
李哥深度学习班 图像分类
红框左边(
One-hot 编码
One-hot 编码(独热编码) 是一种将类别型变量(离散、非数值)转换为数值向量的方法
为什么需要独热编码?
因为大多数机器学习模型(如线性回归、神经网络)只能处理数值输入,而不能直接理解字符串或离散标签
核心思想:用一个只含 0 和 1 的向量表示一个类别,其中“1”所在的位置代表该类别。
图像分类了解
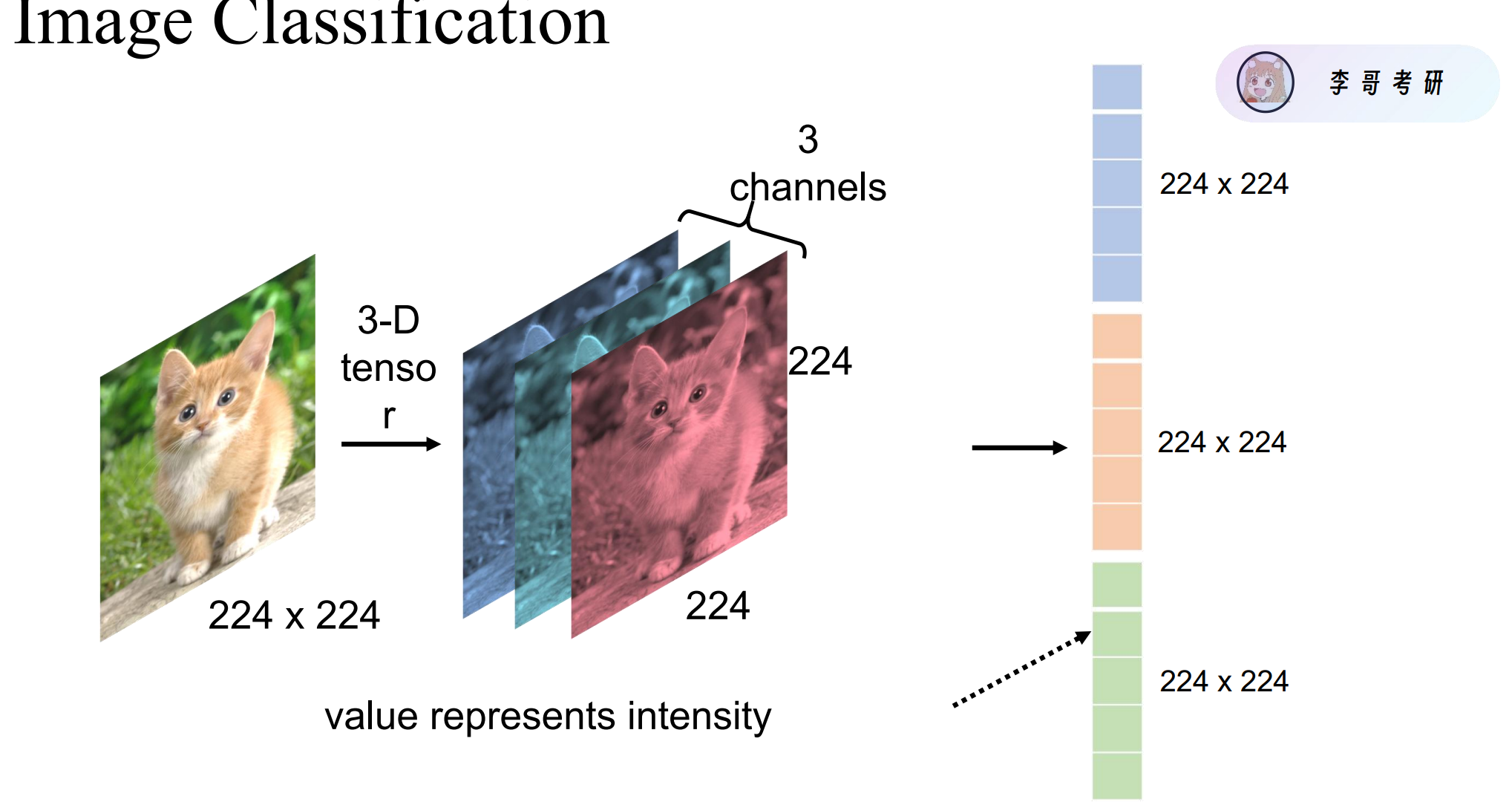
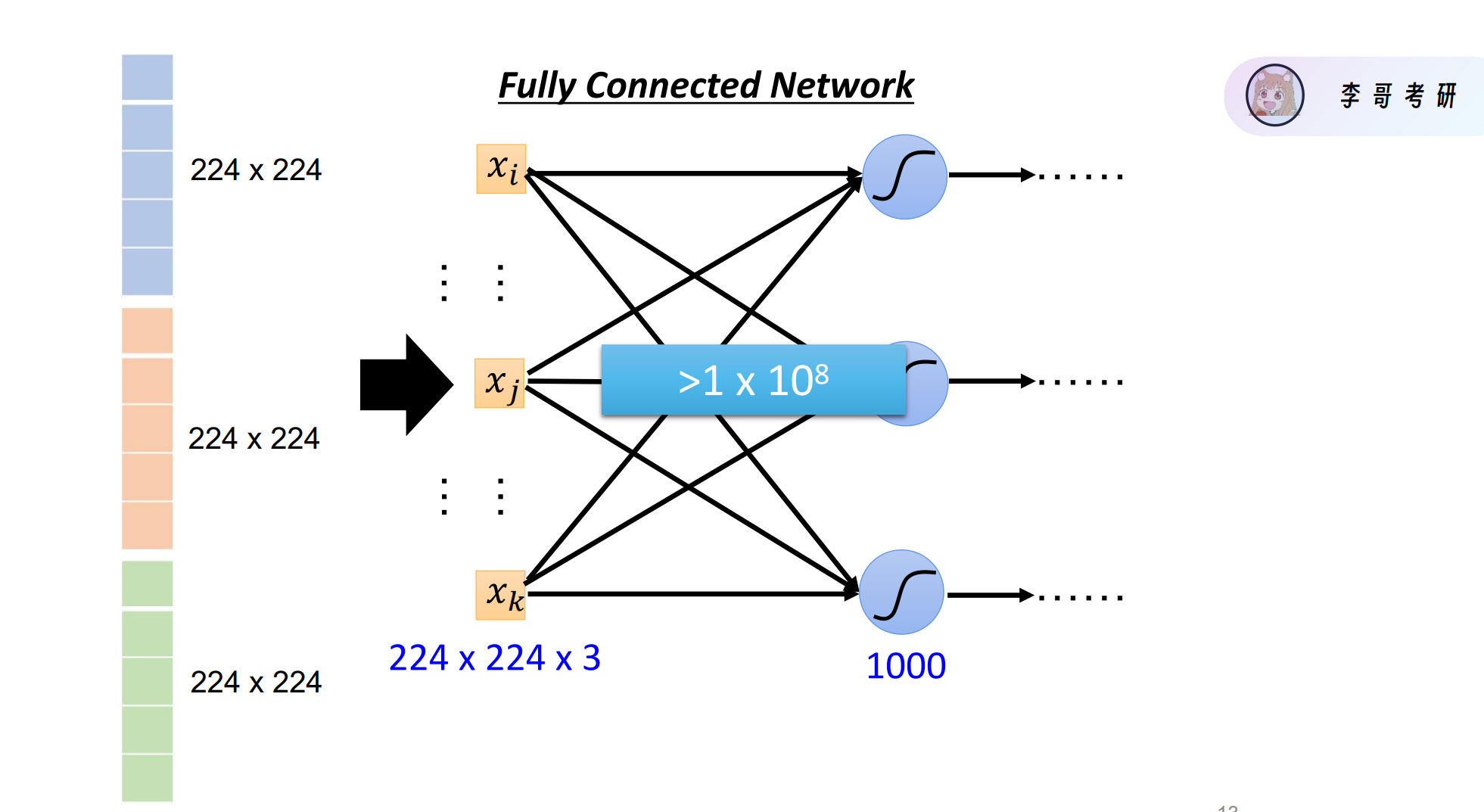
