
强化学习—值函数近似
我们要首先定义目标函数,然后再不断地优化目标函数。这里S是随机变量,所以它就一定要遵守概率分布,应该是哪种呢?在这里介绍两种:首先第一种就是均匀分布,也就是我给每一个状态都赋予同样的概率,这是最简单的做法。但是也有缺点,target state 及其附近状态显示是更重要的,这种分布无法体现出状态之间的区别,第二种方法stationary distribution 能够很好的解决这个问题:到现在为止
1、Motivating examples:from table to function
到目前为止,state value和action value都是在表格里存储的:

优点就是直观、容易分析。但是缺点就是当state 和 action space特别大的时候,在存储和泛化能力方面都会有很大问题,存储问题是很直观的,泛化能力主要体现在所有的state-action pair都必须被访问,但是太多了不可能全都访问到。那么为了解决这个问题,我们就想用曲线去拟合这些values。下面我们来举几个例子:
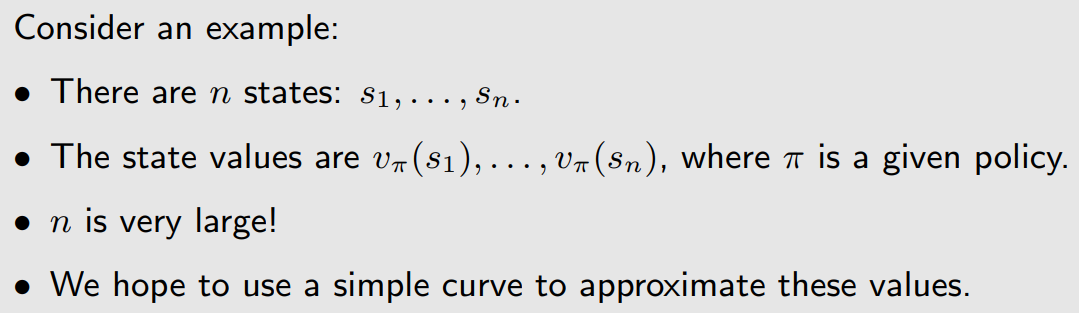
首先我们用最简单的直线来拟合:
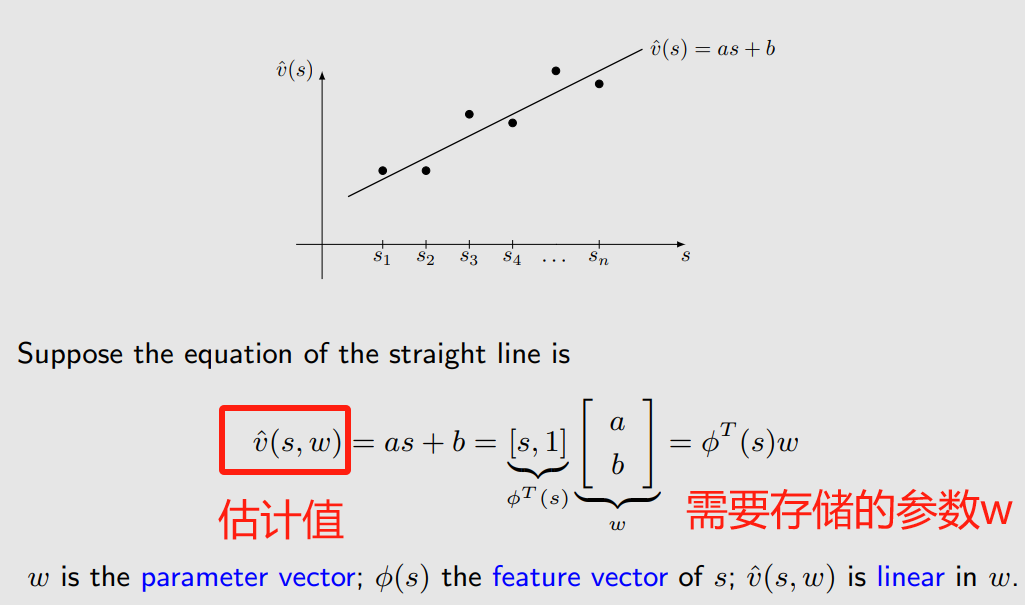

但是这样的简单曲线是很不精确的,所以我们叫它是approximation,为了更加精准,我们可以用下面更高阶的函数来拟合, 跟s不是线性的,但是跟 w 是线性的。

栗子举完了,我们来做个总结:

泛化能力具体体现在:访问一些状态s,相邻的状态也被估计了。

2、 State value estimation
2.1 Objective function(原理—目标函数介绍)

