
李哥深度学习班---生成实战
Bart是生成模型,他有解码器生成=Encoder+Decoder。
关键代码解释
1.process_data 处理数据
train_data = train_df.sample(frac=0.9, random_state=0, axis=0) #采样0.9的比例
val_data = train_df[~train_df.index.isin(train_data.index)] #干啥的, 过来用
#train_data.index 作为训练数据,
#train_df.index.isin 在整个数据集中
#~ 取反
#~train_df.index.isin(train_data.index) 这表示验证集的下标
#所以train_df[~train_df.index.isin(train_data.index)]意思就是取验证集的下标 在前面加 train_df
就取到验证集的数据2.pro_vocab 处理词
词表 就是每一个字与它的下标对应
line = line.strip().split(",")
#strip() 是字符串(str)的一个方法,用于移除字符串开头和结尾的空白字符(包括空格、制表符 \t、换行符 \n 等)。
#.split(","):再用逗号 , 作为分隔符,把字符串切分成一个列表。
from collections import Counter
token2count = Counter() #计数工具 哈希表
for i in train_data:
token2count.update(i) #不需要知道原理
#用来统计出现了多少个词,, 每个词出现的次数tail = []
ct = 0
for k, v in token2count.items():
if v >= ct:
tail.append(k)
#token2count.items() 就是一个字典
#只要词出现次数大于0 就把他加入tail列表中tokenizer = BertTokenizer.from_pretrained(args.pre_model_path) #分词器 Bert Bart都行
vocabs = tokenizer.get_vocab() #获取模型词表
