
verl 强化学习框架速通
verl 强化学习框架以及一些llm ppo 理论速通一下,不太懂,如果里面有不对的欢迎指正
首先我们先跑个它官方给的math 数据集:
https://verl.readthedocs.io/en/latest/start/quickstart.html
RL 背景知识
组成
Actor 是“大脑”,告诉 agent 怎么行动。(模型)
Rollout 是“实地采样”,让 actor 去环境里试一试。(一个数据生成过程)
Critic 是“参谋”,告诉 actor 这个状态/动作好不好。(价值估计)
| 组件 | 作用 | 典型任务 |
|---|---|---|
| Actor (策略网络) | 负责生成动作(在文本生成里就是生成下一 token 的策略) | 训练 PPO 时更新策略梯度 |
| Rollout (采样器 / 推理引擎) | 使用 actor 模型生成训练样本(状态-动作-奖励序列) | 产生训练数据,用于计算 advantage |
| Critic (值函数网络) | 评估当前状态的价值 V(s) | 用来计算优势函数 A(s,a) = R - V(s) → actor 更新用 |
符号定义
| 符号 | 解释 |
|---|---|
s_t |
state(状态),表示在时间步 t 下环境/模型的观测信息 |
a_t |
action(动作),表示 agent 在 s_t 下做出的选择 |
state (s_t)
表示 当前生成的上下文
对应的就是 prompt + 已生成的 tokens
每生成一个 token,state 就更新一次(下一个 token 的上下文加上前面的 tokens)
换句话说:state 是你模型看到的“写到哪了”的信息。
action (a_t)
表示 模型生成的下一个 token
所以每步 a_t 是一个离散动作(词表里的 token)
log_prob(a_t) 会被用在 PPO 的 loss 里
e.g
| t | s_t | a_t |
|---|---|---|
| 0 | "2 + 3 = " |
"5" |
| 1 | "2 + 3 = 5" |
结束 token |
| 名称 | 作用 |
|---|---|
| reward | Actor生成序列后得到的标量评分(已知) |
| return_t | 从 s_t 开始实际得到的累计 reward(由 reward + γ 计算) |
| V(s_t) | Critic 对 return_t 的预测 |
| A_t | return_t 与 V(s_t) 的差值,用于指导 Actor 更新 |
Actor
最终保存、拿去推理 / 部署 / vLLM 用的 checkpoint
目标:生成的 token 能拿高 reward
head:语言模型 head
输出:
1. rollout序列:token, log_prob
2. reward:来自reward model / rule / environment)
loss:PPO policy loss + KL
Rollout
s_0, a_0, log_prob(a_0), s_1, a_1, log_prob(a_1), ..., s_T, a_T, log_prob(a_T)
| 符号 | 含义 |
|---|---|
| s_t | 当前状态 = prompt + 已生成的 tokens |
| a_t | 当前动作 = 生成的下一个 token |
| log_prob(a_t) | 模型生成 a_t 的概率对数,用于 PPO loss |
e.g
s_0 = "2 + 3 = "
a_0 = "5"
log_prob(a_0) = -0.2
s_1 = "2 + 3 = 5"
a_1 = <end>
log_prob(a_1) = -0.1
Reward 函数
reward 函数的输出,是一个「标量分数」,用来评价“这一次完整生成好不好”
注意, reward 不是 per-token 的, 而是一条完整序列 → 一个标量
(prompt, response) → r ∈ ℝ
input: prompt + actor output
output: scalar reward
