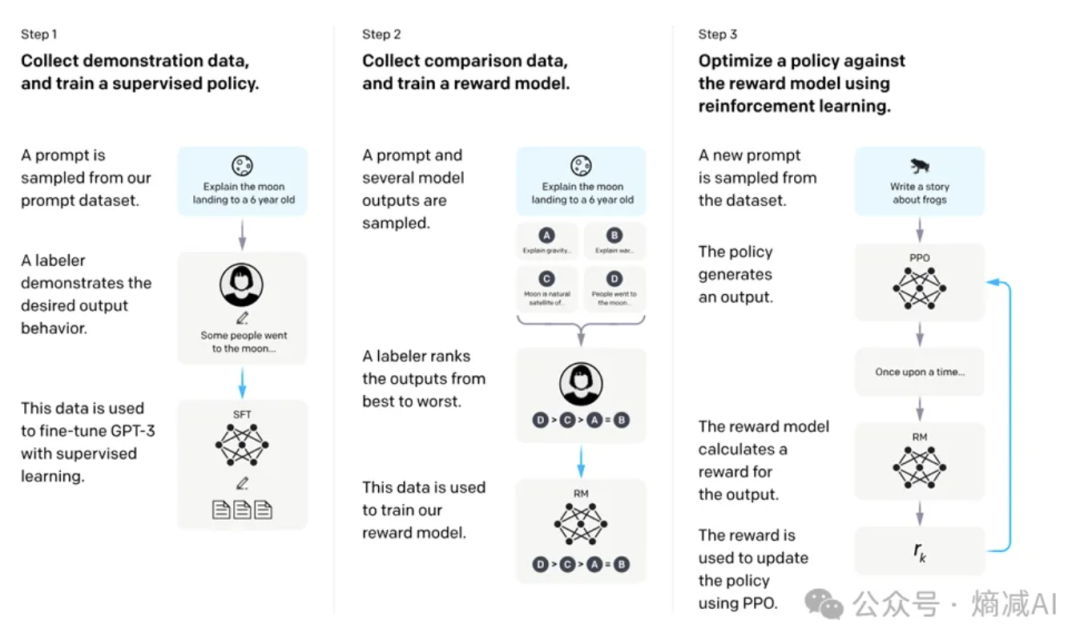
首先要以人类偏好训练一个reward model
什么是人类偏好,就是比如问你,范冰冰,李小璐,白百合,你媳妇,谁好看?让你排序,你回答:
1- 范冰冰
2- 李小璐
3- 白百合
4- 你媳妇
然后不同人有不同的选择,比如第二个人打分
1- 李小璐
2- 白百合
3- 范冰冰
4- 你媳妇
这个目的是为了防止大家独特的人类偏好影响数据分布,比如你只选一个可能其他美女就不会被选中,但是以排序的方式,就变成了一种隐式加权,所以大家的权重都能保留下来,然后基于大数法则,那最后范冰冰获胜了,所以以后你问谁最好看,LLM就回答,范冰冰
这个问题是什么呢?
问题就是只有答案,什么叫问题是只有答案呢?
因为你的reward也就是奖励的依据,就只有答案,比如你回答范冰冰能得4分,你回答你媳妇就得1分,它是基于这个最终结果来对齐偏好的。
那这样的问题是什么呢?
就是你问我答呗,有什么问题呢?那现在就回答我一个问题,我问范冰冰和你媳妇谁好看,你很容易不加思索来告诉我,范冰冰。
那我问你这样一个问题

你能马上回答我吗?
当然大概率你马上回答我,“给我拿一遍去,不想看!”
但是如果你能解的话,你需要想很久,为什么要想呢?
因为你的大脑的前额叶会先拿到任务,然后它到处派发,基底神经拿各个子任务在不同神经元之前切换,比如有算矩阵的,有算方程的,小脑去确保精准度,颞叶来搞各种符号话,当然肯定不像我说这么简单,就大概这么理解吧
其实LLM在处理复杂问题时,如果能把复杂问题拆解化,它回答的成功率也会变高,早起就有metaGPT,autoGPT来做这种外置的agent形式,引导LLM一个任务,一个任务的完成
另外一个角度就说LLM其实有自己的COT chain of thought,就是它也会把复杂问题给进行分解一步一步的,这种你可以用step by step answer my question等 prompt去把隐式的COT给激活来回答问题
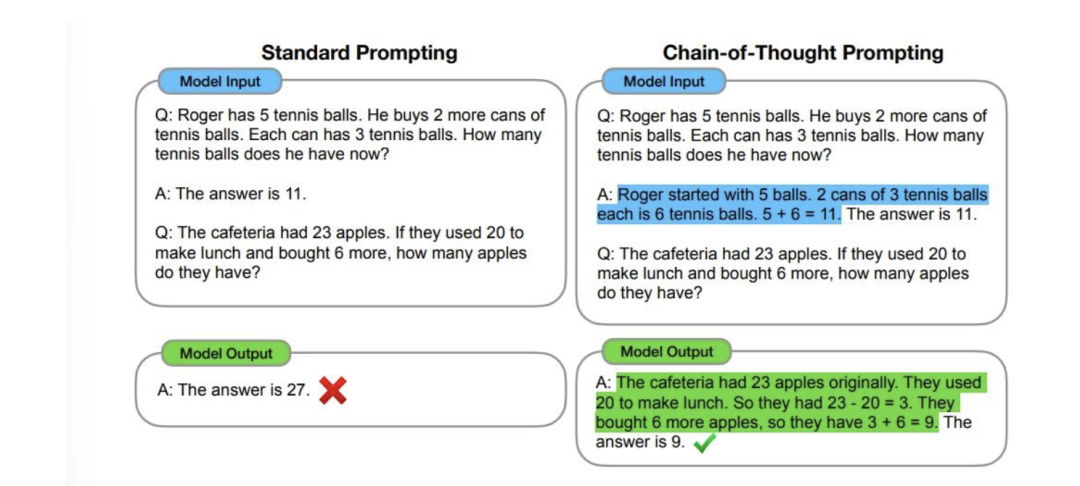
隐式COT是怎么形成的?