如果使用全连接神经网络,会导致参数量爆炸。于是引入卷积神经网络
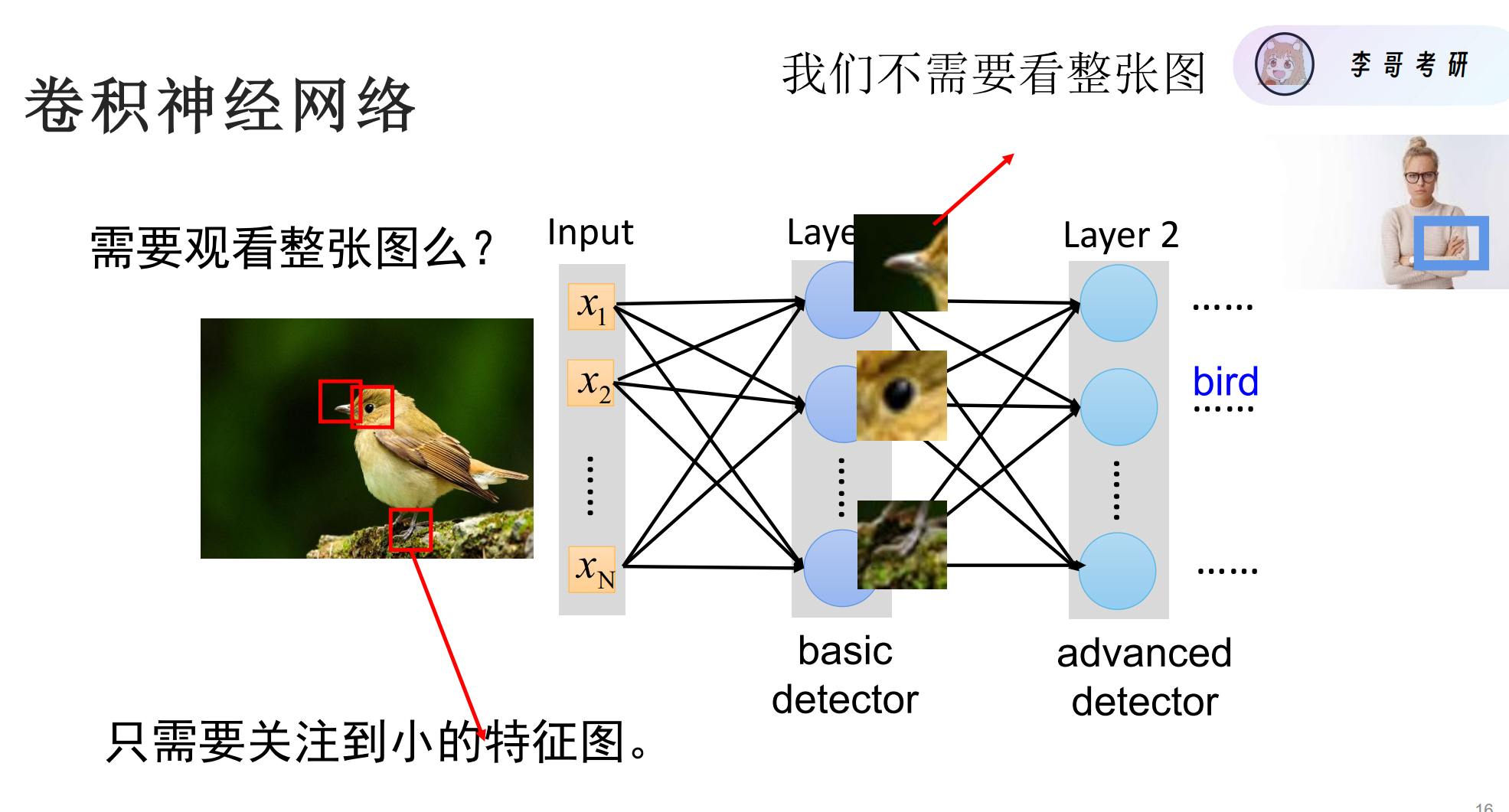
卷积神经网络
简单介绍
图片的构成
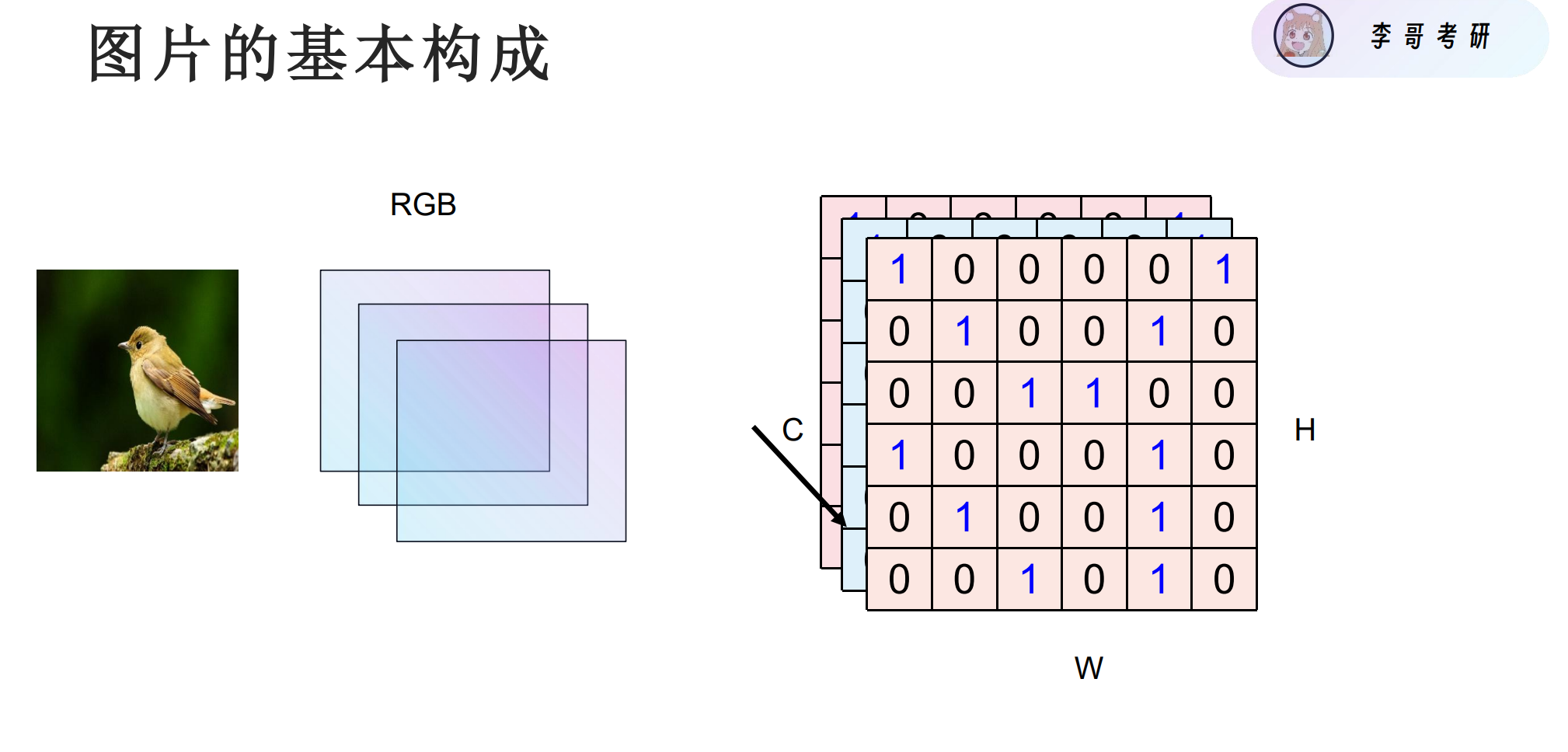
| 字母 | 全称 | 中文含义 | 说明 |
|---|---|---|---|
| W | Width | 宽度 | 图像的水平方向像素数(横向有多少列) |
| H | Height | 高度 | 图像的垂直方向像素数(纵向有多少行) |
