
2025年RAG实战手册:零基础构建知识库与智能问答系统,程序员必学指南!
本文全面介绍RAG技术原理与实战开发,涵盖核心基础、架构设计、开发流程及部署优化。采用Cloudflare无服务器架构,集成千问与Gemini模型,指导读者从零构建知识库与智能问答系统,适合不同技术背景开发者学习应用。
简介
本文全面介绍RAG技术原理与实战开发,涵盖核心基础、架构设计、开发流程及部署优化。采用Cloudflare无服务器架构,集成千问与Gemini模型,指导读者从零构建知识库与智能问答系统,适合不同技术背景开发者学习应用。
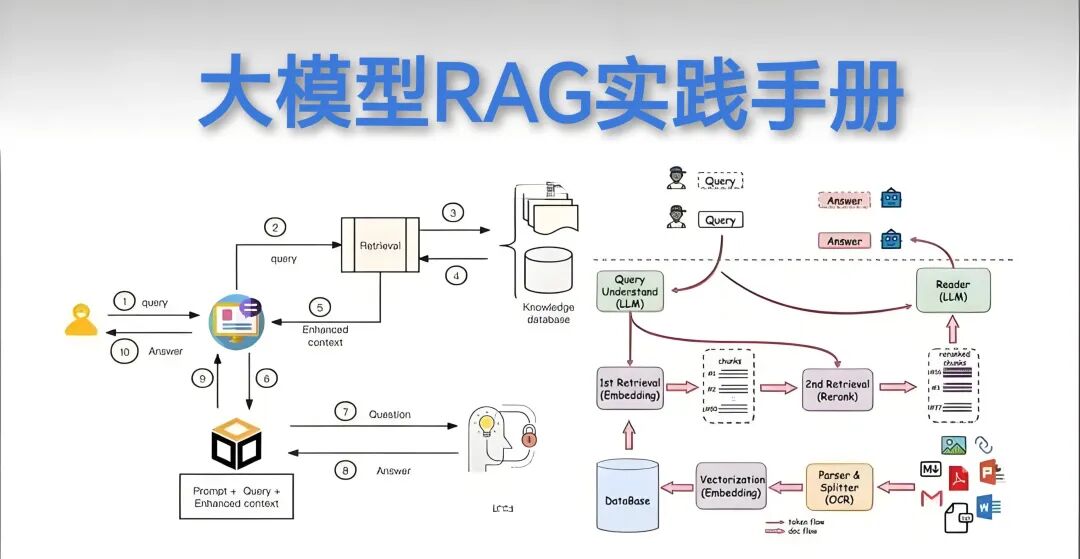
“2025年RAG实践手册:构建知识库和问答系统的实战指南”和“字节跳动RAG实践手册(2025)”,旨在帮助读者从零构建基于 RAG 技术的知识库与智能问答系统(如聊天机器人),并实现多场景部署与优化。
一、核心基础与原理
RAG 核心定义:即检索增强生成技术,通过结合外部知识库检索与生成式 AI,解决传统大语言模型知识截止、幻觉、领域专业性不足、个性化缺失等问题,尤其适合构建个人数字分身。
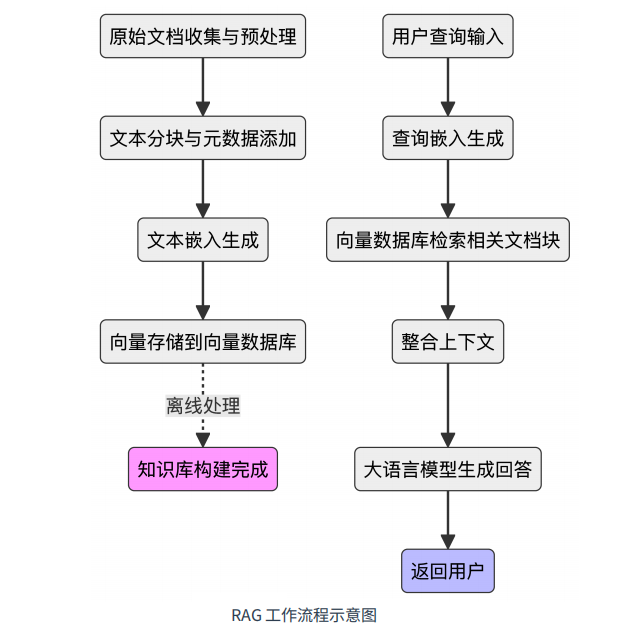
核心流程:分离线知识库构建与实时查询响应两阶段。前者含文档收集预处理、分块、嵌入生成向量并存储到向量数据库;后者将用户问题向量化后检索相关文档,整合上下文后交由大语言模型生成回答。
RAG 分类:包括 Naive RAG(基础三步流程,减少幻觉)、Advanced RAG(多阶段处理提升检索与生成质量,手册示例属此类)、Modular RAG(模块化拆分支持灵活扩展)、Agentic RAG(多智能体架构,动态决策处理复杂任务)。
二、技术栈与架构设计
