
ECCV | 注意力最后变成“背台词”?ASR 把 Channel Attention 训练完就焊死进模型里,无成本提升性能
你可能见过这样的线上事故:同一个视觉模型,离线评测分数漂亮,一上手机端或摄像头端就“掉帧”,工程师只好把注意力模块(attention module)一刀切掉。更尴尬的是——这篇论文抛出一个很反直觉的发现:很多 channel attention 训练到后期,可能根本没有在“因图制宜”地看输入,它们对不同图片给出的权重,竟然会收敛到接近常数的 per-channel 向量。如果这是真的,那我们在部署端为“动态注意力”付出的算力和延迟,究竟是在买什么?
ECCV 这篇论文《Stripe Observation Guided Inference Cost-free Attention Mechanism》【代码】把这个冲突推到台前:一边是业界对 attention 的依赖(提升精度、增强表达),一边是它在推理阶段的昂贵代价;而作者的反直觉观察(Stripe Observation)暗示:至少对 channel attention 来说,很多收益可能来自“数据集层面的平均先验”而非每张图的动态决策。于是他们干脆顺势而为,提出 ASR(attention-alike structural re-parameterization):训练时借 attention 的“形”,推理时把它“折叠”进卷积/BN 权重里,让部署阶段没有 attention、也没有额外开销。
1. 背景:Attention 好用,但为什么一上端就变“奢侈品”?
过去几年里,Structural Re-parameterization(SRP)是一条很务实的路线:训练时结构复杂一点(多分支、多层),推理时通过等价变换把它们合并回主干,从而做到“训练占便宜、部署不背债”。这类方法已经在 normalization、convolution 等组件上玩得很成熟。
但 attention 一直是 SRP 里的硬骨头。原因并不神秘:典型的 channel attention(如 SE)会先对输入特征做 Global Average Pooling(GAP),再过一个小网络 F θ F_\theta Fθ,得到每个通道的权重 v v v,最后用乘法门控 x ′ = x ⊙ v x' = x \odot v x′=x⊙v。这个 v v v 是 input-dependent 的:每张图都要算一次,乘法门控也让“合并进权重”变得不自然。
更现实的问题是:attention 经常很慢。作者用 ResNet164 做了一个直观对比:在 CIFAR100 上原模型推理速度 1944 FPS,但加上 CBAM 之后降到 793 FPS(下降约 59%);SE、SRM、DIA 等也带来明显掉速。而 ASR 版本却几乎不掉速,参数量也不变——这恰好戳中部署侧的痛点:我们想要 attention 的精度红利,但不想在推理端付“税”。
表 1:注意力模块带来显著掉速,而 ASR 版本几乎不影响 FPS
这里的表格数据也很清晰:**SRP 的承诺是“推理免费”,attention 的现实是“推理昂贵”。**如果 attention 的作用真是“每张图动态调权”,那它就很难被 SRP 化;但如果它并没有那么动态呢?
2. 反直觉的“意外”:Stripe Observation 到底观察到了什么?
