
YOLO深度学习(计算机视觉)一注意力模块无敌透彻(CBAM、SpatialAttention、C2PSA)
本文介绍了两种注意力机制在目标检测中的应用对比,重点讲解了CBAM模块的原理与实现。作者通过玉米雄穗检测案例,说明Transformer类注意力机制不适合微小目标检测,而轻量级的CBAM模块通过通道和空间双重注意力能有效强化小目标特征。文章详细展示了在YOLOv11中插入CBAM模块的代码实现过程,包括模块初始化、模型结构调整和训练配置优化。实验结果表明,CBAM能精准定位微小目标,同时保持较低的
提示:这里专门写得是针对适用于YOLO的注意力模块写法,对于所有人工智能框架在原理层面是没有任何的,但是代码方面仅使用于YOLO
一、【注意力】简单概念
由于我自己也是小白,非人工智能科班生临时学的,所以我也不深究其中的深层原理,大致了解一下是个什么东西就行
首先【注意力】顾名思义,就是让计算机专注于图像中我们关心的目标物体,而忽略周边的无关像素,而做法就是要调各个像素的参数权重,让专注的像素的参数权重高、其他的参数权重低
这就涉及了两大类注意力:【Transformer 类注意力机制】VS【卷积类注意力模块】

1、【Transformer 类注意力机制】
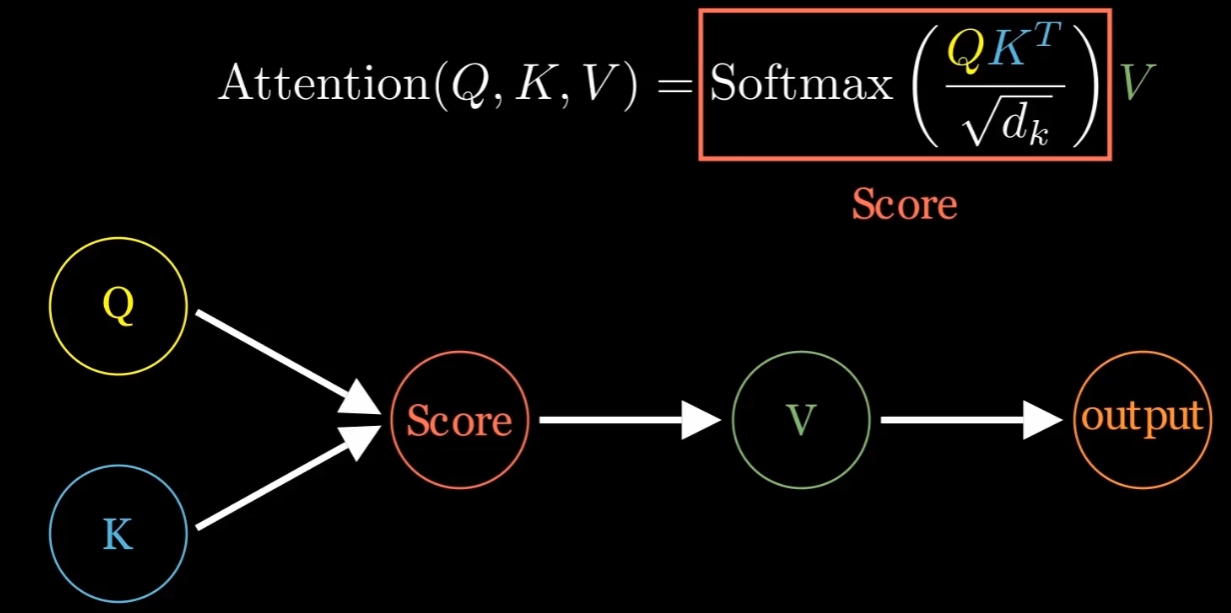
它的原理就是用下图这个公式得到结果:它的核心思想是通过对输入的每一个元素(Q、K、V)进行加权和计算,进而获得最相关的部分进行重点关注。
- 这个公式里涉及了3个参数:Q、K、V
- 大致结构如图,看一眼就够了,我只是想显得专业一点而已.....
至于我为什么要介绍这个【Transformer 类注意力机制】,是因为它跟我们YOLO目标检测要用到的注意力模块暂时无需关心,他最常用于NLP大语言模型,虽然现在计算机视觉领域也开始称王,但是作为初学者,像我这种SB很有可能会花时间去了解它,而到最后啥也没学会
这里我只是为了告诉各位【Transformer 类注意力机制】和【卷积类注意力模块】是两个不一样的东西,前者我们先不用,后者才是我们要用的。

2、【卷积类注意力模块】
卷积类注意力通常是指在卷积神经网络中通过局部感受野进行关注。与Transformer不同,卷积操作是基于局部区域的特征进行提取,因此它对局部空间的注意力更加专注,而不是全局的信息交互。卷积类注意力的计算方式更偏向于局部感知,适用于空间结构数据(如图像),而Transformer类注意力则更擅长处理长距离依赖的全局信息。当然这也决定了卷积类注意力只适用于计算机视觉,而非NLP大语言模型。
3、二者对比
- Transformer类注意力:
- 全局关注:可以通过【全局】信息建模,适合处理NLP语言的【长距离依赖】。
- 计算量大:由于需要计算所有输入元素之间的关系,计算开销相对较高。
- 灵活性强:能够处理任何类型的输入序列数据(如文本、语音等)。
- 卷积类注意力:
- 局部关注:主要聚焦于【局部】区域特征,只适用于【图像等】数据。
- 计算效率高:由于卷积操作具有局部性,计算效率比Transformer高。
- 不善处理长距离依赖:卷积结构不适合直接捕捉远距离信息,可能需要多层卷积来近似全局关系。


二、YOLO适用的卷积类注意力
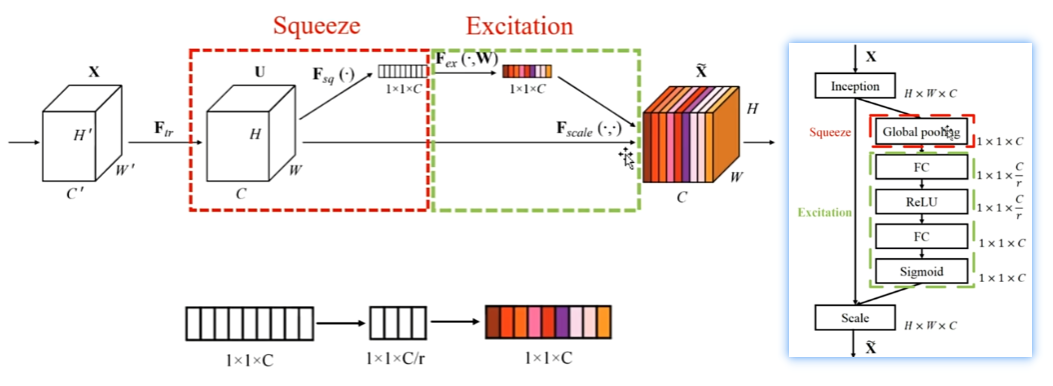
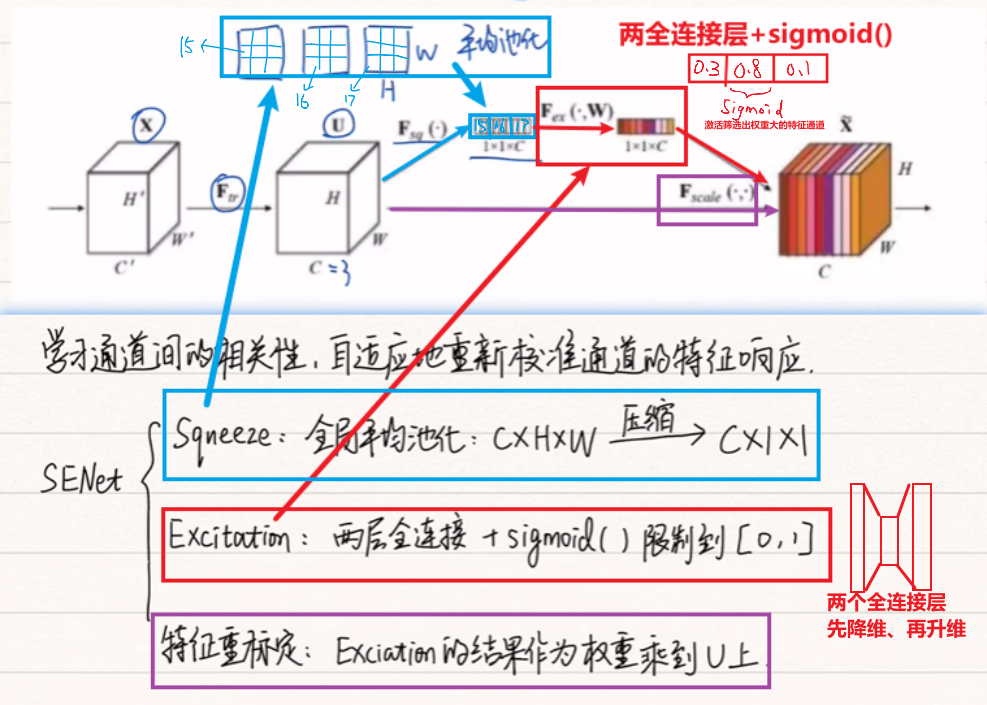
1、第一代:SEnet模块
- 结构:【平均池化压缩】+【2全连接层 + Sigmoid()函数】+【结果乘上输入权重】
- 特点:
- ✔ 只做通道注意力
- ✔ 结构极简
- ❌ 不知道空间位置
- 效果:我自己对一个数据集进行了一次【不加SE】和【加了SE】训练
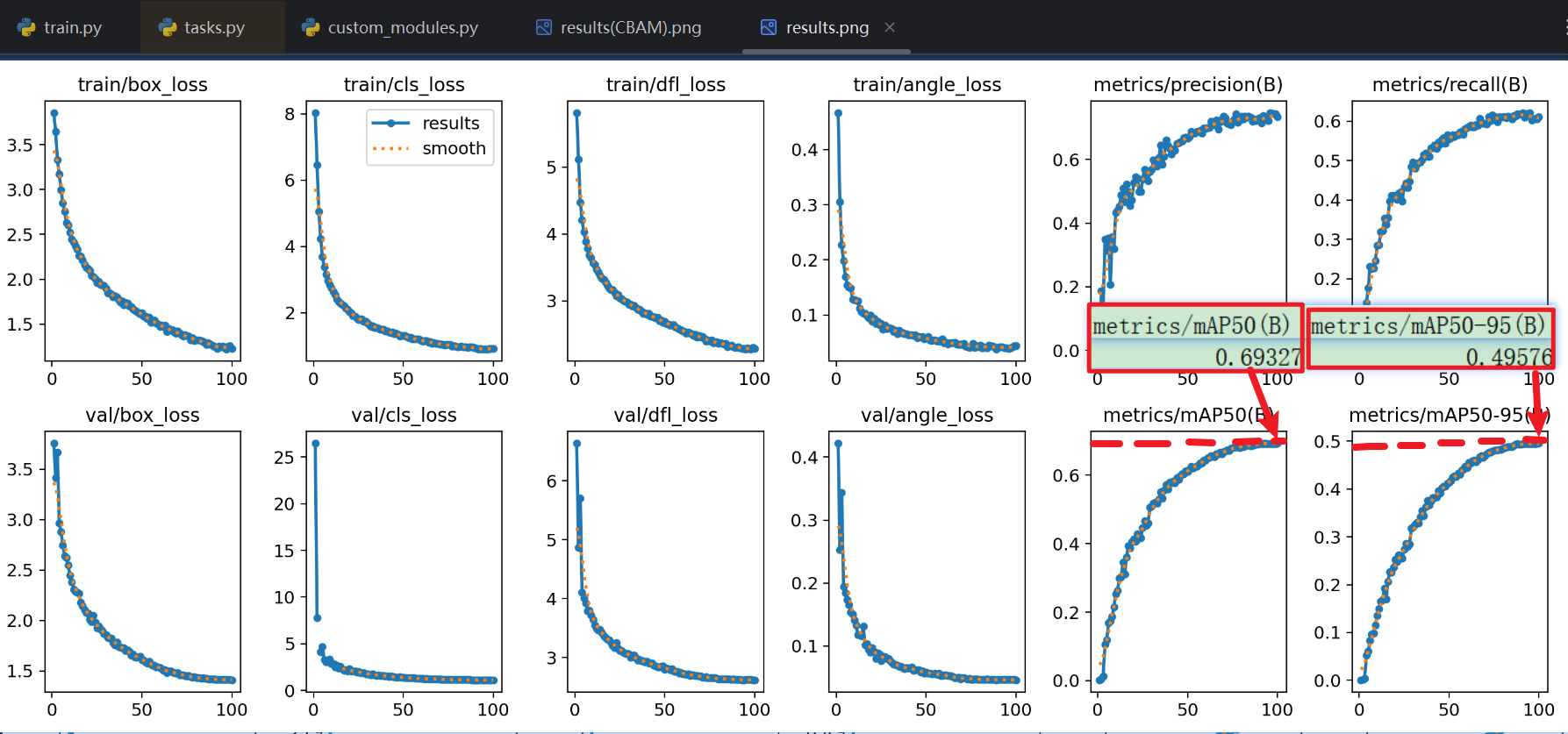
- 【不加SE】得效果
- 整体效果虽然不错,但是mAP50在69%、mAP50~95在49%左右,都还不够高
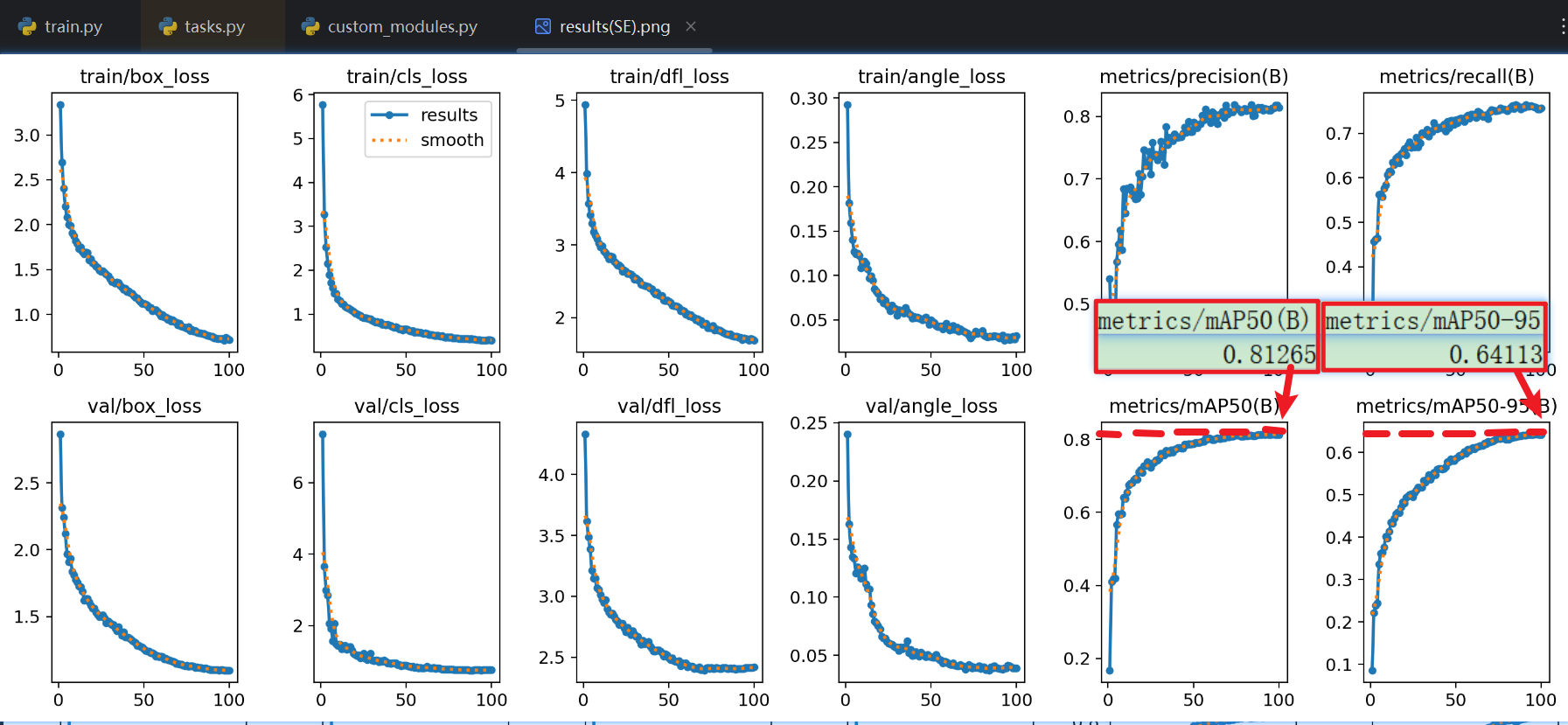
- 【加了SE】得效果
- 很顶级:明显mAP50提高了很多!!说明IoU高了,也就是预测框的定位更准
- 另外注意看 验证集的损失值 也降低了很多!!
2、第二代:CBAM模块(重点,实用)
那么YOLO最常见的注意力模块就是【CBAM注意力模块】,是因为对于微小目标检测,它更轻量、即插即用,专门强化小目标特征!!!
CBAM 的全称是 Convolutional Block Attention Module(卷积块注意力模块),是专门为卷积网络设计的轻量注意力模块(算力消耗低,适合大部分电脑)。
它的核心逻辑是:从两个维度给特征 “加权”—— 先选对【通道】,再选对【位置】,两步操作都针对小目标优化。
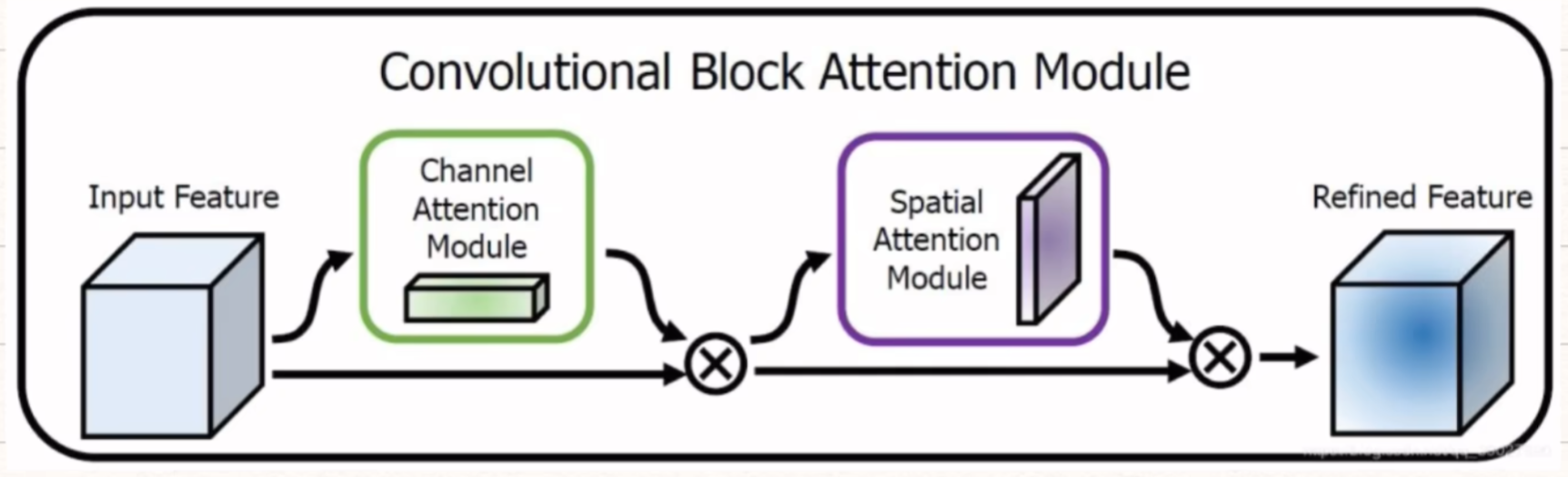
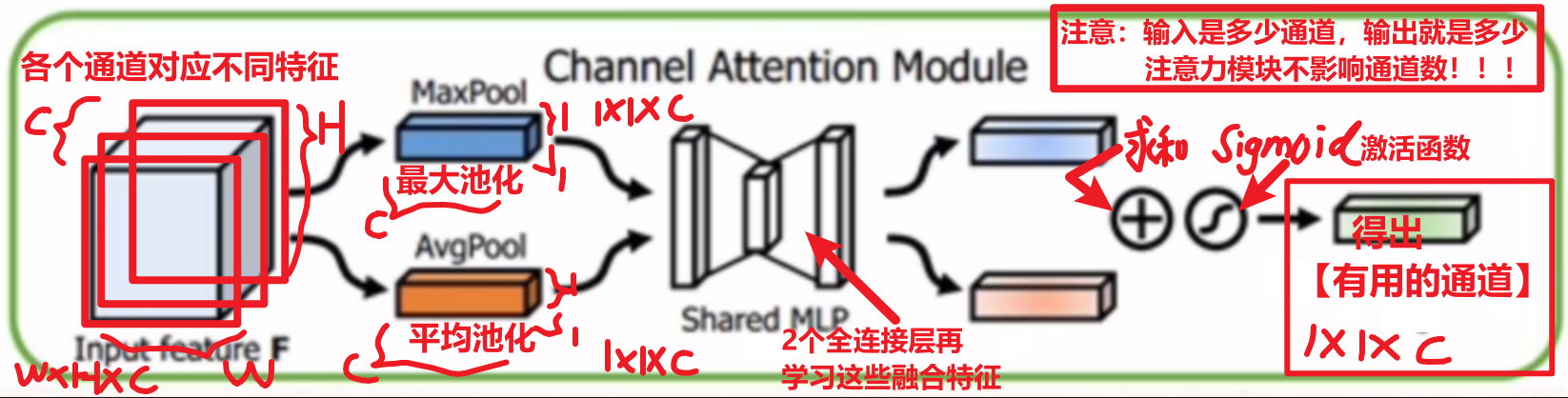
1)通道注意力(Channel Attention)—— 选 “有用的特征通道”


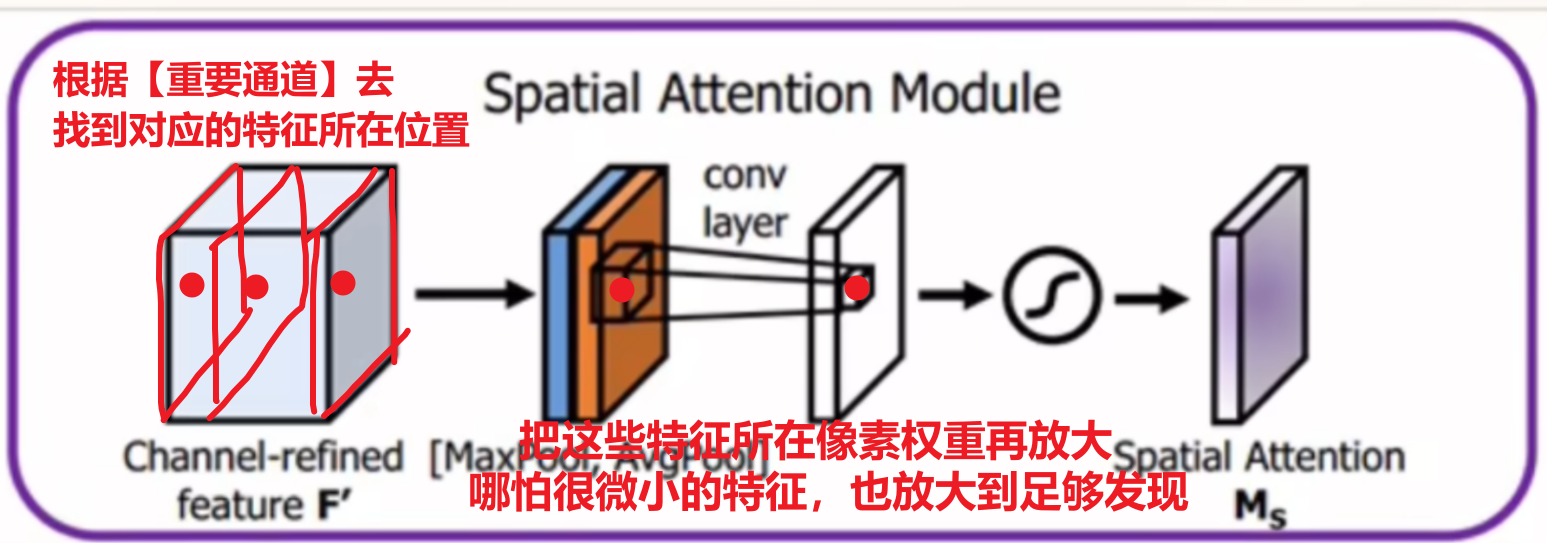
2)空间注意力(Spatial Attention)—— 选 “有用的像素位置”
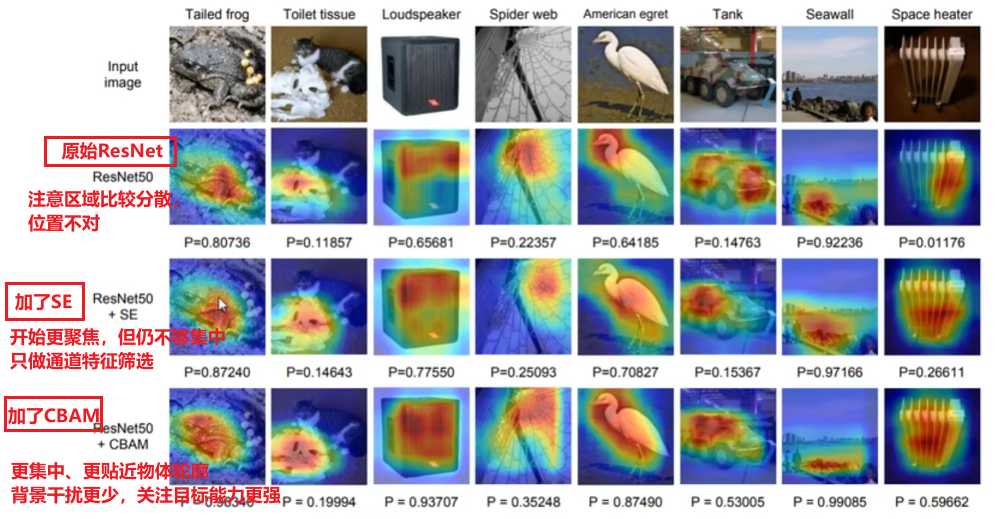
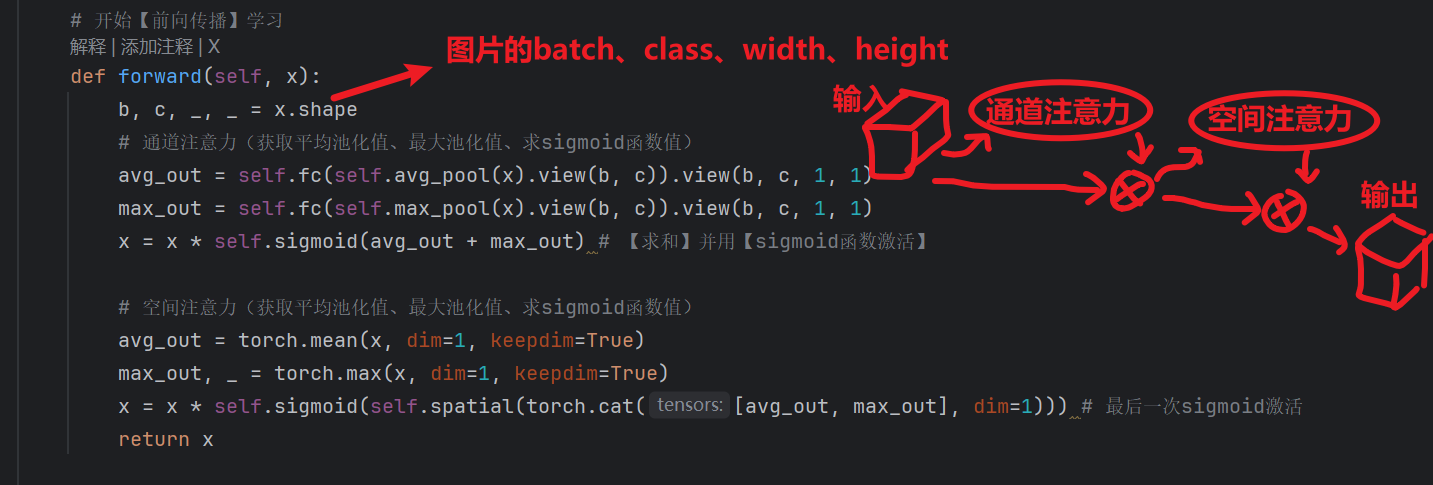
还是以“玉米雄穗”为例子,经过通道注意力后,模型已经聚焦到 “绿色纹理” 这类特征,但还不知道这些纹理在图片的哪个位置(是雄穗的位置,还是叶片的位置?)
