
【跟我学YOLO】Mamba YOLO:基于状态空间模型的目标检测基线模型
Mamba YOLO目标检测模型,通过状态空间模型(SSM)替代传统Transformer的自注意力机制,显著降低计算复杂度。核心创新包括:1)设计ODMamba主干网络,采用线性复杂度SSM实现高效全局建模;2)提出RG Block模块增强通道信息提取,解决SSM在图像任务中的感受野不足问题;3)构建完整检测框架,包含Simple Stem、PAFPN颈部网络和解耦头部。
欢迎关注『跟我学 YOLO』系列
【跟我学YOLO】YOLO5 环境配置与检测
【跟我学YOLO】YOLO8 环境配置与推理检测
【跟我学YOLO】YOLO11 环境配置与基本应用
【跟我学YOLO】Mamba YOLO:基于状态空间模型的目标检测基线模型
0. 论文简介
0.1 基本信息
2024年,Wang 等在 AAAI2025 发布论文 【Mamba YOLO:基于状态空间模型的目标检测基线模型】(Mamba YOLO: A Simple Baseline for Object Detection with State Space Model)。
论文下载: AAAI, arxiv
项目地址: Github/Mamba-YOLO
引用格式: Wang, Z., Li, C., Xu, H., Zhu, X., & Li, H. (2025). Mamba YOLO: A Simple Baseline for Object Detection with State Space Model. Proceedings of the AAAI Conference on Artificial Intelligence, 39(8), 8205-8213. https://doi.org/10.1609/aaai.v39i8.32885
0.2 论文概览
设计理念
用 线性复杂度的 SSM 替代 Transformer 自注意力 降低计算负担,同时通过多模块协同优化特征提取与融合,无需大规模预训练即可高效训练。
核心架构
Mamba YOLO 由 ODMamba 主干网络和 PAFPN 颈部网络构成。
-
ODMamba主干网络
- Simple Stem模块:采用两次步长为2的3×3卷积(非传统ViT的4×4非重叠分块),平衡效率与特征保留能力。
- ODSSBlock 核心特征提取模块:整合 SS2D(全局空间建模) 与 RG Block(通道信息建模),解决 SSM 在图像任务中感受野不足、定位能力弱的问题。
SS2D(Selective-Scan-2D):通过四方向扫描(上下、左右、对角线)扩展感受野,合并全局特征;
RG Block(Residual Gated Block):
-
颈部:PAFPN(路径聚合特征金字塔网络),沿用 YOLO 系列的 PAFPN 结构,但将核心的 C2f 模块替换为 ODSSBlock
-
头部:Decoupled Head(解耦头),将颈部输出的融合特征转换为最终检测结果
0.3 摘要
受深度学习技术快速发展的推动,YOLO系列为实时目标检测器树立了新标杆。与此同时,基于Transformer的结构已成为该领域最强大的解决方案,极大地扩展了模型的感受野并实现了显著的性能提升。然而,这种改进是以牺牲计算效率为代价的——自注意力机制的二次复杂度增加了模型的计算负担。
为解决这一问题,我们提出了一种简单而有效的基线方法Mamba YOLO,其主要贡献如下:
- 在ODMamba骨干网络中引入具有线性复杂度的状态空间模型,以替代自注意力的二次复杂度。与其他基于Transformer或SSM的方法不同,ODMamba无需预训练即可直接训练;
- 为满足实时性需求,设计了ODMamba的宏观结构,确定了最优阶段比例与缩放尺寸;
- 提出RG模块,采用多分支结构对通道维度建模,以解决SSM在序列建模中可能存在的感受野受限和图像定位能力不足问题,从而更精准地捕捉局部图像依赖关系。
在公开COCO基准数据集上的大量实验表明,Mamba YOLO相较现有方法取得了最优性能。具体而言,其轻量版在单张4090 GPU上推理耗时仅1.5毫秒时,mAP指标提升达7.5%。
