
深度学习实战:Caffe ResNet-50框架
Caffe(Convolutional Architecture for Fast Feature Embedding)是一个由伯克利人工智能研究(BAIR)/ Berkeley Vision and Learning Center (BVLC) 和社区贡献者开发的深度学习框架。它专门为满足学术研究和工业应用的需求而设计,具有表达力强、模块化、速度快的特点。在深度网络中,引入残差单元(Residu

简介:Caffe ResNet-50是专注于速度和精度的深度学习框架Caffe的一个深度残差网络变种,它解决了梯度消失和梯度爆炸问题,允许构建更深的网络结构。本文详细介绍了ResNet-50的架构及其在ImageNet数据集上预训练模型的应用,以及如何通过Caffe模型和配置文件在计算机视觉任务中实践应用。开发者可以利用预训练的模型进行快速迁移学习和微调。 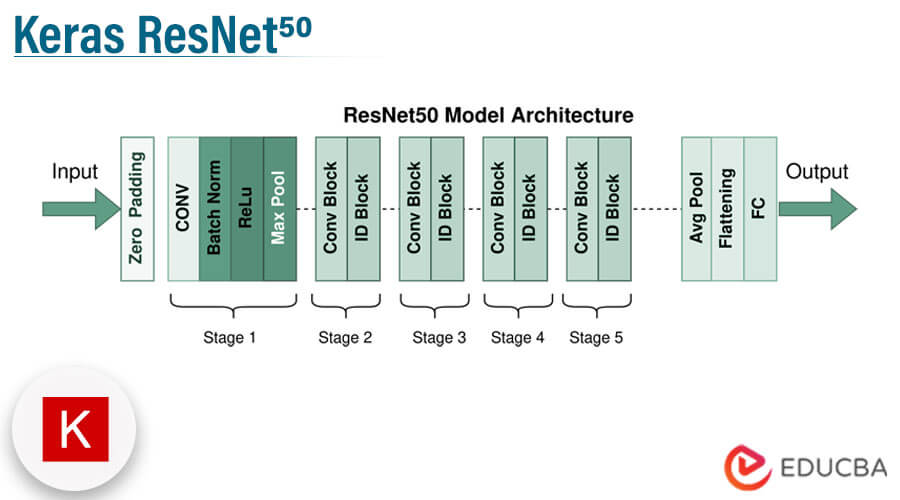
1. Caffe框架介绍
1.1 Caffe的起源和发展
Caffe(Convolutional Architecture for Fast Feature Embedding)是一个由伯克利人工智能研究(BAIR)/ Berkeley Vision and Learning Center (BVLC) 和社区贡献者开发的深度学习框架。它专门为满足学术研究和工业应用的需求而设计,具有表达力强、模块化、速度快的特点。
1.2 Caffe的架构与优势
Caffe的模块化设计使其特别适合于图像分类和卷积神经网络(CNN)相关的研究。它使用特定的数据结构(blobs)来处理数据,并通过层(layer)来构建网络。Caffe的优势在于其高效的内存和计算优化,特别是对于GPU加速的支持。
1.3 应用与实例
Caffe广泛应用于计算机视觉领域,例如图像分类、目标检测、图像分割等任务中。在工业界,众多科技公司利用Caffe作为产品中的深度学习引擎。例如,搜狗的图像搜索技术就是基于Caffe深度学习框架研发的。
本文的剩余部分将会详细解析ResNet-50网络架构,探索梯度消失和梯度爆炸问题的解决方法,以及如何利用Caffe框架进行模型训练和部署。
2. ResNet-50网络架构
深度学习的革命性进步之一便是图像识别领域中卷积神经网络(CNNs)的广泛使用,而ResNet-50作为最前沿的深度网络之一,不仅在模型的精度上有所突破,更在模型的深度上实现了重大突破。ResNet-50是深度残差网络(Residual Networks)的一种实现,这一网络在2015年的ImageNet挑战赛中一举成名。本章将深入探讨ResNet-50的架构和工作原理,以及其在训练中所采用的关键技术。
2.1 残差网络的基本概念
2.1.1 残差单元的定义和作用
在深度网络中,引入残差单元(Residual Block)的主要目的是为了解决深度网络在训练过程中出现的梯度消失或爆炸问题。一个标准的残差单元包含两个卷积层和一个“短路连接”(或称为“跳跃连接”),用于将层的输入直接加到较深层的输出上。
在数学表述中,如果假设残差单元的输入为 ( x ),那么该单元的输出 ( F(x) ) 就是通过两个卷积层得到的结果,而残差单元的最终输出 ( y ) 是 ( F(x) + x )。这种设计使得网络即使在很深的层中也能保持一定的信息传递,极大地缓解了传统深层网络训练难度大的问题。
import tensorflow as tf
# 残差单元的示例代码
def residual_block(input, filters, kernel_size=3, stride=1):
x = tf.keras.layers.Conv2D(filters, kernel_size, strides=stride, padding='same')(input)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(filters, kernel_size, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
# 残差连接
shortcut = tf.keras.layers.Conv2D(filters, 1, strides=stride, padding='same')(input)
shortcut = tf.keras.layers.BatchNormalization()(shortcut)