我们要首先定义目标函数,然后再不断地优化目标函数。

这里S是随机变量,所以它就一定要遵守概率分布,应该是哪种呢?在这里介绍两种:
首先第一种就是均匀分布,也就是我给每一个状态都赋予同样的概率,这是最简单的做法。

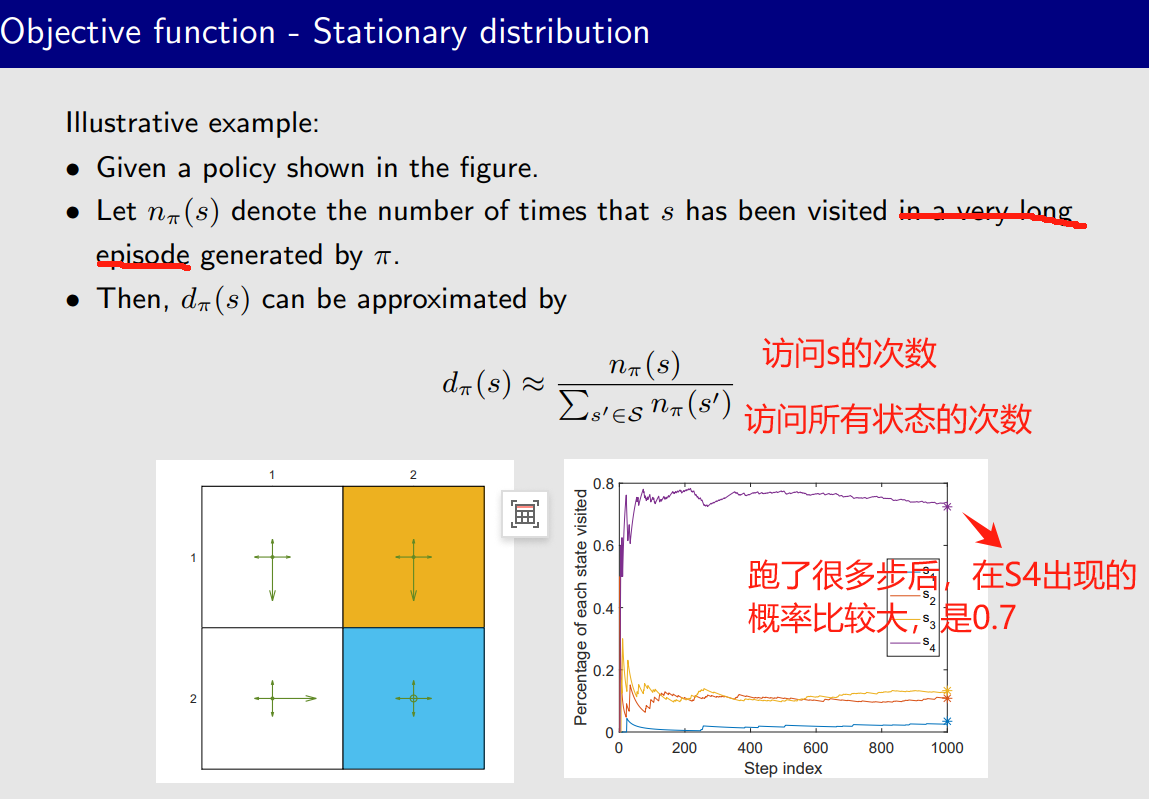
但是也有缺点,target state 及其附近状态显示是更重要的,这种分布无法体现出状态之间的区别,第二种方法stationary distribution 能够很好的解决这个问题:


下面给一个更加清晰的例子:
2.2 Optimization algorithms(原理—优化算法和函数选择)
刚刚的2.1已经提出了目标函数,那么接下来我们就要优化目标算法,第一反应就是用梯度下降或者梯度上升,这里我们是minimize 目标算法,所以用梯度下降。

但是这里要计算true gadient就要计算expectation,为了避免这个计算,我们可以用stochastic gradient 来代替true gradient:

紧接着又出现了新的问题,就是 是我们要求的量,是未知的,那么我们只能继续去想办法估计它。下面我们用到介绍过的两种model-free方法:蒙特卡洛和TD算法。

以上的优化算法就是在估计一个给定策略的state value,下面才会推广到如何得到action value,然后再推广到怎样和policy improvement 相结合,能够去搜索最优策略。
2.3 Selection of function approximators
这一节主要来介绍一下我们如何选择 ,介绍两种方法,一种是之前得到广泛使用的线性方法,一种是现在广泛使用的非线性-神经网络。

再来看一下线性的情况 :