空间注意力的作用:给雄穗所在的像素位置加权重,给背景位置降权重 —— 让模型精准定位小目标的位置。
总结:
以玉米雄穗数据集为例子,大致流程就是:
- 输入特征图(抓极小雄穗) ↓
- 通道注意力:选“绿色纹理”通道 → 加权 ↓
- 空间注意力:选“雄穗位置”像素 → 加权 ↓
- 输出加权后的特征图(雄穗特征被放大,背景被抑制)

3)比【SE】优秀的原因,为什么我们要选他
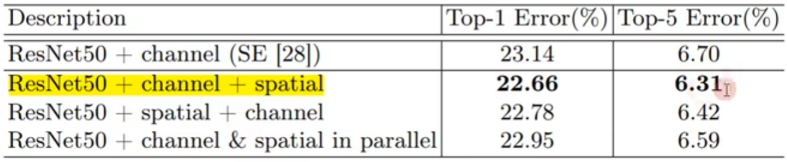
CBAM融合了 “通道注意力 + 空间注意力”,并构成了一段包含池化、全连接、卷积的代码。对于他提出的论文里也和SE做了详细对比:
- 在加入【平均池化】+【最大池化】后,对比效果最好
- 加入【通道注意力】+【空间注意力】
- 而且先【通道】再【空间】的顺序,对比效果最好
- 以及热力图效果对比
- 另外,YOLO官方还提供了拆开的【通道注意力ChannelAttention】、【空间注意力SpatialAttention】
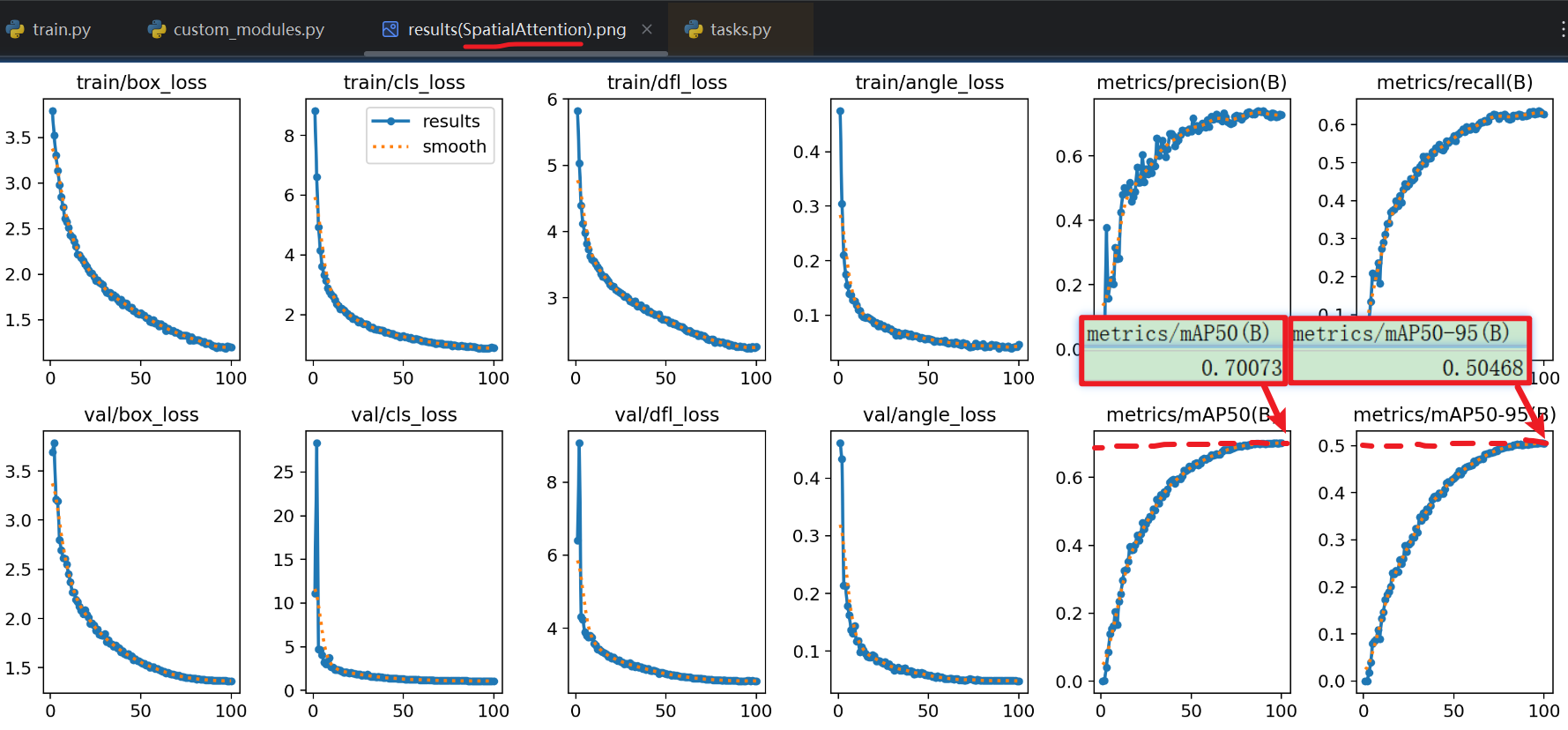
- 效果:但是我经过亲自实验,【单独用这两个】注意力模块的效果比【整个CBAM的:先“通道” 再“空间”】的效果差!!!
- 单独用【空间注意力SpatialAttention】的效果
- 甚至还不如【SE模块】的效果。。。。拉完了
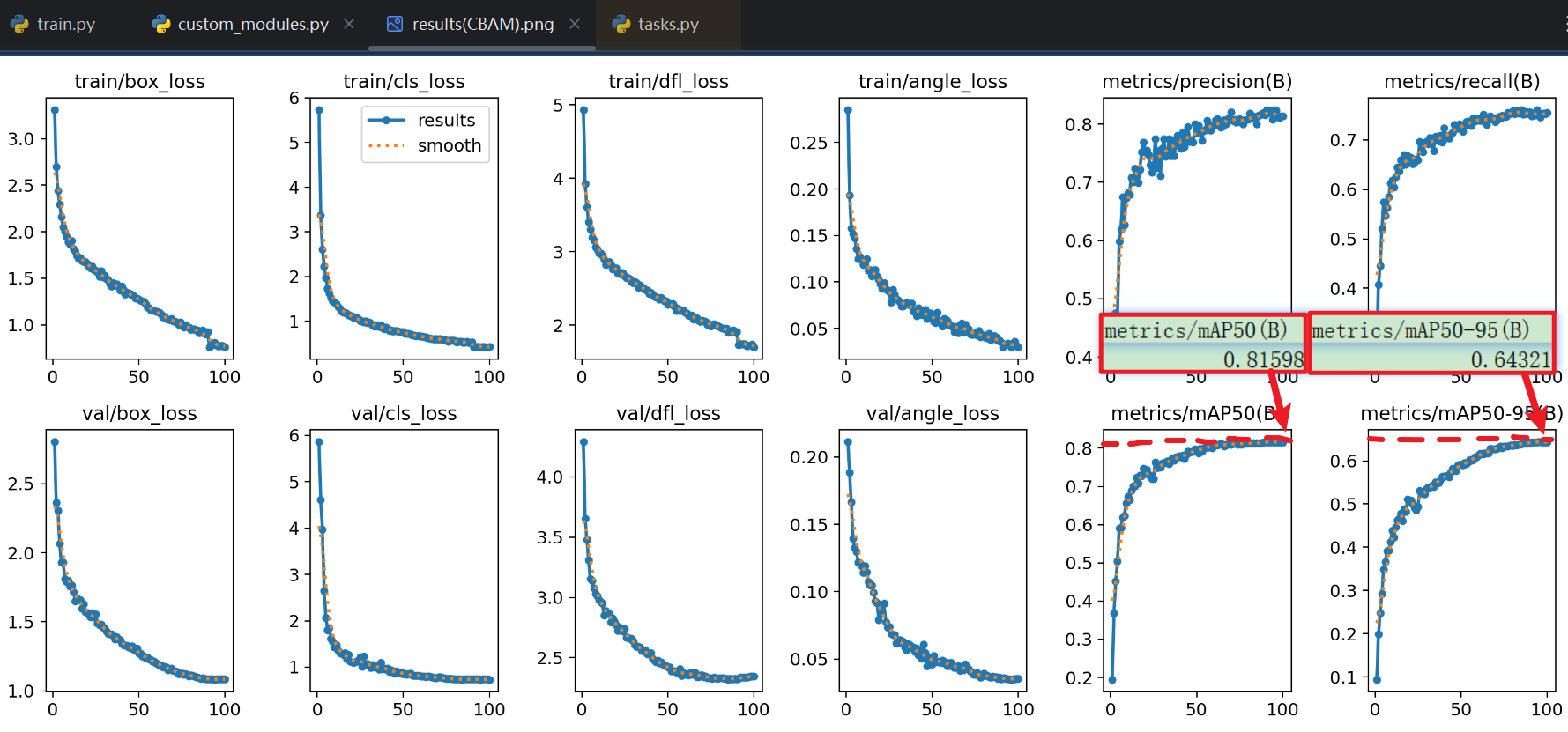
- 整个用【CBAM】的效果:
- 夯爆了:明显这次mAP比【单独用空间注意力】、或用【SE模块】得高!!!另外看损失指标也降低了很多(看图表纵坐标数据,别只看曲线)

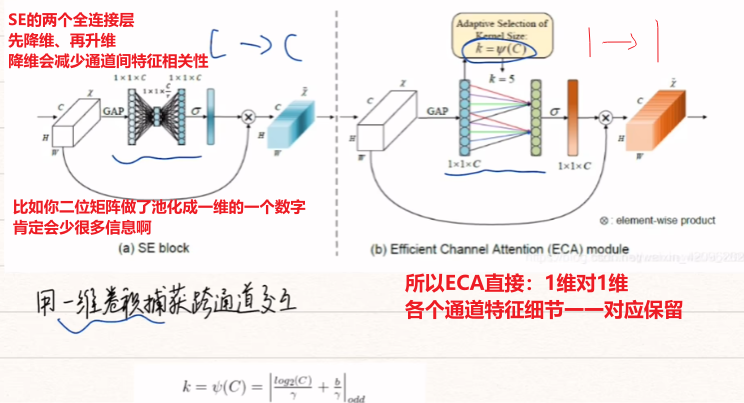
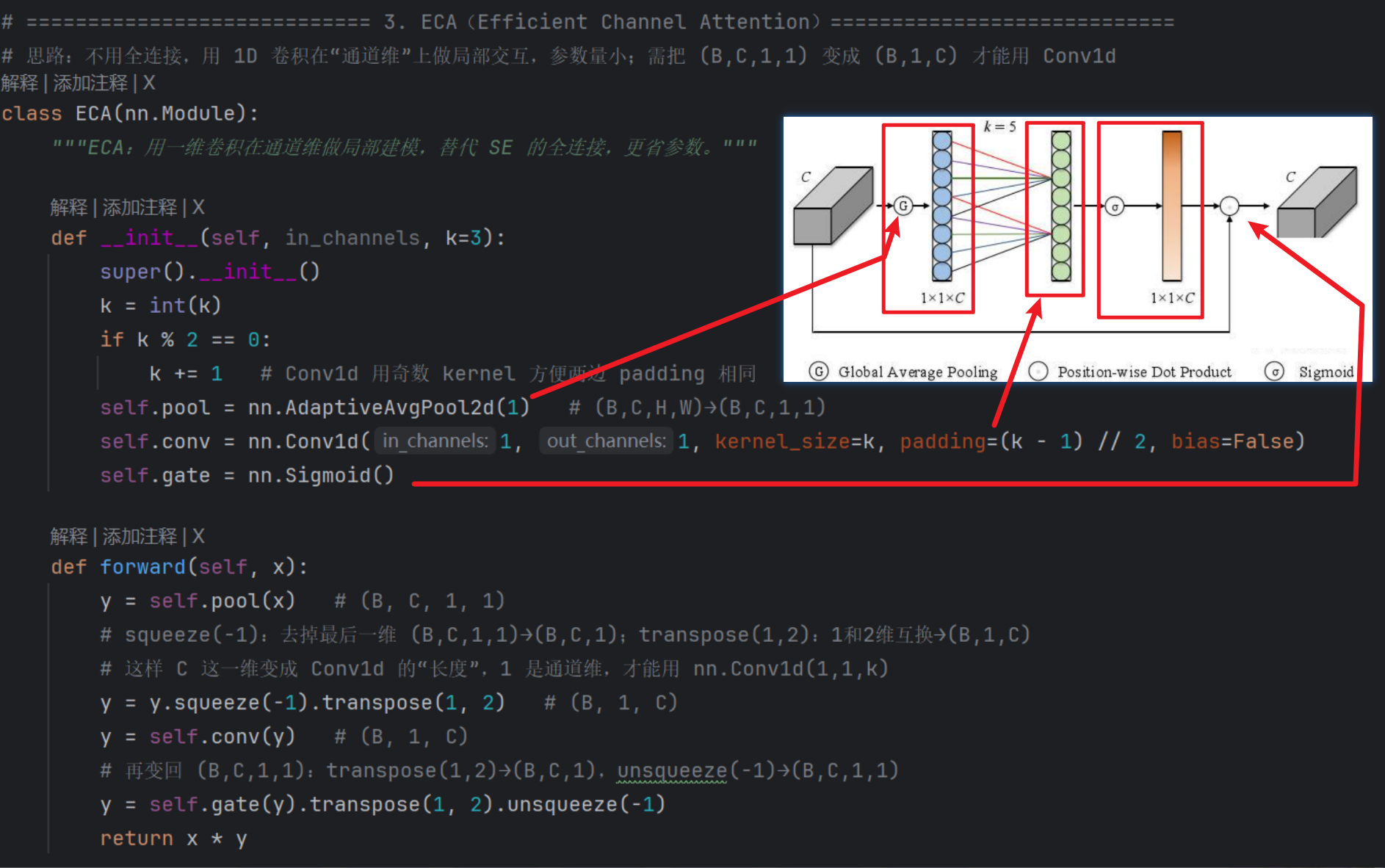
3、第三代:ECA模块
SENet中降维会给通道注意力机制带来副作用,并且捕获所有通道之间的关系效率不高,且非必要。ECA注意力机制模块直接在全局平均池化层后使用1*1卷积,去除全连接层。避免了维度锐减,有效的捕获了跨通道交互。
- 实现步骤如下:
- (1)将输入特征图经过全局平均池化,特征图从[h,w,c]的矩阵变成[1,1,c]的向量。
- (2)根据特征图的通道数计算得到自适应的一维卷积核大小kernelsize。
- (3)将kernelsize用于一维卷积中,得到对于特征图的每个通道的权重。
- 将归一化权重和原输入特征图逐通道相乘,生成加权后的特征图。
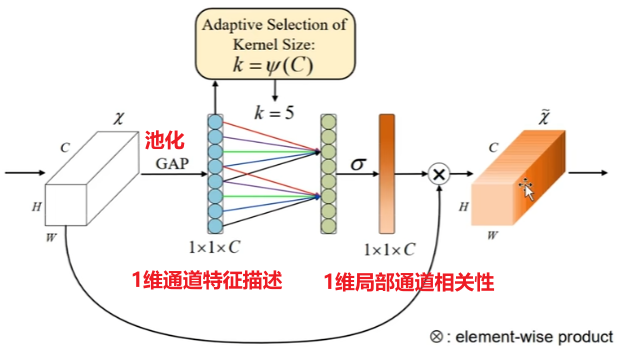
- 说白了就两个人话:
- 1、不降维
- 2、专注【局部】通道特征交互融合
- 特点:
- ✔ 更轻量
- ✔ 参数更少
- ✔ 效果接近甚至超过CBAM
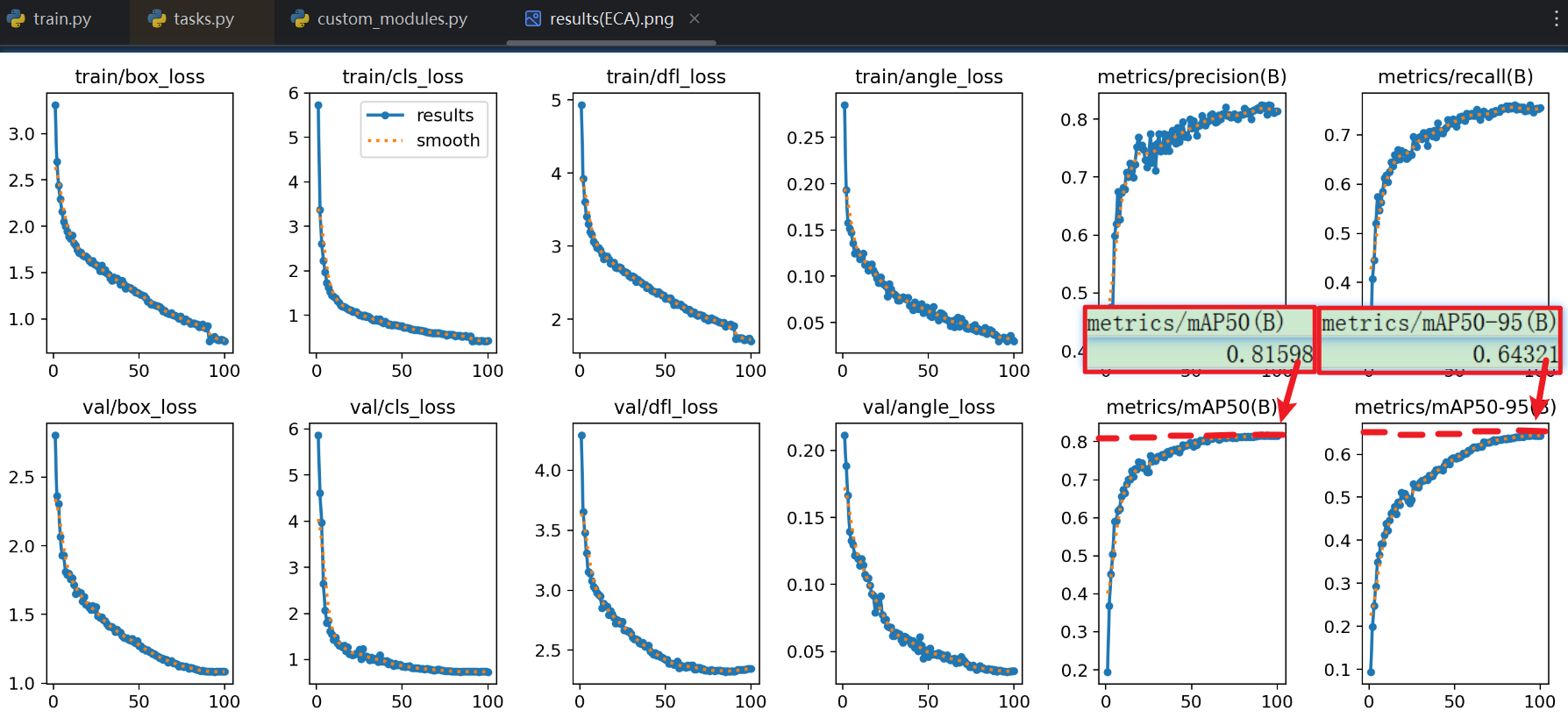
- 实际效果:
- 那么经过我换成【ECA模块】后得到的实验结果,竟然和【CBAM】一模一样,基本数据完全一样,那就说明【ECA】≈【CBAM】基本没区别
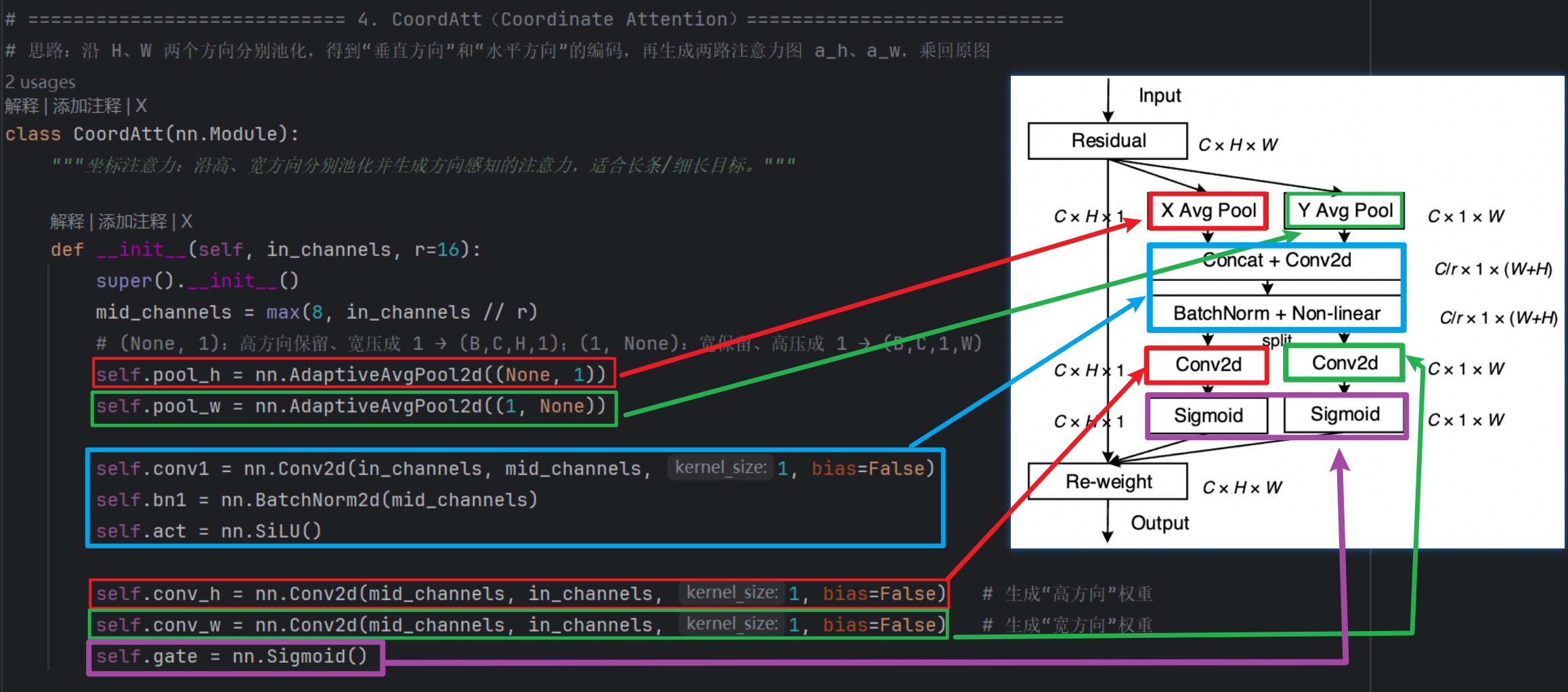
4、第四代:Coordinate Attention模块
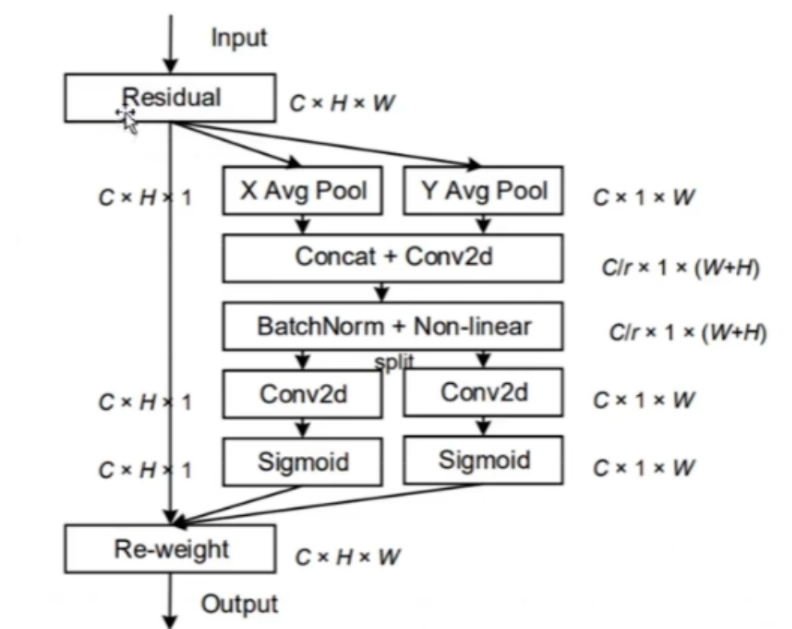
现有的注意力机制(如CBAM、SE)在求取通道注意力的时候,通道的处理一般是采用全局最大池化/平均池化,这样会损失掉物体的空间信息。Coordinate Attention模块作者期望在引入通道注意力机制的同时,引入空间注意力机制,作者提出直接将注意力机制将位置信息嵌入到了通道注意力中
步骤如下:
将输入特征图分别在为宽度和高度两个方向分别进行全局平均池化,分别获得在宽度和高度两个方向的特征图。
假设输入进来的特征层的形状为[C,H,W],在经过宽方向的平均池化后,获得的特征层shape为[C,H,1],此时我们将特征映射到了高维度上;
在经过高方向的平均池化后,获得的特征层shape为[C,1,W],此时我们将特征映射到了宽维度上。
然后将两个并行阶段合并,将宽和高转置到同一个维度,然后进行堆叠,将宽高特征合并在一起,此时我们获得的特征层为:[C,1,H+W],利用卷积+标准化+激活函数获得特征。
之后再次分开为两个并行阶段,再将宽高分开成为:[C,1,H]和[C,1,W],之后进行转置。获得两个特征层[C,H,]和[C,1,w]。
然后利用1x1卷积调整通道数后取sigmoid获得宽高维度上的注意力情况。乘上原有的特征就是CA注意力机制。
- 特点:
- ✔ 结合位置信息
- ✔ 更适合检测任务
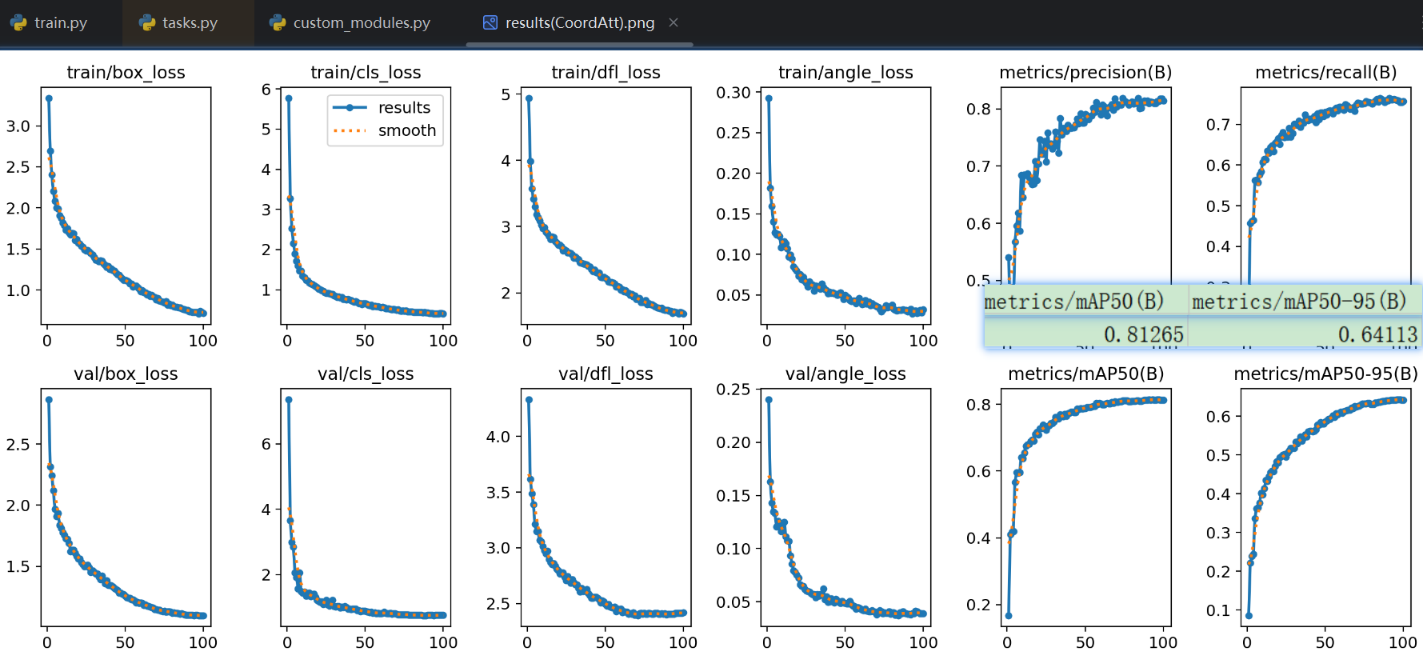
- 实际效果:
- 我个人的实验证明,效果跟【CBAM】和【ECA】没有太大区别
- 而且略微在小数级别比他两低一点,给到一个人上人吧
5、总结汇总
这里还有一个C2PSA,yolo加入的一个官方注意力模块,我好奇试了一下,效果就是一坨屎,后来我才知道这玩意只适用在backbone处加,而我们一般加注意力、调整结构就调head就好了,所以不推荐C2PSA,也不过多介绍它

三、代码实操
首先讲一下写一个模块的套路(不管是注意力模块、C3k2、上采样下采样...等),无非就是:
规定模板套路:
- def __init__(self, ......):初始化这个模块
- 先继承父类:super().__init__()
- 然后分别针对不同模块,创建内部每一个细节结构
- def forward(self, ......):规定前向传播的流程
- 根据前面__init__定义的结构,返回权重结果w
- 一般全连接层的流程是【嵌套函数】,比如A—>B—>C,代码就是C ( B( A( w ) ) )
然后yolo的【nn】提供的一些便捷函数:
- nn.AdaptiveAvgPool2d(要压缩成的维度):平均池化
- nn.Conv2d():创建卷积
- 一般就6个参数(输入通道, 输出通道, kernel_size, stride, padding, bias)
- - 输入通道数(输入特征图有几层“通道”)。
- - 输出通道数(卷积后得到几层通道)。
- - 卷积核大小(如 1 表示 1×1,只做通道混合、不改变 H,W;3 或 7 表示 3×3、7×7)。
- - stride:步长,默认 1(不缩小尺寸)。
- - padding:四周补零圈数,通常取 (kernel_size-1) // 2 使 H、W 不变。
- - bias:是否加偏置,True/False
- nn.Linear():全连接层(线性变换)
- 对每个样本做「输入维 → 输出维」的矩阵乘法
- 一般三个函数(输入通道, 输出通道, bias)
nn.Linear() nn.Conv2d() 输入形状 (B, in_channels),没有 H、W (B, 2, H, W),有高、宽 输出形状 (B, out_channels) (B, 1, H, W),还是 H×W 在做什么 对整根向量做线性组合(全局、无空间) 对每个位置用一个小窗口做线性组合(局部、有空间) “2 / 1” 的含义 不适用 2 个通道进 → 1 个通道 - nn.损失函数名字:调用现成写好的各种损失函数
- 例如:nn.ReLU()、nn.SiLU().......