# 将残差连接的结果与卷积层输出相加
x = tf.keras.layers.add([x, shortcut])
x = tf.keras.layers.Activation('relu')(x)
return x
上述代码定义了一个残差块的结构,其中 filters 参数指定了卷积层中滤波器的数量, kernel_size 和 stride 则是卷积操作的标准参数。残差连接是通过一个额外的卷积层实现的,保持维度的一致性,并与卷积操作的结果相加。
2.1.2 深度残差网络的进化路径
残差网络的设计允许构建非常深的网络结构,而不会像传统CNNs那样容易出现性能下降。随着深度的增加,残差网络具有更好的学习能力和泛化能力。ResNet的进化路径从ResNet-18到ResNet-152,展现了一系列不同深度和复杂度的模型架构。在其中,ResNet-50代表了一个较深的网络结构,它在保持计算效率的同时实现了高精度的性能。
2.2 ResNet-50的具体结构
2.2.1 各层结构与功能解析
ResNet-50的架构可以看作由多个残差单元堆叠而成,其网络由50层卷积层组成。整个网络大致可以分为以下几个部分:
- 卷积层和池化层的堆叠 :网络开始部分包含卷积层和最大池化层,用于提取图像的基础特征。
- 残差模块(Residual Blocks) :构成网络主体部分,按特征图大小不同,可以分成多个组,每个组内包含多个残差单元。
- 全局平均池化层和全连接层 :在深层特征提取之后,全局平均池化层负责将特征图压缩成固定维度的向量,然后通过全连接层进行分类。
graph TD
A[输入层] --> B[卷积层]
B --> C[最大池化层]
C --> D[残差模块组1]
D --> E[残差模块组2]
E --> F[残差模块组3]
F --> G[残差模块组4]
G --> H[全局平均池化层]
H --> I[全连接层]
I --> J[输出层]
这个mermaid图表展示了ResNet-50的网络结构的基本组成部分。每个残差模块组包含多个残差单元,深度逐渐增加,并通过残差连接连接。
2.2.2 特征提取与融合策略
在ResNet-50中,特征提取的效率与准确性被进一步优化。特征融合策略主要体现在网络的后半部分,在不同深度级别的残差模块之间,ResNet采用“跳跃连接”将浅层特征与深层特征融合,从而让网络能够学习到更加丰富的特征表示。
2.3 网络训练的关键技术
2.3.1 权重初始化方法
权重初始化对于网络的性能和收敛速度有重大影响。ResNet-50推荐使用He初始化(也称为He正态初始化),这种初始化方式考虑了ReLU激活函数的特性,能够在训练初期就保持激活值的方差稳定,加快收敛速度,提高网络的性能。
from keras.initializers import HeNormal
# 使用He Normal初始化方法
kernel_initializer = HeNormal()
在上述代码中, HeNormal 用于初始化卷积层或全连接层的权重。这种方式在深度学习框架中广泛被支持,例如在Keras中直接使用即可。
2.3.2 正则化与批量归一化技术
为了避免过拟合,ResNet-50在其卷积层中广泛使用了批量归一化(Batch Normalization)。批量归一化通过标准化每一层的输入,减小内部协变量偏移,加快训练速度并使得网络对初始化不那么敏感。
from keras.layers import BatchNormalization
# 批量归一化层示例
x = BatchNormalization()(x)
在上述代码段中,批量归一化操作被作为层添加到模型中,以保证输入数据的均值接近0,方差接近1,从而起到正则化的作用。
通过上述技术的综合运用,ResNet-50在图像识别任务中取得了令人瞩目的成绩,成为许多研究和应用工作的基础模型之一。
3. 梯度消失和梯度爆炸问题的解决
3.1 梯度消失和梯度爆炸的影响
3.1.1 理解梯度消失和梯度爆炸的概念
梯度消失和梯度爆炸是深度学习训练过程中常见的两个问题,它们影响着网络的收敛速度和最终性能。梯度消失指的是在深层网络中,随着误差反向传播,梯度值越来越小,导致靠近输入层的权重得不到有效的更新。这会使得网络难以学习到有效的特征表示,特别是对于深层特征。而梯度爆炸则是指反向传播时梯度值过大,可能会造成权重更新过大,从而导致网络的不稳定性,甚至模型发散。
3.1.2 问题出现的场景与后果
