
深度学习篇---Label Smoothing(标签平滑)
标签平滑(Label Smoothing)是一种正则化技术,通过软化one-hot标签来防止模型过度自信。它将少量概率分配给错误类别(如90%正确类+10%均匀分配),使模型输出更稳健。这种方法能提高泛化能力、容忍标注错误并改善概率校准,在分类任务中效果显著(推荐0.1平滑系数)。PyTorch只需一行代码即可实现:CrossEntropyLoss(label_smoothing=0.1)。其核心
Label Smoothing(标签平滑)
如果说正则化是让模型不要太自信,那么Label Smoothing就是给模型的"自信"加上一个安全阀——不让模型对训练标签过于绝对,留一点怀疑的空间。
这就像是一位明智的老师,不会说"这道题100%是答案A",而是说"这道题90%可能是A,但也有一点点可能是其他选项"。这种"谦逊"反而让模型在考试(测试)时表现更好!
一、Label Smoothing是什么?
1.1 最直观的理解
# 传统one-hot标签(过于绝对)
one_hot = [1.0, 0.0, 0.0, 0.0] # 模型:我100%确定是第0类
# 平滑后的标签(留有余地)
smooth_label = [0.9, 0.033, 0.033, 0.033] # 模型:90%确定是第0类,
# 但也有10%的可能性是其他类生活比喻:
-
传统标签:就像你100%确定明天会下雨(但万一天晴了呢?)
-
平滑标签:就像你看天气预报说有90%概率下雨,10%概率不下(更符合现实)
1.2 数学定义
import torch
import torch.nn.functional as F
def label_smoothing(labels, num_classes, smoothing=0.1):
"""
labels: 原始标签 [batch_size]
num_classes: 类别总数
smoothing: 平滑系数 (通常0.1)
"""
# 原始one-hot
one_hot = F.one_hot(labels, num_classes).float()
# 平滑标签公式:
# y_smooth = (1 - smoothing) * y_onehot + smoothing / num_classes
smooth_label = (1 - smoothing) * one_hot + smoothing / num_classes
return smooth_label
# 示例
labels = torch.tensor([0, 2, 1])
smoothed = label_smoothing(labels, num_classes=10, smoothing=0.1)
print(smoothed[0]) # 第一个样本的平滑标签
# 输出: [0.9, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01]
# PyTorch直接使用
criterion = nn.CrossEntropyLoss(label_smoothing=0.1) # 一行代码搞定!二、为什么需要Label Smoothing?
2.1 传统one-hot标签的问题
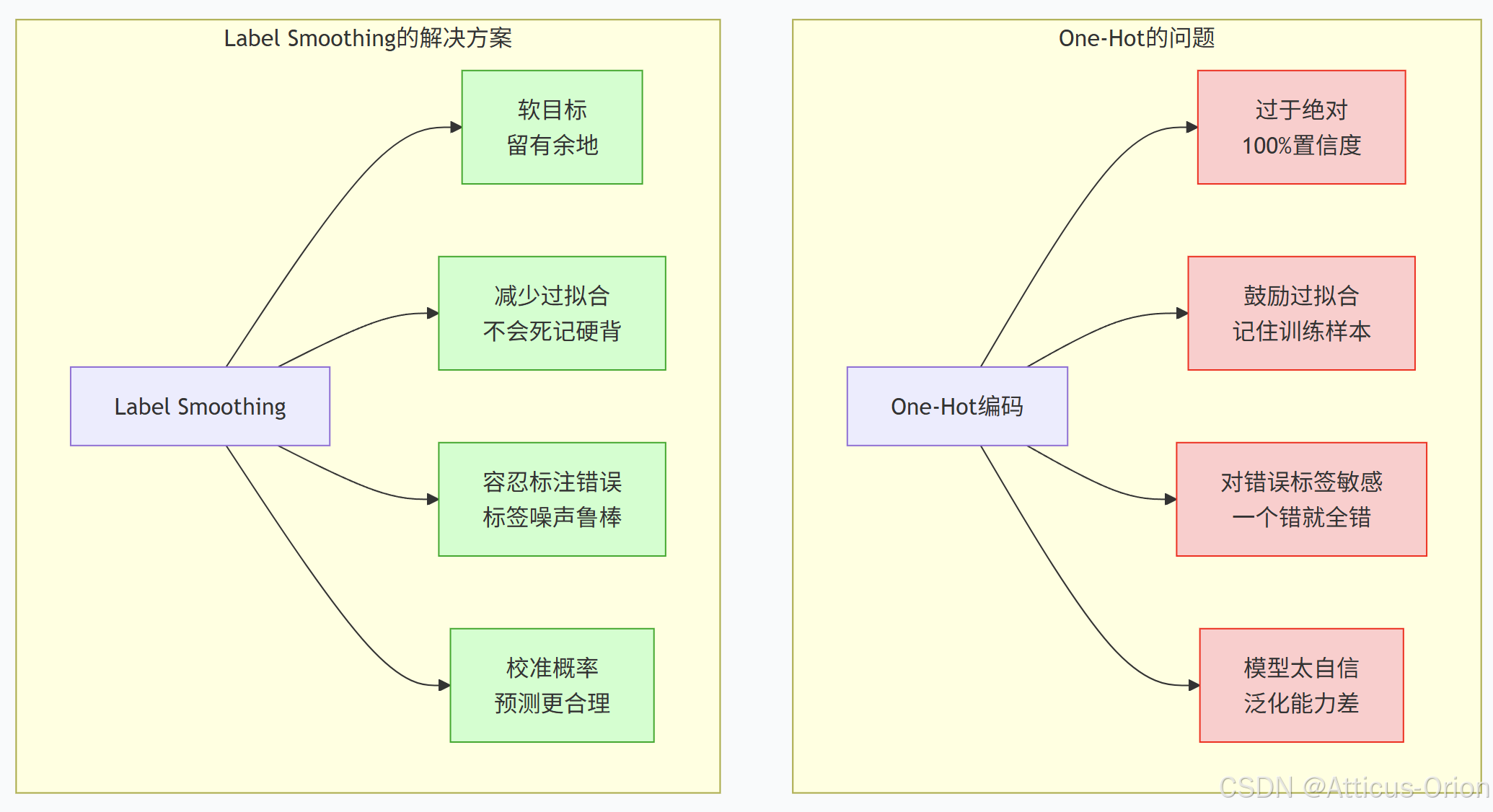
2.2 直观理解:为什么要"软化"标签?
def why_smooth():
"""
为什么需要标签平滑?
"""
