
GitHub39.4k Star, 可训练25.8M极简语言模型MiniMind项目架构设计
MiniMind这个开源仓库很适合学习,也有小伙伴私信要求讲一下这个开源项目的架构设计,今天分享给大家.

大家好! 上周我们分享MiniMind的介绍:
仅用3元成本2小时即可训练出仅为25.8M的超小语言模型库
MiniMind这个开源仓库很适合学习,也有小伙伴私信要求讲一下这个开源项目的架构设计,今天分享给大家.
🔥项目信息
项目名称:MiniMind (极简语言模型)
GitHub 链接:https://github.com/jingyaogong/minimind
社区认可度:⭐39.4k+Star
🚀架构设计
MiniMind 是一款极致轻量化的大语言模型(LLM),核心分为 Dense(稠密) 和 MoE(混合专家) 两大架构分支,整体基于 Transformer Decoder-Only 结构,同时针对轻量化场景做了针对性优化,以下是其核心架构设计细节:
MiniMind整体目录结构:
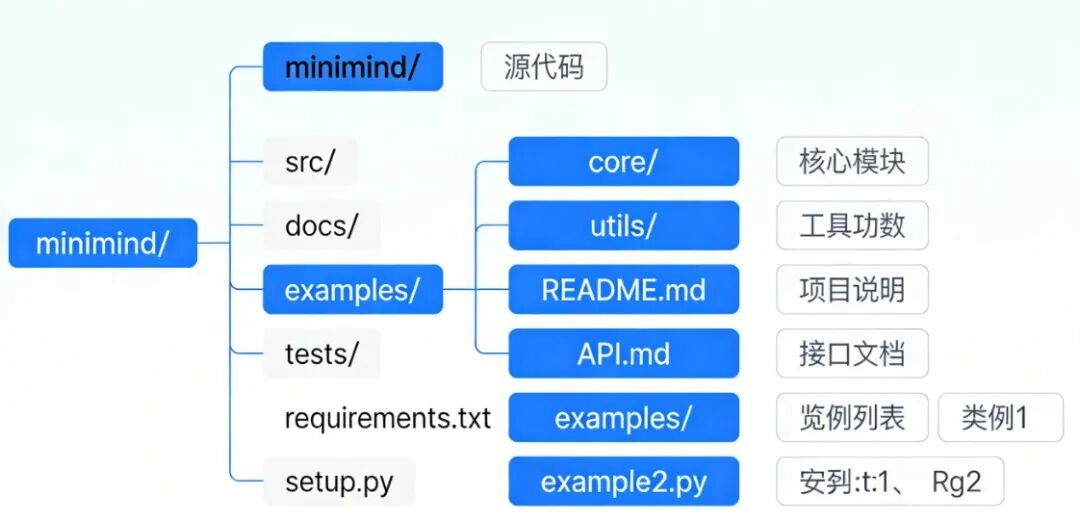
MiniMind文件详细说明:
minimind/
├── LICENSE # Apache 2.0 开源协议文件,定义使用/分发/修改的法律规则
├── README.md # 中文核心文档:项目介绍、快速开始、训练流程、数据集说明等
├── README_en.md # 英文核心文档:面向国际用户的项目说明、数据集/训练细节
├── .gitignore # Git 忽略规则:排除缓存、训练输出、编译文件等无需版本控制的内容
