
【毕业设计】融合图神经网络与深度学习的加密流量异常检测技术研究
围绕资源受限环境下的恶意加密流量检测问题展开研究,提出了两种创新的轻量化检测方法并构建了实时检测系统。项目首先通过特征选择与随机森林组合实现快速流量筛选,结合知识蒸馏机制构建了双阶段轻量化模型LightMETD;其次引入KL变换压缩与注意力增强的深度可分离卷积网络,提出了更轻量的CompactMalID模型;最后基于B/S架构设计实现了云边协同的实时检测系统NetSentinel,能够根据设备算力
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是:
🎯融合图神经网络与深度学习的加密流量异常检测技术研究
选题意义背景
随着5G、物联网、工业互联网等新型网络技术的快速发展,网络空间已演变成由各类异构设备构成的复杂生态系统,接入设备跨越云、边、端多个层级。在这一背景下,加密通信作为保障数据安全和用户隐私的关键技术,其应用范围日益广泛。然而,加密流量在提升数据安全性的同时,也为恶意行为的隐藏提供了便利,传统的基于深度包检测的安全机制难以有效分析加密流量内容,导致网络安全防御面临严峻挑战。
当前,恶意加密流量检测主要面临几大难点。首先,加密流量的内容不可见性使得传统基于特征匹配的检测方法失效,需要依赖流量的统计特征和行为模式进行分析。其次,深度学习技术在恶意流量检测中的应用虽然提升了检测精度,但复杂的模型结构带来了巨大的计算开销,难以在资源受限的边缘设备上实时运行。再者,随着网络攻击手段的不断演进,恶意流量呈现出多样化、隐蔽化的特点,传统检测模型的适应性和泛化能力不足,容易出现误报和漏报问题。此外,在大规模网络环境中,流量数据量呈爆炸式增长,如何高效处理海量加密流量并实现实时检测,也是当前研究的重要挑战。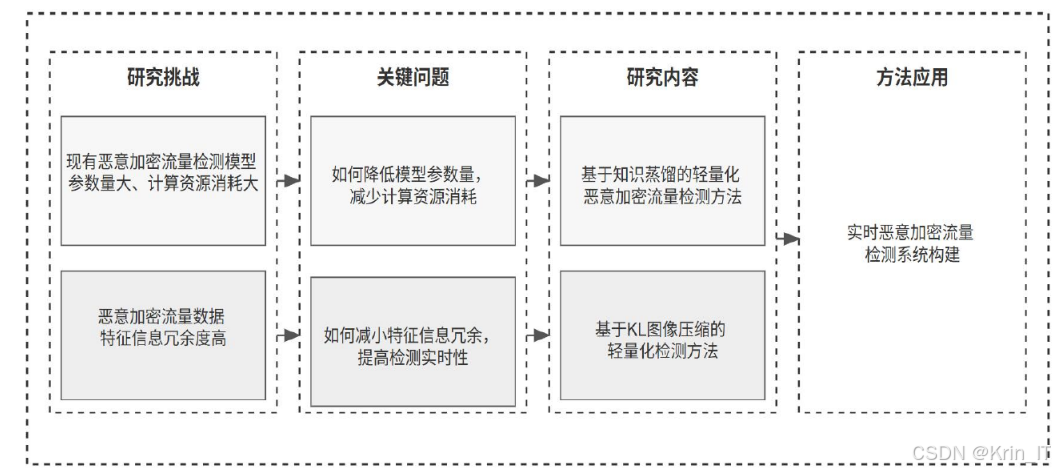
从应用需求来看,边缘计算的普及使得越来越多的计算任务需要在资源受限的设备上完成。在物联网、工业控制网络等场景中,大量设备的计算能力和存储空间有限,无法部署复杂的深度学习模型。同时,这些场景对实时性要求较高,需要快速响应潜在的安全威胁,避免攻击扩散造成严重损失。因此,研究轻量化的恶意加密流量检测方法,在保证检测精度的前提下降低计算开销,对于提升边缘网络的安全性具有重要意义。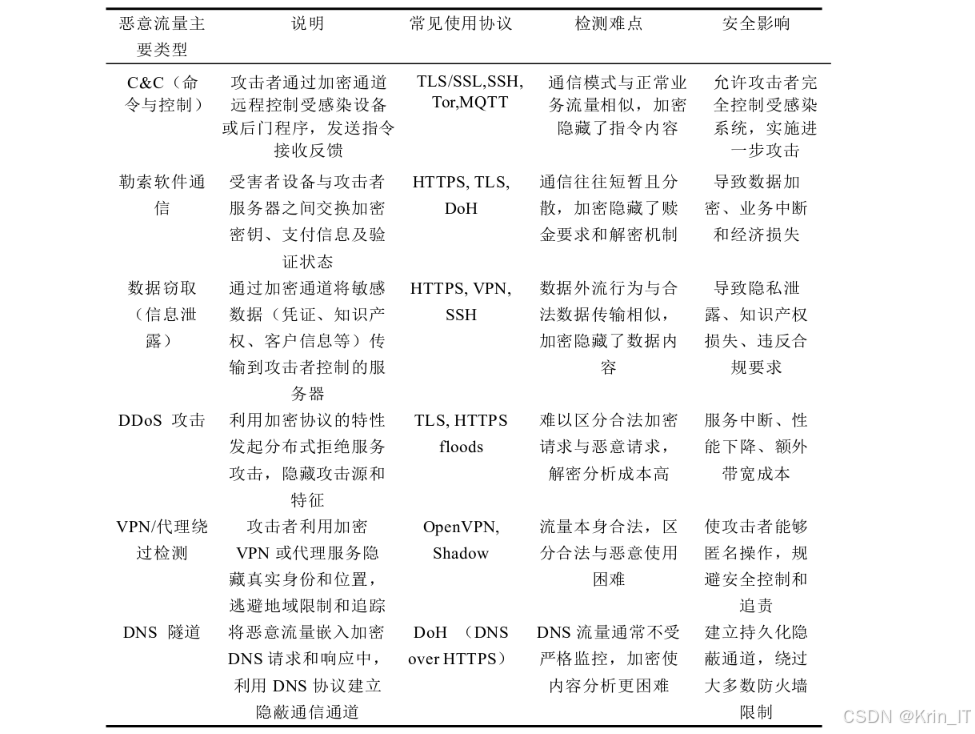
从技术发展趋势来看,轻量化深度学习技术为解决这一问题提供了新的思路。知识蒸馏、模型压缩、轻量级网络设计等技术的出现,使得在资源受限设备上部署高性能的深度学习模型成为可能。通过这些技术,可以在不显著降低检测精度的前提下,大幅减少模型的参数量和计算复杂度,满足实时检测的需求。因此,结合轻量化深度学习技术和恶意加密流量检测,具有重要的理论价值和实际应用前景。
数据集
本研究在实验过程中主要使用了两个数据集:USTC-TFC2016数据集和自建的MalID数据集,以及ISCX数据集,用于训练和评估所提出的恶意加密流量检测模型。这些数据集涵盖了多种恶意加密流量类型,为模型的训练和测试提供了丰富的样本支持。