# 场景1:标注错误
# 假设一张猫的图片被错误标成了狗
# 传统one-hot:模型拼命学习"这是狗",导致困惑
# 平滑标签:模型学到"90%可能是狗,但也可能是别的",错误影响减小
# 场景2:类别模糊
# 一张图片里既有猫又有狗,该标哪个?
# 传统one-hot:强制选择,不合理
# 平滑标签:允许一定的模糊性
# 场景3:防止过度自信
story = """
想象你在参加一个考试:
- 绝对自信的学生:所有题目都100%确定,但错一题就全扣分
- 谦逊的学生:每道题都说"90%把握",但会检查其他可能性
考试结果往往是谦逊的学生得分更高,因为:
1. 不会因为一道题的错误影响整体
2. 对不确定的题目会多思考
3. 最终的答案分布更合理
"""
return story三、Label Smoothing的工作原理
3.1 数学原理深度解析
import numpy as np
import matplotlib.pyplot as plt
def visualize_smoothing_effect():
"""可视化标签平滑的效果"""
# 假设有5个类别,真实标签是第2类
num_classes = 5
true_class = 2
smoothing = 0.1
# 生成原始one-hot和平滑标签
one_hot = np.zeros(num_classes)
one_hot[true_class] = 1.0
smooth = np.ones(num_classes) * (smoothing / num_classes)
smooth[true_class] = 1 - smoothing + smoothing / num_classes
# 可视化
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
x = np.arange(num_classes)
width = 0.6
ax1.bar(x, one_hot, width, color='red', alpha=0.7)
ax1.set_title('One-Hot 标签\n(过于绝对)', fontsize=14)
ax1.set_xlabel('类别')
ax1.set_ylabel('概率')
ax1.set_ylim(0, 1.2)
ax2.bar(x, smooth, width, color='green', alpha=0.7)
ax2.set_title(f'平滑标签 (smoothing={smoothing})\n(留有余地)', fontsize=14)
ax2.set_xlabel('类别')
ax2.set_ylabel('概率')
ax2.set_ylim(0, 1.2)
plt.tight_layout()
plt.show()
# 计算KL散度(衡量两个分布的差异)
def kl_divergence(p, q):
return np.sum(p * np.log(p / q))
kl_original = kl_divergence(one_hot, one_hot)
kl_smooth = kl_divergence(one_hot, smooth)
print(f"原始标签的自KL散度: {kl_original:.4f}")
print(f"平滑标签的KL散度: {kl_smooth:.4f}")
print("平滑后的KL散度变小了,模型不需要追求完美的one-hot分布")
# 调用可视化
visualize_smoothing_effect()3.2 损失函数的变化
def compare_losses():
"""比较传统交叉熵和平滑交叉熵"""
# 模型预测(logits)
logits = torch.tensor([[2.0, 1.0, 0.1, 0.05, 0.01]]) # 模型认为第0类最好