new_vocabs = list(vocabs.keys()) #先把模型词表的词加入
print(len(vocabs))
count = 0
for v in vocab: #mn复杂度
if v not in vocabs: #如果在模型词表没找到
count += 1
new_vocabs.append(v) #直接加入新词表
为什么需要调用模型?
词表长度变了,模型就要变。 为什么?
词表长度直接决定了模型中“嵌入层(Embedding Layer)”和“输出分类层(LM Head)”的参数矩阵大小。一旦词表长度改变,这些层的维度就不再匹配,必须调整模型结构,否则会报错或结果错误。
model = BartForConditionalGeneration.from_pretrained(args.pre_model_path) #模型
# 关键!让模型适配新的词表大小
model.resize_token_embeddings(len(new_vocabs))3.自监督预训练
细枝末节的处理完成后 进入正题
自监督预训练(Self-supervised Pre-training)通常指在大量无标签数据上,通过设计“自监督任务”来学习通用语言表示;之后在特定下游任务(如分类、生成)上进行有监督微调(Fine-tuning)。这个过程常被称为“上游预训练 + 下游微调”范式。
一、什么是“自监督预训练”?
🔹 核心思想:
- 不依赖人工标注标签;
- 利用数据本身的结构自动构造监督信号(即“自监督”);
- 目标是让模型学会语言的通用知识(语法、语义、事实等)
例如:在Bert模型中
| BERT | 掩码语言建模(MLM) | 随机遮盖句子中一些词,让模型预测被遮盖的词 |
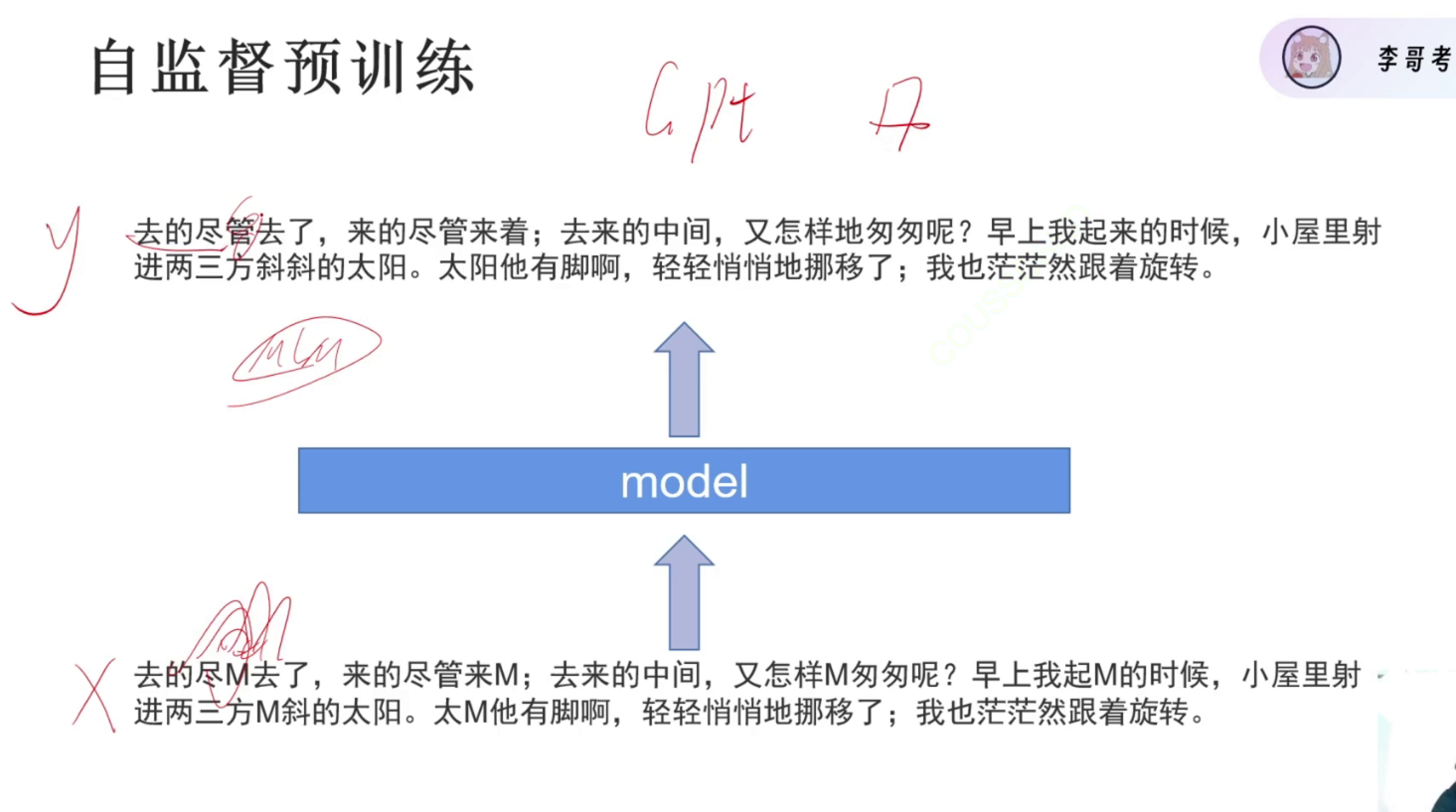
本节用的方法还是MLM
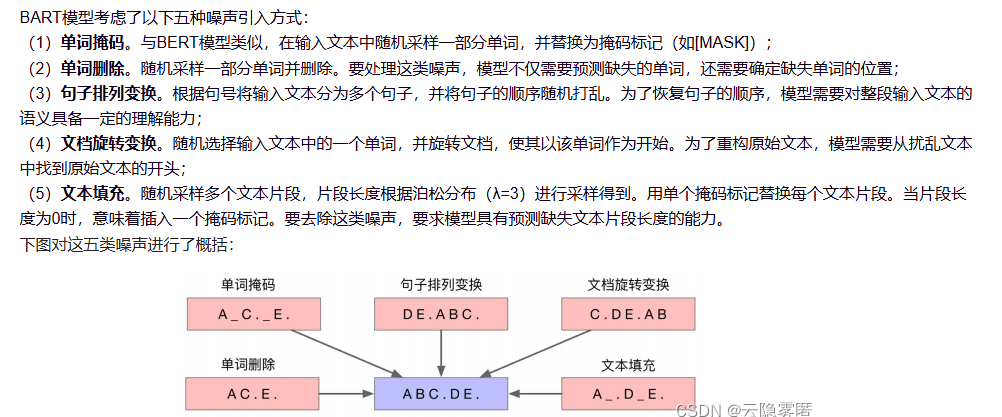
为什么选用Bart模型?(要对其周围模也了解 transformer、gpt)
Bart在摘要生成任务 效果达到最好。
Bart是生成模型,他有解码器 生成=Encoder+Decoder
预训练过程
为什么要在大佬预训练之后再进行预训练呢?预训练的数据来源于哪里?