PyTorch代码已开源:https://github.com/HZAI-ZJNU/Mamba-YOLO
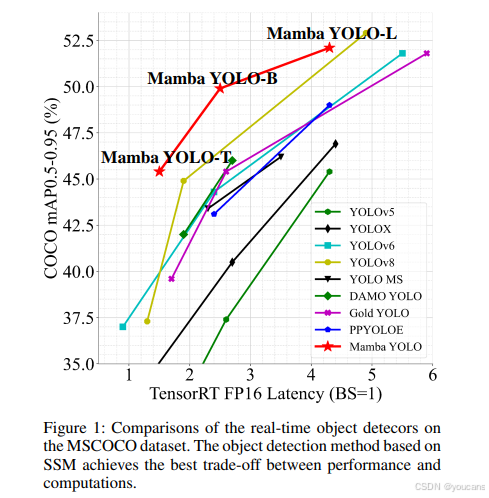
图1:在MSCOCO数据集上实时对象检测器的比较。基于SSM的方法在性能与计算量之间实现了最佳权衡。
1. 引言
近年来,深度学习发展迅猛,尤其在计算机视觉领域,一系列强大的架构取得了令人瞩目的性能。从卷积神经网络(CNNs)(Huang等,2017;Tan与Le,2020;Liu等,2022)到视觉Transformer(ViTs)(Liu等,2021;Shi,2023),各类结构的应用展现了它们在计算机视觉中的巨大潜力。在目标检测这一下游任务中,CNN(Ren等,2016;Liu等,2016)和Transformer结构(Carion等,2020;Zhang等,2022)占据主导地位。尽管CNN及其系列改进在保证精度的同时实现了较快的运行速度,但其图像关联性建模能力较弱。为应对这一问题,研究者将ViT引入目标检测领域,例如DETR系列(Carion等,2020;Zhu等,2020),利用自注意力的强大全局建模能力。随着硬件技术的进步,该结构带来的内存计算量增加已不构成主要障碍。
然而近年来越来越多研究(Liu等,2022;Zhang等,2023;Wang等,2023)开始重新思考如何设计CNN以实现更快的模型,同时更多实践者对Transformer结构的二次复杂度日益不满。研究者开始采用混合结构重构模型以降低复杂度,例如MobileViT(Mehta与Rastegari,2021)、EdgeViT(Chen等,2022)和EfficientFormer(Li等,2023)。但混合模型也带来新的挑战,其性能的明显下降令人担忧。因此,如何在性能与速度间取得平衡始终是研究者关注的重点。
最近,基于结构化状态空间模型(SSM)的方法(如Mamba(Gu与Dao,2023))为解决这些问题提供了新思路。这类方法凭借对长距离依赖的强大建模能力以及线性时间复杂度的优越特性,为计算机视觉模型设计开辟了新的方向。
本文提出了一种名为Mamba YOLO的检测器模型。
我们设计了目标检测结构化ODSSBlock模块(如图2所示),将状态空间模型应用于目标检测领域。与用于图像分类的视觉状态空间模块不同,目标检测任务通常涉及更高分辨率和像素密度的图像。考虑到状态空间模型主要面向文本序列建模设计,其本身缺乏充分利用图像通道深度的能力。为利用高分辨率图像提供的增强细节与多通道信息,我们引入了残差门控模块架构。该结构采用选择性扫描二维处理来优化输出,利用高维点积运算增强通道间关联性并提取更丰富的特征表示。我们在MSCOCO数据集上进行了详尽实验,结果表明Mamba YOLO在通用目标检测任务中展现出强大竞争力。
本文主要贡献可归纳如下:
- 提出的基于状态空间模型的Mamba YOLO具有简洁高效的结构与线性内存复杂度,且无需在大规模数据集上进行预训练,为YOLO系列在目标检测领域建立了新基线。
- 提出ODSSBlock以弥补状态空间模型在局部建模能力的不足。
通过重新设计多层感知机层结构,结合门控聚合思想与有效卷积及残差连接,构建的残差门控模块能有效捕捉局部依赖关系并增强模型鲁棒性。 - 设计了一套多尺度模型Mamba YOLO(轻量版/基础版/大型版),支持不同规模任务的部署需求。
如图1所示,在MSCOCO数据集上的实验表明,Mamba YOLO相较现有最优方法实现了显著性能提升。
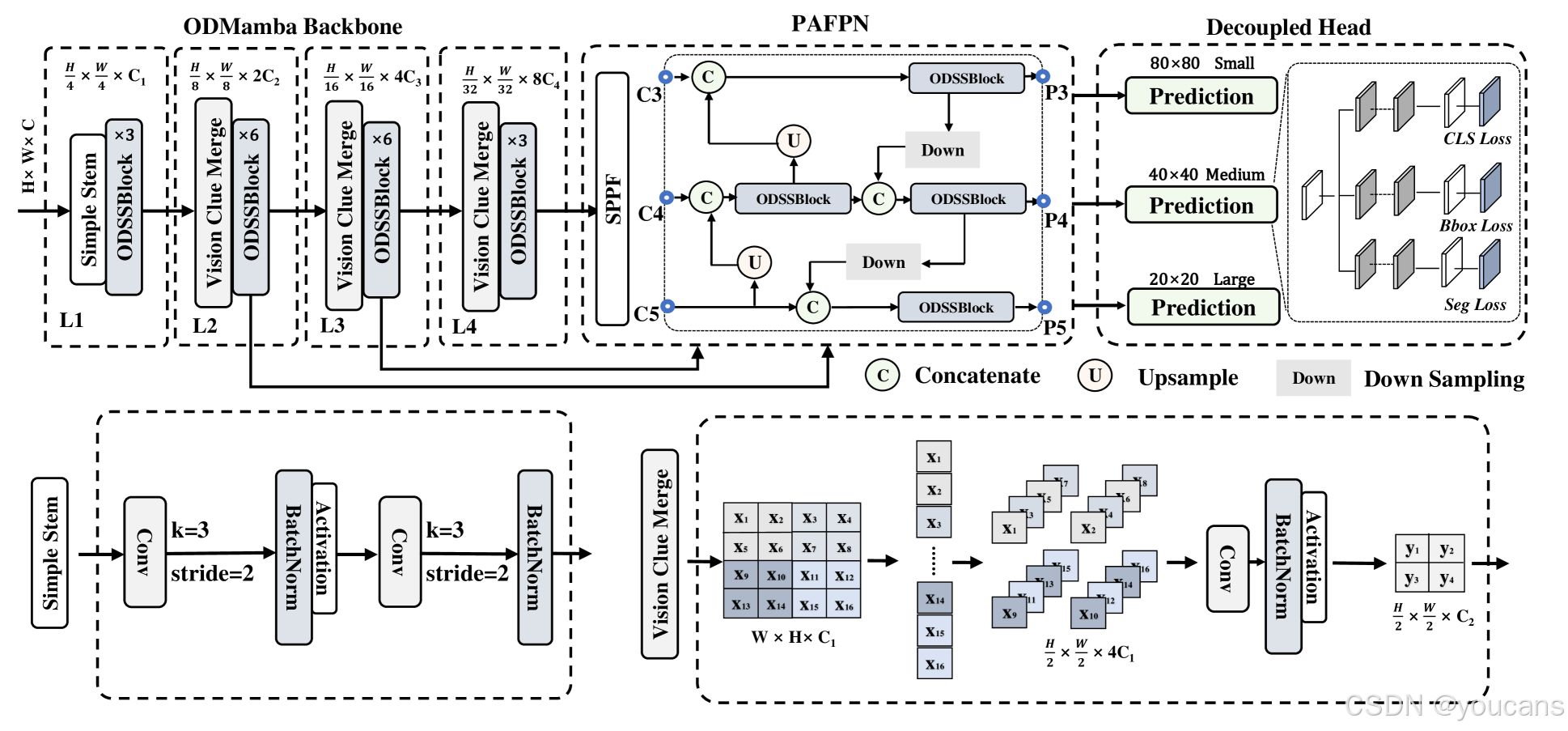
图2:Mamba YOLO架构的示例。
Mamba YOLO利用结合选择性SSM的ODSSBlock构建其骨干网络,使用Simple Stem将输入图像分割成多个 patches,并使用Vision Clue Merge进行下采样操作。从骨干网络中提取多级特征 {C3,C4,C5},然后融合到PAFPN中,ODSSBlock进一步细化和融合高层语义特征和低层空间特征,最终生成的 {P3,P4,P5} 特征输出到解耦头部以输出检测结果。
2. 相关工作
实时目标检测器