# 真实标签
targets = torch.tensor([0])
# 1. 传统交叉熵
ce_loss = F.cross_entropy(logits, targets)
# 2. 标签平滑交叉熵
smooth_loss = F.cross_entropy(logits, targets, label_smoothing=0.1)
print(f"传统交叉熵损失: {ce_loss.item():.4f}")
print(f"平滑交叉熵损失: {smooth_loss.item():.4f}")
# 3. 分析差异
probs = F.softmax(logits, dim=-1)
print(f"\n模型预测概率: {probs[0].detach().numpy()}")
# 平滑标签的目标
smooth_target = torch.zeros_like(probs)
smooth_target[0, 0] = 0.9
smooth_target[0, 1:] = 0.1 / 4 # 4个其他类别
print(f"平滑目标分布: {smooth_target[0].numpy()}")
# 平滑损失鼓励模型:
# 1. 正确类别的概率接近0.9(不是1.0)
# 2. 错误类别也有一定概率(不是0)
# 3. 总体分布更平滑
return ce_loss, smooth_loss四、Label Smoothing的实际效果
4.1 对模型输出的影响
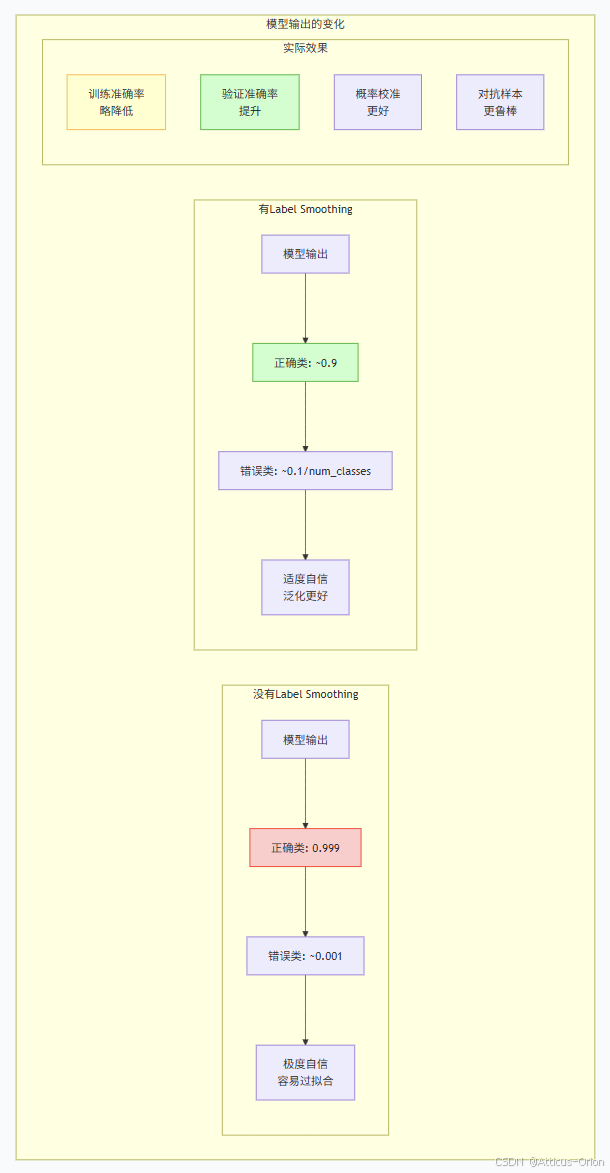
4.2 概率校准效果
def probability_calibration():
"""标签平滑对概率校准的影响"""
# 生成模拟数据
np.random.seed(42)
# 模型预测的置信度(x轴)vs 实际正确率(y轴)
confidences = np.linspace(0, 1, 100)
# 没有平滑的模型:过度自信
accuracy_no_smooth = 1 / (1 + np.exp(-10 * (confidences - 0.3)))
# 有平滑的模型:校准更好
accuracy_with_smooth = confidences * 0.9 + 0.05
plt.figure(figsize=(10, 6))
plt.plot(confidences, confidences, 'k--', label='完美校准', alpha=0.5)
plt.plot(confidences, accuracy_no_smooth, 'r-', label='无平滑 (过度自信)', linewidth=2)
plt.plot(confidences, accuracy_with_smooth, 'g-', label='有平滑 (校准良好)', linewidth=2)
plt.xlabel('预测置信度')
plt.ylabel('实际准确率')
plt.title('标签平滑改善概率校准')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 解释
explanation = """
红色曲线在低置信度区域:实际准确率远高于预测(过于保守)
红色曲线在高置信度区域:实际准确率远低于预测(过于自信)
绿色曲线更接近对角线:预测置信度≈实际准确率
"""
return explanation五、Label Smoothing的超参数
5.1 平滑系数的影响
def smoothing_parameter_effect():
"""不同平滑系数的影响"""
num_classes = 10