- nn.Sequential:就是一个按顺序执行的模块容器:
- 输入依次通过第 1 个、第 2 个、第 3 个.....子模块,得到输出。不用自己写 forward。
- 例如:
out = 输入
out = 第1层(out)
out = 第2层(out)
out = 第3层(out)
return out
- nn.Sequential = “把好几层按顺序串起来,当一个小网络用”;
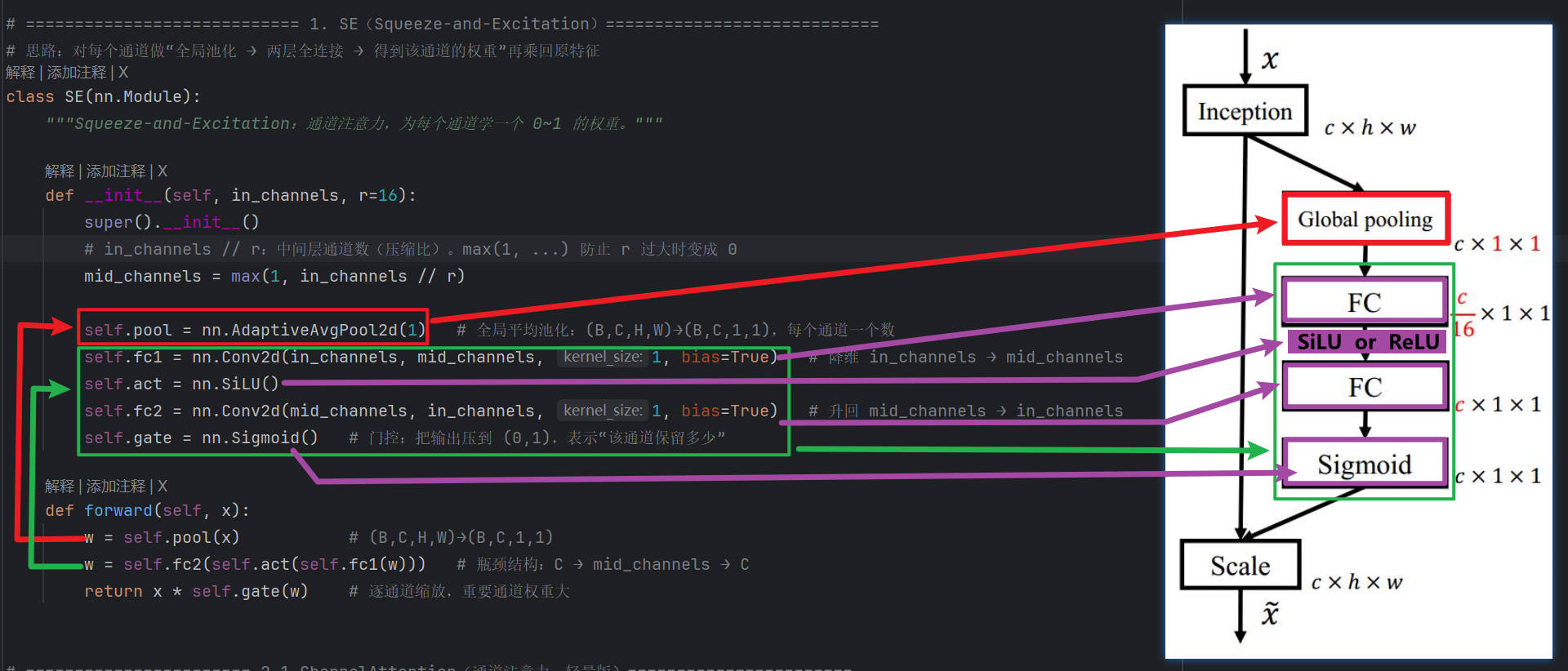
1、SEnet模块
1)导入【SE】模块
由于yolo11官方代码没有写SE模块,不知道是觉得没用废除了还是为啥,这里我们只能自己手写一个,记住SE的结构:
- 1、全局平均池化:把每个通道C对应的2维数据用平均数压缩成一个1维数字
- 2、2个卷积夹一个损失函数:fc1 —> 损失函数 —> fc2
- 注意损失函数可以是ReLU也可以是SiLU,SiLU计算精度更高
- 另外注意:1×1 卷积等价于“按通道做线性变换”,大家也习惯叫 “全连接”
- 3、最后接一个Sigmoid()函数
(具体代码我会放在在最后,可以直接复制拿去直接用)
【注意:一定要做!!!!】
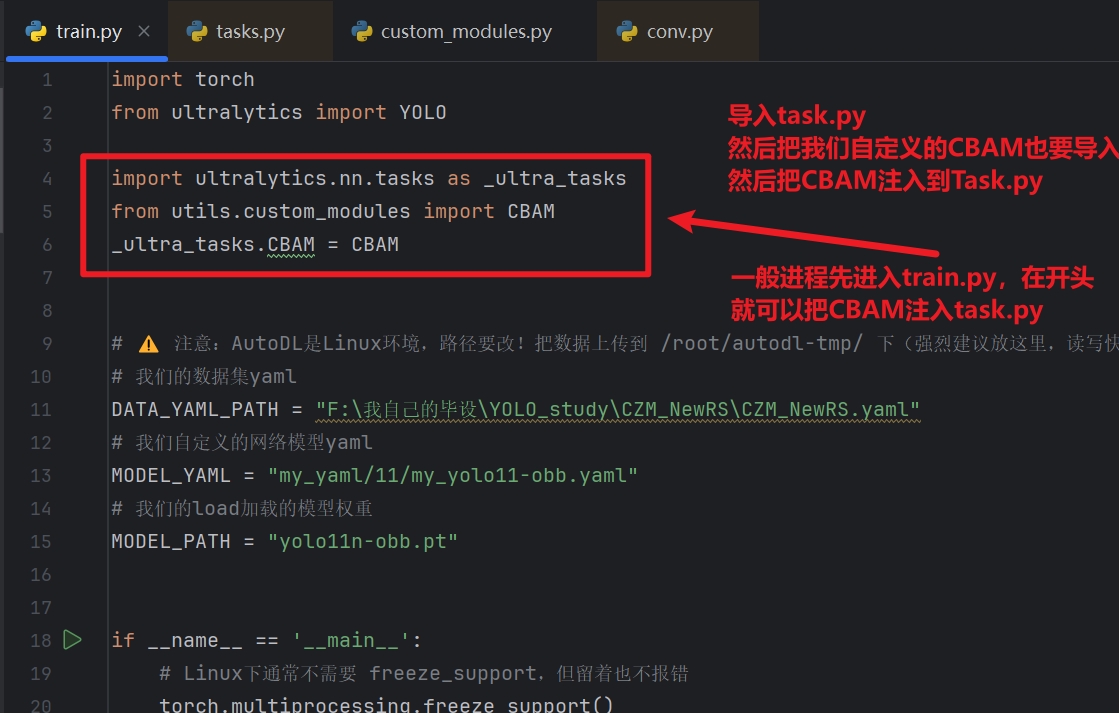
- 自定义模块还需要从【train.py】前面注入:
- 对应task.py那,你注册的当前train.py路径为全局环境变量“XXX”,然后task.py才能获取XXX的时候读到train.py路径
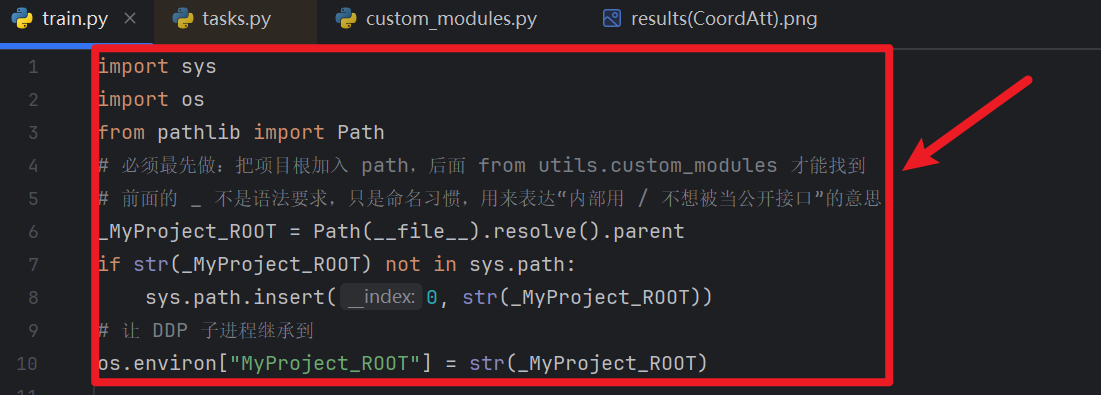
import sys import os from pathlib import Path # 必须最先做:把项目根加入 path,后面 from utils.custom_modules 才能找到 # 前面的 _ 不是语法要求,只是命名习惯,用来表达“内部用 / 不想被当公开接口”的意思 _你设置的全局环境变量 = Path(__file__).resolve().parent if str(_你设置的全局环境变量) not in sys.path: sys.path.insert(0, str(_你设置的全局环境变量)) # 让 DDP 子进程继承到 os.environ["你设置的全局环境变量"] = str(_你设置的全局环境变量)- task.py能读到train.py后,再把我们自定义的模块注入
# 让 yaml 里能使用自定义的 SE、ECA、CoordAtt(必须在 import YOLO 之前注入到 tasks) import ultralytics.nn.tasks as _ultra_tasks from utils.custom_modules import SE, ECA, CoordAtt _ultra_tasks.SE = SE _ultra_tasks.ECA = ECA _ultra_tasks.CoordAtt = CoordAtt
2)yaml网络结构插入
提醒:【注意力模块】不改变通道数!!!!!!!
那么我们应该插到哪?怎么插呢?
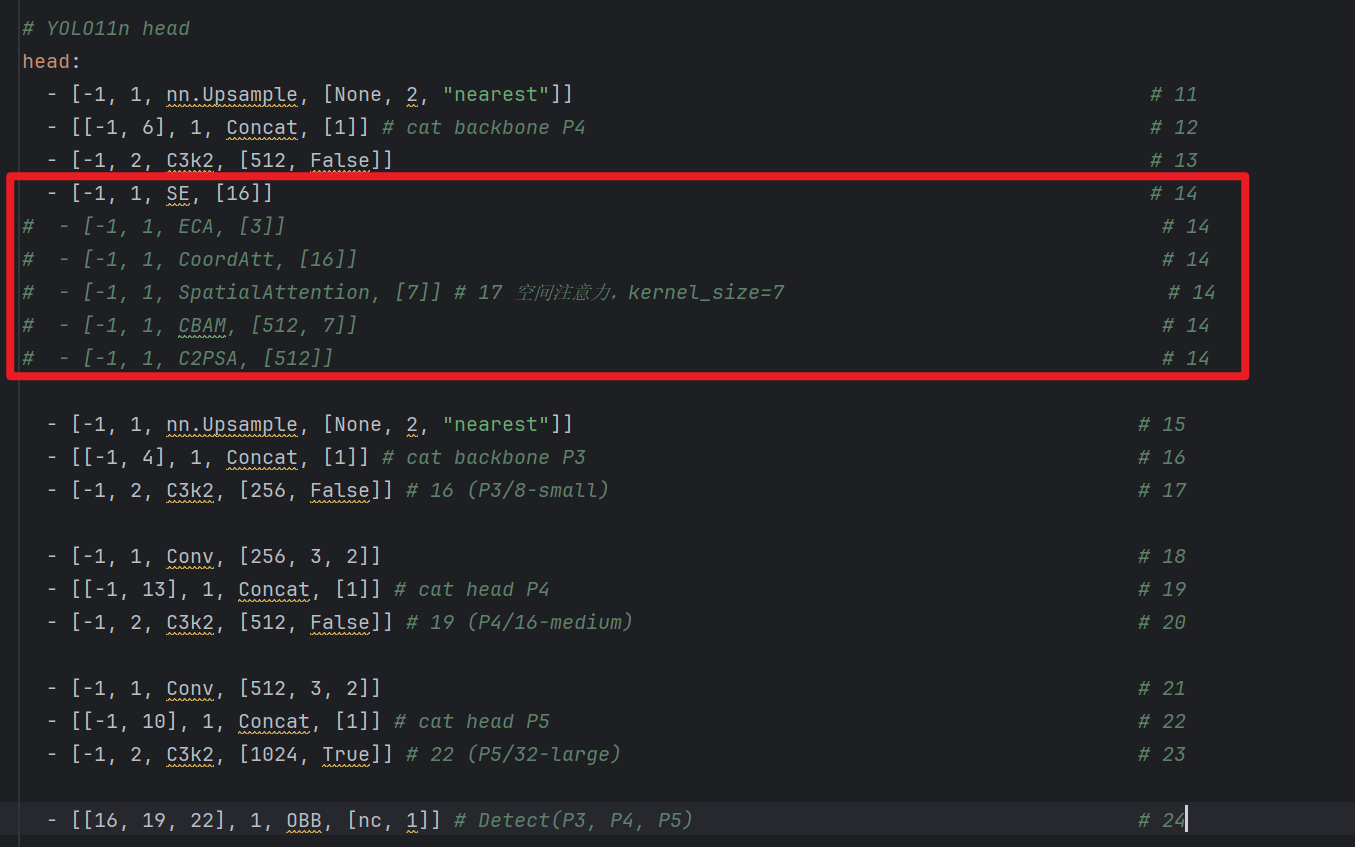
- 1、插入到【捕捉最大尺寸】检测头的【上采样 + concat + C3k2】的【前面】
- 在这插注意力,就是在 “分流” 给检测头之前,先给 “水流” 做一次 “过滤”和“加压”。如果最大尺寸层的特征被精炼了,那么下游的检测头拿到的东西质量都会变高。
- 说人话就是:我们要在最大尺寸的图片中用【注意力】捕捉细节!!!