早期YOLO的性能提升与主干网络的改进密切相关,并促进了DarkNet的广泛应用。YOLOv7提出了E-ELAN结构,在不破坏原始梯度路径的前提下增强模型能力。YOLOv8综合了前几代YOLO的特性,采用具有更丰富梯度流的CSPDarknet53到两阶段特征金字塔网络结构,在兼顾精度的同时实现了轻量化与多场景适应性。近期,Gold YOLO引入了名为“收集-分发”的新机制,通过自注意力操作解决传统特征金字塔网络和Rep-PAN的信息融合问题,成功实现了最先进性能。
端到端目标检测器
DETR首次将Transformer引入目标检测领域,采用编码器-解码器架构,绕过了锚框生成与非极大值抑制等传统手工组件,将检测任务转化为直接的集合预测问题。可变形DETR引入了可变形注意力机制,通过采样参考点周围的稀疏关键点集合,解决了DETR处理高分辨率特征图的局限性。DINO融合了混合查询选择策略与可变形注意力,并通过噪声注入训练与查询优化实现了性能提升。RT-DETR提出混合编码器来解耦尺度内交互与跨尺度融合,实现了高效的多尺度特征处理。然而,DETR系列的优异性能严重依赖大规模数据集预训练,且面临训练收敛、计算成本与小目标检测等挑战,而YOLO系列仍在精度与速度兼备的轻量化建模领域保持领先地位。
视觉状态空间(VSS)模型
基于状态空间模型的研究,Mamba展现了输入尺寸的线性复杂度特性,解决了Transformer在长序列建模中的计算效率问题。在通用视觉主干领域,Vision Mamba提出了首个基于选择性状态空间模型的纯视觉主干模型。VMamba通过交叉扫描模块实现了对二维图像的选择性扫描增强,在图像分类任务中展现了优越性。LocalMamba专注于视觉空间模型的窗口扫描策略,通过优化视觉信息捕捉局部依赖关系,并引入动态扫描方法为不同层级搜索最优选择。受VMamba在视觉任务中显著成果的启发,本文首次提出Mamba YOLO这一新型状态空间模型。与传统基于状态空间模型的视觉主干不同,该模型无需在大规模数据集上进行预训练,旨在兼顾全局感受野的同时展现其在目标检测领域的潜力。
3. 方法
3.1 预备知识
基于状态空间模型的结构化状态空间序列模型S4和Mamba,均源自一个连续系统。该系统将单变量序列𝑥(𝑡)∈ℝ通过隐式潜在中间状态ℎ(𝑡)∈ℝ^𝑁映射为输出序列𝑦(𝑡)。该设计不仅建立了输入与输出之间的关联,还封装了时间动态特性。该系统可通过如下数学公式定义:
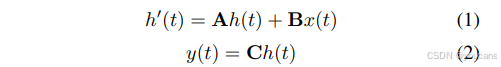
在公式(1)中, 𝐀 ∈ R ( 𝑁 × 𝑁 ) 𝐀∈ℝ^{(𝑁×𝑁)} A∈R(N×N) 表示状态转移矩阵,控制隐藏状态随时间演变的规律; 𝐁 ∈ R ( 𝑁 × 1 ) 𝐁∈ℝ^{(𝑁×1)} B∈R(N×1) 表示输入空间相对于隐藏状态的权重矩阵。此外, 𝐂 ∈ R ( 𝑁 × 1 ) 𝐂∈ℝ^{(𝑁×1)} C∈R(N×1)为观测矩阵,将隐藏中间状态映射到输出。Mamba 通过采用固定离散化规则将参数𝐀和𝐁分别转换为离散对应项 A ‾ \overline{A} A 和 B ‾ \overline{B} B,从而将此连续系统应用于离散时间序列数据,使其更好地融入深度学习架构。为此常用的离散化方法是零阶保持法,其离散化形式定义如下:
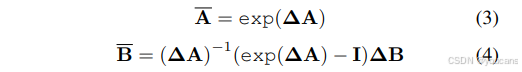
在公式(4)中,𝚫 表示时间尺度参数,用于调节模型的时间分辨率;𝚫𝐀和𝚫𝐁分别对应给定时间区间内连续参数的离散时间形式。此处 𝐈 表示单位矩阵。经过转换后,模型通过线性递归形式进行计算,定义如下:
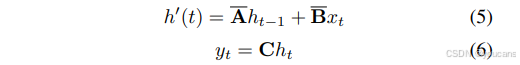
整个序列变换也可用卷积形式表示,定义如下:
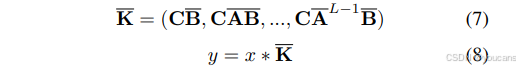
其中 𝐊 ˉ ∈ R 𝐿 𝐊̄∈ℝ^𝐿 Kˉ∈RL表示结构化卷积核,𝐋代表输入序列的长度。在本文提出的设计中,模型采用卷积形式进行并行训练,并利用线性递归公式实现高效的自回归推理。
3.2 整体架构
Mamba YOLO的架构概览如图2所示。
我们的目标检测模型分为ODMamba主干网络和颈部网络两部分。ODMamba由简易初始模块和下采样块构成。在颈部网络中,我们沿用PAFPN的设计思路,使用ODSSBlock模块替代C2f模块以捕捉更丰富的梯度信息流。