USTC-TFC2016数据集是一个广泛使用的网络流量分类数据集,包含了多种加密和非加密的网络流量。该数据集通过在真实网络环境中捕获流量数据,并进行人工标注,确保了数据的真实性和可靠性。数据集中的恶意流量类型包括DoS攻击、僵尸网络通信、漏洞利用、信息窃取、横向移动、命令控制通信和隐蔽隧道等多种常见的网络攻击行为。这些样本涵盖了不同的攻击手段和技术特点,为模型学习多样化的恶意流量模式提供了基础。数据集的规模较大,包含了大量的训练样本和测试样本,可以有效避免模型过拟合问题,提高模型的泛化能力。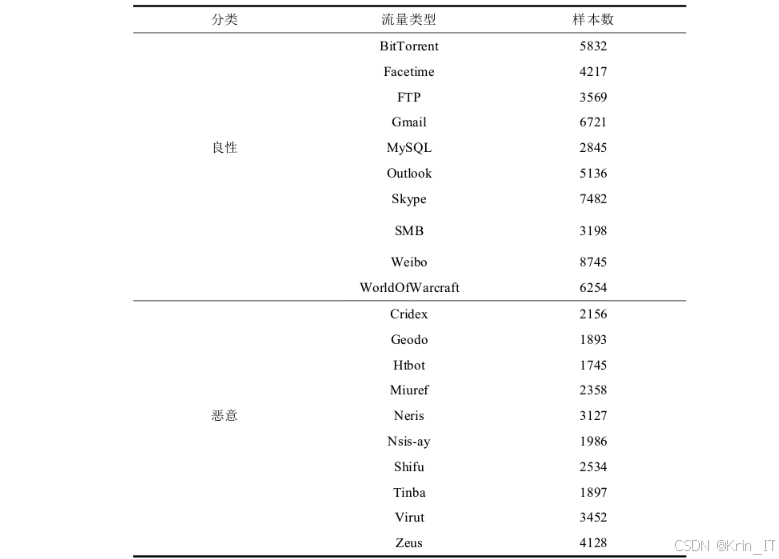
自建的MalID数据集是本研究团队在实际网络环境中收集和标注的加密流量数据集,旨在补充现有公开数据集的不足,提供更贴近真实应用场景的训练和测试数据。该数据集通过部署网络流量采集设备,在不同的网络环境中收集加密流量数据,并结合安全分析工具和人工验证进行标注。MalID数据集包含了近年来出现的新型恶意加密流量样本,如基于HTTPS的命令控制通信、加密隧道等,这些样本在现有公开数据集中相对较少,能够更好地评估模型对新型攻击的检测能力。此外,为了模拟资源受限环境下的流量特点,数据集还特别包含了低带宽、高延迟网络环境中的加密流量样本,为模型的适应性测试提供了条件。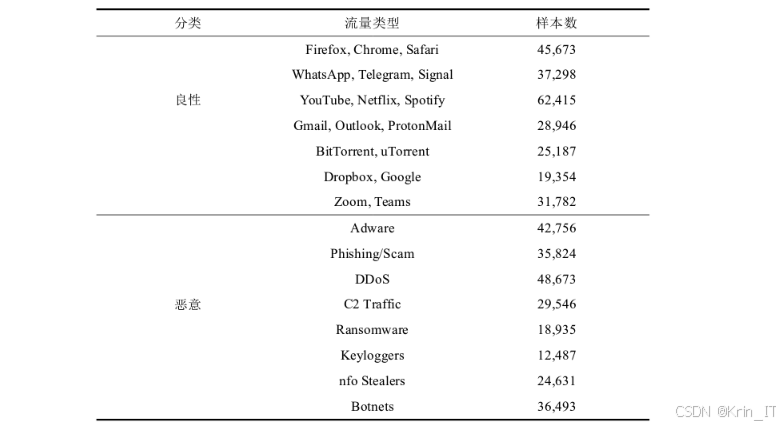
ISCX数据集则是基于ISCX VPN-nonVPN、ISCX僵尸网络数据集和ISCX CIC-IDS 2018数据集组合而成,包含了7种恶意加密流量样本类别,如DoS/DDoS、僵尸网络、漏洞利用、信息窃取、横向移动、C&C通信和隐蔽隧道等。该数据集的样本数量丰富,各类别样本分布相对均衡,能够有效评估模型的分类性能和泛化能力。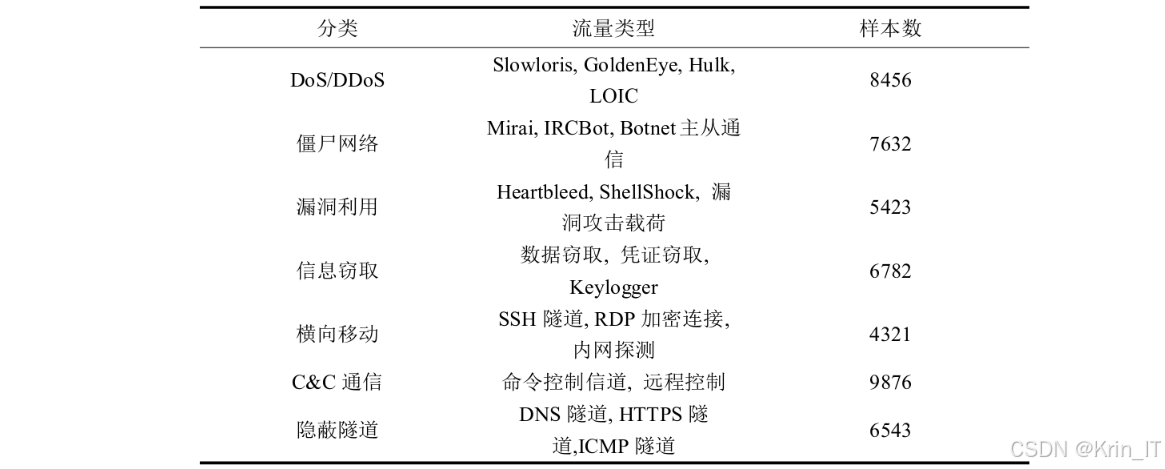
在数据预处理方面,研究团队对原始流量数据进行了一系列处理,以适应模型训练的需求。首先,对原始PCAP文件进行解析,提取流量的五元组信息(源IP、目的IP、源端口、目的端口、协议)以及统计特征,如包大小分布、到达时间间隔等。其次,对数据进行清洗,去除无效和异常的流量样本,确保数据质量。然后,对流量数据进行特征工程处理,包括特征标准化、特征选择等,以减少冗余特征的干扰,提高模型的学习效率。最后,将处理后的流量数据转换为适合深度学习模型输入的格式,如向量形式或图像形式,以便模型进行特征提取和分类。
在数据分割策略上,研究采用了标准的80/20划分方法,即将数据集的80%用于模型训练,20%用于模型测试。这种划分方式能够有效评估模型的泛化能力,确保模型在未见数据上也能保持良好的检测性能。此外,为了避免训练过程中的过拟合问题,还采用了交叉验证的方法,将训练集进一步划分为训练子集和验证子集,用于模型参数调优和性能评估。
通过这些数据集的使用和处理,本研究能够全面评估所提出的轻量化恶意加密流量检测方法的性能,确保其在不同网络环境和攻击场景下都能保持高效的检测能力。同时,丰富的数据集也为模型的持续优化和改进提供了基础,有助于推动恶意加密流量检测技术的进一步发展。
项目功能
本项目开发的轻量化恶意加密流量检测系统NetSentinel具备全面的功能模块,能够实现从流量采集、分析到检测、告警的全流程安全管理。系统基于云边协同架构,在云端部署数据中心、模型管理中心和态势感知中心,在边端设备上部署轻量级Agent,实现了对异构网络环境的全面覆盖和高效防护。
信息采集模块