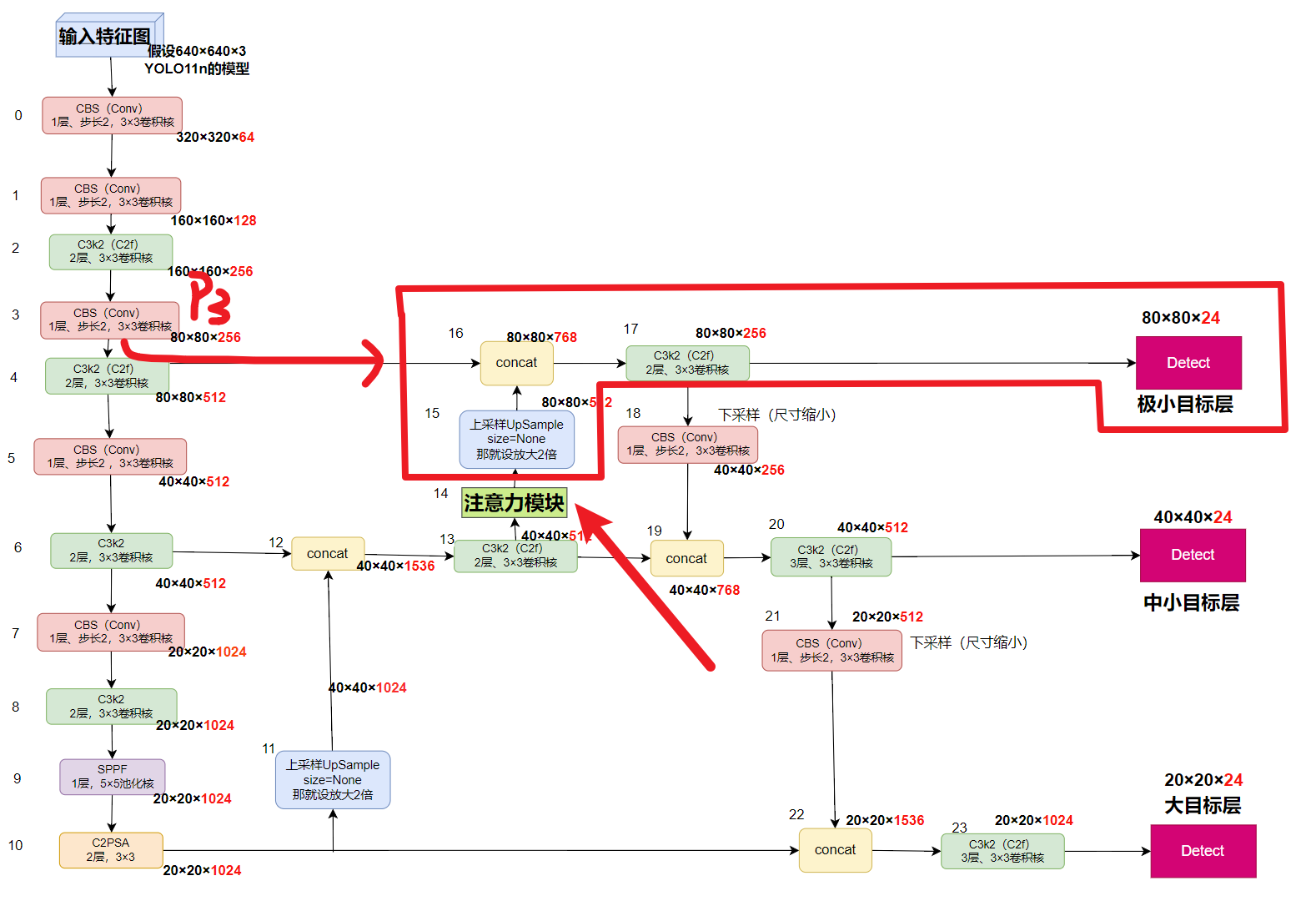
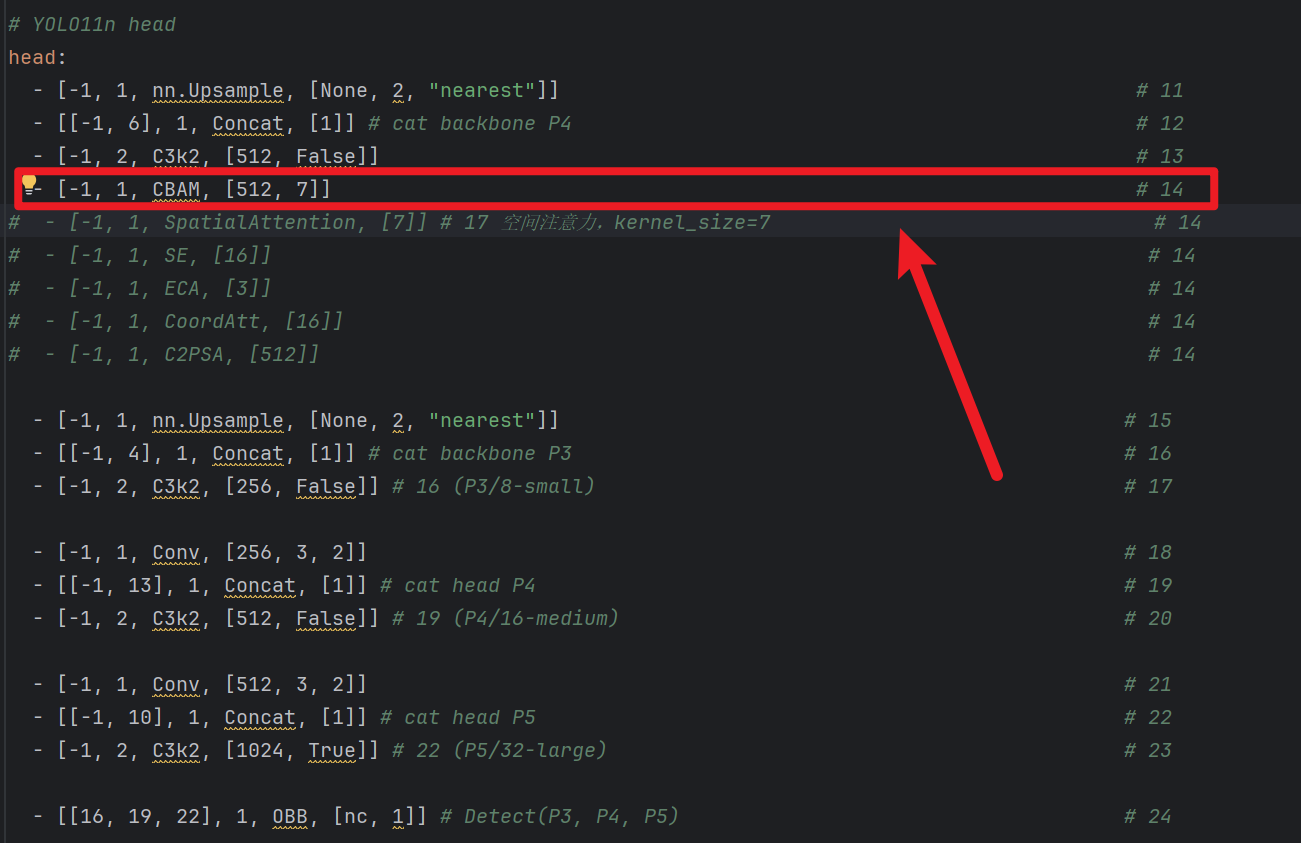
- 比如:你当前是3个检测层,那就插入到P3的【上采样 + concat + C3k2】的【前面】(就是第14层)
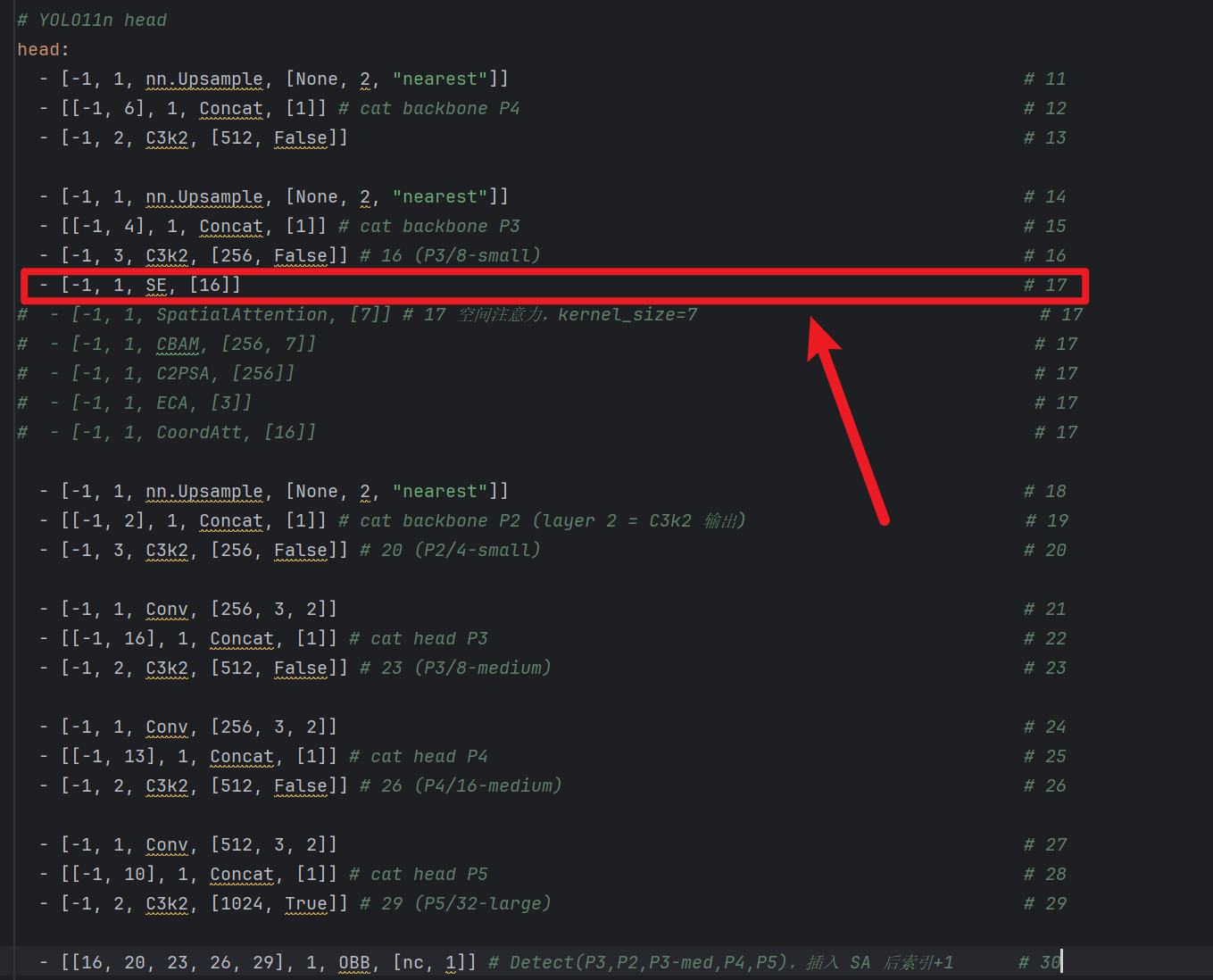
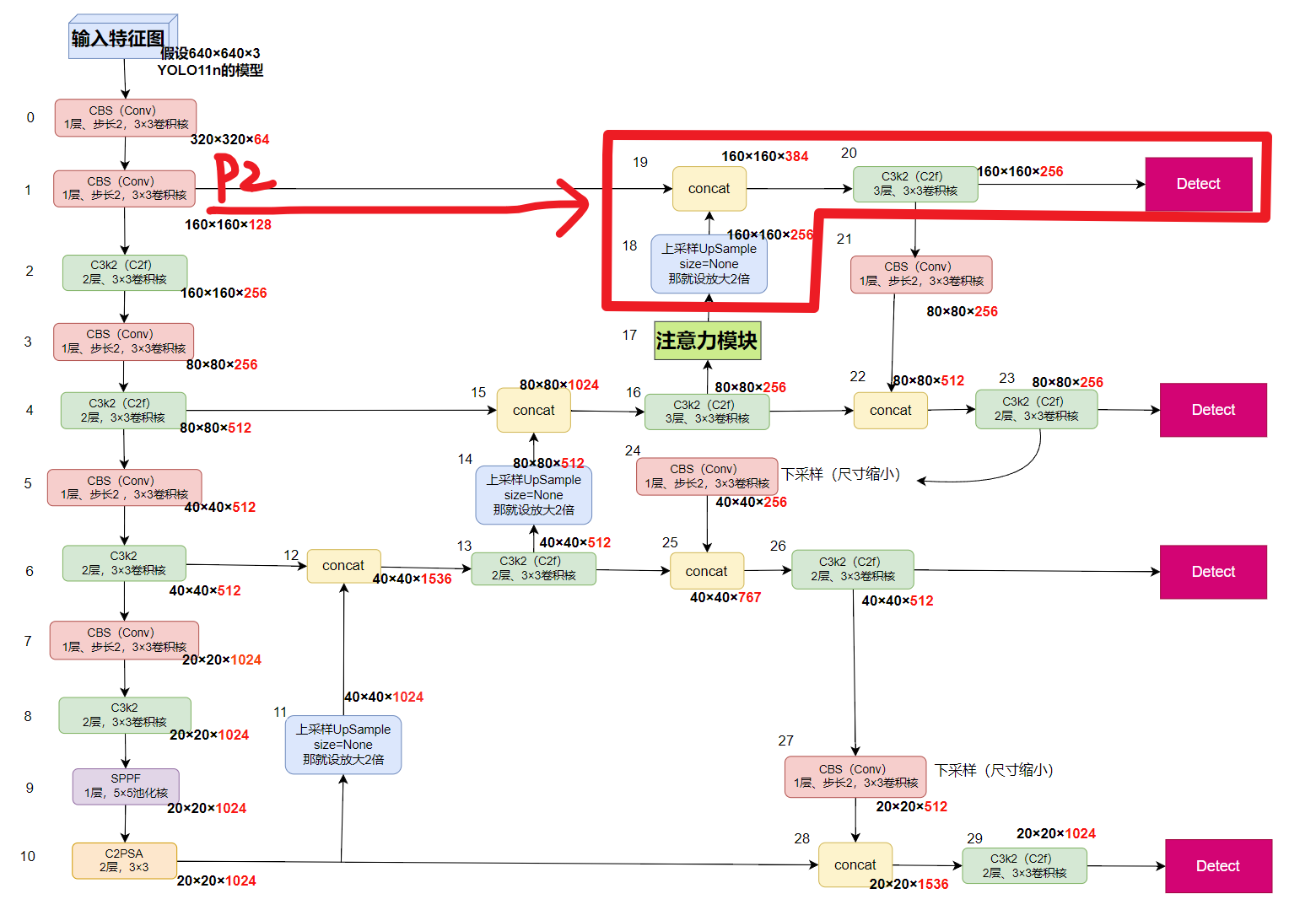
- 比如:你当前是4个检测层,那就插入到P2的【上采样 + concat + C3k2】的【前面】(就是第17层)
- 2、SE后面只用填一个参数:[16]
- 代表的是【压缩比:reduction=16】,不用管为什么,这就是默认的

2、CBAM模块
因为YOLO官方有相关代码,只不过没有引入,所以我们可以用官方的代码引入、也可以自己写,两种方式使用!
1)导入【CBAM】模块
【直接用官方给的CBAM模块(推荐)】
去到你的ultralytics安装路径下:
- windows本地路径:
- 去你pycharm下面点开 “外部库 / site-packages / ultralytics / nn / modules”,
- 或者在我的电脑的 “你的conda安装目录 / envs / 你当前虚拟环境目录 / Lib / site-packages / ultralytics / nn / modules”
- 如果用autodl服务器的linux系统下路径:“ / root / miniconda3 / envs / 你的虚拟环境目录 / lib / pythonx.x / site-packages / ultralytics / nn / modules”
- 查找【conv.py】有无该模块
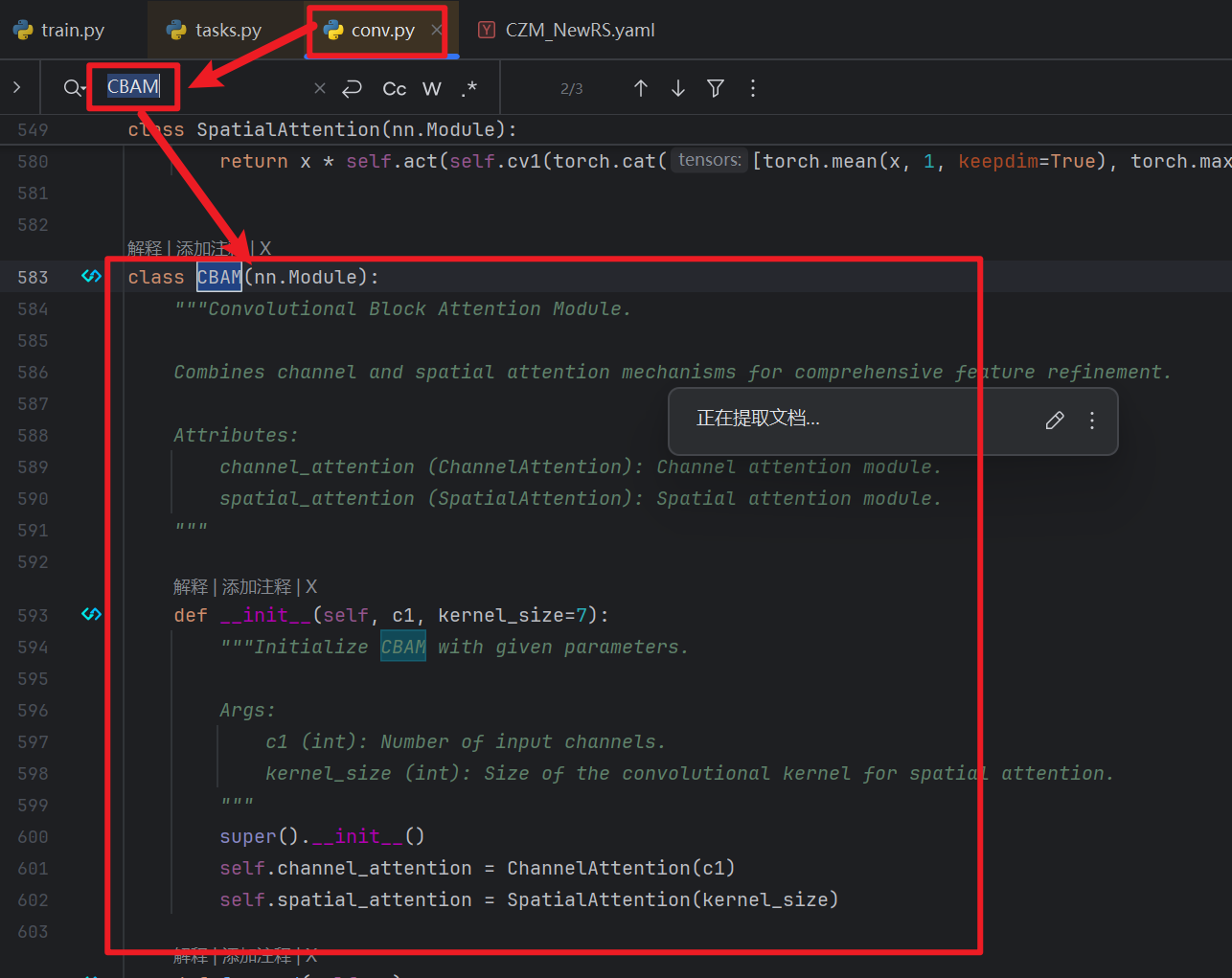
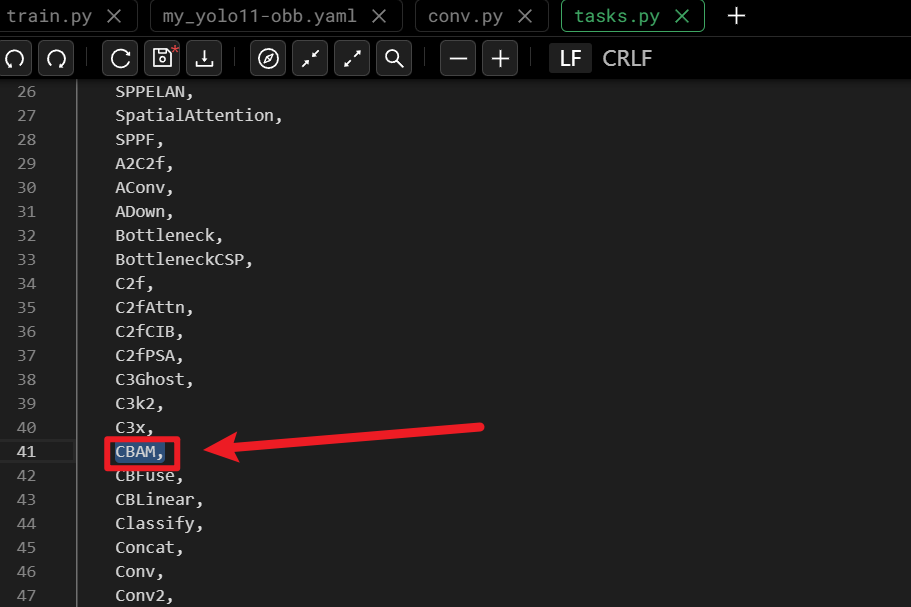
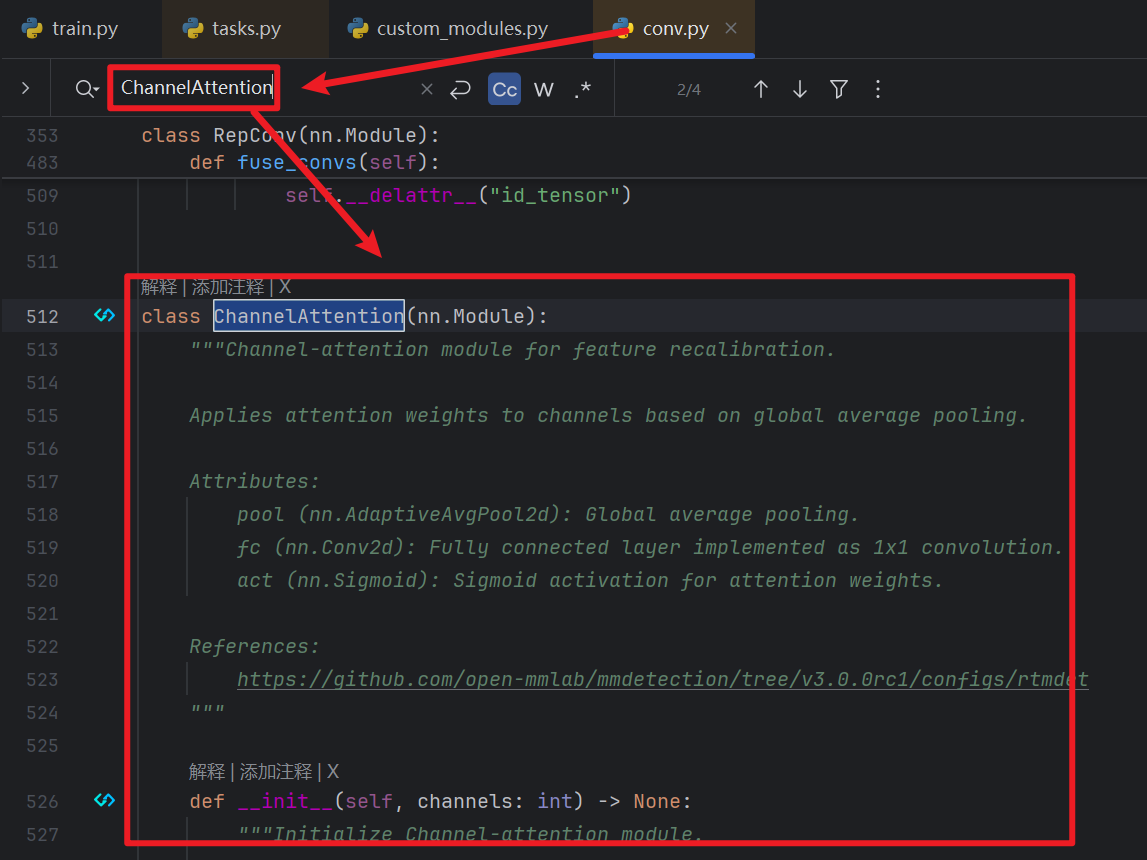
- 找到ultralytics的 nn / models目录后,可以看到一个【conv.py】文件,这个文件就是定义了各个模块,我们可以【Ctrl + F】查找一下有没有CBAM这个模块
- 如果有CBAM模块,那么我们继续在ultralytics的 nn目录下找到【task.py】文件
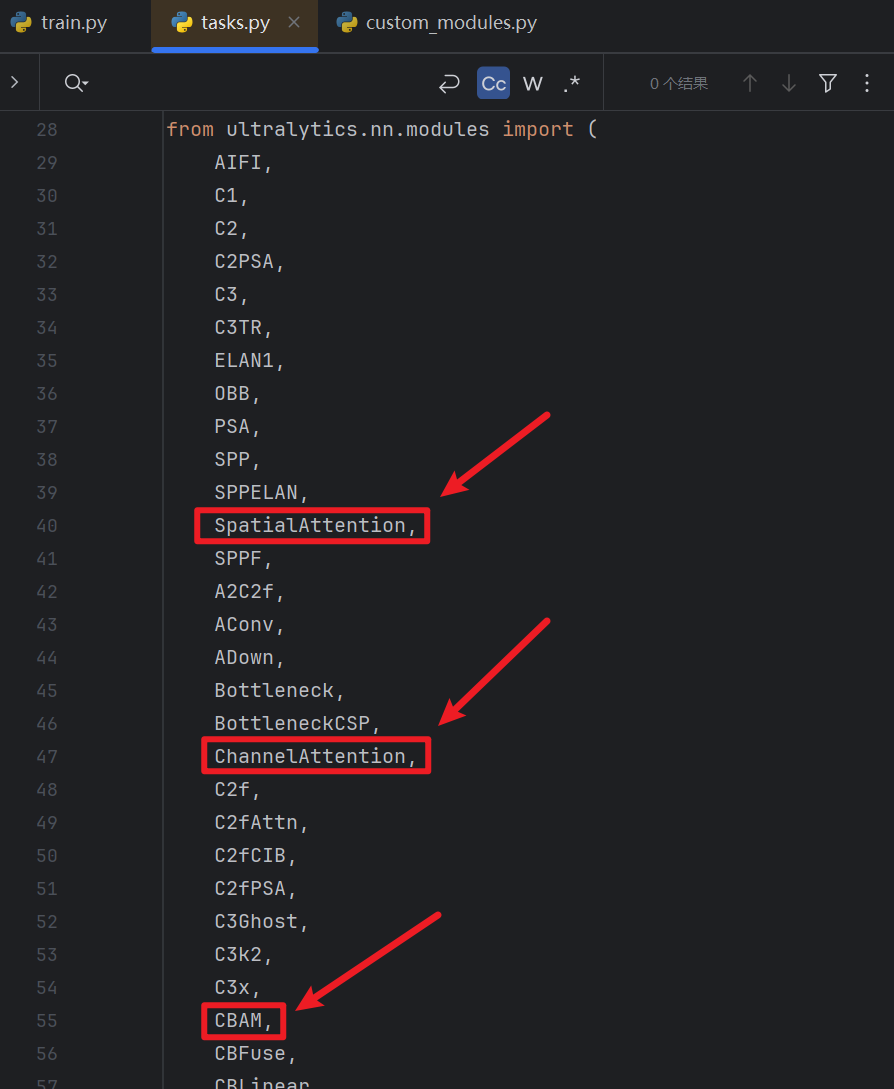
- 然后在代码前面 from ultralytics.nn.modules import (......)里面加上【CBAM】,这样task.py才可以用到ultralytics的 nn / models / conv.py的CBAM模块
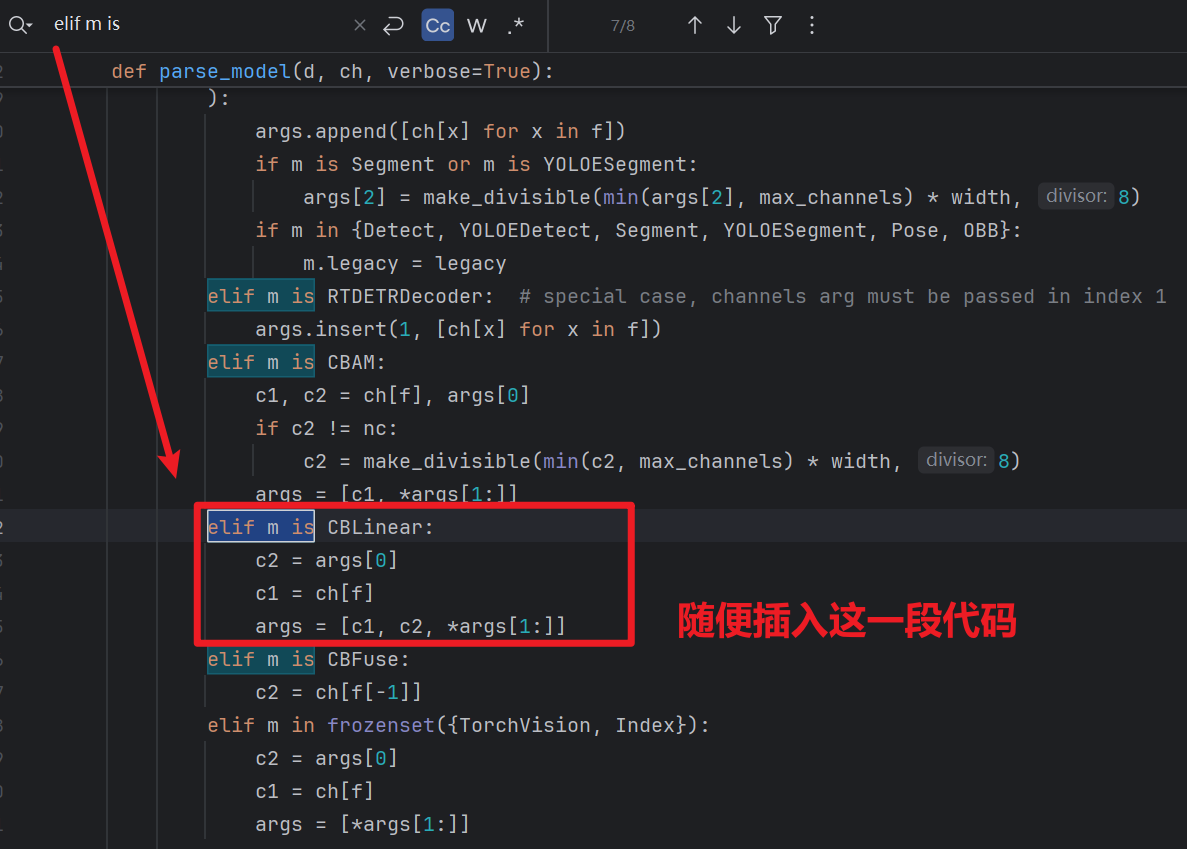
- 然后还是在task.py,【Ctrl + F】查找一下 “elif m is”就能找到下图这么一块地方
- 然后插入一段代码,一定要补上不然会报错!!!:
elif m is CBLinear: c2 = args[0] c1 = ch[f] args = [c1, c2, *args[1:]]
【自定义手写CBAM模块(想懂原理可以试试)】
有的ultralytics包可能特殊点,conv.py里没有CBAM这玩意,那就只能我们自己手写了
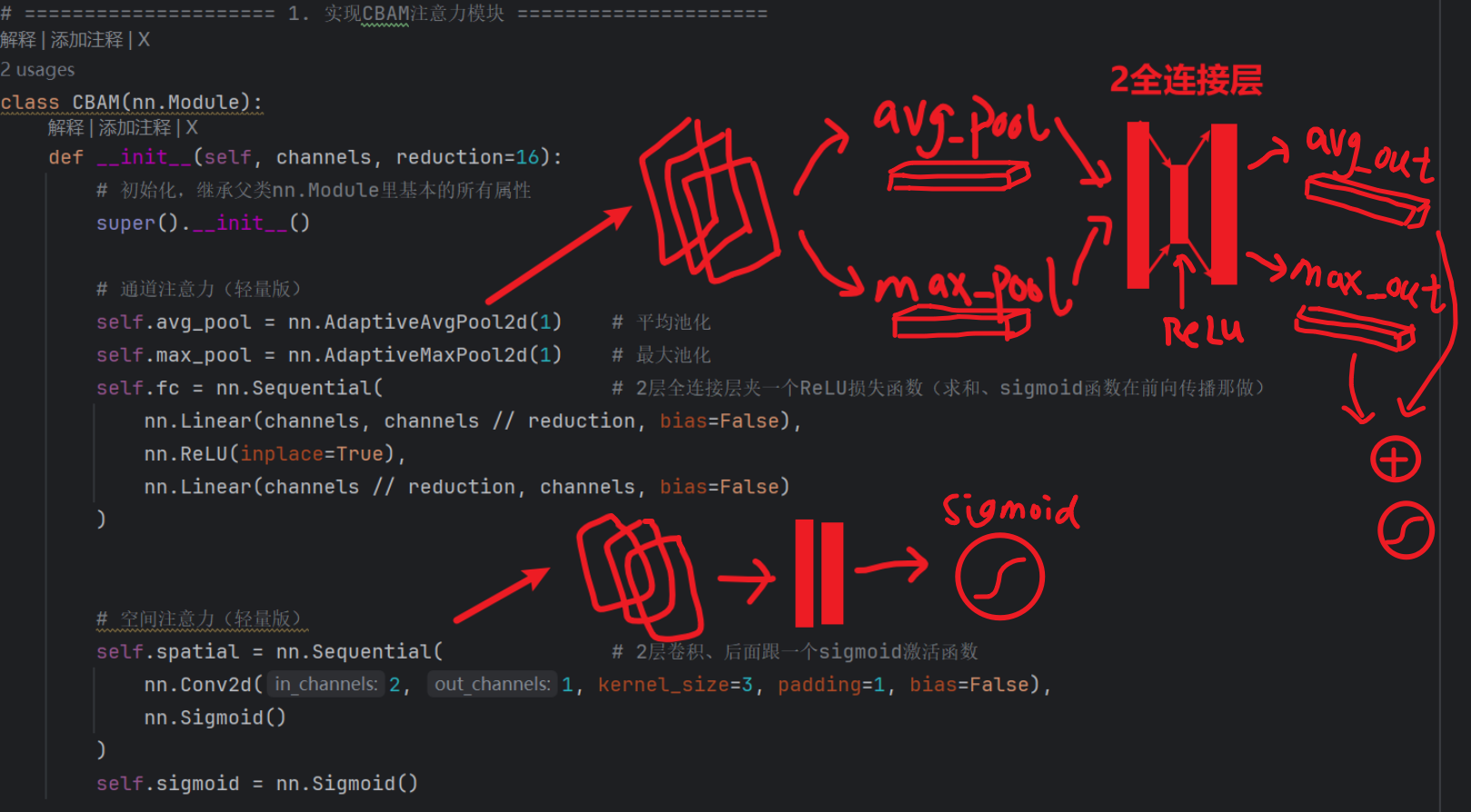
回到上面我给的CBAM结构图,只要记住了CBAM的结构,就可以创建一个CBAM模块了(就是背 “前人” 定义好的结构就行):
- 1、通道注意力:
- 平均池化 + 最大池化 + 2个全连接层夹1个损失函数
- 2、空间注意力:
- 1个卷积 + sigmoid激活函数
- 最后,在【train.py】代码注入CBAM
- 因为我们写的自定义CBAM模块不在ultralytics源码里,我们要加载它,就需要先在运行train.py的时候,把它注入task.py里
(具体代码我会放在在最后,可以直接复制拿去直接用)
然后自定义代码模块注入记得做,前面SE模块写过了。。。。。
2)yaml网络结构插入
提醒:【注意力模块】不改变通道数!!!!!!!
