
DETR目标检测框架:革新传统检测范式的Transformer方案
DETR(Detection Transformer)是目标检测领域的革命性突破,通过Transformer架构和集合预测范式,摒弃了传统方法中的锚框和NMS后处理。其核心创新包括:1)端到端训练,直接输出检测结果;2)采用匈牙利算法实现预测与真实标签的最优匹配;3)全局建模能力显著提升检测精度。尽管存在训练收敛慢、小目标检测不足等挑战,但通过Deformable-DETR等改进模型,在训练效率、
目录
在计算机视觉领域,目标检测作为核心任务之一,长期面临检测流程复杂、依赖人工先验知识等挑战。传统方法如Faster R-CNN依赖区域候选(Region Proposal)机制,YOLO系列则通过预设锚框(Anchor)实现密集预测,但均需非极大值抑制(NMS)等后处理步骤,导致模型部署效率低下。2020年,Facebook AI Research团队提出的DETR(Detection Transformer)框架,通过引入Transformer架构和集合预测范式,彻底重构了目标检测的技术路径,成为该领域里程碑式的突破。
一、DETR的核心架构
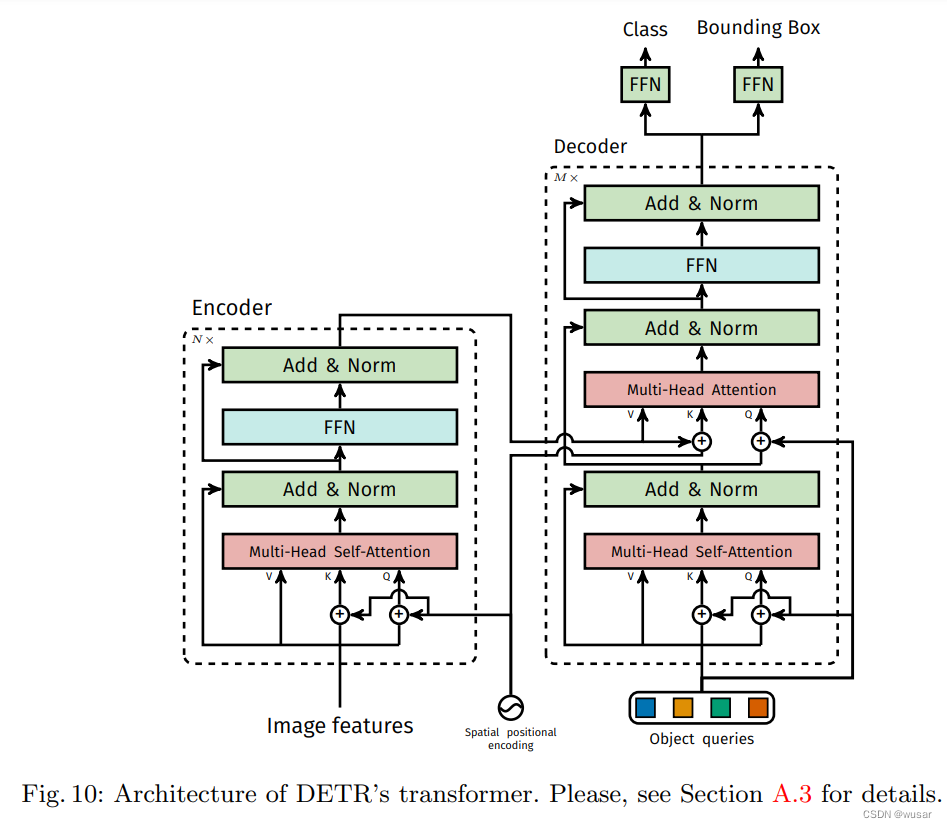
DETR采用经典的Backbone-Transformer-Head三阶段架构,实现了从输入图像到检测结果的直接映射,无需任何手工设计的后处理步骤。
-
Backbone特征提取
DETR使用ResNet等深度卷积神经网络作为骨干网络,将输入图像转换为高维特征图。例如,ResNet50通过多层卷积和池化操作,将原始图像尺寸压缩32倍,生成通道数为2048的特征图。随后,通过1×1卷积降维至256通道,并展平为序列形式(如尺寸为[256, H×W]),为后续Transformer处理提供结构化输入。 -
Transformer编码器-解码器
- 编码器:由6层Transformer块组成,每层包含自注意力机制和前馈神经网络。自注意力机制通过计算特征图中所有位置间的相关性,捕获全局上下文信息。例如,在COCO数据集上,编码器输出的特征向量可同时关注图像中的多个目标,实现跨区域语义关联。
- 解码器:同样包含6层Transformer块,但引入可学习的目标查询(Object Queries)。这些查询向量(默认100个)与编码器输出的特征图通过交叉注意力机制交互,逐步生成目标的类别标签和边界框坐标。例如,部分查询向量会倾向于关注图像左下角的小物体,而另一些则专注于水平方向的大物体,体现对目标尺度的自适应建模能力。
-
预测头
解码器输出的特征向量通过两个前馈神经网络(FFN)分别预测类别和边界框。类别预测采用线性层加Softmax函数,输出类别概率分布(含背景类);边界框预测通过回归标准化中心坐标、高度和宽度实现。最终,模型输出固定数量的预测结果(如100个),通过置信度阈值筛选得到最终检测框。
二、DETR的创新点
DETR的核心突破在于将目标检测定义为集合预测问题,并通过匈牙利算法实现唯一匹配,彻底摒弃了传统方法中的锚框和NMS。
-
集合预测范式
DETR直接预测一组目标集合,而非对每个位置或锚框进行独立分类和回归。这种设计使得模型能够全局优化检测结果,避免重复预测和漏检问题。例如,在密集场景中,DETR可通过自注意力机制抑制背景区域的响应,突出目标特征。 -