├── requirements.txt # 项目依赖清单:PyTorch、transformers、streamlit 等第三方库版本
├── eval_llm.py # 模型评测脚本:支持 C-Eval/C-MMLU 等榜单,验证模型性能
├── model/ # 模型核心定义目录
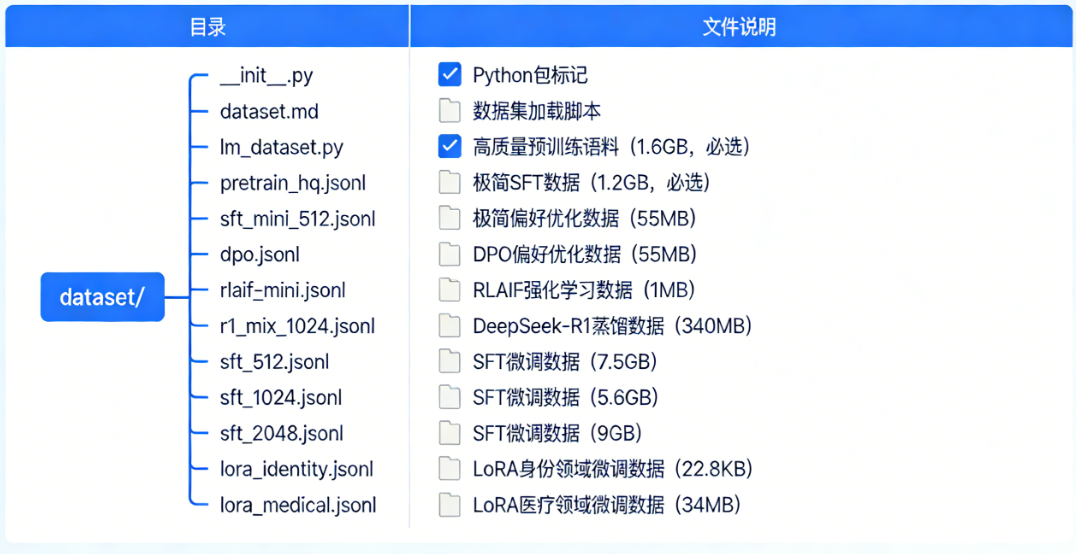
├── dataset/ # 数据集目录:存放训练/微调所需各类数据
├── trainer/ # 训练脚本核心目录(所有训练需 cd 至此执行)
├── scripts/ # 辅助脚本目录
├── images/ # 可视化资源目录
│ ├── LLM-structure.png # Dense 版模型结构可视化图
│ ├── LLM-structure-moe.png # MoE 版模型结构可视化图
│ ├── dataset.jpg # 数据集构成/量级/使用方案可视化图
│ ├── compare_radar.png # 模型性能对比雷达图
│ ├── logo.png/logo2.png # 项目 Logo 图片
│ └── minimind2.gif # 对话效果动态演示图
└── out/ # 训练输出目录(自动生成)
└── *.pth # 训练权重文件:每隔 100 步保存,覆盖旧文件(.gitignore 排除)
trainer/(训练脚本目录):

model/(模型核心定义目录):

dataset(数据集结构):
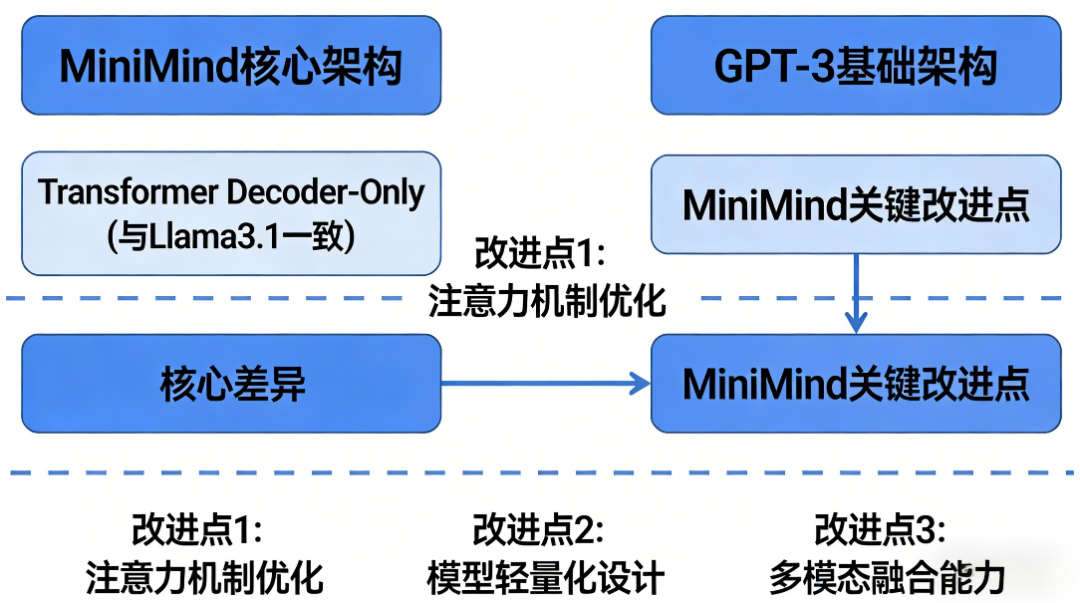
一、整体架构基础