# 测试不同的平滑系数
smoothings = [0.0, 0.05, 0.1, 0.2, 0.3, 0.5]
for s in smoothings:
# 对真实类别为0的样本
target_prob = 1 - s + s / num_classes
other_prob = s / num_classes
print(f"\n平滑系数 s={s}:")
print(f" 真实类别目标概率: {target_prob:.4f}")
print(f" 其他类别目标概率: {other_prob:.4f}")
if s == 0:
print(" → 传统one-hot,模型追求100%置信度")
elif s < 0.1:
print(" → 轻微平滑,轻度正则化")
elif s < 0.2:
print(" → 适中平滑,推荐范围")
elif s < 0.3:
print(" → 较强平滑,可能欠拟合")
else:
print(" → 过强平滑,几乎均匀分布")
# 推荐范围
recommendation = """
🔍 平滑系数经验值:
- 0.0: 无平滑(传统方式)
- 0.05: 轻微平滑(小数据集)
- 0.1: 标准推荐(大多数任务)
- 0.2: 强平滑(标签噪声大)
- >0.3: 过强(可能导致欠拟合)
"""
return recommendation5.2 不同任务的最佳值
| 任务类型 | 推荐平滑系数 | 说明 |
|---|---|---|
| 图像分类 | 0.1 | ImageNet比赛常用值 |
| 目标检测 | 0.1-0.2 | 多标签场景稍大 |
| 自然语言处理 | 0.1 | BERT等模型常用 |
| 人脸识别 | 0.1-0.2 | 大规模分类任务 |
| 标签噪声大 | 0.2-0.3 | 容忍标注错误 |
| 小数据集 | 0.05-0.1 | 防止欠拟合 |
六、Label Smoothing的变种
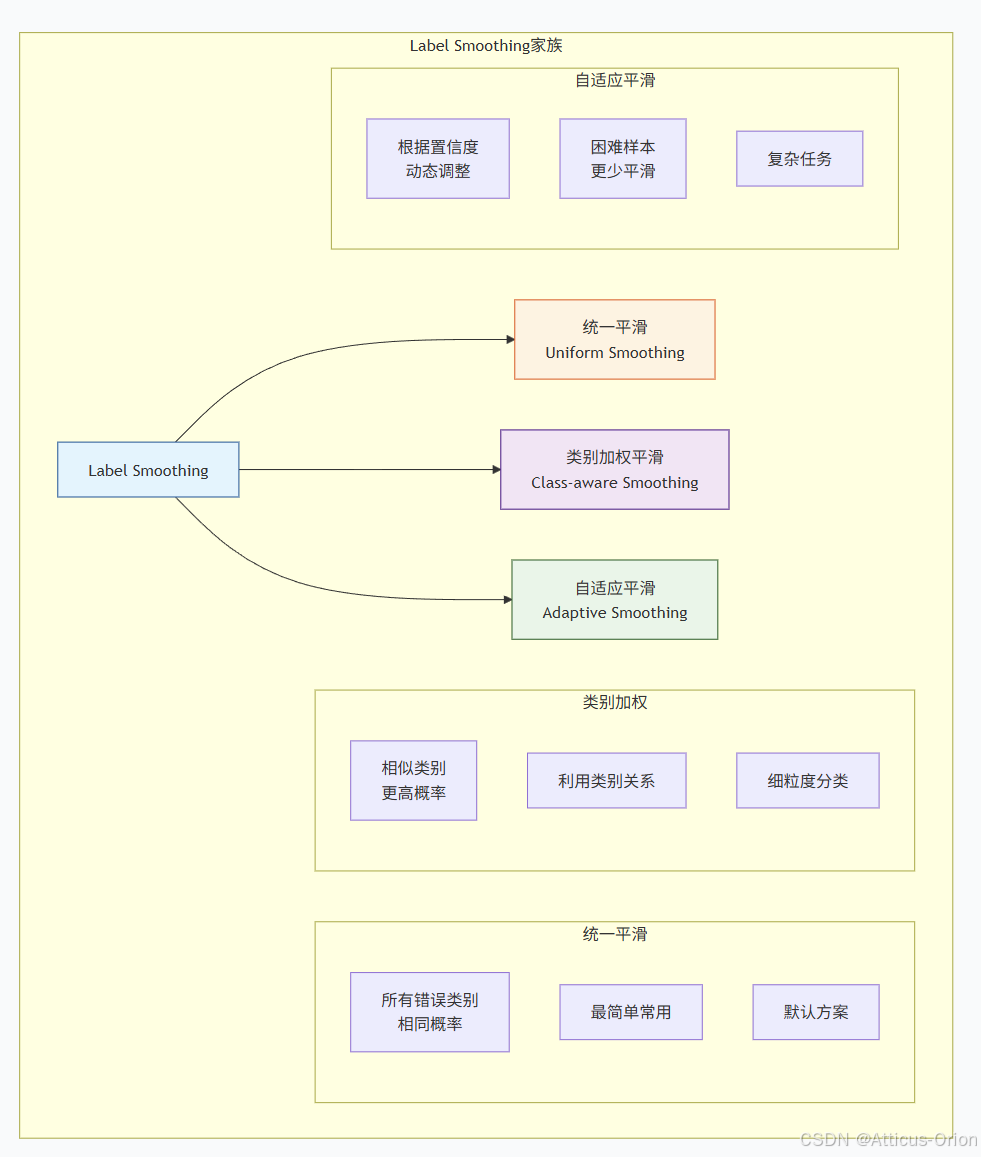
6.1 类别加权平滑
class ClassAwareLabelSmoothing(nn.Module):
"""考虑类别相似性的标签平滑"""
def __init__(self, num_classes, class_similarity_matrix, smoothing=0.1):
super().__init__()
self.num_classes = num_classes
self.smoothing = smoothing
self.similarity = class_similarity_matrix # 类别相似度矩阵
def forward(self, targets):
"""
生成考虑类别相似性的平滑标签
比如:猫和老虎的相似度高,平滑时给更高概率
"""
batch_size = targets.size(0)
# 基础平滑部分(均匀分布)
uniform_part = torch.ones(batch_size, self.num_classes) * self.smoothing / self.num_classes
# 根据相似度调整
for i, target in enumerate(targets):
# 相似类别获得更高的平滑概率
similarities = self.similarity[target]
uniform_part[i] += similarities * self.smoothing / 2
# 正确类别部分
one_hot = F.one_hot(targets, self.num_classes).float()
smooth_labels = (1 - self.smoothing) * one_hot + uniform_part