总结下来有这么几点
- 海量数据预训练
确保模型接触到广泛领域的语料,包括隐含推理和逻辑推导的内容。
- 多任务学习
通过同时训练多种推理任务,增强模型泛化能力。
- 复杂任务微调
设计需要隐性推理的任务(如填空、问答),鼓励模型内化中间推理过程。
- 层级表征的优化
通过架构调整或特定正则化方法,增强模型的隐性逻辑表征。
除了以上几点模型一定要够大,这个其实也是传统scaling law的一个分支benifit吧,因为足够大,你就会有机会和潜能学到隐式表征,而隐式表征,其实很多时候你也不知道它到底是啥(这句到不算是开玩笑),COT也包含在里面
隐式COT的问题是什么?
第一是调用费劲,本来你也没特意训练它,怎么调,就靠prompt神经刀
第二是不一定能出来,道理参见第一条
第三是不一定优,就是你的COT路径先不说能不能解决问题,解决了也不见的是最好的答案
先说第一个和第二个问题
隐式不好弄,我门就给它显性化呗,o1也好,R1也好,都是显示COT训练的一个门派
O1我以前讲过好几篇文章这里就不在废话了,大家自己翻翻
R1它的不一样在哪里呢?
在于它并没有PRM,不对中间的生成步骤做任何干预(MCTS也没用)就是让模型自己的生成COT,然后因为模型被教育要一直思考,就不停的生成,生成多了,突然就到了一个“Aha”时刻,问题就被解答了,其实简单讲就式这个意思,不断的循环RL,对你要做的police,这个policy在这里就指带最初的V3,因为它是个在线的RL,不断的优化策略逼近 output reward最高的标准(它连reward模型都没有,因为是GRPO,GRPO本质上是一种DPO,纯靠偏好function来做RL的)
当你的policy,也就是策略优化到“Aha”的时候,它做什么其他的范化题就都按着“Aha”的套路来了,如果你看过R1的中间输出,你会发现它是不断的reflect自己之前的答案,本质上也算是一种self-play自博弈了
这个方法的好处显而易见
你不用去像o1或者其他的test time inference来做COT数据用来训练,训两个reward, PRM和ORM,你直接自己做完了COT数据,刷自己,然后刷完了接着你变身成相对更高的自己,然后再基于t‘时间的自己,再造COT数据,再刷,不断的左脚踩右脚,然后螺旋升天,直到"Aha"时刻的到来
非常简单,如果非要我比喻的话,就有点像当年AlphaGo学围棋棋谱一样,或者像你自己拿RL 玩超级玛丽是一个道理
那它的问题在哪?
对中间过程的控制有限,或者几乎不控制,R1论文也写了,中间过程不太好给损失量化,PRM也不好训,这其实就已经不是AI领域的问题了,很多是数据工程的问题,但是它通过不断的刷来出的中间结果,往往被选中的都是那些最长的COT,道理也简单,你生成东西多,在context没超总体限制的情况下,参考就多,步骤多,分解任务细,反思的也多。
但是
你是不是显存占的也多啊?
