
YOLOv5改进系列——融合BiFPN(双向特征金字塔网络)增加P2微小目标检测层
本文探讨了改进YOLOv5进行小目标检测的方法,重点关注BiFPN(双向特征金字塔网络)的融合应用。主要内容包括:1)BiFPN的核心优势,如双向特征融合机制和加权融合策略;2)小目标检测的定义及技术难点;3)两种YOLOv5融合方案:基于BiFPN_Add2的简化版本和结合BiFPN_Add3的增强版本,均通过添加P2检测层提升微小目标(8-32像素)识别能力。实验表明,改进后的模型参数量增幅可
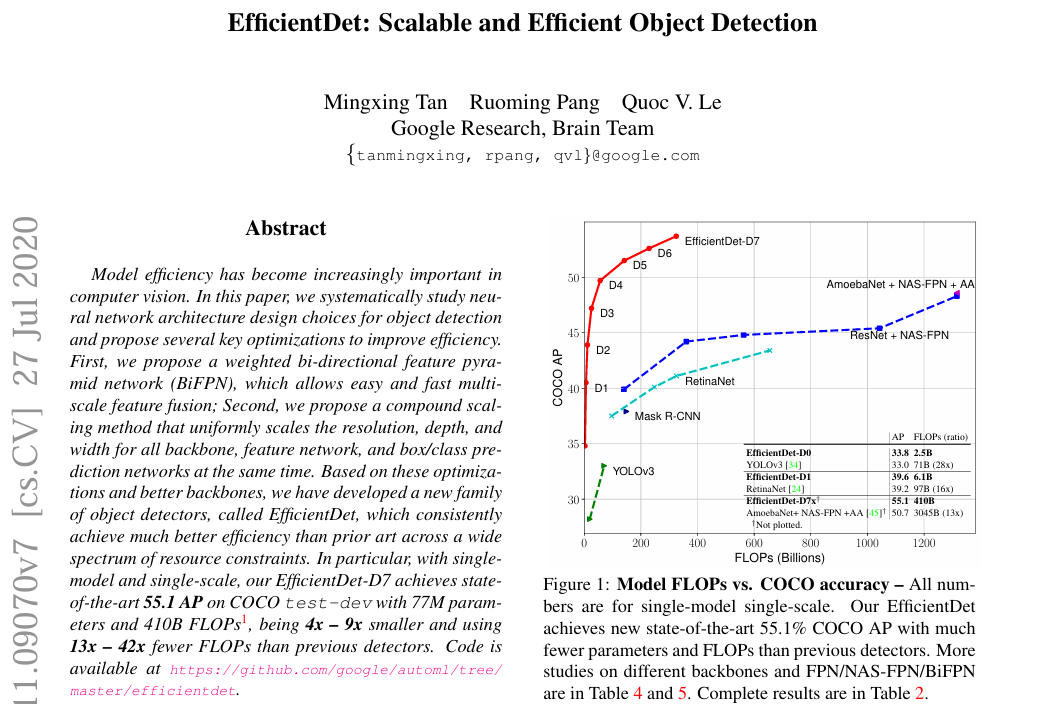
一、BiFPN
1.1、主要贡献
-
双向特征融合:同时引入自顶向下和自底向上的信息流,提高不同尺度间的特征交互。
-
加权融合机制:为每个输入特征分配可学习权重,使网络自动关注更有用的特征。
-
结构简化与优化:移除单输入节点,添加横向连接,提升融合效率,减少冗余。
-
高效可扩展:结构可堆叠,计算量低,适配轻量模型。
1.2、原理要点
-
双向路径提升多尺度融合能力。
-
可学习的加权融合避免信息平均,提升特征选择性。
-
简化连接和统一尺度处理使结构更高效、易部署。
BiFPN 一种结构简洁、融合充分、计算高效的特征融合模块,是 EfficientDet 性能与效率兼顾的关键组件。
原理图:
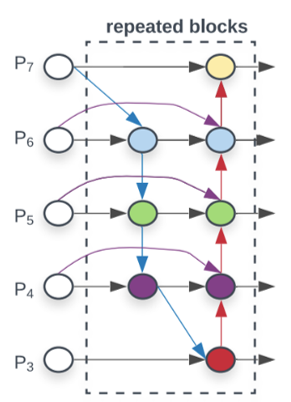
论文地址: [1911.09070] EfficientDet: Scalable and Efficient Object Detection.