梯度消失通常发生在深层神经网络中,尤其是使用了饱和激活函数(如sigmoid或tanh)的情况下。而梯度爆炸则可能在深层网络或权重初始化不当的时候出现。这些情况会导致模型训练时间过长,或者根本无法收敛到一个良好的性能。在极端情况下,梯度爆炸会导致权重值变为非常大的数值,造成数值溢出,影响整个网络的训练。
3.2 残差网络中的优化策略
3.2.1 残差连接的作用机制
残差网络(ResNet)通过引入残差连接(或跳跃连接)来缓解梯度消失问题。残差连接允许网络学习一个残差映射,而不是直接学习一个恒等映射,这有助于梯度更直接地流向前面的层。简单来说,残差连接将输入直接连接到后面的层,使得网络在训练时能够获得从输出层回传的梯度,即使在网络的深层部分也是如此。
3.2.2 梯度传递的分析与改进
在残差网络中,梯度传递变得更加直接和高效。当一个残差块被训练时,梯度可以直接通过残差连接传递到前面的层,而不需要通过多层链式法则计算。这样,即使是在很深的网络中,梯度消失的问题也得到了显著的缓解。残差块的设计包括了批量归一化和权重初始化的优化,这些都有助于稳定梯度的流动,从而改善网络的训练效率和性能。
3.3 实践中的解决方案
3.3.1 实验设置与实验结果
为了验证残差网络在实际中的效果,可以进行一系列实验。实验设置包括数据集的准备、网络结构的搭建、训练参数的选择等。在实验结果中,可以看到ResNet与其他没有残差连接的网络相比,在训练过程中梯度消失的问题得到显著的缓解。具体的,实验结果可能显示ResNet在深层网络中的性能比其他网络要好,特别是在数据集较大,训练轮数较多时。
3.3.2 对比分析与应用建议
进行对比分析时,可以将ResNet与其他网络模型的训练效果进行比较。例如,将ResNet-50与普通网络结构在相同的训练条件下进行比较,观察在相同层数下,ResNet的梯度更稳定,训练更快收敛。基于这样的分析,我们建议在设计深层网络时,应优先考虑使用残差连接来缓解梯度消失问题。同时,应该对网络的初始化和归一化技术给予足够的重视,以进一步改善网络的性能和训练效率。
4. ImageNet预训练模型
4.1 ImageNet数据集的介绍
4.1.1 数据集的规模与重要性
ImageNet是目前计算机视觉领域中最为广泛使用的一个大规模图像数据库,它由斯坦福大学的李飞飞教授领导的研究团队在2009年发起。该数据集包含超过1400万张标记过的图片,涵盖了22000多个类别,这些类别是根据WordNet的层级结构进行组织的。ImageNet项目的重要贡献在于,它推动了深度学习在图像识别领域的研究和应用,并直接促成了ILSVRC(ImageNet大规模视觉识别挑战赛)的举办。
重要性方面,ImageNet不仅作为一个大规模且丰富的数据源,为深度学习模型提供了充足的训练材料,而且由于其广泛的认可度和使用率,成为评估计算机视觉算法性能的一个重要基准。模型在ImageNet上的表现通常被认为是该模型泛化能力和实用性的一个关键指标。
4.1.2 数据预处理的方法
在使用ImageNet数据集进行模型训练之前,数据预处理是一个非常关键的步骤,它通常包括以下几个方面:
-
归一化 :将图片像素值归一化到0-1之间,有时也会进行标准化处理,即减去均值并除以标准差,这有助于模型更快地收敛。
-
大小调整 :训练之前需要将图片调整为统一的大小,比如224x224像素,以适应模型输入层的尺寸要求。
-
数据增强 :通过旋转、缩放、裁剪、颜色变换等手段生成训练数据的变体,能够有效扩大数据集大小,增加模型对不同场景的泛化能力。
-
数据批处理 :为提高训练效率,通常会将图像分批输入模型。在批处理过程中,还需要考虑到内存限制,合理设置批大小。
-
预处理流程 :通过一系列预处理步骤将原始数据转换为模型可以处理的格式。例如,对于ResNet-50,输入数据经过预处理后,可以被正确地送入网络的卷积层进行学习。
4.2 预训练模型的迁移学习
4.2.1 迁移学习的概念与优势
迁移学习是指在一个任务中训练好的模型,将学到的知识应用到另一个相关任务的过程。在计算机视觉领域,这个概念通常是指使用在大数据集(如ImageNet)上预训练好的模型,进一步在特定数据集上进行微调。
迁移学习的优势包括:
-
减少训练时间 :由于预训练模型已经学习到了丰富的特征,因此在特定任务上进行微调时,所需的训练时间会大大减少。
-
提高模型性能 :在特定任务上即使只有少量标注数据,通过预训练模型也可以获得较好的性能。
-