| C | Channels | 通道数 | 图像的颜色通道数量(如 RGB = 3 个通道) |
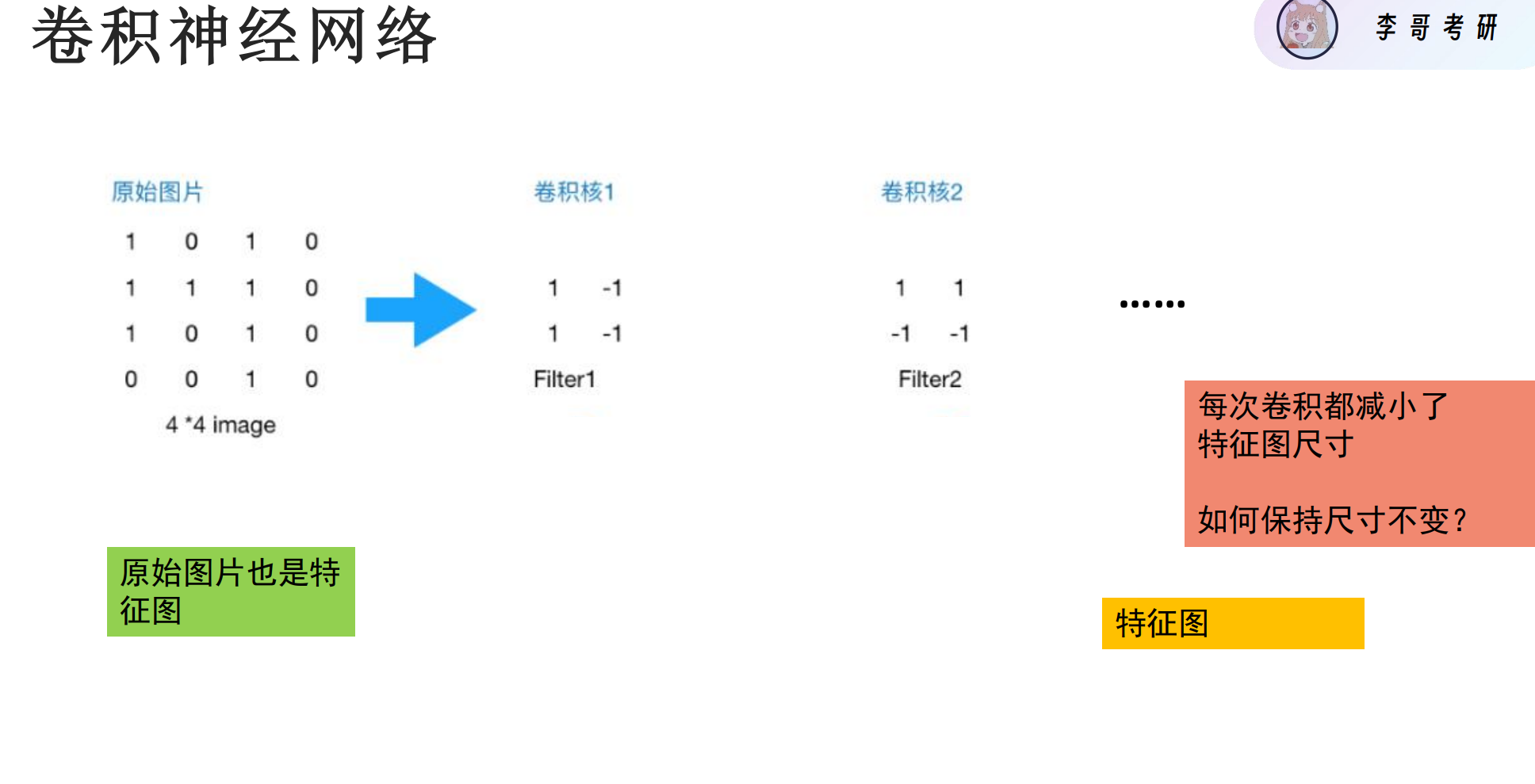
卷积核
卷积核(Convolution Kernel),也叫 滤波器(Filter),它们是深度学习和图像处理中用于提取图像特征的关键工具。
卷积核大小又称为 神经元的感受野
padding填充
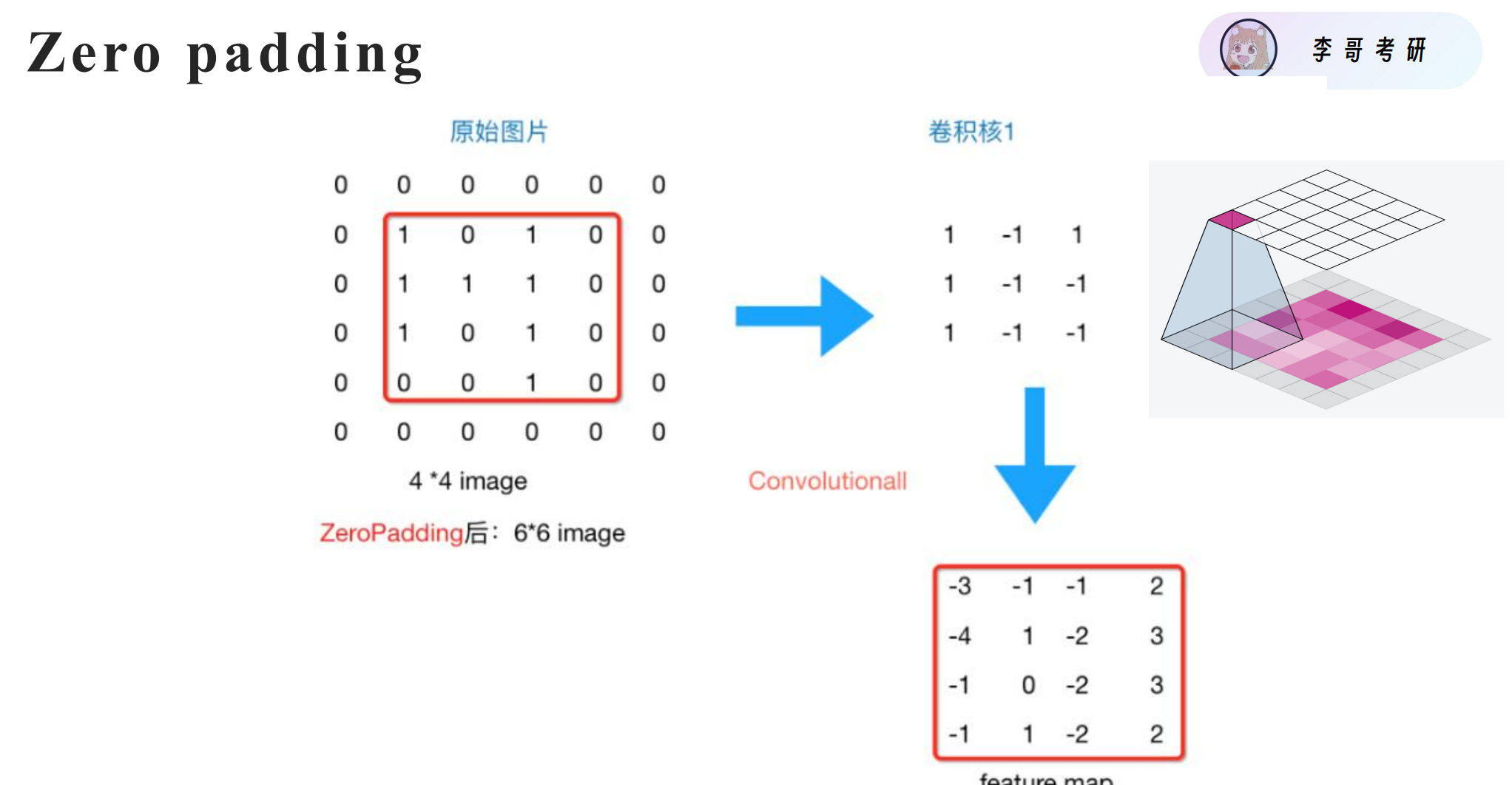