主干网络首先通过初始模块进行下采样,得到分辨率为H/4×W/4的二维特征图。随后,所有模型均采用ODSSBlock后接视觉线索融合模块的级联结构进行进一步下采样。
在颈部网络中,我们采用PAFPN架构设计,使用ODSSBlock替换C2f模块,其中卷积层仅负责下采样操作。
-
简易初始模块
现代视觉Transformer通常采用分块机制作为初始模块,将图像划分为非重叠的图块。这种划分过程通过核尺寸为4、步长为4的卷积操作实现。然而近期研究(如EfficientFormerV2)表明,这种方法可能限制视觉Transformer的优化能力,影响整体性能。为平衡性能与效率,我们提出了一种精简的初始层结构。采用两个核尺寸为3、步长为2的卷积层替代传统的非重叠分块方式。 -
视觉线索融合模块
虽然卷积神经网络和视觉Transformer结构通常采用卷积进行下采样,但我们发现这种方法会干扰选择性扫描二维操作在不同信息流阶段的选择性运算。为此,VMamba通过拆分二维特征图并使用1×1卷积进行降维处理。我们的实验表明,为状态空间模型保留更多视觉线索有利于模型训练。
相较于传统的维度减半方法,我们通过以下步骤简化该过程:
- 移除归一化层
- 拆分维度映射
- 将多余特征图附加至通道维度
- 使用4倍压缩的逐点卷积进行下采样
与使用步长为2的3×3卷积不同,我们的方法保留了上一层经选择性扫描二维操作筛选的特征图。
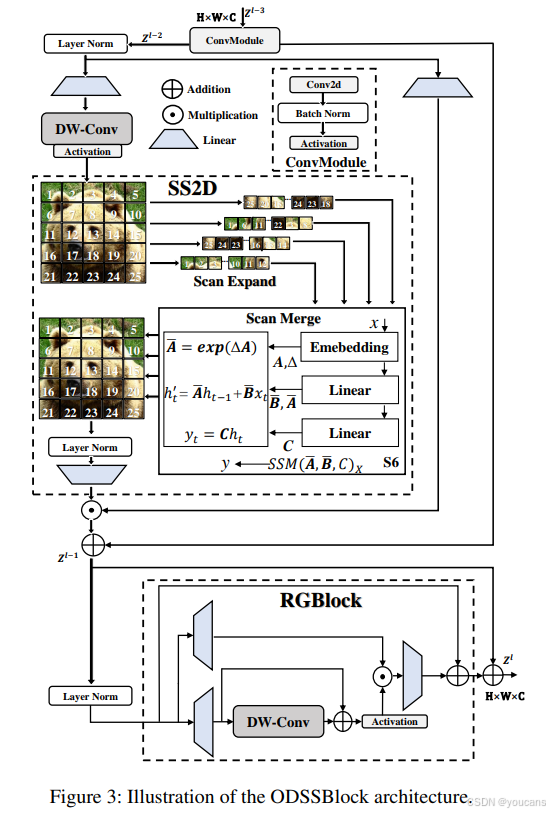
图3:ODSSBlock架构的示例。
3.3 ODSSBlock
如图3所示,ODSSBlock是Mamba YOLO的核心模块。
在输入阶段,它经过一个卷积模块,使网络能够学习更深层次、更丰富的特征表示。假设输入特征 𝑍 ( 𝑙 − 3 ) 𝑍^{(𝑙−3)} Z(l−3)的维度为 R ( 𝐶 × 𝐻 × 𝑊 ) ℝ^{(𝐶×𝐻×𝑊)} R(C×H×W),则有:
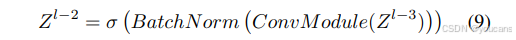
其中σ表示激活函数(非线性SiLU)。ODSSBlock的层归一化与残差连接设计借鉴了Transformer块的结构风格,使得模型在深度堆叠时仍能保持高效的信息流动与训练稳定性。
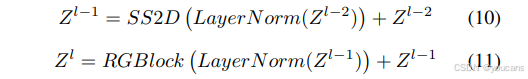
ODSSBlock可解耦为两个独立的功能组件:选择性扫描二维(·)负责全局空间信息传播,残差门控块(·)负责通道信息传播,其中 𝑍 ( 𝑙 − 1 ) 𝑍^{(𝑙−1)} Z(l−1)表示经过选择性扫描二维处理后的中间状态。
选择性二维扫描(SS2D)
扫描扩展、S6块和扫描合并是选择性扫描二维算法的三个主要步骤,其流程如图3所示。扫描扩展操作将输入图像扩展为一系列子图像,每个子图像代表特定方向。从对角线视角观察时,扫描扩展操作沿四个对称方向进行:自上而下、自下而上、从左到右和从右到左。这种布局不仅全面覆盖输入图像的所有区域,还通过系统的方向变换为后续特征提取提供丰富的多维信息基础,从而提升图像特征多维捕捉的效率与全面性。选择性扫描二维中的扫描合并操作将获得的序列输入S6块进行处理,并将不同方向的序列合并,使特征提取提升至全局特征层面。
残差门控块(RG)
原始多层感知机仍是应用最广泛的结构,VMamba架构中的多层感知机也遵循Transformer设计,通过对输入序列进行非线性变换以增强模型表达能力。近期研究表明,门控多层感知机在自然语言处理中表现出强大性能,我们发现门控机制在视觉领域同样具有潜力。如图3所示,本文提出的残差门控块采用简洁设计,旨在以较低计算成本提升模型性能。该模块从输入 𝑓 𝐴 ′ 𝑓^′_𝐴 fA′和 𝑓 B ′ 𝑓^′_B fB′创建两个分支,分别保留全局与局部信息,其中 𝒯 ( ⋅ ) 𝒯(·) T(⋅) 表示线性层。
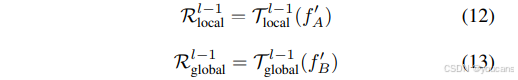
