
Med Image Anal:新方法!dHCP:一种基于深度学习的快速新生儿皮层表面重建流程
本研究提出了一种基于深度学习的快速新生儿皮质表面重建流程,显著优化了发展人类连接组项目(dHCP)的处理效率。通过整合深度学习驱动的脑提取、多尺度微分同胚变形网络(实现端到端皮质重建无需组织分割)以及优化的无监督球面投影方法,结合GPU加速技术,将处理时间从原流程的6.5小时缩短至24秒(提速约1000倍)。实验表明,新方法在82.5%测试样本中取得更优或相当的表面质量(54.2%优于原流程),尤
摘要总结:
本文提出了一种基于深度学习的快速处理流程,用于新生儿皮质表面重建,旨在解决Developing Human Connectome Project (dHCP) 现有流程耗时过长的问题。该方法整合了深度学习驱动的脑提取、多尺度变形网络实现端到端皮质表面重建(无需依赖组织分割)、优化后的无监督球形投影,并通过GPU加速关键步骤,将整体处理时间缩短至24秒,较原始流程提速约1000倍。实验表明,新方法在82.5%的测试样本中实现了更优或相当的表面质量(54.2%优于原流程),尤其在顶叶和枕叶等低对比度区域有效减少伪影。通过分析皮质形态特征与孕龄的相关性验证了其对新生儿脑发育的捕捉能力,并在ePrime数据集上展示了良好的泛化性能。球形投影模块在边缘和面积畸变上较传统方法显著降低(0.119mm/0.023mm² vs 原流程0.186mm/0.064mm²),且仅需0.33秒/半球。该方法为大规模新生儿神经影像研究提供了高效解决方案,后续计划扩展功能以支持半监督学习及更多分割任务。
摘要:
人脑连接组发育项目(dHCP)旨在探索人类大脑在围产期的发育模式。目前,已开发出一种自动化处理流程,用于从结构性脑磁共振(MR)图像中提取高质量的大脑皮层表面,以用于dHCP新生儿数据集。然而,当前的流程实现处理一次MRI扫描需要超过6.5小时,使得在大规模神经影像研究中成本过高。本文中,研究者提出了一种快速的基于深度学习(DL)的dHCP新生儿皮层表面重建流程,该流程结合了基于深度学习的脑提取、皮层表面重建和球面投影,以及GPU加速的皮层表面膨胀和皮层特征估计。研究者引入了一个多尺度变形网络,用于从T2加权脑部MRI中端到端地学习微分同胚的皮层表面重建。研究者整合了一种快速的无监督球面映射方法,以最小化皮层表面与投影球之间的度量失真。基于深度学习的dHCP流程的整个工作流程在现代GPU上仅需24秒即可完成,这比原始dHCP流程快了将近1000倍。定性评估表明,在82.5%的测试样本中,研究者基于深度学习的流程重建的皮层表面实现了更优(54.2%)或相等(28.3%)的表面质量,相较于原始dHCP流程而言。
1 引言
1.1背景
在围产期,人脑会经历显着的发育变化,其特征是解剖学和功能连接的形成。发展人类连接组项目(dHCP)在这方面发挥着关键作用。它旨在编制一个广泛的胎儿和新生儿脑磁共振成像。这个雄心勃勃的项目有助于促进对早期大脑发育的深入了解,并为年轻大脑构建四维连接组。dHCP数据集是研究大脑结构发育的正常和异常模式及其各自连接组的宝贵资产。值得注意的是,dHCP公开发布了其新生儿数据集,其中包括783名早产儿和足月新生儿的MRI扫描,总共产生了887张图像。
皮质表面是指大脑皮层的内表面和外表面。内表面,也称为白质表面,是白质和皮质灰质之间的边界。外表面,也称为软脑膜表面,是cGM和脑脊液之间的边界。皮质表面通常由3D多边形网格发送,并且应该具有属0拓扑,即拓扑上等同于没有任何“孔”的2球体。新生儿的皮质折叠和大脑发育可以通过皮质表面的形态特征(如皮质厚度、平均曲率和脑沟深度)进行建模和量化。FreeSurfer和人类连接组计划(HCP)因其针对成年人的自动化神经影像处理流程而受到认可,这些显著成果强调了为dHCP胎儿和新生儿数据集实施基于皮层表面的结构性脑MRI处理与分析的重要性。
然而,成人和新生儿大脑之间的显着差异给调整现有的成人MRI处理方案用于新生儿带来了重大挑战。一个主要挑战在于新生儿脑部MRI的分辨率有限,这是数据采集时间必然短暂的结果。新生儿头部尺寸较小进一步加剧了这种限制,这导致感兴趣区域减少。此外,新生儿大脑的快速发育变化导致不同年龄段大脑的几何形状和大小存在显着差异。另一个值得注意的方面是新生儿脑部MRI的反向对比,这归因于白质中正在进行的髓鞘形成过程,该过程尚未完成。
1.2.相关工作
为了应对新生儿皮质表面提取的挑战,Makropoulos等人(2018)提出了一种用于dHCP新生儿数据集的自动化结构脑MRI处理方案。该方案包括大脑提取、偏置场校正、大脑分割、皮质表面重建、膨胀和包裹、皮质特征估计和球面投影。dHCP新生儿结构采用FMRIB软件库(FSL)大脑提取工具(BET)用于头骨剥离,N4算法用于偏差校正。采用Draw-EM方法进行大脑区域和组织分割。引入了一种基于可变形模型的方法用于皮质表面重建。这种方法迭代地变形初始凸包表面,以拟合WM分割定义的隐式表面的零水平集。根据T2w MRI强度,然后向WM/cGM和cGM/CSF界面变形表面,以生成白质和软脑膜表面。球形拓扑是有保证的,没有拓扑校正是必填的。对于球面投影,dHCP方案采用球面多维缩放(MDS)方法,以最大限度地减少球体和白质表面之间的测地线距离畸变。流程的其余部分遵循FreeSurfer和HCP的设计。