减少标注成本 :依赖预训练模型的微调,可以减少对大规模标注数据的依赖,从而降低数据收集和标注的成本。
4.2.2 预训练模型的微调技术
微调预训练模型的基本方法涉及以下步骤:
-
选择预训练模型 :挑选在ImageNet数据集上预训练好的模型,如ResNet-50等。
-
修改模型结构 :根据特定任务的需求,可能会对预训练模型的结构进行微调,例如增加或减少分类层的数量。
-
加载预训练权重 :将预训练模型的权重加载到新模型中,作为微调的起点。
-
替换输出层 :通常用一个适应特定任务的输出层替换原有分类器。
-
训练参数设置 :可能需要减小学习率,以避免在微调时破坏预训练的特征。
-
模型训练 :在特定任务的数据集上进行训练,通常会冻结大部分网络层,只训练最后几个层或新增的层。
-
评估和调整 :评估微调后的模型,并根据需要进一步调整模型结构或训练策略。
4.3 应用场景分析
4.3.1 基于ResNet-50的图像分类实例
在本章节,我们将讨论如何利用ImageNet预训练的ResNet-50模型在具体图像分类任务中的应用实例。假设我们有一个较为封闭的植物分类任务,包含100种不同的植物,每种植物仅有少量样本可用。
数据处理 : - 首先需要对数据集进行划分,分为训练集、验证集和测试集。 - 对图片数据进行预处理,包括缩放到合适的尺寸,应用数据增强技术等。
模型配置 : - 使用Caffe框架加载预训练的ResNet-50模型。 - 根据新的分类任务,修改最后的全连接层以匹配目标分类数量(100类)。 - 保留前几层的权重,因为它们包含从ImageNet学到的丰富特征表示。
训练与评估 : - 在训练阶段,选择合适的损失函数(例如softmax分类损失)和优化器(例如SGD),设置学习率、批量大小等超参数。 - 通过验证集调整超参数,监控在验证集上的性能,以避免过拟合。 - 在测试集上评估模型的最终性能,可以使用准确率、混淆矩阵等指标。
4.3.2 预训练模型在其他任务中的应用
除了图像分类任务外,预训练的ResNet-50模型还可被应用于其他计算机视觉任务中,例如目标检测、图像分割等。通过迁移学习,模型能够利用在图像分类任务中学到的特征,并将其用于解决不同的视觉识别问题。
例如,在目标检测任务中,预训练的ResNet-50可以被用作特征提取器,以构建如Faster R-CNN或YOLO等检测模型。这些检测模型通常会在ResNet-50的特征表示之上添加额外的卷积层来定位和分类图像中的目标。
在图像分割任务中,同样可以利用ResNet-50作为骨干网络来提取高级特征,并通过额外的解码器层来预测每个像素的类别标签,从而实现细粒度的图像理解。
通过这些应用场景,我们可以看出预训练模型在计算机视觉领域中具有广泛的应用潜力和灵活性。预训练模型的成功迁移不仅缩短了训练时间,也提高了模型在特定任务上的性能。
5. Caffe模型与配置文件
5.1 Caffe的模型文件格式
5.1.1 .binaryproto文件结构与解析
Caffe框架采用 .binaryproto 格式用于存储神经网络的结构与权重信息,这种格式采用二进制形式,相较于文本格式的 .prototxt 文件,提供了更紧凑的存储方式和更快的读写速度。 .binaryproto 文件通常包含网络层的信息、学习到的权重参数、偏置等数据。
文件结构解析
.binaryproto 文件开始部分是文件头,用来存储文件的元数据信息。随后是层参数,包括每个层的权重、偏置以及层内的其他参数。这些数据会根据层类型的不同而有不同的存储格式。例如,卷积层会存储卷积核的权重,而全连接层则会存储权重矩阵以及偏置向量。
layer {
name: "conv1"
type: CONVOLUTION
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
上例是一个 .prototxt 文件片段,定义了一个卷积层。在 .binaryproto 中,这个层的权重和偏置等参数会被存储为二进制数据。
参数说明
name: 层的名字。type: 层的类型,比如CONVOLUTION(卷积层)。bottom: 输入数据的名称。top: 输出数据的名称。convolution_param: 卷积层的参数,包括滤波器数量、大小、步长等。
5.1.2 .caffemodel文件的作用与加载
.caffemodel 文件存储的是训练完成的神经网络模型参数,包括所有的权重和偏置。这个文件对于模型的预测、微调以及迁移学习至关重要。它允许用户加载一个已经训练好的模型,用于新的数据集上进行预测或者进一步的训练。