信息采集模块负责实时采集边端设备的运行状态信息和网络流量数据。该模块采用轻量级Docker容器封装,能够高效采集设备的CPU使用率、内存占用情况、操作系统类型及版本、网络连接状态等关键参数。在处理器信息采集方面,通过读取/proc文件系统数据获取CPU相关信息,包括峰值计算能力和当前负载,并定期采样记录历史负载峰值。内存状态监控通过Docker Stats API和系统命令实现,采集动态存储信息,获取内存容量、当前占用量等关键指标。在网络流量采集方面,记录平均每小时网络通信量和通信量峰值,通过ping测试获取网络延迟数据,全面捕捉设备的网络行为特征。数据上报机制采用MQTT协议与云端态势感知总控制器通信,通过TLS加密建立安全传输通道,确保数据传输的安全性。为优化网络资源使用,模块实现增量传输策略,仅在参数发生显著变化时触发数据上报,同时本地SQLite数据库作为缓存机制确保网络中断情况下数据完整性。
模型分配模块
模型分配模块是系统的核心功能模块,负责根据边端设备的计算能力智能分配适合的恶意加密流量检测模型。该模块首先进行计算代价估算,基于模型的参数规模、算法复杂度以及待检测数据量,估算使用该模型进行威胁检测所需的计算代价,包括处理器的负载量和动态内存占用量。然后进行设备资源评估,检查全域设备信息库中每台设备的资源状况,获取设备的处理器信息、内存资源情况等,判断设备是否满足模型运行的资源要求。最后,在满足资源约束条件的前提下,依据效用函数对候选模型进行打分,选择得分最高的模型部署至设备。对于计算资源非常充足的设备,分配完整的深度学习模型以获得最高的检测精度;对于计算资源相对较低的设备,分配LightMETD模型以平衡检测效率和精度;对于实时性要求非常高的设备,分配CompactMalID模型以确保快速响应。这种自适应的模型分配策略,确保了系统在异构网络环境下的高效运行,实现了对加密流量的精准分类和恶意行为的实时检测。
数据上传与解析模块
数据上传与解析模块负责模型的分发、流量数据的实时检测和结果上报。模型分发由云端统一管理与调度,将模型及其依赖打包为轻量级容器镜像,通过安全OTA机制推送至目标设备。模型部署完成后,模块监听网卡或数据通道,实时对经过的网络流量进行检测和分类,提取流量的关键特征,如五元组信息,并通过模型进行推理,判断其所属的流量类型或是否为恶意行为。检测结果随后被标准化整理,包括流量标签、协议类型等。为实现高效上报,模块采用差分上传策略与数据压缩机制,仅将关键检测结果与告警信息通过加密通道传回云端。系统支持Zstandard等压缩算法减少带宽开销,同时通过MQTT 5.0协议保障传输可靠性,支持QoS等级、消息优先级与过期时间配置。在网络条件不佳的情况下,模块还具备本地缓存与智能批量上传机制,避免数据丢失。
可视化模块
可视化模块用于对边缘Agent上报的检测结果进行实时处理与动态展示,为管理人员提供高可视化的网络安全态势感知界面。模块后端基于Spring Boot构建RESTful服务,结合Kafka消息队列实现数据的异步接收与处理,具备良好的可扩展性和高并发处理能力。后端采用Redis缓存与TimescaleDB时序数据库进行数据存储与高效查询,支持按时间窗口进行聚合分析与回溯查询。可视化大屏前端基于Vue.js框架开发,结合ECharts图表库与WebSocket协议实现秒级数据推送与图表实时刷新,确保页面内容的实时性与交互性。界面展示包括检测到的恶意流量趋势图、攻击源IP热力图、边缘节点处理状态概览等,所有图表均支持动态缩放与筛选,方便用户按需查看特定时间段或节点的行为模式。系统还具备多维度视图能力,将流量行为与地理位置结合,生成全网攻击热力地图,为网络安全运营提供强有力的技术支撑和决策依据。