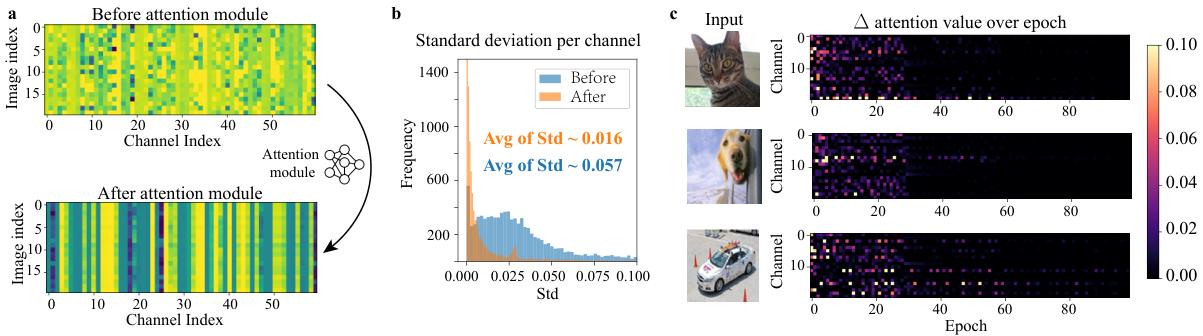
图 1:左图:热力图,横轴 image index,纵轴 channel index,颜色表示 attention value,呈现明显横向条纹;中图:每个 channel 的标准差直方图,峰值靠近 0;右图:attention value 随 epoch 的一阶差分曲线,多数快速下降趋近 0。
作者在多种设置下看到一种条纹状统计现象(Stripe Observation):把不同图片通过某个 channel attention 模块得到的 v v v 画出来,你会发现同一通道上的权重在不同图片之间越来越接近,像一条条横向“条纹”。更进一步的统计是:每个通道的 attention 值在样本维度上的标准差几乎围绕 0 分布;训练过程中 attention 的一阶差分也很快趋近 0,意味着它迅速稳定在某个常数附近。
这不是在说“attention 完全无用”,也不是在泛化到所有注意力类型(作者明确说 spatial attention 不成立)。它更尖锐的含义在于:对 channel attention 来说,很多时候它学到的可能是数据集的平均偏好(prior),而不是每张图的即时判断。
谁受益、谁受损?如果这个现象成立,受益者首先是部署工程团队:他们可以把一部分“注意力收益”用更便宜的方式拿到;受损的可能是注意力模块“动态推理叙事”的拥护者——至少在某些数据集/训练设置下,channel attention 的动态性可能被高估了。更微妙的损失者还可能是追求极致 OOD 泛化的人:如果学到的是数据集平均先验,那换域时可能会有隐患。
3. 方法:ASR 如何把 attention 变成“训练期临时工”?
ASR 的核心设计非常直接:既然训练后 v v v 往往接近常数,那就让它从输入端开始就不依赖图像。
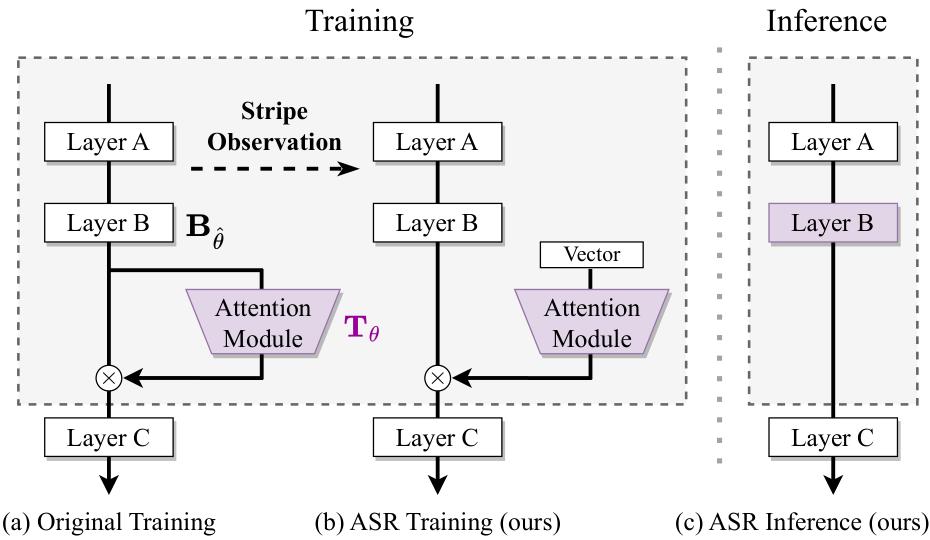
图 2:ASR 结构示意:训练时有 attention 形态,推理时融合进主干参数