加载方法
在Caffe中,加载 .caffemodel 文件通常涉及到使用 Net 类,具体步骤如下:
import caffe
# 加载网络结构
net = caffe.Net('deploy.prototxt', 'model_iter_10000.caffemodel', caffe.TEST)
上面代码段展示了如何用Python加载一个训练好的模型,其中 deploy.prototxt 是网络结构文件,而 model_iter_10000.caffemodel 是我们训练好的参数文件。 caffe.TEST 表示加载模型后,将网络置于测试模式。
5.2 配置文件的设计与编写
5.2.1 .prototxt文件的基本组成
.prototxt 文件定义了Caffe模型的网络结构,包括网络层的类型、参数配置和连接信息。这是构建和训练模型时不可或缺的一部分,其结构和内容为构建网络提供了详细的指令。
文件组成
一个典型的 .prototxt 文件由以下部分组成:
name: 模型的名称。layer: 网络层的定义,包括层类型、名称、参数以及与其他层的连接。input: 定义网络的输入格式,比如数据的尺寸、通道数等。output: 网络的输出层,指定输出层的名称。
下面是一个简化的 .prototxt 文件示例:
name: "LeNet"
layer {
name: "data"
type: INPUT
top: "data"
input_param { shape: { dim: 1 dim: 1 dim: 28 dim: 28 } }
}
layer {
name: "conv1"
type: CONVOLUTION
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
}
}
# ... 其他层的定义
在这个例子中,我们定义了一个名为"LeNet"的网络,包含了输入层(data)和卷积层(conv1)。
参数说明
name: 指定层的名称。type: 指定层的类型,如INPUT、CONVOLUTION等。bottom: 输入数据的名称,表示该层接收的前一层输出。top: 输出数据的名称,表示该层的输出。input_param: 指定输入层的数据形状。
5.2.2 网络结构定义与参数设置
在 .prototxt 文件中,每种类型的层都需要不同的参数设置。这些参数控制着层的行为和性能,例如卷积层需要设置滤波器的数量、大小和步长等。
网络结构定义
网络结构的定义是通过一系列的层来实现的,每种层有其特定的参数。层的类型包括但不限于卷积层(CONVOLUTION)、池化层(POOLING)、激活层(ACTIVATION)和全连接层(INNER_PRODUCT)。
layer {
name: "pool1"
type: POOLING
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
上面代码定义了一个名为"pool1"的最大池化层,输入层为"conv1"。
参数设置
层的参数设置需要根据具体任务进行调整。例如,卷积层的参数 num_output 定义了滤波器的数量, kernel_size 和 stride 则定义了滤波器的尺寸和步长,这些参数直接影响网络的感受野和模型的性能。
layer {
name: "conv2"
type: CONVOLUTION
bottom: "pool1"
top: "conv2"
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
pad: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
在上述卷积层定义中,设置了滤波器数量为50,大小为5x5,步长为1,同时使用高斯分布初始化权重,偏置初始化为0。
5.3 模型训练与部署
5.3.1 训练过程的配置与优化
模型训练通常需要经历多个阶段,从设置数据集、定义网络结构到选择损失函数和优化器。配置 .prototxt 文件中包含了这些关键步骤,它们的设置对模型性能有着决定性的影响。
配置文件设置
在Caffe中,配置文件通常包括三个主要部分:数据层(DATA LAYER)、网络层(NETWORK LAYER)和求解器(SOLVER)。数据层定义了数据的来源和预处理方式,网络层定义了模型结构,求解器定义了优化算法和训练策略。