加 padding → 可以保持输出大小不变 =>解决特征图尺寸变小的问题。
zero padding 是最常用且最简单的选择:
- 0 对乘法没有影响(0 × 任意数 = 0),不会引入额外干扰。
- 卷积计算时,边界外的像素贡献为 0,相当于“忽略”。
有关卷积核的参数计算
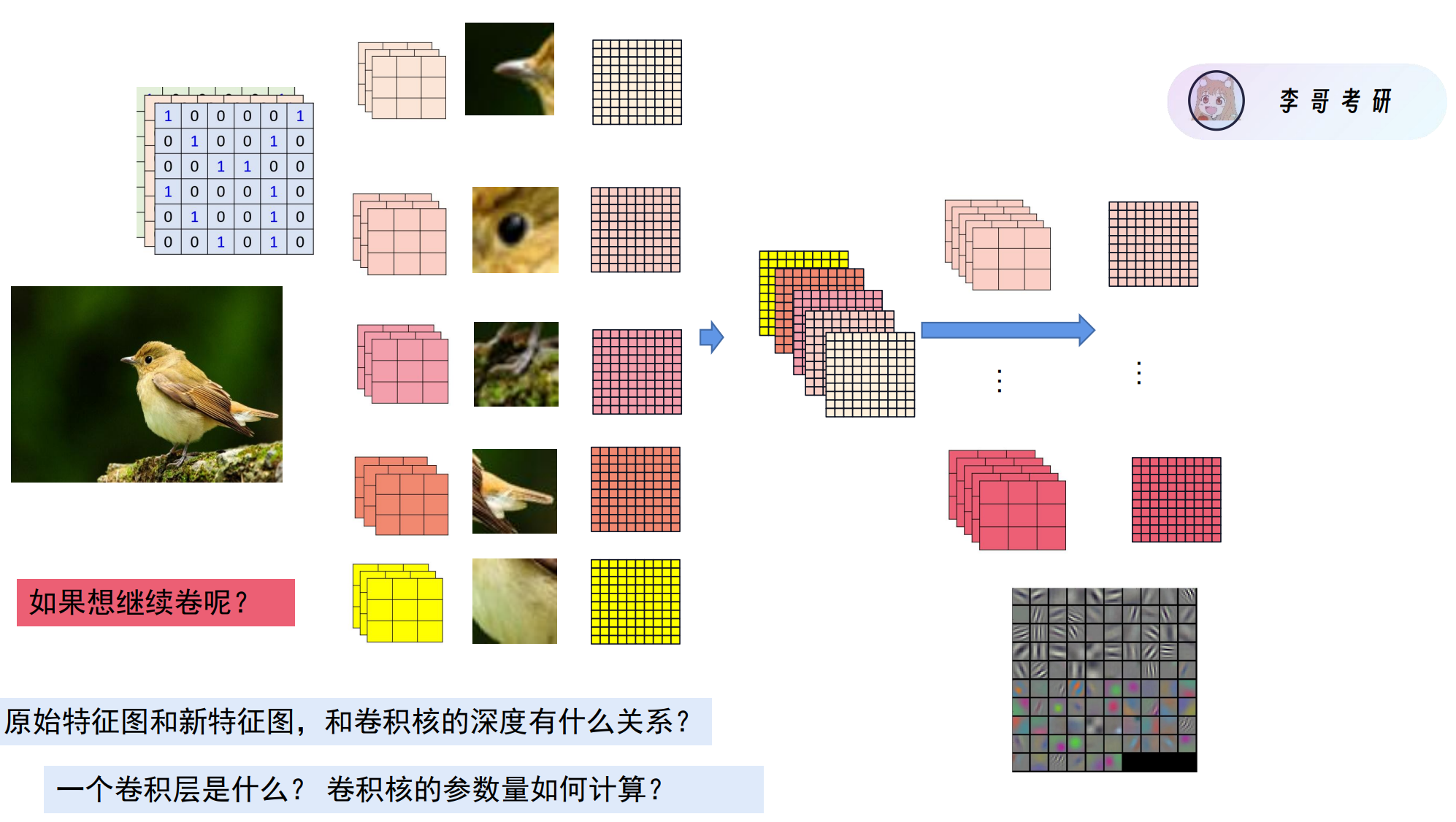
原始特征图:
深度 = 通道数(Channels),即特征图的通道数=卷积核深度
新特征图:
输出深度 = 卷积核的数量,即卷积核的个数=新特征图的深度
一个卷积层是什么?