先回到标准 channel attention 的形式。给定输入特征 x ∈ R C × H × W x \in \mathbb{R}^{C\times H\times W} x∈RC×H×W,先做 GAP 得到 u ∈ R C × 1 × 1 u \in \mathbb{R}^{C\times1\times1} u∈RC×1×1,再经由
v = T θ ( u ) = σ ( F θ ( u ) ) , x ′ = x ⊙ v v = T_\theta(u) = \sigma(F_\theta(u)), \quad x' = x \odot v v=Tθ(u)=σ(Fθ(u)),x′=x⊙v
其中 F θ F_\theta Fθ 是注意力模块的可学习网络, σ \sigma σ 通常是 Sigmoid。
ASR 的“替换”发生在最关键的那一步:它不再用 GAP(x) 得到 u,而是引入一个可学习向量 ψ ∈ R C × 1 × 1 \psi \in \mathbb{R}^{C\times1\times1} ψ∈RC×1×1 作为注意力网络的输入:
v ψ , θ = σ ( F θ ( ψ ) ) v_{\psi,\theta} = \sigma(F_\theta(\psi)) vψ,θ=σ(Fθ(ψ))
这样得到的 v ψ , θ v_{\psi,\theta} vψ,θ 对所有输入都是同一个常数向量,但它并不是手工设定的,而是和主干网络一起训练出来的。
真正让它成为 SRP 的,是推理阶段的“折叠”:因为 v ψ , θ v_{\psi,\theta} vψ,θ 是常数,乘法门控可以被并入相邻层的参数。论文给了卷积的等价变换例子:若某层是卷积 C ( x ; K , b ) C(x;K,b) C(x;K,b),则
C ( x ; K , b ) ⊙ v = C ( x ; K ⊙ v , b ⊙ v ) C(x;K,b)\odot v = C(x;K\odot v,\; b\odot v) C(x;K,b)⊙v=C(x;K⊙v,b⊙v)