MiniMind核心沿用TransformerDecoder-Only架构(与Llama3.1一致),并在GPT-3基础上做了关键改进,核心差异点:
二、两大核心架构分支
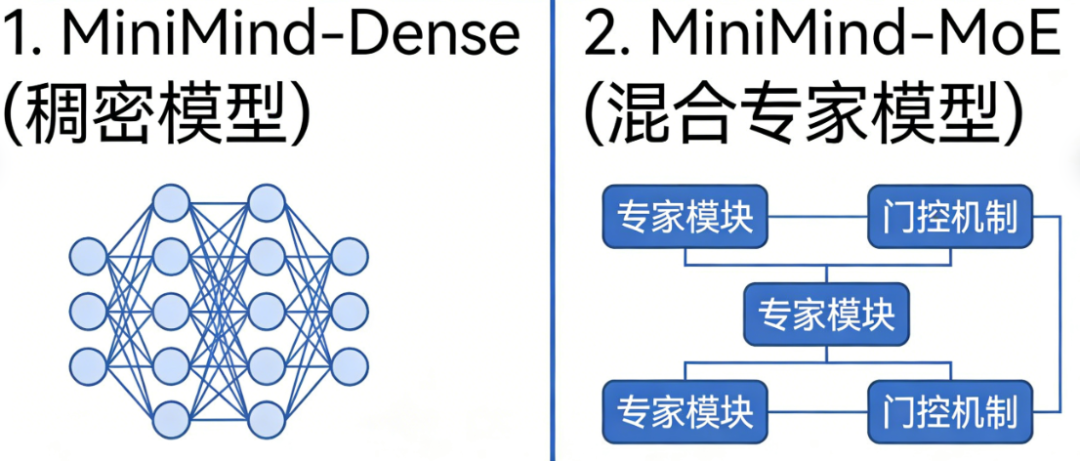
- MiniMind-Dense(稠密模型)
核心特点:无专家机制,所有层参数全局共享,结构极简,适合轻量化部署。
代码入口:模型配置可修改 ./model/LMConfig.py(核心结构定义在 ./model/model_minimind.py)。
- MiniMind-MoE(混合专家模型)
核心基础:基于 Llama3 + DeepSeek-V2/3 的 MixFFN 混合专家模块,针对前馈网络(FFN)做精细化设计。
关键优化:
采用更细粒度的专家分割策略,提升专家利用率;
引入「共享专家隔离技术」,避免共享专家成为性能瓶颈;
考虑 MoE 负载均衡 Loss,优化专家分配效率。
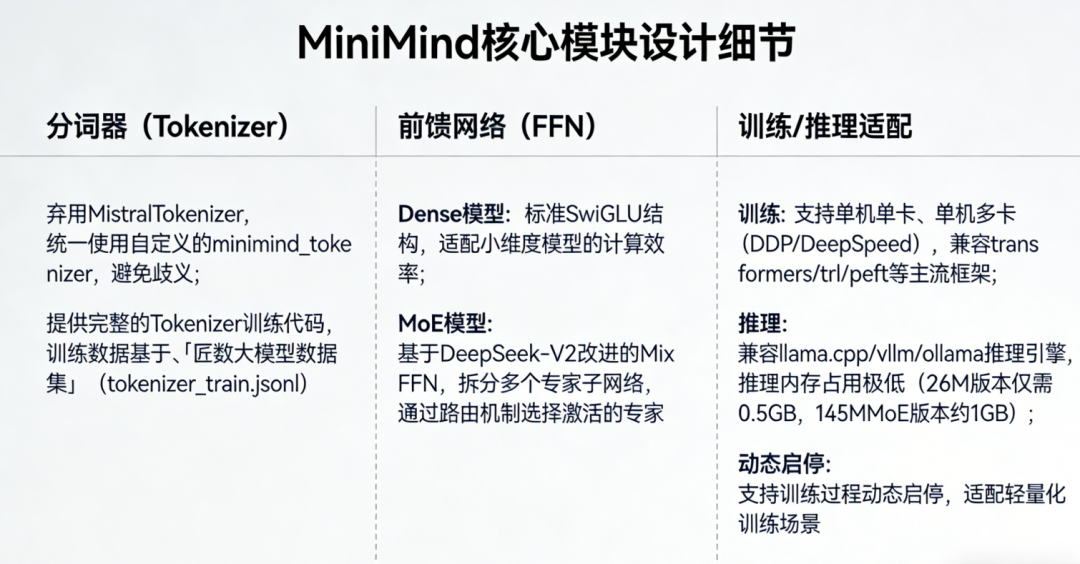
三、核心模块设计细节
四、架构设计的核心目标

- 极致轻量化:最小版本仅 26M 参数量(GPT-3 的 1/7000),普通个人 GPU(如 3090)可 2 小时完成训练,成本仅 3 元;
- 全流程可复现:核心算法(预训练 / SFT/LoRA/DPO/ 蒸馏)基于 PyTorch 原生重构,无第三方抽象接口依赖;
- 易拓展性:已拓展至视觉多模态(MiniMind-V),且支持私有数据集迁移(如医疗、法律等垂直领域)。
五、架构可视化
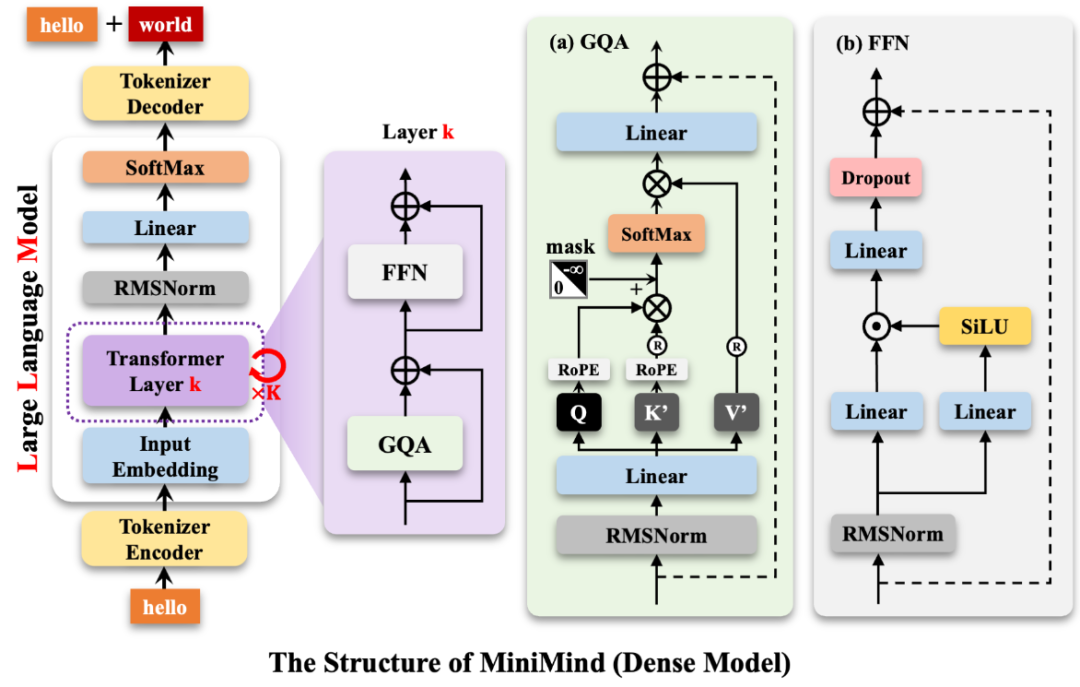