dHCP结构方案在基于皮质表面的新生儿MRI分析中显示出其优势,并为下游应用提供了关键支持。然而,目前的dHCP方案以及其他传统的婴儿神经图像处理方案,如婴儿 FreeSurfer和iBEAT,仍然存在局限性。首先,这些方案需要几个小时来处理一次脑部MRI扫描,这对于大规模神经图像研究来说是相当昂贵的。此外,方案提取的皮质表面的质量在很大程度上依赖于脑组织分割。因此,不准确的分割会导致皮质表面随后的腐败,特别是在T2w MRI图像对比度较低的顶叶和枕叶中。
为了克服传统神经图像方案的局限性,一种替代解决方案是深度学习(DL),它在大型数据集上训练深度神经网络,并在推理过程中进行端到端预测。基于DL的方法由TensorFlow(Abadi et al., 2016)和PyTorch(Paszke et al., 2019) 等成熟框架支持,并由具有快速并行计算的现代图形处理单元(GPU)加速。最近,提出了几种基于DL的脑MRI处理程序,例如FastSurfer(Henschel et al.,2020)、DeepCSR(Cruz et al.,2021)、SegRecon(Gopinath et al.,2021,2023)和iBEAT V2.0(Wang et al., 2023)。这些程序引入了基于学习的模块,以预测大脑MRI的隐式表面,以进行皮质表面重建。隐式表面被表示为分割或有符号距离函数(SDF),SDF是指示到表面的有符号距离的水平集。可以使用行进立方体算法从隐式表面中提取显式3D网格。随后,拓扑校正算法通常用于修复提取表面中的拓扑误差,使其在拓扑上等效于球体。然而,这种拓扑校正算法通常非常耗时,因为它们要么重复将表面投影到球体上以检测拓扑缺陷,要么迭代所有体素以检测临界点。因此,当前基于DL的流程仍然需要半小时以上来处理单个受试者,尽管它们可以提取准确的皮质表面。
与学习隐性表面相反,基于显式学习的方法预测了大脑MRI的一系列变形,将初始模板表面明确变形为皮质表面。由于显式变形不会改变表面拓扑,因此如果初始表面具有属0拓扑,则不需要耗时的拓扑校正。因此,显式方法既快速又能够端到端学习,只需几秒钟即可提取皮质表面,有效规避了不精确分割造成的损坏。为了学习高质量的流形网格,微分同胚变形,这些变形被广泛用于医学图像配准,已被纳入最近基于显式学习的皮质表面重建方法,例如CortexODE(马等人,2022年)、CorticalFlow(Lebrat等人,2021年)、CorticalFlow(Santa Cruz 等人,2022年)、CoTAN、V2C-Flow Bongratz等人(2024年)和Zheng等人(2024年)。此类实验旨在学习微分同胚表面变形,以保留表面拓扑结构并防止表面自相交,这将影响皮质体积、表面积和皮质厚度等皮质几何特征的估计。
表面重建后,通常进行球面投影或球面贴图,以将皮质表面投影到球形网格上,同时最大限度地减少其度量畸变,例如,边缘长度、面面积或测地线距离的畸变。球面投影允许在球面坐标系中对皮质表面进行重复,以执行下游任务,例如皮质表面配准和图集构建。传统的球面投影方法由于皮质表面的迭代膨胀和度量失真的优化,计算密集型。最近,Zhao等人(2022)提出了一种用于球面映射的端到端无监督学习框架。采用多尺度球面U-Net模型(Zhao et al.,2019a,b)来学习粗细微分同胚变形场,以使初始投影球体变形。球形U型网络通过最小化每个分辨率的变形球体和重新采样的皮质表面之间的无监督度量失真来训练。
1.3 贡献
基于原始的dHCP结构研究者提出了一种新的基于DL的方案,用于dHCP新生儿皮质表面重建。该方案包括大脑提取、偏置场校正、皮质表面重建、皮质表面膨胀、皮质特征估计和球面投影。
提出了一种多尺度微分同胚变形网络,用于从T2w MRI端到端提取皮质表面,而无需组织分割。改进了原始的无监督球面映射框架,使运行时间从 2.1 秒加速到0.3秒,同时边缘和区域失真显着减少。按照原始dHCP的过程,方案的其余步骤将使用GPU加速重新实现。研究者基于DL的dHCP新生儿方案主要用Python实现。方案中的大多数处理步骤都是使用PyTorch实现的,这是一个著名的深度学习库,支持GPU加速。研究者基于DL的方案速度快且内存效率高,只需24秒即可在具有12GB内存的GPU上完成所有过程。这比原始dHCP快近1000×,后者需要超过6.5小时的运行时间。研究者对测试集中的皮质表面进行手动质量控制,这表明研究者基于dHCP DL产生的皮质表面质量优于原始dHCP,同时速度快几个数量级。基于DL的dHCP新生儿方案的代码已公开。
2 基于深度学习的dHCP新生儿方案
2.1 数据采集
在本文中,使用了第三次公开dHCP数据发布的新生儿数据集2。dHCP新生儿数据集包括783名新生儿受试者和887次扫描。出于纵向研究的目的,一小部分受试者被扫描了不止一次。在27周和45周的月经后年龄(PMA)对新生儿进行扫描,出生时和扫描时的年龄分布如图1所示。
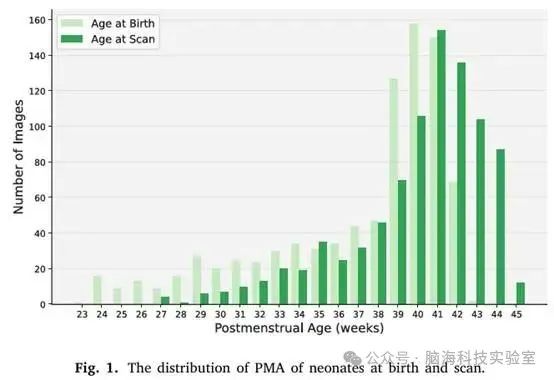
图1.新生儿出生时和扫描时PMA的分布
对于MRI采集,婴儿在自然睡眠中的3T飞利浦扫描仪上进行成像,该扫描仪配备了专用的新生儿脑成像系统。T2图像是在轴向和矢状面的两堆2D切片中以0.8 × 0.8 mm2分辨率和1.6 mm重叠切片获取的。采集使用参数重复/回波时间TR/TE = 12 s/156 ms,SENSE因子为2.11(轴向)和2.60(矢状面)。采用运动校正技术来补偿成像过程中的头部运动。以0.5 mm3各向同性分辨率重建为高质量的3D体积。详细的MRI采集方案在Edwards等人中进行了描述。
2.2 流程概述