匈牙利匹配算法
训练阶段,DETR通过匈牙利算法在预测结果和真实标签间建立最优匹配。匹配代价函数综合考虑分类损失和边界框回归损失(如L1损失和GIoU损失),确保每个真实目标被唯一分配给一个预测框。例如,若预测框与真实框的IoU高于阈值且分类置信度高,则匹配成本较低,优先被选中。 -
端到端训练
DETR的损失函数直接基于匹配结果计算,无需中间监督或后处理步骤。这种设计简化了训练流程,但同时也对模型收敛性提出挑战。原始DETR需训练500个epoch才能达到收敛,后续改进如Deformable-DETR通过引入稀疏注意力机制,将训练时间缩短至36个epoch。
三、DETR的挑战与改进方向
尽管DETR在检测精度和设计简洁性上表现优异,但其原始版本仍存在训练收敛慢、小目标检测性能不足等问题。
- 训练效率优化
- 稀疏注意力机制:Deformable-DETR通过动态关注关键区域,减少全局自注意力的计算量,显著提升训练速度。
- 辅助解码层:在解码器中间层引入辅助损失,加速模型早期阶段的收敛。例如,RT-DETR在解码器的第1-5层添加辅助分类和回归头,使训练效率提升40%。
- 小目标检测增强
- 多尺度特征融合:D-FINE等模型通过融合Backbone的多层次特征,增强对小目标的纹理细节捕捉能力。例如,在无人机图像检测任务中,D-FINE将高分辨率特征图与Transformer编码器输出结合,使小目标AP提升12%。
- 动态查询扩展:DEIM(DETR with Improved Matching)通过数据增强技术动态增加每张图像中的目标数量,缓解监督稀疏性问题。在COCO数据集上,DEIM使小目标检测AP从21.3%提升至24.5%。
- 计算资源优化
- 轻量化设计:通过模型剪枝、量化等技术降低Transformer的计算复杂度。例如,Mobile-DETR将模型参数量压缩至1/3,同时保持90%的原始精度。
- 硬件加速:结合TensorRT等推理引擎,优化Transformer模块的部署效率。在NVIDIA T4 GPU上,优化后的DETR模型推理速度可达124 FPS,满足实时检测需求。
四、DETR的未来展望
DETR的集合预测范式为计算机视觉任务提供了统一框架,其影响力已扩展至全景分割、视频目标检测等领域。未来研究可进一步探索以下方向:
- 时空建模:将DETR扩展至视频领域,通过引入时序注意力机制建模目标运动轨迹。
- 自监督学习:利用DETR的匹配机制设计预训练任务,减少对标注数据的依赖。
- 3D目标检测:结合点云数据,设计适用于自动驾驶场景的3D DETR变体。
DETR通过Transformer架构和集合预测范式,重新定义了目标检测的技术边界。尽管面临训练效率和小目标检测等挑战,但通过持续优化,DETR及其衍生模型正逐步成为工业级检测系统的核心组件,推动计算机视觉向更高层次的智能化演进。
文章正下方可以看到我的联系方式:鼠标“点击” 下面的 “威迪斯特-就是video system 微信名片”字样,就会出现我的二维码,欢迎沟通探讨。
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)