因为大佬预训练的数据来源于网络,而本次任务属于医学领域(CT影像),大佬的模型很可能没见过这样的数据,所以还要再进行预训练。
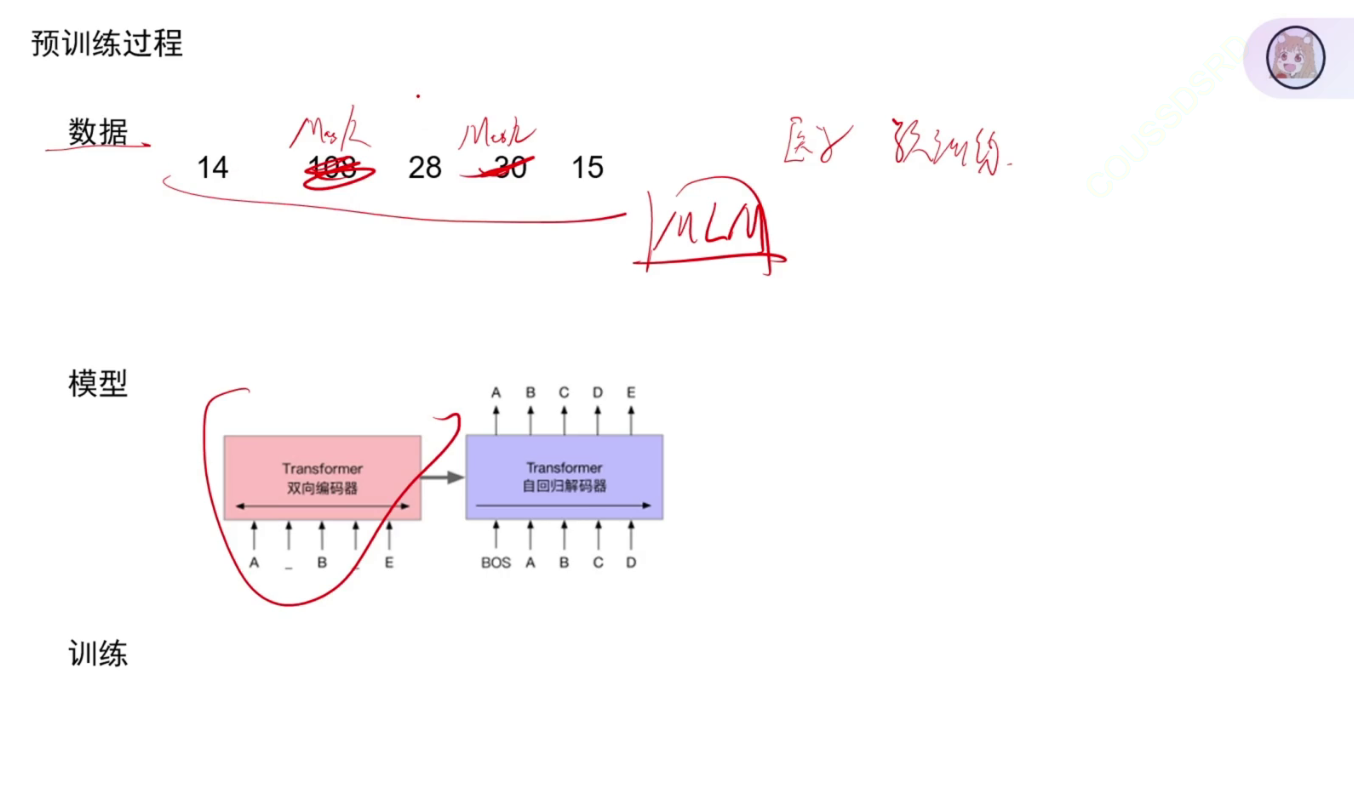
谁能够参加预训练呢(那些数据集)? 预训练是为了提升模型的性能!!