基于DL的dHCP新生儿方案的工作流程如图2所示。基于DL通过集成多个基于 DL 的模块和重新实现的算法以及GPU加速来加速原始dHCP结构。该方案由五个主要步骤组成:预处理、皮质表面重建、皮质表面膨胀、皮质特征估计和球面投影。
遵循原始的dHCP结构,研究者使用T2w结构脑MRI作为主要输入。给定一张T2w图像,该方案使用3D U-Net来学习大脑掩码以提取大脑ROI。然后,应用N4偏置场校正来归一化T2图像的强度。处理后的图像与40周的dHCP图谱精确。引入了一个多尺度变形网络,该网络学习了微分同胚表面变形的顺序,以从对齐的T2w图像中首尾相连地重建皮质白质和软膜表面。预测的白质表面被迭代膨胀和平滑,以生成膨胀和非常膨胀的表面。接下来,从提取的皮质表面计算皮层的形态特征,包括皮质厚度、曲率和沟深度。如果提供T1 MRI,方案会根据T1/T2比率估计髓鞘图。最后,该方案采用球形U型网将白质表面投射到球体上,同时最大限度地减少公制失真。
2.3 数据集准备
为了训练和评估所提出的基于DL的方案的每个组件,研究者在dHCP新生儿数据集中使用了879张图像,其中8个样本在数据清理过程中被排除在外。每个数据样本包括T2结构脑MRI以及原始dHCP结构方案生成的伪地面实况(GT)分割和皮质表面。
原始 T2w 图像的大小为 217 × 290 × 290。数据集被随机拆分为训练/验证/测试集,比例为60∕10∕30%。研究者生成初始模板图像、表面和球体,用于训练和运行方案。生成的模板将为所有主题共享。如图3所示从40周的dHCP图谱创建图像模板。由于研究者的目标是开发快速且内存高效的方案,因此研究者将原始图集从0.5 mm3的各向同性分辨率下采样到 0.6 mm3,并将其裁剪为176 × 224 × 160的大小,以降低GPU内存成本。下采样后的图集用作仿射配准的目标图像模板。应该注意的是,如果GPU内存允许,则不需要降采样。
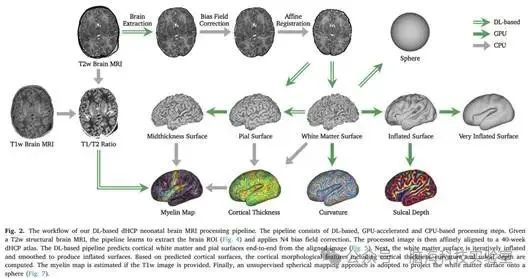
图2. 基于DL的dHCP新生儿脑部MRI处理的流程
接下来,研究者运行原始的dHCP,从dHCP图谱中提取中厚表面。对于每个大脑半球,迭代平滑和重新划分中间厚度表面,以创建一个膨胀的初始表面,该表面与图像模板位于同一空间中。这样的初始表面网格有150k个顶点,用作皮质表面重建的输入模板表面。这使得所提出的基于DL的方案能够预测具有相同网格连接和固定顶点数量的皮质表面,而原始的dHCP方案提取具有适应顶点数量的皮质表面,导致对皮质形态特征的估计不准确,例如年轻受试者的脑沟深度。最后,研究者使用FreeSurfer mris_inflate和mris_sphere将初始曲面投影到初始球体上,该球体具有与初始曲面相同的网格连通性,并最大限度地减少了met ric畸变。初始球体用作球面投影的输入。
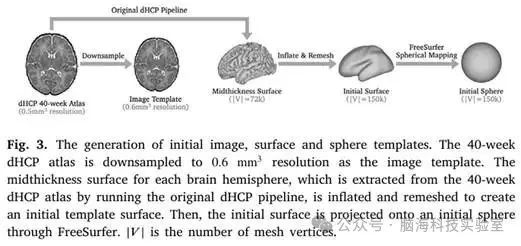
图3. 生成初始图像、表面和球体模板
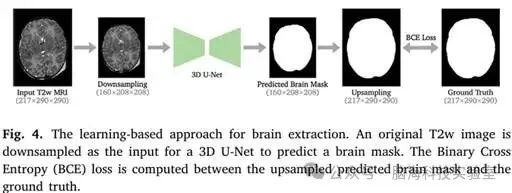
图4. 基于学习的大脑提取方法
2.4 预处理
脑提取。预处理步骤包括脑提取、偏场校正和仿射配准。对于脑提取,如图4所示,研究者训练了一个3D U-Net来从输入的原始T2w图像中预测脑掩膜。为了减少GPU内存使用量,研究者将输入的T2w图像下采样到160 × 208 × 208的尺寸。预测的脑掩膜会被上采样到原始尺寸以提高准确性。研究者计算预测结果与真实情况(GT)脑掩膜之间的二元交叉熵(BCE)损失。真实情况的脑掩膜由FSL BET(Smith,2002)生成,该方法已集成到原始dHCP结构流水线(Makropoulos等,2018)中。3D U-Net模型使用Adam优化器进行训练,学习率为10−4,共训练100个周期。
偏差场校正和仿射配准。使用N4偏置场校正来归一化大脑提取的 T2w 图像的强度。然后,研究者将偏差校正图像与dHCP 40周图像模板进行精确对齐,如第2.3节所述。为了提高准确性,研究者首先应用刚性配准以获得初始变换,然后应用仿射配准。仿射配准将所有MRI转换为大小为176 × 224 × 160的模板空间,从而降低后续过程的GPU内存成本。所提出的方案集成了Python中的高级Normalization工具(ANTsPy),它提供了CPU。
2.5 皮质表面重建
研究者提出了一种基于端到端学习的皮质表面重建方法。为了解决新生皮质表面所需的大变形,研究者引入了多尺度变形网络,该网络学习一系列微分同胚变换,使初始表面变形为白质和软膜。
由于单个SVF(静态变形场)的表示能力有限,本文提出多尺度变形网络,以学习一系列用于大脑皮层表面重建的微分同胚变形场𝜙1,…,𝜙𝐿。如图5所示,给定一个仿射对齐的T2w图像,研究者将其从原始尺寸176 × 224 × 160裁剪为112 × 224 × 160,以分别处理左脑或右脑半球。随后,多尺度变形网络从裁剪后的脑部MRI端到端地预测大脑皮层表面。由于所提出的神经网络模型一次仅处理一个脑半球,因此这种裁剪不仅为大脑皮层表面重建提供了必要的信息,还有效地降低了GPU内存消耗和推理时间。请注意,脑部分割不需要作为输入,因为这将导致后续的校正问题。
放置剪辑的T2图像。然后,从提取的特征图中预测一系列多尺度体积SVF v1,...,vL。对于l = 1,..., L − 1,每个 SVF vl 将原始脑部 MRI 体积下采样 2L−l−1 倍。最后一个SVF vL 的大小与输入音量相同,以捕捉精细细节。以前的工作采用正向欧拉法求解常微分方程(1),该方法速度很快,但可能会引入较大的数值误差。相反,研究者使用缩放和平方方法进行集成,更准确,广泛用于医学图像配准任务。对于每个尺度𝑙 = 1,…, 𝐿,研究者将初始变换设为𝜙𝑙𝑇∕2𝐾 = 𝑖𝑑 + 𝑇⁄2𝐾 ∙ 𝑢𝑙,然后可以通过𝜙𝑙𝑇∕2𝐾−1 = 𝜙𝑙𝑇∕2𝐾 ◦𝜙𝑙𝑇∕2𝐾递归地更新变形场,其中𝐾是缩放和平方的步数。这相当于执行了2𝐾步的前向欧拉法。通过积分,网络预测了多分辨率的微分同胚变形场𝜙𝑙,每个变形场的大小均与对应的SVF 𝑣𝑙相同。