同时, reward函数的设计并非二元的, 每条生成可以先对每个指标给一个分数(比如 0/1 或 0~1 连续值),然后汇总成一个 最终 scalar reward, 比如reward = w1 * correctness + w2 * format + w3 * fluency
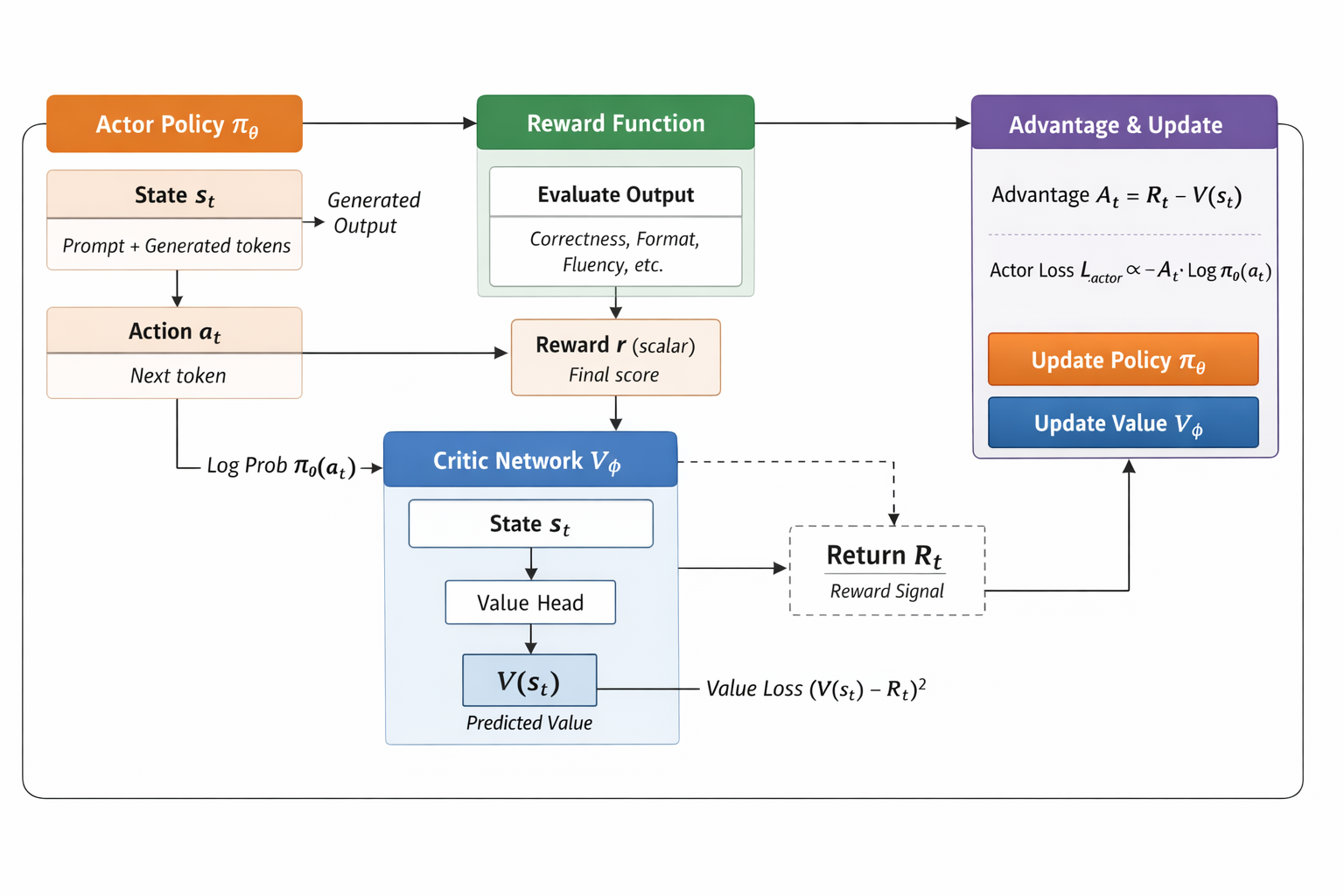
经过计算, 得到Return_t
从 s_t 开始,实际获得的未来 reward(由 reward function 给出)
Critic
训练时的“教练”,训练完基本可以丢掉
目标:预测从当前状态开始,未来能得到的 reward 总和(value function)
-
head:value head(通常是 1 维)
-
input: 状态state s_t (或 state+action)
-
输出:V(s_t) = value_head(backbone(s_t)) ≈ E[future reward] 从这个状态开始,未来能够得到的总 reward 。 得到V(s_0), V(s_1), V(s_2), …, V(s_T)
-
loss:value regression loss: (V(s_t) - return_t)^2
计算步骤
1. 编码 state
把 s_t (prompt + 已生成 tokens)编码成向量
LLM backbone 可以是 Transformer,输出每个 token 的 hidden state
2. 取最后一个 token 的 hidden state
这是当前上下文的 summary
也可以做 pooling 或者 attention
hidden state: 每个 token 的 hidden state都包含它左边所有 token 的信息(因为是 causal attention), 最后一个 token 的 hidden state包含了整个生成序列的上下文,是对整个生成序列的“压缩总结”,可以用来预测未来 reward。
3. value head
一个小的线性层,把 hidden vector → scalar
输出 V(s_t)
这个 scalar 就是 critic 预测的“从 s_t 开始未来能得到的 reward 的期望”
*reward 是已经算好的监督信号;critic 只是拿 reward 当 label,学一个 value function。
Advantage 函数
定义:衡量某个动作 a_t 相比“平均水平”(V(s_t))好多少

用来更新 Actor 策略
训练流程
一次 PPO update,用的是「一整批 rollout 数据」
Rollout 生成数据 + 计算 Reward
Rollout 用 actor 生成一批序列(状态、动作、log_prob)。
Reward 计算
- task reward / rule / voting
- KL penalty(actor vs ref)
Critic计算价值
Critic 估计每个状态的价值 V(s)。
然后计算优势函数 A(s,a) = R + γ V(s') - V(s)。
Actor (策略网络) 更新
使用 PPO objective(剪切概率比)用 Advantage 更新更新策略。
使用 mini-batch + micro-batch 分布式梯度累积。
Critic更新
使用 value loss 更新 critic。
也可以用 mini-batch/micro-batch 控制显存。
{
prompt: "请解释 PPO 是什么",
response: "PPO 是一种……",
tokens: [101, 2345, ...],
logprobs: [-1.2, -0.8, ...], # actor 当时的概率
values: [0.3, 0.4, ...], # critic 的估计
reward: 0.76, # 外部/内部打分
advantages: ... # 算出来的
}
batch理解***
带点数值进去理解吧
train_batch_size= 256(最顶层) “每一轮 PPO 训练”用到的 rollout 数据总量
Actor rollout 一次,一共收集 256 条样本
每条样本 = prompt + response + reward + log_prob + value
这一步是 数据收集阶段,还没开始更新参数
actor.ppo_mini_batch_size = 128(PPO 优化层)