深度可分离卷积作为位置编码模块应用于 R g l o b a l ( 𝑙 − 1 ) ℛ_{global}^{(𝑙−1)} Rglobal(l−1)分支,通过残差连接在训练期间实现更高效的梯度回流。该设计以较低计算成本显著提升性能,同时保留并利用图像的空间结构信息。残差门控块采用非线性GeLU作为激活函数,控制各层级的信息流动。 𝒴 ( 𝑥 ) 𝒴(𝑥) Y(x) 过程可表述为:
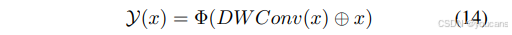
通过 𝒴 ( 𝑥 ) 𝒴(𝑥) Y(x) 处理的局部信息与 R g l o b a l ( 𝑙 − 1 ) ℛ_{global}^{(𝑙−1)} Rglobal(l−1) 的全局信息相乘,全局特征经过线性层细化以融合局部通道信息,并通过残差连接与原始输入 𝑓 𝐴 ′ 𝑓^′_𝐴 fA′ 及隐藏层特征相加。残差门控块在仅轻微增加计算成本的情况下捕获更多全局与局部特征,其输出特征 𝑓 𝑅 𝐺 𝑓_{𝑅𝐺} fRG定义如下:
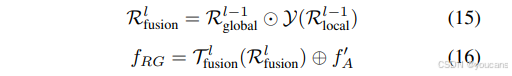
其中Φ表示激活函数(非线性GeLU)。本文中,残差门控块的门控机制通过集成卷积操作保留空间信息,同时使模型对图像中的细粒度特征更加敏感。与传统的多层感知机相比,残差门控块将全局依赖关系与全局特征传递至每个像素,以捕捉相邻特征的依赖关系,这使得上下文信息更加丰富,从而进一步增强模型的表达能力。
4. 实验
本节针对目标检测任务对Mamba YOLO进行了全面实验。我们使用MSCOCO数据集验证所提出的Mamba YOLO的优越性,并与最先进方法进行比较。所有模型均在8张NVIDIA H800 GPU上进行训练。
4.1 与现有最优方法的比较
表1展示了在MSCOCO验证集上的实验结果,表明我们提出的方法在FLOPs、参数量、精度以及实测GPU延迟之间取得了最佳综合权衡。具体而言,相较于高性能微型轻量化模型PPYOLOE-S/YOLO-MS-XS,Mamba YOLO-T的AP指标分别显著提升1.1%/1.5%,同时GPU推理延迟降低0.9毫秒/0.2毫秒。与精度相近的基准模型YOLOv8-S相比,Mamba YOLO-T的参数量减少48%,FLOPs降低53%,GPU推理延迟下降0.4毫秒。
在参数量和FLOPs相近的情况下,Mamba YOLO-B相较Gold-YOLO-M实现了3.7%的AP增益。即使与精度相当的PPYOLOE-M对比,Mamba YOLO-B仍将参数量减少18%,FLOPs降低9%,GPU推理延迟下降1.8毫秒。对于更大规模的模型,Mamba YOLO-L在所有先进目标检测器中也取得了更优或相当的性能表现。与当前表现最佳的Gold-YOLO-L相比,Mamba YOLO-L在参数量减少0.9%的同时,AP提升0.3%。如表示所示,采用从头训练方法的Mamba YOLO-T在所有训练方式中表现最为突出。
此外,图4对比了Mamba YOLO-L与DINO-R50在帧率(FPS)和GPU内存占用方面的表现。结果表明,在更高分辨率下Mamba YOLO-L仍能保持更优的精度与速度,其内存效率和FLOPs呈线性增长趋势。这些对比结果证明,在不同尺度的Mamba YOLO模型中,我们所提出的方法相较现有最先进技术均具有显著优势。
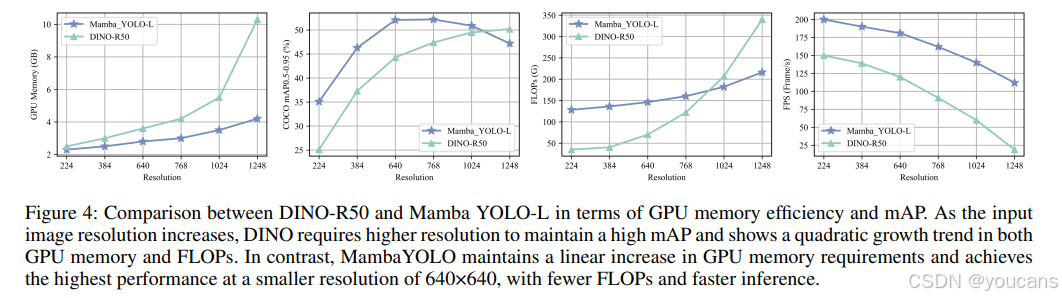
图4:DINO-R50与Mamba YOLO-L在GPU内存效率和mAP方面的比较。
随着输入图像分辨率的增加,DINO需要更高的分辨率以保持高mAP,并且在GPU内存和FLOPs方面均表现出二次增长的趋势。相比之下,Mamba YOLO在640×640的较小分辨率下保持GPU内存需求的线性增长,并以较少的FLOPs和更快的推理速度实现最高性能。
4.2 Mamba YOLO消融实验
本节我们对ODSSBlock中的各个模块进行独立研究,并在不使用视觉线索融合模块的情况下,通过传统卷积下采样来评估该模块对精度的影响。消融实验在MSCOCO数据集上使用Mamba YOLO-T模型进行。表2的实验结果表明:线索融合机制为状态空间模型保留了更多视觉线索,同时验证了ODSSBlock结构的最优性论断。
4.3 RG Block结构消融实验
