
GPU选型参考
本文介绍了GPU的关键参数与选型要素。GPU由GPU芯片、显存、PCB板等组件构成,可通过Linux命令查看详细信息。主要性能指标包括:1)算力(TFLOPS),决定计算速度;2)显存容量与带宽,影响数据处理能力;3)核心数量,提升并行处理效率。GPU架构演进从Volta到Hopper,不同架构对应不同计算能力版本号(sm_xx)。选型还需考虑软件生态、互联技术及物理参数。此外,文章详细解析了FP
GPU各架构数据卡代表产品参数对比-用于训练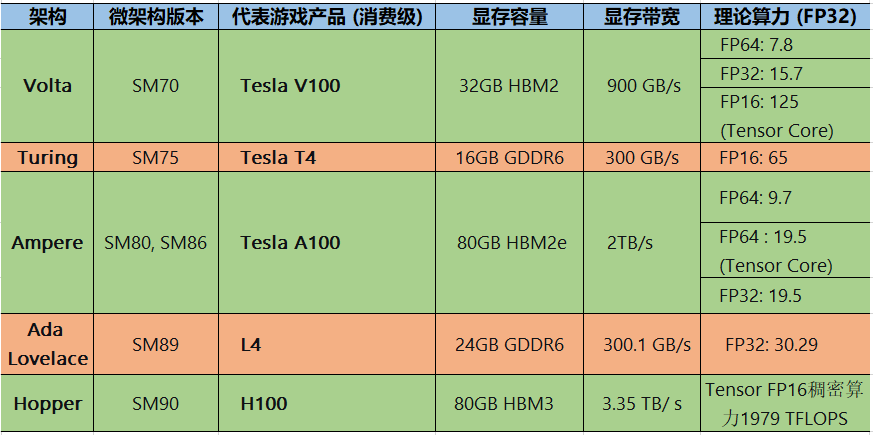
GPU各架构游戏卡代表产品参数对比-用于部署推理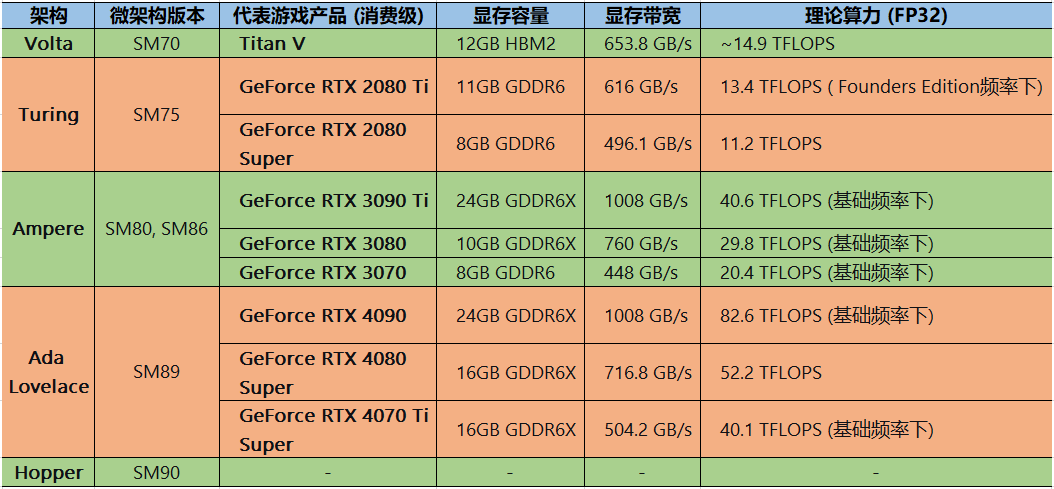
显卡:GPU芯片+显存+PCB板+散热器风扇+供电模块+接口
linux下查看GPU芯片信息:torch.cuda.get_device_properties(0)
各参数介绍:
1.Tesla: NVIDIA 的专业计算卡产品线数据卡 Tesla V100-SXM2-32GB:
2.V100: 基于 Volta 架构的旗舰级计算卡
3.SXM2: 一种封装形式
4.32GB: 显存容量。这是高带宽内存(HBM2),容量巨大
5.major=7, minor=0,sm_70 / compute_70 ,7.0 对应 Volta架构
major :主版本号,minor :次版本号,定义了GPU的硬件特性(如支持的指令集、线程结构、内存布局等)。
CUDA代码在编译时需要指定一个计算能力版本,以生成针对该架构优化的机器码
6.total_memory=32501MB
, GPU 显存大小
7.multi_processor_count=80:流式多处理器(Streaming Multiprocessors, SMs) 的数量,衡量GPU并行计算能力的一个关键指标
SM 是 GPU 的最核心的计算单元,是GPU的“心脏”,是一个强大的计算核心集群。每个 SM 包含大量的 CUDA 核心(对于 V100,每个 SM 有 64 个 FP32 核心和 64 个 INT32 核心)。SM 数量越多,GPU 的并行处理能力越强。
V100 有 80 个 SM
8.uuid=025c7591-2264-ccd3-4c66-f4c769430979,GPU设备的通用唯一识别码
9.L2_cache_size=6MB 二级缓存的大小
GPU选型参考因素:
一、性能参数
1.算力(TFLOPS) 即计算能力,GPU每秒浮点运算次数,是核心性能指标
算力 (FLOPS) = 19.5 TFLOPS=计算单元数量 × 核心频率 (Hz) × 每个时钟周期能完成的操作数 (FLOPS/cycle)
峰值理论算力理想条件才能达到,各指令高效率工作,更关注有效算力
精度与算力挂钩,不同精度之间的算力通常存在简单的倍数关系: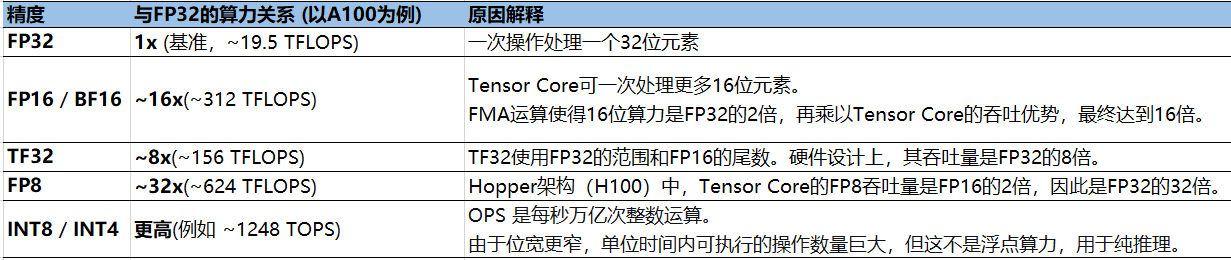
2.显存
(1)容量(GB):硬件固定值,nvidia-smi查看