BN 也类似,把缩放 γ \gamma γ 与偏置 β \beta β 按通道乘上 v v v 即可。于是推理图里,attention 模块可以消失,只留下已经“焊死”了的权重。
这一步其实把“谁在推理时承担计算”这件事重新分配了:attention 不再是部署时的算子,而是训练期用来塑形的一种机制。换句话说,ASR 把 attention 从“在线决策”改造成“离线校准”。
4. 实验结果:免费推理的代价是谁付的?效果又是谁拿到的?
作者覆盖的实验设置很广:backbone 包括 ResNet、VGG、ShuffleNetV2、MobileNet、ViT,以及本身属于 SRP 体系的 RepVGG、ACNet;数据集包括 ImageNet、CIFAR10/100、STL10;任务还扩展到 COCO 上的 Mask R-CNN 做 detection/instance segmentation。指标以分类 Top-1 accuracy 和 COCO AP 为主,并强调至少 3 次 runs 以保证统计意义。
在 ImageNet 分类上,ASR 在多个 backbone 上给出稳定增益。在 COCO 的 Mask R-CNN 上,ASR 也能带来 AP 增益。
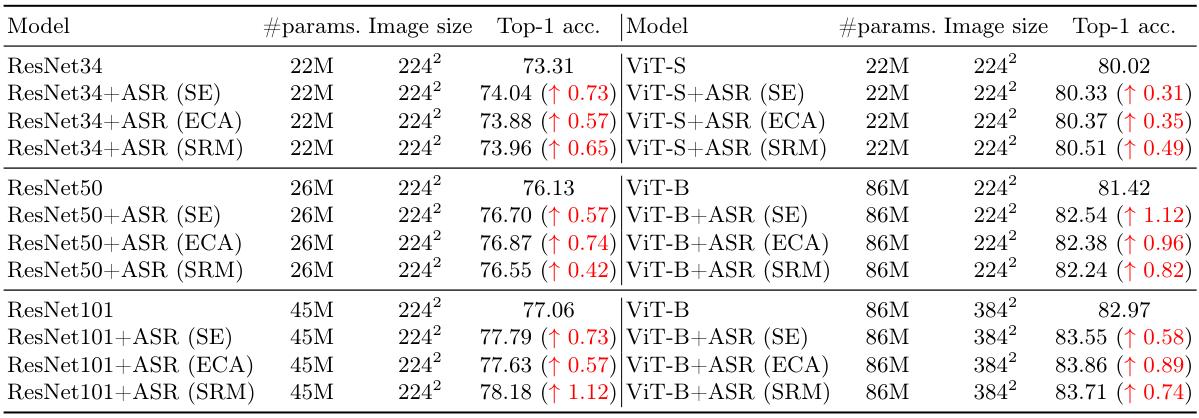
表 2:ImageNet 分类:ResNet/ViT 上的 Top-1 提升
作者也展示了与已有 SRP (如ACNet)以及 “ASR + 原 attention”叠加的效果,强调 ASR 的兼容性。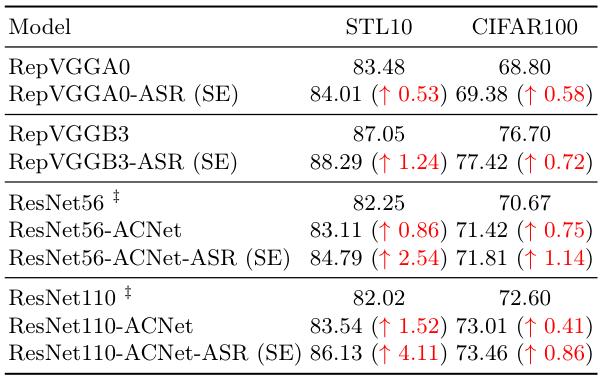
表 3:ASR 兼容 SRP (如ACNet)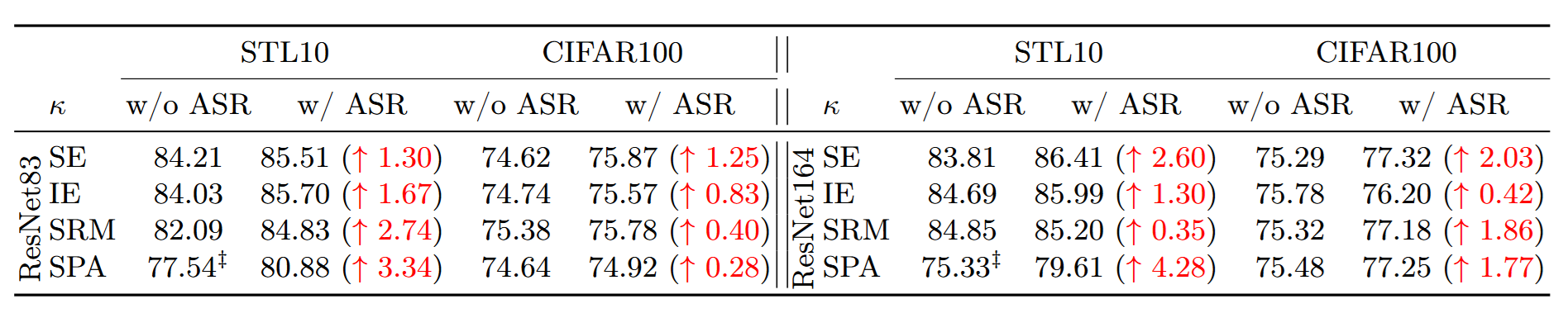
表 4:ASR 兼容 原 attention module
更关键的是“免费”这件事的证据:作者在速度与参数量上对齐展示,ASR 版本在推理速度上与原模型几乎一致,而常见 attention 模块会显著拖慢(前文 Table 1 的对比就是这一点)。
5. 分析与边界:当“免费”可以无限叠加时,为什么模型反而变差?