从原始特征图经过卷积得到新特征图,这就是一个卷积层。
参数量如何计算!!!(重点)
图中卷积核有5个,每个卷积核有3*3*3(W:3 H:3 C:3),所以卷积核参数为5*3*3*3
特征图一直大小不变, 你怎么卷参数展平后都需要大量参数。如何解决?
特征图怎么变小
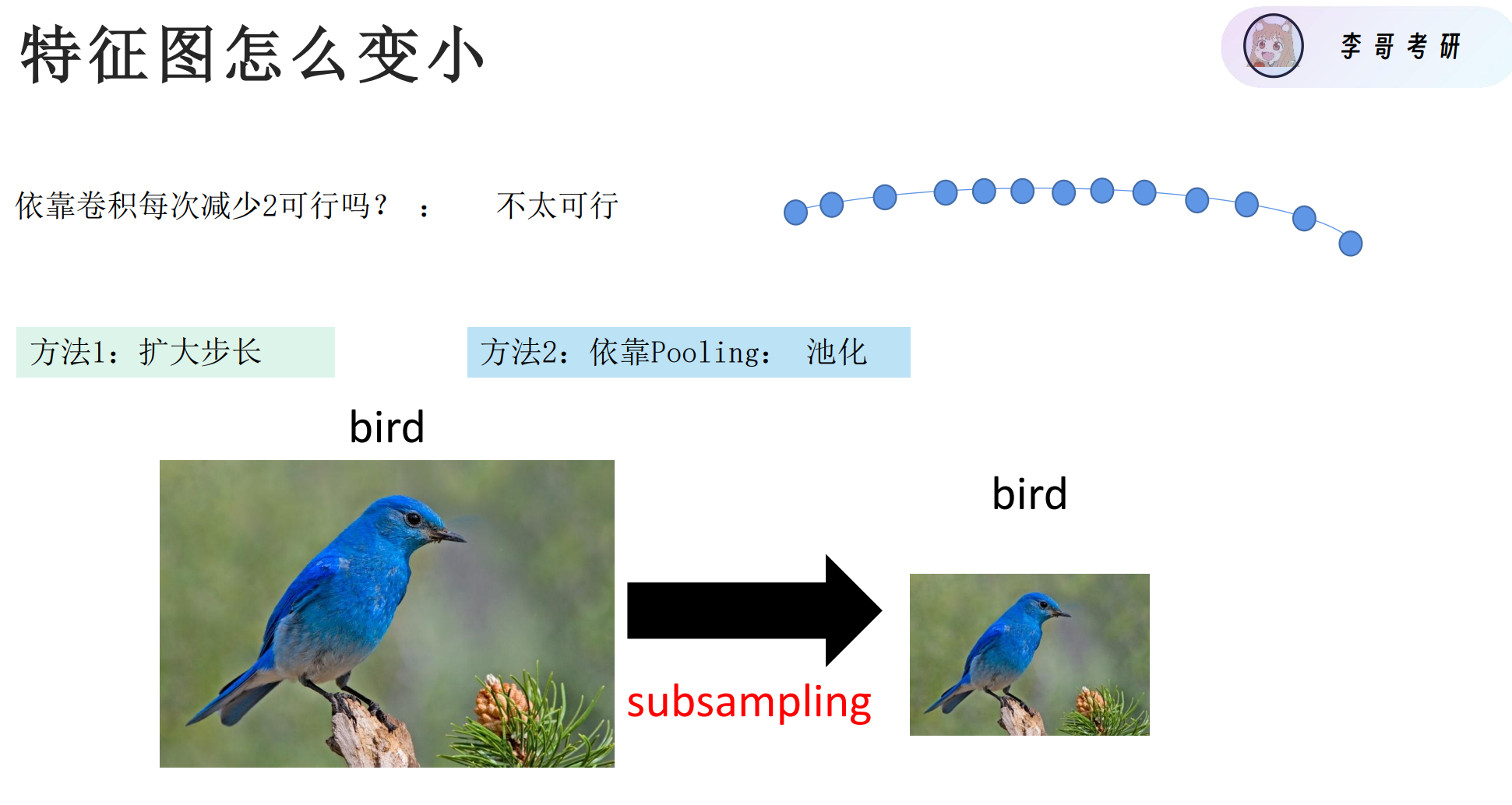
方法一:扩大步长
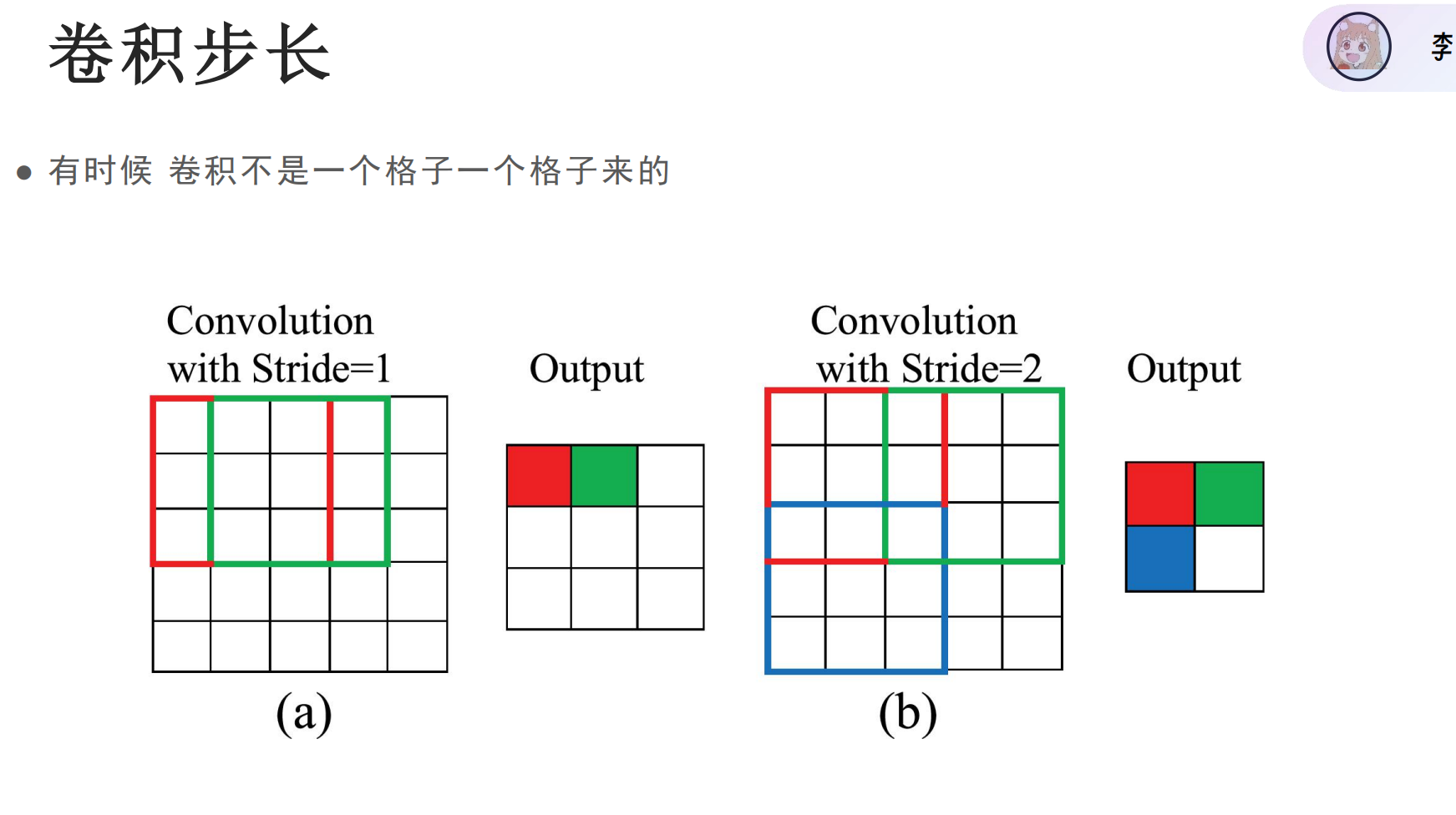

方法二:池化
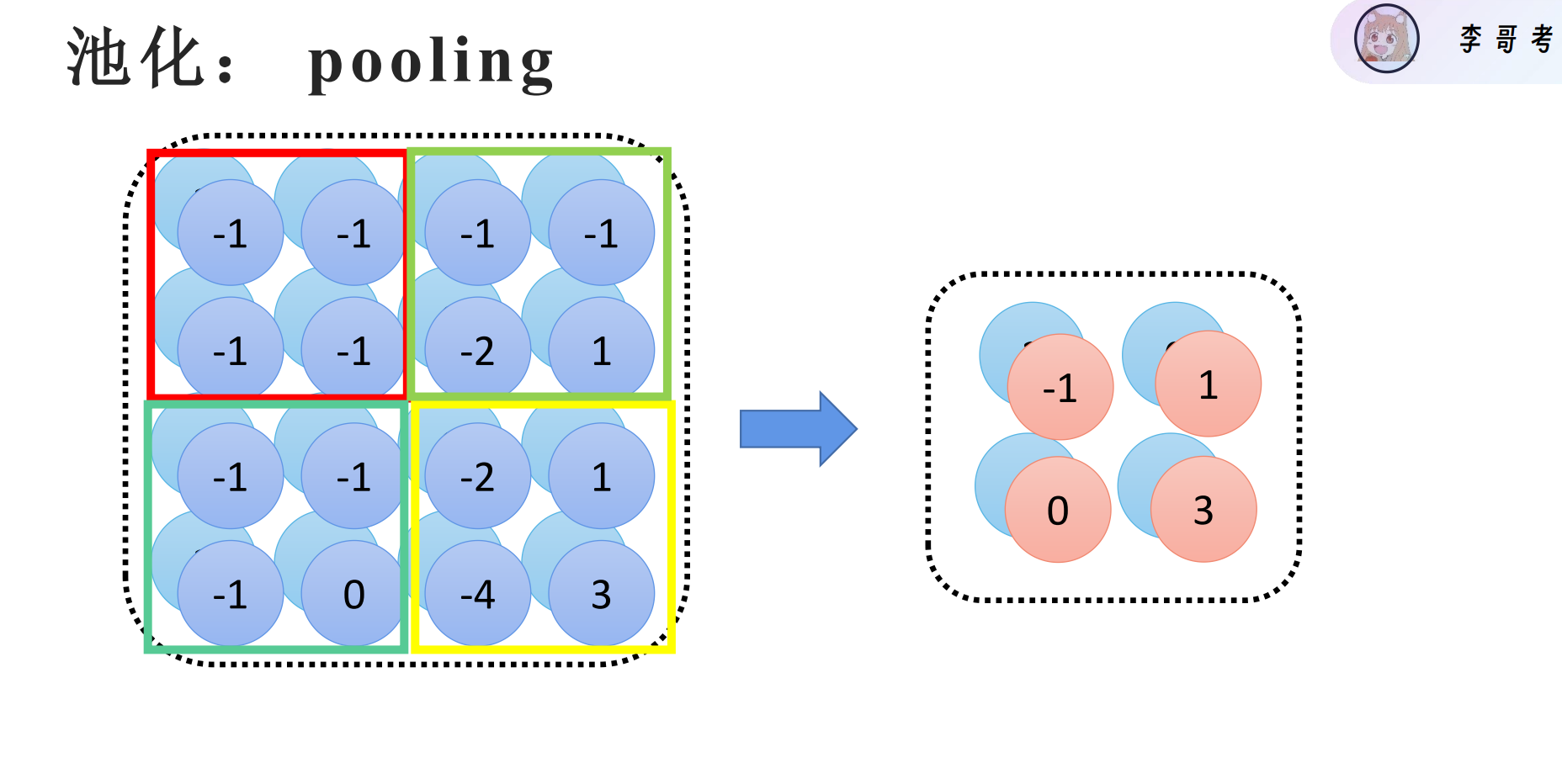
将划分的每一块都用一个数据来代替