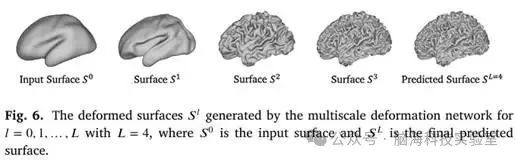
图6. 多尺度变形网络生成的变形面L,对于l = 0,1,..., L,L = 4,其中S0是输入面,SL是最终预测面
最后,研究者将变形场迭代地应用于输入表面𝑆0 ⊂ R3。表面网格顶点的位移通过线性插值进行采样。通过𝑆𝑙 = 𝜙𝑙(𝑆𝑙−1)对表面进行更新,其中𝑙 = 1,…, 𝐿。研究者将尺度数量设置为𝐿 = 4,这使得多尺度变形网络能够对从粗到细的表面变形进行建模。变形场𝜙1和𝜙2的尺寸分别缩小了4倍和2倍。如图6所示,𝜙1和𝜙2包含全局信息,并将输入表面𝑆0变形为粗糙且平滑的中间表面。𝜙3和𝜙4的尺寸与输入脑MRI相同,能够捕捉详细的皮质褶皱,并为最终预测的白质或软脑膜表面𝑆𝐿提供进一步的优化。
对于白质表面提取,研究者使用图3中描述的初始模板表面作为所有受试者的输入表面。预测的白质表面通过Taubin平滑(Taubin,1995)进一步优化,以提高网格质量,即三角网格的平滑度和规则性。对于软脑膜表面重建,研究者使用预测的白质表面作为输入表面。由于初始表面具有0亏格拓扑结构,并且微分同胚变形保持拓扑结构不变,因此所有表面均保持相同的拓扑特性。
研究者训练了四个多尺度变形网络,用于两个大脑半球的白质和软膜表面重建。研究者考虑以下损失函数:
![]()
具体而言,𝑋和𝑌分别表示预测的和伪真实值(pseudo GT)皮质表面的网格顶点集合。伪真实值皮质表面是使用原始的dHCP流程生成的。所有伪真实值表面都被重新网格化,使其具有15万个顶点,以减少计算Chamfer距离时由于点匹配引入的误差。研究者采用了PyTorch3,它提供了快速的计算支持。
引入边缘长度和法线一致性约束,以促进预测皮质表面的平滑度并改善网格质量。对于曲面网格M =(V,E,F),其中V,E,F分别是顶点、边和面的集合,边长损失定义为:
![]()
其中 vi, vj 是由边 eij = (i, j)连接的两个顶点。正常一致性损失定义为:
![]()
这里,𝑛𝑖是面𝑓𝑖∈𝐹的单位法向量,而𝑒 = 𝑓𝑖 ∩ 𝑓𝑗是相邻面𝑓𝑖和𝑓𝑗相交的边。法向一致性损失惩罚任意两个相邻面之间法向量的点积。法向一致性损失的数值取决于新生儿的PMA(产后年龄)和大脑皮质表面的曲率。对于具有高度折叠和弯曲皮质表面的较大新生儿,两个相邻面的法向方向之间存在较大差异。因此,法向一致性损失达到较高值以加强表面的平滑性。而对于皮质表面尚未完全成熟的较小受试者,该损失相对较低,因为其大脑皮质表面已经足够平滑。对于多尺度形变网络的架构,研究者如第2.5.2节中讨论的那样,将尺度数设为𝐿 = 4。较小的𝐿无法提供足够的全局信息,而较大的𝐿更适合高分辨率图像下的脑部MRI。隐层通道数在白质表面重建中设为{16,32,64,128,128},而在软脑膜表面重建中则设为{16,32,32,32,32},以避免过拟合。研究者对白质和软脑膜表面重建使用了相同的超参数。正则化权重通过网格搜索选择,并设为𝜆𝑒𝑑𝑔𝑒 = 0.3和𝜆𝑛𝑐 = 3.0,以获得满意的网格质量。
2.6 大脑皮层表面膨胀
根据HCP和原始dHCP流程(Makropoulos等,2018),研究者的dHCP DL流程包含了两种类型的皮层表面膨胀。首先,原始流程采用Connectome Workbench(Glasser等,2013)对mid-thickness表面进行迭代膨胀和平滑处理,以生成膨胀表面和极度膨胀表面。这些表面主要用于可视化。每个网格体顶点都是通过积分顶点沿其法线方向的位移来计算的。由于所有皮质表面都有固定数量的顶点,研究者基于 DL 的 dHCP 方案提供与年龄一致的脑沟深度估计,而原始 dHCP 方案为年幼的婴儿提取顶点数量较少的皮质表面,导致表面过度膨胀和高估脑沟深度。
2.7 皮质特征估计
基于提取的皮质表面,研究者基于深度学习的dHCP流程提供了皮质形态特征的估计,如皮质厚度、曲率和脑沟深度,以及功能特征如髓鞘图。皮质特征的估计与之前的流程一致(Glasser等人,2013;Makropoulos等人,2018)。皮质厚度是通过计算白质和软脑膜表面之间的双向距离的平均值得出的。这是通过Python中的SciPy包(Virtanen等人,2020)实现的。此外,通过基于PyTorch的重新实现、,计算了白质表面的平均曲率。配准到T2图像后,研究者在进行强度归一化之前将T1图像除以原始T2图像,以计算T1/T2比值。随后,通过体到面映射方法,将T1/T2比值投影到中厚度表面上,以此估算髓鞘图。该过程使用Connectome Workbench软件实现。对于中厚度表面网格中的每个顶点,研究者找到其在T1/T2比值图像中对应的位置,并计算其邻近体素的高斯平均值,作为该位置的髓鞘图值。仅考虑皮质带 ROI 内的体素。然而,检查体素或点是否位于内皮质表面和外皮质表面之间是计算密集型的,特别是对于具有 150k 顶点的高分辨率网格。为了加速体积到表面的映射,研究者训练一个3D U-Net来学习二元皮质带掩模,即皮质GM分割。学习过程类似于大脑提取,如图4所示。伪GT分割由集成在原始dHCP方案中的Draw-EM方法生成。
2.8 球面投影