显存容量决定能加载多大的模型,即GPU一次性能处理多大的数据。模型主要由权重参数(Weights) 和前向传播的中间激活(Activations)占用空间还有优化器状态、梯度
、中间激活值、输入数据(Batch Size)。训练中需要预留比模型权重本身多得多的显存。推理时则主要考虑权重和批次数据。
模型权重所需显存 ≈ 参数量 × 每个参数所占字节数
FP32: 每个参数占 4 字节
FP16 / BF16: 每个参数占 2 字节
INT8 : 每个参数占 1 字节
INT4 : 每个参数占 0.5 字节
举例:
一个 70亿(7B) 参数的模型,在不同精度下所需的显存大致为:
FP32: 7B × 4 Bytes = 28 GB
FP16: 7B × 2 Bytes = 14 GB
(2)带宽(GB/s):数据从显存移动到计算核心的速度。HBM (高带宽内存)
显存带宽 = 显存频率 × 显存位宽 / 8 × 2
显存频率(MHz):每秒传输的次数。
显存位宽(bit):每次传输的数据量。好比高速公路的车道数。
÷ 8:将比特(bit)转换为字节(Byte)。
× 2:因为GDDR和HBM采用DDR(双倍数据速率)技术,一个时钟周期可以传输两次数据。
举例: RTX 4090 使用 21 Gbps 的 GDDR6X 显存,位宽为 384-bit。
带宽 = 21 GHz × 384 bit / 8 × 2 ≈ 1008 GB/s ≈ 1.0 TB/s
3.核心数量
CUDA Cores :并行计算的基本单位,数量越多,并行处理能力越强。
Tensor Cores:专为AI矩阵运算设计的核心,能极大加速FP16/BF16/INT8等混合精度计算。是AI卡和游戏卡的本质区别之一。
RT Cores:专为光线追踪计算设计,主要用于图形渲染和游戏。
算力(TFLOPS) 和 显存带宽(GB/s) 是衡量GPU性能的两个最关键指标,前者决定计算快慢,后者决定数据供给能力。
二、GPU架构
演进顺序:Volta (sm70) -> Turing (sm75) -> Ampere (sm80/86) -> Ada (sm89) -> Hopper (sm90)
训练:数据中心卡,V100等
推理部署:消费级游戏卡, RTX 20/30/40系列
数据卡>可视化卡(专业卡)>游戏卡:Tesla>RTX>GeForce RTX
架构 (Architecture) -> 产品 (Product) -> 计算能力 (Compute Capability)
Ada Lovelace 架构 -> 生产了 RTX 4090 (消费级卡) 等产品 -> 它的计算能力是 sm89。
1.架构(Architecture)
(1)Hopper (2017)
包含H100、H200。专为大规模AI和HPC(高性能计算)设计的数据中心架构,数据中心卡
(2)Ada Lovelace (2018)
消费级游戏卡 (GeForce RTX):RTX 40系列:RTX4090、RTX4080、RTX4070等
专业可视化卡 (RTX):RTX6000、RTX4000
(3)Ampere (2020)