二、小目标检测
2.1 什么是小目标检测?
小目标检测
指图像中尺寸较小、像素区域较少的目标,常见定义如面积小于 32×32 像素(COCO标准)。
特点: 特征弱、易被忽略、检测难度高。
微小目标检测
比小目标更小,通常尺寸 小于16×16像素,甚至只有几个像素点。
特点: 信息极少、边缘模糊、极易被背景干扰。
三、YOLOv5融合BiFPN(双向特征金字塔网络)增加P2微小目标检测层方法
3.1 网络结构
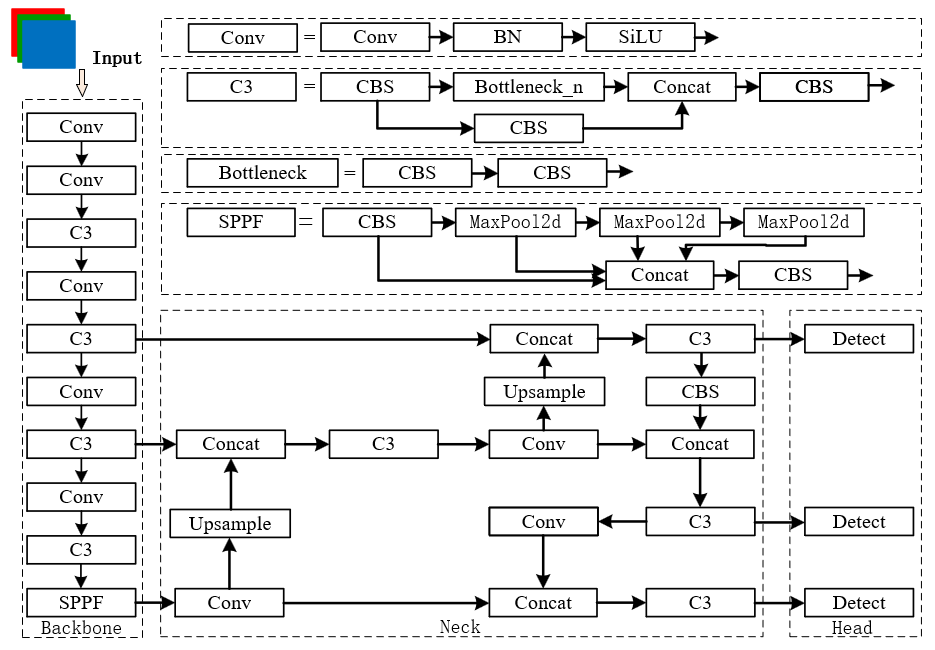
上图是YOLOv5-7.0的网络结构图,由 输入+Backbone+Neck +Head 组成。
YOLOv5s 一共有 3 个检测头(Head),分别用于处理不同尺度的目标检测任务(大中小目标)。假设输入图像大小为 640×640,以下是每个检测头的输出特征图尺寸与主要检测的目标尺度:
| 检测头 | 特征图尺寸 (输入640x640时) | 下采样倍数 | 主要检测的目标尺寸(像素) |
|---|---|---|---|
| P3 | 80 × 80 | 8x | 小目标(约16~64像素) |
| P4 | 40 × 40 | 16x | 中目标(约64~128像素) |
| P5 | 20 × 20 | 32x | 大目标(约128~512像素) |
将其中的Concat模块替换为BiFPN_Add2模块进行更深度层次的融合,并加入P2微小目标检测头,用于检测特征图尺寸160x160,像素约8-32目标
| 检测头层级 | 层编号 | 下采样倍数 | 特征图尺寸 | 主要检测目标像素范围 |
|---|---|---|---|---|
| P2 | 21 | 1/4 | 160 × 160 | 微小目标(8~32 像素) |
| P3 | 24 | 1/8 | 80 × 80 | 小中目标(1664 像素) |
| P4 | 27 | 1/16 | 40 × 40 | 中大目标(64128 像素) |
| P5 | 30 | 1/32 | 20 × 20 | 大目标(128~512+ 像素) |
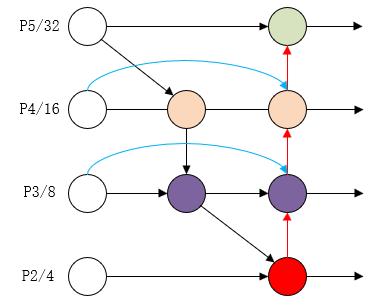
BiFPN融合P2小目标检测层结构图
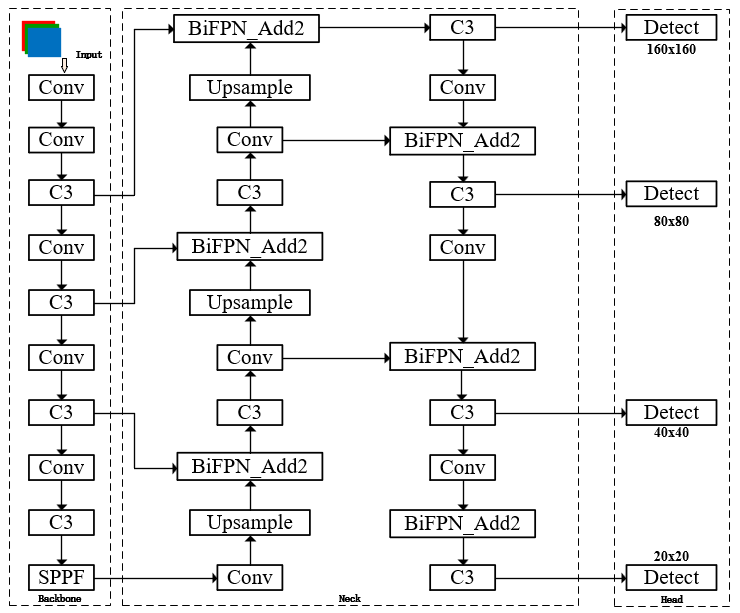
上图为融合BiFPN_Add2(双向特征金字塔网络)增加P2微小目标检测层的网络结构图
3.2、添加步骤
①在models→common.py文件中添加:
# 结合BiFPN 设置可学习参数 学习不同分支的权重,深度融合网络结构,更深层次提取目标特征
# 两分支add操作
class BiFPN_Add2(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add2, self).__init__()