通过这些功能模块的协同工作,NetSentinel系统实现了对恶意加密流量的全方位、智能化检测与防护,能够有效应对复杂网络环境下的安全威胁,为构建安全、可靠的网络环境提供了有力保障。
算法理论
本项目提出了两种创新的轻量化恶意加密流量检测方法:基于知识蒸馏的LightMETD模型和基于KL图像压缩的CompactMalID模型。这两种方法分别从不同角度解决了资源受限环境下恶意加密流量检测的效率与精度问题。
LightMETD模型采用双阶段检测策略,旨在提升在资源受限环境下的检测效率与精度。第一阶段为快速筛选阶段,采用特征选择算法与随机森林组合对流量数据进行初步筛选,实现对高区分度样本的快速过滤。特征选择算法通过评估每个特征的重要性,选择最具判别力的特征子集,减少冗余特征的干扰,提高分类效率。随机森林作为一种集成学习方法,具有较强的抗过拟合能力和较高的分类效率,能够快速识别出明显的恶意流量和良性流量。对于无法明确分类的模糊样本,则进入第二阶段进行精细分类。第二阶段采用优化结构的卷积神经网络(CNN)对流量特征进行深度学习,提取更深层次的特征表示,提高分类精度。为了提升轻量模型的学习能力,LightMETD引入了垂直知识蒸馏机制,通过设计蒸馏损失函数引导轻量模型有效继承教师模型的判别能力。教师模型通常是一个复杂的深度神经网络,具有较强的特征提取和分类能力,而学生模型则是一个轻量级的网络结构。知识蒸馏通过最小化学生模型和教师模型之间的输出差异,使学生模型能够学习到教师模型的知识和决策边界,从而在保持模型轻量化的同时,提升检测性能。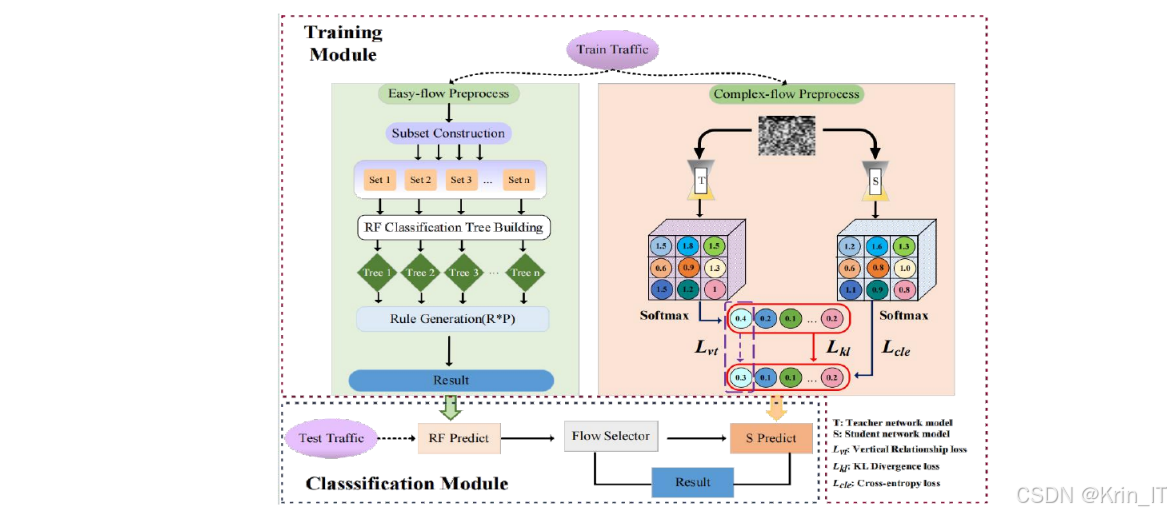
CompactMalID模型则通过KL变换压缩和注意力增强的深度可分离卷积网络,实现了更高效的恶意加密流量检测。首先,模型将原始流量数据转换为灰度图像,这种转换方式能够保留流量的时序特征和统计特征,同时将高维的流量数据转换为结构化的二维图像数据,便于后续的特征提取和处理。然后,引入KL变换对灰度图像进行压缩处理,KL变换是一种基于特征值分解的正交变换,能够将原始数据投影到新的正交坐标系中,仅保留方差最大的前k个主成分,从而实现数据的降维和压缩。通过KL变换,可以有效减少数据的维度和冗余信息,降低模型的计算复杂度和内存需求。为了确定最优的压缩维度k,模型采用自适应阈值确定方法,根据数据的特征值分布自动选择合适的k值,在保证信息保留率的同时,最大化压缩效率。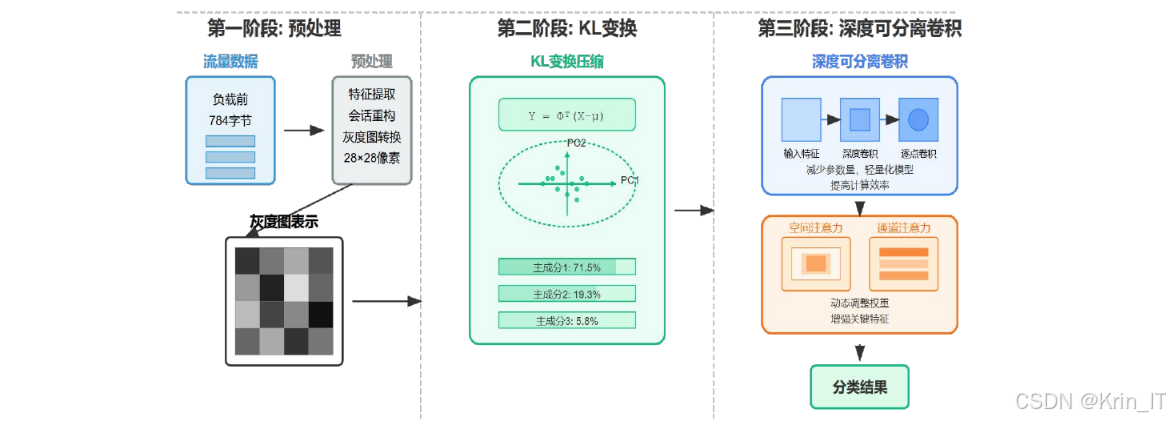
在特征提取阶段,CompactMalID采用了注意力增强的深度可分离卷积网络。深度可分离卷积将标准卷积分解为深度卷积和点卷积两个步骤,深度卷积对每个输入通道单独进行卷积操作,点卷积则通过1×1卷积融合不同通道的特征。这种结构能够大幅减少模型的参数量和计算复杂度,同时保持较高的特征提取能力。为了进一步提升模型对关键特征的感知能力,模型引入了双重注意力机制,包括通道注意力和空间注意力。通道注意力机制通过学习特征通道的重要性权重,突出关键特征通道;空间注意力机制通过学习特征图空间位置的重要性,聚焦于最具判别力的区域。注意力机制的应用能够帮助模型更有效地提取加密流量的关键特征,提高检测精度。