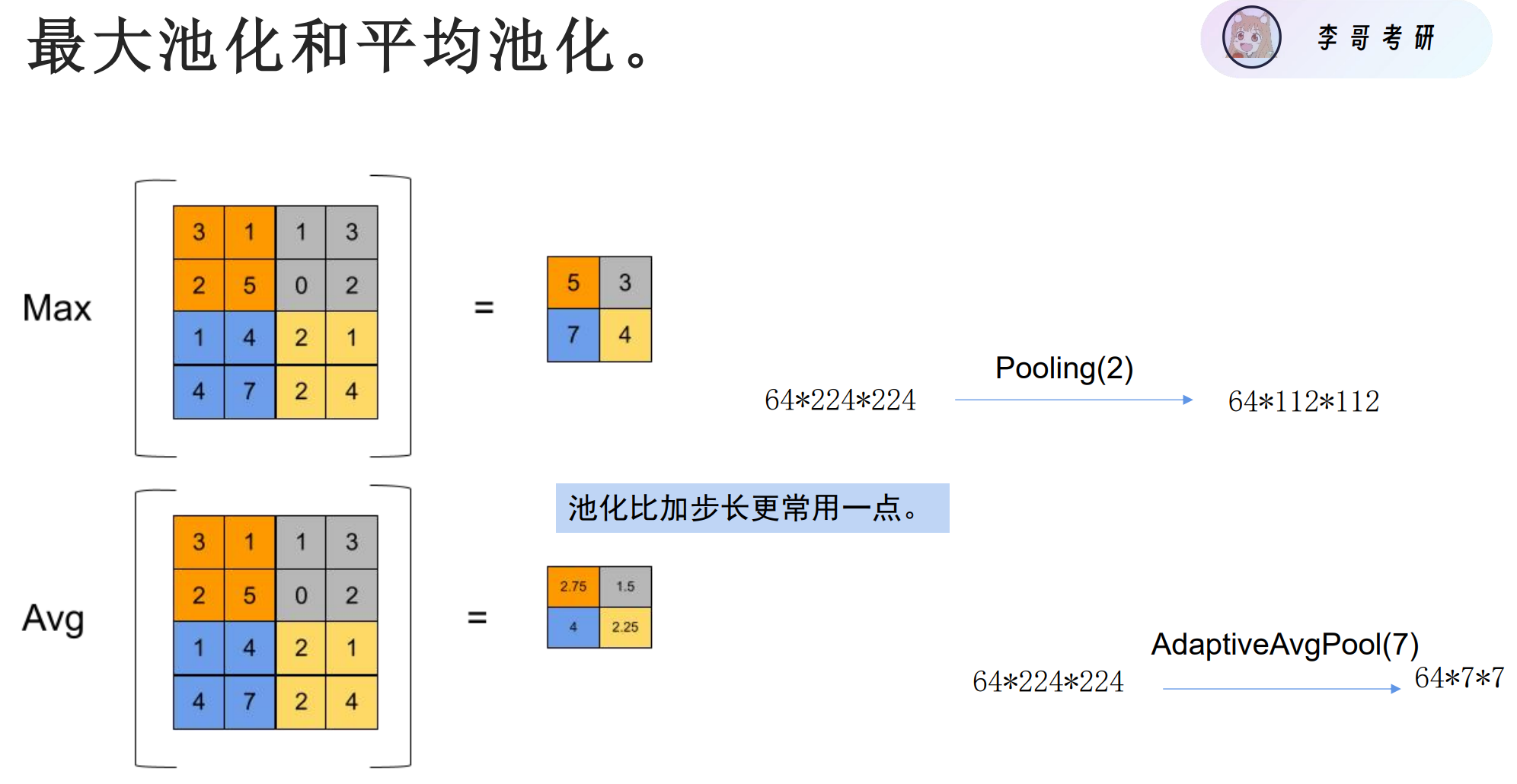
更常用的是最大池化。减少计算是关键
Pooling(2) 表示使用 2×2 的窗口 进行池化操作
- 参数:
- 核大小 = 2×2
- 步长 = 2
自适应平均池化(Adaptive Average Pooling),将任意大小的输入强制调整为固定输出尺寸:7×7 这里的 (7) 表示输出的 高度和宽度都是 7。
手搓卷积神经网络

分析过程:
3 * 224*224 -> 64*224*224:首先卷积核肯定是64个,卷积核深度为3 大小选择常用3*3,经padding保持特征图尺寸不变
64*224*224 ->(128 * 224*224):卷积核128个,卷积核深度64,padding填充
(128 * 224*224)->128*112*112:第一次池化 通常是 MaxPool(2)
128*112*112 –> 256*56*56:第二次池化+卷积 先卷积 → 再池化 → 尺寸变小(56),通道数变多(256)=卷积核个数
256*56*56 -> 512 * 28*28:第三次池化+卷积 同上
512 * 28*28 -> 1024 * 14*14:第四次池化+卷积 同上
1024 * 14*14 ->1024*7*7:第五次池化
实现了从 224→7 的空间压缩!