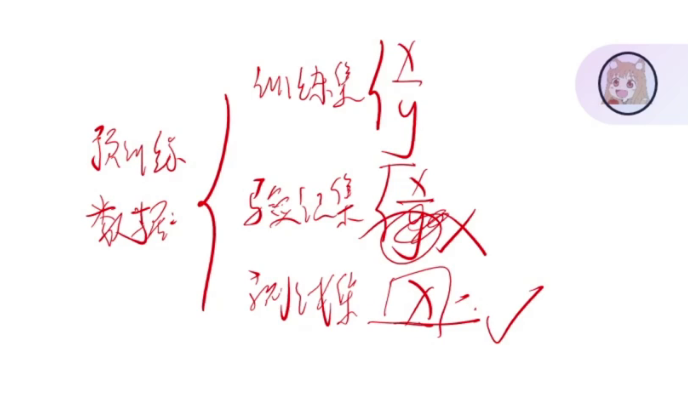
为什么验证集的Y不行? 因为要在下游的任务上做测试的,如果它已见过这个Y了,那就相当于作弊了。
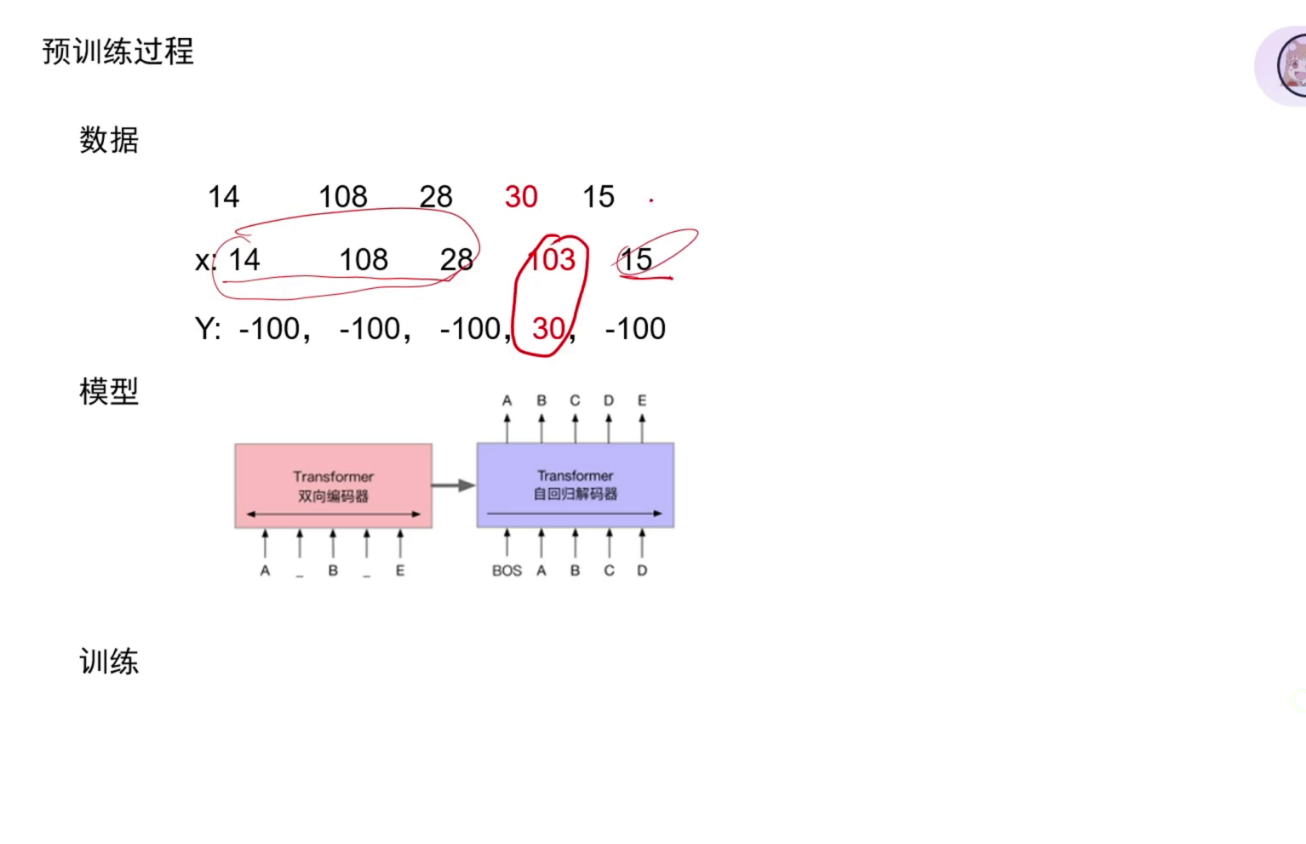
原始数据经过MLM之后,也就是第二行是真正训练时的数据,而Y黑色部分为什么是-100?是由于在进行交叉熵损失时,会使loss为0,也就是不用看原始的数据了,因为都没变化效果不大,只看MLM的部分它提供的loss。
pretrain重点关注部分
def main():
args = parse_args() #设置 字典
setup_logging()
setup_device(args)
setup_seed(args)
os.makedirs(args.savedmodel_path, exist_ok=True)
logging.info("Training/evaluation parameters: %s", args) #LINUX
train_and_validate(args)
if __name__ == '__main__':
main()
####os.makedirs(args.savedmodel_path, exist_ok=True) 创建保存路径
#os.makedirs("a/b/c") # 即使 a/ 和 a/b/ 不存在,也会自动创建 a/ → a/b/ → a/b/c/
#exist_ok=True 设置 exist_ok=True 后:
#如果目录不存在 → 正常创建;
#如果目录已存在 → 不做任何操作,也不报错。finetine(微调)重点学习
def __getitem__(self, idx):