球面投影或球面映射的目的是将白质表面投影到球体上,同时最大限度地减少公制失真。在 Zhao 等人(2022 年)的推动下,研究者提出了一种用于球面投影的无监督学习框架,并将其集成到研究者基于 DL 的 dHCP 方案中。如图7所示,球面投影框架的输入包括所有受试者的白质表面和固定的初始球体。请注意,由于所有白质表面都是从相同的初始模板表面变形的,因此白质表面与初始球体具有相同的网格连通性,初始球体是由FreeSurfer从初始表面生成的(见图3)。因此,与其充气白质表面并投影膨胀表面,为每个受试者创建一个球体。
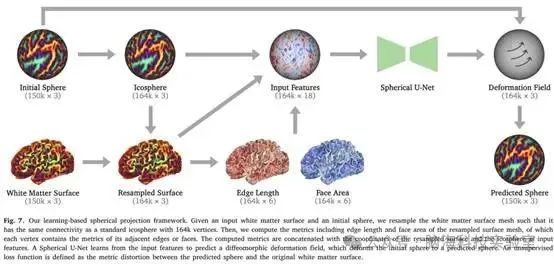
图7. 基于学习的球面投影框架
对输入的白质表面网格进行重采样,使其具有与标准二十面体球(具有163,842个顶点)相同的连接性。这是通过在初始球体与二十面体之间进行重心插值实现的,其中重心坐标是预先计算好的,以加速重采样过程。然后,研究者计算重采样后的白质表面的度量,包括边长和面面积。每个顶点包含其相邻边和面的度量信息。研究者将重采样后的白质表面坐标、二十面体坐标以及计算得到的度量信息作为输入特征,输入至一个球面U型网络,该网络已广泛应用于皮层表面分析任务,如皮层表面配准(Zhao等,2021a)、分区(Zhao等,2019b)和发展预测。训练球形 U-Net 通过使用缩放和平方积分 SVF 来学习球面域中的微分同胚变形场。研究者没有在损失函数中添加正则化项,而是将拉普拉斯网格平滑应用于变形场以鼓励平滑度。预测的球体是通过变形初始球体得出的,其中每个顶点的位移是通过使用重心插值从变形场中采样来确定的。
3 与现有神经影像方法的比较
3.1 与原始dHCP的比较
基于DL的dHCP新生儿方案与原始dHCP方案(Makropoulos 等人,2018 年)在方法、实施和运行时间方面进行了比较。第4节提供了表面和球体质量的比较。在表1中比较了原始和基于DL的dHCP之间主要处理步骤的不同方法。研究者基于DL的方案为关键处理步骤集成了基于学习的新方法,并端到端地预测皮质表面,而无需组织分割。
在表1中比较了原始方案和基于深度学习的dHCP(developmental Human Connectome Project,人类发展连接组计划)方案之间主要处理步骤的不同方法。研究者的基于深度学习的方案整合了基于学习的新方法用于关键处理步骤,并且无需进行组织分割即可端到端地预测皮质表面。
表1. 原始dHCP和研究者基于DL的dHCP之间脑提取、组织分割、皮质表面重建和球面投影方法的比较

原始的dHCP方案使用MIRTK(Makropoulos等人,2018)、Connectome Workbench(Glasser等人,2013)和FSL(Jenkinson等人,2012)实现。由于MIRTK包的安装和配置较为复杂,因此很难复现或修改原始的dHCP方案。对于研究者的基于深度学习的dHCP方案,每个处理步骤的实现见表2。研究者的基于深度学习的dHCP方案主要用Python和PyTorch实现,这简化了部署,提高了可重复性,并允许更直接的修改和调整。PyTorch库为并行计算和GPU加速提供了无缝支持。PyTorch3D包是皮质表面重建训练所必需的,并为基于网格的处理提供实用工具。ANTsPy用于N4偏置校正和仿射配准。Connectome Workbench(WB)用于可视化和髓鞘图估计。研究者的基于深度学习的方案具有GPU内存效率,训练仅使用12GB内存,推理使用7.6GB GPU内存。因此,通过微调神经网络模型,可以轻松地将该方案适配到新的数据集。
表2. 所提出的dHCP DL的实现和运行
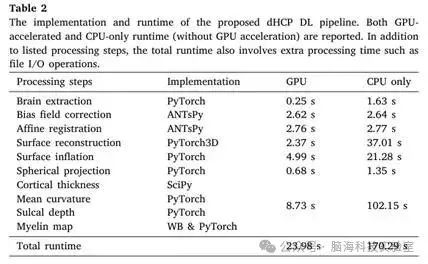
表3. 基于DL的神经图像处理之间的功能和运行时间比较:FastSurfer、iBEAT V2.0和dHCP DL

为了测量运行时间,研究者运行原始和基于DL的dHCP来处理10名dHCP新生儿受试者的脑部MRI,这些受试者是从测试集中随机选择的。运行时间是在8核Intel Core i7-11700K CPU和具有3080 GB内存的NVIDIA GeForce RTX 12 GPU上测量的。原始的dHCP仅在CPU上运行,需要6小时38分钟才能处理单个受试者。基于体积和表面的处理分别需要2小时9分钟和4小时29分钟。对于基于DL的方案,在表2中报告了有和没有GPU加速的运行时。通过GPU加速,运行整个基于DL只需24 秒,比原始dHCP快995倍。皮质表面重建和球面投影总共只需要3 s,这要归功于强大的端到端深度学习方法。即使没有GPU加速,基于DL也只需要170秒即可在CPU上完成,与原始dHCP相比,这仍然快了140倍。
3.2 与基于DL的神经图像方案的比较
将dHCP DL与现有的基于DL的神经图像处理进行了比较,包括FastSurfer 和iBEAT V2.0。表3中报告了有关GPU上功能和近似运行时间的比较。
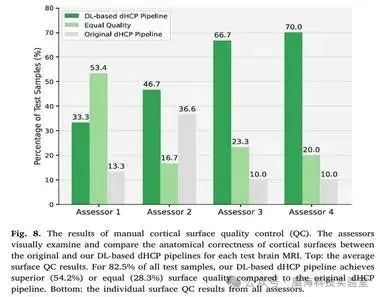
图8. 手动皮质表面质量控制(QC)的结果
表3显示,以前基于DL侧重于基于学习的大脑区域和组织分割方法。然而,这些仍然采用传统的皮质表面重建方法,包括计算密集型拓扑校正,因此需要一个多小时来处理一次脑部MRI扫描。研究者基于DL的dHCP引入了基于快速学习的方法,以加速最耗时的皮质表面重建和球面投影,分别比FastSurfer和iBEAT V2.0快150×和 600×。