卷积与全连接
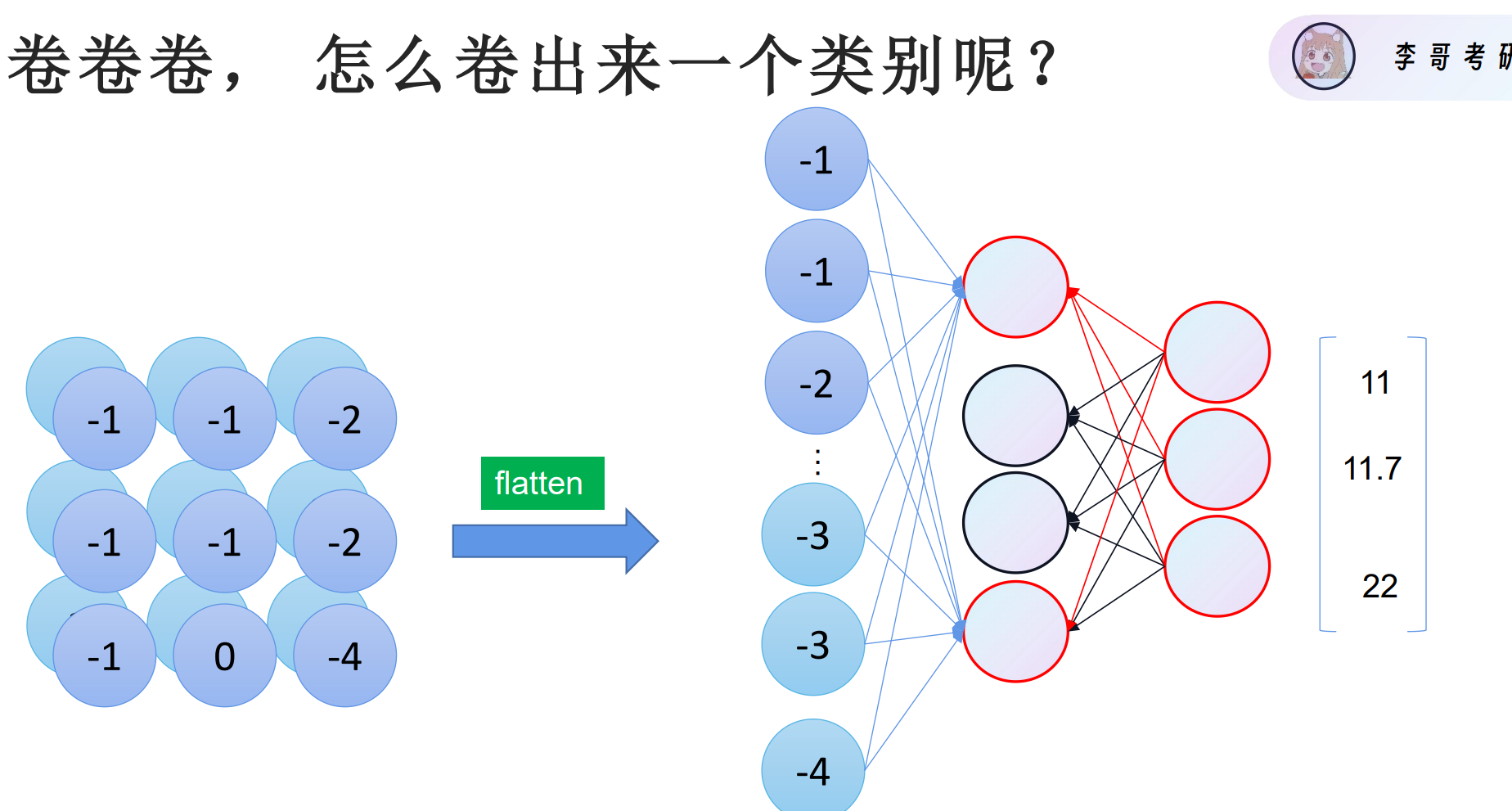
如何把这个“卷”出来的特征,变成一个具体的类别(比如猫、狗、车)?
flatten 操作:
- 把
3×3的二维特征图“拉平”成一维向量
为什么 flatten?
因为后续的分类任务要用全连接层,而全连接层只能接收一维向量作为输入
输出是 3 个数字:[11, 11.7, 22]
例如:如果类别是【猫、狗、车】,那么:
- 猫:得分 11
- 狗:得分 11.7
- 车:得分 22→ 最终预测为 “车”(因为得分最高)
CNN 的“卷”是为了提取特征,而“分类”是靠最后的全连接层完成的。


红框左边(全连接层的原始输出)(作为output)是给loss模型的输入,右边是经过(softmax)loss模型自动将左边转化为右边
分类神经网络
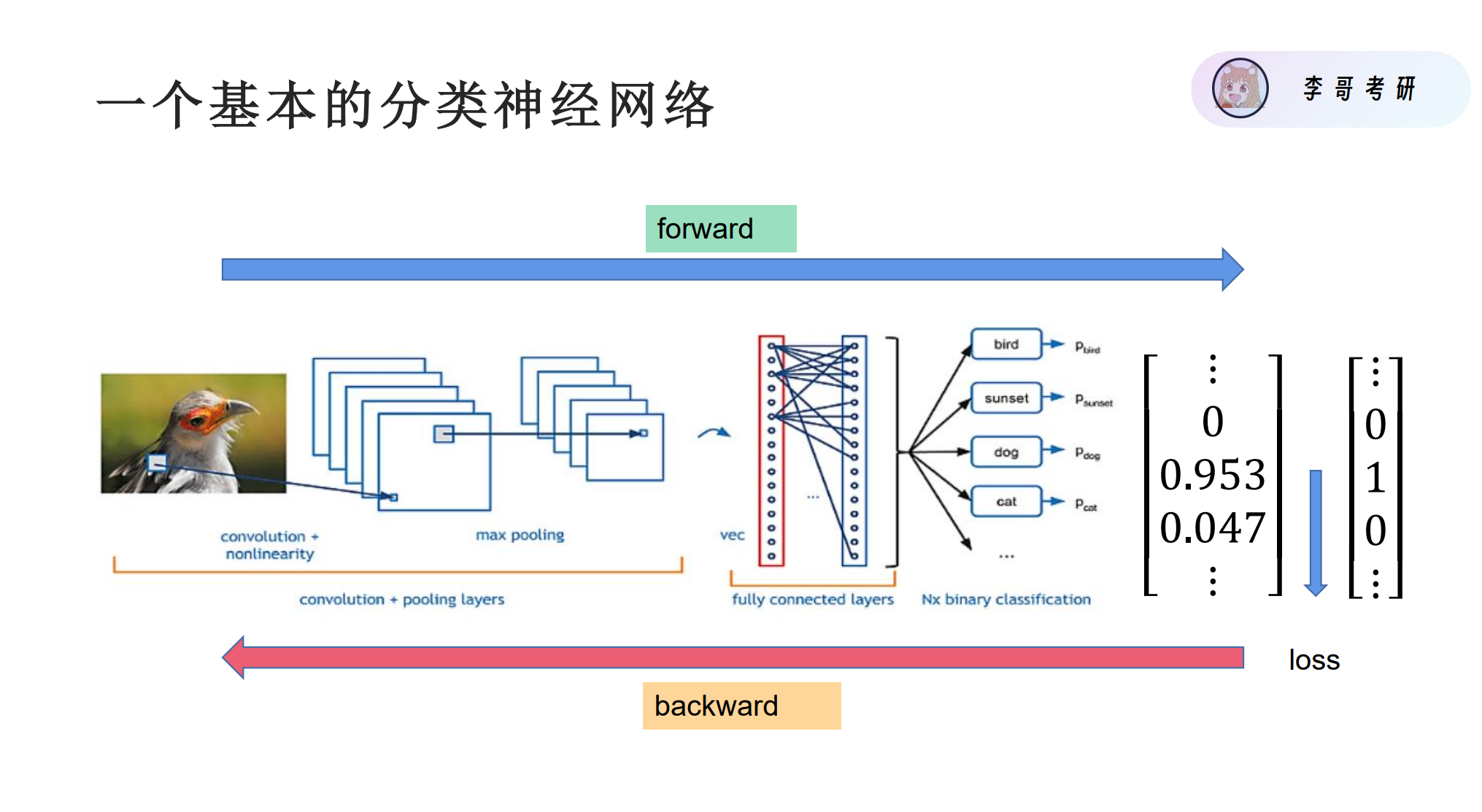
首先给一张图片,开始卷积,得到新的特征图后,经flatten 拉直,经过全连接,输出每一类的预测值(就是上图红框左侧的数据,即要给loss模型的参数),经过softmax之后,跟真实的标签求loss,求出loss之后回传梯度(与回归一样),之后更新模型。唯一不同 输入输出
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)