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1]))
# 三分支add操作
class BiFPN_Add3(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add3, self).__init__()
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1] + weight[2] * x[2]))
②修改models→yolo.py文件
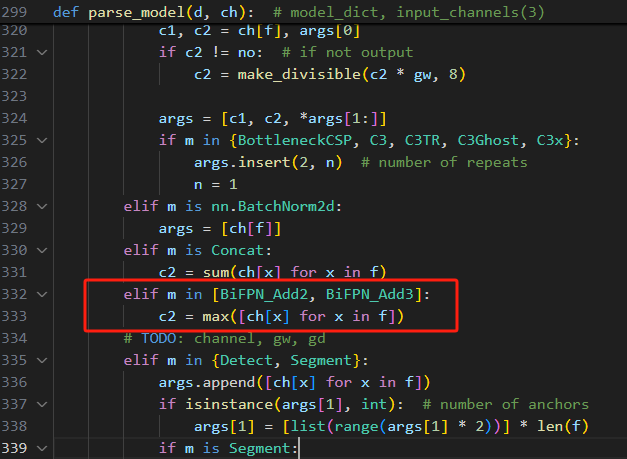
在parse_model函数中添加:
elif m in [BiFPN_Add2 , BiFPN_Add3]:
c2 = max([ch[x] for x in f])3.2.1 版本一
使用BiFPN_Add2融合,创建自定义yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters (P2, P3, P4, P5)都输出,宽深与large版本相同,相当于比large版本能检测更小物体
nc: 7 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors: 4 # AutoAnchor evolves 3 anchors per P output layer
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v7.0 head with (P2, P3, P4, P5) outputs
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #11
[[-1, 6], 1, BiFPN_Add2, [256,256]],
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #15
[[-1, 4], 1, BiFPN_Add2, [128,128]],
[-1, 3, C3, [256, False]], # 17
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, BiFPN_Add2, [64,64]], # cat backbone P2
[-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 18], 1, BiFPN_Add2, [64,64]], # cat head P3
[-1, 3, C3, [256, False]], # 24 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, BiFPN_Add2, [128,128]], # cat head P4