研究者基于 DL 的 dHCP 方案从 T2w 脑部 MRI中端到端提取皮质表面,无需中间组织分离。这可以防止错误从分割传播到皮质表面。因此,如表3所示,目前研究者的管线不提供脑组织分割和皮质表面分块。研究者将开发相应的基于DL的方法,并在未来的工作中将其集成到研究者的方案中。
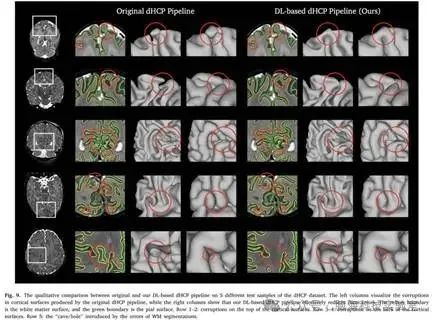
图9.原始和基于DL的dHCP在dHCP数据集的5个不同测试样本上的定性比较
4 质量控制
4.1 皮质表面质量
通过目视检查进行手动质量控制,以评估基于DL的dHCP生成的皮质表面的质量。皮质表面质量,即皮质表面的解剖正确性,是通过皮质表面解剖错误和腐败的数量和严重程度来衡量的。由于缺乏GT表面,研究者使用原始dHCP生成的皮质表面作为基线。更具体地说,研究者的视觉QC旨在检查与原始dHCP相比,基于DL的dHCP是否提取出具有更好表面质量的皮质表面。
265个测试用例中随机选择30个T2w脑部MR样本进行。对于每个测试脑部MRI,研究者分别通过原始dHCP和基于DL的dHCP提取两组皮质表面。视觉QC由四名具有临床背景或在神经图像分析方面拥有丰富经验的专家评估员进行,以减轻个体差异。为确保公平性,所有评估员在不知道相应的重建方法(原始或基于DL)的情况下独立评估两组皮质表面。要求评估人员仔细检查和检测两组皮质表面的腐败区域,然后根据已识别缺陷和伪影的数量和严重程度,为每个测试样品选择表面质量较好的组。
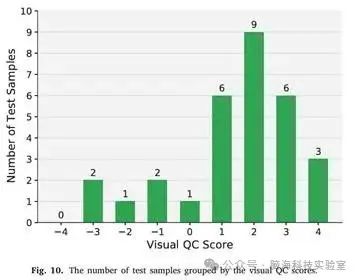
图10. 按视觉QC分数分组的测试样本数
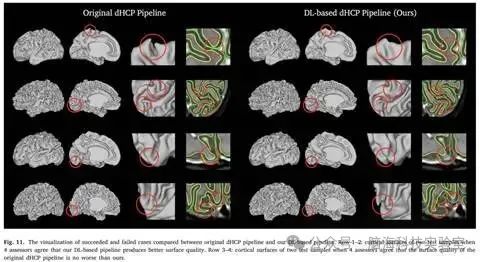
图11. 原始dHCP和基于DL之间比较成功和失败案例的可视化
图8中的个别QC结果也表明,研究者基于DL的dHCP方案在所有评估人员的定性评估中取得了更好的性能。这些表明,研究者基于DL的dHCP可以重建更高质量的皮质表面,同时比原始dHCP方案快995×。此外提供了通过原始和基于DL的dHCP重建的皮质表面之间的视觉比较。图9显示了5个不同样品的皮质表面。这表明,由于T2w脑MRI相应区域的图像对比度较低,原始dHCP容易在皮质表面的顶部和背面(顶叶和枕叶)产生破坏,而研究者基于DL的方案与原始dHCP方案相比,在这些区域实现了更好的解剖正确性。此外,原始dHCP方案产生的表面受到不精确的Draw-EM分割的影响,因此偶尔会产生意想不到的“洞穴”或“孔洞”,如图9所示。研究者基于DL的dHCP利用微分同胚表面变形,并从脑部MRI中端到端学习皮质表面,从而有效避免此类问题。
根据手动QC结果进一步测量了30个测试样品中每个样品的视觉QC分数。每个测试对象的视觉QC分数s由s = ∑4 i = 1si 计算,其中 si = 1 如果第i个评估员观察到基于DL的与原始dHCP的基线相比产生更好的表面质量,si = 1 如果原始方案性能更好,si = 0 表示相同的表面质量。例如,s = 4 表示所有 4 个评估员都同意研究者基于 DL 的方案在表面质量方面具有更好的性能。研究者计算按视觉 QC 分数 -4 分组的测试对象数量 -4 ≤ 秒≤ 4。图10所示的结果表明,30个测试用例中有80%的视觉QC得分为0>,这意味着研究者基于DL的方案比原始dHCP方案实现了更好的解剖正确性。为了探索所提出的基于DL的dHCP方案的成功和失败案例,在图11中,研究者可视化了QC分数s = 4和s = −3的测试样品,即所有4位评估者都同意研究者基于DL的dHCP方案的表面质量更好,也不比原始方案更好。图11中的第1-2行显示,成功的案例(s = 4)可以减轻原始dHCP方案产生的皮质表面顶部和背面的系统误差。然而,第 3-4 行中基于 DL 的方案的失败示例 (s = −3) 仍然在枕叶中引入腐败,受到 p 有限表面质量的影响。
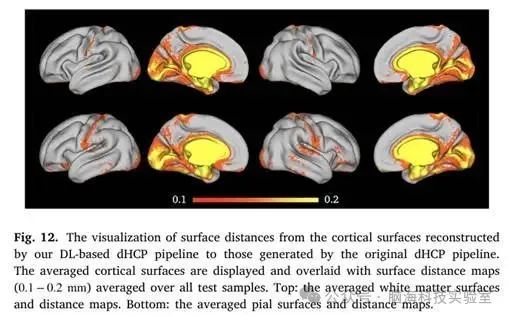
图12. 可视化从基于DL的dHCP重建的皮质表面到原始dHCP生成的表面距离
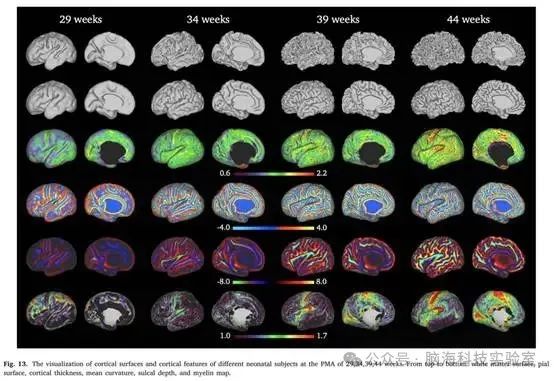
图13. 29、34、39、44 周 PMA 时不同新生儿受试者皮质表面和皮质特征的可视化。从上到下:白质表面、软脑膜表面、皮质厚度、平均曲率、沟深度和髓鞘图
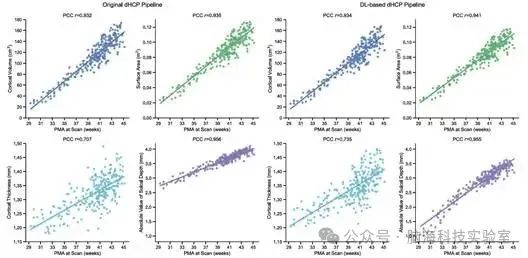
图14. 比较265名扫描时具有不同PMA的测试新生儿受试者的皮质形态特征,包括皮质体积(cm3)、表面积(m2)、平均皮质厚度(mm)和颅沟深度的平均绝对值(mm)
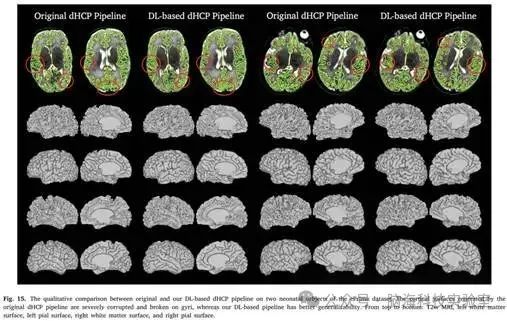
图15. 原始和基于DL的dHCP对ePrime数据集的两个新生儿受试者的定性比较
图12中显示的距离图显示了皮质表面的顶部,背部(枕叶)和内侧壁的较大表面距离。结合手动QC结果,皮质表面顶部和背面的巨大定量差异意味着研究者基于DL的方案可以减少原始dHCP方案在图9中观察到的这些区域引入的系统误差。此外,内侧壁上的大表面距离超出了皮质表面分析的ROI,这是预期的,因为原始的dHCP从包含内侧壁清晰边界的分段中提取皮质表面,而基于DL的方案从脑部MRI扫描中端到端提取皮质表面。