这篇论文最值得工程师警惕的一点,恰恰是它自己揭示的失败模式:ASR 虽然推理不加成本,但并不意味着你可以无限堆叠。
作者用 δ \delta δ 表示在网络相同位置插入 ASR 的次数(或频率),实验显示性能会“先升后降”。在 CIFAR100 的 ResNet164 上,某些模块在 δ = 2 \delta=2 δ=2 时达到更高点,但继续增加到 δ = 4 \delta=4 δ=4 反而回落。论文给出的解释很朴素也很硬核:attention 输出一般经过 Sigmoid,值域 ≤ 1 \le 1 ≤1。当你多次乘上这些向量,本质上在对特征做反复衰减,特征会越来越小,影响信息传递与训练稳定性;同时训练成本也会上升。

表 5:多次插入 ASR 的“先升后降”:δ 增大并非越多越好
另一个边界是适用范围:作者明确指出 Stripe Observation 主要针对 channel attention;对 spatial attention 并不成立,因为后者对每张输入会产生差异化的空间注意力图,这使得“常数化再融合”不直接可行。这一点很重要,它把 ASR 从“注意力通用替代”拉回到更精确、也更可信的定位:它是对 channel-wise gating 的 SRP 化,而不是对所有 attention 的否定。
最后,关于“为什么会趋于常数”,作者给了经验解释:数据集存在先验(例如分类数据常见主体居中、颜色/构图偏好),attention 模块擅长捕捉归纳偏置,训练到后期就可能收敛到某种“平均先验”的表达。他们用 Grad-CAM 在 STL10/ImageNet 上对 SENet、SRMNet 抽样 500 张图做平均可视化,发现关注区域倾向中心。但在检测/分割任务中仍能观察到 Stripe,作者推测那是更高层的先验,暂不易可视化——这也为后续研究留下了悬念。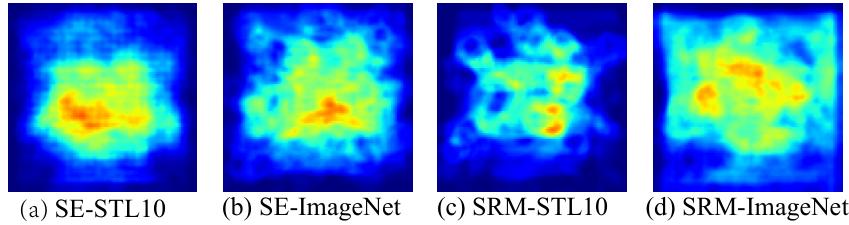
图 3: Grad-CAM 在 STL10/ImageNet 上对 SENet、SRMNet 抽样 500 张图做平均可视化,发现关注区域倾向中心
6. 小结:如果 attention 学到的是“平均先验”,那它在换域时会帮你还是害你?
ASR 的故事之所以有冲击力,不只是“推理免费”这种工程爽点,而是它背后反直觉的发现:至少在一些常见训练设定里,channel attention 的动态性可能正在塌缩成数据集层面的常数偏好。ASR 把这个现象变成一种可部署的技术:训练时借力 F θ F_\theta Fθ 学出常数向量 v ψ , θ v_{\psi,\theta} vψ,θ,推理时把它融合进卷积/BN 权重里,让 attention 变成“干完活就消失”的临时工。
但真正悬而未决的问题是:这些常数向量到底编码了什么?它们是“有益的平均规律”,还是“数据偏见的固化”?当你把这种先验焊死进权重里,遇到分布转移(domain shift)时,它会成为鲁棒性的护栏,还是会变成看不见的枷锁?
此外,这一高效、0成本提升性能的方法能否应用于实际复杂场景,例如医疗图像分类?这是悬而未决的挑战。
论文:https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/03451.pdf
代码:https://github.com/zhongshsh/ASR
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)