source =[self.sos_id]+ self.tk.convert_tokens_to_ids([x for x in self.samples[idx][1].split()]) + [self.eos_id]
#self.samples[idx] 就是我们的样本
#举例['1624', '296 12 74 71 64 56 13 112 52 43 44 23 21 25 10 169 14 108 28 15 13 31 29 20 18 10 14 32 101 102 51 93 45 11 575 39 16 14 47 51 764 10 24 977 26 37 15 13 68 60 556 79 46 50 19 15 13 20 18 10', '150 107 104 113 110 226 296 12 74 71 64 56 91 208 73 14 198 209 40 73 45 11 124 105 133 134 27 125 183 238 203 241 121 98 1118']
#第一个为id 第二个为CT描述 第三个为医生描述
#[x for x in self.samples[idx][1].split()] 将CT描述空格分隔开 -》一个一个的数字列表 因为CT描述是作为X(数据)输入
#然后把它转为ids 可理解为原本是汉字
#完整步骤 self.tk.convert_tokens_to_ids把汉字转为ids 在前面和后面都加上token (开始和结束)
用于图片字幕的相似度评判。图片image作为下标,并不是关注点,把真实标签y和预测值pred都传入,关注的是下标后面的字幕。
知道用法就行。调用CiderD函数,把标签跟预测值传入 就会自动计算相似度
为什么要处理词表?