RG Block通过逐像素获取全局依赖关系与全局特征,以捕捉像素级的局部依赖关系。该模块采用多分支结构对通道维度进行建模,解决了状态空间模型在序列建模中可能存在的感受野不足与图像定位能力弱等局限性。关于RG Block的设计细节,我们还考虑了三种变体:
- 卷积MLP:在原始MLP基础上增加深度可分离卷积
- 残差卷积MLP:以残差连接方式在原始MLP中加入深度可分离卷积
- 门控MLP:基于门控机制设计的MLP变体
图6展示了这些变体结构,表3呈现了原始MLP、RG Block及各变体在MSCOCO数据集上的性能表现(测试模型为Mamba YOLO-T),以验证我们对MLP分析的有效性。我们观察到,单独引入卷积并不能带来有效的性能提升;而在图6所示的门控MLP变体中,其输出由两个逐元素相乘的线性投影组成,其中一个投影包含残差连接的深度可分离卷积与门控激活函数。这种设计实际上赋予了模型通过层级结构传播重要特征的能力,有效提升了模型的精度与鲁棒性。本实验表明,在处理复杂图像任务时,引入卷积的性能改进与门控聚合机制密切相关,且需在残差连接的框架下应用方能发挥最佳效果。
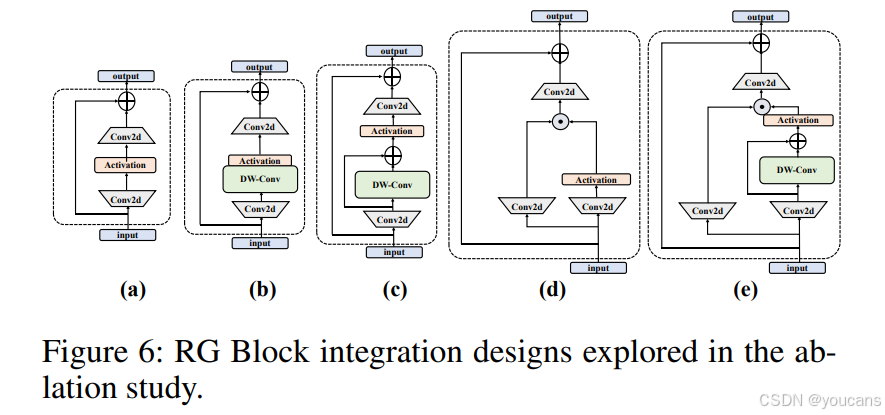
图6:消融研究中探索的RG Block集成设计。
4.4 Mamba YOLO变体参数设置的消融研究
我们探究了主干网络中ODSSBlock重复次数的四种不同配置方案:
- 9,3,3,3]会增加额外计算开销,但并未带来相应程度的精度提升
- [3,9,3,3]、[3,3,9,3]和[3,3,3,9]则因ODSSBlock过度重复而存在冗余
实验证明,[3,6,6,3]是Mamba YOLO中更合理的配置方案。
在颈部网络部分,虽然移除ODSSBlock可以实现更轻量化模型,但这会不可避免地降低模型精度,而保留该模块能提供丰富的梯度流与特征融合能力。选择输出特征图为{P2,P3,P4,P5}的变体可显著提升精度,但不可避免地大幅增加GFLOPs。
Mamba YOLO最终选定Blocks=[3,6,6,3]、特征图={P3,P4,P5}的配置,并在颈部网络中使用ODSSBlock。该配置在精度与复杂度之间取得了更优的平衡,更适合高效执行实例分割任务。具体结果如表4所示。
表4:Mamba YOLO变体中值设置类型的消融研究。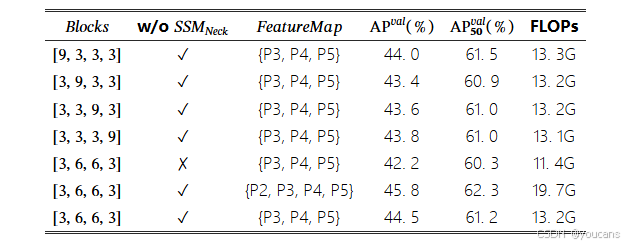
4.5 可视化分析
为进一步确认我们所提检测框架的优势,我们从MSCOCO数据集中随机选取了两个样本进行可视化分析。图5展示了各主流检测器与Mamba YOLO的可视化对比结果。可以看出,Mamba YOLO能够在多种困难场景下实现精确检测,在面对高度重叠、严重遮挡的物体以及复杂背景时均表现出强大的检测能力。

图5:各检测器在COCO数据集上的推理结果。为了更好地展示,详细对象已被放大。
5. 结论
本文提出了一种基于状态空间模型设计、并继承YOLO框架扩展的检测器,其训练过程显著简化,无需依赖大规模数据集的预训练。我们重新分析了传统多层感知机的局限性,提出了残差门控块结构,其门控机制与深度卷积残差连接的设计赋予模型在层级结构中传播重要特征的能力。我们的目标是建立YOLO系列的新基准,证明Mamba YOLO具有高度竞争力。本工作是首次将Mamba架构应用于实时目标检测任务的探索,我们也希望能为该领域的研究者带来新的思路。
6. Github 项目介绍
项目地址:github

6.1 预训练模型
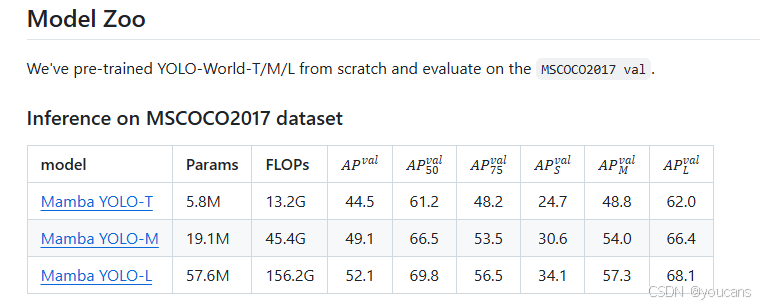
6.2 AutoMorph 快速入门
-
安装环境
Mamba YOLO 基于 torch2.3.0、pytorch-cuda12.1 和 CUDA Version==12.6 开发。 -
克隆项目
git clone https://github.com/HZAI-ZJNU/Mamba-YOLO.git
- 创建并激活 conda 环境
conda create -n mambayolo -y python=3.11
conda activate mambayolo
- 安装 torch
pip3 install torch===2.3.0 torchvision torchaudio
- 安装依赖库
pip install seaborn thop timm einops