研究者提供定性和定量评估,以验证研究者的 dHCP DL 方案提取的皮质表面是否可以捕捉新生儿的大脑发育。研究者在图 13 中可视化了在 29、34、39、44 周的 PMA 扫描的不同新生儿受试者的皮质表面以及相应的皮质特征。在图13中观察到皮质折叠,PMA的增加。皮质厚度和脑沟深度也随着大脑的生长而增加。对于原始和基于DL的dHCP方案,研究者在图14中测量和绘制了所有265名测试新生儿受试者的皮质形态特征,包括皮质体积,表面积,皮质厚度和脑沟深度。皮质体积等于两个大脑半球的软膜表面体积减去白质表面的体积。表面积是指胶囊表面的网格面积。每个受试者的皮质厚度和脑沟深度是通过平均皮质厚度和表面网格上所有顶点上的脑沟深度的绝对值来测量的。
表4 皮质表面自相交面(SIF)数量
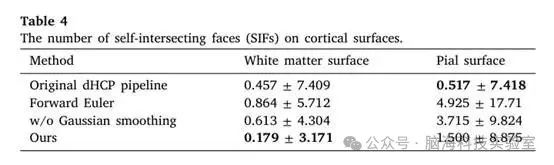
图14显示了形态特征随着PMA增加的正向趋势,这反映了新生儿大脑皮层的生长和折叠。此外,研究者计算皮尔逊相关系数r来测量形态特征与PMA之间的相关性。PCCs如图14所示,表明所有皮质形态特征都与新生儿的年龄呈强正相关。这验证了研究者基于DL的提取的皮质表面能够。
与原始的dHCP相比,基于DL的测量的皮质体积和表面积表现出相似的趋势。对于皮质厚度,研究者基于DL的方案比原始方案具有更强的相关性和更高的PCC值。研究者注意到,在图14中,原始方案估计的脑沟深度绝对值远高于研究者的。通过原始dHCP提取的皮质表面具有适应的顶点数量,即对于年轻受试者来说,顶点较少。结果,年幼婴儿的皮质表面在充气过程中过度膨胀,从而导致高估沟深度。
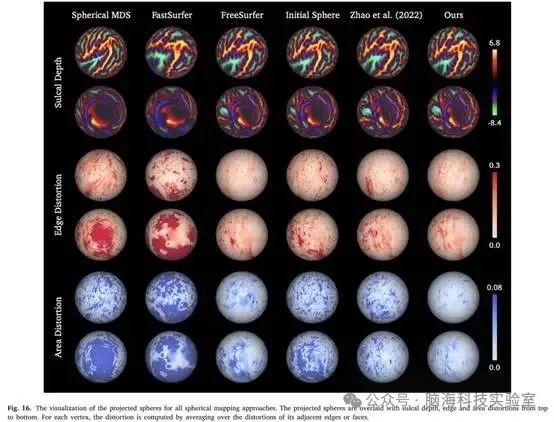
图16. 所有球面映射方法的投影球体的可视化。投影的球体从上到下覆盖着沟的深度、边缘和区域扭曲。对于每个顶点,通过对其相邻边或面的畸变进行平均来计算畸变
进一步检查表面自交,通常出现在软膜表面的狭窄沟中,会影响皮质形态特征的估计。研究者检测并计算原始和基于DL的dHCP方案生成的白质和软脑膜表面网格中的自相交面(SIF)数量。为了验证所提出的多尺度变形网络能够有效减少SIF,研究者通过去除高斯平滑层或替换缩放平方方法来进行烧蚀实验与前锋欧拉进行整合。SIF的数量如表4所示。
尽管研究者的多尺度变形网络在理论上保证了微分同构,但离散化过程中由数值误差引起的SIF数量仍然可以忽略不计,例如微分方程整数、变形场的体积表示和网格顶点数量有限。表4显示基于DL的dHCP方案在白质表面平均仅产生0.18 个SIF。原始的dHCP方案在 pial 表面产生的 SIF 比研究者的方案略少,因为它在迭代表面变形期间执行碰撞检测。表4还验证了通过添加高斯平滑层并使用缩放和平方方法可以有效减少SIF。
4.2 球体质量
研究者通过方程中定义的度量畸变来评估球面投影的性能。与原始dHCP流程类似,球体的质量是通过白质表面与投影球体之间的边长和面面积的形变程度来衡量的。研究者将基于无监督学习的方法与现有的球面映射方法进行了比较,这些方法包括球面MDS(Elad 等,2005)、FreeSurfer(Fischl,2012)、FastSurfer的方法。研究者还提供了白质表面与初始球体之间的度量形变作为基准。为了公平比较,研究者在Zhao 等(2022)的方法中仅使用了与研究者方法类似的单尺度球面U-Net。边长和面积的形变程度以及每个大脑半球的平均运行时间见表5。进行了配对t检验以检验研究者的无监督学习方法是否在结果上存在显著差异。
表5 球面投影方法之间度量畸变的比较报告了每个大脑半球的边缘畸变 (mm)、面积畸变(mm2)和运行时间
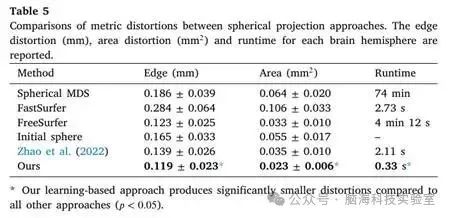
表5表明,与所有基线方法相比,研究者的方法取得了显著更好的性能(p < 0.05),且运行时间仅需0.33秒。如表5所述,由于计算成对测地距离耗时较长,球面MDS的运行时间超过一个小时。尽管FastSurfer中的球面嵌入方法效率较高,但它并未优化度量畸变。FreeSurfer取得了令人满意的性能,但处理每个半球需要4分钟。FreeSurfer生成的初始球体作为一个良好的起点,在无额外变形的情况下有效地减少了基线度量畸变。
与Zhao等人(2022年)相比,研究者的方法有几个广告优势。首先,Zhao等人(2022)需要对白质表面进行膨胀和投射以创建初始球体,在研究者的实验中,每个大脑半球需要1.79秒的GPU加速。相反,研究者的方法对所有主题使用固定的初始球体,无需额外处理。初始球体由 FreeSurfer 生成,其度量失真最小化,如表 5 所示。这为训练提供了一个强大的先验,但初始失真很小。这样的全局初始表面还节省了插值和重采样的运行时间,因为可以预先计算重心坐标。因此,研究者的方法能够在 0.33 秒内将皮质表面投射到球体上,比 (Zhao et al., 2022)快6倍。此外,Zhao等人(2022)计算了重采样的白质表面和二十层之间的度量畸变,因此需要多尺度网络来提高性能。如表5所示,Zhao等人(2022)在单尺度架构方面并没有优于FreeSurfer。
研究者还提供了如图16所示定性比较,该比较可视化了所有方法的投影球体覆盖着皮质沟深度、边缘和面积扭曲。图16显示,Spher ical MDS和FastSurfer在边缘长度和面面积上产生了较大的畸变。与表5中报告的最佳基线方法FreeSurfer相比,研究者的无监督学习方法实现了类似的脑沟深度可视化、相似的边缘失真、更小的面积失真以及760倍更快的运行时间。
5 讨论
在本研究中,研究者提出了一种基于深度学习的快速皮质表面重建流程,用于结构脑MRI的处理和分析,适用于dHCP新生儿数据集。所提出的基于深度学习的dHCP流程主要使用Python和PyTorch实现,包括基于学习的大脑提取、皮质表面重建和球面投影,以及GPU加速的皮质表面膨胀和特征估计。整个流程在GPU加速下仅需24秒即可完成,即使在没有GPU支持的情况下也用时不到3分钟。这比传统神经影像流程至少快一个数量级,后者至少需要6小时的运行时间,同时也比现有的基于深度学习的皮质表面重建流程。