那么我们应该插到哪?怎么插呢?————根【SE】一样!
- 1、插入到【捕捉最大尺寸】检测头的【上采样 + concat + C3k2】的【前面】
- 比如:你当前是3个检测层,那就插入到P3的【上采样 + concat + C3k2】的【前面】(就是第14层)
- SpatialAttention和CBAM同理
- 2、后面的参数怎么填
- CBAM后面参数:[? , ?]
- 第一个代表【通道数】,那么上一行是多少他就照抄就行,因为【注意力模块】不改变通道数!!
- 第二个代表【卷积核数量】,一般默认7
- SpatialAttention后面参数[?]
- 代表【卷积核数量】,一般默认7
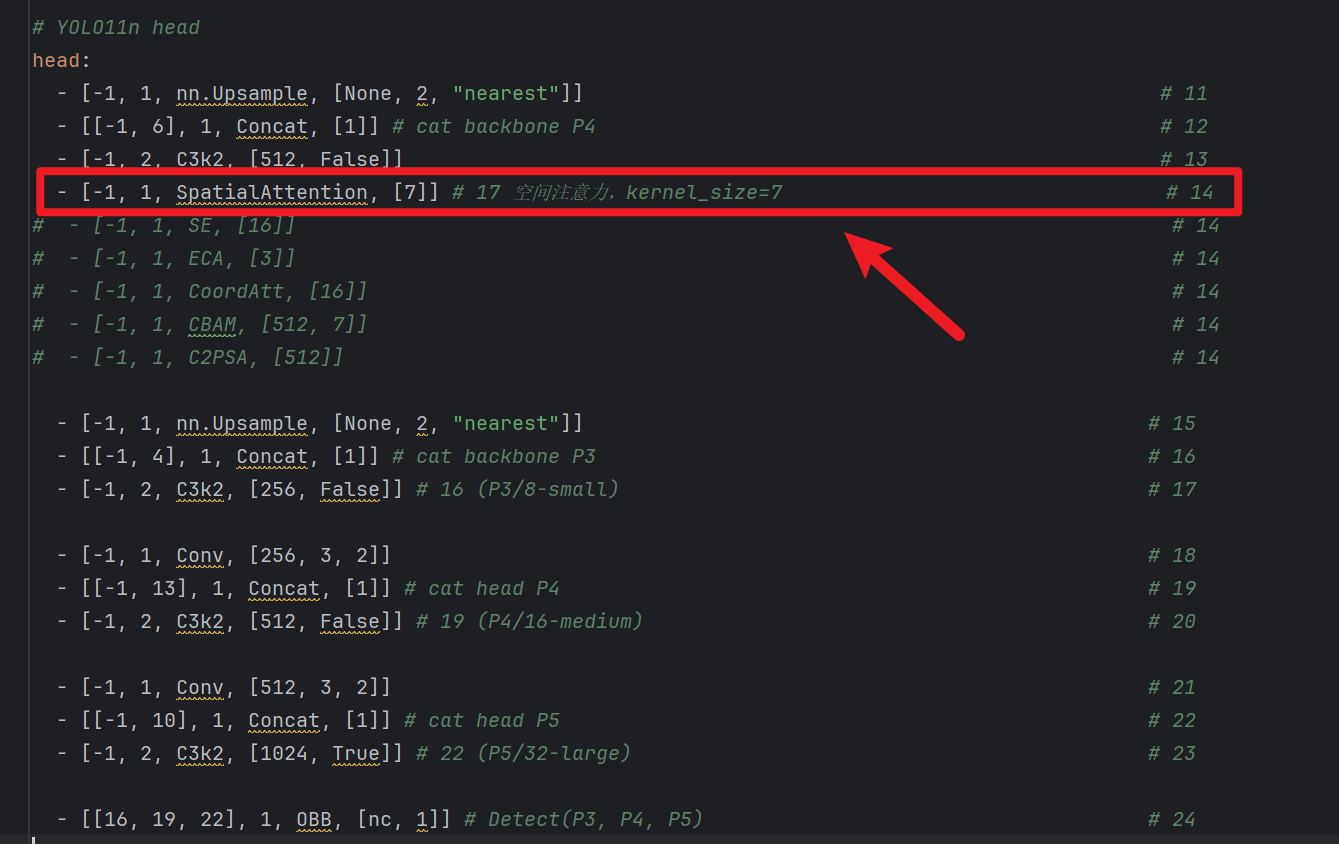


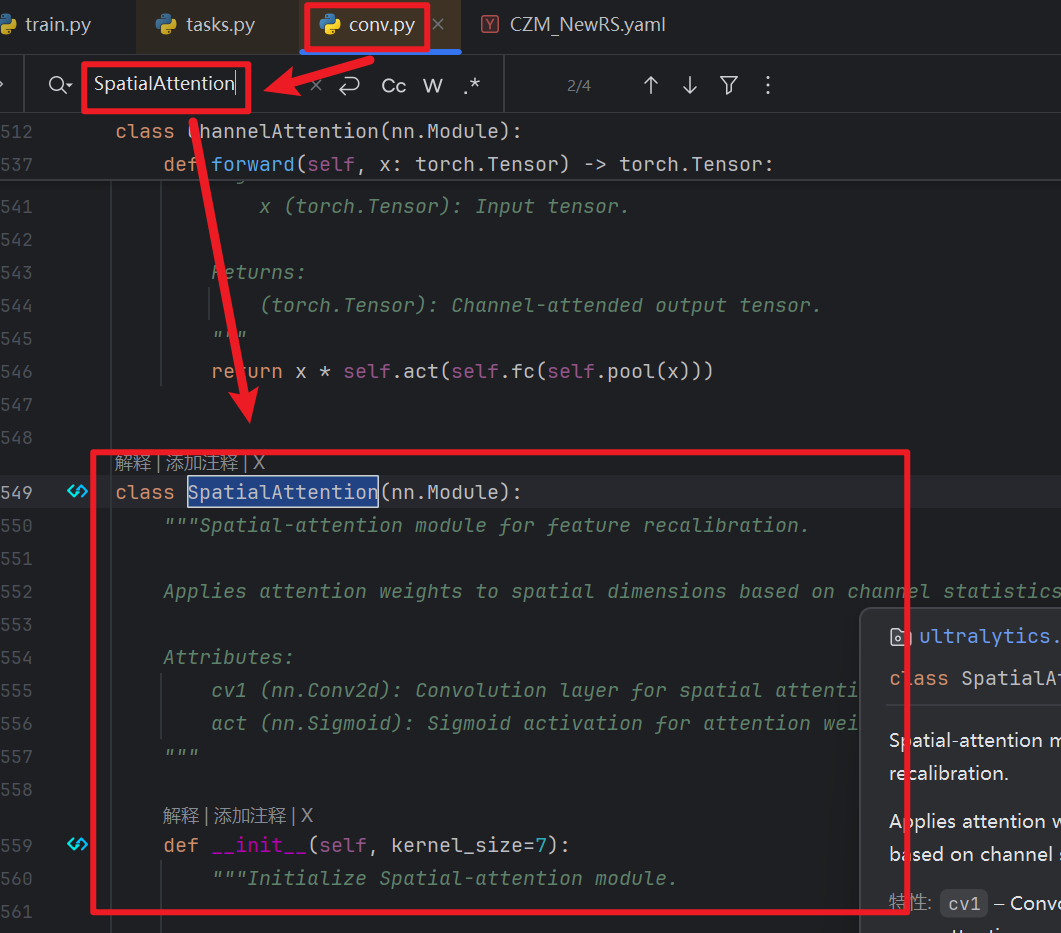
3)拓展:单独拆出【通道注意力】和【空间注意力】
这里我当时咨询chatGPT的时候,我说的是想要单独加强【空间定位】的注意力,他一开始是把【空间注意力:SpatialAttention】拆出来了来训练的,所以我单独研究了一下,CBAM的【通道注意力】和【空间注意力】是可以单独分为两个注意力模块使用的
【使用方法】:
- 1、yolo官方在【conv.py】写了这两个注意力模块的
- 2、那么直接像CBAM一样插入【task.py】就行了,只需要在开头导入这一步就够了
- 然后如果要手动自己写代码,结构上会有少许区别:
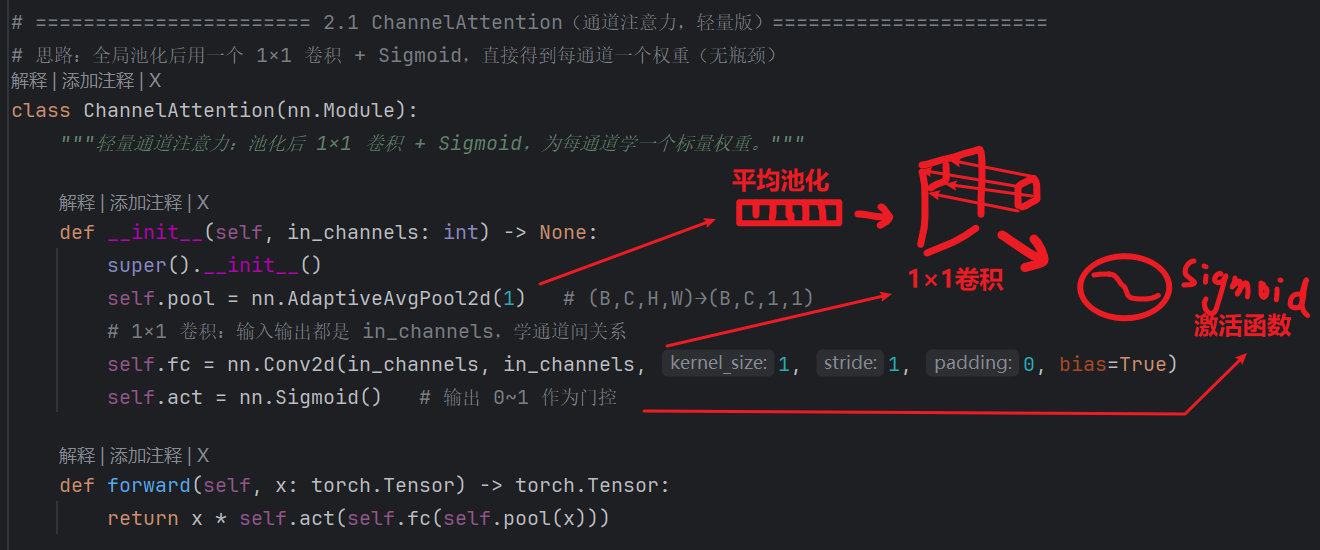
- 【通道注意力ChannelAttention】:
- CBAM的通道注意力部分采用标准的论文结构:双路池化 + 两层全连接层 + 相加 + Sigmoid
- 而YOLO单独拆出来的ChannelAttention是 “轻量版”:单路池化 + 一层卷积 + Sigmoid
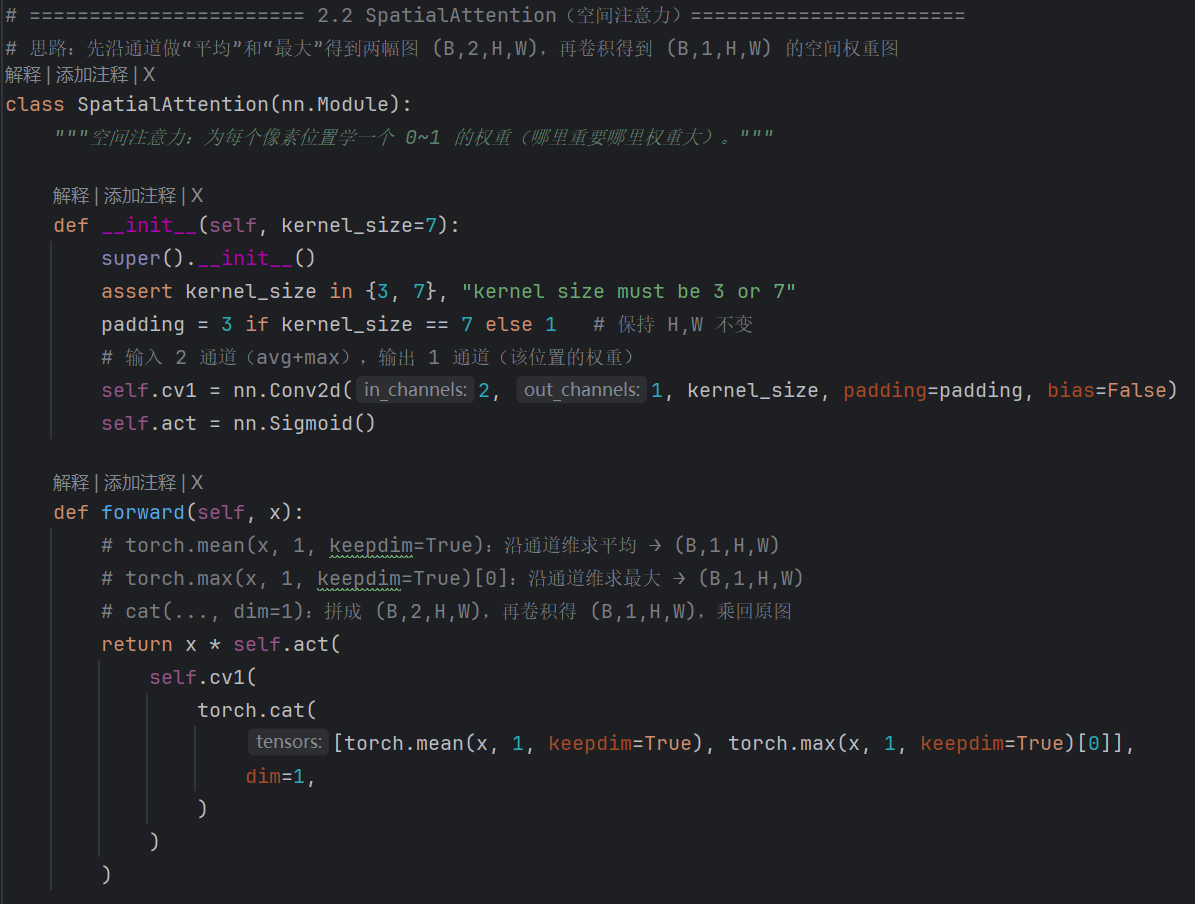
- 【空间注意力SpatialAttention】:
- 结构上倒是没有太大区别,只不过写法有点区别
- 但是这里我没有仔细介绍是因为,前面说过,不管是单独使用【通道注意力ChannelAttention】、还是单独使用【空间注意力SpatialAttention】,效果都并没有明显变好!!!!只有像CBAM那样【先“ChannelAttention” 再“SpatialAttention”】的注意力效果才有用!!!!
3、ECA模块
1)导入【ECA】模块
YOLO依旧没有这块代码,需要我们自己手写:
- 1、先在自定义模块脚本写他的代码:
- 解析模块有点烦了,各位自己根据图片和注释自己看吧
2、【注意:一定要做!!!!】
- 和SE一样,自定义模块还需要从【train.py】前面注入:
- 对应task.py那,你注册的当前train.py路径为全局环境变量“XXX”,然后task.py才能获取XXX的时候读到train.py路径
import sys import os from pathlib import Path # 必须最先做:把项目根加入 path,后面 from utils.custom_modules 才能找到 # 前面的 _ 不是语法要求,只是命名习惯,用来表达“内部用 / 不想被当公开接口”的意思 _你设置的全局环境变量 = Path(__file__).resolve().parent if str(_你设置的全局环境变量) not in sys.path: sys.path.insert(0, str(_你设置的全局环境变量)) # 让 DDP 子进程继承到 os.environ["你设置的全局环境变量"] = str(_你设置的全局环境变量)- task.py能读到train.py后,再把我们自定义的模块注入
# 让 yaml 里能使用自定义的 SE、ECA、CoordAtt(必须在 import YOLO 之前注入到 tasks) import ultralytics.nn.tasks as _ultra_tasks from utils.custom_modules import SE, ECA, CoordAtt _ultra_tasks.SE = SE _ultra_tasks.ECA = ECA _ultra_tasks.CoordAtt = CoordAtt
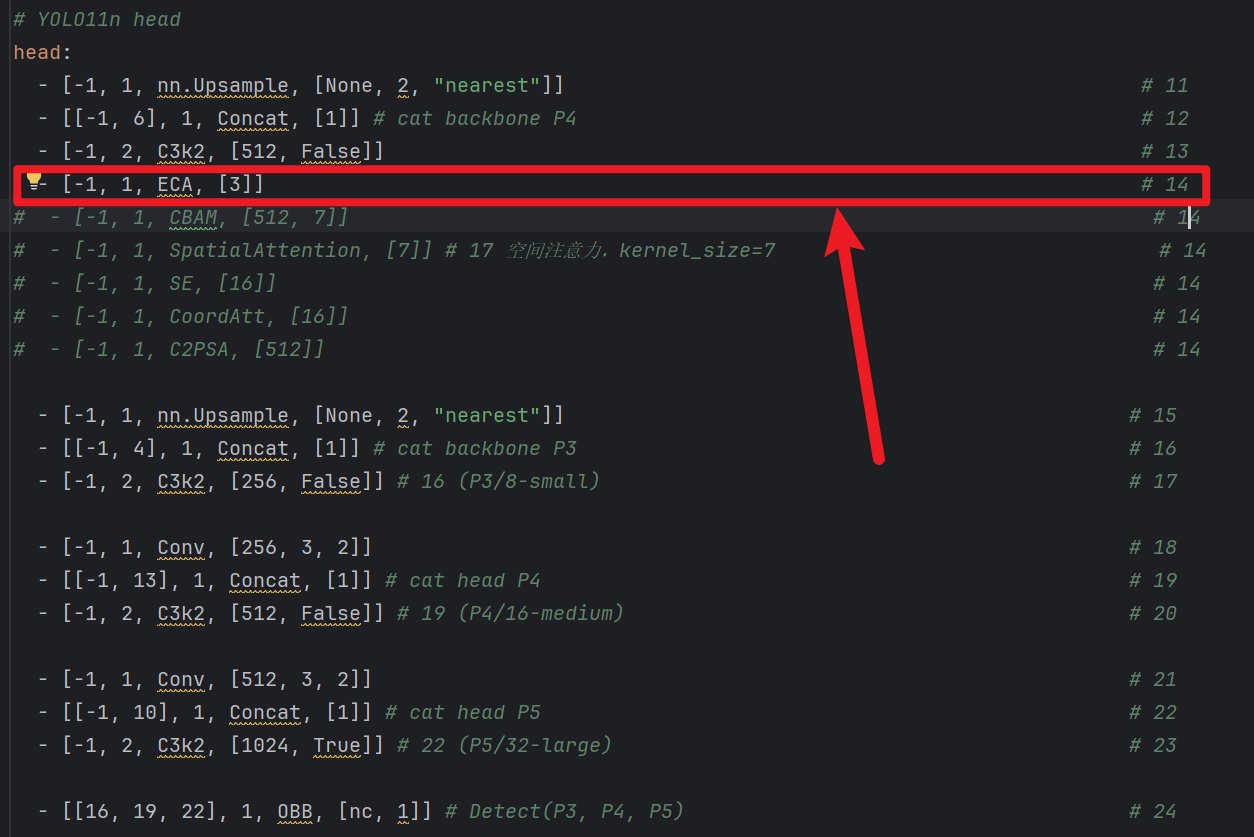
2)yaml网络结构插入
提醒:【注意力模块】不改变通道数!!!!!!!
那么我们应该插到哪?怎么插呢?
- 还是跟上面模块原理一样
- 后面的参数怎么填
- ECA后面参数:[3]
- 代表【1D局部卷积核数量】,一般默认3

4、Coordinate Attention模块
1)导入【ECA】模块
YOLO依旧没有这块代码,需要我们自己手写:
- 1、先在自定义模块脚本写他的代码:
- 解析模块有点烦了,各位自己根据图片和注释自己看吧
2、【注意:一定要做!!!!】
- 和SE一样,自定义模块还需要从【train.py】前面注入:
- 对应task.py那,你注册的当前train.py路径为全局环境变量“XXX”,然后task.py才能获取XXX的时候读到train.py路径
import sys import os from pathlib import Path # 必须最先做:把项目根加入 path,后面 from utils.custom_modules 才能找到 # 前面的 _ 不是语法要求,只是命名习惯,用来表达“内部用 / 不想被当公开接口”的意思 _你设置的全局环境变量 = Path(__file__).resolve().parent if str(_你设置的全局环境变量) not in sys.path: sys.path.insert(0, str(_你设置的全局环境变量)) # 让 DDP 子进程继承到 os.environ["你设置的全局环境变量"] = str(_你设置的全局环境变量)- task.py能读到train.py后,再把我们自定义的模块注入
# 让 yaml 里能使用自定义的 SE、ECA、CoordAtt(必须在 import YOLO 之前注入到 tasks) import ultralytics.nn.tasks as _ultra_tasks from utils.custom_modules import SE, ECA, CoordAtt _ultra_tasks.SE = SE _ultra_tasks.ECA = ECA _ultra_tasks.CoordAtt = CoordAtt

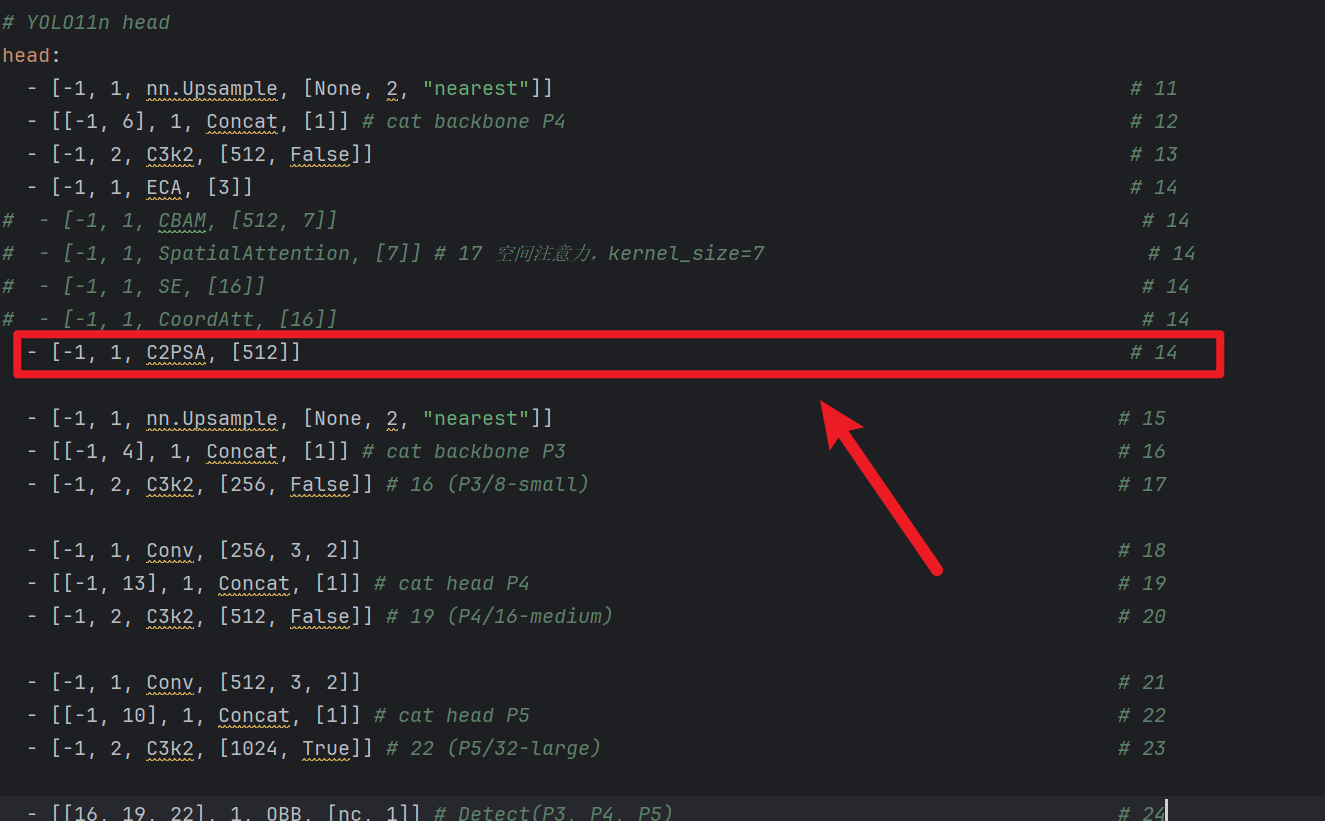
2)yaml网络结构插入
提醒:【注意力模块】不改变通道数!!!!!!!
那么我们应该插到哪?怎么插呢?