cd selective_scan && pip install . && cd ..
pip install -v -e .
- 准备 MSCOCO2017 数据集
确保数据集结构如下:
├── coco
│ ├── annotations
│ │ ├── instances_train2017.json
│ │ └── instances_val2017.json
│ ├── images
│ │ ├── train2017
│ │ └── val2017
│ ├── labels
│ │ ├── train2017
│ │ ├── val2017
- 训练 Mamba-YOLO-T
python mbyolo_train.py --task train --data ultralytics/cfg/datasets/coco.yaml \
--config ultralytics/cfg/models/mamba-yolo/Mamba-YOLO-T.yaml \
--amp --project ./output_dir/mscoco --name mambayolo_n
7. 参考文献
Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov,A.; and Zagoruyko, S. 2020. End-to-End Object Detectionwith Transformers. arXiv:2005.12872.
Chen, Y.; Yuan, X.; Wu, R.; Wang, J.; Hou, Q.; andCheng, M.-M. 2023. YOLO-MS: Rethinking Multi-ScaleRepresentation Learning for Real-time Object Detection. arXiv:2308.05480.
Chen, Z.; Zhong, F.; Luo, Q.; Zhang, X.; and Zheng, Y. 2022. Edgevit: Efficient visual modeling for edge comput ing. In International Conference on Wireless Algorithms,Systems, and Applications, 393–405. Springer.
Dauphin, Y. N.; Fan, A.; Auli, M.; and Grangier, D. 2017. Language Modeling with Gated Convolutional Networks. arXiv:1612.08083.
Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei Fei, L. 2009. Imagenet: A large-scale hierarchical imagedatabase. In 2009 IEEE conference on computer vision andpattern recognition, 248–255. Ieee.
Gu, A.; and Dao, T. 2023. Mamba: Linear-Time SequenceModeling with Selective State Spaces. arXiv:2312.00752.
Gu, A.; Goel, K.; and Re, C. 2022. Efficiently Mod- ´eling Long Sequences with Structured State Spaces. arXiv:2111.00396.
Gu, A.; Johnson, I.; Goel, K.; Saab, K.; Dao, T.; Rudra, A.;and Re, C. 2021. Combining Recurrent, Convolutional, and ´Continuous-time Models with Linear State-Space Layers. arXiv:2110.13985.