MiniMind的整体结构一致,只是在RoPE计算、推理函数和FFN层的代码上做了一些小调整。 其结构如下图:
稠密模型结构:
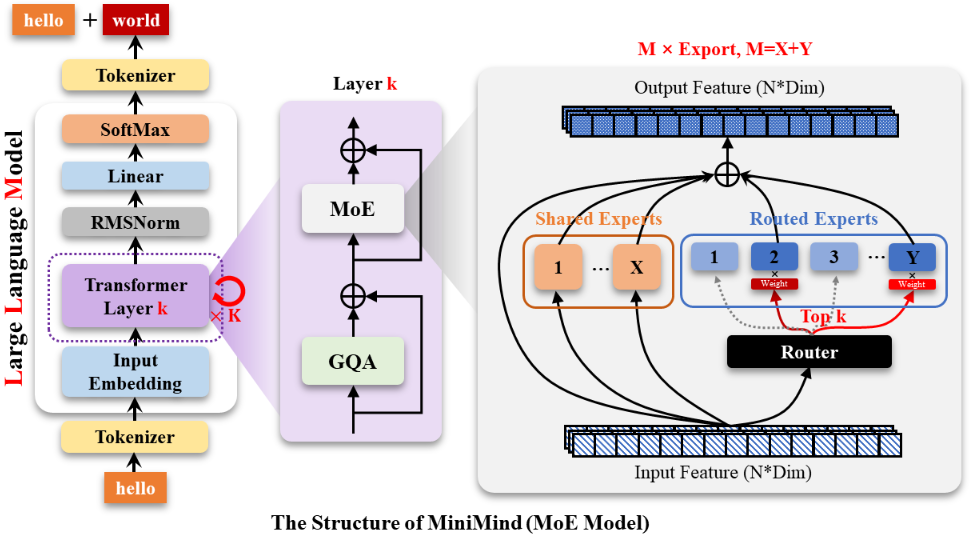
MoE 模型结构:
总结
MiniMind架构的核心是「极简+适配」:以经典TransformerDecoder-Only为基底,通过RMSNorm、SwiGLU、RoPE等技术优化基础性能,同时拆分Dense/MoE分支适配不同轻量化场景,最终实现「极低成本、全流程可复现、易拓展」的小模型设计目标。
🚀MiniMind的优势
- 超轻量化设计
- 最小版本模型仅 25.8MB,约为 GPT-3 的 1/7000。
- 普通个人 GPU(如 NVIDIA RTX 3090)即可训练,大大降低硬件门槛。
- 开源完整训练流程
- 提供从数据清洗、预训练到监督微调、LoRA 微调、偏好强化学习(DPO)、模型蒸馏等所有步骤的完整代码。
- 全部代码基于 PyTorch 原生框架重构,无第三方抽象接口依赖,便于开发者理解和修改。
- 支持多模态任务
- 不仅能处理文本,还能通过 MiniMind-V 扩展支持图像理解等多模态任务。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2026 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2026 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐
 6
6 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)