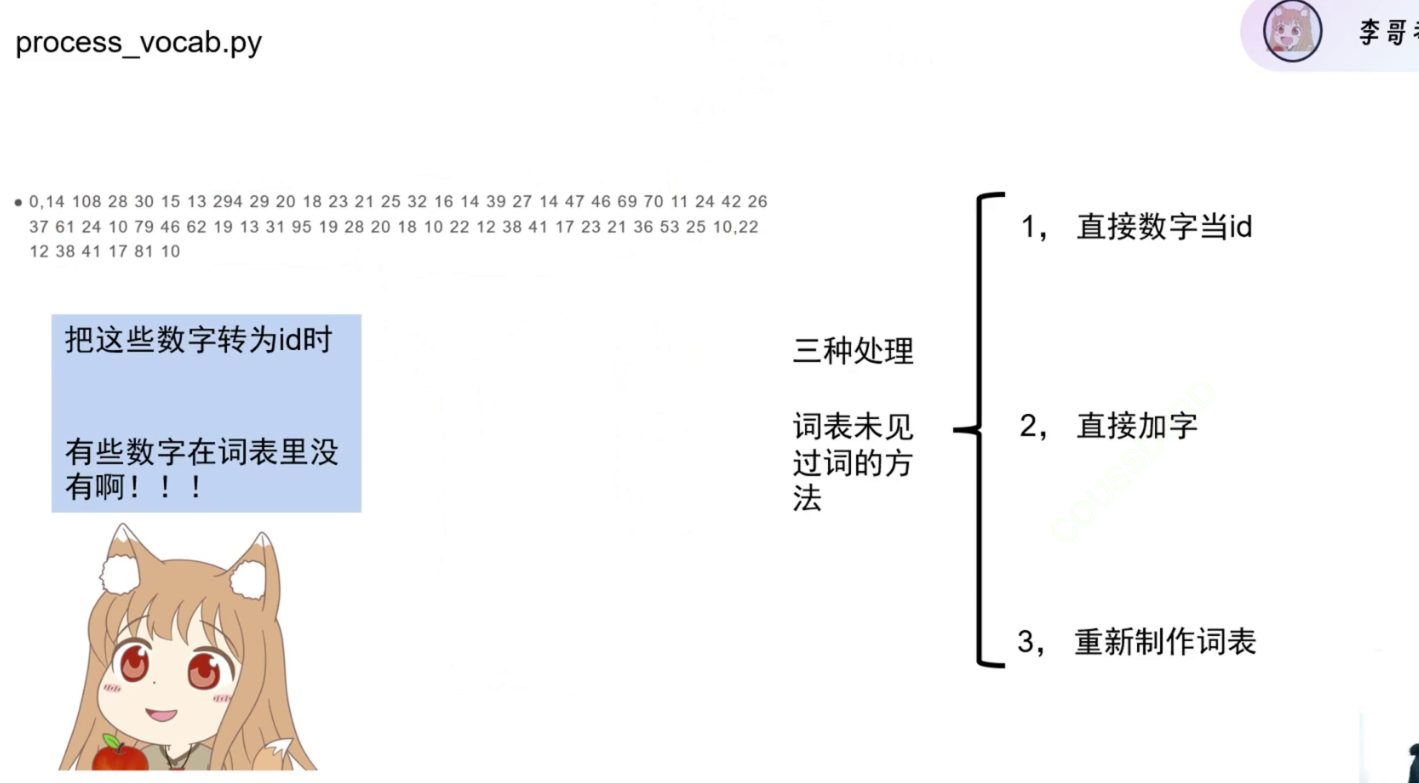
🔹 核心原因:词表是模型与文本之间的桥梁
- 模型不能直接读中文/英文单词;
- 必须把每个 token 映射成一个整数 ID(即词表中的索引);
- 如果某个 token 不在词表里 → 无法映射 → 变成
<unk>(未知词),信息丢失!
为什么不选1、2
1.如果你“直接用数字当 ID”而不通过 tokenizer 映射,那么 101 可能被错误地当作 [CLS],而实际上它在你的新词表中代表一个普通词(比如“苹果”)。这会导致模型严重误解输入,性能崩溃。
2.关于‘直接加字’的方法,虽然实现简单,但它可能导致词表过度膨胀。
因为预训练模型(如 BERT)的词表已经包含数万个子词单元,如果我们在其基础上不断添加新词(尤其是低频领域词),会导致:
- 嵌入层参数急剧增加,占用更多显存;
- 输出分类层维度变大,使得 softmax 计算开销上升;
- 大量新增词频次极低,难以有效训练,反而引入噪声。
3为什么效果好
1. 保证模型结构与词表一致
- 模型的嵌入层(embedding layer)大小 =
vocab_size - 如果你只“加几个字”,但没调用
resize_token_embeddings(),就会出现:- 输入 ID 超出嵌入矩阵维度 → 报错或取到随机值
- 输出 logits 维度不对 → loss 计算错误
💡 只有重新制作词表 + 重新加载模型 + 调整 embedding 层,才能确保所有组件匹配
2.提高任务性能
- 重新建词表可以让:
- 高频领域词获得更高频率 → 更好的嵌入表示;
- 低频通用词被合并或过滤 → 降低噪声;
- 整体词表更“贴合任务”。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)