在模型训练方面,两种模型均采用端到端的深度学习优化方法进行训练。训练过程中,使用交叉熵损失作为主要评估指标,衡量模型预测与真实标签之间的差距。为了提高模型的泛化能力并防止过拟合现象的发生,训练过程中引入了L2正则化项,通过对模型参数施加惩罚,有效控制模型复杂度。优化器方面,采用了Adam优化器,结合了动量法和自适应学习率的优势,能够有效处理梯度稀疏和噪声问题。初始学习率设置为较小值,并实施学习率衰减策略,确保模型在训练后期能够收敛到更精细的局部最优解。此外,还采用了数据增强技术,如随机水平翻转、随机旋转和随机亮度对比度调整等,增加训练数据的多样性,提升模型的鲁棒性。
实验结果表明,LightMETD模型在保持检测精度的同时,实现了模型体积压缩至教师模型的2%,检测速度提升近90%;CompactMalID模型在保持高检测精度的同时,推理速度提升约9%,显著提升了实际部署的可行性与实时性。这两种轻量化检测方法为资源受限环境下的恶意加密流量检测提供了有效的解决方案,能够满足不同场景下的安全需求。
核心代码
知识蒸馏
知识蒸馏是LightMETD模型的核心技术之一,通过将复杂教师模型的知识转移到轻量级学生模型中,实现模型的轻量化,知识蒸馏的核心训练过程:定义了教师模型和学生模型的网络结构,教师模型通常是一个复杂的深度学习模型,而学生模型则是一个轻量级的网络结构。在训练过程中,教师模型保持固定(设置为评估模式),学生模型则通过优化两种损失函数进行学习:一种是传统的交叉熵损失(硬标签损失),另一种是基于KL散度的知识蒸馏损失(软标签损失)。通过温度参数控制软标签的平滑程度,alpha参数平衡两种损失的权重。这种训练方式能够使学生模型有效继承教师模型的知识和决策边界,从而在保持模型轻量化的同时,提升检测性能。以下代码片段展示了知识蒸馏的核心实现逻辑:
import torch
import torch.nn as nn
import torch.optim as optim
class TeacherModel(nn.Module):
def __init__(self):
super(TeacherModel, self).__init__()
# 定义复杂的教师模型结构,例如深层CNN或ResNet
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
# 更多的卷积层和池化层...
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
# 前向传播逻辑
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# 更多的前向传播步骤...
x = self.fc(x)
return x
class StudentModel(nn.Module):
def __init__(self):
super(StudentModel, self).__init__()
# 定义轻量级的学生模型结构,例如浅层CNN或MobileNet
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.relu = nn.ReLU(inplace=True)
# 更少的卷积层和池化层...
self.fc = nn.Linear(256, num_classes)
def forward(self, x):
# 前向传播逻辑
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# 更多的前向传播步骤...