整体架构:采用无服务器架构,分数据源层、数据处理层、存储层、计算层、AI 服务层、展示层,数据流程含离线数据摄取(Markdown 文档处理、向量生成存储)与实时对话交互(用户查询处理、向量检索、回答生成)。
核心技术栈
- 后端:Cloudflare Workers(边缘计算,低延迟、自动扩缩容)、Cloudflare Vectorize(向量数据库,存储与检索向量),开发语言为 TypeScript。
- AI 模型:支持千问(Qwen,中文处理佳、成本低)与 Gemini(多模态适配),嵌入模型可选千问 text-embedding-v4、Gemini text-embedding-004 等。
- 前端:Widget.js(轻量聊天界面,支持 Markdown 渲染)、Hugo(静态网站生成器)。
- Vectorize 关键特性:无缝集成 Cloudflare 生态,支持元数据索引与命名空间管理,自动优化索引,按查询与存储维度计费,适合快速部署扩展。
三、实战开发流程
环境准备:需 Node.js 20+、Wrangler CLI,申请千问 / Gemini API 密钥,配置 Cloudflare(注册账号、创建 Vectorize 索引与元数据索引、初始化项目并配置环境变量)。
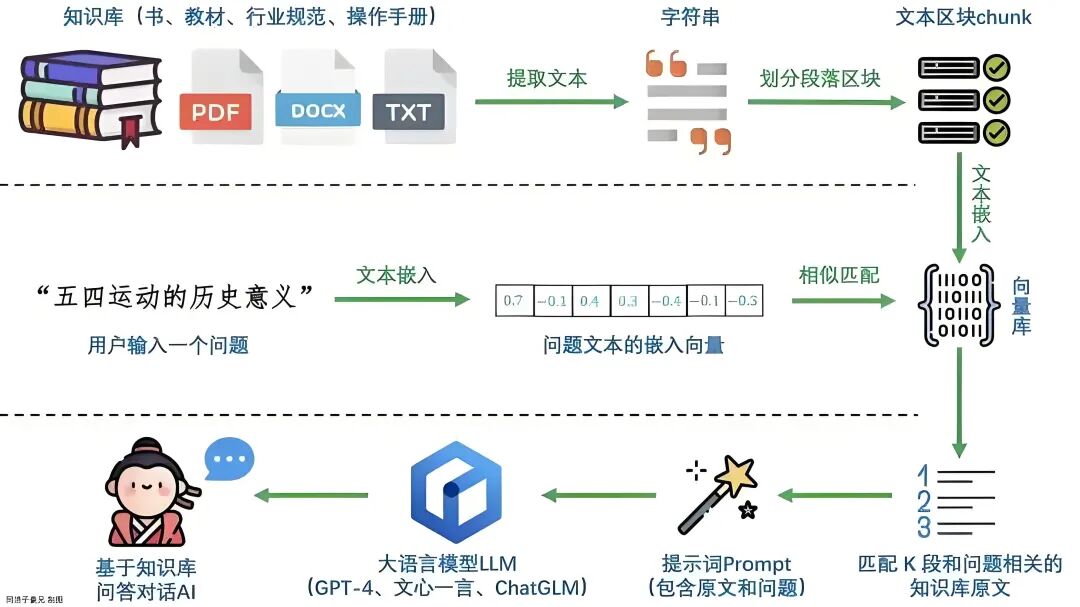
知识库构建:选择个人博客、专业文档等数据源,通过脚本自动化收集 Hugo 网站 Markdown 文档(跳过草稿、处理多语言目录),并规范元数据。
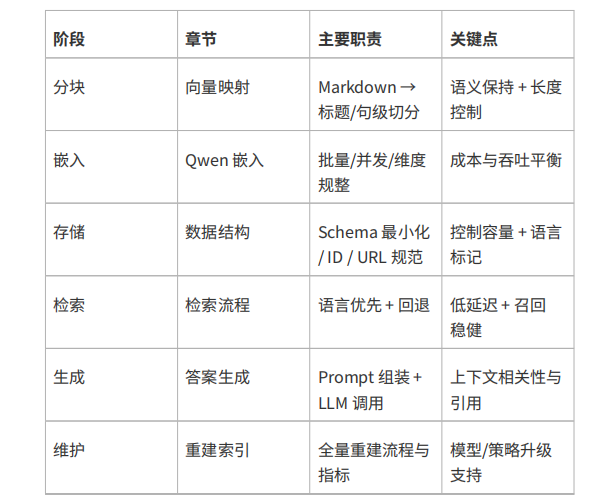
数据处理与向量化:解析 Markdown 文档并按标题、句末标点分块(控制长度≤800 字符),生成短 ID(基于文档路径、块索引等确保唯一可追溯),调用嵌入模型批量生成向量,规整维度后批量上传至 Vectorize,同时设计元数据(含文本、标题、URL 等关键字段,控制大小)。