在80%的测试样本中,研究者基于深度学习的dHCP流程生成的皮质表面质量更高(占54.2%)或与原始dHCP流程相当。特别是,对皮质表面的视觉检查以及对表面距离的定量评估表明,研究者基于学习的皮质表面重建方法可以有效减少原始dHCP流程所产生的皮质表面上部和枕叶区域的伪影。研究者还验证了所提出的基于深度学习的dHCP流程能够很好地泛化到未见过的和低分辨率的ePrime新生儿脑部MRI数据。此外,研究者基于无监督学习的球面投影框架与以往方法相比,显著减少了边缘和面积的形变。
HCP DL方案中,由于监督学习的局限性,预测的皮质表面的解剖正确性不可避免地受到原始dHCP方案生成的伪GT皮质表面质量的限制。此外,所提出的多尺度变形网络直接从输入的T2w脑MRI预测皮质表面,而无需依赖分割。这种端到端框架促进了表面重建过程,并避免了不精确分割引入的皮质表面的潜在错误,同时这也意味着研究者基于DL的dHCP流程不提供脑组织分割和皮质表面分割。在未来的工作中,研究者将考虑半监督学习技术,以进一步增强皮质表面的解剖正确性。除了伪GT皮质表面外,无监督的脑MRI强度将用于使皮质表面向WM/cGM或cGM/CSF边界变形,其中MRI实现最大图像对比度。此外,研究者计划丰富功能,并将更多GPU加速的处理步骤纳入研究者基于DL的dHCP流程中,例如大脑区域和组织分割、皮质分区和局部回旋指数估计。
精读分享
研究背景
轻度创伤性脑损伤(mTBI)是临床实践中最常见的创伤性脑损伤类型,但其临床表现多样,潜在的病理生理机制尚不完全清楚。尽管mTBI通常被认为是一种轻微损伤,但它可能导致持续的身体、认知和情绪变化,即脑震荡后症状,这些症状对社会造成了显著负担。磁共振成像(MRI)作为一种非侵入性技术,已被广泛应用于mTBI后神经生物学标志物的探究,成为研究mTBI发病机制的有力工具。然而,大多数先前的研究集中在特定人群或仅关注结构连接性或功能连接性的单一方面,对mTBI患者结构和功能连接性同时异常的探索有限。因此,进一步研究mTBI患者的特征及其结构和功能连接性的演变对于理解mTBI的发生和发展至关重要。本研究旨在探讨mTBI患者在急性期结构和功能连接性的异常是否可以作为其影像学数据和认知功能纵向变化的指标。
研究方法
本研究是一项纵向研究,共招募了46例mTBI患者和36例健康对照者(HCs)。mTBI患者在受伤后2周内接受评估,而健康对照者则通过社交平台招募。所有参与者均接受了静息态功能MRI(rs-fMRI)和扩散加权成像(DWI)数据采集,用于图论网络分析。使用3T MRI扫描仪获取高分辨率结构MRI序列、静息态功能MRI数据和扩散MRI数据。
图像预处理:对功能图像进行预处理,包括去除初始10个体积、切片时间校正、三维头动校正等。结构图像则进行配准、分割和标准化处理。
网络构建:使用Brainnetome图谱定义图节点,将大脑分为246个皮质和皮质下感兴趣区(ROIs),计算各ROI间平均时间序列的Pearson相关系数,得到246×246的连接矩阵。对于结构图像,使用PANDA工具包进行全脑纤维确定性追踪,生成每个参与者的连接矩阵。
图论分析:使用GRETNA工具包计算功能连接(FC)、分数各向异性(FA)和纤维数(FN)网络的图论指标,包括全局效率(Eg)、局部效率(Eloc)、聚类系数(Cp)和小世界属性(σ)。
神经心理学测试:所有参与者完成数字符号替换测试(DSST)和连线测试(TMT)A和B,以评估其认知功能。
研究结果
人口学和临床特征:mTBI患者和健康对照者在性别、年龄和教育程度上无显著差异。mTBI患者在急性期倾向于表现出认知功能下降,但差异无统计学意义。然而,在超过3个月的随访期间,22例完成两次MRI扫描的mTBI患者显示出结构和功能连接性以及认知功能的恢复趋势。
全局图论结果:横断面分析显示,mTBI患者在背侧注意网络(DAN)中表现出显著降低的全局效率(Eg)和显著增高的小世界属性(σ)。纵向分析揭示,从急性期到慢性期,mTBI患者的全局效率和局部效率显著增加,而小世界属性显著降低。在DAN和默认模式网络(DMN)中,全局和局部效率在随访期间也显著增加。
节点图论结果:横断面分析中mTBI患者和健康对照者在节点水平上无显著差异,但在慢性期,mTBI患者在多个脑区(如额上回、额中回、中央前回等)显示出更高的度中心性(Dc)、节点效率(Ne)和节点局部效率(NLe),以及更短的节点最短路径长度(NLp)和更低的节点聚类系数(NCp)。
更高效的网络(更高的Dc、Ne、Eloc和更短的NLp)与更好的认知功能相关联。急性期DAN的小世界属性(σ)与右侧颞中回节点效率的纵向变化呈正相关,表明急性期的小世界属性可能是mTBI患者连接性纵向变化的预测指标。
参考文献
Ma Q, Liang K, Li L, et al. The Developing Human Connectome Project: A fast deep learning-based pipeline for neonatal cortical surface reconstruction.Med Image Anal. 2025;100:103394. doi:10.1016/j.media.2024.103394
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)