x = self.fc(x)
return x
# 知识蒸馏训练函数
def distillation_training(teacher_model, student_model, train_loader, temperature=4, alpha=0.7):
student_optimizer = optim.Adam(student_model.parameters(), lr=0.001)
criterion_ce = nn.CrossEntropyLoss() # 硬标签损失
criterion_kl = nn.KLDivLoss(reduction='batchmean') # KL散度损失
teacher_model.eval() # 教师模型设置为评估模式
student_model.train() # 学生模型设置为训练模式
for data, target in train_loader:
student_optimizer.zero_grad()
# 教师模型输出(不带梯度)
with torch.no_grad():
teacher_output = teacher_model(data)
# 学生模型输出
student_output = student_model(data)
# 计算硬标签损失
loss_ce = criterion_ce(student_output, target)
# 计算软标签损失(知识蒸馏损失)
# 将教师输出和学生输出除以温度参数,并应用softmax
soft_teacher_output = nn.functional.softmax(teacher_output / temperature, dim=1)
soft_student_output = nn.functional.log_softmax(student_output / temperature, dim=1)
loss_kl = criterion_kl(soft_student_output, soft_teacher_output) * (temperature ** 2)
# 总损失 = alpha * 软标签损失 + (1 - alpha) * 硬标签损失
loss = alpha * loss_kl + (1 - alpha) * loss_ce
# 反向传播和优化
loss.backward()
student_optimizer.step()
return student_model
KL变换
KL变换是CompactMalID模型的关键技术之一,通过对流量灰度图像进行降维和压缩,减少模型的计算复杂度和内存需求。KL变换的核心功能,包括拟合(计算特征向量)、变换(降维)和逆变换(重建)。在拟合阶段,首先计算输入数据的均值,然后对数据进行中心化处理,接着计算协方差矩阵并求解其特征值和特征向量。根据预设的方差保留阈值,自动确定需要保留的特征数量k,仅保留方差最大的前k个特征向量。在变换阶段,将输入数据投影到保留的特征向量上,实现数据的降维和压缩。以下代码片段展示了KL变换的核心实现逻辑:
import numpy as np
class KLTTransform:
def __init__(self):
self.eigenvectors = None
self.mean = None
self.k = None
def fit(self, X, threshold=0.95):
# X: 输入数据,形状为[样本数, 特征数]
# 计算均值
self.mean = np.mean(X, axis=0)
# 数据中心化
X_centered = X - self.mean
# 计算协方差矩阵
cov_matrix = np.cov(X_centered, rowvar=False)
# 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix)
# 对特征值和特征向量按特征值降序排序
idx = eigenvalues.argsort()[::-1]
eigenvalues = eigenvalues[idx]
eigenvectors = eigenvectors[:, idx]
# 根据阈值确定保留的特征数量k
total_variance = np.sum(eigenvalues)
cumulative_variance = np.cumsum(eigenvalues) / total_variance
self.k = np.argmax(cumulative_variance >= threshold) + 1
# 保留前k个特征向量
self.eigenvectors = eigenvectors[:, :self.k]
def transform(self, X):
# 数据中心化
X_centered = X - self.mean
# 应用KL变换
X_transformed = np.dot(X_centered, self.eigenvectors)
return X_transformed
def inverse_transform(self, X_transformed):
# 逆变换,重建原始数据
X_centered = np.dot(X_transformed, self.eigenvectors.T)
X_reconstructed = X_centered + self.mean
return X_reconstructed
# 流量数据转灰度图像并应用KL变换
def traffic_to_compressed_image(traffic_data, klt_model, image_size=(32, 32)):
# 步骤1: 将流量数据转换为灰度图像
# 假设traffic_data是一维流量特征向量
# 这里使用简单的线性映射将流量数据转换为灰度图像
# 实际应用中可能需要更复杂的转换方法
min_val = np.min(traffic_data)
max_val = np.max(traffic_data)
# 归一化到[0, 255]范围
normalized_data = (traffic_data - min_val) / (max_val - min_val) * 255
# 调整为指定的图像大小
# 这里使用简单的插值方法,实际应用中可能需要更复杂的重采样技术
# 注意:实际实现中需要确保数据维度与图像大小匹配
# 这里为了简化,假设traffic_data的长度能够被reshape为image_size
# 实际应用中可能需要进行裁剪或填充
image = normalized_data[:image_size[0] * image_size[1]].reshape(image_size)
# 步骤2: 对灰度图像应用KL变换进行压缩
# 将二维图像展平为一维向量
flattened_image = image.flatten()
# 应用KL变换
compressed_features = klt_model.transform(flattened_image.reshape(1, -1))
return compressed_features
此外,代码还展示了如何将流量数据转换为灰度图像并应用KL变换进行压缩的过程。首先将一维的流量特征向量映射到[0, 255]的灰度范围,然后调整为指定的图像大小。接着将二维图像展平为一维向量,应用KL变换进行降维,得到压缩后的特征表示。这种处理方式能够有效减少数据的维度和冗余信息,降低后续模型的计算复杂度和内存需求。
深度可分离卷积网络
注意力增强的深度可分离卷积网络是CompactMalID模型的核心组件,通过引入通道注意力和空间注意力机制,提升模型对关键特征的感知能力。注意力增强的深度可分离卷积网络的核心结构,首先定义了通道注意力模块和空间注意力模块,通道注意力模块通过全局平均池化和多层感知机学习不同通道的重要性权重,空间注意力模块通过通道维度的最大池化和平均池化,结合卷积层学习空间位置的重要性权重。然后定义了深度可分离卷积模块,将标准卷积分解为深度卷积和点卷积两个步骤,大幅减少模型的参数量和计算复杂度。最后,将这些模块组合成完整的网络结构,通过在深度可分离卷积层后应用注意力机制,提升模型对关键特征的感知能力。以下代码片段展示了该网络的核心实现逻辑:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