Huang, G.; Liu, Z.; van der Maaten, L.; and Weinberger,K. Q. 2017. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition.
Huang, T.; Pei, X.; You, S.; Wang, F.; Qian, C.; and Xu, C. 2024. LocalMamba: Visual State Space Model with Win dowed Selective Scan. arXiv:2403.09338.
Jocher, G.; Chaurasia, A.; and Qiu, J. 2023. UltralyticsYOLO.
Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.;Li, Q.; Cheng, M.; Nie, W.; et al. 2022. YOLOv6: A single stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976.
Li, Y.; Hu, J.; Wen, Y.; Evangelidis, G.; Salahi, K.; Wang, Y.;Tulyakov, S.; and Ren, J. 2023. Rethinking Vision Trans formers for MobileNet Size and Speed. In Proceedings ofthe IEEE international conference on computer vision.
Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; ´and Belongie, S. 2017. Feature pyramid networks for ob ject detection. In Proceedings of the IEEE conference oncomputer vision and pattern recognition, 2117–2125.
Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick,R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C. L.; andDollar, P. 2015. Microsoft COCO: Common Objects in Con- ´text. arXiv:1405.0312.
Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu,C.-Y.; and Berg, A. C. 2016. SSD: Single Shot MultiBoxDetector, 21–37. Springer International Publishing. ISBN9783319464480.
Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye,Q.; and Liu, Y. 2024. VMamba: Visual State Space Model. arXiv preprint arXiv:2401.10166.
Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin,S.; and Guo, B. 2021. Swin Transformer: Hierarchical Vi sion Transformer using Shifted Windows. In Proceedingsof the IEEE/CVF International Conference on Computer Vi sion (ICCV).
Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.;and Xie, S. 2022. A ConvNet for the 2020s.
Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.;Shen, H.; Ren, J.; Han, S.; Ding, E.; et al. 2020. PP-YOLO:An effective and efficient implementation of object detector. arXiv preprint arXiv:2007.12099.
Mehta, S.; and Rastegari, M. 2021. Mobilevit: light-weight,general-purpose, and mobile-friendly vision transformer. arXiv preprint arXiv:2110.02178.
Rajagopal, A.; and Nirmala, V. 2021. Convolutional GatedMLP: Combining Convolutions gMLP. arXiv:2111.03940.
Ren, S.; He, K.; Girshick, R.; and Sun, J. 2016. FasterR-CNN: Towards Real-Time Object Detection with RegionProposal Networks. arXiv:1506.01497.
Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.;Li, J.; and Sun, J. 2019. Objects365: A large-scale, high quality dataset for object detection. In Proceedings ofthe IEEE/CVF international conference on computer vision,8430–8439.
Shi, D. 2023. TransNeXt: Robust Foveal Visual Perceptionfor Vision Transformers. arXiv:arXiv:2311.17132.
Smith, J. T. H.; Warrington, A.; and Linderman, S. W. 2023. Simplified State Space Layers for Sequence Mod eling. arXiv:2208.04933.
Tan, M.; and Le, Q. V. 2020. EfficientNet: Rethinking ModelScaling for Convolutional Neural Networks.
Wang, A.; Chen, H.; Lin, Z.; Pu, H.; and Ding, G. 2023. Repvit: Revisiting mobile cnn from vit perspective. arXivpreprint arXiv:2307.09283.
Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; andHan, K. 2024. Gold-YOLO: Efficient object detector viagather-and-distribute mechanism. Advances in Neural In formation Processing Systems, 36.
Wang, C.-Y.; Bochkovskiy, A.; and Liao, H.-Y. M. 2023. YOLOv7: Trainable bag-of-freebies sets new state-of-the art for real-time object detectors. In Proceedings ofthe IEEE/CVF conference on computer vision and patternrecognition, 7464–7475.
Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni,L. M.; and Shum, H.-Y. 2022. DINO: DETR with ImprovedDeNoising Anchor Boxes for End-to-End Object Detection. arXiv:2203.03605.
Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang,Z.; Huang, T.; Wang, Y.; and Wang, C. 2023. Rethink ing mobile block for efficient attention-based models. In2023 IEEE/CVF International Conference on Computer Vi sion (ICCV), 1389–1400. IEEE Computer Society.
Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu,Y.; and Chen, J. 2023. DETRs Beat YOLOs on Real-timeObject Detection. arXiv:2304.08069.
Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; and Wang,X. 2024. Vision Mamba: Efficient Visual RepresentationLearning with Bidirectional State Space Model. arXivpreprint arXiv:2401.09417.
Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; and Dai, J. 2020. Deformable DETR: Deformable Transformers for End-to End Object Detection. arXiv preprint arXiv:2010.04159
【本节完】
本文由 youcans@xidian 对论文 Mamba YOLO: A Simple Baseline for Object Detection with State Space Model 进行摘编和翻译。该论文版权属于原文期刊和作者,译文只供研究学习使用。
引用格式: Wang, Z., Li, C., Xu, H., Zhu, X., & Li, H. (2025). Mamba YOLO: A Simple Baseline for Object Detection with State Space Model. Proceedings of the AAAI Conference on Artificial Intelligence, 39(8), 8205-8213. https://doi.org/10.1609/aaai.v39i8.32885
版权声明:
youcans@xidian 作品,转载必须标注原文链接:
【跟我学YOLO】Mamba YOLO:基于状态空间模型的目标检测基线模型(https://youcans.blog.csdn.net/article/details/155461540)
Copyright 2025 by youcans@Xidian
Crated:2025-12
更多推荐

 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)