[-1, 3, C3, [512, False]], # 27 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, BiFPN_Add2, [256,256]], # cat head P5
[-1, 3, C3, [1024, False]], # 30 (P5/32-large)
[[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
]
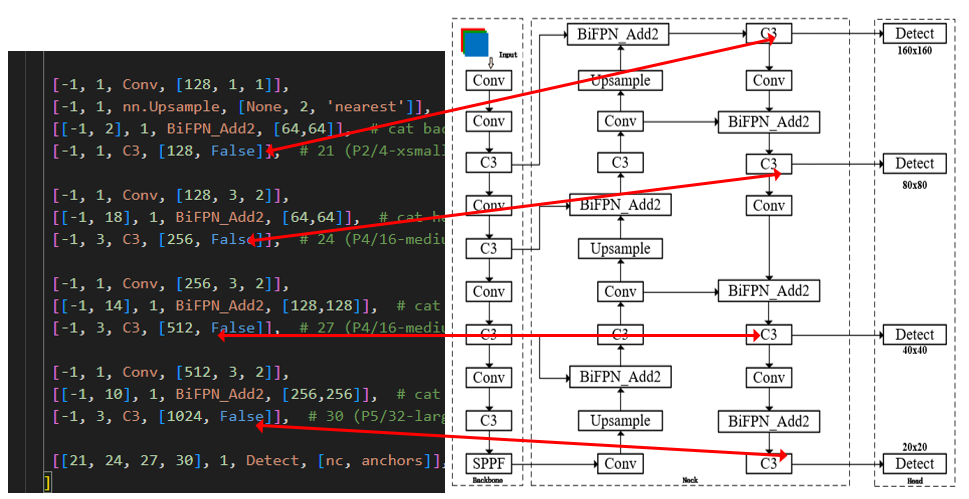
分别在第17层、24层、27层、30层连接检测头,一共使用四层[21, 24, 27, 30]进行检测。
运行结果
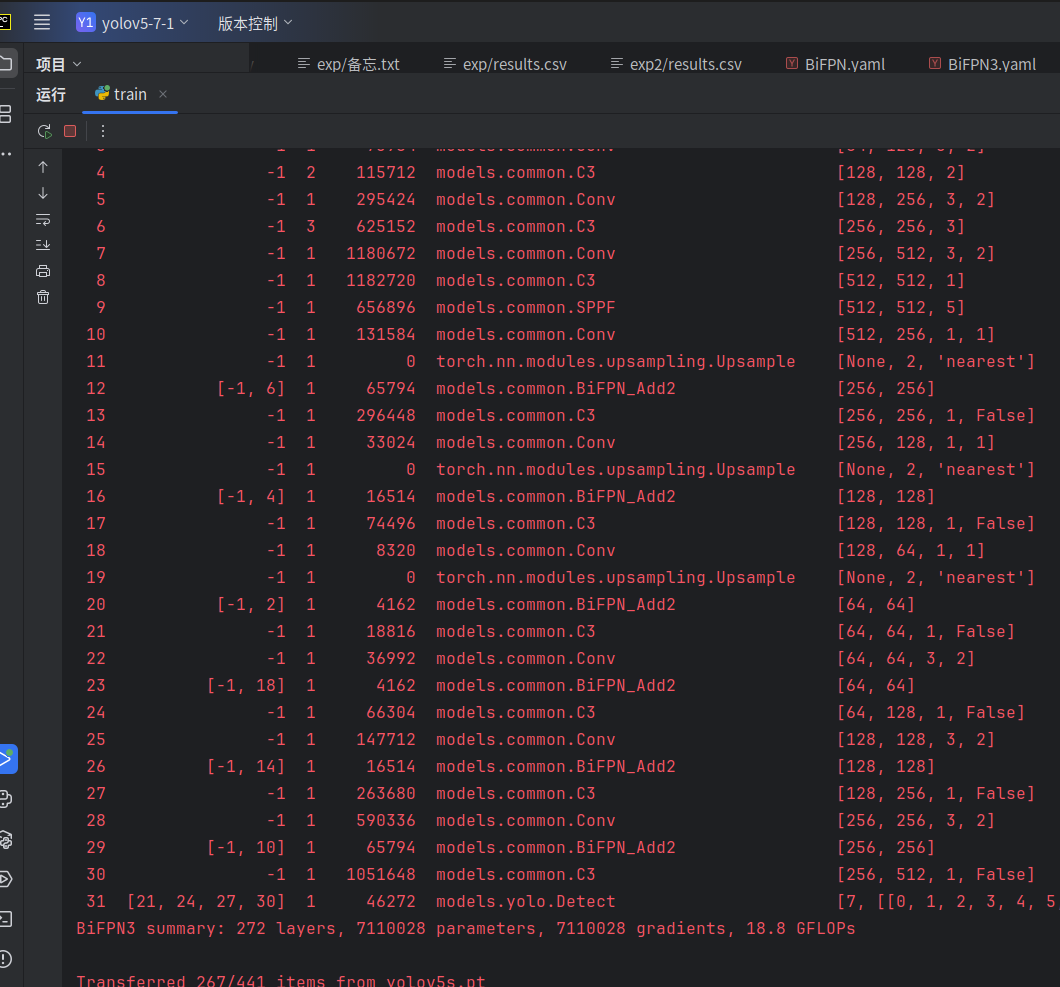
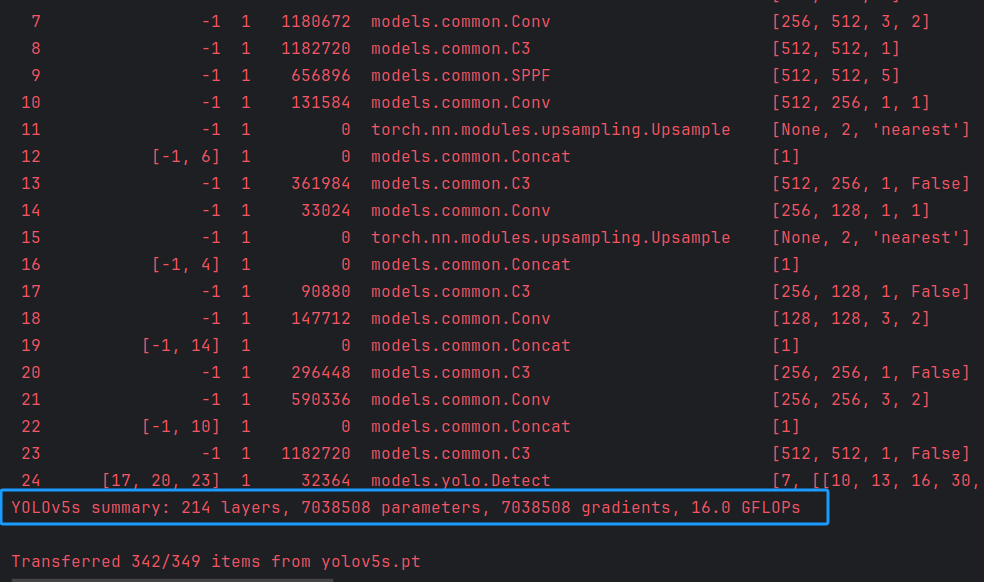
上图为YOLOv5s原模型参数量
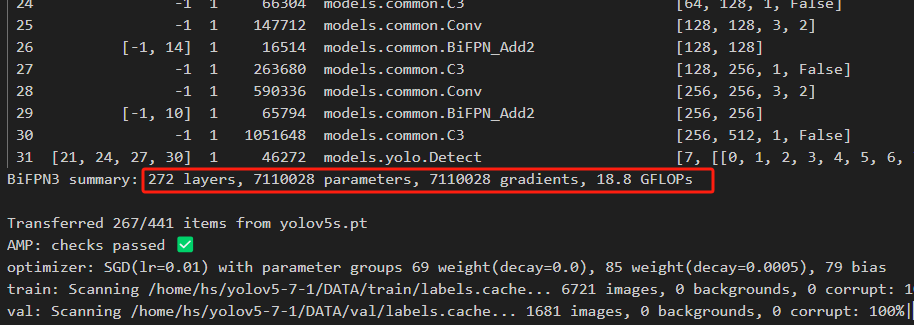
对比YOLOv5s参数量有所上涨,但不大。
3.2.2 版本二
使用BiFPN_Add2和BiFPN_Add3融合,创建自定义yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters (P2, P3, P4, P5)都输出,宽深与large版本相同,相当于比large版本能检测更小物体
nc: 7 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors: 4 # AutoAnchor evolves 3 anchors per P output layer
# YOLOv5 v7.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v7.0 head with (P2, P3, P4, P5) outputs
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, BiFPN_Add2, [256,256]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, BiFPN_Add2, [128,128]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, BiFPN_Add2, [64,64]], # cat backbone P2
[-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
[-1, 1, Conv, [128, 3, 2]],
[-1, 1, Conv, [256, 1, 1]],