layer {
name: "data"
type: DATA
data_param {
source: "train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "loss"
type: SOFTMAX_LOSS
bottom: "ip2"
top: "loss"
}
# ... 其他层定义
在上述配置中,定义了一个数据层(data)用于从训练集 train_lmdb 加载数据,以64的批次大小进行训练,并选择LMDB作为数据的后端存储。
参数优化
参数优化主要涉及调整网络的参数,如学习率、权重衰减(权重正则化)和动量等。这些参数需要根据具体的数据集和任务进行精心调整。
solver {
net: "train_val.prototxt"
test_iter: 100
test_interval: 500
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
type: "SGD"
}
上述求解器配置设置了一个基于SGD的优化器,以0.01的初始学习率训练,并采用0.9的动量。权重衰减设置为0.0005,用于防止过拟合。
5.3.2 模型部署与推理
训练完成后,模型需要被部署到目标平台进行实际的预测任务。这个过程通常涉及模型参数的加载、预处理输入数据、模型推理和后处理输出结果。
模型推理步骤
模型推理在Caffe中涉及到使用 Net 类,加载已经训练好的 .caffemodel 和对应的 .prototxt 文件:
import caffe
net = caffe.Net('deploy.prototxt', 'model_iter_10000.caffemodel', caffe.TEST)
# 加载输入数据
input_data = ... # 这里需要加载你的输入数据
out = net.forward_all(data=input_data)
模型部署
模型部署需要根据特定的应用场景选择合适的硬件和软件平台。例如,在嵌入式设备上可能会需要将模型转换为适合硬件加速的形式。对于服务器部署,则可能需要确保模型能够高效地处理大量并发请求。
在本节中,我们详细了解了Caffe模型文件和配置文件的格式与解析,同时也学习了如何设计和编写配置文件。此外,我们还探讨了如何进行模型训练和部署。下一章节将讲述计算机视觉任务中的应用实践,其中将涉及图像分类、检测与分割等任务的实际操作和案例分析。
6. 计算机视觉任务中的应用与实践
在计算机视觉领域,深度学习已经成为了推动发展的核心力量。特别是在图像分类、检测、分割、关键点检测以及姿态估计等任务上,深度学习的贡献尤为显著。本章将深入探讨在各种计算机视觉任务中如何应用ResNet-50网络,并且分析在实践过程中进行性能评估的方法和经验。
6.1 计算机视觉任务概述
6.1.1 图像分类、检测与分割
图像分类是计算机视觉中最基础的任务之一,旨在将图像分配到预定义的类别中。深度学习模型如ResNet-50在这一领域表现卓越,其深层结构能够捕捉图像中复杂多变的特征。
图像检测则更进一步,它不仅需要识别出图像中的对象,还需要确定这些对象的位置,通常通过边界框(bounding box)的方式标示。在这一任务中,ResNet-50常被用作特征提取器,结合区域建议网络(Region Proposal Network, RPN)等技术,实现精确的目标检测。
图像分割任务更上一层楼,它关注于像素级别的分类,目标是将图像划分为多个区域,每个区域对应一个类别标签。在语义分割中,ResNet-50可以通过特征金字塔网络(Feature Pyramid Network, FPN)等结构来提升对不同尺度信息的捕捉。
6.1.2 关键点检测与姿态估计
关键点检测旨在识别图像中特定对象的关键位置点,例如人体姿态估计中的人体关键点。ResNet-50的深层结构有助于提取到更精细的特征,这些特征对于精确定位关键点至关重要。
姿态估计进一步扩展关键点检测的应用,它不仅识别关键点,还要根据关键点之间的关系推断出对象的姿态。结合ResNet-50和姿态估计算法,如姿态估计卷积神经网络(Pose Estimation Convolutional Neural Network, PECNN),可以实现对人体姿态的准确估计。
6.2 ResNet-50在CV任务的应用
6.2.1 高性能特征提取器的角色