# 全局平均池化
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 多层感知机(MLP)
self.mlp = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction_ratio, kernel_size=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // reduction_ratio, in_channels, kernel_size=1, bias=False)
)
# Sigmoid激活函数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 计算全局平均池化
avg_out = self.avg_pool(x)
# 通过MLP计算通道注意力权重
channel_weights = self.sigmoid(self.mlp(avg_out))
# 将注意力权重与输入特征相乘
return x * channel_weights
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
# 卷积层,用于学习空间注意力权重
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size//2, bias=False)
# Sigmoid激活函数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 计算通道维度的最大池化和平均池化
max_out, _ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.mean(x, dim=1, keepdim=True)
# 拼接两种池化结果
concat_out = torch.cat([max_out, avg_out], dim=1)
# 通过卷积层计算空间注意力权重
spatial_weights = self.sigmoid(self.conv(concat_out))
# 将注意力权重与输入特征相乘
return x * spatial_weights
class DepthwiseSeparableConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(DepthwiseSeparableConv, self).__init__()
# 深度卷积:对每个输入通道单独进行卷积
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=in_channels, bias=False)
# 点卷积:1×1卷积,融合不同通道的特征
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
# 批归一化和激活函数
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
x = self.bn(x)
x = self.relu(x)
return x
class AttentionEnhancedDSCNN(nn.Module):
def __init__(self, num_classes=10):
super(AttentionEnhancedDSCNN, self).__init__()
# 初始卷积层
self.init_conv = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU(inplace=True)
# 注意力增强的深度可分离卷积块1
self.ds_conv1 = DepthwiseSeparableConv(32, 64, kernel_size=3, stride=1, padding=1)
self.channel_att1 = ChannelAttention(64)
self.spatial_att1 = SpatialAttention()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 注意力增强的深度可分离卷积块2
self.ds_conv2 = DepthwiseSeparableConv(64, 128, kernel_size=3, stride=1, padding=1)
self.channel_att2 = ChannelAttention(128)
self.spatial_att2 = SpatialAttention()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 全局平均池化
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
# 全连接层,用于分类
self.fc = nn.Linear(128, num_classes)
def forward(self, x):
# 初始卷积
x = self.init_conv(x)
x = self.bn1(x)
x = self.relu1(x)
# 第一个注意力增强的深度可分离卷积块
x = self.ds_conv1(x)
x = self.channel_att1(x)
x = self.spatial_att1(x)
x = self.pool1(x)
# 第二个注意力增强的深度可分离卷积块
x = self.ds_conv2(x)
x = self.channel_att2(x)
x = self.spatial_att2(x)
x = self.pool2(x)
# 全局平均池化和分类
x = self.global_avg_pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
在网络的前向传播过程中,输入数据首先经过初始卷积层进行特征提取,然后通过两个注意力增强的深度可分离卷积块进一步提取和增强特征。每个卷积块中,深度可分离卷积负责特征提取,通道注意力和空间注意力分别从通道和空间维度增强关键特征的表达。最后,通过全局平均池化将特征图转换为特征向量,并输入到全连接层进行分类。这种网络结构在保持高检测精度的同时,显著降低了模型的参数量和计算复杂度,非常适合在资源受限的环境中部署。
重难点和创新点
本项目在轻量化恶意加密流量检测方法的研究中,面临着多个技术难点和挑战,同时也取得了一系列创新成果。以下从重难点和创新点两个方面进行详细介绍。
技术重难点
-
加密流量特征表示与提取:加密流量的内容不可见性使得传统基于包内容的特征提取方法失效,需要从流量的统计特征、时序特征等角度入手,构建有效的特征表示。如何设计能够捕捉加密流量本质特征的特征工程方法,是项目面临的首要难点。项目团队通过深入分析加密流量的特点,提出了基于流量统计特征和时序特征的综合特征提取方法,并结合灰度图像转换技术,将高维的流量数据转换为结构化的二维图像数据,便于后续的深度学习模型进行特征提取和处理。
-
模型轻量化与性能平衡:在资源受限环境下,需要在保证检测精度的同时,大幅降低模型的计算复杂度和内存需求。如何实现模型轻量化与检测性能的有效平衡,是项目的核心难点。项目团队通过引入知识蒸馏、KL变换压缩、深度可分离卷积等技术,成功实现了模型的轻量化。在知识蒸馏过程中,通过设计合适的温度参数和损失函数权重,确保学生模型能够有效继承教师模型的知识;在KL变换压缩中,通过自适应阈值确定方法,在保证信息保留率的同时,最大化压缩效率;在深度可分离卷积设计中,通过优化网络结构和参数,确保在减少计算量的同时,保持较高的特征提取能力。
-
实时检测与自适应部署:在大规模网络环境中,需要处理海量的加密流量数据,并实现实时检测和响应。同时,不同设备的计算能力存在显著差异,需要根据设备算力智能分配适合的检测模型。如何实现实时检测和自适应部署,是项目的另一大难点。项目团队通过设计云边协同架构,在云端部署数据中心、模型管理中心和态势感知中心,在边端设备上部署轻量级Agent,实现了对异构网络环境的全面覆盖。通过实时采集设备状态信息,评估设备计算能力,智能分配检测模型,确保了系统在不同设备上的高效运行。同时,通过优化数据传输和处理流程,采用差分上传策略与数据压缩机制,有效提升了系统的实时响应能力。
-