256 条 rollout 数据
→ 拆成 train_batch_size/actor.ppo_mini_batch_size (256/128=2)个 PPO mini-batch
→ 每个 mini-batch 更新一次 actor / critic
actor.ppo_micro_batch_size_per_gpu = 16
每张 GPU 实际一次 forward/backward 吃的数据量
e.g
GPU 数 = 8
单个 mini-batch = 128
每 GPU micro-batch = 16
一次 forward/backward:16 × 8 = 128(正好 1 次完成 1 个 mini-batch)
critic.ppo_micro_batch_size_per_gpu = 4
critic 为啥更小?
critic 需要forward value, backward value loss, 常常比 actor 更容易 OOM(尤其是大模型)
GPU 数 = 8
单个 mini-batch = 128
每 GPU micro-batch = 4
一次 forward/backward:4 × 8 = 32 ( 4 次梯度累积才完成 1 个 mini-batch)
Data Process
这里它有个把json 转化成parquet 的过程
.parquet 是列式存储的二进制数据格式,专门为「大规模、高吞吐训练」设计的;
json 更像是“人能看”的格式,不是“GPU 能高效吃”的格式。
prompt | response | reward | length
--------------------------------------------------------
"hi" | "hello" | 0.9 | 5
"tell me a joke" | "..." | 0.2 | 32
verl 的数据特点
通常包含:
-
prompt
-
response / completion
-
reward / advantage
-
logprob / ref_logprob
-
length / mask
-
rollout metadata
环境配置
之前因为requirements.txt 和版本不匹配折腾半天
总之 v0.4 的时候是 vllm 0.84, 后边都换新的vllm 框架了
训练参数
官方文档:
https://verl.readthedocs.io/en/latest/examples/config.html
defaults
- actor@actor_rollout_ref.actor: dp_actor
- data@data: legacy_data
- reward_manager@reward_manager
- ref@actor_rollout_ref.ref: dp_ref
- rollout@actor_rollout_ref.rollout: rollout
- model@actor_rollout_ref.model: hf_model
- critic@critic: dp_critic
- reward_model@reward_model: dp_reward_loop
- algorithm@algorithm.rollout_correction: rollout_correction
- _self_
-
作用:指定各个组件的默认配置文件(YAML 或者 dataclass)。
-
示例:
-
actor_rollout_ref.actor→ actor 模型的具体配置。 -
data→ 数据集相关配置。 -
_self_→ 当前 YAML 的字段会覆盖以上 defaults。
-
custom_reward_function
-
path:自定义奖励函数的 Python 文件路径,如果为空则使用内置奖励。
-
name:自定义奖励函数的函数名,默认
compute_score。
actor_rollout
策略网络,负责 PPO 的策略梯度更新
actor_rollout_ref.model.path
指定 actor 模型的权重初始化路径。
actor_rollout_ref.actor.optim.lr
Actor 的学习率