这就是我说的如果你要玩R1派的后训练的化,你是要比传统的PRM那套(有规划路径)的要废显存的,因为你一个PRM加一个ORM加个value sever才能占多少显存啊,而且他们不更新权重,只输出reward,可是COT这玩意理论上每个都能给你打到很长
比如我最近玩hf的R1复现
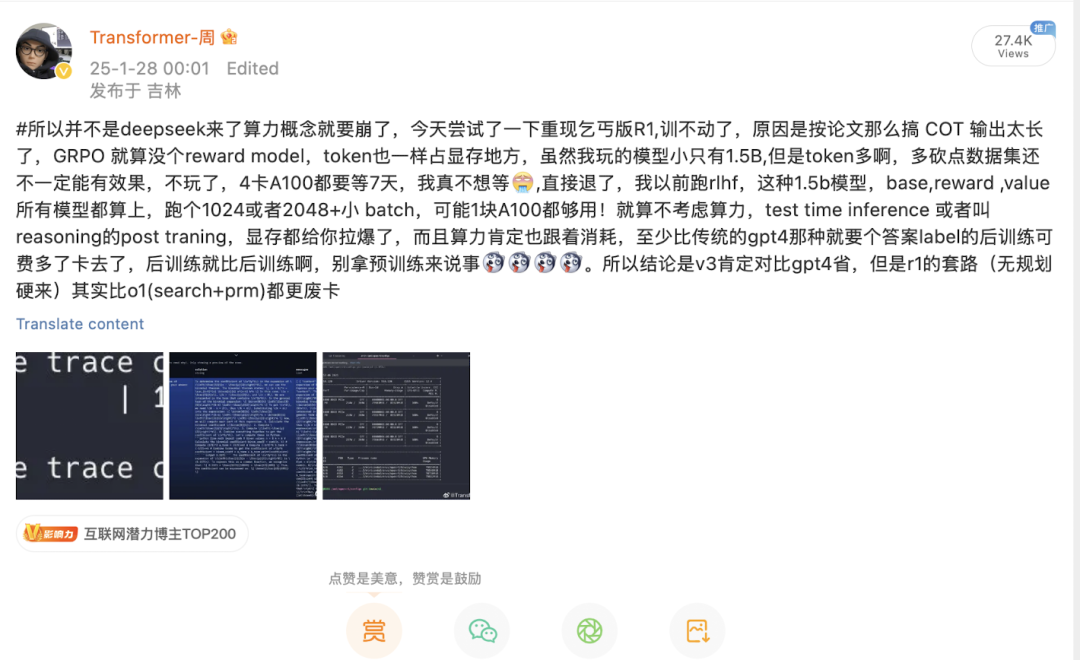
我4个A100 80G,每个卡跑1个batch还zero3呢,都跑不动,我玩的只是7B的模型(或者我应该1.5B的才是)
nohup accelerate launch \--config_file configs/zero3.yaml \src/open_r1/grpo.py \--output_dir DeepSeek-R1-Distill-Qwen-7B-GRPO \--model_name_or_path deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \--dataset_name AI-MO/NuminaMath-TIR \--max_prompt_length 256 \--per_device_train_batch_size 1 \--gradient_accumulation_steps 16 \--logging_steps 10 \--bf16 \--report_to none \> output.log 2>&1 &
COT太多步骤了,尤其是被引导以后
我这还没到自己产数据呢,就拿点通用的数据刷GRPO都费劲
我们算一下,我7B的 BF16能有占大,14G的参数,14G的梯度,28*2的一阶二阶优化器,84G呗,我4块80G啊,320G啊? 那这240多G全让激活啥的给吃了
最后说一下第三点 不一定优
什么叫不一定优呢?因为训练R1一定是损失函数拟合以后才能停止训练的对吧,也就是说基本上它肯定该答对,答对啊,它是对结果reward么
但是结果分为全局和局部
全局就是你这个答案的对与否,这个是第一要义,首先你要打错了就白扯了
那局部呢,就是你每一步的解体思路是否最优,比如你说你从海淀去密云,你非要做飞机去,能不能去,肯定是可以,但是你降落在哪啊?密云也没有机场,大概就是这个意思
每一个局部最优不见的全局最优,但是是最高概率的全局最优解
比如O1类的训练其实是采用的这个模式,所以你会发现O1满血其实比o1-preview的中间状态更短,因为它对这个做了优化,但是特别复杂的问题,它也会通过增加中间步骤,增加推理时间来取得更好的结果,从这个意义上来讲R1和O1是在推理测对立统一的
而这个时间是什么呢?
这个时间全是算力,也就是我们说的test time,着也就是他们被称为test time inferece model的由来,比如O1它的时间就被应用到,生成更多的search 路径,然后去判断哪个最优,继续下一步,比如R1,它就生成更多的tokens,然后再里面找context进行分析
再慢思考的解题条件下,不管是R1还是O1都不会省算力,以后也只可能是更废,比如所谓的O3让你解一条问题花3000美金
但两者还是有点区别,R1对显存的要求更高,因为中间结果并不太受控制
好了,总结一下,R1模式诞生会不会对AI算力有影响
1- 预训练有影响,这也不怨deepseek,要不你说黄仁勋它吹FP8干什么?那它出了,就是让人用的对吧?毫无问题,这个至少省你一半卡,我估计老黄一想到最近一直在推FP4的GB300,它就肉疼



2- 对后训练的影响,R1会比PRM+search更消耗资源
3- 对推理,R系列还是o系列都会越来越耗费资源
今天就讲到这里,祝大家新年快乐!
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)