return smooth_labels6.2 自适应平滑
class AdaptiveLabelSmoothing(nn.Module):
"""根据模型置信度自适应调整平滑强度"""
def __init__(self, base_smoothing=0.1, confidence_threshold=0.8):
super().__init__()
self.base_smoothing = base_smoothing
self.threshold = confidence_threshold
def forward(self, targets, model_confidences):
"""
targets: 真实标签
model_confidences: 模型对当前样本的置信度
"""
# 置信度高的样本,用标准平滑
# 置信度低的样本,用更强的平滑(帮助探索)
smoothing = self.base_smoothing * torch.ones_like(model_confidences)
# 低置信度样本增加平滑
low_conf_mask = model_confidences < self.threshold
smoothing[low_conf_mask] *= 2.0
# 生成平滑标签
batch_size = targets.size(0)
num_classes = 10 # 假设
smooth_labels = []
for i in range(batch_size):
uniform = torch.ones(num_classes) * smoothing[i] / num_classes
one_hot = F.one_hot(targets[i], num_classes).float()
smooth = (1 - smoothing[i]) * one_hot + uniform
smooth_labels.append(smooth)
return torch.stack(smooth_labels)七、Label Smoothing实战技巧
7.1 训练策略
class LabelSmoothingTrainer:
"""标签平滑的训练技巧"""
@staticmethod
def warmup_smoothing(epoch, max_epochs):
"""平滑系数预热"""
# 初期用较小平滑(帮助快速拟合)
# 后期用标准平滑(防止过拟合)
if epoch < max_epochs * 0.2:
# 预热阶段:平滑系数从0.05增加到0.1
return 0.05 + 0.05 * (epoch / (max_epochs * 0.2))
else:
return 0.1
@staticmethod
def mixup_with_smoothing():
"""与Mixup数据增强结合使用"""
def mixup_loss(logits, targets, smoothing=0.1):
# Mixup产生软标签,再结合标签平滑
# Mixup的混合标签
mixup_targets = alpha * target_a + (1 - alpha) * target_b
# 再应用标签平滑
smooth_targets = (1 - smoothing) * mixup_targets + smoothing / num_classes
loss = -(smooth_targets * F.log_softmax(logits, dim=-1)).sum(dim=-1).mean()
return loss7.2 与其他技术结合