actor_rollout_ref.actor.ppo_mini_batch_size
PPO 的 mini-batch 大小
Rollout 收集数据 → 一个 batch(比如 256 条经验)
划分 mini-batch → 128 条/mini-batch
每个 mini-batch 更新 actor
影响:mini-batch 越小,更新越频繁但噪声大;越大,更新稳定但显存压力大。
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu
分布式训练时,每个 GPU 上的小 batch。
如果你有 8 张 GPU,且 mini-batch=128
每个 GPU micro-batch=16
那么每轮更新会拆成 128 / 16 = 8 步 GPU 梯度累积
actor_rollout_ref.rollout.tensor_model_parallel_size=1
并行大小。
critic.model.path=$MODEL_PATH
critic 的初始化权重路径。
critic.ppo_micro_batch_size_per_gpu=4
critic 的微 batch 大小。
algorithm
-
gamma:折扣因子 γ,越小未来奖励越不重要(PPO标准)。
-
lam:GAE(广义优势估计)参数 λ,调节 bias/variance 平衡。
-
adv_estimator:优势估计方法,
gae最常用。 -
norm_adv_by_std_in_grpo:GRPO 时是否用标准差归一化优势。
-
use_kl_in_reward:是否将 KL 罚项加入奖励。
-
kl_penalty:KL估计方法,可选
kl/abs/mse。 -
kl_ctrl:
-
type:KL控制类型(固定或自适应)。
-
kl_coef:KL罚系数。
-
horizon / target_kl:自适应KL控制用。
-
-
use_pf_ppo:是否启用 Preference Feedback PPO(用人工偏好训练)。
-
pf_ppo.reweight_method:样本加权方法。
-
pf_ppo.weight_pow:pow 方法的指数。
trainer
-
balance_batch:分布式训练时是否平衡 batch。
-
total_epochs:训练轮数。
-
total_training_steps:训练总步数,可覆盖 epoch。
-
project_name / experiment_name:用于日志追踪(WandB)。
-
logger:日志后端。
-
log_val_generations:验证时记录多少生成样本。
-
rollout_data_dir / validation_data_dir:保存数据路径。
-
nnodes / n_gpus_per_node:分布式训练节点和GPU数量。
-
save_freq:模型 checkpoint 保存频率。
-
esi_redundant_time:弹性训练实例(Elastic Server Instance)冗余时间。
-
resume_mode:自动恢复训练模式。
-
val_before_train / val_only:训练前验证或仅验证。
-
test_freq:验证频率。
-
critic_warmup:先训练多少步 critic 再更新 actor。
-
device:训练设备。
Wandb 指标
Actor(策略)
actor/ppo_kl
-
是什么:新策略 π_new 和旧策略 π_old 的 KL 距离(PPO 用它来防止策略一步走太远)。
-
怎么看
-
太大:更新太猛,容易崩/性能抖动。
-
太小/接近 0:基本没学到(策略几乎没变化),常见原因:LR 太小、adv 太小、奖励太弱/全 0、clip 太严、或者梯度被截掉了。
-
actor/pg_loss
-
是什么:policy gradient 的损失(通常是要最小化
-E[adv * logπ]的某种形式)。 -
怎么看
-
它的绝对值没那么重要,更重要是:有没有稳定趋势、是否和 reward 同向变化。
-
大幅来回跳:优势估计噪声大、batch 太小、奖励稀疏、学习率/clip 不合适。
-
-
你图里:有明显抖动,后期变正且偏大 → 可能优势分布/奖励尺度不稳定。
actor/pg_clipfrac
-