- 还是跟上面模块原理一样
- 后面的参数怎么填
- ECA后面参数:[16]
- 代表的是【压缩比:reduction=16】,不用管为什么,这就是默认的
总结
关于注入模块
- 目前yolo11只有ChannelAttention、SptailAttention、CBAM这三个注意力模块可以直接加入到task.py使用
- 其他的注意力模块需要我们手动编写,并在train.py开头注入
关于【yaml】部分插入
- 1、位置你就记着要么插14行、要么17行,就这么简单就完事了
- 2、参数部分:
- 要填【通道数】得模块直接抄上一行的、
- 压缩比例reduction固定16、
- 1d卷积固定3、
- 2d卷积固定7就行了

四、完整代码:
1、我的train.py代码:
import sys import os from pathlib import Path # 必须最先做:把项目根加入 path,后面 from utils.custom_modules 才能找到 # 前面的 _ 不是语法要求,只是命名习惯,用来表达“内部用 / 不想被当公开接口”的意思 _MyProject_ROOT = Path(__file__).resolve().parent if str(_MyProject_ROOT) not in sys.path: sys.path.insert(0, str(_MyProject_ROOT)) # 让 DDP 子进程继承到 os.environ["MyProject_ROOT"] = str(_MyProject_ROOT) import torch from ultralytics import YOLO # 让 yaml 里能使用自定义的 SE、ECA、CoordAtt(必须在 import YOLO 之前注入到 tasks) import ultralytics.nn.tasks as _ultra_tasks from utils.custom_modules import SE, ECA, CoordAtt _ultra_tasks.SE = SE _ultra_tasks.ECA = ECA _ultra_tasks.CoordAtt = CoordAtt # ⚠️ 注意:AutoDL是Linux环境,路径要改!把数据上传到 /root/autodl-tmp/ 下(强烈建议放这里,读写快) # 我们的数据集yaml DATA_YAML_PATH = "F:\我自己的毕设\YOLO_study\CZM_NewRS\CZM_NewRS.yaml" # 我们自定义的网络模型yaml MODEL_YAML = "my_yaml/11/my_yolo11-obb.yaml" # 我们的load加载的模型权重 MODEL_PATH = "yolo11n-obb.pt" if __name__ == '__main__': # Linux下通常不需要 freeze_support,但留着也不报错 torch.multiprocessing.freeze_support() # 加载模型,建议load换成 s (Small) 或 m (Medium) 模型,AutoDL显卡完全跑得动,精度比n高很多 model = YOLO(MODEL_YAML).load(MODEL_PATH) results = model.train( data=DATA_YAML_PATH, epochs=100, # 多跑一点,100轮对于从头练可能刚收敛 patience=60, # 60轮不提升就停,省点钱 imgsz=1240, # 1280也可以,但1024是标准倍数,训练更稳 # 【速度拉满配置】 device=0, # ❗关键:开启双卡并行训练! batch=-1, # 如果设batch=16,则双卡合计32;设-1自动适配 workers=6, # 有40核CPU,大胆给!16-24都可以,数据加载飞快 # cache="ram", # ❗有180G内存,直接把数据全读进RAM,速度起飞! amp=True, # 混合精度训练,速度快显存占用少 # 【增强参数微调:适当即可,拒绝卡通画】 augment=True, hsv_h=0.015, # 色相微调,保持不变 hsv_s=0.3, # ❗降下来!原0.7太高,导致色彩过饱和像动画片 hsv_v=0.3, # ❗降下来!原0.4太高,导致对比度太强 # 【几何增强】 degrees=5.0, # 稍微给点旋转,OBB任务很需要 translate=0.05, # 稍微平移一下 scale=0.5, # 尺度缩放 perspective=0.0, # ✅ 必须0!透视太大,图片都变形了,0.0001都算大的 # 【Mosaic 策略】 mosaic=0.2, # 开启马赛克增强 mixup=0, # 给一点点混合,不要太多 copy_paste=0.0, # ✅ 先关掉(后面再开) close_mosaic=10, # ❗最后10轮关闭Mosaic即可,50轮太早了,浪费了增强效果 # 📉【损失函数权重】提高定位相关权重,不降分类(老师:定位还不够好) # 默认:box=7.5, cls=0.5, dfl=1.5。OBB 的 angle 已含在 box loss 里,无单独权重 box=10.0, # 提高边界框/定位损失权重(默认 7.5) dfl=2.0, # 提高 DFL 损失权重,利于框边更精细(默认 1.5) cls=0.5, # 分类权重保持不变,不降低 # 📉【优化器】 optimizer='SGD', # 这种大数据集,SGD通常比AdamW后期泛化更好 lr0=0.01, lrf=0.01, cos_lr=True, # 余弦退火学习率,训练更丝滑 )
2、我的yolo11.yaml代码
3层检测目标层情况(仅head部分)
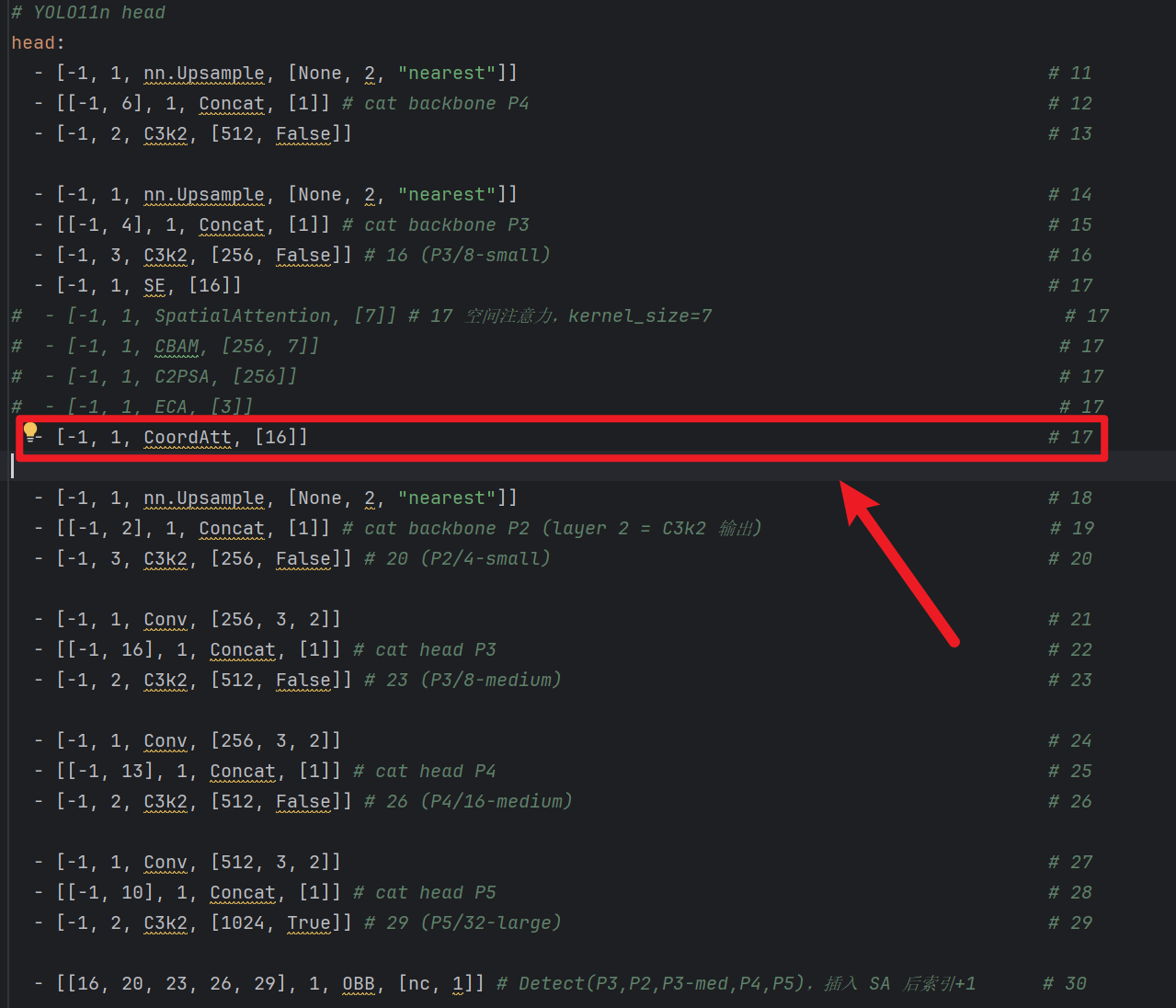
# YOLO11n head head: - [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 11 - [[-1, 6], 1, Concat, [1]] # cat backbone P4 # 12 - [-1, 2, C3k2, [512, False]] # 13 - [-1, 1, ECA, [3]] # 14 # - [-1, 1, CBAM, [512, 7]] # 14 # - [-1, 1, SpatialAttention, [7]] # 17 空间注意力,kernel_size=7 # 14 # - [-1, 1, SE, [16]] # 14 # - [-1, 1, CoordAtt, [16]] # 14 - [-1, 1, C2PSA, [512]] # 14 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 15 - [[-1, 4], 1, Concat, [1]] # cat backbone P3 # 16 - [-1, 2, C3k2, [256, False]] # 16 (P3/8-small) # 17 - [-1, 1, Conv, [256, 3, 2]] # 18 - [[-1, 13], 1, Concat, [1]] # cat head P4 # 19 - [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium) # 20 - [-1, 1, Conv, [512, 3, 2]] # 21 - [[-1, 10], 1, Concat, [1]] # cat head P5 # 22 - [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large) # 23 - [[16, 19, 22], 1, OBB, [nc, 1]] # Detect(P3, P4, P5) # 244层检测目标层情况(仅head部分)
# YOLO11n head head: - [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 11 - [[-1, 6], 1, Concat, [1]] # cat backbone P4 # 12 - [-1, 2, C3k2, [512, False]] # 13 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 14 - [[-1, 4], 1, Concat, [1]] # cat backbone P3 # 15 - [-1, 3, C3k2, [256, False]] # 16 (P3/8-small) # 16 - [-1, 1, SE, [16]] # 17 # - [-1, 1, SpatialAttention, [7]] # 17 空间注意力,kernel_size=7 # 17 # - [-1, 1, CBAM, [256, 7]] # 17 # - [-1, 1, C2PSA, [256]] # 17 # - [-1, 1, ECA, [3]] # 17 - [-1, 1, CoordAtt, [16]] # 17 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 18 - [[-1, 2], 1, Concat, [1]] # cat backbone P2 (layer 2 = C3k2 输出) # 19 - [-1, 3, C3k2, [256, False]] # 20 (P2/4-small) # 20 - [-1, 1, Conv, [256, 3, 2]] # 21 - [[-1, 16], 1, Concat, [1]] # cat head P3 # 22 - [-1, 2, C3k2, [512, False]] # 23 (P3/8-medium) # 23 - [-1, 1, Conv, [256, 3, 2]] # 24 - [[-1, 13], 1, Concat, [1]] # cat head P4 # 25 - [-1, 2, C3k2, [512, False]] # 26 (P4/16-medium) # 26 - [-1, 1, Conv, [512, 3, 2]] # 27 - [[-1, 10], 1, Concat, [1]] # cat head P5 # 28 - [-1, 2, C3k2, [1024, True]] # 29 (P5/32-large) # 29 - [[16, 20, 23, 26, 29], 1, OBB, [nc, 1]] # Detect(P3,P2,P3-med,P4,P5),插入 SA 后索引+1 # 30
3、我的自定义注意力模块代码(包含所有注意力模块)
""" 自定义注意力模块(SE / ECA / CoordAtt / Channel / Spatial / CBAM) 用于 YOLO 等检测网络的 backbone 或 head,增强通道或空间上的重要特征。 【常用名词速查】 - in_channels:输入通道数(本文件已统一用此名)。c_ / mid_channels:中间压缩后的通道数(如 in_channels//r),不是输入 - // :整除(向下取整),例如 256//16=16,用来做“压缩比” - self.fc / self.gate:可学习的子网络;gate 一般指“门控”,输出 0~1 的权重 - squeeze(dim):去掉大小为 1 的维度;transpose:交换维度顺序;view:拉成指定形状 【若自己按逻辑写】 - SEnet:先全局平均池化得到每通道一个数 → 两层“全连接”(降维再升维)→ Sigmoid 得到权重 → 乘回原图。 - ChannelAttention:池化后一个 1×1 卷积 + Sigmoid,直接得到每通道权重(无瓶颈)。 - SpatialAttention:沿通道做 mean 和 max 得到两幅 (1,H,W),拼成 (2,H,W) → 卷积得到 (1,H,W) 权重图 → 乘回原图。 【nn.Conv2d 参数速查】 nn.Conv2d(输入通道, 输出通道, kernel_size, stride=1, padding=0, bias=...) - 第1个参数:输入通道数(输入特征图有几层“通道”)。 - 第2个参数:输出通道数(卷积后得到几层通道)。 - 第3个参数:卷积核大小(如 1 表示 1×1,只做通道混合、不改变 H,W;3 或 7 表示 3×3、7×7)。 - stride:步长,默认 1(不缩小尺寸)。 - padding:四周补零圈数,通常取 (kernel_size-1)//2 使 H、W 不变。 - bias:是否加偏置,True/False。 """ # ---------- 下面这些你可能会碰到的写法简要说明 ---------- # a // b :整除,结果向下取整。如 7//2=3,256//16=16。用来算“压缩后通道数”。 # self.fc :通常指全连接/线性层(或 1×1 卷积),这里用来学“通道权重”或做降维。 # self.gate :门控,一般接 Sigmoid,输出 (0,1),表示“保留多少”。 # .squeeze(-1):去掉最后一维且大小为 1 的维度;(B,C,1,1) → (B,C,1)。 # .transpose(1,2):交换第 1、2 维;(B,C,1) → (B,1,C),方便 Conv1d 在 C 维上卷积。 # .view(b,c) :把张量拉成 (b,c) 形状,不改变元素总数;常用于池化后喂给 Linear。 # .permute(0,1,3,2):按给定顺序重排维度,这里相当于把 dim=2 和 dim=3 互换。 import torch import torch.nn as nn # ============================ 1. SE(Squeeze-and-Excitation)============================ # 思路:对每个通道做“全局池化 → 两层全连接 → 得到该通道的权重”再乘回原特征 class SE(nn.Module): """Squeeze-and-Excitation:通道注意力,为每个通道学一个 0~1 的权重。""" # r 是“压缩比”(reduction ratio),用来算中间层的通道数 def __init__(self, in_channels, r=16): super().__init__() # in_channels // r:中间层通道数(压缩比)。 # max(1, ...) 第一个参数1,是为了防止r过大时mid_channels变成 0,至少也得是1,参数里取最大 mid_channels = max(1, in_channels // r) self.pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化:(B,C,H,W)→(B,C,1,1),每个通道一个数 self.fc1 = nn.Conv2d(in_channels, mid_channels, 1, bias=True) # 降维 in_channels → mid_channels self.act = nn.SiLU() # SiLU或ReLU都可以 self.fc2 = nn.Conv2d(mid_channels, in_channels, 1, bias=True) # 升回 mid_channels → in_channels self.gate = nn.Sigmoid() # 激活函数:把输出压到 (0,1) def forward(self, x): w = self.pool(x) # (B,C,H,W)→(B,C,1,1) w = self.fc2(self.act(self.fc1(w))) # 瓶颈结构:C → mid_channels → C return x * self.gate(w) # 逐通道缩放,重要通道权重大 # ======================= 2.1 ChannelAttention(通道注意力,轻量版)======================= # 思路:全局池化后用一个 1×1 卷积 + Sigmoid,直接得到每通道一个权重(无瓶颈) class ChannelAttention(nn.Module): """轻量通道注意力:池化后 1×1 卷积 + Sigmoid,为每通道学一个标量权重。""" def __init__(self, in_channels: int) -> None: super().__init__() self.pool = nn.AdaptiveAvgPool2d(1) # (B,C,H,W)→(B,C,1,1) # 1×1 卷积:输入输出都是 in_channels,学通道间关系 self.fc = nn.Conv2d(in_channels, in_channels, 1, 1, 0, bias=True) self.act = nn.Sigmoid() # 输出 0~1 作为门控 def forward(self, x: torch.Tensor) -> torch.Tensor: return x * self.act(self.fc(self.pool(x))) # ======================= 2.2 SpatialAttention(空间注意力)======================= # 思路:先沿通道做“平均”和“最大”得到两幅图 (B,2,H,W),再卷积得到 (B,1,H,W) 的空间权重图 class SpatialAttention(nn.Module): """空间注意力:为每个像素位置学一个 0~1 的权重(哪里重要哪里权重大)。""" def __init__(self, kernel_size=7): super().__init__() assert kernel_size in {3, 7}, "kernel size must be 3 or 7" padding = 3 if kernel_size == 7 else 1 # 保持 H,W 不变 # 输入 2 通道(avg+max),输出 1 通道(该位置的权重) self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.act = nn.Sigmoid() def forward(self, x): # torch.mean(x, 1, keepdim=True):沿通道维求平均 → (B,1,H,W) # torch.max(x, 1, keepdim=True)[0]:沿通道维求最大 → (B,1,H,W) # cat(..., dim=1):拼成 (B,2,H,W),再卷积得 (B,1,H,W),乘回原图 return x * self.act( self.cv1( torch.cat( [torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], dim=1, ) ) ) # ============================ 2.3 CBAM(通道+空间串联)============================ # 思路:先做通道注意力再做空间注意力,两段都用“avg+max → 小网络 → sigmoid”的形式 class CBAM(nn.Module): """CBAM = Channel + Spatial:先通道再空间,两段注意力串联。""" def __init__(self, in_channels, reduction=16, kernel_size=7): super().__init__() mid_channels = max(1, in_channels // reduction) # 通道注意力(轻量版) self.avg_pool = nn.AdaptiveAvgPool2d(1) # 平均池化,尺寸:[b,c,1,1] self.max_pool = nn.AdaptiveMaxPool2d(1) # 最大池化,尺寸:[b,c,1,1] self.fc = nn.Sequential( nn.Linear(in_channels, mid_channels, bias=False), nn.ReLU(inplace=True), nn.Linear(mid_channels, in_channels, bias=False), ) # 空间注意力(轻量版) self.spatial = nn.Sequential( # 2层卷积、后面跟一个sigmoid激活函数 nn.Conv2d(2, 1, kernel_size=3, padding=1, bias=False), nn.Sigmoid() ) self.sigmoid = nn.Sigmoid() # 开始【前向传播】学习 def forward(self, x): b, c, _, _ = x.shape # 通道注意力(获取平均池化值、最大池化值、求sigmoid函数值) # view(b, c):把 (B,C,1,1) 拉成 (B,C) 才能喂给 Linear avg_out = self.fc(self.avg_pool(x).view(b, c)).view(b, c, 1, 1) max_out = self.fc(self.max_pool(x).view(b, c)).view(b, c, 1, 1) x = x * self.sigmoid(avg_out + max_out) # 【求和】并用【sigmoid函数激活】 # 空间注意力(获取平均池化值、最大池化值、求sigmoid函数值) avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = x * self.sigmoid(self.spatial(torch.cat([avg_out, max_out], dim=1))) # 最后一次sigmoid激活 return x # ============================ 3. ECA(Efficient Channel Attention)============================ # 思路:不用全连接,用 1D 卷积在“通道维”上做局部交互,参数量小;需把 (B,C,1,1) 变成 (B,1,C) 才能用 Conv1d class ECA(nn.Module): """ECA:用一维卷积在通道维做局部建模,替代 SE 的全连接,更省参数。""" def __init__(self, in_channels, k=3): super().__init__() k = int(k) if k % 2 == 0: k += 1 # Conv1d 用奇数 kernel 方便两边 padding 相同 self.pool = nn.AdaptiveAvgPool2d(1) # (B,C,H,W)→(B,C,1,1) self.conv = nn.Conv1d(1, 1, kernel_size=k, padding=(k - 1) // 2, bias=False) self.gate = nn.Sigmoid() def forward(self, x): y = self.pool(x) # (B, C, 1, 1) # squeeze(-1):去掉最后一维 (B,C,1,1)→(B,C,1);transpose(1,2):1和2维互换→(B,1,C) # 这样 C 这一维变成 Conv1d 的“长度”,1 是通道维,才能用 nn.Conv1d(1,1,k) y = y.squeeze(-1).transpose(1, 2) # (B, 1, C) y = self.conv(y) # (B, 1, C) # 再变回 (B,C,1,1):transpose(1,2)→(B,C,1),unsqueeze(-1)→(B,C,1,1) y = self.gate(y).transpose(1, 2).unsqueeze(-1) return x * y # ============================ 4. CoordAtt(Coordinate Attention)============================ # 思路:沿 H、W 两个方向分别池化,得到“垂直方向”和“水平方向”的编码,再生成两路注意力图 a_h、a_w,乘回原图 class CoordAtt(nn.Module): """坐标注意力:沿高、宽方向分别池化并生成方向感知的注意力,适合长条/细长目标。""" def __init__(self, in_channels, r=16): super().__init__() mid_channels = max(8, in_channels // r) # (None, 1):高方向保留、宽压成 1 → (B,C,H,1);(1, None):宽保留、高压成 1 → (B,C,1,W) self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) self.pool_w = nn.AdaptiveAvgPool2d((1, None)) self.conv1 = nn.Conv2d(in_channels, mid_channels, 1, bias=False) self.bn1 = nn.BatchNorm2d(mid_channels) self.act = nn.SiLU() self.conv_h = nn.Conv2d(mid_channels, in_channels, 1, bias=False) # 生成“高方向”权重 self.conv_w = nn.Conv2d(mid_channels, in_channels, 1, bias=False) # 生成“宽方向”权重 self.gate = nn.Sigmoid() def forward(self, x): b, c, h, w = x.shape x_h = self.pool_h(x) # (B, C, H, 1) # permute(0,1,3,2):把 (B,C,1,W) 变成 (B,C,W,1),方便后面和 x_h 在 dim=2 上 cat x_w = self.pool_w(x).permute(0, 1, 3, 2) # (B, C, W, 1) y = torch.cat([x_h, x_w], dim=2) # (B, C, H+W, 1) y = self.act(self.bn1(self.conv1(y))) y_h, y_w = torch.split(y, [h, w], dim=2) # 再拆回高、宽两段 y_w = y_w.permute(0, 1, 3, 2) # (B, mid_channels, 1, W) a_h = self.gate(self.conv_h(y_h)) # (B, C, H, 1) a_w = self.gate(self.conv_w(y_w)) # (B, C, 1, W) return x * a_h * a_w # 广播相乘,得到带高、宽注意力的特征
4、我的task.py代码
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license import contextlib import pickle import re import types from copy import deepcopy from pathlib import Path import torch import torch.nn as nn # 自定义注意力 SE/ECA/CoordAtt:需让 Python 找到你项目下的 utils(项目根必须在 sys.path 里) # 方式1:train.py 最开头 sys.path.insert(0, 项目根) 再 import ultralytics # 方式2:设置环境变量 CZM_NEWRS_ROOT=项目根(如 F:\我自己的毕设\YOLO_study\CZM_NewRS),便于 DDP 子进程也能找到 import sys as _sys import os as _os _MyProject_ROOT = _os.environ.get("MyProject_ROOT") if _MyProject_ROOT and _MyProject_ROOT not in _sys.path: _sys.path.insert(0, _MyProject_ROOT) try: from utils.custom_modules import SE, ECA, CoordAtt _CUSTOM_ATTN = {SE, ECA, CoordAtt} except ImportError: _CUSTOM_ATTN = set() from ultralytics.nn.autobackend import check_class_names from ultralytics.nn.modules import ( AIFI, C1, C2, C2PSA, C3, C3TR, ELAN1, OBB, PSA, SPP, SPPELAN, SpatialAttention, SPPF, A2C2f, AConv, ADown, Bottleneck, BottleneckCSP, ChannelAttention, C2f, C2fAttn, C2fCIB, C2fPSA, C3Ghost, C3k2, C3x, CBAM, CBFuse, CBLinear, Classify, Concat, Conv, Conv2, ConvTranspose, Detect, DWConv, DWConvTranspose2d, Focus, GhostBottleneck, GhostConv, HGBlock, HGStem, ImagePoolingAttn, Index, LRPCHead, Pose, RepC3, RepConv, RepNCSPELAN4, RepVGGDW, ResNetLayer, RTDETRDecoder, SCDown, Segment, TorchVision, WorldDetect, YOLOEDetect, YOLOESegment, v10Detect, ) from ultralytics.utils import DEFAULT_CFG_DICT, LOGGER, YAML, colorstr, emojis from ultralytics.utils.checks import check_requirements, check_suffix, check_yaml from ultralytics.utils.loss import ( E2EDetectLoss, v8ClassificationLoss, v8DetectionLoss, v8OBBLoss, v8PoseLoss, v8SegmentationLoss, ) from ultralytics.utils.ops import make_divisible from ultralytics.utils.patches import torch_load from ultralytics.utils.plotting import feature_visualization from ultralytics.utils.torch_utils import ( fuse_conv_and_bn, fuse_deconv_and_bn, initialize_weights, intersect_dicts, model_info, scale_img, smart_inference_mode, time_sync, ) class BaseModel(torch.nn.Module): """Base class for all YOLO models in the Ultralytics family. This class provides common functionality for YOLO models including forward pass handling, model fusion, information display, and weight loading capabilities. Attributes: model (torch.nn.Module): The neural network model. save (list): List of layer indices to save outputs from. stride (torch.Tensor): Model stride values. Methods: forward: Perform forward pass for training or inference. predict: Perform inference on input tensor. fuse: Fuse Conv2d and BatchNorm2d layers for optimization. info: Print model information. load: Load weights into the model. loss: Compute loss for training. Examples: Create a BaseModel instance >>> model = BaseModel() >>> model.info() # Display model information """ def forward(self, x, *args, **kwargs): """Perform forward pass of the model for either training or inference. If x is a dict, calculates and returns the loss for training. Otherwise, returns predictions for inference. Args: x (torch.Tensor | dict): Input tensor for inference, or dict with image tensor and labels for training. *args (Any): Variable length argument list. **kwargs (Any): Arbitrary keyword arguments. Returns: (torch.Tensor): Loss if x is a dict (training), or network predictions (inference). """ if isinstance(x, dict): # for cases of training and validating while training. return self.loss(x, *args, **kwargs) return self.predict(x, *args, **kwargs) def predict(self, x, profile=False, visualize=False, augment=False, embed=None): """Perform a forward pass through the network. Args: x (torch.Tensor): The input tensor to the model. profile (bool): Print the computation time of each layer if True. visualize (bool): Save the feature maps of the model if True. augment (bool): Augment image during prediction. embed (list, optional): A list of feature vectors/embeddings to return. Returns: (torch.Tensor): The last output of the model. """ if augment: return self._predict_augment(x) return self._predict_once(x, profile, visualize, embed) def _predict_once(self, x, profile=False, visualize=False, embed=None): """Perform a forward pass through the network. Args: x (torch.Tensor): The input tensor to the model. profile (bool): Print the computation time of each layer if True. visualize (bool): Save the feature maps of the model if True. embed (list, optional): A list of feature vectors/embeddings to return. Returns: (torch.Tensor): The last output of the model. """ y, dt, embeddings = [], [], [] # outputs embed = frozenset(embed) if embed is not None else {-1} max_idx = max(embed) for m in self.model: if m.f != -1: # if not from previous layer x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers if profile: self._profile_one_layer(m, x, dt) x = m(x) # run y.append(x if m.i in self.save else None) # save output if visualize: feature_visualization(x, m.type, m.i, save_dir=visualize) if m.i in embed: embeddings.append(torch.nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten if m.i == max_idx: return torch.unbind(torch.cat(embeddings, 1), dim=0) return x def _predict_augment(self, x): """Perform augmentations on input image x and return augmented inference.""" LOGGER.warning( f"{self.__class__.__name__} does not support 'augment=True' prediction. " f"Reverting to single-scale prediction." ) return self._predict_once(x) def _profile_one_layer(self, m, x, dt): """Profile the computation time and FLOPs of a single layer of the model on a given input. Args: m (torch.nn.Module): The layer to be profiled. x (torch.Tensor): The input data to the layer. dt (list): A list to store the computation time of the layer. """ try: import thop except ImportError: thop = None # conda support without 'ultralytics-thop' installed c = m == self.model[-1] and isinstance(x, list) # is final layer list, copy input as inplace fix flops = thop.profile(m, inputs=[x.copy() if c else x], verbose=False)[0] / 1e9 * 2 if thop else 0 # GFLOPs t = time_sync() for _ in range(10): m(x.copy() if c else x) dt.append((time_sync() - t) * 100) if m == self.model[0]: LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module") LOGGER.info(f"{dt[-1]:10.2f} {flops:10.2f} {m.np:10.0f} {m.type}") if c: LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total") def fuse(self, verbose=True): """Fuse the `Conv2d()` and `BatchNorm2d()` layers of the model into a single layer for improved computation efficiency. Returns: (torch.nn.Module): The fused model is returned. """ if not self.is_fused(): for m in self.model.modules(): if isinstance(m, (Conv, Conv2, DWConv)) and hasattr(m, "bn"): if isinstance(m, Conv2): m.fuse_convs() m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv delattr(m, "bn") # remove batchnorm m.forward = m.forward_fuse # update forward if isinstance(m, ConvTranspose) and hasattr(m, "bn"): m.conv_transpose = fuse_deconv_and_bn(m.conv_transpose, m.bn) delattr(m, "bn") # remove batchnorm m.forward = m.forward_fuse # update forward if isinstance(m, RepConv): m.fuse_convs() m.forward = m.forward_fuse # update forward if isinstance(m, RepVGGDW): m.fuse() m.forward = m.forward_fuse if isinstance(m, v10Detect): m.fuse() # remove one2many head self.info(verbose=verbose) return self def is_fused(self, thresh=10): """Check if the model has less than a certain threshold of BatchNorm layers. Args: thresh (int, optional): The threshold number of BatchNorm layers. Returns: (bool): True if the number of BatchNorm layers in the model is less than the threshold, False otherwise. """ bn = tuple(v for k, v in torch.nn.__dict__.items() if "Norm" in k) # normalization layers, i.e. BatchNorm2d() return sum(isinstance(v, bn) for v in self.modules()) < thresh # True if < 'thresh' BatchNorm layers in model def info(self, detailed=False, verbose=True, imgsz=640): """Print model information. Args: detailed (bool): If True, prints out detailed information about the model. verbose (bool): If True, prints out the model information. imgsz (int): The size of the image that the model will be trained on. """ return model_info(self, detailed=detailed, verbose=verbose, imgsz=imgsz) def _apply(self, fn): """Apply a function to all tensors in the model that are not parameters or registered buffers. Args: fn (function): The function to apply to the model. Returns: (BaseModel): An updated BaseModel object. """ self = super()._apply(fn) m = self.model[-1] # Detect() if isinstance( m, Detect ): # includes all Detect subclasses like Segment, Pose, OBB, WorldDetect, YOLOEDetect, YOLOESegment m.stride = fn(m.stride) m.anchors = fn(m.anchors) m.strides = fn(m.strides) return self def load(self, weights, verbose=True): """Load weights into the model. Args: weights (dict | torch.nn.Module): The pre-trained weights to be loaded. verbose (bool, optional): Whether to log the transfer progress. """ model = weights["model"] if isinstance(weights, dict) else weights # torchvision models are not dicts csd = model.float().state_dict() # checkpoint state_dict as FP32 updated_csd = intersect_dicts(csd, self.state_dict()) # intersect self.load_state_dict(updated_csd, strict=False) # load len_updated_csd = len(updated_csd) first_conv = "model.0.conv.weight" # hard-coded to yolo models for now # mostly used to boost multi-channel training state_dict = self.state_dict() if first_conv not in updated_csd and first_conv in state_dict: c1, c2, h, w = state_dict[first_conv].shape cc1, cc2, ch, cw = csd[first_conv].shape if ch == h and cw == w: c1, c2 = min(c1, cc1), min(c2, cc2) state_dict[first_conv][:c1, :c2] = csd[first_conv][:c1, :c2] len_updated_csd += 1 if verbose: LOGGER.info(f"Transferred {len_updated_csd}/{len(self.model.state_dict())} items from pretrained weights") def loss(self, batch, preds=None): """Compute loss. Args: batch (dict): Batch to compute loss on. preds (torch.Tensor | list[torch.Tensor], optional): Predictions. """ if getattr(self, "criterion", None) is None: self.criterion = self.init_criterion() if preds is None: preds = self.forward(batch["img"]) return self.criterion(preds, batch) def init_criterion(self): """Initialize the loss criterion for the BaseModel.""" raise NotImplementedError("compute_loss() needs to be implemented by task heads") class DetectionModel(BaseModel): """YOLO detection model. This class implements the YOLO detection architecture, handling model initialization, forward pass, augmented inference, and loss computation for object detection tasks. Attributes: yaml (dict): Model configuration dictionary. model (torch.nn.Sequential): The neural network model. save (list): List of layer indices to save outputs from. names (dict): Class names dictionary. inplace (bool): Whether to use inplace operations. end2end (bool): Whether the model uses end-to-end detection. stride (torch.Tensor): Model stride values. Methods: __init__: Initialize the YOLO detection model. _predict_augment: Perform augmented inference. _descale_pred: De-scale predictions following augmented inference. _clip_augmented: Clip YOLO augmented inference tails. init_criterion: Initialize the loss criterion. Examples: Initialize a detection model >>> model = DetectionModel("yolo11n.yaml", ch=3, nc=80) >>> results = model.predict(image_tensor) """ def __init__(self, cfg="yolo11n.yaml", ch=3, nc=None, verbose=True): """Initialize the YOLO detection model with the given config and parameters. Args: cfg (str | dict): Model configuration file path or dictionary. ch (int): Number of input channels. nc (int, optional): Number of classes. verbose (bool): Whether to display model information. """ super().