def combine_with_other_techniques():
"""标签平滑与其他技术的结合"""
techniques = {
'知识蒸馏': {
'teacher软标签 + student平滑': '双重软化,效果更好',
'建议': 'teacher温度2-4,student平滑0.1'
},
'自蒸馏': {
'自己教自己 + 平滑': '防止模型退化',
'建议': '平滑系数逐渐减小'
},
'对抗训练': {
'对抗样本 + 平滑': '提高鲁棒性',
'建议': '对抗扰动强度适中'
},
'置信度惩罚': {
'直接惩罚过度自信': '等价于标签平滑',
'建议': '可以组合使用'
}
}
return techniques八、Label Smoothing的效果验证
8.1 实验对比代码
def compare_smoothing_experiment():
"""对比有无标签平滑的实验"""
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 创建简单数据集
num_samples = 1000
num_classes = 10
input_dim = 20
X = torch.randn(num_samples, input_dim)
y = torch.randint(0, num_classes, (num_samples,))
dataset = TensorDataset(X, y)
loader = DataLoader(dataset, batch_size=64, shuffle=True)
# 定义简单模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, num_classes)
def forward(self, x):
x = torch.relu(self.fc1(x))
return self.fc2(x)
# 训练函数
def train_model(use_smoothing, smoothing=0.1, epochs=50):
model = SimpleModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)
if use_smoothing:
criterion = nn.CrossEntropyLoss(label_smoothing=smoothing)
else:
criterion = nn.CrossEntropyLoss()
losses = []
accuracies = []
for epoch in range(epochs):
epoch_loss = 0
correct = 0
total = 0
for batch_X, batch_y in loader:
optimizer.zero_grad()
outputs = model(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += batch_y.size(0)
correct += (predicted == batch_y).sum().item()
losses.append(epoch_loss / len(loader))
accuracies.append(correct / total)
return losses, accuracies
# 运行对比
losses_no_smooth, acc_no_smooth = train_model(False)
losses_smooth, acc_smooth = train_model(True)