数据中心/AI卡 (Tesla):A100、A800
消费级游戏卡(GeForce RTX) :RTX 30系列: RTX 3090, 3080, 3070等
专业可视化卡(RTX) :RTX A6000、A5000、A4000等
(4)Turing (2022)
消费级游戏卡 (GeForce RTX/GTX):
RTX 20系列: RTX 2080 Ti, 2080, 2070
GTX 16系列: GTX 1660 Ti, 1660
专业可视化卡 (Quadro):RTX 8000、RTX 6000、 RTX 5000等 (首次在专业卡上启用RTX命名)
(5)Volta (2022)
数据中心/AI卡 (Tesla):V100
消费级至尊卡 (Titan V):Titan V
计算能力版本号:70、75、80、86、89、90。compute_xx 和 sm_xx表示。
CUDA代码在编译时,需要指定一个目标计算能力(如 -arch=sm_80),编译器会根据该架构的特性生成优化的机器码。
-arch=sm_xx 等价于 -arch=compute_xx -code=sm_xx,意为“使用xx代的指令集功能,并专门为xx代的硬件生成本地代码”。
虚拟架构: compute_xx 表示,指定了编译器可以使用的指令集和功能。编译器生成一个中间表示(PTX代码),该代码是跨代的、可移植的。
真实架构:sm_xx 表示,编译器生成优化后的本地机器码(SASS代码) 的具体硬件目标,可获得最佳性能,但缺乏跨代兼容性
- compute_xx 定义了“语言标准”(PTX)
- sm_xx 定义了“目标处理器”(SASS)
2.软件生态系统
NVIDIA:CUDA
AMD ROCm:AMD的开源计算平台,旨在对标CUDA。
Intel oneAPI:Intel为其GPU推出的统一开发模型。
绝大多数深度学习框架(PyTorch, TensorFlow)、科学计算库和软件开发工具都基于CUDA构建。
3.互联技术
多卡并行,互联带宽至关重要
NVLink(NVIDIA):高速直接互联技术,用于高效多卡通信
PCIe Gen(4.0/5.0):GPU与CPU/主板通信的通道。
InfiniBand / RoCE:用于服务器间高速网络互联,构建大规模计算集群的关键。
三、物理与系统参数
1.功耗(TDP/TGP)2.散热设计3.外形尺寸4.接口
FP32、FP16、BF16、TF32、INT8、INT4各精度介绍:
fp16/bf16混合精度训练
量化(FP8/INT4)量化即使高精度到低精度的过程,如FP32->FP8
浮点数=符号位+指数位+小数位
符号位:表示正负
指数位:决定数值的范围(能表示多大或多小的数)
尾数位/小数位:决定数值的精度
FP32:3.1415927
FP16:3.140625 或 3.142。
BF16:3.140625 训练首选,比FP16稳定
TF32:3.1415927
FP8 (E4M3):3.125 或 3.25
INT4:3 或 4
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)