是什么:PPO clipping 触发比例(有多少样本的 ratio 被 clip 到区间边界)。
-
怎么看(经验)
-
0 附近长期不动:几乎没发生有效 PPO 更新(ratio 都在 1 附近)→ 更新太小。
-
很高(比如 0.3~0.8):更新太猛(ratio 经常越界)→ 可能不稳。
-
很多项目里比较舒服的区间:大概 0.05~0.3 左右(因任务而异)。
-
-
你图里:
1e-4级别,基本≈0 → 几乎没 clip,说明策略几乎没变化(这和你 KL 很小是同一个信号)。
actor/pg_clipfrac_lower
-
是什么:通常指被 clip 到下界(ratio < 1-ε)的比例(不同实现命名略有差异)。
-
你图里:全程一条直线 0。
-
常见原因
-
真的没有 ratio 掉到下界(但你 pg_clipfrac 也几乎 0,所以也合理)
-
或者日志没接好/这个项没启用(更少见)
-
-
结论:和
pg_clipfrac≈0一致:策略更新太小。
actor/lr
-
是什么:当前学习率。
-
你图里:
1e-6级别的常数。 -
这非常关键:对 PPO 来说,这个 LR 往往偏小(除非你是超大模型+LoRA 还特别保守)。
如果你用的是 LoRA / 小 batch / reward 很稀疏,1e-6常常会导致:KL 小、clipfrac≈0、reward 不动。
actor/grad_norm
-
是什么:actor 梯度范数。
-
你图里:0.44~0.57 左右,挺正常,不像梯度爆炸/全 0。
-
解释:梯度“有”,但更新“没效果”往往是 LR 太小 或者 adv/reward 太弱 或 被强 clip/强正则限制。
Critic(价值网络)
critic/vf_loss
-
是什么:value function 回归损失(预测 V(s) vs 目标回报/GAE return)。
-
怎么看
-
一般训练中会下降并趋于平稳。
-
-
你图里:从 ~1 降到接近 0.05 左右 → critic 在拟合(至少 loss 在降)。
critic/vf_explained_var
-
是什么:解释方差(explained variance),衡量 V 预测对回报的解释能力。
-
常见定义:
1 - Var(y - y_pred)/Var(y) -
理想:接近 1
-
还行:0~0.5
-
很差:负数(代表“还不如直接预测均值”)
-
-
你图里:非常夸张的负数(-200k 这种量级)并缓慢上升但仍很负。
-
这几乎一定是“尺度/归一化/目标有问题”信号,常见原因:
-
returns 的方差极小(分母 Var(y)≈0,导致数值炸裂)
-
reward 几乎全一样/全 0(例如你 eval reward mean@1 是 0)
-
value 目标的计算/记录口径不对(比如把 token-level / sequence-level 搞混)
-
-
结论:你现在的 critic 指标看起来“不健康”,这会直接让 advantage 质量很差,从而让 actor 学不动。
critic/vpred_mean
-
是什么:critic 预测的 V 的均值。
-
你图里:在 -0.2 到 0.2 来回。
-
单独看意义不大,但配合
values/min能看出 value 分布是否漂移。
critic/values/min 与 critic/values/mean
-
是什么:value 输出(或目标 value/return,取决于记录)在 batch 里的最小值/均值。
-
你图里:min 从大约 -6 往 -1 走(越来越不负),mean 在 -0.2~0.2 摇摆。
-
可能解释:回报尺度可能在变、或者 value 在被拉回(但 explained_var 极负说明“拟合关系”仍不对)。
critic/vf_clipfrac
-
是什么:value clipping 触发比例(PPO 有时也会 clip value 更新)。
-
你图里:除了一次尖峰(~0.085),其余几乎 0。
-
说明:value 更新也比较“温柔”,不太像爆掉。
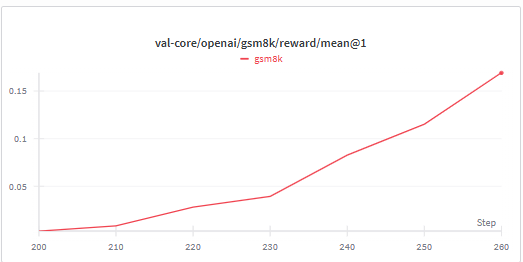
Val
就是验证结果啦,可以看到正在长高就是正常的
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)