# 绘制结果
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(losses_no_smooth, 'r-', label='无平滑', alpha=0.7)
plt.plot(losses_smooth, 'g-', label='有平滑', alpha=0.7)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('训练损失对比')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(acc_no_smooth, 'r-', label='无平滑', alpha=0.7)
plt.plot(acc_smooth, 'g-', label='有平滑', alpha=0.7)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('准确率对比')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 预期结果
expected = """
🔬 实验结果预期:
- 训练损失:平滑版略高(因为目标更soft)
- 训练准确率:平滑版略低(没死记硬背)
- 验证准确率:平滑版更高(泛化更好)
- 概率校准:平滑版更好(置信度≈准确率)
"""
return expected九、Label Smoothing的优缺点
9.1 优点总结
| 优点 | 说明 |
|---|---|
| 减少过拟合 | 不让模型死记硬背训练样本 |
| 提高泛化 | 测试集表现更好 |
| 容忍标签噪声 | 对标注错误不敏感 |
| 概率校准 | 模型置信度更合理 |
| 对抗鲁棒性 | 对微小扰动更稳定 |
| 训练稳定 | 损失曲线更平滑 |
9.2 缺点及解决方案
def smoothing_disadvantages():
"""标签平滑的缺点及解决方案"""
issues = {
'训练损失偏高': {
'原因': '目标不是one-hot,损失自然大',
'解决': '关注验证集表现,不是训练损失'
},
'可能欠拟合': {
'原因': '平滑太强',
'解决': '减小平滑系数 (0.05-0.1)'
},
'知识蒸馏不兼容': {
'原因': 'teacher的softmax已经平滑',
'解决': 'student用更小的平滑或不用'
},
'某些任务效果差': {
'原因': '需要极自信的预测(如人脸识别)',
'解决': '调整平滑系数或不用'
}
}
return issues十、Label Smoothing总结全景图
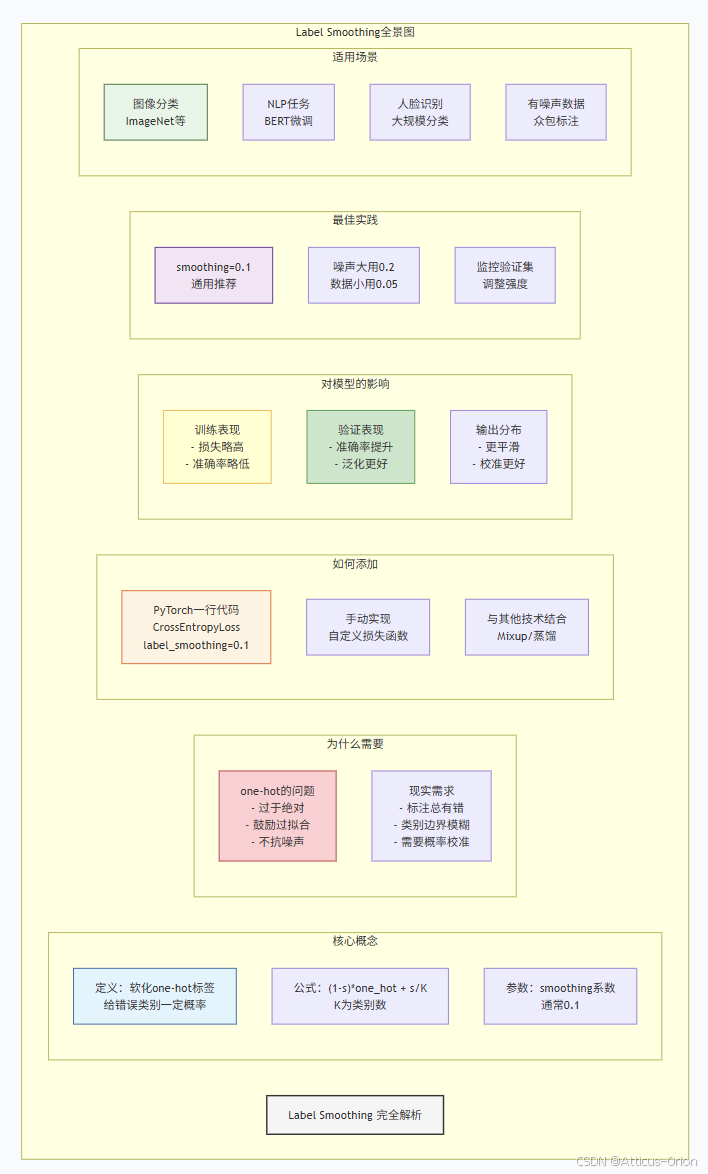
十一、终极总结
Label Smoothing是什么?
-
是一种软化one-hot标签的正则化技术
-
给错误类别分配少量概率,不让模型过于绝对
它解决了什么问题?
-
防止模型过度自信导致的过拟合
-
提高对标注噪声的容忍度
-
改善模型的概率校准
它给模型带来了什么?
-
训练时:损失略高,准确率略低(死记硬背少了)
-
测试时:准确率提升,泛化更好
-
整体:更稳健的概率输出
一句话记住Label Smoothing:
别把话说死,给自己留条后路——留一点怀疑的空间,反而让模型更聪明!
使用口诀:
-
分类任务用平滑,0.1系数最常用
-
标注噪声比较大,加到0.2也不怕
-
训练损失别在意,验证提升是关键
-
一行代码就搞定,PyTorch直接支持
更多推荐


 16
16 0
0- 0



 已为社区贡献82条内容
已为社区贡献82条内容

所有评论(0)