__init__() self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg) # cfg dict if self.yaml["backbone"][0][2] == "Silence": LOGGER.warning( "YOLOv9 `Silence` module is deprecated in favor of torch.nn.Identity. " "Please delete local *.pt file and re-download the latest model checkpoint." ) self.yaml["backbone"][0][2] = "nn.Identity" # Define model self.yaml["channels"] = ch # save channels if nc and nc != self.yaml["nc"]: LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}") self.yaml["nc"] = nc # override YAML value self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # model, savelist self.names = {i: f"{i}" for i in range(self.yaml["nc"])} # default names dict self.inplace = self.yaml.get("inplace", True) self.end2end = getattr(self.model[-1], "end2end", False) # Build strides m = self.model[-1] # Detect() if isinstance(m, Detect): # includes all Detect subclasses like Segment, Pose, OBB, YOLOEDetect, YOLOESegment s = 256 # 2x min stride m.inplace = self.inplace def _forward(x): """Perform a forward pass through the model, handling different Detect subclass types accordingly.""" if self.end2end: return self.forward(x)["one2many"] return self.forward(x)[0] if isinstance(m, (Segment, YOLOESegment, Pose, OBB)) else self.forward(x) self.model.eval() # Avoid changing batch statistics until training begins m.training = True # Setting it to True to properly return strides m.stride = torch.tensor([s / x.shape[-2] for x in _forward(torch.zeros(1, ch, s, s))]) # forward self.stride = m.stride self.model.train() # Set model back to training(default) mode m.bias_init() # only run once else: self.stride = torch.Tensor([32]) # default stride, e.g., RTDETR # Init weights, biases initialize_weights(self) if verbose: self.info() LOGGER.info("") def _predict_augment(self, x): """Perform augmentations on input image x and return augmented inference and train outputs. Args: x (torch.Tensor): Input image tensor. Returns: (torch.Tensor): Augmented inference output. """ if getattr(self, "end2end", False) or self.__class__.__name__ != "DetectionModel": LOGGER.warning("Model does not support 'augment=True', reverting to single-scale prediction.") return self._predict_once(x) img_size = x.shape[-2:] # height, width s = [1, 0.83, 0.67] # scales f = [None, 3, None] # flips (2-ud, 3-lr) y = [] # outputs for si, fi in zip(s, f): xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max())) yi = super().predict(xi)[0] # forward yi = self._descale_pred(yi, fi, si, img_size) y.append(yi) y = self._clip_augmented(y) # clip augmented tails return torch.cat(y, -1), None # augmented inference, train @staticmethod def _descale_pred(p, flips, scale, img_size, dim=1): """De-scale predictions following augmented inference (inverse operation). Args: p (torch.Tensor): Predictions tensor. flips (int): Flip type (0=none, 2=ud, 3=lr). scale (float): Scale factor. img_size (tuple): Original image size (height, width). dim (int): Dimension to split at. Returns: (torch.Tensor): De-scaled predictions. """ p[:, :4] /= scale # de-scale x, y, wh, cls = p.split((1, 1, 2, p.shape[dim] - 4), dim) if flips == 2: y = img_size[0] - y # de-flip ud elif flips == 3: x = img_size[1] - x # de-flip lr return torch.cat((x, y, wh, cls), dim) def _clip_augmented(self, y): """Clip YOLO augmented inference tails. Args: y (list[torch.Tensor]): List of detection tensors. Returns: (list[torch.Tensor]): Clipped detection tensors. """ nl = self.model[-1].nl # number of detection layers (P3-P5) g = sum(4**x for x in range(nl)) # grid points e = 1 # exclude layer count i = (y[0].shape[-1] // g) * sum(4**x for x in range(e)) # indices y[0] = y[0][..., :-i] # large i = (y[-1].shape[-1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices y[-1] = y[-1][..., i:] # small return y def init_criterion(self): """Initialize the loss criterion for the DetectionModel.""" return E2EDetectLoss(self) if getattr(self, "end2end", False) else v8DetectionLoss(self) class OBBModel(DetectionModel): """YOLO Oriented Bounding Box (OBB) model. This class extends DetectionModel to handle oriented bounding box detection tasks, providing specialized loss computation for rotated object detection. Methods: __init__: Initialize YOLO OBB model. init_criterion: Initialize the loss criterion for OBB detection. Examples: Initialize an OBB model >>> model = OBBModel("yolo11n-obb.yaml", ch=3, nc=80) >>> results = model.predict(image_tensor) """ def __init__(self, cfg="yolo11n-obb.yaml", ch=3, nc=None, verbose=True): """Initialize YOLO OBB model with given config and parameters. Args: cfg (str | dict): Model configuration file path or dictionary. ch (int): Number of input channels. nc (int, optional): Number of classes. verbose (bool): Whether to display model information. """ super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose) def init_criterion(self): """Initialize the loss criterion for the model.""" return v8OBBLoss(self) class SegmentationModel(DetectionModel): """YOLO segmentation model. This class extends DetectionModel to handle instance segmentation tasks, providing specialized loss computation for pixel-level object detection and segmentation. Methods: __init__: Initialize YOLO segmentation model. init_criterion: Initialize the loss criterion for segmentation. Examples: Initialize a segmentation model >>> model = SegmentationModel("yolo11n-seg.yaml", ch=3, nc=80) >>> results = model.predict(image_tensor) """ def __init__(self, cfg="yolo11n-seg.yaml", ch=3, nc=None, verbose=True): """Initialize Ultralytics YOLO segmentation model with given config and parameters. Args: cfg (str | dict): Model configuration file path or dictionary. ch (int): Number of input channels. nc (int, optional): Number of classes. verbose (bool): Whether to display model information. """ super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose) def init_criterion(self): """Initialize the loss criterion for the SegmentationModel.""" return v8SegmentationLoss(self) class PoseModel(DetectionModel): """YOLO pose model. This class extends DetectionModel to handle human pose estimation tasks, providing specialized loss computation for keypoint detection and pose estimation. Attributes: kpt_shape (tuple): Shape of keypoints data (num_keypoints, num_dimensions). Methods: __init__: Initialize YOLO pose model. init_criterion: Initialize the loss criterion for pose estimation. Examples: Initialize a pose model >>> model = PoseModel("yolo11n-pose.yaml", ch=3, nc=1, data_kpt_shape=(17, 3)) >>> results = model.predict(image_tensor) """ def __init__(self, cfg="yolo11n-pose.yaml", ch=3, nc=None, data_kpt_shape=(None, None), verbose=True): """Initialize Ultralytics YOLO Pose model. Args: cfg (str | dict): Model configuration file path or dictionary. ch (int): Number of input channels. nc (int, optional): Number of classes. data_kpt_shape (tuple): Shape of keypoints data. verbose (bool): Whether to display model information. """ if not isinstance(cfg, dict): cfg = yaml_model_load(cfg) # load model YAML if any(data_kpt_shape) and list(data_kpt_shape) != list(cfg["kpt_shape"]): LOGGER.info(f"Overriding model.yaml kpt_shape={cfg['kpt_shape']} with kpt_shape={data_kpt_shape}") cfg["kpt_shape"] = data_kpt_shape super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose) def init_criterion(self): """Initialize the loss criterion for the PoseModel.""" return v8PoseLoss(self) class ClassificationModel(BaseModel): """YOLO classification model. This class implements the YOLO classification architecture for image classification tasks, providing model initialization, configuration, and output reshaping capabilities. Attributes: yaml (dict): Model configuration dictionary. model (torch.nn.Sequential): The neural network model. stride (torch.Tensor): Model stride values. names (dict): Class names dictionary. Methods: __init__: Initialize ClassificationModel. _from_yaml: Set model configurations and define architecture. reshape_outputs: Update model to specified class count. init_criterion: Initialize the loss criterion. Examples: Initialize a classification model >>> model = ClassificationModel("yolo11n-cls.yaml", ch=3, nc=1000) >>> results = model.predict(image_tensor) """ def __init__(self, cfg="yolo11n-cls.yaml", ch=3, nc=None, verbose=True): """Initialize ClassificationModel with YAML, channels, number of classes, verbose flag. Args: cfg (str | dict): Model configuration file path or dictionary. ch (int): Number of input channels. nc (int, optional): Number of classes. verbose (bool): Whether to display model information. """ super().__init__() self._from_yaml(cfg, ch, nc, verbose) def _from_yaml(self, cfg, ch, nc, verbose): """Set Ultralytics YOLO model configurations and define the model architecture. Args: cfg (str | dict): Model configuration file path or dictionary. ch (int): Number of input channels. nc (int, optional): Number of classes. verbose (bool): Whether to display model information. """ self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg) # cfg dict # Define model ch = self.yaml["channels"] = self.yaml.get("channels", ch) # input channels if nc and nc != self.yaml["nc"]: LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}") self.yaml["nc"] = nc # override YAML value elif not nc and not self.yaml.get("nc", None): raise ValueError("nc not specified. Must specify nc in model.yaml or function arguments.") self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # model, savelist self.stride = torch.Tensor([1]) # no stride constraints self.names = {i: f"{i}" for i in range(self.yaml["nc"])} # default names dict self.info() @staticmethod def reshape_outputs(model, nc): """Update a TorchVision classification model to class count 'n' if required. Args: model (torch.nn.Module): Model to update. nc (int): New number of classes. """ name, m = list((model.model if hasattr(model, "model") else model).named_children())[-1] # last module if isinstance(m, Classify): # YOLO Classify() head if m.linear.out_features != nc: m.linear = torch.nn.Linear(m.linear.in_features, nc) elif isinstance(m, torch.nn.Linear): # ResNet, EfficientNet if m.out_features != nc: setattr(model, name, torch.nn.Linear(m.in_features, nc)) elif isinstance(m, torch.nn.Sequential): types = [type(x) for x in m] if torch.nn.Linear in types: i = len(types) - 1 - types[::-1].index(torch.nn.Linear) # last torch.nn.Linear index if m[i].out_features != nc: m[i] = torch.nn.Linear(m[i].in_features, nc) elif torch.nn.Conv2d in types: i = len(types) - 1 - types[::-1].index(torch.nn.Conv2d) # last torch.nn.Conv2d index if m[i].out_channels != nc: m[i] = torch.nn.Conv2d( m[i].in_channels, nc, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None ) def init_criterion(self): """Initialize the loss criterion for the ClassificationModel.""" return v8ClassificationLoss() class RTDETRDetectionModel(DetectionModel): """RTDETR (Real-time DEtection and Tracking using Transformers) Detection Model class. This class is responsible for constructing the RTDETR architecture, defining loss functions, and facilitating both the training and inference processes. RTDETR is an object detection and tracking model that extends from the DetectionModel base class. Attributes: nc (int): Number of classes for detection. criterion (RTDETRDetectionLoss): Loss function for training. Methods: __init__: Initialize the RTDETRDetectionModel. init_criterion: Initialize the loss criterion. loss: Compute loss for training. predict: Perform forward pass through the model. Examples: Initialize an RTDETR model >>> model = RTDETRDetectionModel("rtdetr-l.yaml", ch=3, nc=80) >>> results = model.predict(image_tensor) """ def __init__(self, cfg="rtdetr-l.yaml", ch=3, nc=None, verbose=True): """Initialize the RTDETRDetectionModel. Args: cfg (str | dict): Configuration file name or path. ch (int): Number of input channels. nc (int, optional): Number of classes. verbose (bool): Print additional information during initialization. """ super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose) def _apply(self, fn): """Apply a function to all tensors in the model that are not parameters or registered buffers. Args: fn (function): The function to apply to the model. Returns: (RTDETRDetectionModel): An updated BaseModel object. """ self = super()._apply(fn) m = self.model[-1] m.anchors = fn(m.anchors) m.valid_mask = fn(m.valid_mask) return self def init_criterion(self): """Initialize the loss criterion for the RTDETRDetectionModel.""" from ultralytics.models.utils.loss import RTDETRDetectionLoss return RTDETRDetectionLoss(nc=self.nc, use_vfl=True) def loss(self, batch, preds=None): """Compute the loss for the given batch of data. Args: batch (dict): Dictionary containing image and label data. preds (torch.Tensor, optional): Precomputed model predictions. Returns: loss_sum (torch.Tensor): Total loss value. loss_items (torch.Tensor): Main three losses in a tensor. """ if not hasattr(self, "criterion"): self.criterion = self.init_criterion() img = batch["img"] # NOTE: preprocess gt_bbox and gt_labels to list. bs = img.shape[0] batch_idx = batch["batch_idx"] gt_groups = [(batch_idx == i).sum().item() for i in range(bs)] targets = { "cls": batch["cls"].to(img.device, dtype=torch.long).view(-1), "bboxes": batch["bboxes"].to(device=img.device), "batch_idx": batch_idx.to(img.device, dtype=torch.long).view(-1), "gt_groups": gt_groups, } if preds is None: preds = self.predict(img, batch=targets) dec_bboxes, dec_scores, enc_bboxes, enc_scores, dn_meta = preds if self.training else preds[1] if dn_meta is None: dn_bboxes, dn_scores = None, None else: dn_bboxes, dec_bboxes = torch.split(dec_bboxes, dn_meta["dn_num_split"], dim=2) dn_scores, dec_scores = torch.split(dec_scores, dn_meta["dn_num_split"], dim=2) dec_bboxes = torch.cat([enc_bboxes.unsqueeze(0), dec_bboxes]) # (7, bs, 300, 4) dec_scores = torch.cat([enc_scores.unsqueeze(0), dec_scores]) loss = self.criterion( (dec_bboxes, dec_scores), targets, dn_bboxes=dn_bboxes, dn_scores=dn_scores, dn_meta=dn_meta ) # NOTE: There are like 12 losses in RTDETR, backward with all losses but only show the main three losses. return sum(loss.values()), torch.as_tensor( [loss[k].detach() for k in ["loss_giou", "loss_class", "loss_bbox"]], device=img.device ) def predict(self, x, profile=False, visualize=False, batch=None, augment=False, embed=None): """Perform a forward pass through the model. Args: x (torch.Tensor): The input tensor. profile (bool): If True, profile the computation time for each layer. visualize (bool): If True, save feature maps for visualization. batch (dict, optional): Ground truth data for evaluation. augment (bool): If True, perform data augmentation during inference. embed (list, optional): A list of feature vectors/embeddings to return. Returns: (torch.Tensor): Model's output tensor. """ y, dt, embeddings = [], [], [] # outputs embed = frozenset(embed) if embed is not None else {-1} max_idx = max(embed) for m in self.model[:-1]: # except the head part if m.f != -1: # if not from previous layer x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers if profile: self._profile_one_layer(m, x, dt) x = m(x) # run y.append(x if m.i in self.save else None) # save output if visualize: feature_visualization(x, m.type, m.i, save_dir=visualize) if m.i in embed: embeddings.append(torch.nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten if m.i == max_idx: return torch.unbind(torch.cat(embeddings, 1), dim=0) head = self.model[-1] x = head([y[j] for j in head.f], batch) # head inference return x class WorldModel(DetectionModel): """YOLOv8 World Model. This class implements the YOLOv8 World model for open-vocabulary object detection, supporting text-based class specification and CLIP model integration for zero-shot detection capabilities. Attributes: txt_feats (torch.Tensor): Text feature embeddings for classes. clip_model (torch.nn.Module): CLIP model for text encoding. Methods: __init__: Initialize YOLOv8 world model. set_classes: Set classes for offline inference. get_text_pe: Get text positional embeddings. predict: Perform forward pass with text features. loss: Compute loss with text features. Examples: Initialize a world model >>> model = WorldModel("yolov8s-world.yaml", ch=3, nc=80) >>> model.set_classes(["person", "car", "bicycle"]) >>> results = model.predict(image_tensor) """ def __init__(self, cfg="yolov8s-world.yaml", ch=3, nc=None, verbose=True): """Initialize YOLOv8 world model with given config and parameters. Args: cfg (str | dict): Model configuration file path or dictionary. ch (int): Number of input channels. nc (int, optional): Number of classes. verbose (bool): Whether to display model information. """ self.txt_feats = torch.randn(1, nc or 80, 512) # features placeholder self.clip_model = None # CLIP model placeholder super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose) def set_classes(self, text, batch=80, cache_clip_model=True): """Set classes in advance so that model could do offline-inference without clip model. Args: text (list[str]): List of class names. batch (int): Batch size for processing text tokens. cache_clip_model (bool): Whether to cache the CLIP model. """ self.txt_feats = self.get_text_pe(text, batch=batch, cache_clip_model=cache_clip_model) self.model[-1].nc = len(text) def get_text_pe(self, text, batch=80, cache_clip_model=True): """Get text positional embeddings for offline inference without CLIP model. Args: text (list[str]): List of class names. batch (int): Batch size for processing text tokens. cache_clip_model (bool): Whether to cache the CLIP model. Returns: (torch.Tensor): Text positional embeddings. """ from ultralytics.nn.text_model import build_text_model device = next(self.model.parameters()).device if not getattr(self, "clip_model", None) and cache_clip_model: # For backwards compatibility of models lacking clip_model attribute self.clip_model = build_text_model("clip:ViT-B/32", device=device) model = self.clip_model if cache_clip_model else build_text_model("clip:ViT-B/32", device=device) text_token = model.tokenize(text) txt_feats = [model.encode_text(token).detach() for token in text_token.split(batch)] txt_feats = txt_feats[0] if len(txt_feats) == 1 else torch.cat(txt_feats, dim=0) return txt_feats.reshape(-1, len(text), txt_feats.shape[-1]) def predict(self, x, profile=False, visualize=False, txt_feats=None, augment=False, embed=None): """Perform a forward pass through the model. Args: x (torch.Tensor): The input tensor. profile (bool): If True, profile the computation time for each layer. visualize (bool): If True, save feature maps for visualization. txt_feats (torch.Tensor, optional): The text features, use it if it's given. augment (bool): If True, perform data augmentation during inference. embed (list, optional): A list of feature vectors/embeddings to return. Returns: (torch.Tensor): Model's output tensor. """ txt_feats = (self.txt_feats if txt_feats is None else txt_feats).to(device=x.device, dtype=x.dtype) if txt_feats.shape[0] != x.shape[0] or self.model[-1].export: txt_feats = txt_feats.expand(x.shape[0], -1, -1) ori_txt_feats = txt_feats.clone() y, dt, embeddings = [], [], [] # outputs embed = frozenset(embed) if embed is not None else {-1} max_idx = max(embed) for m in self.model: # except the head part if m.f != -1: # if not from previous layer x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers if profile: self._profile_one_layer(m, x, dt) if isinstance(m, C2fAttn): x = m(x, txt_feats) elif isinstance(m, WorldDetect): x = m(x, ori_txt_feats) elif isinstance(m, ImagePoolingAttn): txt_feats = m(x, txt_feats) else: x = m(x) # run y.append(x if m.i in self.save else None) # save output if visualize: feature_visualization(x, m.type, m.i, save_dir=visualize) if m.i in embed: embeddings.append(torch.nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten if m.i == max_idx: return torch.unbind(torch.cat(embeddings, 1), dim=0) return x def loss(self, batch, preds=None): """Compute loss. Args: batch (dict): Batch to compute loss on. preds (torch.Tensor | list[torch.Tensor], optional): Predictions. """ if not hasattr(self, "criterion"): self.criterion = self.init_criterion() if preds is None: preds = self.forward(batch["img"], txt_feats=batch["txt_feats"]) return self.criterion(preds, batch) class YOLOEModel(DetectionModel): """YOLOE detection model. This class implements the YOLOE architecture for efficient object detection with text and visual prompts, supporting both prompt-based and prompt-free inference modes. Attributes: pe (torch.Tensor): Prompt embeddings for classes. clip_model (torch.nn.Module): CLIP model for text encoding. Methods: __init__: Initialize YOLOE model. get_text_pe: Get text positional embeddings. get_visual_pe: Get visual embeddings. set_vocab: Set vocabulary for prompt-free model. get_vocab: Get fused vocabulary layer. set_classes: Set classes for offline inference. get_cls_pe: Get class positional embeddings. predict: Perform forward pass with prompts. loss: Compute loss with prompts. Examples: Initialize a YOLOE model >>> model = YOLOEModel("yoloe-v8s.yaml", ch=3, nc=80) >>> results = model.predict(image_tensor, tpe=text_embeddings) """ def __init__(self, cfg="yoloe-v8s.yaml", ch=3, nc=None, verbose=True): """Initialize YOLOE model with given config and parameters. Args: cfg (str | dict): Model configuration file path or dictionary. ch (int): Number of input channels. nc (int, optional): Number of classes. verbose (bool): Whether to display model information. """ super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose) @smart_inference_mode() def get_text_pe(self, text, batch=80, cache_clip_model=False, without_reprta=False): """Get text positional embeddings for offline inference without CLIP model. Args: text (list[str]): List of class names. batch (int): Batch size for processing text tokens. cache_clip_model (bool): Whether to cache the CLIP model. without_reprta (bool): Whether to return text embeddings without reprta module processing. Returns: (torch.Tensor): Text positional embeddings. """ from ultralytics.nn.text_model import build_text_model device = next(self.model.parameters()).device if not getattr(self, "clip_model", None) and cache_clip_model: # For backwards compatibility of models lacking clip_model attribute self.clip_model = build_text_model("mobileclip:blt", device=device) model = self.clip_model if cache_clip_model else build_text_model("mobileclip:blt", device=device) text_token = model.tokenize(text) txt_feats = [model.encode_text(token).detach() for token in text_token.split(batch)] txt_feats = txt_feats[0] if len(txt_feats) == 1 else torch.cat(txt_feats, dim=0) txt_feats = txt_feats.reshape(-1, len(text), txt_feats.shape[-1]) if without_reprta: return txt_feats head = self.model[-1] assert isinstance(head, YOLOEDetect) return head.get_tpe(txt_feats) # run auxiliary text head @smart_inference_mode() def get_visual_pe(self, img, visual): """Get visual embeddings. Args: img (torch.Tensor): Input image tensor. visual (torch.Tensor): Visual features. Returns: (torch.Tensor): Visual positional embeddings. """ return self(img, vpe=visual, return_vpe=True) def set_vocab(self, vocab, names): """Set vocabulary for the prompt-free model. Args: vocab (nn.ModuleList): List of vocabulary items. names (list[str]): List of class names. """ assert not self.training head = self.model[-1] assert isinstance(head, YOLOEDetect) # Cache anchors for head device = next(self.parameters()).device self(torch.empty(1, 3, self.args["imgsz"], self.args["imgsz"]).to(device)) # warmup # re-parameterization for prompt-free model self.model[-1].lrpc = nn.ModuleList( LRPCHead(cls, pf[-1], loc[-1], enabled=i != 2) for i, (cls, pf, loc) in enumerate(zip(vocab, head.cv3, head.cv2)) ) for loc_head, cls_head in zip(head.cv2, head.cv3): assert isinstance(loc_head, nn.Sequential) assert isinstance(cls_head, nn.Sequential) del loc_head[-1] del cls_head[-1] self.model[-1].nc = len(names) self.names = check_class_names(names) def get_vocab(self, names): """Get fused vocabulary layer from the model. Args: names (list): List of class names. Returns: (nn.ModuleList): List of vocabulary modules. """ assert not self.training head = self.model[-1] assert isinstance(head, YOLOEDetect) assert not head.is_fused tpe = self.get_text_pe(names) self.set_classes(names, tpe) device = next(self.model.parameters()).device head.fuse(self.pe.to(device)) # fuse prompt embeddings to classify head vocab = nn.ModuleList() for cls_head in head.cv3: assert isinstance(cls_head, nn.Sequential) vocab.append(cls_head[-1]) return vocab def set_classes(self, names, embeddings): """Set classes in advance so that model could do offline-inference without clip model. Args: names (list[str]): List of class names. embeddings (torch.Tensor): Embeddings tensor. """ assert not hasattr(self.model[-1], "lrpc"), ( "Prompt-free model does not support setting classes. Please try with Text/Visual prompt models." ) assert embeddings.ndim == 3 self.pe = embeddings self.model[-1].nc = len(names) self.names = check_class_names(names) def get_cls_pe(self, tpe, vpe): """Get class positional embeddings. Args: tpe (torch.Tensor, optional): Text positional embeddings. vpe (torch.Tensor, optional): Visual positional embeddings. Returns: (torch.Tensor): Class positional embeddings. """ all_pe = [] if tpe is not None: assert tpe.ndim == 3 all_pe.append(tpe) if vpe is not None: assert vpe.ndim == 3 all_pe.append(vpe) if not all_pe: all_pe.append(getattr(self, "pe", torch.zeros(1, 80, 512))) return torch.cat(all_pe, dim=1) def predict( self, x, profile=False, visualize=False, tpe=None, augment=False, embed=None, vpe=None, return_vpe=False ): """Perform a forward pass through the model. Args: x (torch.Tensor): The input tensor. profile (bool): If True, profile the computation time for each layer. visualize (bool): If True, save feature maps for visualization. tpe (torch.Tensor, optional): Text positional embeddings. augment (bool): If True, perform data augmentation during inference. embed (list, optional): A list of feature vectors/embeddings to return. vpe (torch.Tensor, optional): Visual positional embeddings. return_vpe (bool): If True, return visual positional embeddings. Returns: (torch.Tensor): Model's output tensor. """ y, dt, embeddings = [], [], [] # outputs b = x.shape[0] embed = frozenset(embed) if embed is not None else {-1} max_idx = max(embed) for m in self.model: # except the head part if m.f != -1: # if not from previous layer x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers if profile: self._profile_one_layer(m, x, dt) if isinstance(m, YOLOEDetect): vpe = m.get_vpe(x, vpe) if vpe is not None else None if return_vpe: assert vpe is not None assert not self.training return vpe cls_pe = self.get_cls_pe(m.get_tpe(tpe), vpe).to(device=x[0].device, dtype=x[0].dtype) if cls_pe.shape[0] != b or m.export: cls_pe = cls_pe.expand(b, -1, -1) x = m(x, cls_pe) else: x = m(x) # run y.append(x if m.i in self.save else None) # save output if visualize: feature_visualization(x, m.type, m.i, save_dir=visualize) if m.i in embed: embeddings.append(torch.nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten if m.i == max_idx: return torch.unbind(torch.cat(embeddings, 1), dim=0) return x def loss(self, batch, preds=None): """Compute loss. Args: batch (dict): Batch to compute loss on. preds (torch.Tensor | list[torch.Tensor], optional): Predictions. """ if not hasattr(self, "criterion"): from ultralytics.utils.loss import TVPDetectLoss visual_prompt = batch.get("visuals", None) is not None # TODO self.criterion = TVPDetectLoss(self) if visual_prompt else self.init_criterion() if preds is None: preds = self.forward(batch["img"], tpe=batch.get("txt_feats", None), vpe=batch.get("visuals", None)) return self.criterion(preds, batch) class YOLOESegModel(YOLOEModel, SegmentationModel): """YOLOE segmentation model. This class extends YOLOEModel to handle instance segmentation tasks with text and visual prompts, providing specialized loss computation for pixel-level object detection and segmentation. Methods: __init__: Initialize YOLOE segmentation model. loss: Compute loss with prompts for segmentation. Examples: Initialize a YOLOE segmentation model >>> model = YOLOESegModel("yoloe-v8s-seg.yaml", ch=3, nc=80) >>> results = model.predict(image_tensor, tpe=text_embeddings) """ def __init__(self, cfg="yoloe-v8s-seg.yaml", ch=3, nc=None, verbose=True): """Initialize YOLOE segmentation model with given config and parameters. Args: cfg (str | dict): Model configuration file path or dictionary. ch (int): Number of input channels. nc (int, optional): Number of classes. verbose (bool): Whether to display model information. """ super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose) def loss(self, batch, preds=None): """Compute loss. Args: batch (dict): Batch to compute loss on. preds (torch.Tensor | list[torch.Tensor], optional): Predictions. """ if not hasattr(self, "criterion"): from ultralytics.utils.loss import TVPSegmentLoss visual_prompt = batch.get("visuals", None) is not None # TODO self.criterion = TVPSegmentLoss(self) if visual_prompt else self.init_criterion() if preds is None: preds = self.forward(batch["img"], tpe=batch.get("txt_feats", None), vpe=batch.get("visuals", None)) return self.criterion(preds, batch) class Ensemble(torch.nn.ModuleList): """Ensemble of models. This class allows combining multiple YOLO models into an ensemble for improved performance through model averaging or other ensemble techniques. Methods: __init__: Initialize an ensemble of models. forward: Generate predictions from all models in the ensemble. Examples: Create an ensemble of models >>> ensemble = Ensemble() >>> ensemble.append(model1) >>> ensemble.append(model2) >>> results = ensemble(image_tensor) """ def __init__(self): """Initialize an ensemble of models.""" super().__init__() def forward(self, x, augment=False, profile=False, visualize=False): """Generate the YOLO network's final layer. Args: x (torch.Tensor): Input tensor. augment (bool): Whether to augment the input. profile (bool): Whether to profile the model. visualize (bool): Whether to visualize the features. Returns: y (torch.Tensor): Concatenated predictions from all models. train_out (None): Always None for ensemble inference. """ y = [module(x, augment, profile, visualize)[0] for module in self] # y = torch.stack(y).max(0)[0] # max ensemble # y = torch.stack(y).mean(0) # mean ensemble y = torch.cat(y, 2) # nms ensemble, y shape(B, HW, C) return y, None # inference, train output # Functions ------------------------------------------------------------------------------------------------------------ @contextlib.contextmanager def temporary_modules(modules=None, attributes=None): """Context manager for temporarily adding or modifying modules in Python's module cache (`sys.modules`). This function can be used to change the module paths during runtime. It's useful when refactoring code, where you've moved a module from one location to another, but you still want to support the old import paths for backwards compatibility. Args: modules (dict, optional): A dictionary mapping old module paths to new module paths. attributes (dict, optional): A dictionary mapping old module attributes to new module attributes. Examples: >>> with temporary_modules({"old.module": "new.module"}, {"old.module.attribute": "new.module.attribute"}): >>> import old.module # this will now import new.module >>> from old.module import attribute # this will now import new.module.attribute Notes: The changes are only in effect inside the context manager and are undone once the context manager exits. Be aware that directly manipulating `sys.modules` can lead to unpredictable results, especially in larger applications or libraries. Use this function with caution. """ if modules is None: modules = {} if attributes is None: attributes = {} import sys from importlib import import_module try: # Set attributes in sys.modules under their old name for old, new in attributes.items(): old_module, old_attr = old.rsplit(".", 1) new_module, new_attr = new.rsplit(".", 1) setattr(import_module(old_module), old_attr, getattr(import_module(new_module), new_attr)) # Set modules in sys.modules under their old name for old, new in modules.items(): sys.modules[old] = import_module(new) yield finally: # Remove the temporary module paths for old in modules: if old in sys.modules: del sys.modules[old] class SafeClass: """A placeholder class to replace unknown classes during unpickling.""" def __init__(self, *args, **kwargs): """Initialize SafeClass instance, ignoring all arguments.""" pass def __call__(self, *args, **kwargs): """Run SafeClass instance, ignoring all arguments.""" pass class SafeUnpickler(pickle.Unpickler): """Custom Unpickler that replaces unknown classes with SafeClass.""" def find_class(self, module, name): """Attempt to find a class, returning SafeClass if not among safe modules. Args: module (str): Module name. name (str): Class name. Returns: (type): Found class or SafeClass. """ safe_modules = ( "torch", "collections", "collections.abc", "builtins", "math", "numpy", # Add other modules considered safe ) if module in safe_modules: return super().find_class(module, name) else: return SafeClass def torch_safe_load(weight, safe_only=False): """Attempt to load a PyTorch model with the torch.load() function. If a ModuleNotFoundError is raised, it catches the error, logs a warning message, and attempts to install the missing module via the check_requirements() function. After installation, the function again attempts to load the model using torch.load(). Args: weight (str): The file path of the PyTorch model. safe_only (bool): If True, replace unknown classes with SafeClass during loading. Returns: ckpt (dict): The loaded model checkpoint. file (str): The loaded filename. Examples: >>> from ultralytics.nn.tasks import torch_safe_load >>> ckpt, file = torch_safe_load("path/to/best.pt", safe_only=True) """ from ultralytics.utils.downloads import attempt_download_asset check_suffix(file=weight, suffix=".pt") file = attempt_download_asset(weight) # search online if missing locally try: with temporary_modules( modules={ "ultralytics.yolo.utils": "ultralytics.utils", "ultralytics.yolo.v8": "ultralytics.models.yolo", "ultralytics.yolo.data": "ultralytics.data", }, attributes={ "ultralytics.nn.modules.block.Silence": "torch.nn.Identity", # YOLOv9e "ultralytics.nn.tasks.YOLOv10DetectionModel": "ultralytics.nn.tasks.DetectionModel", # YOLOv10 "ultralytics.utils.loss.v10DetectLoss": "ultralytics.utils.loss.E2EDetectLoss", # YOLOv10 }, ): if safe_only: # Load via custom pickle module safe_pickle = types.ModuleType("safe_pickle") safe_pickle.Unpickler = SafeUnpickler safe_pickle.load = lambda file_obj: SafeUnpickler(file_obj).load() with open(file, "rb") as f: ckpt = torch_load(f, pickle_module=safe_pickle) else: ckpt = torch_load(file, map_location="cpu") except ModuleNotFoundError as e: # e.name is missing module name if e.name == "models": raise TypeError( emojis( f"ERROR ❌️ {weight} appears to be an Ultralytics YOLOv5 model originally trained " f"with https://github.com/ultralytics/yolov5.\nThis model is NOT forwards compatible with " f"YOLOv8 at https://github.com/ultralytics/ultralytics." f"\nRecommend fixes are to train a new model using the latest 'ultralytics' package or to " f"run a command with an official Ultralytics model, i.e. 'yolo predict model=yolo11n.pt'" ) ) from e elif e.name == "numpy._core": raise ModuleNotFoundError( emojis( f"ERROR ❌️ {weight} requires numpy>=1.26.1, however numpy=={__import__('numpy').__version__} is installed." ) ) from e LOGGER.warning( f"{weight} appears to require '{e.name}', which is not in Ultralytics requirements." f"\nAutoInstall will run now for '{e.name}' but this feature will be removed in the future." f"\nRecommend fixes are to train a new model using the latest 'ultralytics' package or to " f"run a command with an official Ultralytics model, i.e. 'yolo predict model=yolo11n.pt'" ) check_requirements(e.name) # install missing module ckpt = torch_load(file, map_location="cpu") if not isinstance(ckpt, dict): # File is likely a YOLO instance saved with i.e. torch.save(model, "saved_model.pt") LOGGER.warning( f"The file '{weight}' appears to be improperly saved or formatted. " f"For optimal results, use model.save('filename.pt') to correctly save YOLO models." ) ckpt = {"model": ckpt.model} return ckpt, file def load_checkpoint(weight, device=None, inplace=True, fuse=False): """Load a single model weights. Args: weight (str | Path): Model weight path. device (torch.device, optional): Device to load model to. inplace (bool): Whether to do inplace operations. fuse (bool): Whether to fuse model. Returns: model (torch.nn.Module): Loaded model. ckpt (dict): Model checkpoint dictionary. """ ckpt, weight = torch_safe_load(weight) # load ckpt args = {**DEFAULT_CFG_DICT, **(ckpt.get("train_args", {}))} # combine model and default args, preferring model args model = (ckpt.get("ema") or ckpt["model"]).float() # FP32 model # Model compatibility updates model.args = args # attach args to model model.pt_path = weight # attach *.pt file path to model model.task = getattr(model, "task", guess_model_task(model)) if not hasattr(model, "stride"): model.stride = torch.tensor([32.0]) model = (model.fuse() if fuse and hasattr(model, "fuse") else model).eval().to(device) # model in eval mode # Module updates for m in model.modules(): if hasattr(m, "inplace"): m.inplace = inplace elif isinstance(m, torch.nn.Upsample) and not hasattr(m, "recompute_scale_factor"): m.recompute_scale_factor = None # torch 1.11.0 compatibility # Return model and ckpt return model, ckpt def parse_model(d, ch, verbose=True): """Parse a YOLO model.yaml dictionary into a PyTorch model. Args: d (dict): Model dictionary. ch (int): Input channels. verbose (bool): Whether to print model details. Returns: model (torch.nn.Sequential): PyTorch model. save (list): Sorted list of output layers. """ import ast # Args legacy = True # backward compatibility for v3/v5/v8/v9 models max_channels = float("inf") nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales")) depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape")) scale = d.get("scale") if scales: if not scale: scale = next(iter(scales.keys())) LOGGER.warning(f"no model scale passed. Assuming scale='{scale}'.") depth, width, max_channels = scales[scale] if act: Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = torch.nn.SiLU() if verbose: LOGGER.info(f"{colorstr('activation:')} {act}") # print if verbose: LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}") ch = [ch] layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out base_modules = frozenset( { Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, C2fPSA, C2PSA, DWConv, Focus, BottleneckCSP, C1, C2, C2f, C3k2, RepNCSPELAN4, ELAN1, ADown, AConv, SPPELAN, C2fAttn, C3, C3TR, C3Ghost, torch.nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3, PSA, SCDown, C2fCIB, A2C2f, } ) repeat_modules = frozenset( # modules with 'repeat' arguments { BottleneckCSP, C1, C2, C2f, C3k2, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3, C2fPSA, C2fCIB, C2PSA, A2C2f, } ) for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args m = ( getattr(torch.nn, m[3:]) if "nn." in m else getattr(__import__("torchvision").ops, m[16:]) if "torchvision.ops." in m else globals()[m] ) # get module for j, a in enumerate(args): if isinstance(a, str): with contextlib.suppress(ValueError): args[j] = locals()[a] if a in locals() else ast.literal_eval(a) n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain if m in base_modules: c1, c2 = ch[f], args[0] if c2 != nc: # if c2 != nc (e.g., Classify() output) c2 = make_divisible(min(c2, max_channels) * width, 8) if m is C2fAttn: # set 1) embed channels and 2) num heads args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) args[2] = int(max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]) args = [c1, c2, *args[1:]] if m in repeat_modules: args.insert(2, n) # number of repeats n = 1 if m is C3k2: # for M/L/X sizes legacy = False if scale in "mlx": args[3] = True if m is A2C2f: legacy = False if scale in "lx": # for L/X sizes args.extend((True, 1.2)) if m is C2fCIB: legacy = False elif m is AIFI: args = [ch[f], *args] elif m in frozenset({HGStem, HGBlock}): c1, cm, c2 = ch[f], args[0], args[1] args = [c1, cm, c2, *args[2:]] if m is HGBlock: args.insert(4, n) # number of repeats n = 1 elif m is ResNetLayer: c2 = args[1] if args[3] else args[1] * 4 elif m is torch.nn.BatchNorm2d: args = [ch[f]] elif m in _CUSTOM_ATTN: c1 = ch[f] c2 = ch[f] # 注意力不改变通道数 args = [c1, *args] elif m is Concat: c2 = sum(ch[x] for x in f) elif m in frozenset( {Detect, WorldDetect, YOLOEDetect, Segment, YOLOESegment, Pose, OBB, ImagePoolingAttn, v10Detect} ): args.append([ch[x] for x in f]) if m is Segment or m is YOLOESegment: args[2] = make_divisible(min(args[2], max_channels) * width, 8) if m in {Detect, YOLOEDetect, Segment, YOLOESegment, Pose, OBB}: m.legacy = legacy elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1 args.insert(1, [ch[x] for x in f]) elif m is CBAM: c1, c2 = ch[f], args[0] if c2 != nc: c2 = make_divisible(min(c2, max_channels) * width, 8) args = [c1, *args[1:]] elif m is CBLinear: c2 = args[0] c1 = ch[f] args = [c1, c2, *args[1:]] elif m is CBFuse: c2 = ch[f[-1]] elif m in frozenset({TorchVision, Index}): c2 = args[0] c1 = ch[f] args = [*args[1:]] else: c2 = ch[f] m_ = torch.nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module t = str(m)[8:-2].replace("__main__.", "") # module type m_.np = sum(x.numel() for x in m_.parameters()) # number params m_.i, m_.f, m_.type = i, f, t # attach index, 'from' index, type if verbose: LOGGER.info(f"{i:>3}{f!s:>20}{n_:>3}{m_.np:10.0f} {t:<45}{args!s:<30}") # print save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist layers.append(m_) if i == 0: ch = [] ch.append(c2) return torch.nn.Sequential(*layers), sorted(save) def yaml_model_load(path): """Load a YOLOv8 model from a YAML file. Args: path (str | Path): Path to the YAML file. Returns: (dict): Model dictionary. """ path = Path(path) if path.stem in (f"yolov{d}{x}6" for x in "nsmlx" for d in (5, 8)): new_stem = re.sub(r"(\d+)([nslmx])6(.+)?$", r"\1\2-p6\3", path.stem) LOGGER.warning(f"Ultralytics YOLO P6 models now use -p6 suffix. Renaming {path.stem} to {new_stem}.") path = path.with_name(new_stem + path.suffix) unified_path = re.sub(r"(\d+)([nslmx])(.+)?$", r"\1\3", str(path)) # i.e. yolov8x.yaml -> yolov8.yaml yaml_file = check_yaml(unified_path, hard=False) or check_yaml(path) d = YAML.load(yaml_file) # model dict d["scale"] = guess_model_scale(path) d["yaml_file"] = str(path) return d def guess_model_scale(model_path): """Extract the size character n, s, m, l, or x of the model's scale from the model path. Args: model_path (str | Path): The path to the YOLO model's YAML file. Returns: (str): The size character of the model's scale (n, s, m, l, or x). """ try: return re.search(r"yolo(e-)?[v]?\d+([nslmx])", Path(model_path).stem).group(2) except AttributeError: return "" def guess_model_task(model): """Guess the task of a PyTorch model from its architecture or configuration. Args: model (torch.nn.Module | dict): PyTorch model or model configuration in YAML format. Returns: (str): Task of the model ('detect', 'segment', 'classify', 'pose', 'obb'). """ def cfg2task(cfg): """Guess from YAML dictionary.""" m = cfg["head"][-1][-2].lower() # output module name if m in {"classify", "classifier", "cls", "fc"}: return "classify" if "detect" in m: return "detect" if "segment" in m: return "segment" if m == "pose": return "pose" if m == "obb": return "obb" # Guess from model cfg if isinstance(model, dict): with contextlib.suppress(Exception): return cfg2task(model) # Guess from PyTorch model if isinstance(model, torch.nn.Module): # PyTorch model for x in "model.args", "model.model.args", "model.model.model.args": with contextlib.suppress(Exception): return eval(x)["task"] # nosec B307: safe eval of known attribute paths for x in "model.yaml", "model.model.yaml", "model.model.model.yaml": with contextlib.suppress(Exception): return cfg2task(eval(x)) # nosec B307: safe eval of known attribute paths for m in model.modules(): if isinstance(m, (Segment, YOLOESegment)): return "segment" elif isinstance(m, Classify): return "classify" elif isinstance(m, Pose): return "pose" elif isinstance(m, OBB): return "obb" elif isinstance(m, (Detect, WorldDetect, YOLOEDetect, v10Detect)): return "detect" # Guess from model filename if isinstance(model, (str, Path)): model = Path(model) if "-seg" in model.stem or "segment" in model.parts: return "segment" elif "-cls" in model.stem or "classify" in model.parts: return "classify" elif "-pose" in model.stem or "pose" in model.parts: return "pose" elif "-obb" in model.stem or "obb" in model.parts: return "obb" elif "detect" in model.parts: return "detect" # Unable to determine task from model LOGGER.warning( "Unable to automatically guess model task, assuming 'task=detect'. " "Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify','pose' or 'obb'." ) return "detect" # assume detect
五、拓展、理解小目标层P3、中目标层P4、大目标层P5....等
【如果你使用CPU跑模型】
import torch import os from ultralytics import YOLO # 解决OMP冲突(Windows必加) os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # 1. 加载你的YOLO11s模型(带CBAM的也可以) model = YOLO("yolo11s.pt") # 把模型设为eval模式,避免BatchNorm干扰 model.eval() # 2. 创建一个和你训练时一样尺寸的测试张量(1张图,3通道,1280×1280) dummy_input = torch.randn(1, 3, 1280, 1280).to("cuda" if torch.cuda.is_available() else "cpu") # 3. 遍历模型每一层,打印输出尺寸(关键!) print("=== 各层输出尺寸(尺寸越大=小目标层)===") x = dummy_input for i, layer in enumerate(model.model.model): x = layer(x) # 只打印4维特征图(排除分类/回归头的一维输出) if len(x.shape) == 4: # 修改点:使用三引号 """ 将字符串包裹起来,允许内部换行 print(f"""层{i}:输出尺寸 = {x.shape} → 对应目标类型:{ '极小目标(P2)' if x.shape[2] == 160 else '中小目标(P3)' if x.shape[2] == 80 else '大目标(P4)' if x.shape[2] == 40 else '其他层' }""")【如果你使用GPU跑模型】
import torch import os from ultralytics import YOLO os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # 1. 加载模型 model = YOLO("yolo11s.pt") device = "cuda" if torch.cuda.is_available() else "cpu" model.model.to(device) # 移动模型到 GPU # 2. 定义字典存储输出 outputs = {} # 3. 定义钩子函数 def get_output(idx): def hook(module, input, output): # 只保存4维特征图 if isinstance(output, torch.Tensor) and len(output.shape) == 4: outputs[idx] = output return hook # 4. 【关键修改】直接遍历 model.model.model 列表 # model.model 是 DetectionModel # model.model.model 才是真正的 nn.Sequential 列表 try: # 尝试获取模型中的Sequential列表 model_list = model.model.model if not isinstance(model_list, torch.nn.Sequential): # 如果获取的不是Sequential,尝试直接遍历model.model(虽然通常不行,但做个兼容) print("警告:未能直接找到 model.model.model 列表,尝试直接遍历 model.model...") model_list = model.model for i, layer in enumerate(model_list): # 注册钩子,使用索引 i 作为 key layer.register_forward_hook(get_output(i)) except Exception as e: print(f"遍历模型层出错: {e}") print("尝试打印模型结构以调试:") print(model.model) # 5. 运行推理 dummy_input = torch.randn(1, 3, 1280, 1280).to(device) with torch.no_grad(): _ = model.model(dummy_input) # 6. 格式化打印 print("-" * 80) print(f"{'Layer Index':<12} | {'Output Shape (C, H, W)':<25} | {'Target Type'}") print("-" * 80) if not outputs: print("未捕获到任何输出,请检查模型结构或钩子注册逻辑。") else: # 按索引排序 for idx in sorted(outputs.keys()): out = outputs[idx] c, h, w = out.shape[1], out.shape[2], out.shape[3] target_type = ( '极小目标层' if h == 160 else '中小目标层' if h == 80 else '大目标层' if h == 40 else '其他层' ) print(f"{idx:<12} | {str((c, h, w)):<25} | {target_type}") print("-" * 80)


更多推荐


 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)