[[-1, 17, 4], 1, BiFPN_Add3, [128,128]], # cat head P3
[-1, 3, C3, [256, False]], # 25 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[-1, 1, Conv, [512, 1, 1]],
[[-1, 13, 6], 1, BiFPN_Add3, [256,256]], # cat head P4
[-1, 3, C3, [512, False]], # 29 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, BiFPN_Add2, [256,256]], # cat head P5
[-1, 3, C3, [1024, False]], # 32 (P5/32-large)
[[21, 25, 29, 32], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
]运行结果:
/home/hs/yolov5-7-1/train.py:125: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 65794 models.common.BiFPN_Add2 [256, 256]
13 -1 1 296448 models.common.C3 [256, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 16514 models.common.BiFPN_Add2 [128, 128]
17 -1 1 74496 models.common.C3 [128, 128, 1, False]
18 -1 1 8320 models.common.Conv [128, 64, 1, 1]
19 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
20 [-1, 2] 1 4162 models.common.BiFPN_Add2 [64, 64]
21 -1 1 18816 models.common.C3 [64, 64, 1, False]
22 -1 1 36992 models.common.Conv [64, 64, 3, 2]
23 -1 1 8448 models.common.Conv [64, 128, 1, 1]
24 [-1, 17, 4] 1 16515 models.common.BiFPN_Add3 [128, 128]
25 -1 1 74496 models.common.C3 [128, 128, 1, False]
26 -1 1 147712 models.common.Conv [128, 128, 3, 2]
27 -1 1 33280 models.common.Conv [128, 256, 1, 1]