在许多计算机视觉任务中,ResNet-50充当着高性能特征提取器的角色。它之所以能胜任这样的角色,得益于其深层结构和残差连接的设计。这些设计使得ResNet-50能够学习到更加复杂和抽象的图像特征表示,对提高最终任务的性能有着直接的贡献。
通过在大规模数据集(如ImageNet)上预训练ResNet-50,可以获得泛化的特征提取能力。然后,这些预训练模型可以在特定的计算机视觉任务上进行微调(Fine-tuning),以便更好地适应特定任务的要求。
6.2.2 具体任务的网络微调实例
为了在特定任务上实现最佳性能,网络微调是一个常用的技术手段。以下是使用ResNet-50对图像分类任务进行微调的一个简单实例:
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
# 加载预训练的ResNet-50模型
model = models.resnet50(pretrained=True)
# 替换最后的全连接层以匹配新任务的类别数
num_ftrs = model.fc.in_features
model.fc = torch.nn.Linear(num_ftrs, 新任务的类别数)
# 设置训练参数
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 加载数据集
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_dataset = ImageFolder(root='train_data', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
scheduler.step()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')
# 保存微调后的模型
torch.save(model.state_dict(), 'resnet50_finetuned.pth')
以上代码展示了如何加载预训练的ResNet-50模型,并对其进行微调以适应一个新的图像分类任务。通过替换最后的全连接层并执行训练过程,模型被优化以识别新的类别。
6.3 实践中的性能评估
6.3.1 模型评估指标
在实践中,模型的性能通过一系列评估指标来衡量。对于分类任务,常见的评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1得分(F1 Score)和混淆矩阵(Confusion Matrix)。
准确率是分类任务中最直观的性能指标,它表示模型正确分类的样本占总样本的比例。精确率和召回率则从不同的角度衡量模型的性能。精确率强调模型预测正确的正样本占所有预测为正样本的比例,而召回率关注模型识别出的正样本占实际所有正样本的比例。F1得分是精确率和召回率的调和平均数,用于衡量模型的均衡性能。
混淆矩阵则提供了一个更详细的性能分析,它表示了每个类别的预测结果与实际类别之间的关系。通过分析混淆矩阵,可以识别模型在哪些类别上表现得更好或更差。
6.3.2 案例分析与优化经验
在实际应用中,针对特定的计算机视觉任务,性能评估往往伴随着模型的优化过程。通过细致地分析评估指标,可以获得模型在哪些方面需要改进的线索。例如,如果一个模型在某类别的召回率较低,可能意味着模型对该类别的识别能力不足。
为了提高模型性能,可以采取多种策略。比如,增加训练数据或增强训练数据(如随机裁剪、旋转、缩放),调整模型结构(例如增加或减少网络深度),改变训练策略(例如学习率调度、优化器选择),以及引入正则化技术(如dropout、权重衰减)等。
在优化过程中,不断迭代评估与调整是提高模型性能的关键。在实践中,通常会通过交叉验证、A/B测试等方法来确保模型在未见数据上的泛化能力,并避免过拟合的问题。
通过本章的探讨,我们可以看到ResNet-50在计算机视觉领域的广泛应用以及它在实践中的具体应用案例和性能评估方法。
简介:Caffe ResNet-50是专注于速度和精度的深度学习框架Caffe的一个深度残差网络变种,它解决了梯度消失和梯度爆炸问题,允许构建更深的网络结构。本文详细介绍了ResNet-50的架构及其在ImageNet数据集上预训练模型的应用,以及如何通过Caffe模型和配置文件在计算机视觉任务中实践应用。开发者可以利用预训练的模型进行快速迁移学习和微调。
更多推荐
 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)