用这个方法,理论性质可以得到很好的分析,而且它虽然不能去近似所有的函数,但是还是有很强的表征能力,但是也有缺点,很难去选择合适的特征向量,这也是被神经网络取代的原因。

2.4 故事总结
到现在为止,已经把value function approximation的思想介绍完了,从头捋一下。
首先从objective function出发,是真实的state value和估计 state value之间的函数,然后为了优化,我们用到了gradient-descent方法, 但是问题是里面有一个
我们是未知的,这时候我们又对其进行替代,这时候对应的算法就是TD-learning 和 value function approximation相结合得到的算法。(但是在数学上这种替换是不够严谨的,而且不是minimize的前面的objective function,不过理解这个大体的故事线就可以了,对后面理解算法有很大帮助。)

3、Sarsa with function approximation
刚才的第2节都在估计state value,接下来sarsa这部分我们来估计action value。第4、5节我们是估计它的optimal action value。

这个算法和TD算法一样,只是把 v 换成了q 。上述做的就是policy evaluation,那么接下来我们和policy improvement相结合,这样就可以搜索最优策略。这里和tabular sarsa唯一的区别就在于②,update的是parameter w。

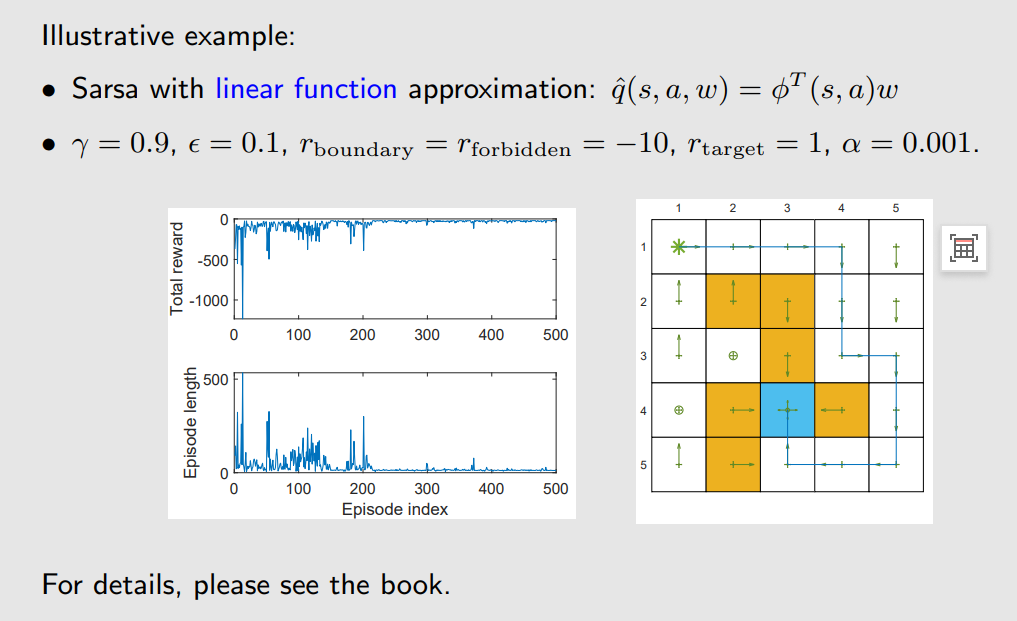
4、Q-learning with function approximation
Q-learning 与 Sarsa 唯一的区别就在下图标注,这里是maximazation,

现在给的是on-policy:

5、Deep Q-learning(DQN)
这个算法是最早的也是最成功的把深度神经网络引入到强化学习中的。为什么我们不直接用刚才说的Q-learning with function approximation,因为这时我们需要对神经网络进行非常底层的运算,计算出梯度,然后赋值,但是神经网络工具包已经很成功了,所以我们可以直接用这个简单的黑盒呀。
那么我们要训练神经网络,就需要loss/objective function,对应的就是J(w)。上节说到的Q-learning就是在求解贝尔曼最优方程,所以下面的q(s,a)和右边的expectation是相等的。当达到最优时,error应该为0,所以我们选择这个作为loss function。

下面就要进行优化, 那么我们如何去计算objective的gradient,来梯度下降呢?这也是DQN的一个贡献。 我们要计算梯度,发现右侧有两个地方含有w,第二个地方计算梯度还是比较简单的,第一个比较难。所以我们把蓝色部分结合起来看作 y ,这时J(w) 实际上就只是第二个w的函数了,这样就简单多了。

按照上面的想法,我们开始设计,首先需要两个network/function:

现在得到了objective function,接下来进行优化,先假设 固定不动,然后计算后面的对w的梯度,然后再去优化J。 这里这样理解:首先我保持
不动,然后就去更新一段时间,可以得到新的main network 的w,然后把这个赋值给
,重复下去,最终二者都收敛到最优。

所以我们得到蓝色部分的梯度,红色部分就没有梯度了 ,这就是DQN的基本思想。这里一共有两个很重要的技巧,下面介绍一下:


(S,A)的分布要是均匀分布,因为没有先验知识,不知道谁更重要,所以我们一视同仁,所有的(S,A)对应的概率都一样。

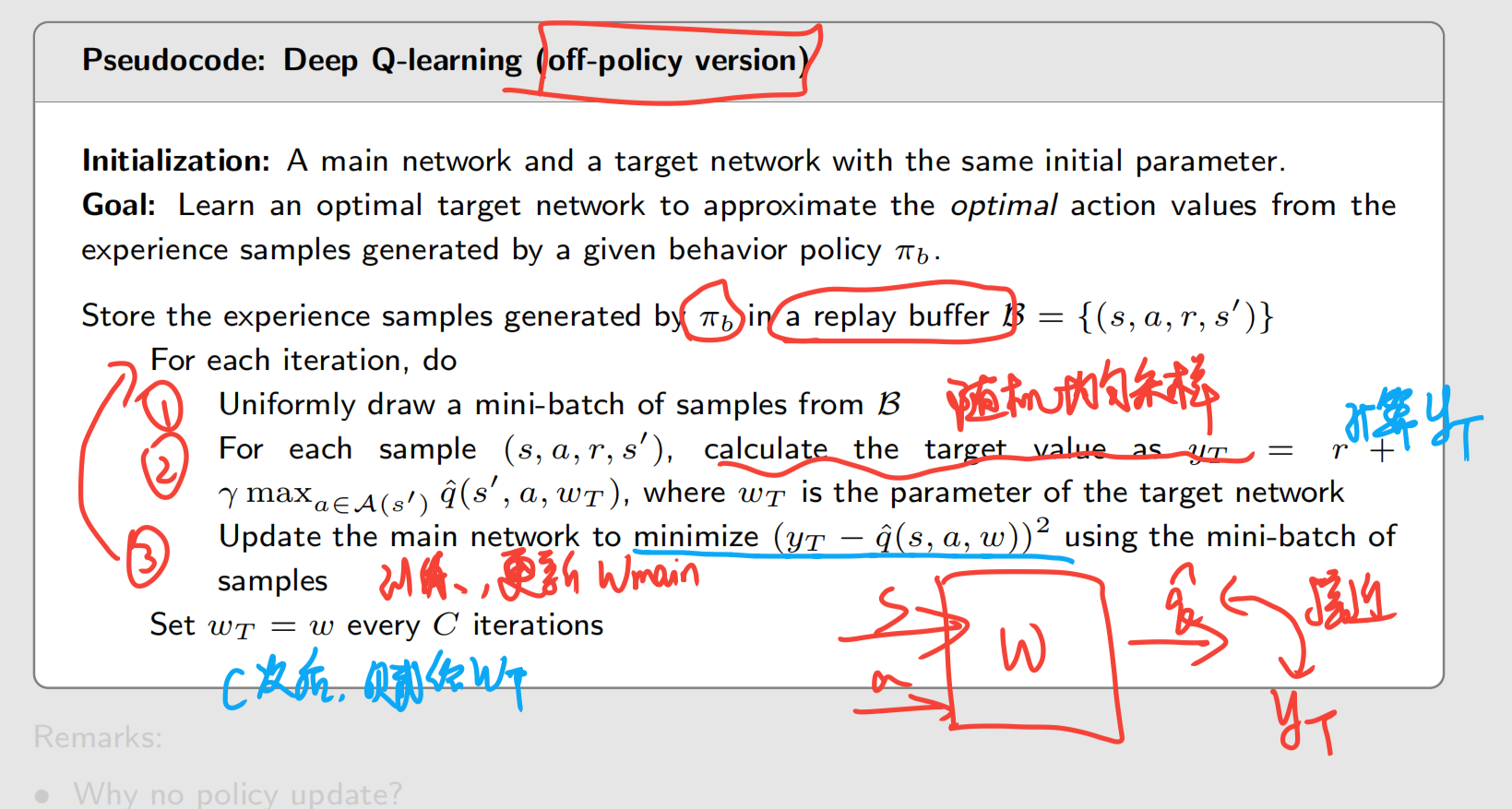
下面给出伪代码:
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)