28 [-1, 13, 6] 1 65795 models.common.BiFPN_Add3 [256, 256]
29 -1 1 296448 models.common.C3 [256, 256, 1, False]
30 -1 1 590336 models.common.Conv [256, 256, 3, 2]
31 [-1, 10] 1 65794 models.common.BiFPN_Add2 [256, 256]
32 -1 1 1051648 models.common.C3 [256, 512, 1, False]
33 [21, 25, 29, 32] 1 46272 models.yolo.Detect [7, [[0, 1, 2, 3, 4, 5, 6, 7], [0, 1, 2, 3, 4, 5, 6, 7], [0, 1, 2, 3, 4, 5, 6, 7], [0, 1, 2, 3, 4, 5, 6, 7]], [64, 128, 256, 512]]
BiFPN summary: 278 layers, 7254350 parameters, 7254350 gradients, 19.5 GFLOPs
Transferred 267/453 items from yolov5s.pt
AMP: checks passed ✅
optimizer: SGD(lr=0.01) with parameter groups 71 weight(decay=0.0), 87 weight(decay=0.0005), 81 bias
train: Scanning /home/hs/yolov5-7-1/DATA/train/labels.cache... 6721 images, 0 backgrounds, 0 corrupt: 100%|██████████| 6721/6721 00:00
val: Scanning /home/hs/yolov5-7-1/DATA/val/labels.cache... 1681 images, 0 backgrounds, 0 corrupt: 100%|██████████| 1681/1681 00:00参数量上升不大,浮点数略微上升。
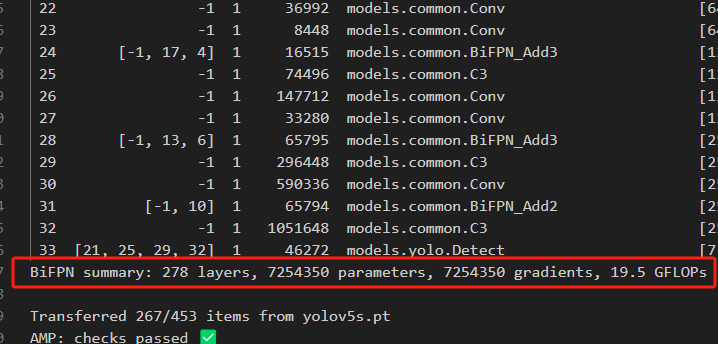
完工,两个都可以正常运行。
使用YOLO做小目标检测算法改进的,可以试试这两种模型,对小目标检测mAP值提升还是比较友好的。
刚萌生想法在CSDN 上撰写博客,既是对所学知识的应用尝试,也是一次自我总结与复盘的过程。若文中存在疏漏和不足,欢迎批评指正。愿在未来的科研之路上,大家一起不断学习、持续进步、成果累累、收获满满。
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)