检索与问答实现:检索阶段采用 “语言优先 + 回退” 策略(优先按语言元数据过滤检索,失败则全量检索后按 URL 二次过滤),优化查询参数(如 topK、返回数据控制);集成大语言模型(配置 API、设计提示词、调优参数),构建含上下文的提示词生成回答;开发聊天机器人核心逻辑,含对话流程设计、上下文管理(向量检索上下文与对话历史管理)、异常处理(API 错误、超时回退)。
四、扩展与部署优化
多语言支持:客户端检测语言(URL 路径优先),Ingestion 阶段写入语言元数据,检索阶段两级过滤,Prompt 构建按语言分支,前端本地化渲染。
部署与迁移:基于 Cloudflare 部署(配置 Workers 路由与环境变量、设置 Vectorize 索引、本地测试后生产部署),提供全量重索引迁移指南(含迁移动因、环境准备、操作流程)。
测试与监控:开展单元测试、集成测试验证功能,监控模型调用(次数、延迟)、流量与向量存储情况,收集用户反馈迭代优化。
问题解决方案:涵盖对话连贯性与检索准确性平衡(分离当前问题检索与历史对话提示构建)、文档与向量 ID 关联(固定生成规则)、Vectorize 使用问题(维度匹配、查询空结果排查、性能优化)等常见问题。
“”适合 AI 技术初学者、有基础的开发者、需构建专属知识库的企业 / 个人及关注知识管理的自媒体人等,读者无需深厚 AI 背景,掌握基础编程与 Markdown 即可学习。通过手册,可掌握 RAG 技术核心原理与开发流程,低成本构建个性化智能聊天机器人,应用于知识管理、个人品牌建设等场景。
五、如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐

 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)