模型泛化能力与适应性:随着网络攻击手段的不断演进,恶意加密流量呈现出多样化、隐蔽化的特点,传统检测模型的泛化能力和适应性不足,容易出现误报和漏报问题。如何提升模型的泛化能力和适应性,是项目的重要挑战。项目团队通过采用数据增强技术,增加训练数据的多样性;引入正则化方法,控制模型复杂度,防止过拟合;设计注意力机制,提升模型对关键特征的感知能力,从而有效提升了模型的泛化能力和适应性。同时,通过持续收集和标注新型恶意加密流量样本,定期更新模型,确保模型能够及时适应新的攻击手段。
创新点
-
双阶段轻量化检测模型设计:项目提出了基于知识蒸馏的双阶段轻量化检测模型LightMETD,通过特征选择与随机森林组合实现快速流量筛选,结合优化结构的卷积神经网络进行精细分类。这种设计在保证检测精度的同时,大幅提升了检测速度,模型体积压缩至教师模型的2%,检测速度提升近90%。双阶段检测策略有效减少了不必要的计算开销,特别适合在资源受限环境中应用。
-
KL变换压缩与注意力增强的深度可分离卷积网络:项目提出了基于KL图像压缩的轻量化检测模型CompactMalID,通过将原始流量数据转换为灰度图像并应用KL变换进行压缩,结合注意力增强的深度可分离卷积网络进行特征提取和分类。KL变换有效减少了数据的维度和冗余信息,深度可分离卷积大幅降低了模型的计算复杂度,注意力机制提升了模型对关键特征的感知能力。实验结果表明,该模型在保持高检测精度的同时,推理速度提升约9%。
-
云边协同的自适应模型分配策略:项目设计并实现了基于云边协同架构的实时恶意加密流量检测系统NetSentinel,能够根据设备的计算能力智能分配适合的检测模型。系统通过实时采集设备状态信息,评估设备算力,对不同计算能力的设备分配差异化的检测模型:对于计算能力充足的设备,分配完整的深度学习模型;对于中等算力设备,分配LightMETD模型;对于低算力且实时性要求高的设备,分配CompactMalID模型。这种自适应的模型分配策略,确保了系统在异构网络环境下的高效运行,实现了资源利用的最大化和检测性能的最优化。
-
多维度特征融合与增强技术:项目在特征提取和表示方面,采用了多维度特征融合与增强技术,综合利用流量的统计特征、时序特征和图像特征,构建更全面、更有效的特征表示。通过灰度图像转换技术,将高维的流量数据转换为结构化的二维图像数据,保留了流量的时序特征和统计特征;通过KL变换压缩,提取最具判别力的特征成分;通过注意力机制,增强关键特征的表达,抑制无关特征的干扰。这些技术的综合应用,有效提升了模型的特征提取能力和分类性能。
-
实用化的系统设计与实现:项目不仅提出了创新的轻量化检测方法,还将这些方法应用于实际系统中,设计并实现了完整的实时恶意加密流量检测系统NetSentinel。系统采用B/S架构,具备良好的可扩展性和易用性;前端基于Vue.js框架开发,结合ECharts图表库实现了高可视化的网络安全态势感知界面;后端基于Spring Boot和Python构建,结合Kafka、Redis、TimescaleDB等技术,实现了高并发、高可用的数据处理和存储能力。系统的成功实现,为轻量化恶意加密流量检测技术的实际应用提供了有力支持,具有重要的推广价值和应用前景。
总结
本项目围绕资源受限环境下的恶意加密流量检测问题展开研究,通过理论分析、算法设计和系统实现,取得了一系列重要成果。项目提出了两种创新的轻量化检测方法:基于知识蒸馏的LightMETD模型和基于KL图像压缩的CompactMalID模型,并构建了云边协同的实时检测系统NetSentinel。这些成果为边缘计算环境下的恶意加密流量检测提供了高效解决方案,具有重要的理论价值和实际应用前景。
LightMETD模型通过双阶段检测策略和知识蒸馏机制,在保持检测精度的同时,实现了模型体积的大幅压缩和检测速度的显著提升。实验结果表明,该模型体积仅为教师模型的2%,检测速度提升近90%,有效解决了资源受限环境下模型部署的难题。CompactMalID模型通过KL变换压缩和注意力增强的深度可分离卷积网络,进一步降低了模型的计算复杂度和内存需求,同时保持了较高的检测精度,推理速度提升约9%,为实时流量分析提供了更高效的解决方案。
NetSentinel系统基于云边协同架构,实现了对异构网络环境的全面覆盖和高效防护。系统通过实时采集设备状态信息,评估设备计算能力,智能分配适合的检测模型,确保了在不同设备上的高效运行。系统具备完善的信息采集、模型分配、数据上传与解析、可视化等功能模块,能够实现从流量采集、分析到检测、告警的全流程安全管理,为网络安全运营提供了强有力的技术支撑和决策依据。
项目的研究成果丰富了恶意加密流量检测的技术体系,特别是在轻量化模型设计和云边协同架构方面取得了显著进展。这些成果不仅可以应用于物联网、工业控制网络等资源受限环境,提升边缘网络的安全性,也可以为其他领域的轻量化模型设计提供参考,推动人工智能技术在资源受限环境中的广泛应用。
未来,随着网络技术的不断发展和攻击手段的持续演进,恶意加密流量检测仍面临诸多挑战。项目团队将继续深入研究,探索自适应检测模型、多模态特征融合、可解释性检测模型等方向,进一步提升检测技术的实用性和有效性,为构建更安全、可靠的网络环境奠定坚实的技术基础。
参考文献
[1] Ji I H, Lee J H, Kang M J, et al. Artificial intelligence-based anomaly detection technology over encrypted traffic: A systematic literature review[J]. Sensors, 2024, 24(3): 898.
[2] Gao R, Lu H, Zhou H, et al. Active and passive attack detection methods for malicious encrypted traffic[C]//2024 20th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob). IEEE, 2024: 359-364.
[3] Shen M, Ye K, Liu X, et al. Machine learning-powered encrypted network traffic analysis: A comprehensive survey[J]. IEEE Communications Surveys & Tutorials, 2022, 25(1): 791-824.
[4] Aceto G, Ciuonzo D, Montieri A, et al. Mobile encrypted traffic classification using deep learning: Experimental evaluation, lessons learned, and challenges[J]. IEEE transactions on network and service management, 2019, 16(2): 445-458.
[5] Mittal P. A comprehensive survey of deep learning-based lightweight object detection models for edge devices[J]. Artificial Intelligence Review, 2024, 57(9): 242.
[6] Cheng J, Wu Y, You J, et al. MATEC: A lightweight neural network for online encrypted traffic classification[J]. Computer Networks, 2021, 199: 108472.
[7] Zheng X, Li H. Identification of malicious encrypted traffic through feature fusion[J]. IEEE Access, 2023, 11: 80072-80080.
[8] Qin L, Gu H, Wei W, et al. Spatio-temporal communication network traffic prediction method based on graph neural network[J]. Information Sciences, 2024, 679: 121003.
最后
更多推荐


 16
16 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)